TCP拥塞控制
为什么需要拥塞控制:不难想象,一个完全遵守(σ,ρ)流量模型和RSVP协议的网络,不需要考虑网络拥塞的问题。在这样的一个网络中,每一个包的发送都需要在事先确认不会发生丢包的情况下,才能得到准许。但是,在现实生活中,绝大多数时候我们仍然采用的是尽力而为的网络模型(一方面是成本问题,另一方面,一个完全遵守(σ,ρ)流量模型和RSVP协议的网络意味着路由需要存储大量状态,并且在适当的时候清除这些状态,这违反了端到端的原则),所以,我们需要引入其他的拥塞控制机制。(这也是两种网络模型的差别——保证服务和尽力而为服务)
最大最小公平分配(Max-min fairness):该策略会将所有需求方需求大小从小到大排序。Demand(i)如果大于现有供给量的平均值(总供给量除以总需求人数),那么只提供现有供给量的平均值,如果等于,提供现有供给量的平均值,如果小于,提供Demand(i)的量。这样的分配,能保证资源需求较小的弱势方获得尽量公平的待遇。
拥塞控制的目标:
1.高吞吐量:提高链路利用率并保证流量的速度。
2.最大最小公平分配。
3.对网络的改变回应迅速。(当有其他流量到达时,需要稍微退让降低拥塞。如果其他流量消失,则需要快速利用空出来的容量)
4.分布式的控制:我们不能依赖于某个中央仲裁者来决定整个网络的速率,相反,我们需要这种操作以分布式的方式进行。
现在,让我们抛开(σ,ρ)流量模型和RSVP协议那一套,既然没有事先的交流沟通和保证,那么,我们就需要另一套机制来确保发生拥塞时,发送者能够在中途知道拥塞已经发生并做出调整。
显式拥塞控制
ECN(显式拥塞控制):核心思想是路由器在检测到拥塞时,不丢包,而是在 IP 报文头 的特定位上做标记。接收方 把这个标记信息反馈给 发送方。发送方 根据反馈调整拥塞窗口,降低发送速率。
