从零搭建 RAG 智能问答系统2:实现chainlit个性化设计以及文件上传预览
在 AI 聊天应用开发中,Chainlit 凭借其轻量化、易集成的特性,成为快速搭建对话界面的热门工具。本文将聚焦 Chainlit 的两大核心需求 ——个性化界面设计与文件上传预览功能,结合实际代码案例,从环境配置到功能实现,带你一步步构建更贴合业务场景的 AI 聊天应用。
一、基础环境准备
在开始个性化开发前,需先完成基础依赖安装与项目初始化,确保后续功能可正常运行。
1.1 核心依赖安装
Chainlit 应用需依赖chainlit本身、llama-index(用于知识库构建与对话引擎),以及对应大模型 SDK。通过 pip 命令一键安装:
# 安装Chainlit核心库
pip install chainlit
# 安装llama-index(含文档处理、向量索引功能)
pip install llama-index-core llama-index-embeddings-huggingface
# 安装大模型相关依赖(以阿里云千问为例,其他模型按需安装)
pip install openai1.2 项目结构
为保证代码可读性与可维护性,建议按功能模块划分文件,推荐项目结构如下:
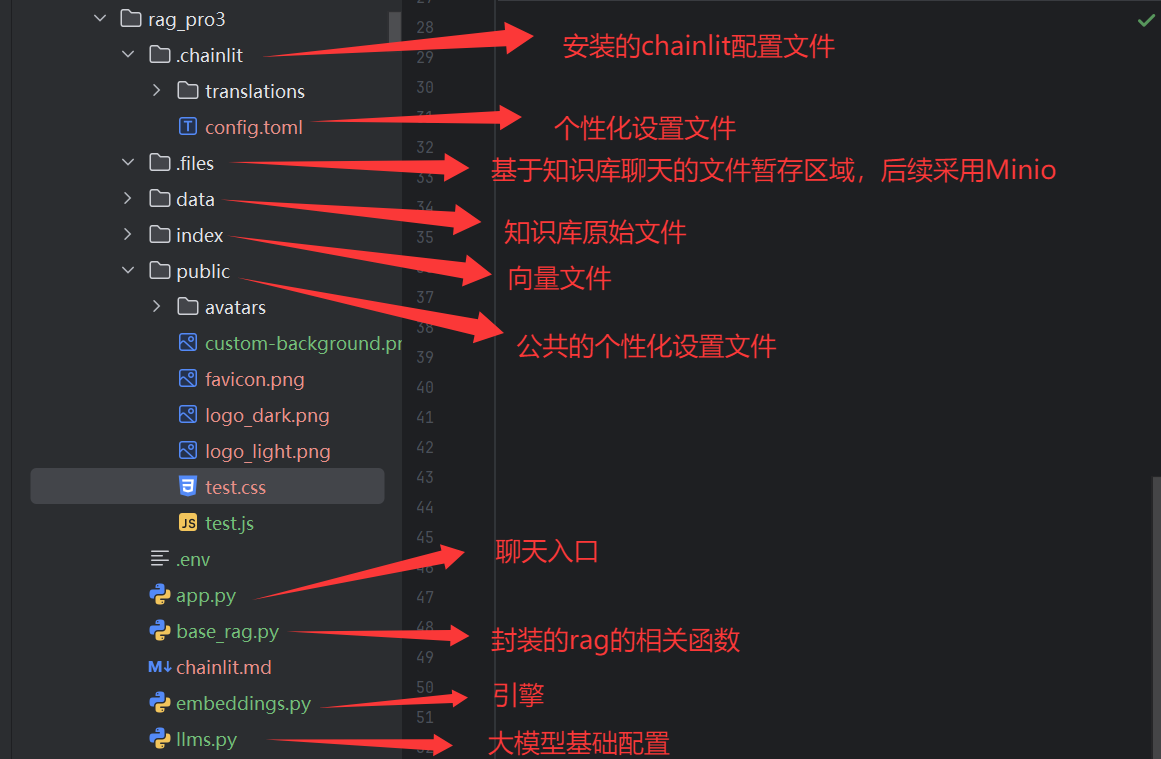
二、Chainlit 个性化界面设计
Chainlit 的界面风格、功能开关均通过配置文件config.toml控制,无需修改前端源码即可实现高度定制。以下从基础样式、功能开关、安全配置三个维度展开,以下是对应的全部代码:
# 项目基础配置
[project]
# 需要用户提供的环境变量列表
user_env = []
# 会话超时时间(秒)
session_timeout = 3600
# 用户会话总超时时间(秒)
user_session_timeout = 1296000
# 是否启用第三方缓存
cache = false
# 是否持久化用户环境变量
persist_user_env = false
# 是否在UI中隐藏用户环境变量明文
mask_user_env = false
# 允许的跨域来源
allow_origins = ["*"]# 功能特性配置
[features]
# 是否允许HTML内容
unsafe_allow_html = false
# 是否支持LaTeX数学表达式
latex = false
# 新消息到达时是否自动滚动
user_message_autoscroll = true
# 是否自动为线程打标签
auto_tag_thread = true
