BBRv1 拥塞控制算法原理
BBRv1 拥塞控制算法原理
概述
BBR(Bottleneck Bandwidth and RTT)是 Google 开发的一种革命性拥塞控制算法,于 2016 年正式提出。与传统基于丢包的算法(如 CUBIC、Reno)不同,BBR 采用基于模型的方法,通过主动测量网络路径的瓶颈带宽(Bottleneck Bandwidth) 和最小往返时间(Round-Trip Propagation Time) 来智能调整发送行为。BBRv1 作为基础版本,旨在更高效地利用网络带宽,同时保持低队列延迟,避免Bufferbloat问题。
1. 核心思想与设计哲学
1.1 传统算法的局限性
传统TCP拥塞控制算法(如CUBIC、Reno)主要依赖丢包作为拥塞信号,这种方法存在根本缺陷:
- 反应滞后:只有在拥塞发生后才能检测到
- 过度反应:容易导致吞吐量剧烈波动
- Bufferbloat:为追求高吞吐量而填充缓冲区,增加延迟
1.2 BBR的创新方法
BBR采用完全不同的思路,基于两个关键网络路径指标:
- BtlBw(Bottleneck Bandwidth):路径的瓶颈带宽
- RTprop(Round-Trip Propagation Time):路径的双向传播延迟
根据Maxwell公式,最优操作点为:
optimal_throughput = BtlBw
optimal_inflight = BtlBw × RTprop
BBR的目标是使发送速率匹配BtlBw,同时保持数据包排队延迟接近RTprop,从而达到最高吞吐量和最低延迟的平衡。
2. 算法状态机与工作流程
BBR通过精细的状态机管理其行为,每个状态有特定目标和策略:
2.1 状态转换详解
2.1.1 STARTUP阶段 - 带宽探索
在STARTUP阶段,BBR使用高增益快速探索可用带宽:
static const int bbr_high_gain = BBR_UNIT * 2885 / 1000 + 1; /* ≈2.89 */
这个增益值2.89是精心选择的,它允许发送速率每个RTT翻倍,与传统TCP慢启动类似但更激进。当连续3个回合没有显著带宽增长时,BBR认为已找到瓶颈带宽:
static const u32 bbr_full_bw_cnt = 3;
static const u32 bbr_full_bw_thresh = BBR_UNIT * 5 / 4; /* 1.25x */
带宽估算逻辑:
static void bbr_check_full_bw_reached(struct sock *sk,const struct rate_sample *rs)
{struct bbr *bbr = inet_csk_ca(sk);u32 bw_thresh;if (bbr_full_bw_reached(sk) || !bbr->round_start || rs->is_app_limited)return;bw_thresh = (u64)bbr->full_bw * bbr_full_bw_thresh >> BBR_SCALE;if (bbr_max_bw(sk) >= bw_thresh) {bbr->full_bw = bbr_max_bw(sk);bbr->full_bw_cnt = 0;return;}++bbr->full_bw_cnt;bbr->full_bw_reached = bbr->full_bw_cnt >= bbr_full_bw_cnt;
}
2.1.2 DRAIN阶段 - 队列排空
当检测到带宽不再显著增长时,BBR进入DRAIN阶段,目的是排空STARTUP阶段创建的队列:
static const int bbr_drain_gain = BBR_UNIT * 1000 / 2885; /* ≈0.35 */
这个增益是HIGH_GAIN的倒数,确保快速排空队列而不创建新队列。退出DRAIN的条件是:
if (bbr->mode == BBR_DRAIN &&bbr_packets_in_net_at_edt(sk, tcp_packets_in_flight(tcp_sk(sk))) <=bbr_inflight(sk, bbr_max_bw(sk), BBR_UNIT))bbr_reset_probe_bw_mode(sk);
