AI智能体(Agent)大模型入门【8】--关于ocr文字识别图片识别
目录
前言
OCR 的定义
OCR 的工作原理
OCR 的应用场景
常见的 OCR 工具
技术挑战
ocr安装
ocr使用演示
前言
本篇章不涉及代码,主要涉及有关于ocr具体是干什么的,以及如何安装ocr,在下一篇章将会教学ocr的代码写法。
OCR 的定义
OCR(Optical Character Recognition,光学字符识别)是一种将图片、扫描文档或手写文字中的字符转换为可编辑和可搜索的文本数据的技术。其核心是通过算法分析图像中的像素分布,识别并提取文字信息。
OCR 的工作原理
- 图像预处理:对输入图像进行降噪、二值化、倾斜校正等操作,提升识别准确率。
- 文本检测:定位图像中的文字区域,通常通过深度学习模型(如CNN、YOLO)实现。
- 字符分割与识别:将检测到的文字分割为单个字符,利用分类模型(如LSTM、Transformer)识别字符内容。
- 后处理:根据语言模型或上下文修正识别结果(如纠错、格式优化)。
OCR 的应用场景
- 文档数字化:将纸质文件转换为电子文档(如PDF、Word)。
- 金融领域:自动识别银行卡、身份证、发票等信息。
- 工业自动化:读取产品标签、流水线编码。
- 移动应用:实时翻译、手写笔记转文字。
常见的 OCR 工具
- 开源工具:Tesseract、EasyOCR。
- 商业服务:Google Cloud Vision、Azure Computer Vision、Adobe Acrobat。
- 移动端 SDK:百度OCR、腾讯OCR。
技术挑战
- 复杂背景干扰:图像中的噪点、水印可能降低识别率。
- 多语言混合:需支持不同语种或特殊符号(如数学公式)。
- 手写体识别:因书写风格差异,准确率低于印刷体。
OK以上就是有关于ocr的快速了解信息,那么接下来就是如何安装相关的ocr了,以及ocr在本地如何使用(代码链接需要下一篇章讲解)
ocr安装
有很多ocr可以选择,但是为了教学和免费使用ocr我们选择一个开源轻便的小巧工具umi-ocr
GitHub - hiroi-sora/Umi-OCR: OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。
进入到该页面,找到右侧栏
点击这个+30进行下载
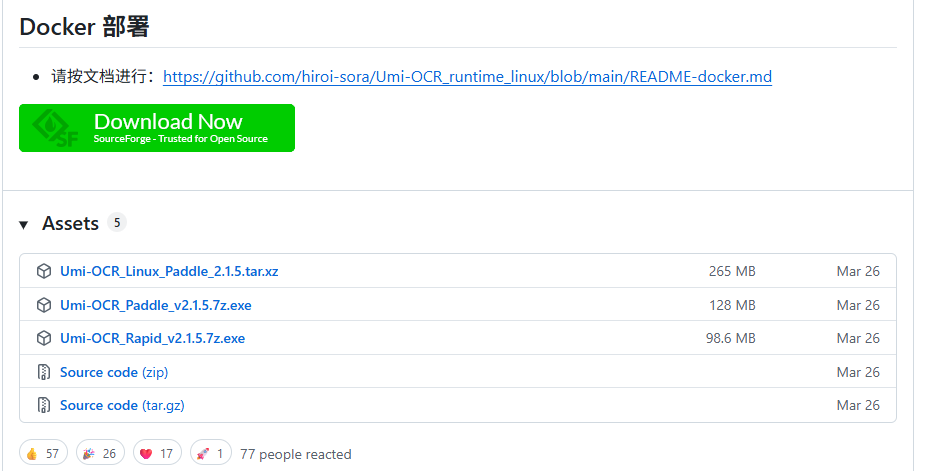
然后下拉找到如图片所示的位置,依据自己的电脑进行下载安装即可
安装很简单
后续

找到全局设置
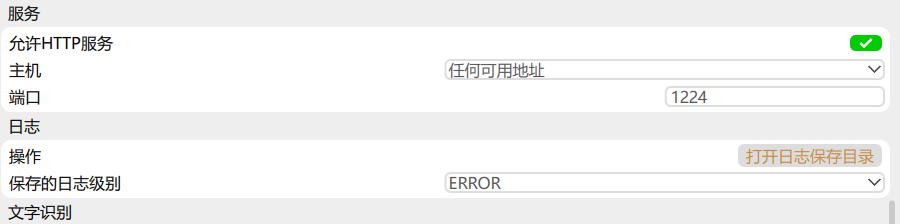
然后将服务改为任何可用地址,其他不变。
ocr使用演示
在此处随便拖入一个文件
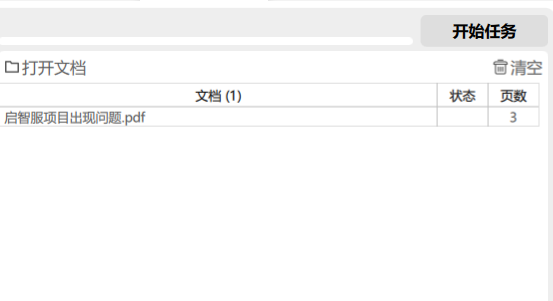
例如图片这样,然后点击开始任务

然后右边就会出现一些文字,比如传入图片也是一样的,不过呢,传入这些图片需要带有文字,否则失败无法识别,至于原因在篇章刚开始的时候已经提到过了
到这里,ocr基本介绍完成,将会在下一篇章介绍如何在pycharm中编写调用ocr工具