网站数据库问题网站开发专业就业培训学校
目录
一、Metamorph
1、概述
2、VPiT
3、数据
4、实验结论
二、LlamaFusion
1、概述
2、回顾Transfusion
3、LlamaFusion架构
4、实验分析
5、LlavaFusion
三、MetaQuery
1、概述
2、架构
3、实验分析
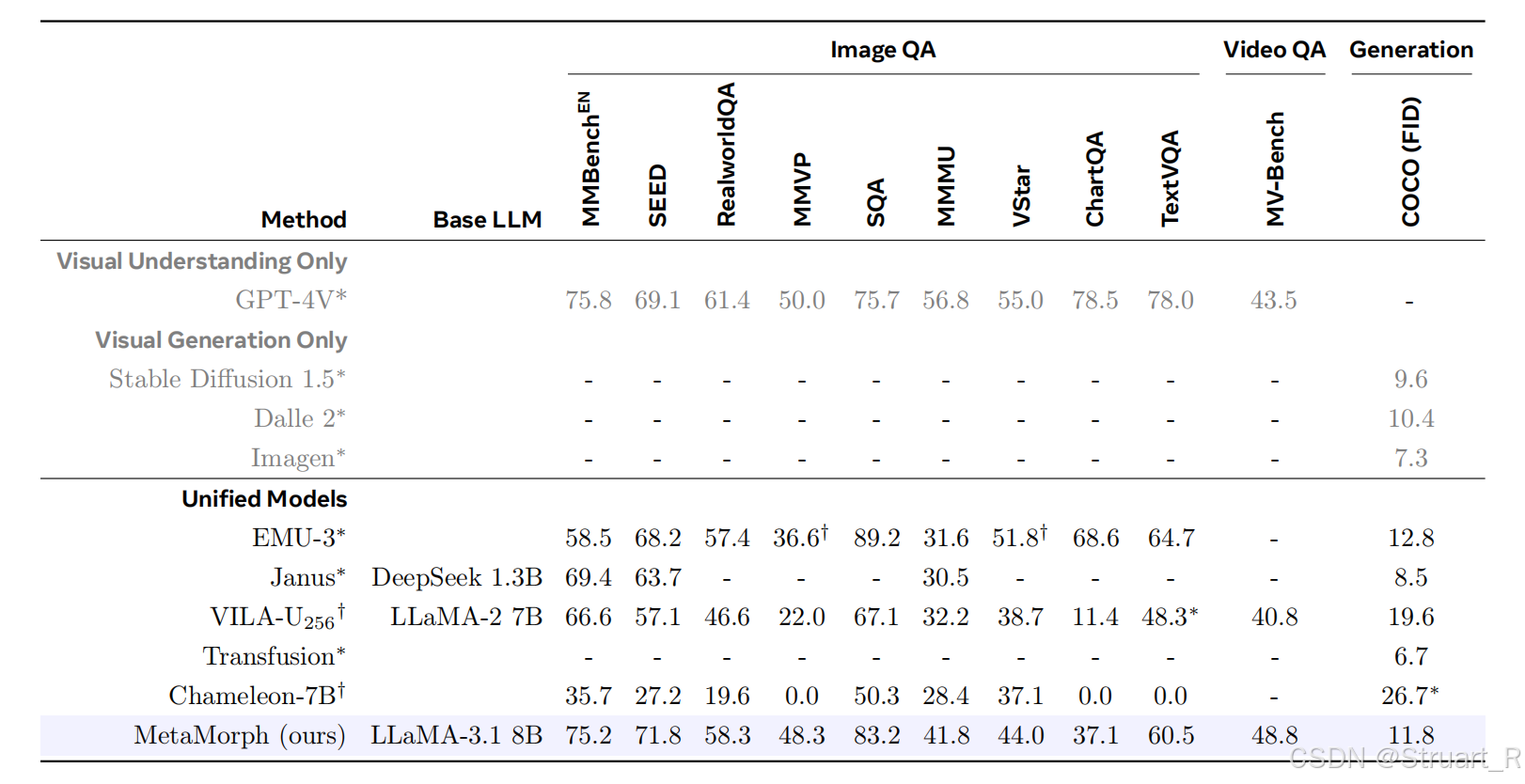
Metamorph、LlamaFusion、MetaQuery这三篇论文都是Meta发布的,均聚焦于统一多模态模型。
Metamorph提出通过指令微调来解锁预训练大语言模型的视觉生成能力,发现视觉生成能力是视觉理解的副产品,理解数据对生成的提升很高。LlamaFusion通过冻结预训练LLM,分离FFN和注意力机制,实现LLM复用,并扩展到图像编辑任务。MetaQuery利用learning query来替代模块分离,实现零训练损失的知识迁移的图像生成。
一、Metamorph
1、概述
Metamorph提出了一个重要的指令微调方法VPiT,可以使得预训练的大语言模型LLM迅速转换为一个统一的自回归多模态生成模型。(而以往的模型都是通过指令微调将LLM实现视觉语言理解功能,所以Saining Xie团队将指令微调转向统一的理解生成模型)
另外用实验证明了生成能力是理解能力的副产品,理解和生成相互促进但并不对称,理解数据对两者贡献更大。
2、VPiT
首先我们知道LLaVA提出了指令微调,将大语言模型能够用于视觉输入,实现视觉理解任务,但需要百万级数量数据的微调。而之后的指令微调操作,也将这个数据量级减小,通过更少的数据微调实现同样的的视觉理解,所以推测生成任务也可以通过少量微调实现。
