建设个人网站可以卖产品吗建筑公司做网站买空间多大合适
深度学习硬件:
CPU:
CPU有数个核心,每个核心可以独立工作,同时进行多个线程,内存与系统共享
GPU:
GPU有上千个核心,但每个核心运行速度很慢,适合并行做类似的工作,不能独立工作,自带内存和缓存
TPU:
专门用于深度学习的硬件,运行速度非常快
GPU的优势:
GPU在大矩阵的乘法运算中有很大的优势,因为矩阵乘法结果中的每一个元素都是原始矩阵某一行与某一列的点积,因此并行进行所有元素的点积运算速度会很快。同样的,卷积核与输入进行卷积运算也可以是并行运算
CUDA:
使用NVIDIA自带的CUDA,可以写出类似于C的代码,直接在GPU上运行。直接写CUDA是一件困难的事,我们可以使用已经NVIDIA已经高度优化且开元的API
深度学习软件:
常见的深度学习框架:
Caffe,PyTorch,TensorFlow
使用深度学习框架的原因:
可以很容易地构建大的计算图,快速地开发及测试new idea
只需要写出前向传播代码,框架可以自动计算梯度
框架的运算可以在GPU上高效地运行
例子:
比如下面的计算图,我们只使用numpy自己编写的正向以及反向传播代码如下:

使用深度学习框架:
TensorFlow版本:
我们只需要把x,y,z设置成3个占位符,并写出它们的正向传播公式,那么使用tf.gradients就可以自动计算出相关的梯度
import numpy as np
np.random.seed(0)
import tensorflow as tf
N, D = 3, 4
# 创建前向计算图
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
z = tf.placeholder(tf.float32)
a = x * y
b = a + z
c = tf.reduce_sum(b)
# 计算梯度
grad_x, grad_y, grad_z = tf.gradients(c, [x, y, z])
with tf.Session() as sess:values = {x: np.random.randn(N, D),y: np.random.randn(N, D),z: np.random.randn(N, D),}out = sess.run([c, grad_x, grad_y, grad_z], feed_dict=values)c_val, grad_x_val, grad_y_val, grad_z_val = outprint(c_val)print(grad_x_val)PyTorch版本:
import torch
device = 'cuda:0' # 在GPU上运行,即构建GPU版本的矩阵
# 前向传播与Numpy类似
N, D = 3, 4
x = torch.randn(N, D, requires_grad=True, device=device)
# requires_grad要求自动计算梯度,默认为True
y = torch.randn(N, D, device=device)
z = torch.randn(N, D, device=device)
a = x * y
b = a + z
c = torch.sum(b)
c.backward() # 反向传播可以自动计算梯度
print(x.grad)
print(y.grad)
print(z.grad)TensorFlow:
我们以搭建两层神经网络,隐藏层激活函数采用ReLU,采用L2距离作为loss,来介绍TensorFlow的大概框架
实现代码如下:
import numpy as np
import tensorflow as tf
N, D , H = 64, 1000, 100
# 创建前向计算图
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
w1 = tf.placeholder(tf.float32, shape=(D, H))
w2 = tf.placeholder(tf.float32, shape=(H, D))
h = tf.maximum(tf.matmul(x, w1), 0) # 隐藏层使用折叶函数
y_pred = tf.matmul(h, w2)
diff = y_pred - y # 差值矩阵
loss = tf.reduce_mean(tf.reduce_sum(diff ** 2, axis=1)) # 损失函数使用L2范数
#另一种更好的计算方法
#loss = tf.losses.mean_squared_error(y_pred, y)
# 计算梯度
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])
# 多次运行计算图
with tf.Session() as sess:values = {x: np.random.randn(N, D),y: np.random.randn(N, D),w1: np.random.randn(D, H),w2: np.random.randn(H, D),}out = sess.run([loss, grad_w1, grad_w2], feed_dict=values)loss_val, grad_w1_val, grad_w2_val = out整个过程分为两个部分,with前面的部分定义计算图,with部分多次运行计算图
1.我们创建了x,y,w1,w2四个tf.placeholder对象,这四个变量作为输入槽
2.之后我们使用这四个变量创建计算图,tf.matmul是矩阵乘法,tf.maximum是取最大值函数,也就是ReLU,h与w2作矩阵乘法算出y_pred,最后计算L2的Loss
3.通过下列代码指定出要求哪个变量关于哪几个变量的梯度
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])这里指定了求loss关于w1,w2的梯度
4.完成计算图的构建后,我们创建一个会话Session来运行计算图和输入数据,在这里,我们需要创建一个字典映射,把上面定义为placeholder的变量名与输入数据的numpy数组作字典,输入进feed_dict参数
5.最后两行代码是运行代码,执行sess.run,指定out接收[loss, grad_w1, grad_w2],进而解包获得
上述的正向+反向传播只进行了一次,需要迭代多次:
with tf.Session() as sess:values = {x: np.random.randn(N, D),y: np.random.randn(N, D),w1: np.random.randn(D, H),w2: np.random.randn(H, D),}learning_rate = 1e-5for t in range(50):out = sess.run([loss, grad_w1, grad_w2], feed_dict=values)loss_val, grad_w1_val, grad_w2_val = outvalues[w1] -= learning_rate * grad_w1_valvalues[w2] -= learning_rate * grad_w2_val最后两行即梯度下降
上述实现没有语法问题,但有很大的效率问题,因为每次run的时候,都要把同样的w1和w2传入,而从CPU传数据到GPU是非常慢的,导致计算速度局限于传输速度,因此我们希望w1和w2能一直保存在计算图中,不需要我们每次run都传进去
1.修改w1和w2的声明方式
w1 = tf.Variable(tf.random_normal((D, H)))
w2 = tf.Variable(tf.random_normal((H, D)))由于不再从外部传入初始化,因此我们需要在声明时就初始化
2.将梯度下降步骤也添加到计算图中
这里使用assign更新w1和w2,若后续步骤不需要用到new_w1和new_w2,=赋值可省略
learning_rate = 1e-5
new_w1 = w1.assign(w1 - learning_rate * grad_w1)
new_w2 = w2.assign(w2 - learning_rate * grad_w2)3.run之前,要先运行参数的初始化tf.global_variables_initializer()
with tf.Session() as sess:sess.run(tf.global_variables_initializer())values = {x: np.random.randn(N, D),y: np.random.randn(N, D),}for t in range(50):loss_val, = sess.run([loss], feed_dict=values)但是上述的代码会有一个问题,实际上梯度不会进行更新。为什么呢?因为我们在run的时候,只要求接收loss,所以tensorflow会自己作优化,只计算loss相关的步骤,将w1,w2的更新步骤忽略不算
解决方法1:
在计算图中加入两个参数的依赖,在执行时需要计算这个依赖(使用tf.group),这样就会让参数更新,然后run时返回group的结果(为空)
具体修改如下:
#计算图构建中加入
updates = tf.group(new_w1,new_w2)#run时改为
loss_val, _ = sess.run([loss, updates], feed_dict=values)解决方法2:
使用tensorflow自带的优化器
#构建计算图时
optimizer = tf.train.GradientDescentOptimizer(1e-5) #学习率
updates = optimizer.minimize(loss) #使loss下降#run时代码
loss_val, _ = sess.run([loss, updates], feed_dict=values)进一步的优化:
上述的w1,w2所代表的神经元层我们可以使用tf自带的api去定义
N, D , H = 64, 1000, 100
x = tf.placeholder(tf.float32, shape=(N, D))
y = tf.placeholder(tf.float32, shape=(N, D))
init = tf.variance_scaling_initializer(2.0) # 定义权重初始化方法,使用He初始化
#定义第一层的输出h
#输入是x,输出列数为H,激活函数是relu,权重初始化器选择刚刚定义的init
h = tf.layers.dense(inputs=x, units=H, activation=tf.nn.relu, kernel_initializer=init)
#定义第二层的输出y_pre,输入为h,输出列数为D,初始化为init
y_pred = tf.layers.dense(inputs=h, units=D, kernel_initializer=init)
loss = tf.losses.mean_squared_error(y_pred, y) # 损失函数使用L2范数
optimizer = tf.train.GradientDescentOptimizer(1e-5)
updates = optimizer.minimize(loss)
with tf.Session() as sess:sess.run(tf.global_variables_initializer())values = {x: np.random.randn(N, D),y: np.random.randn(N, D),}for t in range(50):loss_val, _ = sess.run([loss, updates], feed_dict=values)更高级的封装:tensorflow.keras
Keras是更高层次的封装,使用方式如下:
import numpy as np
import tensorflow as tf
N, D , H = 64, 1000, 100
# 创建模型,添加层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(units=H, input_shape=(D,), activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(D))
# 配置模型:损失函数、参数更新方式
model.compile(optimizer=tf.keras.optimizers.SGD(lr=1e-5), loss=tf.keras.losses.mean_squared_error)
x = np.random.randn(N, D)
y = np.random.randn(N, D)
# 训练
history = model.fit(x, y, epochs=50, batch_size=N)PyTorch:
PyTorch不再使用numpy的ndarray作为数据载体,而是使用tensor对象
自动计算梯度:
import torch
# 创建随机tensors
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
learning_rate = 1e-6