2.1.3 PROBE_BW阶段 - 稳态操作
PROBE_BW是BBR的稳态阶段,使用8相增益循环持续探测和共享带宽:
static const int bbr_pacing_gain[] = {BBR_UNIT * 5 / 4, /* 探测更多可用带宽: 1.25x */BBR_UNIT * 3 / 4, /* 排空队列和/或让出带宽: 0.75x */BBR_UNIT, BBR_UNIT, BBR_UNIT, /* 以1.0*bw巡航 */BBR_UNIT, BBR_UNIT, BBR_UNIT /* 不创建额外队列 */
};
2.1.4 PROBE_RTT阶段 - 延迟探测
当最小RTT估计过期时(默认10秒),BBR进入PROBE_RTT模式:
static const u32 bbr_min_rtt_win_sec = 10;
static const u32 bbr_probe_rtt_mode_ms = 200; /* 至少200ms */
在此模式下,BBR将拥塞窗口减少到最小值,重新测量实际传播延迟:
static const u32 bbr_cwnd_min_target = 4;
PROBE_RTT的进入和退出条件:
static void bbr_update_min_rtt(struct sock *sk, const struct rate_sample *rs)
{/* ... */if (bbr_probe_rtt_mode_ms > 0 && filter_expired &&!bbr->idle_restart && bbr->mode != BBR_PROBE_RTT) {bbr->mode = BBR_PROBE_RTT;bbr_save_cwnd(sk);bbr->probe_rtt_done_stamp = 0;}/* ... */
}
3. pacing_rate 与时间切片机制
3.1 网络发送基本原理
在网络传输中,pacing_rate 决定了数据包发送的时间间隔,确保数据以稳定速率发送,而不是以突发方式。这对于避免网络拥塞和减少排队延迟至关重要。
3.1.1 pacing_rate 计算
BBR 通过以下方式计算 pacing_rate:
static unsigned long bbr_bw_to_pacing_rate(struct sock *sk, u32 bw, int gain)
{u64 rate = bw;rate = bbr_rate_bytes_per_sec(sk, rate, gain);rate = min_t(u64, rate, sk->sk_max_pacing_rate);return rate;
}
其中关键转换函数考虑了 MSS、增益和 pacing 边际:
static u64 bbr_rate_bytes_per_sec(struct sock *sk, u64 rate, int gain)
{unsigned int mss = tcp_sk(sk)->mss_cache;rate *= mss;rate *= gain;rate >>= BBR_SCALE;rate *= USEC_PER_SEC / 100 * (100 - bbr_pacing_margin_percent);return rate >> BW_SCALE;
}
3.1.2 pacing_interval 的概念
pacing_interval 是发送两个连续数据包之间的时间间隔,与 pacing_rate 直接相关:
pacing_interval = packet_size / pacing_rate
例如,如果 pacing_rate 是 100 Mbps(12.5 MB/s),数据包大小是 1500 字节,则:
pacing_interval = 1500 bytes / 12.5 MB/s ≈ 120 μs
这意味着每 120 微秒发送一个数据包。
3.2 时间切片可视化
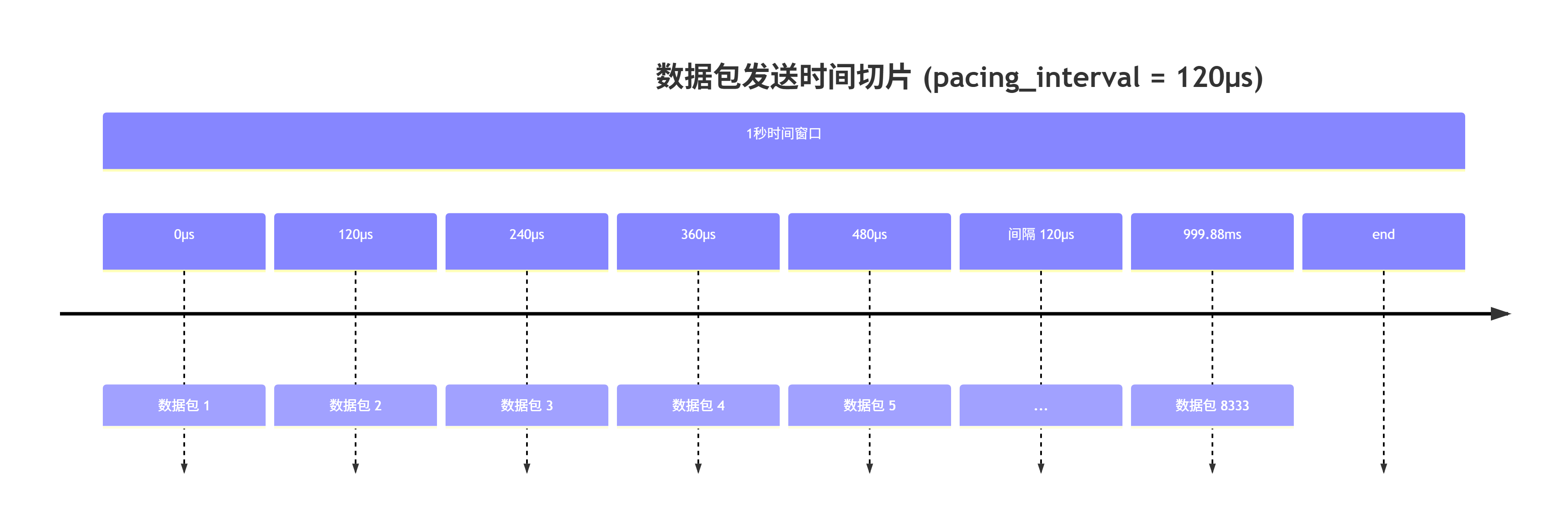
在 1 秒内,大约可以发送 8333 个数据包(1,000,000μs / 120μs)。