Vison Encoder + Adapter
首先将LLM变成MLLM需要一个vision encoder将image变成continuous tokens。另外需要一个adaptor或者叫connector来实现文本与图像tokens的align。
所以这里选择了SigLIP VIT-SO400M-14@384,作为image encoder,可以将图像先转换为连续的SigLIP特征之后插值为64个tokens,之后通过一个两层MLP(GeLU激活作激活层)的Adapter来将图像特征维度与LLM特征维度对齐。
Vision Head(VPiT)
通过AR model接一个Vision Head目的是为了回归一个SigLIP encoder编码时相同的tokens,这里初始用的是linear用来回归预测图像tokens,所以最后的SigLIP编码特征是连续的。
Text Head
采用LLM原有的文本头预测文本tokens
AR Model
采用LLaMA作为大模型基底。
多模态AR Model的训练目标
文本tokens:交叉熵损失
视觉tokens:余弦相似度损失
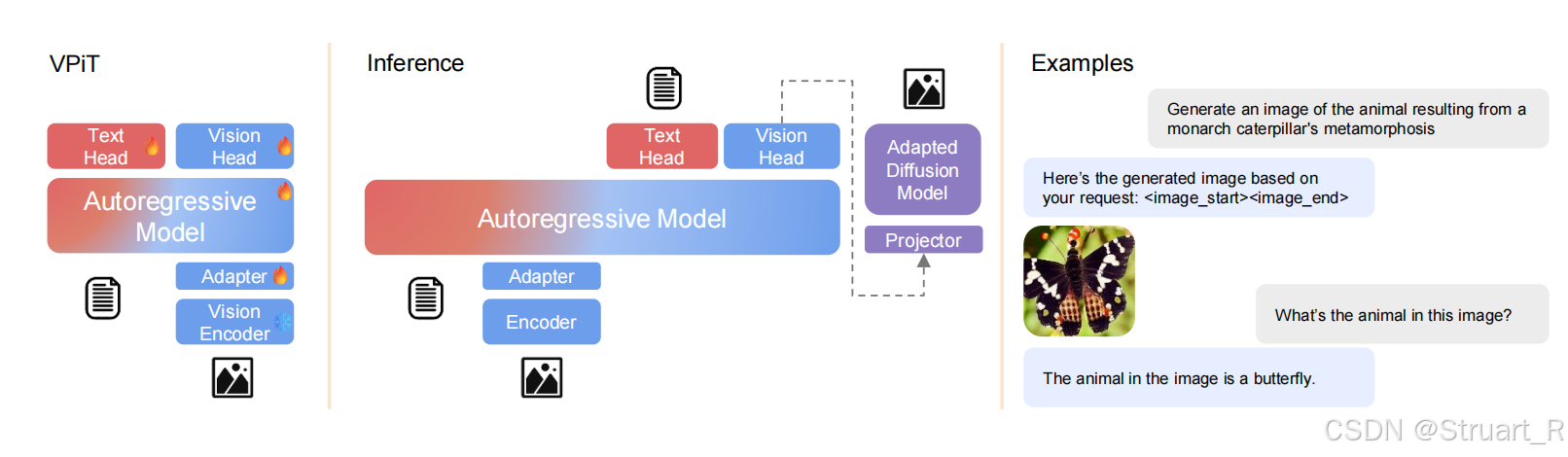
Inference
推理过程架构,不在考虑文本输出,并将VisionHead的输出经过简单的投影层输入到Stable Diffusion1.5中,并生成图片。
这里提到Inference环节不采用任何CoT思维链推理,而通过LLM隐式的推理内部信息,比如“黄石公园所在地的国家国旗”->“黄石公园在美国,美国国旗”->“输出星条旗”。

3、数据
Visual Understanding Data