# 是否允许用户编辑消息
edit_message = true# Slack集成配置
[features.slack]
# 是否在收到消息时添加表情反应
reaction_on_message_received = false# 文件上传配置
[features.spontaneous_file_upload]
# 是否启用文件上传
enabled = true
# 允许的文件类型
accept = ["*/*"]
# 最大上传文件数量
max_files = 20
# 单个文件最大大小(MB)
max_size_mb = 500# 音频功能配置
[features.audio]
# 是否启用音频功能
enabled = false
# 音频采样率
sample_rate = 24000# Model Context Protocol配置
[features.mcp]
# 是否启用MCP功能
enabled = false# MCP SSE子功能
[features.mcp.sse]
enabled = true# MCP Streamable HTTP子功能
[features.mcp.streamable-http]
enabled = true# MCP Stdio子功能
[features.mcp.stdio]
enabled = true
# 允许的可执行文件
allowed_executables = [ "npx", "uvx" ]# UI界面配置
[UI]
# 助手名称
name = "Assistant"
# 默认侧边栏状态
default_sidebar_state = "open"
# Chain of Thought显示模式
cot = "full"
# 自定义CSS文件路径
custom_css = "public/test.css"
# 自定义JavaScript文件路径
custom_js = "public/test.js"
# 警告框样式
alert_style = "classic"
# 登录页面背景图片
login_page_image = ""
# Logo文件URL
logo_file_url = ""
# 默认头像URL
default_avatar_file_url = ""# 元数据
[meta]
# 生成此配置的工具版本
generated_by = "2.7.2"
以下是对应的配置文件名称和作用:
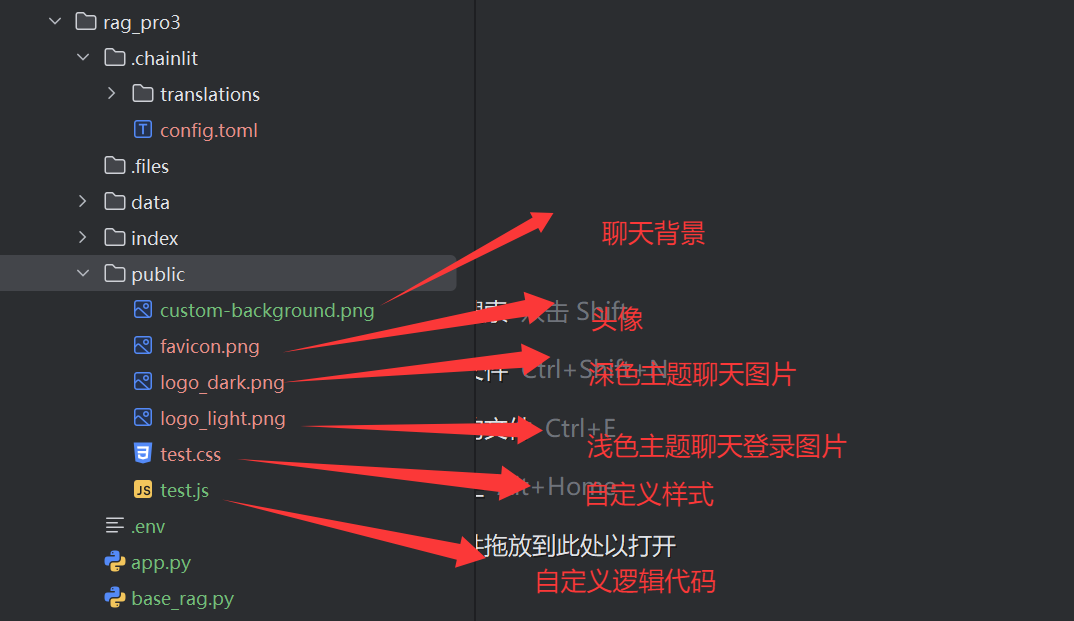
test.css代码(设置聊天背景):