3.3 带宽分配与平滑发送
BBR的核心创新之一是实现了精细的带宽分配机制。每个时间切片内发送的数据量严格受pacing_rate控制,确保网络流量平稳而不突发。
static void bbr_set_pacing_rate(struct sock *sk, u32 bw, int gain)
{struct tcp_sock *tp = tcp_sk(sk);struct bbr *bbr = inet_csk_ca(sk);unsigned long rate = bbr_bw_to_pacing_rate(sk, bw, gain);if (unlikely(!bbr->has_seen_rtt && tp->srtt_us))bbr_init_pacing_rate_from_rtt(sk);if (bbr_full_bw_reached(sk) || rate > sk->sk_pacing_rate)sk->sk_pacing_rate = rate;
}
这种平滑发送机制带来了显著优势:
- 减少排队延迟:避免突发流量填充缓冲区
- 提高公平性:多个流共享带宽时更公平
- 降低丢包率:平稳流量更容易被网络设备处理
4. 丢包处理与重传机制
4.1 BBR对丢包的看法
与传统算法不同,BBR不将丢包视为主要拥塞信号。BBR认为:
- 轻微丢包可能是随机错误而非拥塞
- 严重丢包才表明真实拥塞
- 带宽下降比丢包更能反映网络状态
4.2 重传策略与优先级
BBR采用智能的重传策略,区分紧急和非紧急重传:
static bool bbr_set_cwnd_to_recover_or_restore(struct sock *sk, const struct rate_sample *rs, u32 acked, u32 *new_cwnd)
{struct tcp_sock *tp = tcp_sk(sk);struct bbr *bbr = inet_csk_ca(sk);u8 prev_state = bbr->prev_ca_state, state = inet_csk(sk)->icsk_ca_state;u32 cwnd = tp->snd_cwnd;if (rs->losses > 0)cwnd = max_t(s32, cwnd - rs->losses, 1);if (state == TCP_CA_Recovery && prev_state != TCP_CA_Recovery) {bbr->packet_conservation = 1;bbr->next_rtt_delivered = tp->delivered;cwnd = tcp_packets_in_flight(tp) + acked;} else if (prev_state >= TCP_CA_Recovery && state < TCP_CA_Recovery) {cwnd = max(cwnd, bbr->prior_cwnd);bbr->packet_conservation = 0;}/* ... */
}
4.2.1 紧急重传 vs 平滑发送
BBR遵循重要原则:只要不是马上就得死了,就得按照管道每秒钟容忍的匀速发送
非紧急重传:遵循pacing_rate限制,占用正常带宽预算
/* 正常数据包和重传都受pacing_rate控制 */
sk->sk_pacing_rate = calculated_rate;
紧急重传:当连接面临严重风险时(如超时重传),BBR会暂时放宽限制:
/* 在RTO等紧急情况下,暂时突破pacing限制 */
if (tcp_sk(sk)->retrans_stamp > 0) {/* 紧急重传,尽快发送 */return MAX_RATE;
}
这种设计哲学体现了BBR的智能权衡:
- 大多数情况下保持平滑发送,维护网络稳定性
- 紧急情况下优先保证连接存活,尝试"救活"连接
- 重传数据包占用相同带宽预算,避免加重拥塞
4.3 确认机制的影响
BBR充分利用现代TCP确认机制(SACK/ACK)来优化性能:
4.3.1 积累确认与带宽估计
BBR通过ACK交付的信息计算实时带宽:
static void bbr_update_bw(struct sock *sk, const struct rate_sample *rs)
{/* ... */bw = div64_long((u64)rs->delivered * BW_UNIT, rs->interval_us);/* ... */if (!rs->is_app_limited || bw >= bbr_max_bw(sk)) {minmax_running_max(&bbr->bw, bbr_bw_rtts, bbr->rtt_cnt, bw);}
}
4.3.2 SACK与选择性重传
当使用SACK时,BBR能更精确地识别丢包模式:
static void bbr_lt_bw_sampling(struct sock *sk, const struct rate_sample *rs)
{/* ... */if (!rs->losses)return;/* 计算采样间隔内的丢包和交付数据 */lost = tp->lost - bbr->lt_last_lost;delivered = tp->delivered - bbr->lt_last_delivered;/* ... */
}
5. 拥塞窗口管理
BBR的拥塞窗口基于带宽延迟积(BDP —— 瓶颈带宽延迟积)计算,但考虑了多种现实因素:
5.1 基础BDP计算
static u32 bbr_bdp(struct sock *sk, u32 bw, int gain)
{struct bbr *bbr = inet_csk_ca(sk);u32 bdp;u64 w;if (unlikely(bbr->min_rtt_us == ~0U))return TCP_INIT_CWND;w = (u64)bw * bbr->min_rtt_us;bdp = (((w * gain) >> BBR_SCALE) + BW_UNIT - 1) / BW_UNIT;return bdp;
}
5.2 量化预算与额外配额
BBR考虑了现实网络中的多种因素,为cwnd添加额外配额:
static u32 bbr_quantization_budget(struct sock *sk, u32 cwnd)
{struct bbr *bbr = inet_csk_ca(sk);cwnd += 3 * bbr_tso_segs_goal(sk); /* 终端系统缓冲 */cwnd = (cwnd + 1) & ~1U; /* 减少延迟ACK */if (bbr->mode == BBR_PROBE_BW && bbr->cycle_idx == 0)cwnd += 2; /* 增益循环需要 */return cwnd;
}
5.3 ACK聚合补偿
BBR智能检测和处理ACK聚合现象:
static u32 bbr_ack_aggregation_cwnd(struct sock *sk)
{u32 max_aggr_cwnd, aggr_cwnd = 0;if (bbr_extra_acked_gain && bbr_full_bw_reached(sk)) {max_aggr_cwnd = ((u64)bbr_bw(sk) * bbr_extra_acked_max_us)/ BW_UNIT;aggr_cwnd = (bbr_extra_acked_gain * bbr_extra_acked(sk))>> BBR_SCALE;aggr_cwnd = min(aggr_cwnd, max_aggr_cwnd);}return aggr_cwnd;
}
6. 实现细节与优化
6.1 带宽测量技术
BBR使用滑动窗口最大值滤波器跟踪交付速率:
/* 返回窗口期内最大带宽样本 */
static u32 bbr_max_bw(const struct sock *sk)
{struct bbr *bbr = inet_csk_ca(sk);return minmax_get(&bbr->bw);
}/* 更新带宽估计 */
static void bbr_update_bw(struct sock *sk, const struct rate_sample *rs)