TCP拥塞控制
TCP 的拥塞控制完全由端主机负责,它通过观察丢包等信号、结合滑动窗口机制,来控制发送窗口的大小,从而决定网络中能同时存在安全在途的报文数量。TCP 的发送窗口大小受限于接收方的接收能力(Advertised window)和网络的拥塞控制窗口(cwnd),最终取两者中的最小值(链路压力小就取决于终端,终端压力小就取决于链路);而 cwnd 的值是 TCP 拥塞控制算法需要动态调整的关键。
AIMD:我们使用AIMD来调整cwnd,AIMD分为加性增和乘性减。前者为每个RTT(round trip time),如果没有丢包(丢包为超时或者收到重复确认号),发送方就把cwnd增加1个最大报文段大小。(总体表现为平稳增长)后者为检测到丢包(说明网络拥塞),cwnd就乘以0.5,迅速为网络降压。但是,AIMD并不控制发送数据的速率,AIMD所做的只是控制网络中未确认数据包的数量。
ECN是在网络中实现拥塞控制,而TCP拥塞控制则是在终端实现。
TCP拥塞基础AIMD
单一流情况下
注:讨论在数据到达路由输入端口速率等于数据到达路由输出端口速率的理想模型下进行。也就是说这里我们会把路由等效为一个只有数据到达速率,数据离开速率,缓冲区大小三要素的简单模型。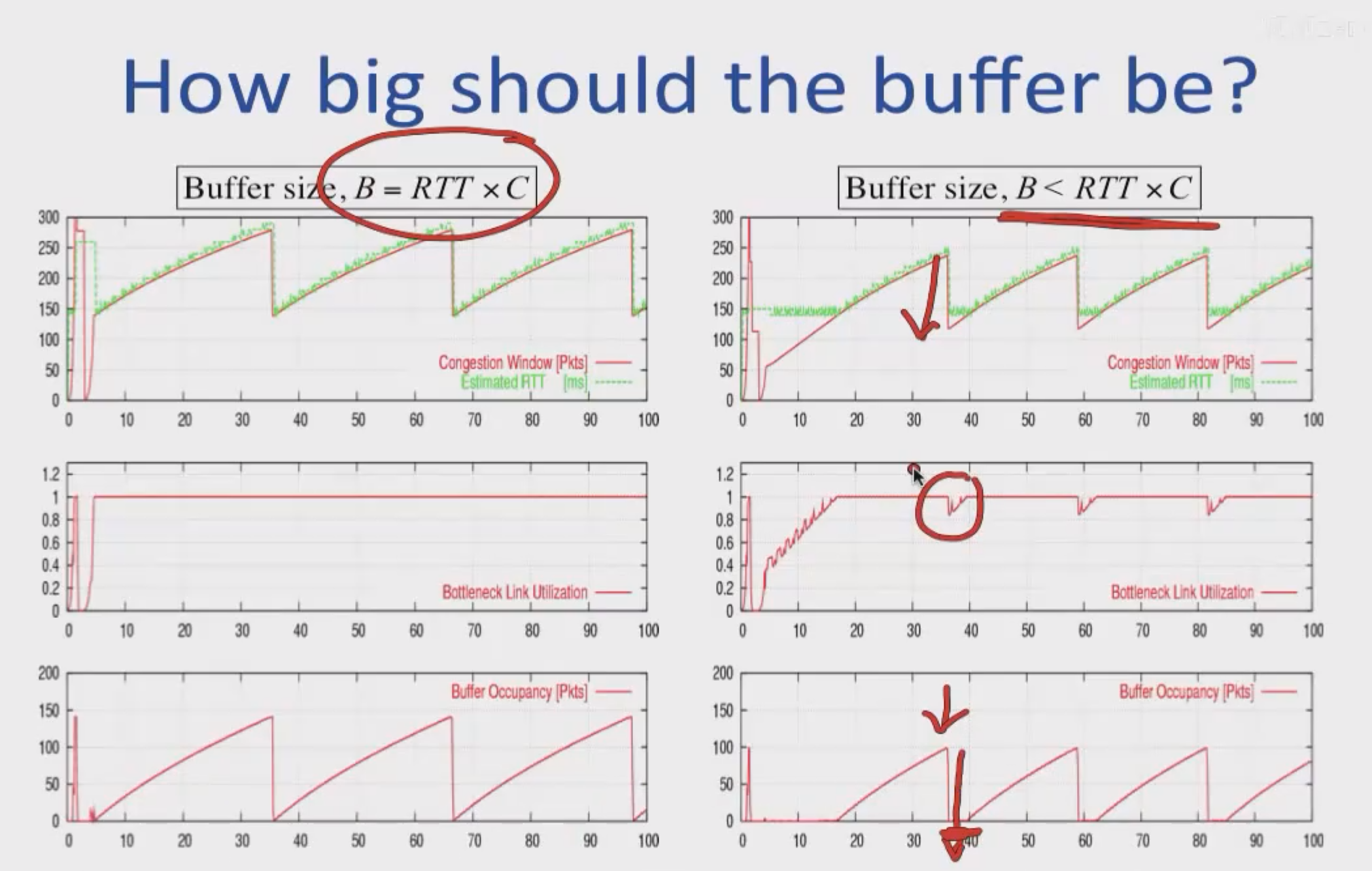
C的含义是带宽(这里特指瓶颈网络链路每秒钟最多能传输多少比特的数据)。
RTT是往返时间,指的是一个数据包的第一个比特位,从发送方出发,到达接收方,再由接收方发回的确认(ACK)的第一个比特位,回到发送方,所经历的总时间。
RTT乘以C得到的就是带宽时延积(BDP),它的含义就是在一个RTT的时间内(这里的RTT是无排队延迟的RTT_min),发送方最多可以发送多少个比特的数据,并将这条网络路径完全“填满”。 换句话说,当发送方的第一个比特刚刚到达接收方,并立即触发一个ACK开始返回时,发送方在这段时间内,总共已经“推”了 BDP 这么多的比特到网络中。