#root {background-image: url('../public/custom-background.png');background-size: cover;background-position: center;background-repeat: no-repeat;
}
test.js代码:
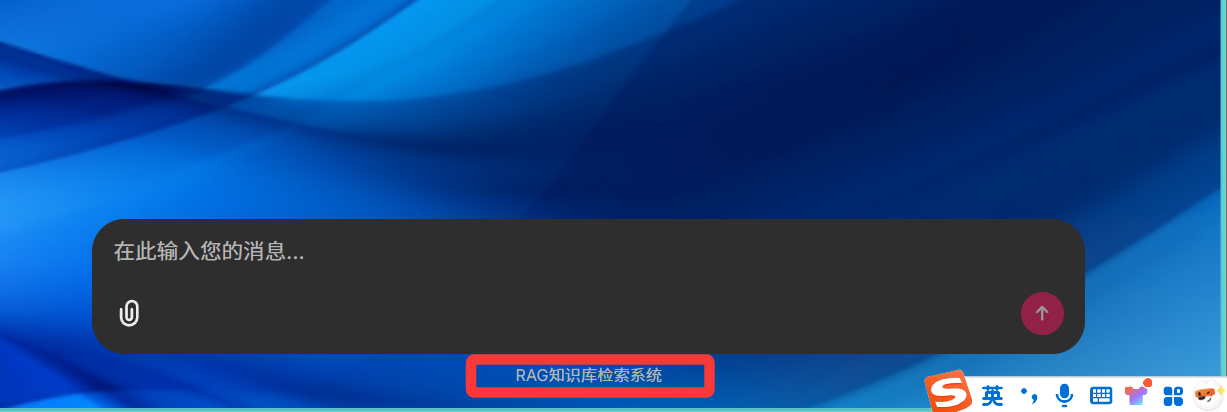
document.addEventListener('DOMContentLoaded', function () {const observer = new MutationObserver(() => {const spanElement = document.querySelector('div.text-xs.text-muted-foreground span');if (spanElement) {spanElement.textContent = "RAG知识库检索系统";observer.disconnect();}});observer.observe(document.body, {childList: true,subtree: true});
});
更多的个性化设置可以查看官网的设置,这里就没有带大家来意义设置了,以下是个性化设置的官网代码:
Overview - Chainlit![]() https://docs.chainlit.io/customisation/overview
https://docs.chainlit.io/customisation/overview
三、文件上传功能实现
用户上传文件(如 PDF、图片)是 AI 聊天应用的常见需求,Chainlit 提供了cl.File和cl.Image类处理上传元素,结合llama-index可实现 “上传文件→构建索引→基于文件对话” 的完整流程。
3.1 核心逻辑:检测上传文件并构建索引
在主程序app_chat.py中,通过@cl.on_message装饰器监听用户消息,提取其中的文件元素,再调用 RAG 模块构建向量索引:
from typing import List
import chainlit as cl
from llama_index.core import Settings, SimpleDirectoryReader
from llama_index.core.chat_engine.types import ChatMode
from llms import qianwen_llm # 导入千问大模型
from base_rag import create_chat_model, create_index_new # 导入RAG功能# 聊天启动时初始化:设置大模型、创建默认聊天引擎
