网站风格评价next wordpress
一、爬虫基础概念
什么是爬虫?
网络爬虫(Web Crawler)是一种自动获取网页内容的程序,它像蜘蛛一样在互联网上"爬行",收集和提取数据。
爬虫应用场景:
-
搜索引擎(Google、百度)
-
价格监控(电商比价)
-
舆情分析(社交媒体监控)
-
数据采集(研究、分析)
二、环境准备
1. 安装Python
-
官网下载:Download Python | Python.org
-
安装时勾选"Add Python to PATH"
2. 安装必要库(命令行执行)
pip install requests beautifulsoup4 pandas3. 安装开发工具(可选)
推荐使用VS Code:Visual Studio Code - Code Editing. Redefined
三、第一个爬虫:获取网页标题
1. 创建文件 first_crawler.py
import requests
from bs4 import BeautifulSoup# 目标网址
url = "https://example.com"# 发送HTTP请求
response = requests.get(url)# 检查请求是否成功
if response.status_code == 200:# 解析HTML内容soup = BeautifulSoup(response.text, 'html.parser')# 提取网页标题title = soup.title.stringprint(f"网页标题: {title}")
else:print(f"请求失败,状态码: {response.status_code}")2. 运行爬虫
python first_crawler.py输出结果:
网页标题: Example Domain四、爬虫核心组件详解
1. requests库 - 发送HTTP请求
# GET请求
response = requests.get(url)# POST请求
response = requests.post(url, data={'key': 'value'})# 添加请求头(模拟浏览器)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)2. BeautifulSoup - 解析HTML
from bs4 import BeautifulSoup# 创建解析器对象
soup = BeautifulSoup(html_content, 'html.parser')# 查找元素
# 通过标签名
soup.find('div') # 查找第一个div
soup.find_all('a') # 查找所有a标签# 通过类名
soup.find(class_='header')# 通过ID
soup.find(id='main-content')# 组合查找
soup.find('div', class_='article', id='post-123')五、爬虫道德与法律
爬虫行为准则:
-
尊重robots.txt:检查目标网站的爬虫协议
-
限制请求频率:避免对网站造成过大负担
-
不爬取敏感信息:如个人隐私、版权内容
-
遵守网站条款:查看网站的使用条款
如何检查robots.txt:
在网站根目录后添加/robots.txt,例如:
https://example.com/robots.txt
多说一句:
代码:title=soup.title.string中的第二个title哪来的?
这个title其实是网页中的title标签,如:
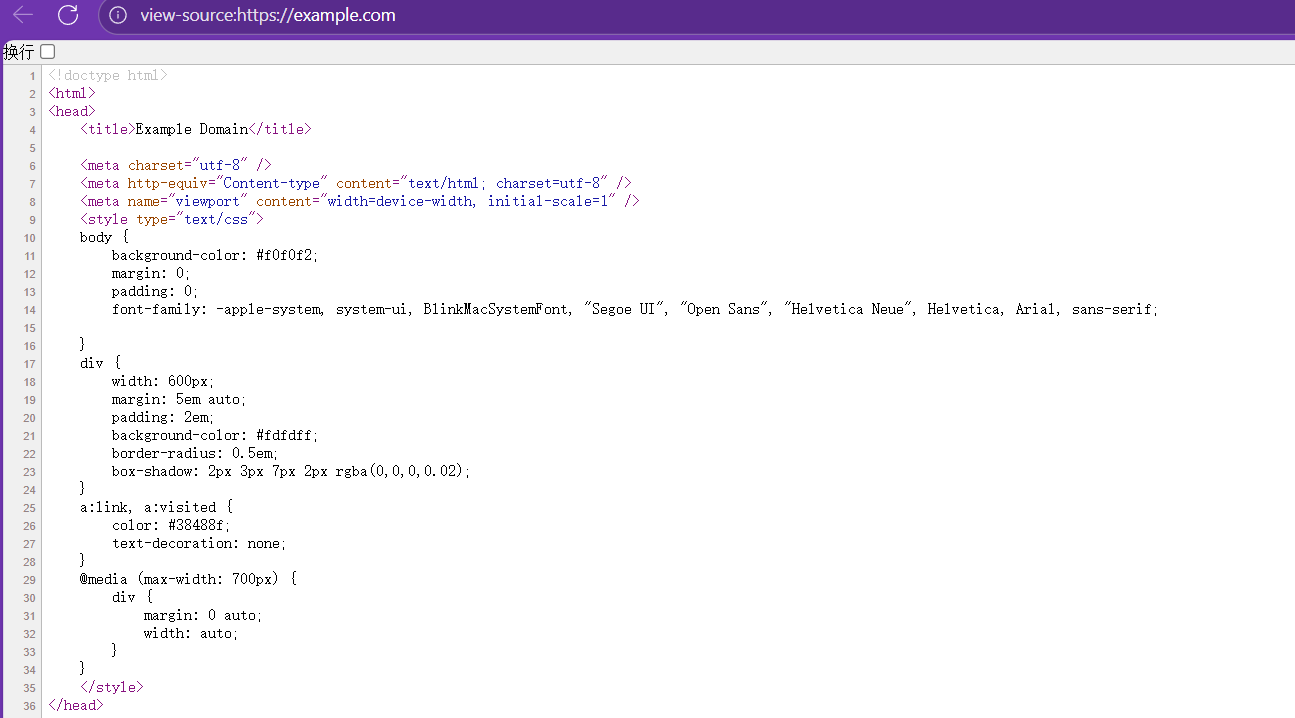
这里的内容是WEB里面的相关知识,这里不过多叙述。
注:该代码是本人自己所写,可能不够好,不够简便,欢迎大家指出我的不足之处。如果遇见看不懂的地方,可以在评论区打出来,进行讨论,或者联系我。上述内容全是我自己理解的,如果你有别的想法,或者认为我的理解不对,欢迎指出!!!如果可以,可以点一个免费的赞支持一下吗?谢谢各位彦祖亦菲!!!!