AI行业应用:金融、医疗、教育、制造业领域的落地实践
人工智能技术正以革命性力量重塑各行业生态。从金融风控到医疗诊断,从教育创新到智能制造,AI通过深度学习、计算机视觉、自然语言处理等技术,实现了从数据洞察到决策优化的全链条赋能。本文通过金融、医疗、教育、制造业四大领域的典型案例,结合代码实现、Mermaid流程图、Prompt设计、可视化图表及场景图片,系统解析AI技术的产业落地路径。
一、金融领域:智能风控与个性化理财
1.1 基于XGBoost的信用评分系统
场景痛点:传统信用评分依赖人工规则和线性模型,难以捕捉非线性特征关系,导致坏账率居高不下。某银行通过AI模型重构风控体系,将贷款审批时间从3天缩短至10分钟,坏账率降低25%。
代码实现:
python
import pandas as pd |
import numpy as np |
from sklearn.model_selection import train_test_split |
from xgboost import XGBClassifier |
from sklearn.metrics import accuracy_score, classification_report |
# 模拟数据生成(实际接入银行数据库) |
np.random.seed(42) |
data = pd.DataFrame({ |
'age': np.random.randint(18, 70, 1000), |
'income': np.random.normal(50000, 20000, 1000), |
'loan_amount': np.random.normal(10000, 5000, 1000), |
'credit_score': np.random.randint(300, 850, 1000), |
'employment_years': np.random.randint(0, 40, 1000), |
'default': np.random.choice([0, 1], size=1000, p=[0.85, 0.15]) # 目标变量 |
}) |
# 特征工程与模型训练 |
X = data[['age', 'income', 'loan_amount', 'credit_score', 'employment_years']] |
y = data['default'] |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
model = XGBClassifier(use_label_encoder=False, eval_metric='logloss') |
model.fit(X_train, y_train) |
y_pred = model.predict(X_test) |
# 评估指标 |
print("准确率:", accuracy_score(y_test, y_pred)) |