图像视频+文本-文本回答对,强化视觉语义理解。包括ImageQA和VideoQA。
ImageQA来自Cambrian-7M数据集,数据集格式为:<视觉token>+文本prompt->输出:文本Response。
VideoQA来自VideosStar和ShareVideo数据集,处理1帧视频,并回答动态问题,数据集格式为:<多帧视觉token>+文本prompt->输出:文本Response
视觉理解数据占比70%,主导模型VQA性能。
Visual Generation Data
文本-视觉token对,激活图像生成能力。MetaCLIP数据集共5M。
MetaCLIP格式为:文本prompt->文本Response+视觉tokens。
视觉生成数据只占20%,用于解锁生成能力。
Other visual Data
多模态序列-视觉token,训练跨模态推理与转换能力。包括:
视频数据SomethingSomethingv2,HowTo100M,用于预测未来帧的视觉信息,
视觉思维数据Visualization-of-Thought和VStar,用于教模型先思考后回答,比如某个区域的颜色,并用视觉方法回答我。
图像编辑数据InstructPix2Pix和Aurora,支持图像编辑,风格迁移。
共占比10%,学习多任务的泛化性。

4、实验结论
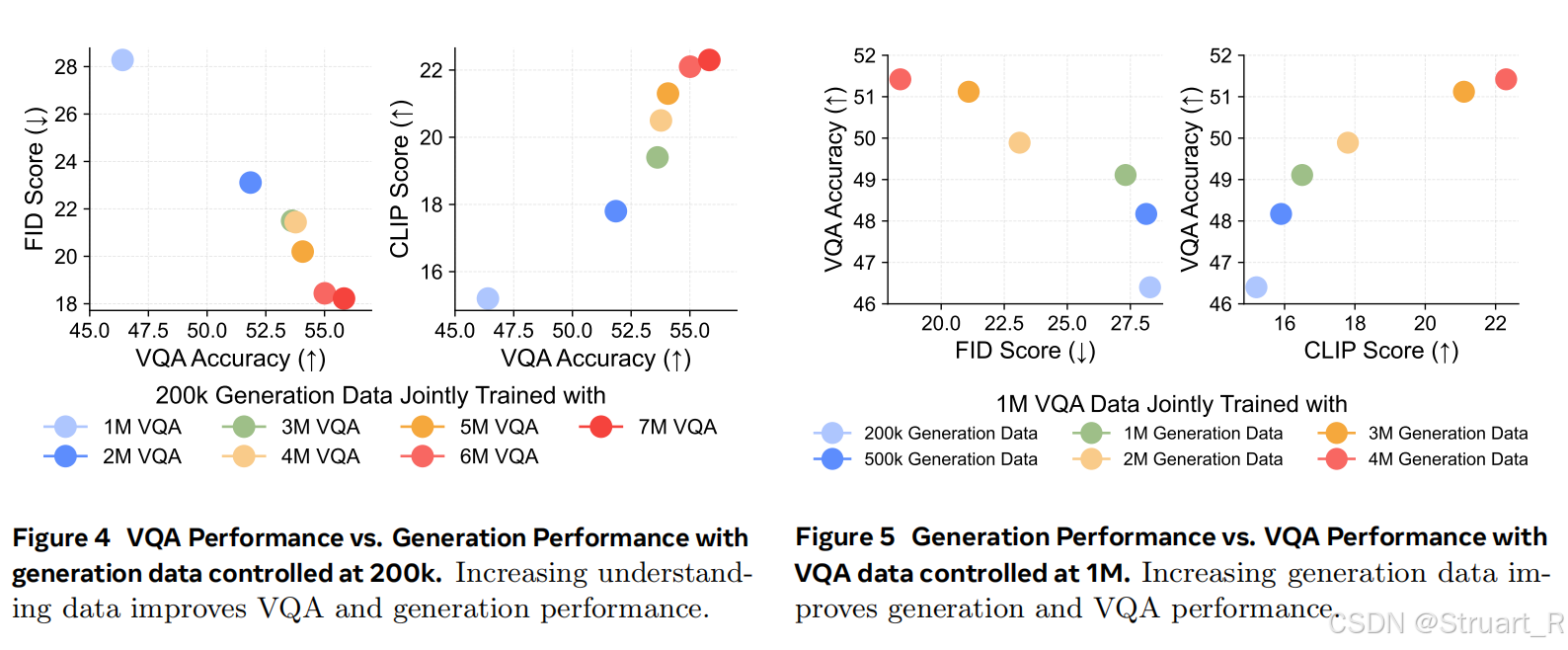
视觉生成可以通过与视觉理解联合训练高效解锁。
left:联合训练可以在更少数据量下实现高质量的生图效果(小于10000)
right:通过多种数据集的混合,不仅提高了生图质量,同时图文对齐能力也大幅增加。