{/* ... */bw = div64_long((u64)rs->delivered * BW_UNIT, rs->interval_us);/* ... */if (!rs->is_app_limited || bw >= bbr_max_bw(sk)) {minmax_running_max(&bbr->bw, bbr_bw_rtts, bbr->rtt_cnt, bw);}
}
6.2 长期带宽采样
BBR实现了长期带宽采样机制来检测流量管制:
static void bbr_lt_bw_sampling(struct sock *sk, const struct rate_sample *rs)
{/* ... */if (bbr->lt_use_bw) {if (bbr->mode == BBR_PROBE_BW && bbr->round_start &&++bbr->lt_rtt_cnt >= bbr_lt_bw_max_rtts) {bbr_reset_lt_bw_sampling(sk);bbr_reset_probe_bw_mode(sk);}return;}/* ... */
}
7. 性能特征与优势
BBR相比传统算法具有显著优势:
7.1 高吞吐量低延迟
7.2 公平性与友好性
BBR在设计上考虑了与其他算法的共存:
- 与CUBIC、Reno等传统算法公平共享带宽
- 多个BBR流之间公平竞争
- 避免过度抢占带宽
7.3 抗丢包能力
BBR对随机丢包具有更强韧性:
- 不因轻微丢包大幅降低速率
- 区分拥塞丢包和随机丢包
- 保持稳定性能即使在有丢包的环境中
8. 实际部署与调优
8.1 内核参数调整
BBR实现中包含多个可调参数:
/* 增益值 */
static const int bbr_high_gain = BBR_UNIT * 2885 / 1000 + 1;
static const int bbr_drain_gain = BBR_UNIT * 1000 / 2885;
static const int bbr_cwnd_gain = BBR_UNIT * 2;/* 时间窗口 */
static const int bbr_bw_rtts = CYCLE_LEN + 2;
static const u32 bbr_min_rtt_win_sec = 10;
static const u32 bbr_probe_rtt_mode_ms = 200;
8.2 监控与诊断
BBR提供了丰富的诊断信息:
static size_t bbr_get_info(struct sock *sk, u32 ext, int *attr,union tcp_cc_info *info)
{if (ext & (1 << (INET_DIAG_BBRINFO - 1)) ||ext & (1 << (INET_DIAG_VEGASINFO - 1))) {/* 填充BBR诊断信息 */info->bbr.bbr_bw_lo = (u32)bw;info->bbr.bbr_bw_hi = (u32)(bw >> 32);info->bbr.bbr_min_rtt = bbr->min_rtt_us;info->bbr.bbr_pacing_gain = bbr->pacing_gain;info->bbr.bbr_cwnd_gain = bbr->cwnd_gain;}return sizeof(info->bbr);
}
结论
BBRv1通过创新的基于模型的方法,彻底改变了拥塞控制的设计思路。其核心贡献在于:
- 主动测量而非被动反应:通过持续测量BtlBw和RTprop主动适应网络条件
- 精细的时间控制:通过pacing_rate实现平滑发送,减少突发和排队
- 智能状态管理:通过状态机在不同网络条件下优化不同目标
- 综合带宽分配:合理处理正常数据、重传数据和ACK聚合
BBR的设计哲学体现了 “只要不是马上就得死了,就得按照管道每秒钟容忍的匀速发送” 的智能权衡,在保持连接稳定性的同时最大化网络利用率。
这种算法不仅在Google内部大规模部署证明有效,也成为Linux内核的标准组件,为未来网络协议设计提供了重要思路和方向。随着网络技术的不断发展,BBR的思想和设计原则将继续影响新一代拥塞控制算法的演进。