为什么RocketMQ选择mmap+write?RocketMQ零拷贝技术深度解析
参考:
1、【kafka为什么这么快?RocketMQ哪里不如Kafka?】 https://www.bilibili.com/video/BV1Zy411e7qY/?share_source=copy_web&vd_source=4e85cdb3e1cd24ca01702aa1b21b55db
2、https://cloud.tencent.com/developer/article/2203072?shareByChannel=link
3、deepseek
read+write:
1、应用程序想要将在磁盘的数据通过网络发送给消费者,传统模式下一般分为两个步骤:
- read:读取本地文件内容;
- 应用程序向操作系统发起read调用,CPU从用户态切换到内核态;
- DMA把数据从磁盘拷贝到内核态缓冲区;
- CPU将系统内存中的数据拷贝到用户空间;
- 从内核态切换到用户态,read方法调用返回。
- write:将读取的内容通过网络发送出去;
- 应用程序发起write系统调用,从用户态切换到内核态;
- CPU把数据从用户缓冲区拷贝到socket缓冲区;
- DMA把数据从socket缓冲区拷贝到网卡的缓冲区中,通过网卡返回给客户端;
- CPU从内核态切换为用户态,write方法调用返回。
以上分析,可以发现,仅仅一个消息发送,就发生了4次用户态和内核态的上下文切换,4次数据拷贝。要想提高性能,就需要减少用户态与内核态的上下文切换和内存拷贝的次数。
mmap+write:
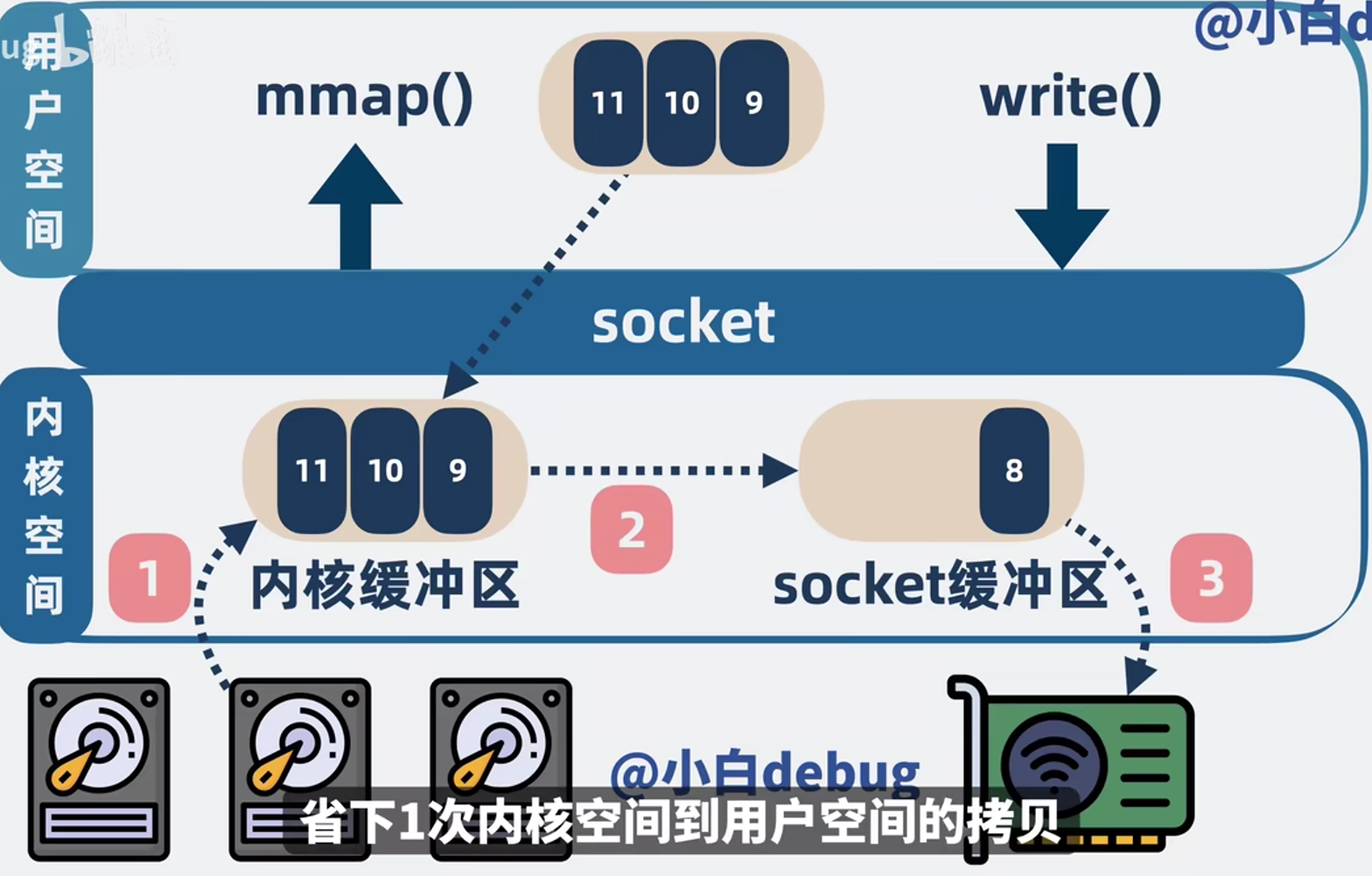
2、还是上面那个背景下,如果我们要实现 应用程序将在磁盘的数据通过网络发送给消费者,在mmap+write的模式下的步骤是这样:
零拷贝技术实现的方式通常有mmap+write和sendfile两种,这里我们先介绍mmap+write这种方式。
- mmap:将文件直接映射到进程的虚拟内存区域,使得应用程序可以通过指针(虚拟地址)直接读写文件内容。