视觉理解与生成相互促进但不对称。理解能力越高会提升生成能力,生成能力也会反馈给理解能力。
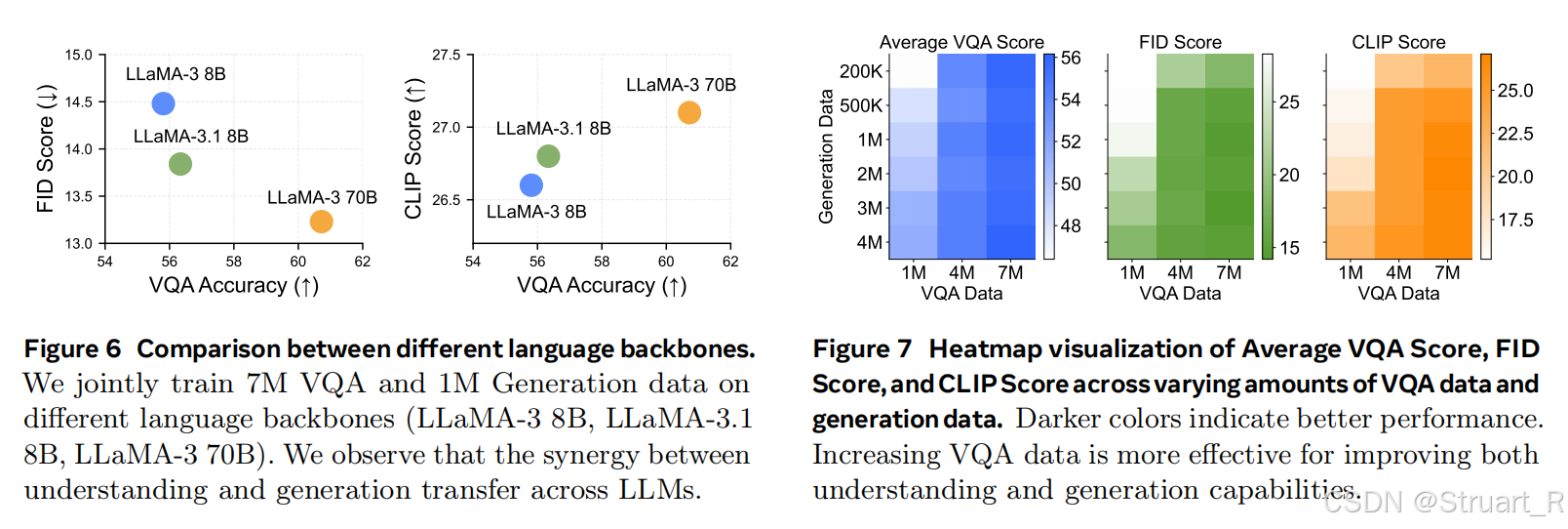
(右图)理解数据对理解和生成都有效。可以看到在理解数据的提升远比生成数据对VQA的提升大。(左图)比较的是不同backbones对文生图和图文对齐的影响。
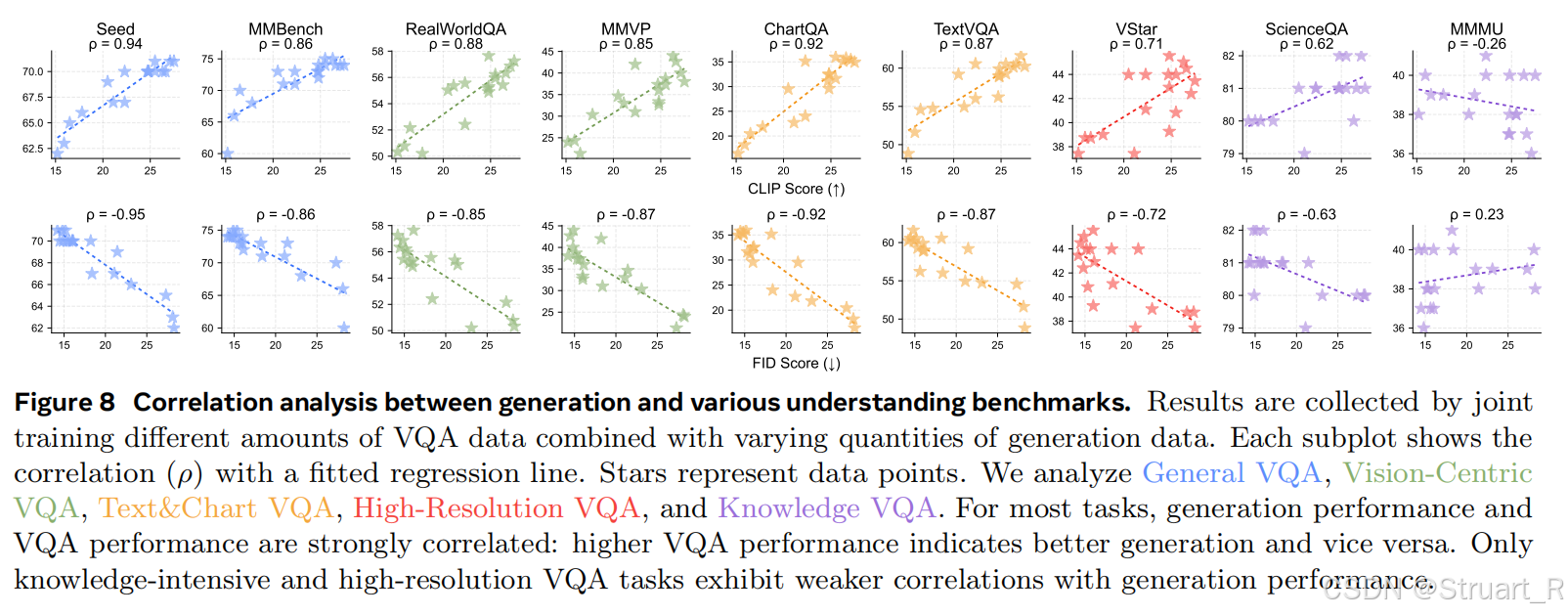
某些视觉要求高的VQA的理解任务甚至与生成任务更相关。
与以往理解or生成or统一模型的多任务对比。只能说与统一模型可以比一下,但是相较于单一任务的模型在质量上还有一些距离,但是可以在推理上由于单一模型(比如否定词,数量程度上的生成)
二、LlamaFusion
1、概述
LlamaFusion其实是对比Transfusion的一个工作。由于Transfusion需要从头开始训练多模态模型,消耗巨大算力,LlamaFusion旨在复用预训练的LLM计算成果,避免重复训练文本模块。
直接微调预训练LLM会导致语言能力退化,所以LlamaFusion在Transfusion统一架构中引入模态分离设计。
LlamaFusion是闭源项目,所以在大多数论文的对比实验中看不到他。
2、回顾Transfusion
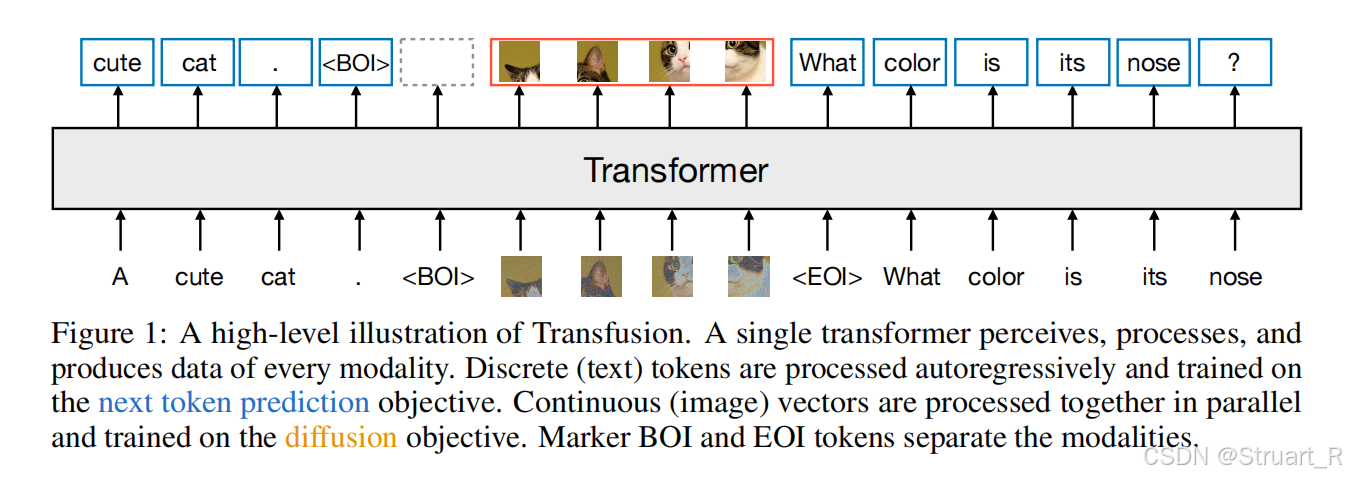
Transfusion与LlamaFusion均为Meta的Luke组的工作,当时采用了单个Transformer网络同时进行语言token和图像token的建模,架构不再是以往的Encoder+MLP+LLM的架构,而是SD+VAE的融合架构。
Transfusion是随机初始化的Transformer从头开始训练的。