@cl.on_chat_start
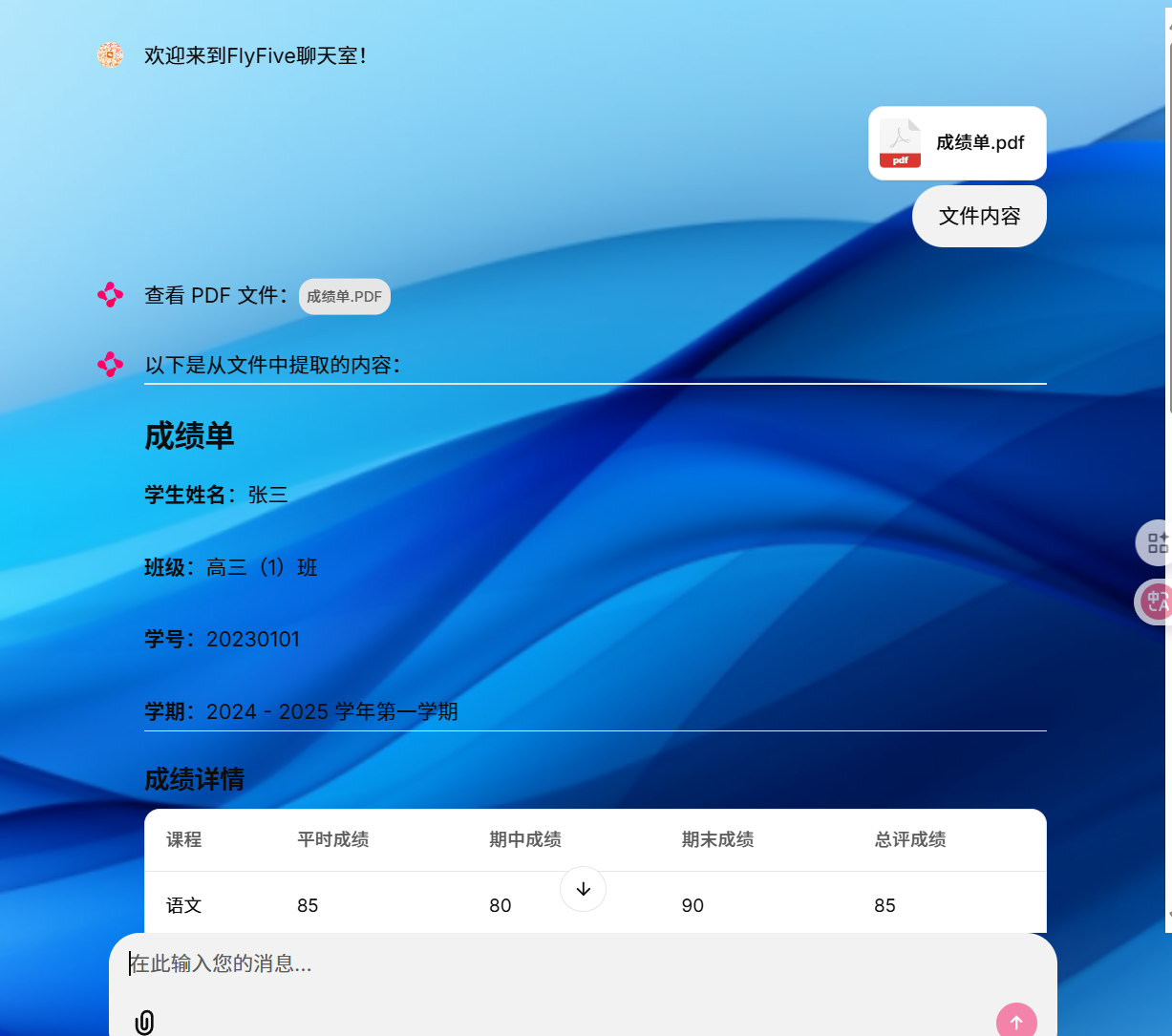
async def start():# 配置大模型(此处用千问,可替换为Moonshot、DeepSeek)Settings.llm = qianwen_llm()# 加载本地知识库的聊天引擎(若无初始知识库,可改用SimpleChatEngine)chat_engine = await create_chat_model()# 将聊天引擎存入用户会话,供后续调用cl.user_session.set("chat_engine", chat_engine)# 发送欢迎消息await cl.Message(author="FlyFive", content="欢迎来到FlyFive聊天室!支持上传PDF并基于文件问答~").send()# 处理用户消息:检测文件上传、更新聊天引擎
@cl.on_message
async def main(message: cl.Message):# 1. 提取用户上传的文件(筛选File和Image类型)files = []for element in message.elements:if isinstance(element, cl.File) or isinstance(element, cl.Image):files.append(element.path) # 存储文件本地路径# 2. 若有文件上传,基于文件创建新索引并更新聊天引擎if len(files) > 0:# 读取文件内容(支持PDF、TXT、Markdown等)data = SimpleDirectoryReader(input_files=files).load_data()# 异步创建向量索引(存入index目录)index = await create_index_new(data)# 基于新索引构建聊天引擎(上下文模式,可关联文件内容)new_chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONTEXT)# 更新用户会话中的聊天引擎,后续对话将基于新文件cl.user_session.set("chat_engine", new_chat_engine)# 告知用户文件处理完成await cl.Message(content=f"已成功加载文件:{[f.split('/')[-1] for f in files]},可开始提问~").send()# 3. 后续逻辑:流式生成AI回复(见下文)# ...
