Whisper推理源码解读
章节1:背景介绍
Whisper是一个由OpenAI开发的自动语音识别(ASR)系统,在多语言环境和嘈杂背景下的语音识别任务中表现出色。它具有如下特点:
- 多语言支持:Whisper被设计为一个多语言模型,能够理解和转录多种语言的语音,包括但不限于英语、中文、阿拉伯语、法语、德语、意大利语、日语、韩语、葡萄牙语、俄语、西班牙语和土耳其语等。
- 鲁棒性:Whisper在处理各种噪声环境下的语音信号方面表现出鲁棒性,这意味着即使在背景噪音较大的情况下,它也能够准确识别和转录语音。
- 高质量的转录:Whisper利用先进的深度学习技术,提供了高质量的语音转文本服务,能够捕捉到语音中的细微差别,包括口音、语速和情感等。
- 开源和可用性:Whisper模型的代码和部分版本已经开源,使得研究人员和开发者可以自由地使用和改进这个模型,推动语音识别技术的发展。
- 预训练和微调:Whisper模型可以通过在特定任务上的预训练和微调来进一步提高其性能,使其更好地适应特定的应用场景和数据集。
Whisper的这些特点使其在多种应用场景中具有潜在的用途,包括自动字幕生成、语音助手、语音翻译、会议记录和内容创作等。随着语音识别技术的不断进步,Whisper和其他类似的系统将继续在提高人类与机器之间交互的自然性和效率方面发挥重要作用。本文将就whisper推理相关代码进行解读。
章节2:运行环境
- 模型类型选择:tiny
- 调试工具基于vscode
- 运行平台Mac
章节3:源码解读
论文(参考文献-1)中whisper框架图如下图所示,可以将推理过程大体分为4个步骤。
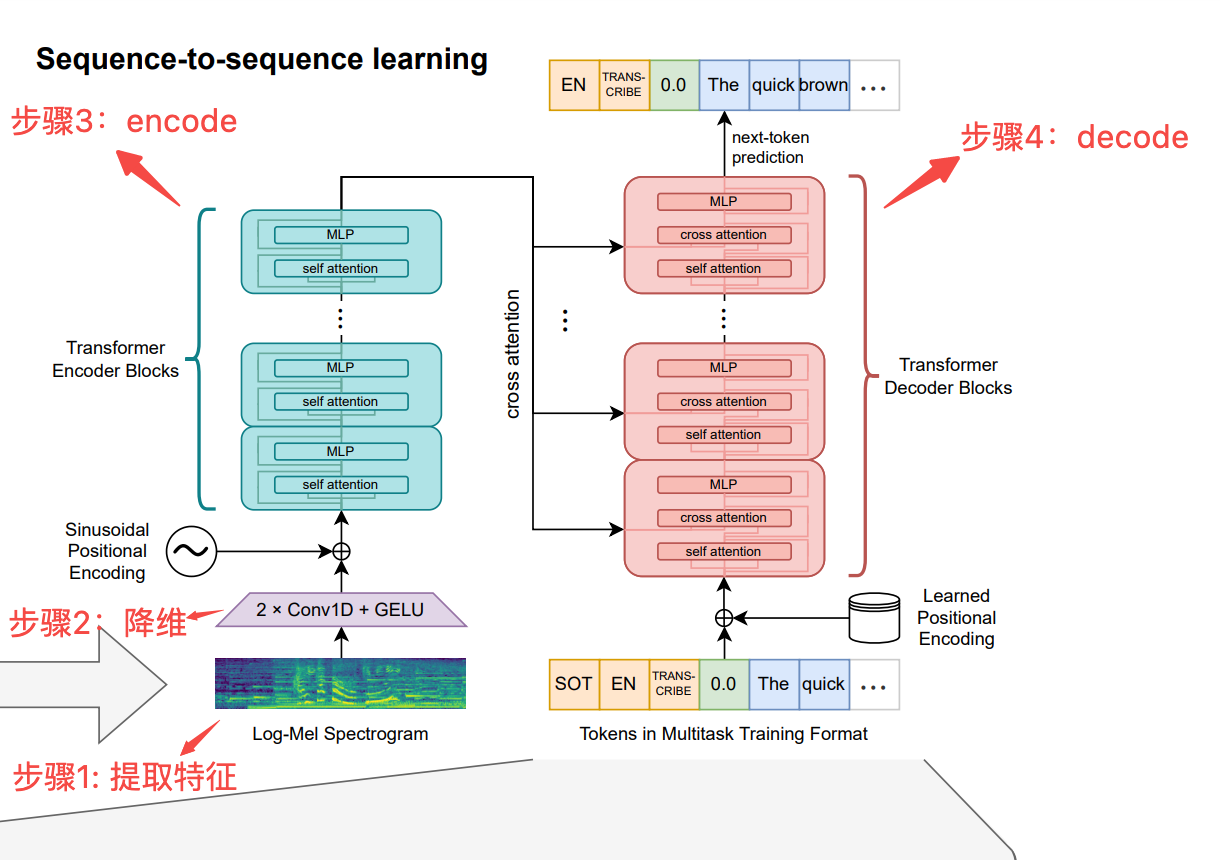
步骤1. 提取音频特征
whipser用的是对数梅尔频谱图(log-mel spectrogram),这是音频信号处理中常用的一种特征表示方法,是一种表示音频信号频率内容的对数功率谱图,它通过模拟人耳的听觉感知特性来加权频率轴,主要过程包括:预处理(分帧、加窗函数)->短时傅里叶变换->Mel滤波器组->对数能量。
code示例如下:
def log_mel_spectrogram(audio: Union[str, np.ndarray, torch.Tensor],n_mels: int = N_MELS,padding: int = 0,device: Optional[Union[str, torch.device]] = None,):window = torch.hann_window(N_FFT).to(audio.device) # 加汉宁窗# 短时傅里叶变化(stft)stft=torch.stft(audio, N_FFT, HOP_LENGTH, window=window, return_complex=True)magnitudes = stft[..., :-1].abs() ** 