相比之前讨论的理想路由模型,其实变化的只有“发送窗口大小会发生变化”,“单位时间由秒变化为RTT”这两点。
单位时间由秒变化为RTT,是因为RTT是发送方从发送到接收网络反馈的最小时间周期。只有在接收到网络反馈之后,才能改变策略,调整发送窗口大小。这个变化不仅仅是“单位的变化”,而是从一个“与时间无关的流体模型”到“一个与反馈延迟紧密耦合的离散控制系统”的转变。
但是,需要注意的是,发送窗口大小依据的RTT是一个变化的量,它会呈上面锯齿状的变化。但是,BDP依赖的RTT却是一个恒定的RTT_min。实际上一个RTT时间内,缓冲区的累积量增量应该为W(t)-BDP(t),这个值就为1MSS(Maximum Segment Size)。这里的BDP(t)是一个动态的量。
小结:总而言之,不论如何,一个RTT时间内W(t)大小加1MSS,缓冲区累积量大小加1MSS,甚至RTT自己也会增大。
多个流的情况下
在多个流的情况下,由于缓冲区接近时刻为满。RTT可以视作不变。而在单个流的情况下,RTT和窗口大小一起变大,两者比值近似常量。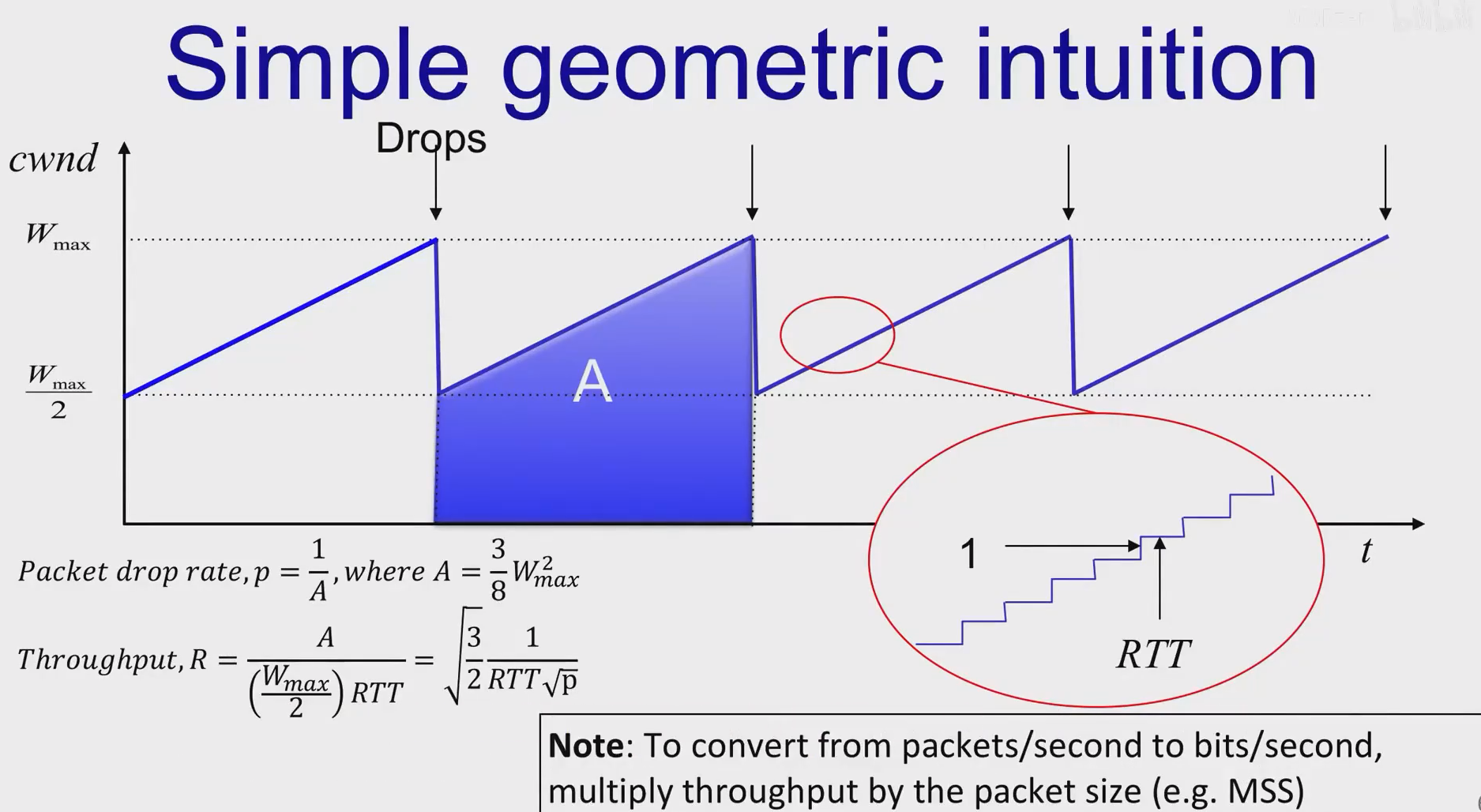
关于p的计算:p是丢包概率,发送量为A的数据,会发生一次丢包。
关于梯形的高的计算:由于一个RTT时间内W增加1,增加二分之Wmax所需的时间当然就是二分之Wmax除以1再乘RTT,就可得到图中的公式。
由Throughput的计算公式可知:
1.RTT趋于很大时,数据输出量会变小。这会对较远的通信造成不符期望的不利影响。
2.p趋于0时,R将持续增加,趋于无限大。这也表明丢包是AIMD拥塞控制的关键角色。