3.2 关键依赖:RAG 模块与嵌入模型
文件上传后需将内容转为向量索引,才能支持 “基于文件问答”,这依赖base_rag.py(索引创建)和embeddings.py(文本转向量):
(1)嵌入模型配置(embeddings.py)
使用开源的BAAI/bge-small-zh-v1.5模型,适合中文文本嵌入:
from llama_index.embeddings.huggingface import HuggingFaceEmbeddingdef embed_model_local_bge_small(**kwargs):"""创建本地嵌入模型,缓存到embed_cache目录"""embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5",cache_folder=r"../embed_cache", # 缓存模型,避免重复下载**kwargs)return embed_model
(2)RAG 索引与聊天引擎(base_rag.py)
实现 “创建索引→加载索引→构建聊天引擎” 的流程:
import os
from llama_index.core.chat_engine.types import ChatMode
from llama_index.core.indices.base import BaseIndex
from llama_index.core.memory import ChatMemoryBufferos.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"# 基础RAG模型
from llama_index.core import (SimpleDirectoryReader,VectorStoreIndex,Settings,StorageContext,load_index_from_storage
)# 导入本地的嵌入模型
from embeddings import embed_model_local_bge_small
# 设置嵌入模型
Settings.embed_model = embed_model_local_bge_small()# 1、创建索引的方法
def create_index():"""构建向量数据索引 """# SimpleDirectoryReader--- 读取目录下的文件# input_dir="data"---- 输入目录# recursive=True ---- 递归搜索# load_data --- 读取数据data = SimpleDirectoryReader(input_dir="data", recursive=True).load_data() # 读取数据# VectorStoreIndex---- 创建向量数据索引# from_documents ------ 从文档创建索引index = VectorStoreIndex.from_documents(data) # 创建索引# storage_context ---- 存储上下文# persist ---- 保存索引# persist_dir="index" --- 保存目录index.storage_context.persist(persist_dir="index") # 保存索引async def create_index_new(data)->BaseIndex:"""构建向量数据索引 """# VectorStoreIndex---- 创建向量数据索引# from_documents ------ 从文档创建索引index = VectorStoreIndex.from_documents(data) # 创建索引# storage_context ---- 存储上下文# persist ---- 保存索引# persist_dir="index" --- 保存目录index.storage_context.persist(persist_dir="index") # 保存索引return index# 2、创建聊天模型
