网站目录爬行wordpress怎么做信息分类
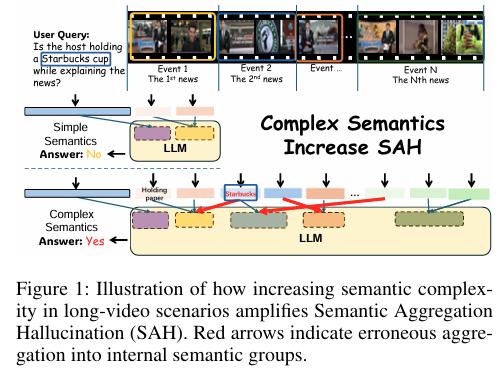
摘要:视频多模态大语言模型(Video-MLLMs)在视频理解领域取得了显著进展。然而,这些模型仍易产生与视频输入不一致或不相关的幻觉内容。既往的视频幻觉基准测试主要聚焦于短视频,并将幻觉归因于语言先验过强、帧缺失或视觉编码器引入的视语言偏差等因素。尽管这些原因确实能解释短视频中的大部分幻觉现象,但仍过于简化了幻觉的成因。有时,模型生成的输出结果有误,但帧级语义却正确无误。我们将此类幻觉称为语义聚合幻觉(Semantic Aggregation Hallucination,SAH),它产生于将帧级语义聚合为事件级语义组的过程中。鉴于SAH在长视频中因多事件语义复杂性的增加而尤为突出,因此有必要将此类幻觉与其他类型区分开来,并进行深入研究。为解决上述问题,我们推出了首个专注于长视频幻觉的基准测试——ELV-Halluc,以实现对SAH的系统性探究。实验证实了SAH的存在,并表明其随语义复杂性的增加而增多。此外,我们还发现,模型在语义快速变化的场景下更易产生SAH。此外,我们探讨了缓解SAH的潜在方法。研究表明,位置编码策略有助于减轻SAH,且我们进一步采用直接偏好优化(DPO)策略,提升了模型区分事件内部及跨事件语义的能力。为此,我们精心构建了一个包含8000对对抗性数据的测试集,并在ELV-Halluc和Video-MME上均取得了改进,其中包括SAH比例显著降低27.7%。Huggingface链接:Paper page,论文链接:2508.21496
研究背景和目的
研究背景:
随着视频理解技术的快速发展,视频多模态大型语言模型(Video-MLLMs)在视频内容解析、事件识别和语义理解等方面取得了显著进展。然而,这些模型在处理长视频时仍然面临一个关键挑战——幻觉(Hallucination)问题。幻觉指的是模型生成的内容与视频输入不一致或无关,严重影响了模型的可靠性和实用性。现有的视频幻觉基准测试主要关注短视频(几秒到几十秒),并将幻觉归因于视觉语言错位、帧质量差或采样策略不佳等因素。然而,这些基准测试未能充分探索长视频中的幻觉问题,尤其是语义聚合幻觉(Semantic Aggregation Hallucination, SAH)。
SAH是一种在长视频中尤为突出的幻觉类型,它发生在将帧级语义聚合为事件级语义组的过程中。在长视频中,由于多个事件的时间扩展和语义连贯性,模型容易在跨事件语义归属上出错,导致错误地关联视觉线索和概念。例如,模型可能正确感知每帧的视觉语义,但在将语义分配到不同事件时出错,从而产生与视频内容不一致的描述。
研究目的:
本研究旨在解决长视频理解中的语义聚合幻觉问题,通过引入首个专门针对长视频幻觉的基准测试ELV-Halluc,系统研究SAH现象。具体目标包括:
- 定义和量化SAH:明确SAH的定义,通过量化长视频中的语义复杂性,揭示SAH在长视频理解中的关键作用。
- 构建基准测试:开发ELV-Halluc基准测试,提供一套系统评估SAH的数据集和评估指标。
- 分析SAH模式:通过实验分析SAH的发生模式,探讨其与视频语义复杂性和变化率的关系。
- 提出缓解策略:探索缓解SAH的有效方法,提高长视频理解模型的可靠性和准确性。
研究方法
1. 基准测试构建:
ELV-Halluc基准测试由500个从YouTube收集的长视频组成,每个视频包含2到10个清晰区分的事件。视频主题涵盖体育、新闻广播、教育、电影片段等多个领域。每个视频经过人工验证,确保事件分割的准确性和语义清晰度。通过半自动化标注流程,生成高质量的地面真实字幕(Ground Truth Captions)和幻觉字幕对(Hallucinated Caption Pairs)。
2. 幻觉字幕生成:
使用GPT-4o生成两种类型的幻觉字幕:
- In-video Hallucination:将地面真实字幕中的对象替换为同一视频中其他事件的对象。
- Out-video Hallucination:将地面真实字幕中的对象替换为视频中未出现的虚构对象。
每种修改策略生成8,630对幻觉字幕,用于评估模型对SAH的敏感性。
3. 评估指标:
引入SAH比率(SAH Ratio)作为主要评估指标,定义为模型在Out-video问答对上的准确率与In-video问答对上的准确率之差除以(1 - In-video准确率)。该指标反映了模型在处理跨事件语义归属时的错误倾向。
4. 实验设置:
评估了14个开源模型(参数范围从1B到78B)和两个闭源模型(GPT-4o和Gemini2.5Flash)在ELV-Halluc上的表现。通过对比不同模型在In-video和Out-video问答对上的准确率,分析SAH的发生模式和影响因素。
5. 缓解策略探索:
- 位置编码策略:评估不同位置编码策略(如VideoRoPE)对缓解SAH的效果。
- 直接偏好优化(DPO):采用DPO策略,通过构造正负响应对,优化模型对正确事件语义的偏好。
研究结果
1. SAH的存在和模式:
实验结果表明,SAH在长视频理解中普遍存在,且随着语义复杂性的增加而加剧。模型在处理快速变化的语义时更容易出现SAH。例如,在视觉细节、动作和对象等低级语义方面,SAH比率显著高于声明性内容等高级语义。
2. 模型性能对比:
不同模型在ELV-Halluc上的表现差异显著。较大的模型通常具有更高的整体准确率,但对SAH的敏感性并未显著降低。例如,Qwen2.5-VL-32B模型在所有模型中SAH比率最低,但仍达到0.2%。
3. 缓解策略效果:
- 位置编码:强化位置编码策略(如VideoRoPE)显著降低了SAH比率,表明更强的位置绑定能力有助于减少语义聚合错误。
- DPO优化:采用DPO策略后,模型在In-video问答对上的准确率显著提高,SAH比率降低了27.7%。同时,模型在VideoMME基准测试上的整体性能也有所提升(+0.9%)。
研究局限
1. 数据集规模和多样性:
尽管ELV-Halluc基准测试包含了500个长视频,但相对于真实世界中的长视频多样性而言,数据集规模仍然有限。此外,半自动化标注流程可能引入Gemini生成字幕的偏差,影响评估结果的普遍性。
2. 基准测试的真实性:
ELV-Halluc中的视频通过事件分割简化了语义复杂性,但与真实世界中的长视频相比,仍存在一定差距。真实长视频中的事件过渡可能更加模糊和复杂,增加了语义聚合的难度。
3. 缓解策略的局限性:
尽管位置编码和DPO策略在一定程度上缓解了SAH问题,但并未完全消除幻觉现象。未来的研究需要探索更有效的缓解方法,进一步提高长视频理解模型的可靠性。
未来研究方向
1. 扩大数据集规模和多样性:
未来的研究可以进一步扩大ELV-Halluc数据集的规模,增加更多主题和场景的长视频,提高评估结果的普遍性和鲁棒性。同时,可以探索完全自动化的标注流程,减少人工标注成本。
2. 改进基准测试设计:
可以设计更复杂的基准测试,模拟真实世界中的长视频场景,增加事件过渡的模糊性和复杂性。此外,可以引入多模态评估指标,综合考虑视觉、语言和音频等多方面的信息,提高评估的全面性。
3. 探索更有效的缓解策略:
除了位置编码和DPO策略外,可以探索其他缓解SAH的方法,如引入外部知识库、加强跨模态交互学习等。同时,可以研究如何结合多种缓解策略,形成更全面的幻觉抑制方案。
4. 加强模型可解释性研究:
未来的研究可以加强模型可解释性方面的探索,揭示模型在处理长视频时的内部机制和决策过程。通过可解释性研究,可以更好地理解SAH的发生原因,为设计更有效的缓解策略提供依据。
5. 跨领域应用探索:
可以将ELV-Halluc基准测试和缓解策略应用于其他视频理解任务中,如视频摘要、视频问答等,验证其普遍性和有效性。通过跨领域应用探索,可以进一步推动长视频理解技术的发展和应用。