TCP Tahoe
在互联网早期,网络经常会进入一种称为拥塞崩溃的状态。拥塞发生,造成丢包问题时,如果发送方不降低发送速率,只是一味重传数据包的话。由于路由缓冲区本就饱和,重传的数据包一样也逃不过丢包的命运,拥塞将持续恶化下去。宝贵的链路资源被大量注定被丢弃的重传数据包所占用,实际有效的数据传输量极低。TCP Tahoe就是是TCP协议中第一个系统性地实现拥塞控制的算法。它主要由Congestion window,Timeout estimation,Self-clocking三部分组成。
他们与TCP Tahoe需要面临的三个问题相对应:
Congestion window
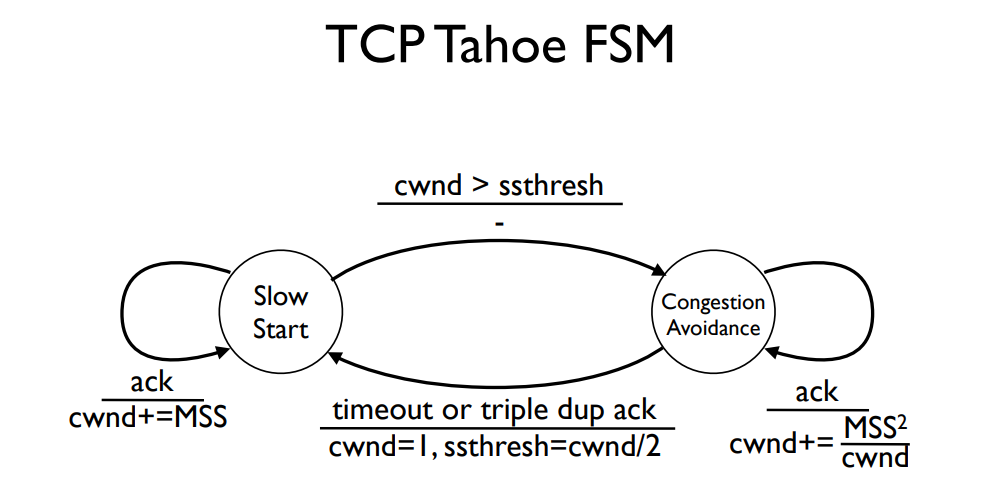
我们把拥塞控制分为两个状态,慢启动和拥塞避免。
慢启动:每当发送方收到一个对新数据的ACK时,它就将自己的cwnd增加1个MSS。
注:慢启动的慢是相对于以前,在三次握手之后就会立刻发送一个很大的窗口。
拥塞避免:每收到一个确认号窗口大小增加MSS平方除以拥堵窗口大小。行为与加性增相符。(一个RTT增加一个MSS,一个RTT预期得到congestion windowSize除以MSS个确认号)
注:通过上面的方式一个RTT内近似增加一个MSS。
Timeout estimation
这是早期的Timeout estimation机制,问题在于该算法无法应对RTT骤增或骤降的情景,当这种情况发生时,需要很长时间才能慢慢把之前的累积量拉回到现在的值。所以,我们不仅需要观察最新测得的RTT,还需要考虑其方差。

下面是TCP Tahoe中更为先进的版本。这个算法既能避免在网络抖动时发生不必要的伪重传,又能在网络稳定时保持一个灵敏的、较短的超时时间。