async def create_chat_model():"""创建聊天模型"""# 读取索引数据# StorageContext---存储上下文# from_defaults ---- 创建存储上下文# persist_dir="index" ---- 索引目录storage_context = StorageContext.from_defaults(persist_dir="index")# 加载索引数据# load_index_from_storage ---- 创建索引index = load_index_from_storage(storage_context)# 构建储存,存储聊天记录,限制token的数量为1024# ChatMemoryBuffer --- 内存缓存数据# token_limit ---- 限制token数量memory = ChatMemoryBuffer.from_defaults(token_limit=1024)# 创建聊天引擎,设置聊天模式为上下⽂模式,并指定记忆和系统提示# chat_mode: 设置聊天模式为上下⽂模式,这意味着AI的回答将基于⽤户提供的上下⽂内容# memory: ⽤于存储聊天历史记录,以便AI在回答时能考虑到之前的对话内容# system_prompt: 系统提示,定义了AI的⾏为准则,即AI助⼿应基于⽤户提供的上下⽂内 容来回答问题,不允许随意编造回答chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONTEXT,memory=memory,system_prompt="你是⼀个AI助⼿,可以基于⽤户提供的上下⽂内容,回答⽤户的问题。不能肆意编造回答。")return chat_engineif __name__ == "__main__":create_index()(3)运行效果
四、PDF 预览功能实现
用户上传 PDF 后,若能直接在界面预览,可大幅提升交互体验。Chainlit 提供cl.Pdf类支持 PDF 嵌入,只需筛选上传文件中的 PDF 类型,生成预览组件即可。
4.1 预览核心函数
在app_chat.py中添加view_pdf函数,筛选 PDF 文件并发送预览消息:
from chainlit.element import ElementBasedasync def view_pdf(elements: List[ElementBased]):"""筛选PDF文件,生成预览组件并发送给用户"""pdf_files = [] # 存储PDF预览组件pdf_names = [] # 存储PDF文件名(用于消息提示)# 遍历元素,筛选后缀为.pdf的文件for element in elements:if element.name.endswith(".pdf"):# 创建PDF预览组件:display="side"表示侧边预览pdf = cl.Pdf(name=element.name,display="side", # 预览模式:side(侧边)/inline( inline(内嵌)path=element.path # PDF文件本地路径)pdf_files.append(pdf)pdf_names.append(element.name)# 若有PDF文件,发送预览消息if len(pdf_files) > 0:await cl.Message(content=f"已为您预览PDF文件:{', '.join(pdf_names)}",elements=pdf_files # 附加PDF预览组件).send()
4.2 集成到消息处理流程
在@cl.on_message中调用view_pdf,实现 “上传即预览”:
@cl.on_message
