向量存储vs知识图谱:LLM记忆系统技术选型
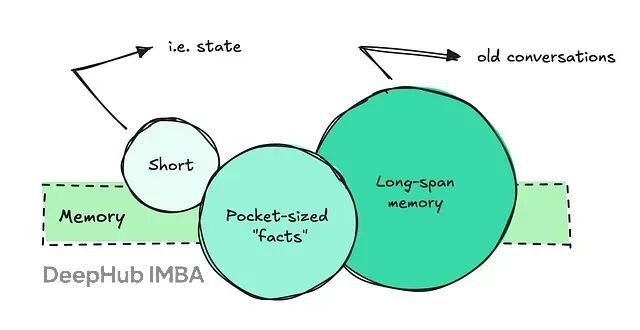
LLM本质上是无状态的,如果你了解HTTP协议就很好理解这个概念,但是如果你没接触过这,那么可以理解成它们没有短期记忆能力,每次和LLM交互,都得把之前的对话重新喂给它。
短期记忆或者说状态管理其实很好处理,拿几组历史问答塞进prompt就行了。但是如果是长期记忆呢?
要让LLM准确提取历史信息、理解过往对话并建立信息关联,需要相当复杂的系统架构。
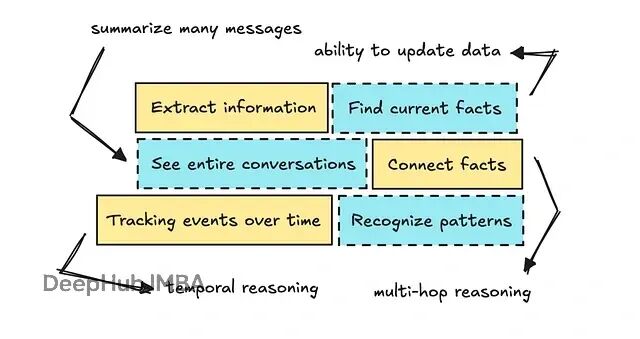
本文会从问题本身出发,看看构建高效记忆系统需要什么,比较不同架构方案,以及市面上有哪些开源和商业化的实现。
基本需求
先看最基本的需求——LLM得能翻出旧消息告诉你之前说过什么,这是基础信息提取能力。
你的第一反应肯定是把整段对话直接扔进context window让模型自己理解。但这样做会让模型分不清信息的重要程度,容易出现幻觉。而且对话一长,context window就撑不住了。
第二个想法可能是存储每条消息加上摘要,然后用语义搜索(RAG里的检索部分)在查询时获取相关信息。
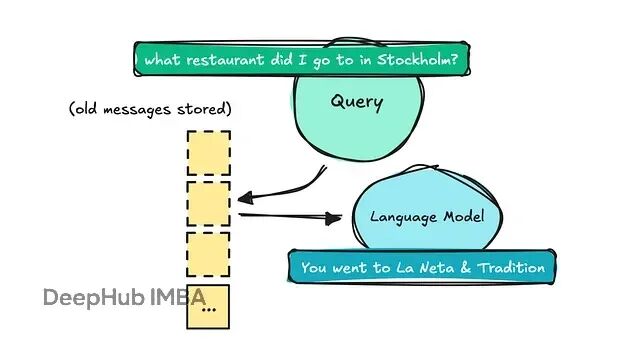
这就是标准的naive retrieval系统的做法。
但是这种方案一旦规模化(除了单纯存消息啥都不做的话),会碰到记忆膨胀、事实过时或冲突、向量数据库不断增长需要频繁清理等麻烦。
还有时间维度的问题。比如问"你第一次提那家餐厅是什么时候?"就需要时间推理能力。你肯定会给数据加上时间戳元数据,甚至搞一套自编辑系统来更新和总结输入内容。自编辑系统虽然复杂,但能在必要时更新事实并标记失效信息。
但是这又带来了新的问题,比如说还需要LLM跨事实进行关联(多跳推理)和模式识别。
比如问"今年去了几场演唱会?"或者"从这些判断我的音乐品味是啥?"这类问题,可能就得考虑知识图谱了。如果这样一步一步加的话,系统就会越来越大。
这个问题复杂到需要系统化的组织方式。业界主流做法是把长期记忆拆成两块:袖珍型事实和长跨度对话记忆。
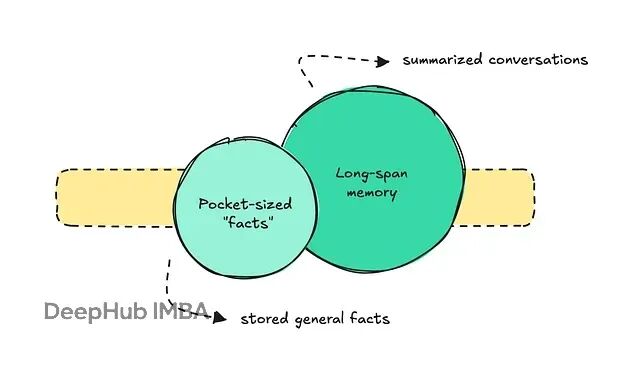
袖珍型事实这块,可以参考ChatGPT的记忆系统。它们大概率用了一个分类器判断某条消息是否包含需要存储的事实。