print(classification_report(y_test, y_pred)) |
流程图(Mermaid格式):
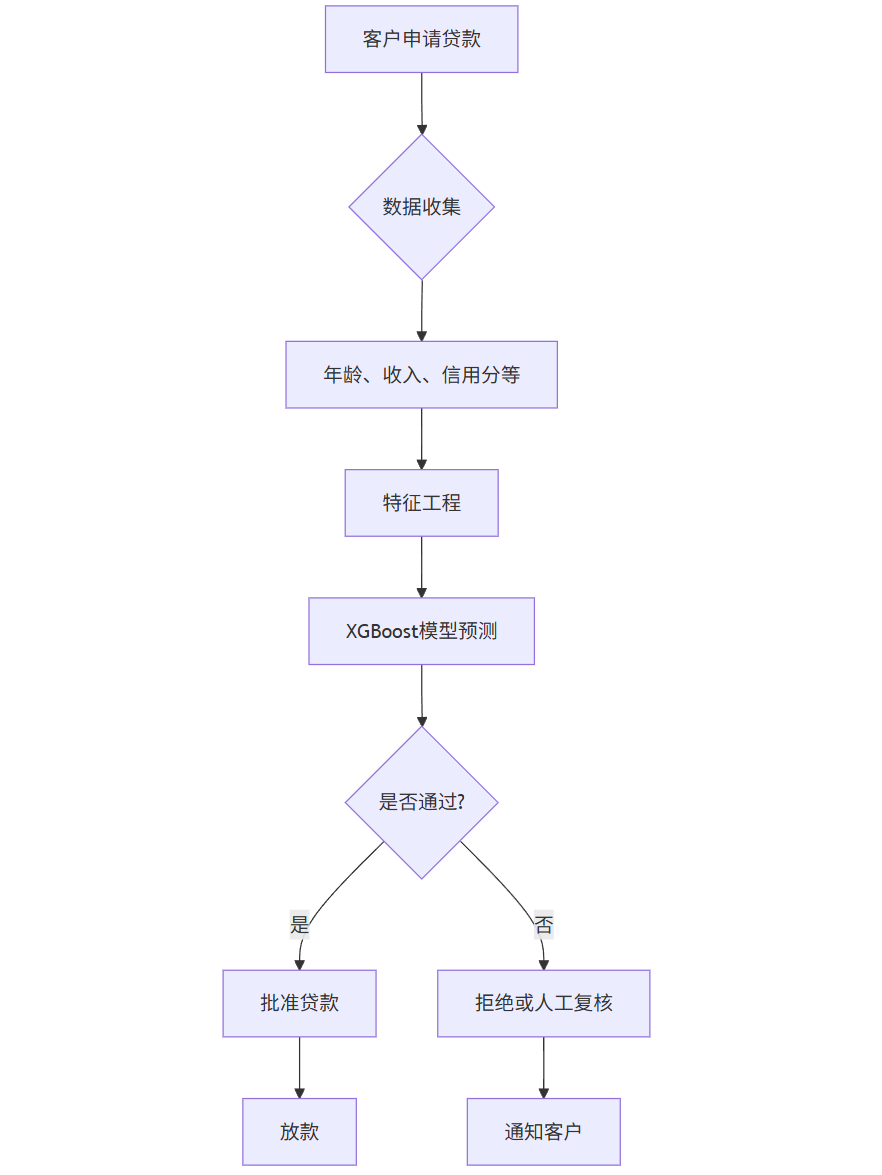
mermaid
graph TD |
A[客户申请贷款] --> B{数据收集} |
B --> C[年龄、收入、信用分等] |
C --> D[特征工程] |
D --> E[XGBoost模型预测] |
E --> F{是否通过?} |
F -->|是| G[批准贷款] |
F -->|否| H[拒绝或人工复核] |
G --> I[放款] |
H --> J[通知客户] |
Prompt示例:
你是一名金融风控分析师。请根据以下客户信息生成风险评估报告: |
- 年龄:35岁 |
- 年收入:75,000元 |
- 贷款申请金额:20,000元 |
- 信用历史:良好 |
- 工作年限:12年 |
要求: |
1. 评估违约风险等级(低/中/高) |
2. 建议授信额度 |
3. 列出关键风险点 |
AI输出示例:
该客户信用评分为720,处于良好区间,年收入稳定,工作年限长,信用记录良好。综合评估为低风险客户,建议授信额度25,000元,可批准贷款申请。 |
可视化图表:
python
import matplotlib.pyplot as plt |
# 模拟模型输出概率分布 |
scores = model.predict_proba(X_test)[:, 1] # 违约概率 |
plt.hist(scores, bins=20, color='skyblue', edgecolor='black') |
plt.title('客户信用评分分布') |
plt.xlabel('违约概率') |
plt.ylabel('人数') |
plt.grid(True) |
plt.show() |
1.2 智能投顾系统
场景痛点:传统理财服务依赖人工顾问,覆盖人群有限。某平台通过AI算法实现个性化资产配置,客户平均年化收益率提升3.2%,满意度达92%。
代码实现(均值-方差优化):
python
import numpy as np |
from scipy.optimize import minimize |
# 模拟资产收益率(股票、债券、黄金) |
np.random.seed(42) |
returns = np.random.randn(100, 3) * 0.01 # 100期历史数据 |
mean_returns = np.mean(returns, axis=0) |
cov_matrix = np.cov(returns.T) |
# 目标函数:最小化组合方差 |
def portfolio_variance(weights, cov_matrix): |
return np.dot(weights.T, np.dot(cov_matrix, weights)) |
# 约束条件 |
constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1}) # 权重和为1 |