训练目标为LM loss(文字token)+DDPM loss(视觉token)
参考Transfusion:Transfusion,Show-o and Show-o2论文解读-CSDN博客
3、LlamaFusion架构
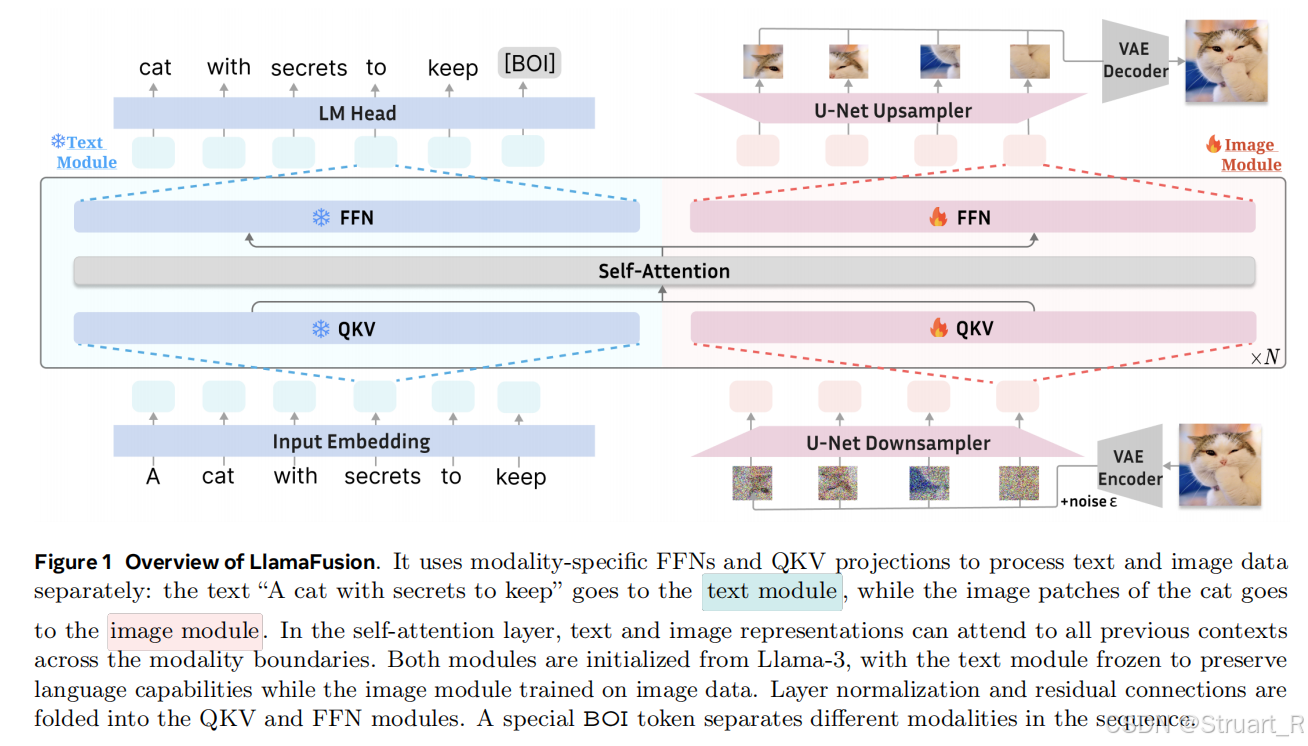
LlamFusion则是在Llama-3基础上利用Transfusion的训练目标继续训练,解决的是在学习图像生成能力的同时,如何防止遗忘文字生成能力,解决方式也是很粗暴,对两种模态的数据采用两套参数,只在self-attention处融合信息。
文本模块:复用Llama-3的FFN,QKV投影,归一化层,并完全冻结参数。输入:文本经过embedding得到文本tokens。输出LM Head复用Llama-3。
图像模块:新增并行FFN、QKV投影、归一化层,独立训练参数。输入:图像经过VAE encoder(未提及具体),并且分块加噪,经过U-Net downsampler得到带噪图像tokens。输出则相反。
自注意力层:支持跨模态交互,采用混合掩码对文本采用因果注意力,图像采用双向注意力,这一点与Tranfusion一致。
训练目标与Transfusion一致。
4、实验分析
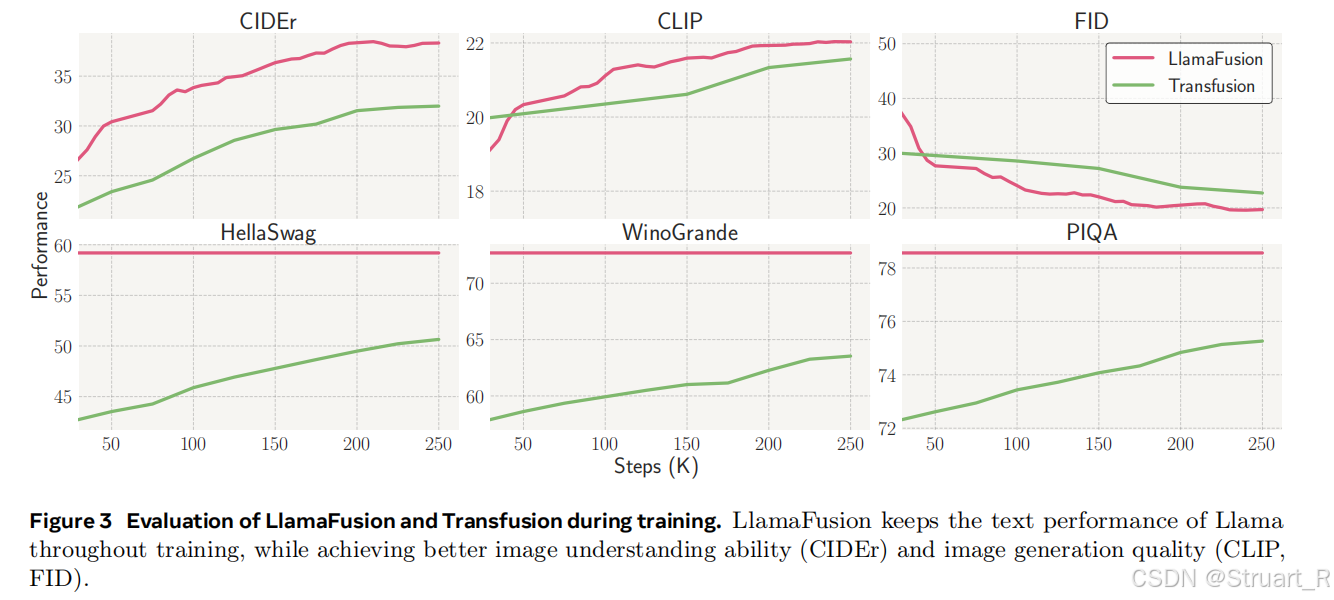
对比LlamaFusion和Transfusion,Llama的解耦操作防止语言能力退化(HellaSwag)
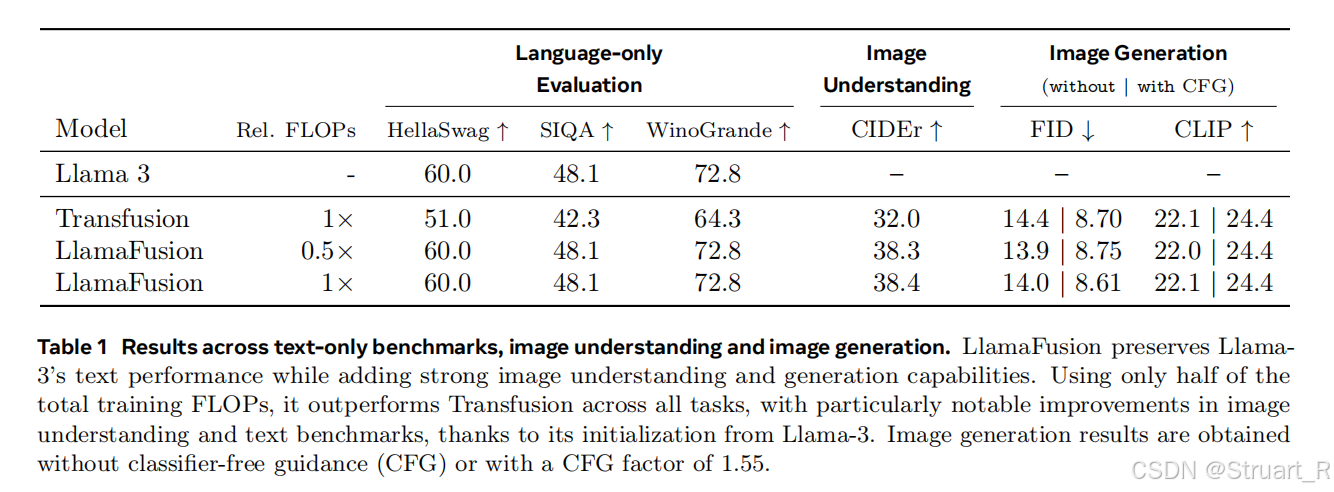
5、LlavaFusion
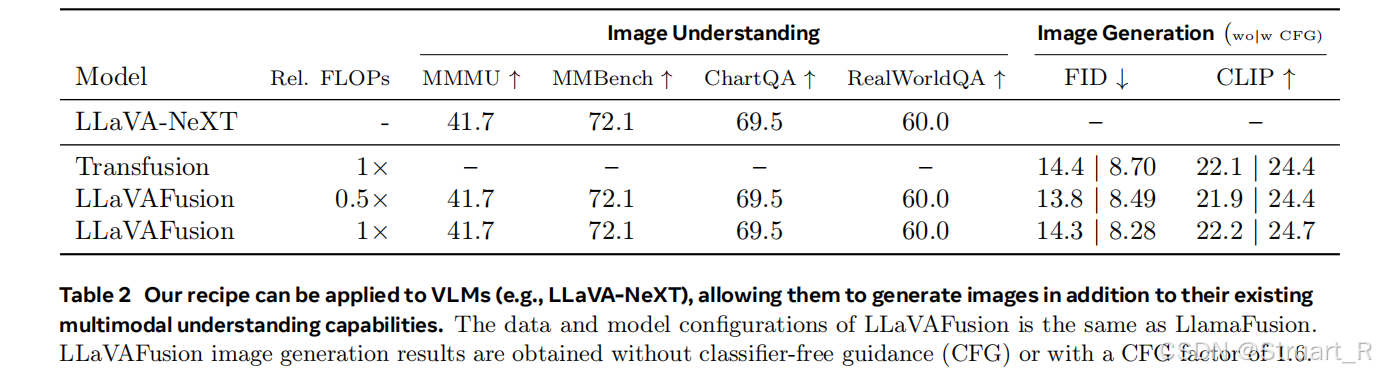