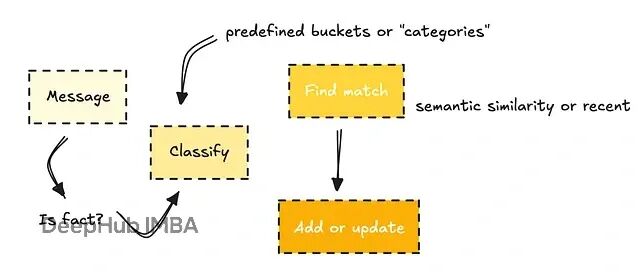
然后把事实归到预设的类别里(比如个人资料、偏好、项目),相似的就更新现有记忆,不同的就新建一条。你可以理解这就是redis,把临时数据以kv的形式存在内存里面,断电了(会话结束)内存的数据没了/
长跨度记忆指的是存储全部消息,并对整段对话做摘要便于后续引用。ChatGPT也有这功能,但需要手动开启。
如果我们要自己实现这种方案的话需要权衡保留多少细节,同时防止前面说的记忆膨胀和数据库爆炸的问题。
架构方案的选择
目前主流架构就两条路:向量方案和知识图谱方案。
前面提到的检索方法是大部分人入门时的选择。检索依赖向量存储(常配合稀疏搜索),能同时支持语义和关键词检索。
检索方案上手简单:把文档embedding后根据用户问题查询就完了。但一般的实现方式有个致命问题——每条输入都是不可变的。就算事实变了,文本还在那儿。
这会导致检索到多条冲突信息把agent搞晕,或者关键事实被埋在一堆检索结果里找不到,agent也搞不清楚某句话是啥时候说的,指的是过去还是将来。
当然这些都有办法绕过去,比如说可以搜索旧记忆并更新它们,给元数据加时间戳,定期总结对话帮LLM理解检索内容的上下文。但向量方案还有个问题——数据库会越来越大。最终得清理旧数据或压缩,这过程中可能丢掉有用信息。
而知识图谱(KG)把信息表示成实体(节点)和关系(边)的网络,而不是非结构化文本。
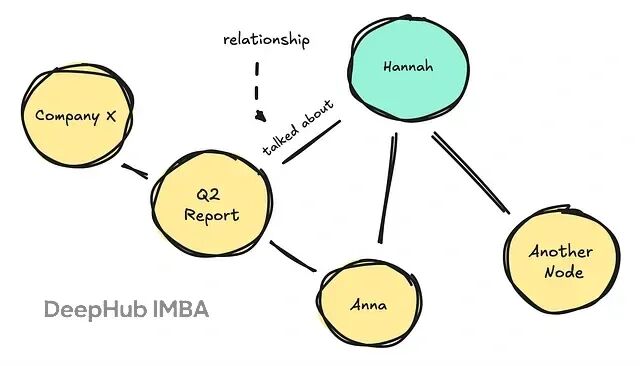
KG不会覆盖数据,而是给旧事实标记
invalid_at
时间,保留历史轨迹。它用图遍历获取信息,可以跨多个节点跟踪关系链。
其实向量方案也能做类似的事,通过检索旧事实然后更新。但KG能在关联节点间跳转,以更结构化的方式维护事实,在多跳推理上表现更好。KG的问题主要是基础设施复杂度。规模上去后,深度遍历时延迟会明显上升,系统得找很远才能定位信息。
总之,不管是向量还是KG方案,业界通常都是更新记忆而不是无脑堆新的,能设置类似"袖珍型"事实那样的分类bucket。
开源方案
下面是我整理的一些搭建记忆系统的独立解决方案,包括实现原理、架构选择和框架成熟度。
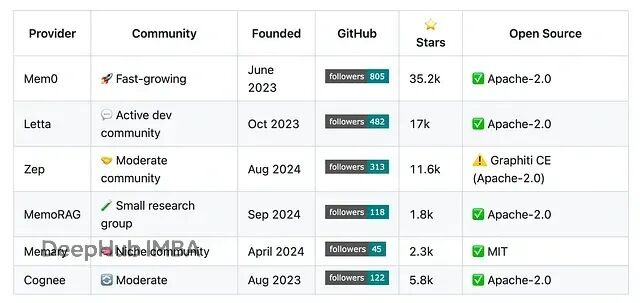