Self clocking
核心思想:TCP的发送速率,不是由一个固定的、外部的计时器(比如“每秒发送N个包”)来驱动的,而是由“确认(ACK)从网络中返回的速率”来驱动的。
理想情况下,发送方应该始终使瓶颈链路利用率为百分之百。但对于发送方来说,网络就是一个“黑箱”,发送方对于它到接收方之间的网络路径一无所知,更别说对瓶颈链路的运行情况了。TCP需要一个反馈机制来感知这个“离开速率”。这个反馈,就是ACK。ACK返回的速率,恰好就反映了数据包成功穿过网络瓶颈的速率。而当ACK返回时(ACK包很小,通常不会引起拥塞,故相对时间间隔假定不变),他们就如同镜像一般准确地反映了数据包离开网络瓶颈的速率。根据返回的ACK来发送数据,能够始终使瓶颈链路保持一个较高的利用率,并且也控制了网络中未确认的数据包的数量,防止瓶颈链路过载进而导致丢包。对于接收方来说,它应该积极的像发送方发送确认 ,因为发送方对于网络的所有判断都依据于它的确认,这是它从网络得到的唯一反馈。
注:但是其实相对时间间隔的事情很复杂,需要考虑排队,交换机类型,缓冲区利用率或者是否为空,同一流多路径等等很复杂的问题,不论路由的数据离开速率相比之前的瓶颈速率较大或较小,相对时间间隔仍然可以变大可以变小,甚至可以不变,但在一个统计平均和稳态的视角下,ACK返回的速率仍能反映瓶颈速率。
TCP Tahoe改进
拥塞窗口:TCP Reno在TCP Tahoe的基础上进一步改进。他们的不同在于,TCP Tahoe在收到三次重复确认时会直接进入慢启动阶段,将窗口大小重新设回1,这被认为是过于保守的,因为此时后面的数据包的确认都以期望的速度到达,我们可以认为当前期望的包由于网络拥塞以外的原因丢失了。