for t in range(500):# 前向传播y_pred = x.mm(w1).clamp(min=0).mm(w2)loss = (y_pred - y).pow(2).sum()# 反向传播loss.backward()# 参数更新with torch.no_grad():w1 -= learning_rate * w1.gradw2 -= learning_rate * w2.gradw1.grad.zero_()w2.grad.zero_()x.mm即矩阵乘法,clamp将小于0的值设置为0,(使最小值为0)
backward()进行反向传播,之后调用变量的grad属性即可获得梯度,最后调用grad.zero_()清空梯度,为下一次梯度传播做准备
torch.no_grad()的意思是在这次计算中不需要计算梯度,因为pytorch是每次运算时才动态构建计算图,为计算梯度做准备,no_grad()的意思就是让它在这次计算中不需要构建计算图。这是pytorch与tensorflow的区别,tf是静态地构建好一个计算图,然后重复运行这个计算图即可
更高级的封装:NN
可以使用nn还有自带的optimizer进一步封装代码
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 定义模型
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),torch.nn.ReLu(),torch.nn.Linear(H, D_out))
# 定义优化器
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 迭代
for t in range(500):y_pred = model(x)loss = torch.nn.functional.mse_loss(y_pred, y)loss.backward()# 更新参数optimizer.step()optimizer.zero_grad()模块定义:
PyTorch中一个模块就是一个神经网络层,输入和输出都是tensor,模块中可以包含权重和其他模块,比如把上面代码中的两层神经网络改为一个模块:
import torch
# 定义上文的整个模块为单个模块
class TwoLayerNet(torch.nn.Module):# 初始化两个子模块,都是线性层def __init__(self, D_in, H, D_out):super(TwoLayerNet, self).__init__()self.linear1 = torch.nn.Linear(D_in, H)self.linear2 = torch.nn.Linear(H, D_out)# 使用子模块定义前向传播,不需要定义反向传播,autograd会自动处理def forward(self, x):h_relu = self.linear1(x).clamp(min=0)y_pred = self.linear2(h_relu)return y_pred
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 构建模型与训练和之前类似
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for t in range(500):y_pred = model(x)loss = torch.nn.functional.mse_loss(y_pred, y)loss.backward()optimizer.step()optimizer.zero_grad()又比如定义一个模块作为模型的一部分:
class ParallelBlock(torch.nn.Module):def __init__(self, D_in, D_out):super(ParallelBlock, self).__init__()self.linear1 = torch.nn.Linear(D_in, D_out)self.linear2 = torch.nn.Linear(D_in, D_out)def forward(self, x):h1 = self.linear1(x)h2 = self.linear2(x)return (h1 * h2).clamp(min=0)model = torch.nn.Sequential(ParallelBlock(D_in, H),ParallelBlock(H, H),torch.nn.Linear(H, D_out))DataLoader:
DataLoader可以包装数据集,并提供获取小批量数据、重新排列、多线程读取,当需要加载自定义数据集时,只需要编写自己的数据集类
import torch
from torch.utils.data import TensorDataset, DataLoader
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
loader = DataLoader(TensorDataset(x, y), batch_size=8)
model = TwoLayerNet(D_in, H, D_out)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
for epoch in range(20):for x_batch, y_batch in loader:y_pred = model(x_batch)loss = torch.nn.functional.mse_loss(y_pred, y_batch)loss.backward()optimizer.step()optimizer.zero_grad()静态图与动态图:
tensorflow使用的是静态图,构建静态图来描述计算,包括找到反向传播的路径,然后每次迭代执行计算的时候,都使用同一张就按图
pytorch使用的是动态图,在每次计算过程中构建计算图,寻找参数梯度路径,每次迭代都抛出计算图,然后再重建
静态图的优势:
由于一张计算图需要反复运行多次,这样框架就会有机会再计算图上进行优化,比如说把下图左侧的计算图优化成右侧
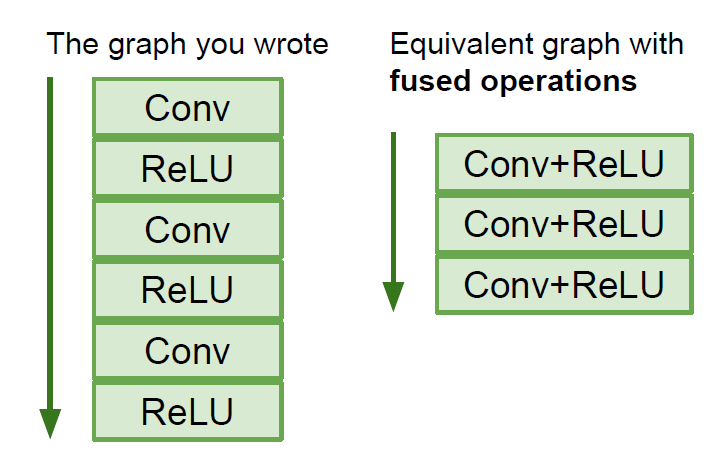
静态图只需要构建一次计算图,所以只要构建好了,即使源码是使用python写的,也可以部署在C++环境,不需要依赖python,而动态图每次迭代都要使用源码
动态图的优势:
动态图的代码比较简洁,很像python操作
比如说在条件判断逻辑中,pytorch可以动态构建计算图,因此可以直接使用python的条件判断流语句,但tensorflow一次性构建静态计算图,因此需要考虑到所有情况,只能使用tensorflow流操作

循环结构也是如此,pytorch直接使用python循环即可,tensorflow需要使用自己的控制流(tf.fold1)