高级LLM应用开发还是个很新的领域,这些方案基本都是最近一两年才出现的。
刚入门时看看这些框架怎么实现的,能帮你理清思路。
下图是它们的功能对比
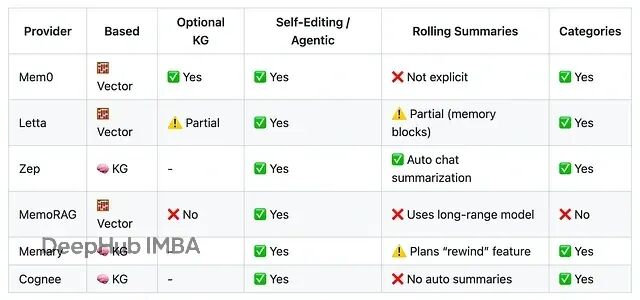
先说Zep(或者Graphiti),基于KG的方案。它们用LLM来提取、添加、失效和更新节点(实体)以及边(带时间戳的关系)。
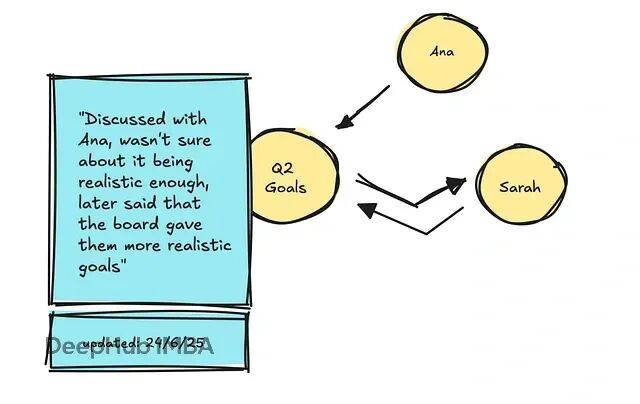
查询时,先做语义和关键词搜索找相关节点,然后遍历到连接节点获取关联事实。新消息如果包含冲突信息,就更新节点但保留旧事实。
Mem0走的是向量路线,它把提取的事实层层叠加,用自编辑系统识别并完全覆盖失效事实。
Letta的工作方式类似,但多了些额外功能,比如core memory,存储对话摘要和定义填充规则的块(或类别)。
所有方案都支持设置类别,定义系统需要捕获什么信息。比如开发情绪管理app,可以设个"当前情绪"类别。这和前面ChatGPT系统里的袖珍型bucket一个道理。
之前提到向量方案在时间推理和多跳推理上有短板。而知识图谱里信息本身就是结构化的,LLM更容易利用全部上下文。
向量方案随着信息增长,噪音会越来越强,系统可能连不起各个点。
Letta和Mem0虽然整体更成熟,但这两个问题依然存在。
成本计算
虽然上面都是开源的系统,但是它们也提供了云服务的付费方案,大部分供应商都有免费额度,但消息量一过几千,费用就上来了。
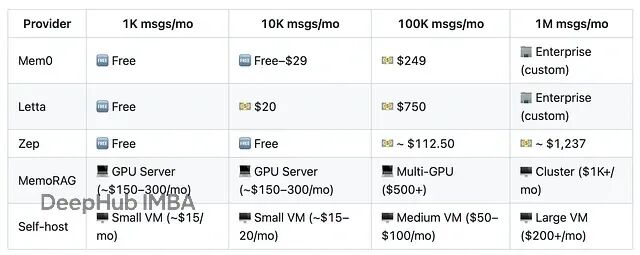
如果组织内每天有几百次对话,所有消息都走云服务的话,账单会很快堆上去。对于测试可以先用云服务,规模起来后切到自部署。
或者搞混合方案,比如自己写个分类器筛选值得存的事实消息来控制成本,其他消息扔自己的向量存储定期压缩和总结。
最后总结
虽然有记忆系统支持,但是也别指望完美。这些系统还是会出现幻觉或者漏掉答案。现在没有系统能做到完美准确,至少目前还没有。研究表明幻觉是LLM固有特性,加记忆层也消除不了这个问题。
希望本文能帮新手理解LLM记忆系统的实现思路。
https://avoid.overfit.cn/post/c0f053ab35c34f5cbd24d936e08dc99f
作者:Ida Silfverskiöld