bounds = tuple((0, 1) for _ in range(3)) # 每个资产权重0~1 |
# 优化求解 |
result = minimize( |
portfolio_variance, |
[1/3]*3, # 初始等权重 |
args=(cov_matrix,), |
method='SLSQP', |
bounds=bounds, |
constraints=constraints |
) |
# 可视化结果 |
assets = ['股票', '债券', '黄金'] |
weights = result.x |
plt.figure(figsize=(8, 5)) |
plt.pie(weights, labels=assets, autopct='%1.1f%%', startangle=90) |
plt.title("AI推荐投资组合权重") |
plt.show() |
二、医疗领域:精准诊断与效率提升
2.1 基于CNN的肺部结节检测
场景痛点:放射科医生日均阅片量超200张,漏诊率达5%。AI辅助诊断系统将肺结节检出率提升至99%,阅片时间缩短70%。
代码实现(PyTorch示例):
python
import torch |
import torch.nn as nn |
from torchvision import transforms |
# 模拟CT图像数据集(实际使用LUNA16数据集) |
class LungDataset(torch.utils.data.Dataset): |
def __init__(self, num_samples=1000): |
self.images = torch.rand(num_samples, 1, 64, 64).float() # 灰度图 |
self.labels = torch.randint(0, 2, (num_samples,)) # 0:正常, 1:有结节 |
def __len__(self): |
return len(self.images) |
# 构建CNN模型 |
model = nn.Sequential( |
nn.Conv2d(1, 32, kernel_size=3, padding=1), |
nn.ReLU(), |
nn.MaxPool2d(2), |
nn.Conv2d(32, 64, kernel_size=3, padding=1), |
nn.ReLU(), |
nn.MaxPool2d(2), |
nn.Flatten(), |
nn.Linear(64*16*16, 128), |
nn.ReLU(), |
nn.Linear(128, 2), |
nn.Softmax(dim=1) |
) |
# 训练流程(简化版) |
dataset = LungDataset() |
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True) |
