微信微网站模板下载delphi 可做网站吗
这篇文章我们首先用go语言爬虫,获取豆瓣top250的电影的信息,并且存到数据库。
文章的内容主要分成四个部分:发送请求,解析网页,获取节点信息,保存信息。
准备工作:我们需要熟悉go语言的http请求,安装goquery驱动解析网站返回的doc树。
一、构造http请求
要知道我们通过代码访问官网,我们就相当于是客户端所以需要创建客户端,
//发送请求client := http.Client{}本次爬虫操作本质上就是一个http请求,所以我们在构造http请求之前需要先到豆瓣top250电影网站,打开F12查看网站的url,请求方法,请求头等内容。
为什么需要请求头呢?不是有url和请求方法就可以访问到内容了吗,许多网站都不让爬虫,请求头是为了模仿浏览器的行为,可以正常爬虫,下面是网站的url路径,请求方法,请求头等信息。
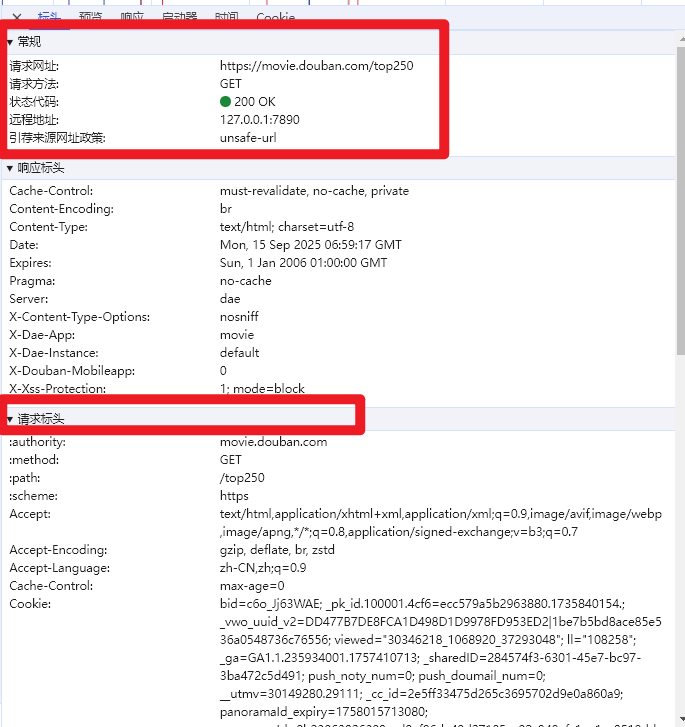
不过要注意//req.Header.Set("Accept-Encoding", "gzip, deflate, br, zstd"),这行代码不能加上,这代表客户端可以接受压缩过的内容,如果加上我们就不能获取页面的正常内容了。
req, err := http.NewRequest("GET", "https://movie.douban.com/top250?start="+page, nil)//设置请求头(Headers)req.Header.Set("Connection", "keep-alive")req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")//req.Header.Set("Accept-Encoding", "gzip, deflate, br, zstd")req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")req.Header.Set("Cache-Control", "no-cache")req.Header.Set("Pragma", "no-cache")req.Header.Set("Priority", "u=0, i")req.Header.Set("Referer", "https://movie.douban.com/chart")req.Header.Set("Content-Type", "application/x-www-form-urlencoded")req.Header.Set("Upgrade-Insecure-Requests", "1")req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36")
使用客户端的Do方法,向网站发送请求。
resp, err := client.Do(req)if err != nil {fmt.Println("发送请求失败:", err)return}二、解析网页内容
我们解析网页内容需要导入goquery包
"github.com/PuerkitoBio/goquery"
client.Do函数返回的结构体resp中,包含Body这个io.Reader类型的读取流类型,并且页面返回的是doc树,所以我们需要goquery包中解析流的函数。
doc, err := goquery.NewDocumentFromReader(resp.Body)三、获取信息节点
返回的doc对象是一个前端的doc树,而我们有用的信息只在某个固定的结点中,其余的信息我们都不需要,所以需要css选择器来获取需要的结点。
goquery里面有Find方法可以通过css选择器获取我们需要的结点,有些结点包含的子节点有多个,此时就需要遍历,goquery里面有Each方法可以遍历这些子节点。
我们爬取的电影有250个,所以一定是在某个包含许多子节点的结点上,大致思路是这样我们通过Find获取到这个结点,再通过Each遍历这个结点的所有子节点。
如下图,所有的电影都被包含在并列的li里面,所以先用Find再用Each的思路是对的,现在怎么通过css选择到这个li呢,右键li这个结点,点击复制,点击复制selector,就可以获取这个结点的css路径了。
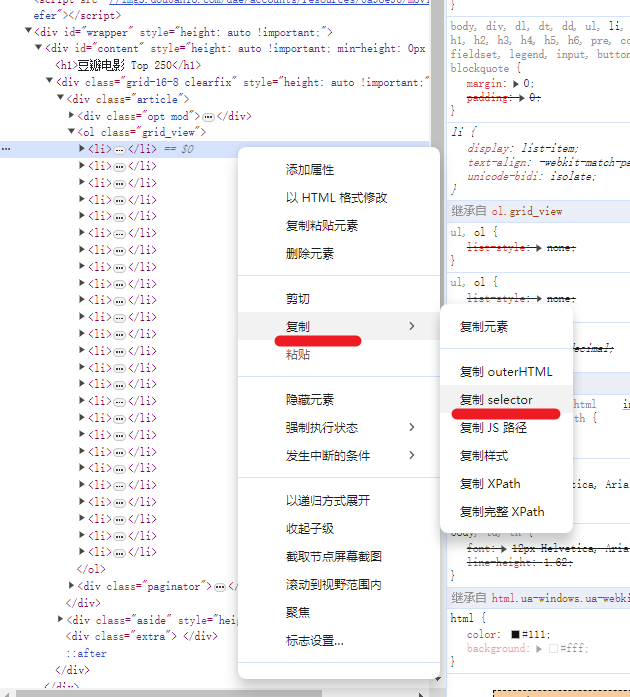
这个代码有两点需要注意:
1.Each函数的参数,第二个参数selection代表当前遍历的结点
2.Text()返回当前结点的内容,是string类型
3.split(),info返回的内容是一个字符串包含许多信息,split就是通过正则表达式把信息拆开。