效仿LlamaFusion框架,将Llava-NeXT模型扩展到VLMs版本,相当于LlamaFusion是LLM到MLLM,LlavaFusion是VLM到MLLM。通过同样的解耦操作,来实现理解和生成的平衡。
三、MetaQuery
1、概述
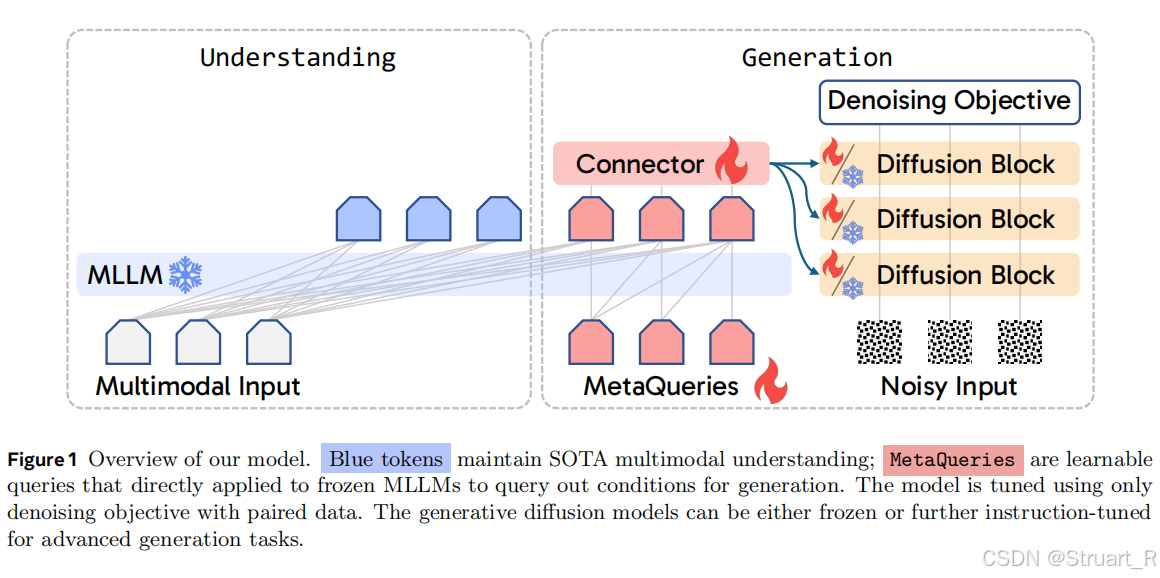
MetaQuery聚焦于不同输出模型之间能力的迁移,如何将自回归多模态LLM的输出高效的转移到Diffusion Model中。实现方法也是fine-tune的,直接使用预训练的MLLM,对预训练的扩散模型SANA进行微调,不需要大规模的训练。
2、架构
整体架构
整体来看就是将预训练的冻结的MLLM与Diffusion Model连接,并使用随机初始化的可学习的查询来作为图像生成部分MLLM的输入。其中MetaQuery对整个序列使用causal mask,也就是包括了MetaQueries部分,可以看到queries也是符合因果注意力的。之后将MetaQueries经过MLLM的序列
,经过一个可训练的Connector与Diffusion Model的输入空间对齐。
MLLM的backbone采用LLaVA-OneVision-0.5B,Diffusion Model采用Sana-0.6B 512 resolution。可学习queries使用64 tokens,Connector使用24层的Transformer encoder。
learning tokens
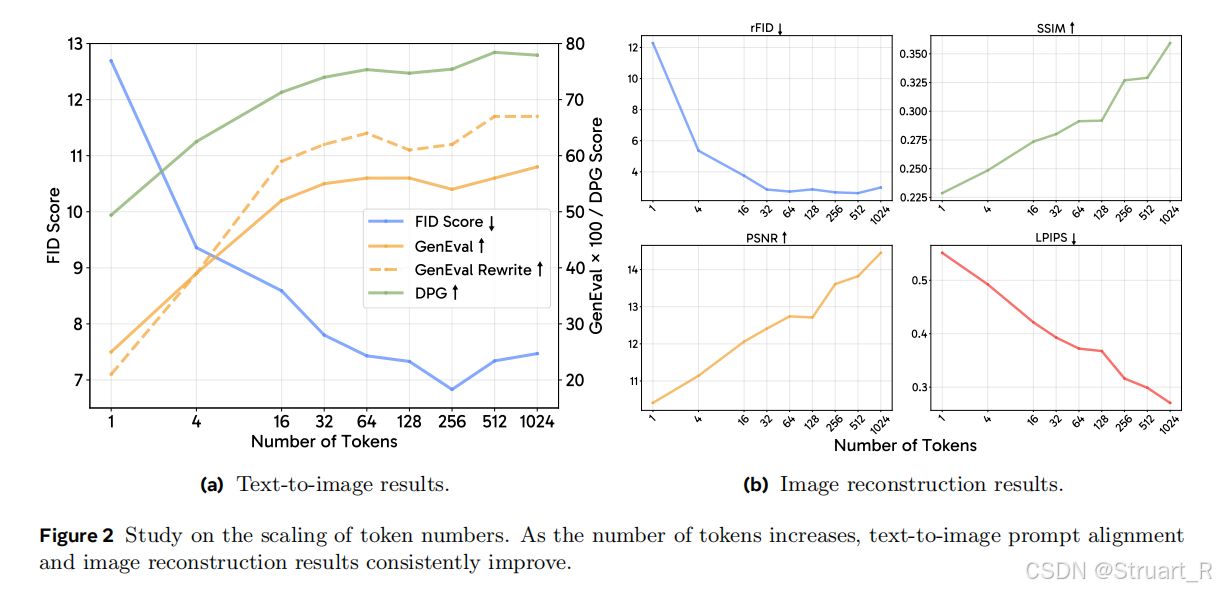
下图表示仅使用64个可学习查询下,比随机查询效果更好,并且tokens数越多性能越好,这符合我们的常规理解。