- 应用程序发起mmap系统调用,CPU从用户态切换到内核态;
- CPU建立了一个映射关系,就是将用户空间的“内存映射空间”映射到了内核空间的“页面缓存”上。应用程序就可以通过指针直接访问用户空间的内存映射区域来读取这些数据。
- DMA把数据从磁盘拷贝到内核缓冲区;
- mmap调用返回,CPU从内核态切换为用户态。
- write:将读取的内容通过网络发送出去;
- 应用程序发起write系统调用,从用户态切换到内核态;
- CPU将数据从内存映射空间复制到socket缓冲区;
- DMA把数据从socket缓冲区拷贝到网卡的缓冲区中,通过网卡返回给客户端;
- CPU从内核态切换为用户态,write方法调用返回。
可以发现,在mmap+write下,发生了4次用户态和内核态的上下文切换,3次数据拷贝。内存映射空间的一个核心作用,就是免去了内核缓存到用户缓存的数据拷贝。
接着,我们代入rocketmq,看一下Broker接收生产者消息 到 Broker为消费者提供消息这些过程是怎么使用mmap技术的:
// Broker接收生产者消息
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {// 传统方式需要:// 1. 网络数据 → 应用缓冲区 (拷贝)// 2. 应用缓冲区 → 内核缓冲区 (write系统调用+拷贝)// 3. 内核缓冲区 → 磁盘 (DMA)// RocketMQ方式:// 1. 网络数据 → 应用缓冲区 (拷贝) ← 这个拷贝无法避免// 2. 应用缓冲区 → 内存映射区域 (直接CommitLog写入、异步构建ConsumeQueue索引)// 3. 内存映射区域自动同步到磁盘
}
// Broker为消费者提供消息