2filters = mel_filters(audio.device, n_mels) # 加mel滤波器组,n_mels=80mel_spec = filters @ magnitudeslog_spec = torch.clamp(mel_spec, min=1e-10).log10() # 求取对数能量# 保证数值稳定性,避免因为数值范围过大导致梯度消失或爆炸log_spec = torch.maximum(log_spec, log_spec.max() - 8.0)log_spec = (log_spec + 4.0) / 4.0return log_spec步骤2. 降低维度
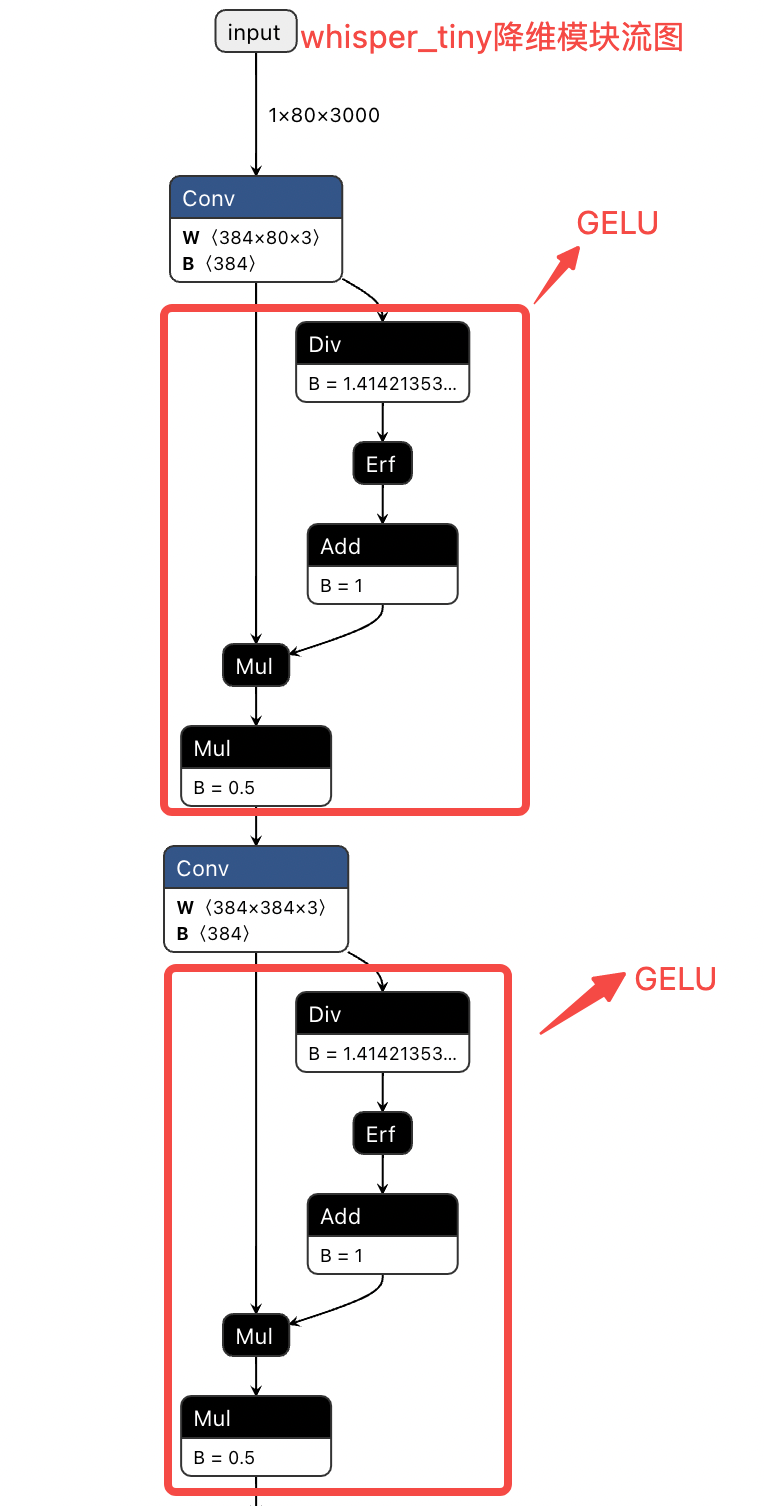
通过两个卷积在时间轴上实现降维,帧数从3000降为1500。
# 代码位于whisper_at/model.py
class AudioEncoder(nn.Module):def forward(self, x: Tensor):"""x : torch.Tensor, shape = (batch_size, n_mels, n_ctx)the mel spectrogram of the audio"""# 输入x shape:[1, 80, 3000]x = F.gelu(self.conv1(x)) # kernel_size=3提取局部特征x = F.gelu(self.conv2(x)) # stride=2,实现降维, x shape变为[1, 384, 1500]x = x.permute(0, 2, 1) # [1, 384, 1500]-> [1, 1500, 384]论文采用在Transformer模型中表现最好的GELU作为激活函数。
-
- 计算公式如下:

-
- 调用方式
torch.nn.functional.gelu(input, approximate='none') → Tensor-
- 实现流图如下:
步骤3. Encode
encode部分由“4层残差注意力块+layernorm”构成,残差注意力块详细描述参《残差注意力结构源码解读》,这里不再赘述。总之,经过编码后每个位置的信息编码成一个定长的隐藏向量表示,所以输出的输入/输出时间维度是相同的。实现code示例:
# reference: whisper_at/model.py
def ResidualAttentionBlock(x, mask, kv_cache):x = x + self.attn(self.attn_ln(x), mask=mask, kv_cache=kv_cache)[0]x = x + self.mlp(self.mlp_ln(x))return x# 输入[1, 1500, 384]
x = (x + self.positional_embedding) # 进行位置编码