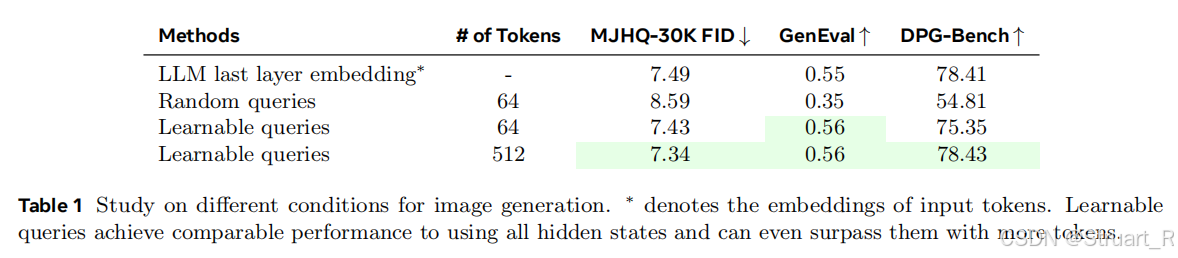
并且对比了选择不同tokens递增下的语义理解和文生图质量对比,虽然说整体上tokens数越多可以实现更好的语义对齐,对于长字幕的性能效果更为明显越好,文生图结果在tokens=64后趋近于平稳。

Connector设计
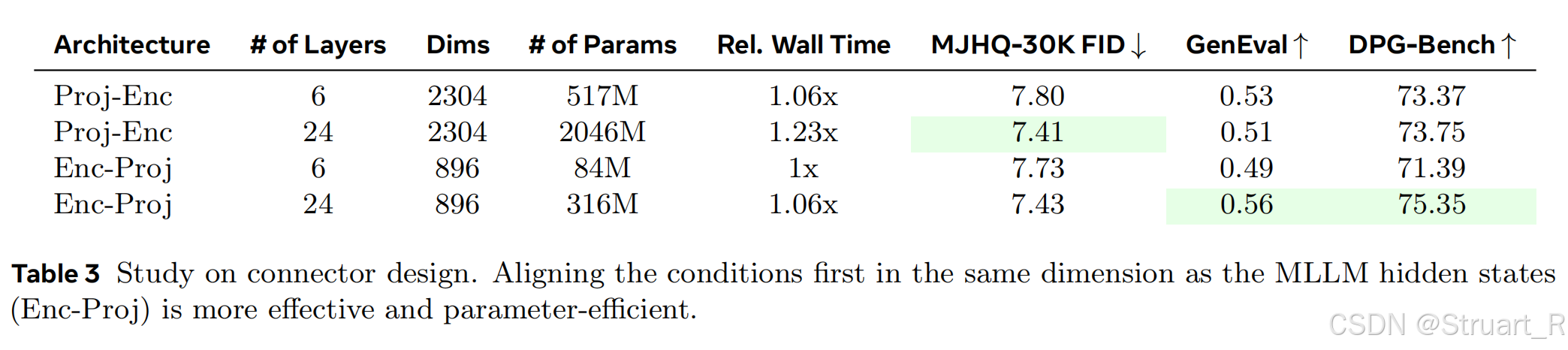
论文中使用了与Qwen2.5 LLM相同架构,共24层Transformer相叠,并且对Connector进行bi-directional attention,取消因果掩码,允许所以tokens之间相互关注。另外架构上设计了Enc-Proj(先Transformer 编码器对齐后投影到扩散空间)和Proj-Enc两种架构,对比实验中看到EncProj效果更优。
训练方法
MetaQuery的训练分为两个阶段,两个阶段中均冻结MLLM并微调MetaQueries、Connector、diffusion model的部分。其中对于不同的尺寸设计了三种MLLM Backbone包括LLAVAOneVision 0.5B(Base)、Qwen2.5-VL 3B(Large)、Qwen2.5-VL 7B(X-Large)。tokens设置256,Connector设置24层Enc-Proj架构。对于Vision Head采用了Stable Diffusion v1.5和SANA=1.6B两个模型。
预训练:在25M的image-caption对上进行预训练4000steps