public GetMessageResult getMessage(...) {// 传统方式需要:// 1. 磁盘 → 内核缓冲区 (DMA)// 2. 内核缓冲区 → 应用缓冲区 (read系统调用+拷贝)// 3. 应用缓冲区 → Socket缓冲区 (write系统调用+拷贝)// RocketMQ方式:// 1. 通过内存映射区域可以直接访问可能已在内核页缓存中的磁盘数据// 2. 应用程序通过内存映射区域访问CommitLog (如果数据在内核缓存中:直接读取;如果不在:内核从磁盘加载到内核缓存 → 然后读取)// 3. 直接从内存映射区域 → Socket缓冲区 (write系统调用+拷贝)
}
sendfile:
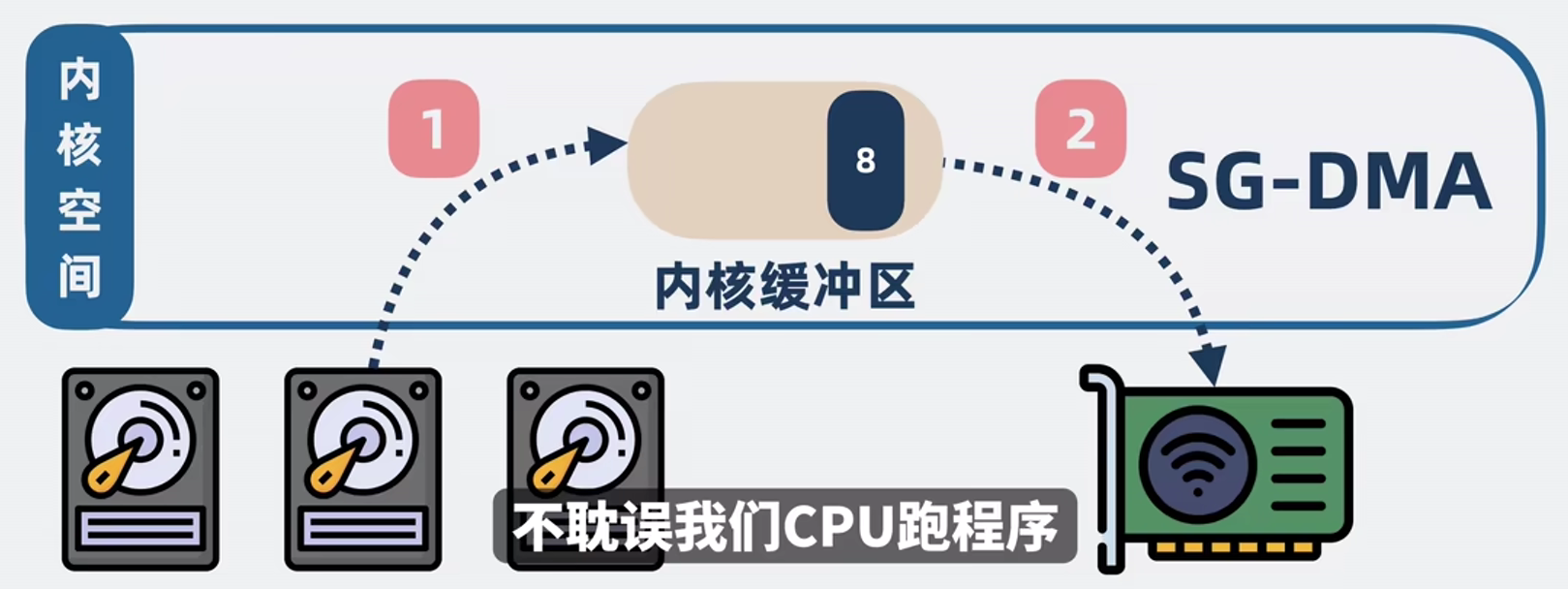
sendfile也是内核提供的一个方法,整个过程就只需要调用sendfile,就可以实现上面的步骤:
- sendfile
- 应用进程调用sendfile(),上下文从用户态转向内核态;
- DMA控制器把数据从硬盘中拷贝到内核缓冲区;
- CPU直接将内核缓冲区的数据拷贝到socket缓冲区中;
- DMA把数据从socket缓冲区拷贝到网卡的缓冲区中;
- 上下文从内核态切换回用户态,sendfile()调用返回;
整个过程就1次系统调用,两次用户空间和内核空间的切换,两次数据拷贝。
为什么RocketMQ选择mmap+write而不是sendfile?
sendfile 的限制:无法读取和修改消息内容。sendfile系统调用是在内核中直接将数据从文件描述符传输到套接字描述符,而不需要经过用户空间。这确实减少了数据拷贝和上下文切换次数。
在RocketMQ中,mmap+write之所以能确保读到消息内容,是因为mmap将文件映射到用户空间的虚拟内存区域,这样应用程序就可以通过指针直接访问文件内容,然后进行必要的处理(如过滤、批量等),最后再通过write将处理后的数据发送出去。
根本原因在于:rocketmq希望业务功能需求 > 极致性能:消费者拉取消息时,Broker需要根据消费者订阅的Tag对消息进行过滤,这需要读取消息的内容(Tag信息在消息体内)。另外,顺序消息、事务消息、延迟消息等也需要读取消息内容。
什么场景用kakfa/rocketMq?
大数据(涉及什么spark\flink)就用kafka
其他用rocketmq