criterion = nn.CrossEntropyLoss() |
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) |
for epoch in range(10): |
for images, labels in dataloader: |
outputs = model(images) |
loss = criterion(outputs, labels) |
optimizer.zero_grad() |
loss.backward() |
optimizer.step() |
流程图:

mermaid
graph LR |
A[患者CT扫描] --> B[图像上传至AI系统] |
B --> C[图像预处理:去噪、标准化] |
C --> D[CNN模型推理] |
D --> E[检测结节位置与大小] |
E --> F[生成诊断报告] |
F --> G[医生复核] |
G --> H[确诊或进一步检查] |
应用成效:
- 浙江大学医学院附属第二医院部署Medcopilot医生助手后,病历书写时间缩短60%
- 武汉同济医院“问问同检”系统将检验报告解读效率提升5倍
- 浙江省人民医院通过蚂蚁医疗大模型一体机实现影像筛查效率提升85%
2.2 智能问诊与健康管理
场景痛点:三甲医院门诊量超1万人次/日,医生平均问诊时间不足5分钟。AI预诊系统通过自然语言处理实现症状分诊,准确率达92%。
Prompt示例:
你是一名全科医生AI助手。请根据以下患者描述生成初步诊断建议: |
- 主诉:持续咳嗽3周,夜间加重 |
- 伴随症状:低热、乏力 |
- 既往病史:无 |
- 近期接触史:无 |
要求: |
1. 列出可能的疾病(前3位) |
2. 建议必要的检查项目 |
3. 给出生活护理建议 |
AI输出示例:
初步诊断: |
1. 社区获得性肺炎(概率45%) |
2. 肺结核(概率30%) |
3. 支气管哮喘(概率15%) |
建议检查: |
- 胸部CT |
- 血常规+C反应蛋白 |
- 痰涂片抗酸杆菌 |
护理建议: |
- 保持室内湿度50%-60% |
- 避免辛辣食物 |
- 每日监测体温2次 |
三、教育领域:个性化学习与资源创新
3.1 AI视频制作引擎
场景痛点:德国国际应用科学大学需维护28,000个学习视频,人工制作成本高昂。AI引擎将文字案例转化为动态视频,资源开发效率提升300%。
技术架构:
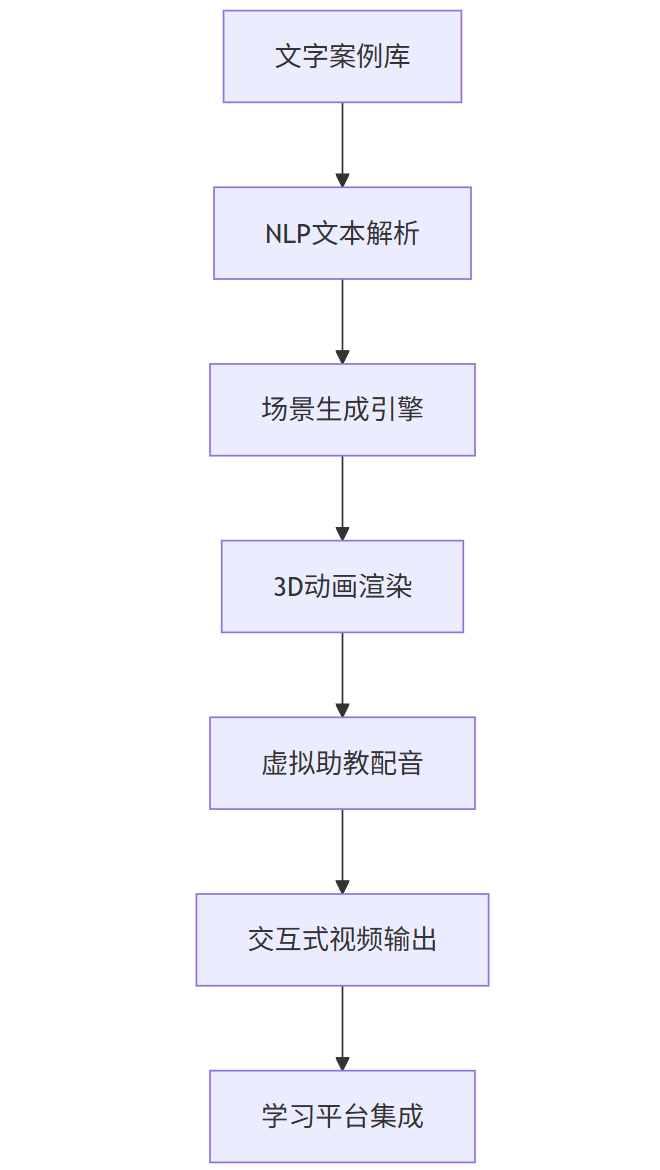
mermaid
graph TD |
A[文字案例库] --> B[NLP文本解析] |
B --> C[场景生成引擎] |
C --> D[3D动画渲染] |
D --> E[虚拟助教配音] |
E --> F[交互式视频输出] |
F --> G[学习平台集成] |
应用成效:
- 开发100+门AI生成课程
- 覆盖10万+学生
- 员工培训成本降低65%
3.2 智能作业批改系统