_ = doc.Find("#content > div > div.article > ol > li").Each(func(i int, selection *goquery.Selection) {title := selection.Find("div > div.info > div.hd > a > span:nth-child(1)").Text()img, ok := selection.Find("div > div.pic > a > img").Attr("src")card := selection.Find("div > div.info > div.bd ")info := card.Find("p:nth-child(1)").Text()year, actor, dir := split(info)score := card.Find("div > span:nth-child(2)").Text()people := card.Find("div > span:nth-child(4)").Text()quote := card.Find("p.quote > span").Text()})拆分的正则表达式需要根据内容来设定。
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
下面这个是split()函数使用正则表达式拆分信息的具体代码。
func split(info string) (year string, director string, actor string) {// 提取年份:使用括号捕获4个数字yearRe := regexp.MustCompile(`\b(\d{4})\b`)yearMatch := yearRe.FindStringSubmatch(info)if len(yearMatch) > 1 {year = yearMatch[1]}// 提取导演:捕获 "导演: " 和 "主演: " 之间的文本directorRe := regexp.MustCompile(`导演:([^主]*)主演:`)directorMatch := directorRe.FindStringSubmatch(info)if len(directorMatch) > 1 {director = directorMatch[1]}// 提取演员:捕获 "主演: " 之后的所有文本actorRe := regexp.MustCompile(`主演:(.*)`)actorMatch := actorRe.FindStringSubmatch(info)if len(actorMatch) > 1 {actor = actorMatch[1]}// 去除捕获到的字符串首尾的空格director = strings.TrimSpace(director)actor = strings.TrimSpace(actor)return
}四、保存数据
我们把收集到的这些变量看作为结构体的字段,并且把结构体对象存入数据库。
初始化并连接数据库,这里我们使用gorm的AutoMigrate函数,创建数据库表。
const (USERNAME = "root"PASSWORD = "123456"HOST = "127.0.0.1"DBNAME = "douban_movie"
)func Init() (DB *gorm.DB, err error) {dns := USERNAME + ":" + PASSWORD + "@tcp(" + HOST + ")/" + DBNAME + "?charset=utf8mb4&parseTime=True&loc=Local"db, err := gorm.Open(mysql.Open(dns), &gorm.Config{})if err != nil {log.Fatalf("连接失败:%v", err)}if err := db.AutoMigrate(&Movie{}); err != nil {log.Fatalf("连接失败:%v", err)}log.Println("表" + DBNAME + "创建成功")return db, nil
}创建电影结构体,存储相关的信息。
type Movie struct {Title string `json:"title"`Img string `json:"img"`Year string `json:"year"`Actor string `json:"actor"`Director string `json:"director"`Score string `json:"score"`People string `json:"people"`Quote string `json:"quote"`
}创建把数据插入数据库的函数。