async def main(message: cl.Message):# 1. 提取文件并更新聊天引擎(前文已实现)# ...(省略文件处理逻辑)# 2. 调用PDF预览函数(关键!上传PDF后自动预览)await view_pdf(message.elements)# 3. 流式生成AI回复(基于文件或默认知识库)chat_engine = cl.user_session.get("chat_engine")msg = cl.Message(content="", author="Assistant")# 异步调用聊天引擎,流式获取回复res = await cl.make_async(chat_engine.stream_chat)(message.content)# 逐token发送回复,实现“打字机”效果for token in res.response_gen:await msg.stream_token(token)# 发送完整回复await msg.send()
效果展示:
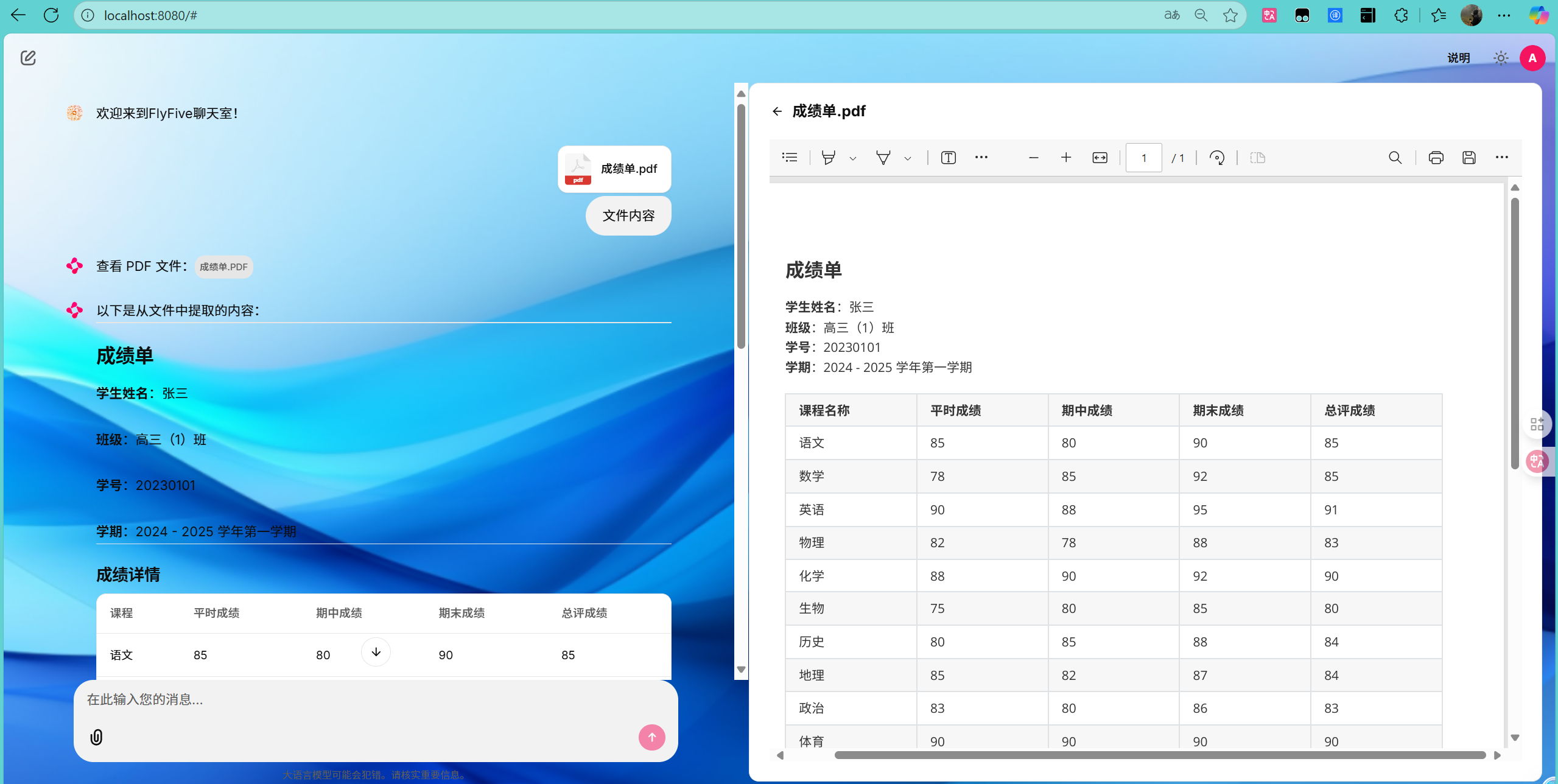
4.3 常见问题解决
若预览时出现 “ConnectionResetError”(远程主机强迫关闭连接),大概率是浏览器插件冲突(如 IDM 下载插件),解决方案:
- 关闭浏览器中的下载类插件(如 IDM、迅雷);
- 若仍有问题,尝试更换浏览器(Chrome/Firefox 兼容性更佳);
- 检查 PDF 文件路径是否正确(确保
element.path为本地可访问路径)。
五、登录权限控制
为保证应用安全性,可添加简单的密码认证,限制仅授权用户使用。Chainlit 提供@cl.password_auth_callback装饰器实现:
@cl.password_auth_callback
def auth_callback(username: str, password: str):"""密码认证回调:验证用户名密码是否匹配"""# 实际生产环境建议从数据库/配置文件读取,此处为示例if (username, password) == ("admin", "admin"):# 认证成功,返回用户信息(含角色、标识)return cl.User(identifier="admin",metadata={"role": "admin", "provider": "credentials"})# 认证失败,返回Nonereturn None
启动应用后,用户需访问http://localhost:8000/login输入账号密码,才能进入聊天界面。
六、应用启动与测试
6.1 启动命令
在项目根目录执行以下命令,指定端口启动应用:
# --port 8000:指定端口为8000
# -w:启用自动重载(代码修改后无需重启)
chainlit run app_chat.py --port 8000 -w
6.2 功能测试流程
- 访问应用:打开浏览器输入
http://localhost:8000,登录(若启用认证); - 个性化验证:确认助手名称、主题、头像是否符合
config.toml配置; - 文件上传:点击聊天框旁的 “上传” 按钮,选择 1-2 个 PDF 文件,观察是否提示 “文件加载完成”;
- PDF 预览:上传后检查是否显示 PDF 预览组件,点击可翻页查看内容;
- 基于文件问答:向 AI 提问 “总结该 PDF 的核心内容”,验证是否基于上传文件回复。
总结
本文围绕 Chainlit 的个性化设计与文件上传预览两大核心需求,从配置文件定制、代码功能实现到测试验证,提供了完整的实战方案。关键亮点包括:
- 通过
config.toml快速实现界面主题、功能开关的个性化; - 基于 Chainlit 的
cl.File与llama-index,实现 “上传文件→构建索引→基于文件对话” 的闭环; - 利用
cl.Pdf类实现 PDF 侧边预览,提升用户交互体验。
后续可进一步扩展功能,如支持更多文件类型(Word、Excel)、添加文件下载功能,或对接云存储(如 OSS、S3)实现文件持久化,让应用更贴合生产场景需求。