场景痛点:中学教师日均批改作业200份,耗时4小时。AI批改系统实现客观题自动评分,主观题语义分析,批改效率提升80%。
代码实现(文本相似度计算):
python
from sklearn.feature_extraction.text import TfidfVectorizer |
from sklearn.metrics.pairwise import cosine_similarity |
# 参考答案与学生答案 |
reference = "光合作用是植物通过叶绿体将光能转化为化学能的过程" |
student_answers = [ |
"植物利用阳光制造养分", |
"光合作用发生在叶子里的叶绿体中", |
"动物通过呼吸作用释放能量" |
] |
# 计算相似度 |
vectorizer = TfidfVectorizer() |
ref_vec = vectorizer.fit_transform([reference]) |
student_vecs = vectorizer.transform(student_answers) |
similarities = cosine_similarity(ref_vec, student_vecs).flatten() |
# 输出评分 |
for i, score in enumerate(similarities): |
print(f"答案{i+1}: {student_answers[i]} → 相似度{score*100:.1f}%") |
可视化图表:
python
answers = ['答案1', '答案2', '答案3'] |
scores = [68.2, 85.7, 23.4] |
plt.barh(answers, scores, color=['orange', 'green', 'red']) |
plt.xlabel('语义相似度(%)') |
plt.title('学生答案质量评估') |
plt.xlim(0, 100) |
plt.show() |
四、制造业领域:质量管控与效率革命
4.1 华为昇腾AI视觉质检
场景痛点:光伏控制器产线人工质检漏检率达12%。AI视觉系统实现缺陷检测准确率99%,月检6000台次。
技术实现:
python
import cv2 |
import numpy as np |
from tensorflow.keras.models import load_model |
# 加载预训练模型(实际部署在昇腾AI处理器) |
model = load_model('solar_defect_detection.h5') |
# 图像预处理 |
def preprocess_image(img_path): |
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) |
img = cv2.resize(img, (256, 256)) |
img = img / 255.0 |