func InsertData(movie Movie) bool {if err := DB.Create(&movie).Error; err != nil {return false}return true
}在获取节点的代码中添加存储消息到数据库的代码。
_ = doc.Find("#content > div > div.article > ol > li").Each(func(i int, selection *goquery.Selection) {title := selection.Find("div > div.info > div.hd > a > span:nth-child(1)").Text()img, ok := selection.Find("div > div.pic > a > img").Attr("src")card := selection.Find("div > div.info > div.bd ")info := card.Find("p:nth-child(1)").Text()year, actor, dir := split(info)score := card.Find("div > span:nth-child(2)").Text()people := card.Find("div > span:nth-child(4)").Text()quote := card.Find("p.quote > span").Text()if ok {movie := Movie{Title: title,Img: img,Year: year,Actor: actor,Director: dir,Score: score,People: people,Quote: quote,}if InsertData(movie) {fmt.Println("插入成功")}}})五、完整代码
package mainimport ("fmt""github.com/PuerkitoBio/goquery""gorm.io/driver/mysql""gorm.io/gorm""log""net/http""regexp""strconv""strings"
)const (USERNAME = "root"PASSWORD = "123456"HOST = "127.0.0.1"DBNAME = "douban_movie"
)type Movie struct {Title string `json:"title"`Img string `json:"img"`Year string `json:"year"`Actor string `json:"actor"`Director string `json:"director"`Score string `json:"score"`People string `json:"people"`Quote string `json:"quote"`
}var DB *gorm.DBfunc main() {DB, _ = Init()for i := 0; i < 10; i++ {Spider(strconv.Itoa(i * 25))}
}func Spider(page string) {//发送请求client := http.Client{}req, err := http.NewRequest("GET", "https://movie.douban.com/top250?start="+page, nil)if err != nil {fmt.Println("创建http请求:", err)return}//设置请求头(Headers)req.Header.Set("Connection", "keep-alive")req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")//req.Header.Set("Accept-Encoding", "gzip, deflate, br, zstd")req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")req.Header.Set("Cache-Control", "no-cache")req.Header.Set("Pragma", "no-cache")req.Header.Set("Priority", "u=0, i")req.Header.Set("Referer", "https://movie.douban.com/chart")req.Header.Set("Content-Type", "application/x-www-form-urlencoded")req.Header.Set("Upgrade-Insecure-Requests", "1")req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36")resp, err := client.Do(req)if err != nil {fmt.Println("发送请求失败:", err)return}doc, err := goquery.NewDocumentFromReader(resp.Body)if err != nil {fmt.Println("获取doc树失败")return}_ = doc.Find("#content > div > div.article > ol > li").Each(func(i int, selection *goquery.Selection) {title := selection.Find("div > div.info > div.hd > a > span:nth-child(1)").Text()img, ok := selection.Find("div > div.pic > a > img").Attr("src")card := selection.Find("div > div.info > div.bd ")info := card.Find("p:nth-child(1)").Text()year, actor, dir := split(info)score := card.Find("div > span:nth-child(2)").Text()people := card.Find("div > span:nth-child(4)").Text()quote := card.Find("p.quote > span").Text()if ok {movie := Movie{Title: title,Img: img,Year: year,Actor: actor,Director: dir,Score: score,People: people,Quote: quote,}if InsertData(movie) {fmt.Println("插入成功")}}})}func split(info string) (year string, director string, actor string) {// 提取年份:使用括号捕获4个数字yearRe := regexp.MustCompile(`\b(\d{4})\b`)yearMatch := yearRe.FindStringSubmatch(info)if len(yearMatch) > 1 {year = yearMatch[1]}// 提取导演:捕获 "导演: " 和 "主演: " 之间的文本directorRe := regexp.MustCompile(`导演:([^主]*)主演:`)directorMatch := directorRe.FindStringSubmatch(info)if len(directorMatch) > 1 {director = directorMatch[1]}// 提取演员:捕获 "主演: " 之后的所有文本actorRe := regexp.MustCompile(`主演:(.*)`)actorMatch := actorRe.FindStringSubmatch(info)if len(actorMatch) > 1 {actor = actorMatch[1]}// 去除捕获到的字符串首尾的空格director = strings.TrimSpace(director)actor = strings.TrimSpace(actor)return
}func Init() (DB *gorm.DB, err error) {dns := USERNAME + ":" + PASSWORD + "@tcp(" + HOST + ")/" + DBNAME + "?charset=utf8mb4&parseTime=True&loc=Local"db, err := gorm.Open(mysql.Open(dns), &gorm.Config{})if err != nil {log.Fatalf("连接失败:%v", err)}if err := db.AutoMigrate(&Movie{}); err != nil {log.Fatalf("连接失败:%v", err)}log.Println("表" + DBNAME + "创建成功")return db, nil
}func InsertData(movie Movie) bool {if err := DB.Create(&movie).Error; err != nil {return false}return true
}
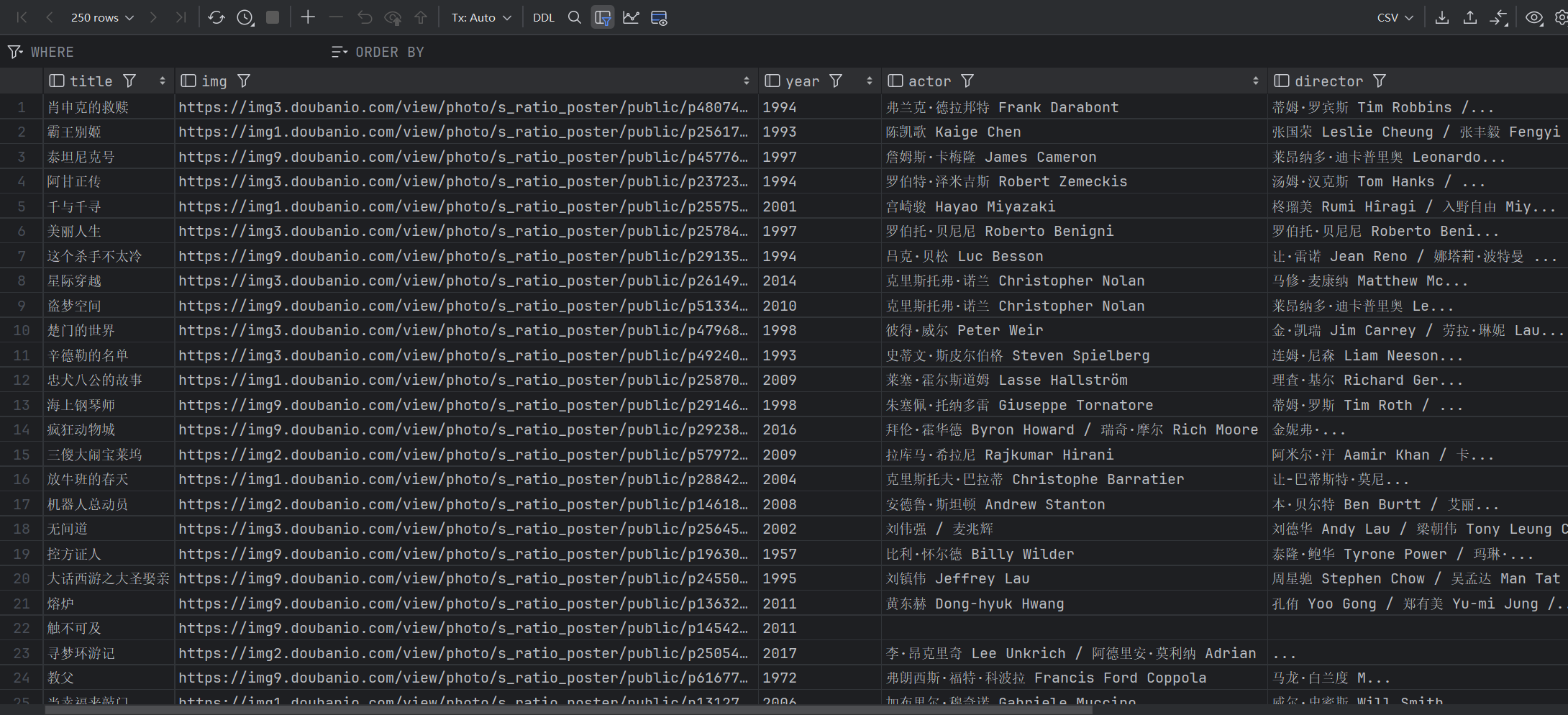
下面是数据库的运行结果
希望这篇文章对你的爬虫学习有帮助!