指令微调:构建语料库来微调数据,语料库包括多模态上下文,交错的文本和相关主题或主题的图像。通过从mmc4 core fewer-faces subset中收集分组图像并带有caption,之后对每一组进行过滤,利用SigLIP指定相似度最小的作为目标图像,其他均为源图像(训练集),并构建2.4M图像对,并借助Qwen2.5-VL 3B生成指令信息。训练中在语料库下微调了3个epoch,batchsize =2048。

后面实验证明了指令微调是行之有效的。

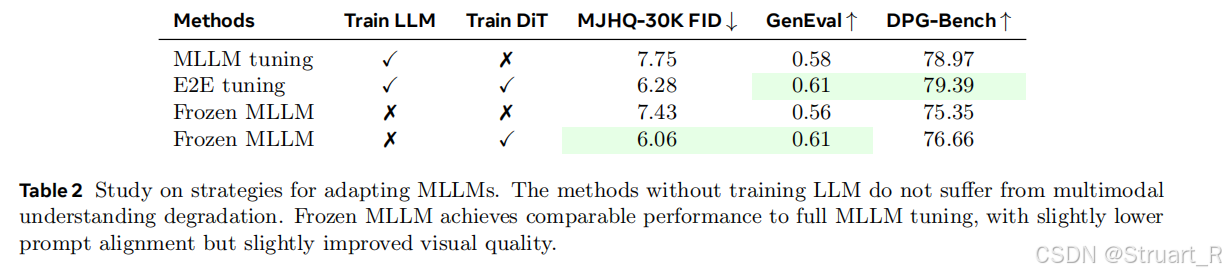
同样也对比了全微调、部分微调和不微调下的性能指标,可以看到冻结MLLM下进行部分微调在图像生成下甚至优于全微调,虽然语义对齐上少了一点,但是整体上训练的效率和参数都减少了很大一部分。
3、实验分析
值得注意的,在推理相关的文生图中,效果比以往的文生图效果和多模态大模型效果好,但不如闭源模型GPT-4o。
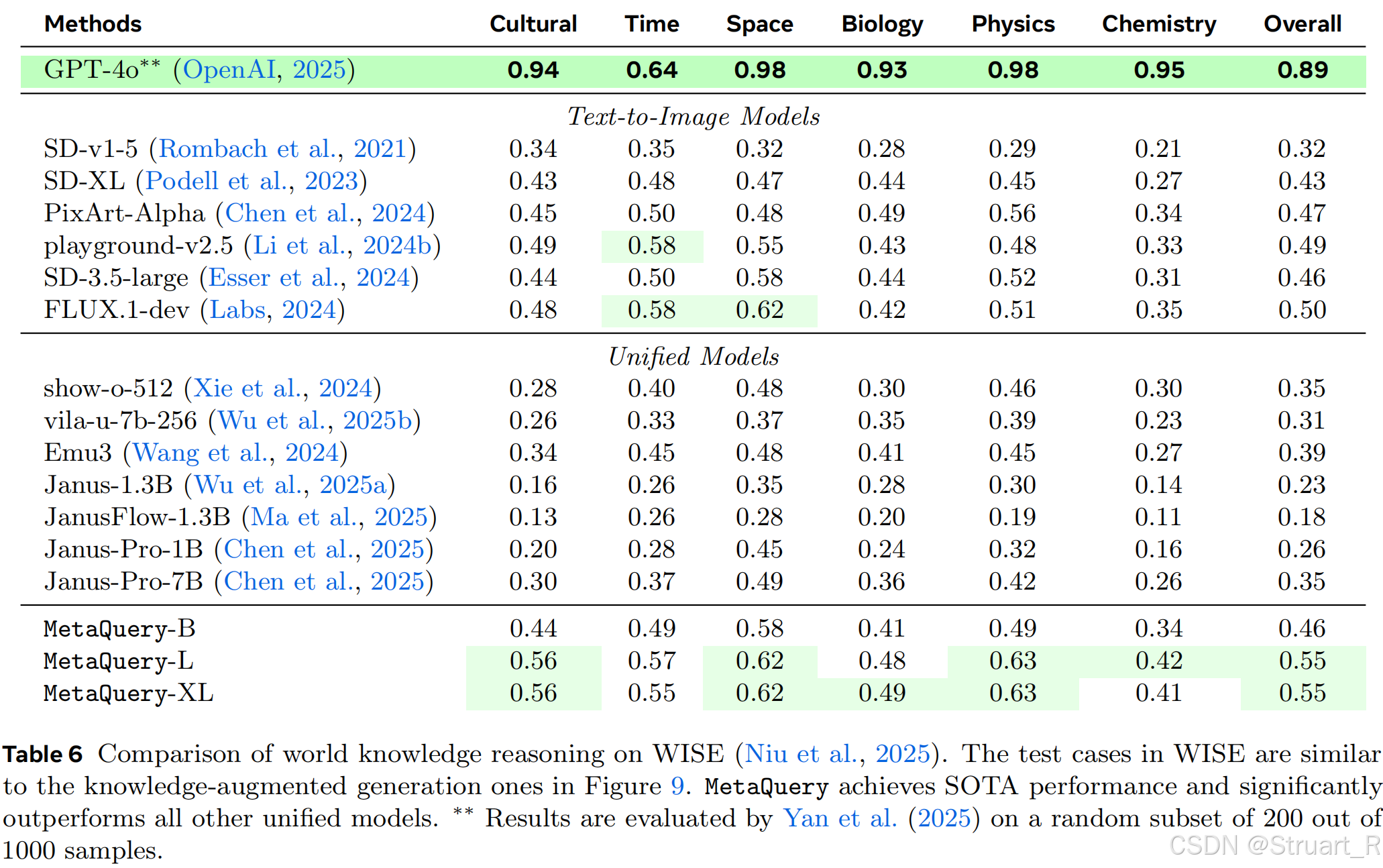
T2I的常识推理能力。显著提升了基础SANA模型的性能,通过大模型的语义学习获得了更多的推理能力。

并且仅通过微调具有图像编辑能力,没有量化。

同样具有图像重建能力(就是通过当前图像预测未来帧的视频),需要考虑风格一致,位置一致,物体一致,同时时间上有所变化或者视角变化。

参考论文:
[2412.14164] MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
LlamaFusion: Adapting Pretrained Language Models for Multimodal Generation
Transfer between Modalities with MetaQueries