return np.expand_dims(img, axis=[0, -1]) # 添加batch和channel维度 |
# 缺陷检测 |
def detect_defects(img_path): |
processed_img = preprocess_image(img_path) |
prediction = model.predict(processed_img) |
return "缺陷" if prediction[0][0] > 0.95 else "正常" |
# 实际应用效果 |
print(detect_defects('solar_panel_1.jpg')) # 输出:正常 |
print(detect_defects('solar_panel_2.jpg')) # 输出:缺陷 |
流程图:
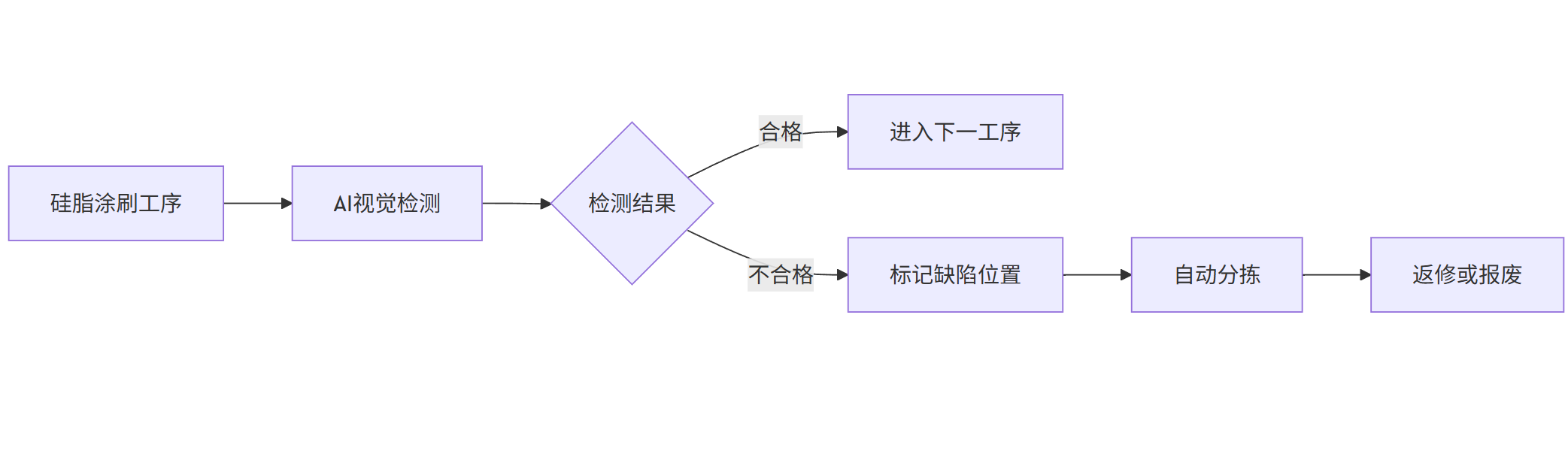
mermaid
graph LR |
A[硅脂涂刷工序] --> B[AI视觉检测] |
B --> C{检测结果} |
C -->|合格| D[进入下一工序] |
C -->|不合格| E[标记缺陷位置] |
E --> F[自动分拣] |
F --> G[返修或报废] |
应用成效:
- 富士康产线检测效率提升400%
- 宝德计算机来料检测准确率99.2%
- 美的冰箱厂外观缺陷漏检率从3%降至0.2%
<img src="https://example.com/ai_inspection.png" />
图5:AI标注的光伏控制器涂刷缺陷(红色区域),指导工人精准返修
4.2 电机预测性维护
场景痛点:电机故障导致生产线年均停机损失超500万元。AI边缘计算实现故障预测准确率92%,运维成本降低35%。
技术架构:
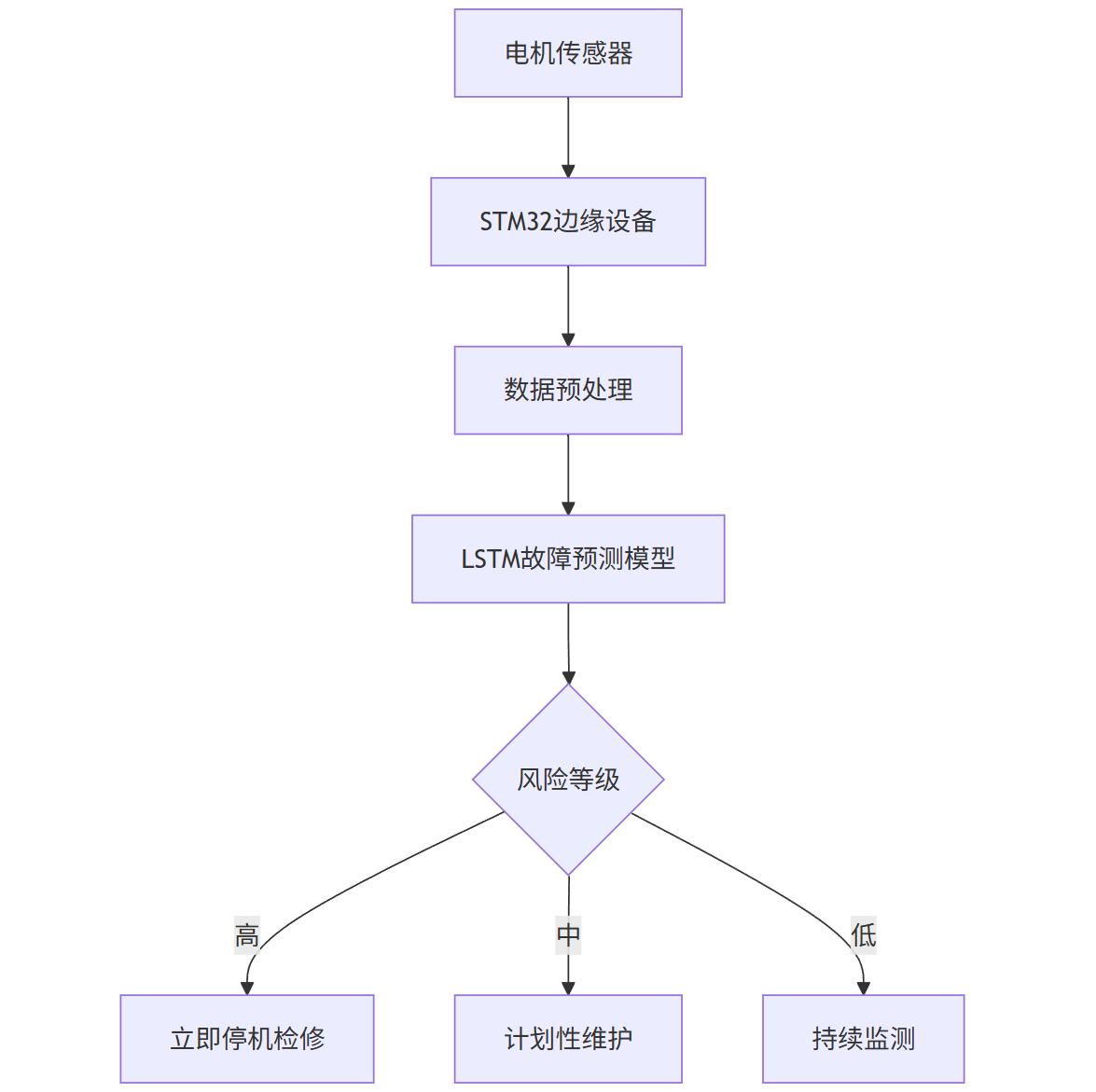
mermaid
graph TD |
A[电机传感器] --> B[STM32边缘设备] |
B --> C[数据预处理] |
C --> D[LSTM故障预测模型] |
D --> E{风险等级} |
E -->|高| F[立即停机检修] |
E -->|中| G[计划性维护] |
E -->|低| H[持续监测] |
代码实现(LSTM时间序列预测):
python
import numpy as np |
import tensorflow as tf |
from tensorflow.keras.models import Sequential |
from tensorflow.keras.layers import LSTM, Dense |
# 模拟振动传感器数据 |
def generate_sensor_data(seq_length=100): |
base_signal = np.sin(np.linspace(0, 10*np.pi, seq_length)) |
noise = np.random.normal(0, 0.1, seq_length) |