for block in self.blocks: # 4层残差注意力块(block=ResidualAttentionBlock)x = block(x)
x = self.ln_post(x)
# 输出[1, 1500, 384]步骤4. Decode
decode部分的目标是:将Encoder的输出以及前面已经生成的序列作为输入,生成下一个位置的token。因为引入Encode的输出,所以需要引入cross attention,示例code如下:
# reference: whisper_at/model.py
def ResidualAttentionBlock(x, xa, mask, kv_cache):x = x + self.attn(self.attn_ln(x), mask=mask, kv_cache=kv_cache)[0]# xa就是encode模块的输出x = x + self.cross_attn(self.cross_attn_ln(x), xa, kv_cache=kv_cache)[0]x = x + self.mlp(self.mlp_ln(x))return x# 先前生成词序列进行词编码(wte)和位置编码(wpe), 得到即包含符号信息又包含位置信息的序列x
# 如首次推理x=[50258](对应token="<|startoftranscript|>"), 经过编码后表示成一个[1, 1, 384]的序列
x = (self.token_embedding(x) + self.positional_embedding)# 4层残差注意力块(block=ResidualAttentionBlock)
for block in self.blocks:# 这里xa是Encode的输出x = block(x, xa, mask=self.mask, kv_cache=kv_cache)x = self.ln(x) # LayerNorm# 隐藏向量映射到token空间:[1, 1, 384]->[1, 1, 51865],如果是greedy-search,直接选择概率最高的token作为预测结果
logits = x @ torch.transpose(self.token_embedding.weight.to(x.dtype), 0, 1)
章节4:参考文献
- Robust Speech Recognition via Large-Scale Weak Supervision: https://arxiv.org/pdf/2212.04356.pdf
- GELU: https://arxiv.org/pdf/1606.08415.pdf
- https://github.com/openai/whisper
- 常用语音特征:https://www.cnblogs.com/LXP-Never/p/11725378.html