而TCP Reno在此时会将拥塞窗口大小设置为之前的一半而非直接为1,避免窗口大小再次回到1进行试探。收到连续三个相同ACK后,不等待超时,TCP会直接重传被认为丢失的数据包,这被称作快速重传。由于阈值仍被设为拥塞窗口大小二分之一,此时TCP Reno可以直接进入拥塞避免状态。 显然,这可以提供TCP的吞吐量。
TCP NewReno在超时时行为仍然保持一致。不同在于在快速重传之后,它不会等待一个RTT的时间来接受那个期望的确认号,它会进入快速恢复阶段,在此阶段中,每再收到一个重复ACK,就将cwnd临时地增加1 MSS,然后发送数据。直到收到期望的ACK之后,窗口大小才会调整到原来的拥塞窗口大小二分之一,并进入拥塞避免状态。
这样的改进使得发送方不会在那里傻傻的等待快速重传对应得到的期望序列号,然后在收到序列号之后一下需要发送几乎接近整个窗口的数据。由于TCP Newreno的改进,在途数据量始终稳定在一个比较高的水平(而TCP Reno在那等待的时候在途数据量可能会降到很低),发送方可以平滑的过渡到正常行为,并且也提高了对链路的利用率。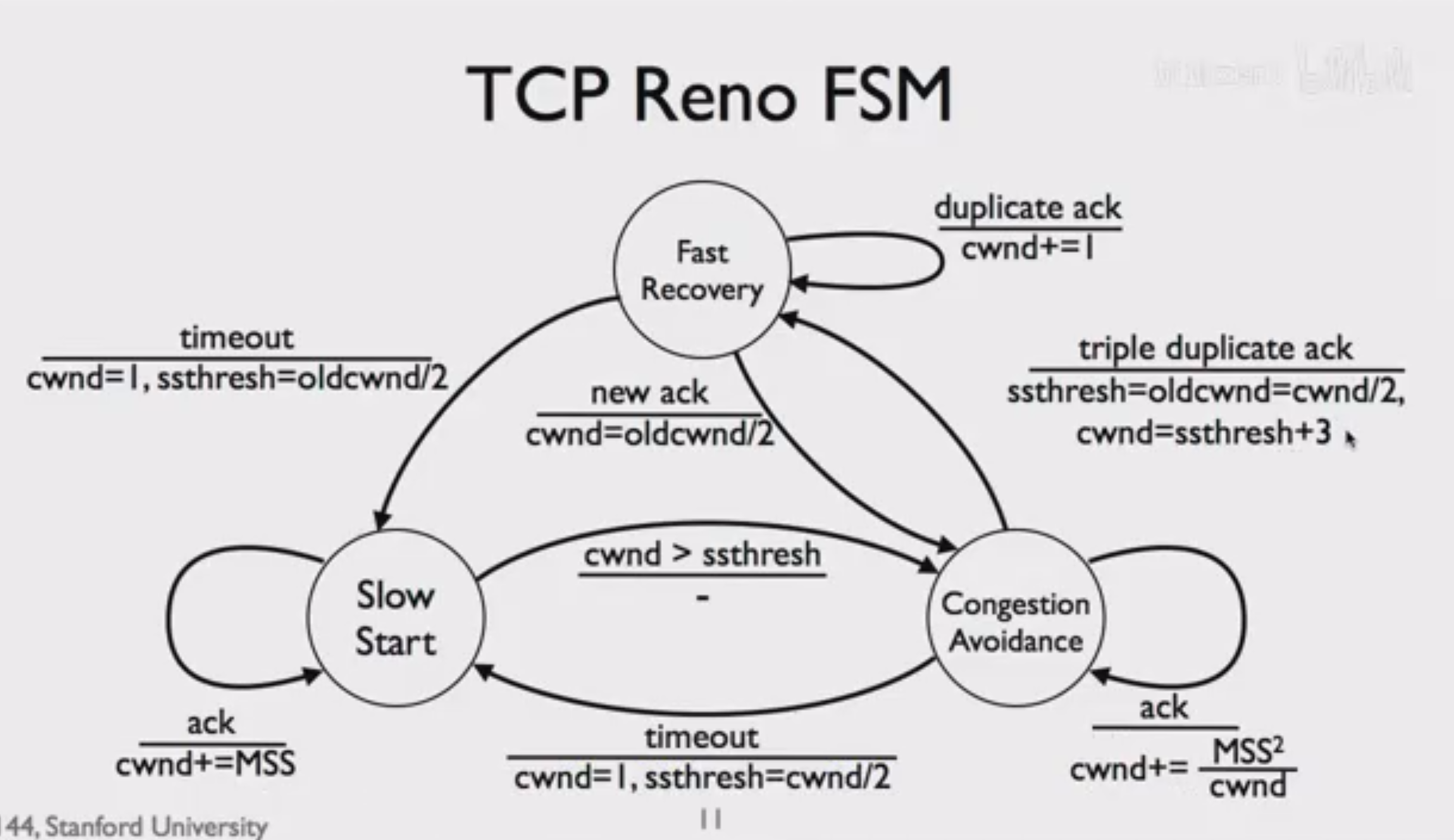
但是,我们仔细推导,可能发现有些地方表现得很奇怪。假如旧窗口大小原本为2i,其中的一号数据包不幸丢失,那么,在收到对应2,3,4号包的重复ACK之后,进入快速恢复阶段。此时新窗口大小变为i+3,然而在途数据包的数量为2i-3(收到 3 个 dupACK 意味着发送方认为至少有 3 个分节已经被接收端收到并“离开”了未确认窗口,但这也只是一种经常被采纳的简化方式),如果将发送条件设定为i+3>2i-3,就会得到一个奇怪的i<6,而i>=6时好像禁止被发送。事实上,对于i<6这种情况极少发生,绝大多数时候i都很大。当i>=6时,我们暂时允许在途数量大于窗口大小,并强行规定,在快速恢复阶段,每接收一个重复ACK,就使窗口大小+1,并发送一个数据包。显然,这样的强行规定对于i<6的阶段并不冲突。