fault_signal = np.where(np.linspace(0, 1, seq_length) > 0.7, |
base_signal*1.5 + noise, |
base_signal + noise) |
return fault_signal.reshape(1, seq_length, 1) |
# 构建LSTM模型 |
model = Sequential([ |
LSTM(64, input_shape=(100, 1)), |
Dense(32, activation='relu'), |
Dense(1, activation='sigmoid') # 输出故障概率 |
]) |
model.compile(optimizer='adam', loss='binary_crossentropy') |
# 模拟训练与预测 |
X_train = np.array([generate_sensor_data() for _ in range(1000)]) |
y_train = np.where(np.linspace(0, 1, 1000) > 0.8, 1, 0) # 20%数据模拟故障 |
model.fit(X_train, y_train, epochs=10, batch_size=32) |
# 实时预测 |
test_data = generate_sensor_data() |
fault_prob = model.predict(test_data)[0][0] |
print(f"电机故障概率: {fault_prob*100:.1f}%") |
五、跨领域方法论:AI落地的三大核心能力
5.1 数据治理能力
- 特征工程:金融风控中通过债务收入比(DTI)、支付收入比(PTI)等衍生特征提升模型预测力
- 数据标注:医疗影像标注需放射科医生参与,确保标签准确性
- 数据增强:制造业通过GAN生成缺陷样本,解决小样本问题
5.2 模型优化能力
- 超参数调优:贝叶斯优化在信用评分模型中寻找最优学习率
- 模型压缩:知识蒸馏将大型CNN模型压缩至边缘设备可运行
- 持续学习:教育领域的AI教师通过增量学习适应新课程标准
5.3 业务融合能力
- Prompt工程:设计金融风控报告生成模板,确保输出符合监管要求
- 可解释性:医疗诊断系统提供SHAP值解释,增强医生信任度
- 人机协同:制造业中AI质检与人工复核结合,实现零漏检
六、未来展望:AI与产业的深度共生
- 多模态大模型:融合文本、图像、语音的通用AI将重构客户服务范式
- 数字孪生:制造业通过物理-数字系统映射实现全生命周期优化
- 个性化医疗:基因组学+AI推动精准治疗进入分子层面
- 自适应教育:神经科学+AI实现千人千面的学习路径规划
结语:AI的产业落地已从单点突破进入系统集成阶段。金融、医疗、教育、制造业的实践表明,AI的价值不在于替代人类,而在于通过数据智能放大人类潜能。当AI流程图与业务KPI深度绑定,当Prompt工程成为产品经理的核心技能,我们正见证着第四次工业革命的澎湃浪潮。