然后,我们再来关注收到快速重传对应的ACK之后如何表现。需要注意的是,在时间轴上,快速重传的前一个包是旧窗口的最后一个包,快速重传的后一个包是由于重复ACK发送的第一个包。假定他们的相对时间次序不变,当收到快速重传包时,接收方尚未收到旧窗口之后的数据,因此只能发送确认旧窗口数据的确认号。这也就导致当从快速恢复阶段回到拥塞避免阶段时,在途数据包数量为2i-4(抛去丢失数据包和3个重复ACK,会有2i-4次重复ACK,发送2i-4次数据包),但我们的cwnd却为i,这意味着一段时间内,由于在途数量大于cwnd,我们都不会发送新的数据包,链路效率将会下降。这就是 Reno 在吞吐率上的一个“硬伤”:恢复后的速率下滑过猛,恢复不够平滑。
虽然TCP Reno看起来做的不够平滑,恢复的不够迅速,但相比它的前辈直接将窗口腰斩为1,它也做的足够好了。
为什么选择AIMD:
实际应用中需要考虑的基本参数:我们希望最大化链路的利用率(运营商的角度),尽量公平的分享链路利用率(用户),并且网络也不会因过度适用而崩溃(干活的牛马)。 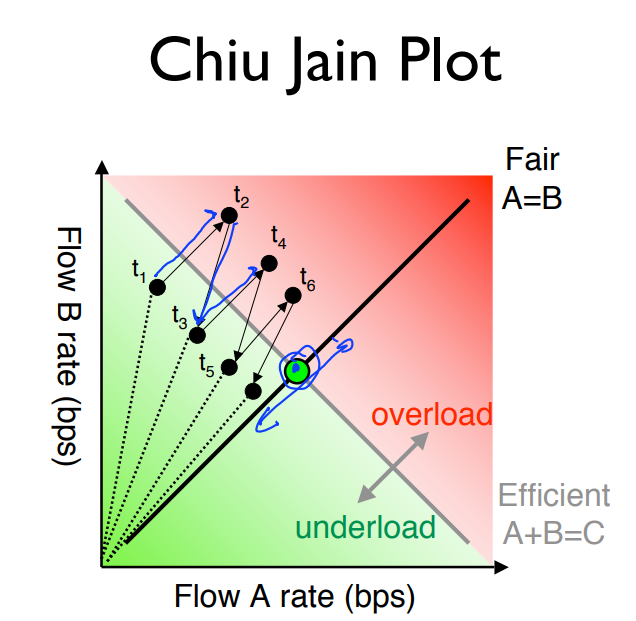
我们来解释一下为什么AIMD有助于达到我们的目标,以及为什么最后的工作状态点会趋于中心的最佳工作点。在网络拥塞未发生时,所有流都处于加性增的阶段,他们一起小心翼翼的向前探索寻找网络拥塞的临界点。直到拥塞发生时,每个流都会受影响然后乘性减。当然,在乘性减的过程中,速率更高的流会被迫放弃更多的带宽(如图中的B),所以,整个系统会自动地趋向公平。如图中所画地那样,最后,网络会在中心点附近振荡。这其实也体现出了最大最小公平原则,虽然我不明白哪里体现了,但是至少看着挺公平的。