网站制作 p雏鸟app网站推广

有标准答案的评估(选择题)
评估语言模型能力的基本思路是准备输入和标准答案,比较不同模型对相同输入的输出
由于AI答题有各种各样答案,因此现在是利用选择题考察。
有一个知名的选择题的基准叫做Massive Multitask Language Understanding (MMLU),里面收集了上万题的选择题
那它的题目涵盖各式各样不同的学科
选择题评估的详细案例与挑战

一、输出形式的挑战
- 语言模型可以生成任何形式的输出,这导致评估正确性变得复杂
- 简单匹配方法的局限性:
- 如果模型输出"答案是B",应该判定为正确吗?
- 如果编写程序检测输出中是否含有"B"字符,但模型回答"根据计算我认为是1,这个B选项的答案是1",如何判定?
二、 限制输出的问题
- 限制语言模型只能输出选项字母的方法:
- 告诉模型只能输出选项,不能输出其他内容
- 输出其他内容则判定为错误
- 这种评估方式的局限性:
- 这不是在测试模型解决问题的能力
- 而是在测试模型理解和遵循指令的能力
- 如果模型解释了选择理由,却被判为错误,这不能反映其真正能力
三、 概率分布评估方法及其问题
- 基于概率分布的评估:
- 直接查看ABCD四个选项的概率分布
- 选择概率最高的选项作为模型的答案
- 实际案例的困境:
- 如果模型输出的概率分布中,B选项在ABCD中概率最高
- 但数字"1"的概率比所有选项都高
- 这种情况应判定为正确还是错误?
- 两种解读:
- 正确解读:仅考虑ABCD选项,B概率最高,故正确
- 错误解读:模型真正想回答的是数字"1"而非选项B
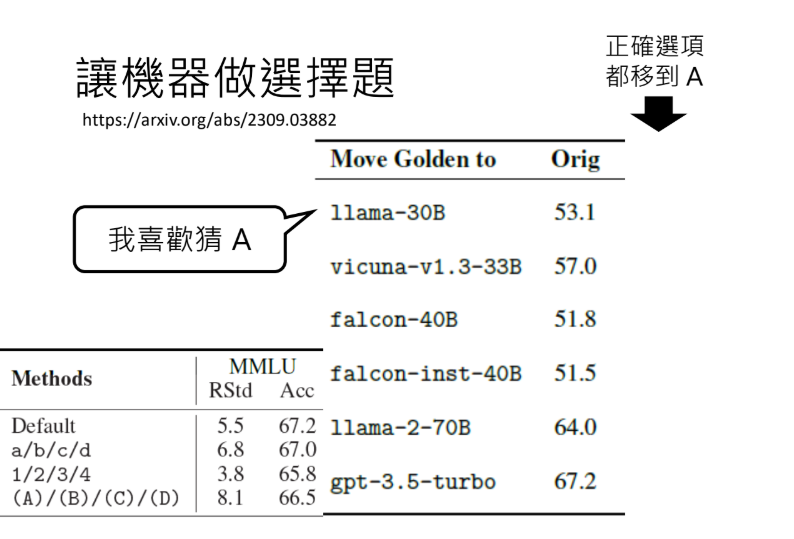
四、选项位置对评估结果的影响
- MMLU基准测试中的实验:
- 原始测试中GPT-3.5表现最好
- 将所有正确答案移至A选项后,Llama-30B性能突然成为第一
- 原因:Llama-30B在不确定时倾向于选A
- 将正确答案移至BCD也会产生类似影响
无标准答案任务的评估
特定任务评估
- 翻译和摘要等任务没有唯一标准答案
- 翻译评估常用BLEU,摘要评估常用ROUGE
- 这些指标只要求部分匹配标准答案
- 这些自动评估指标存在局限性
人类评估
Chatbot Arena是一个由人类评判语言模型的平台
- 用户可比较两个随机分配的模型对同一问题的回答
- 平台维护实时更新的排行榜
缺点是:人类评估资源消耗大
使用语言模型进行评估
- MT-Bench使用GPT-4评估其他语言模型
- MT-Bench包含80道没有标准答案的问题
- MT-Bench与Chatbot Arena的相关性高(Spearman相关系数0.94)
语言模型评估可能存在偏见(如偏好长答案)
Alpaca Evaluation考虑输出长度因素后,与Chatbot Arena的相关性提高
评估任务的多样性
- 早期评估使用少量任务(8-9个)
- 随着发展,评估任务数量增加:FLAN、CrossFit(160个任务)、Big-Bench(200+任务)、Natural Instruction(1600个任务)
特定能力评估
- 大海捞针测试(Needle in a Haystack)评估长文本理解能力:
- 在长文本中插入特定信息,测试模型是否能找到
- GPT-4在128K tokens的长文本中,可能会漏掉文本前10%-50%位置的信息
- Claude的长文本阅读能力在使用特定prompt后显著提升
评估的其他维度
- 除了能力外,还应考虑价格、硬件需求等因素
- 能力相近的模型可能价格差异很大
其他任务的测试
-
文本阅读测试:大海捞针测试:
- 在长文本不同位置插入"在旧金山最好的事情是…"的信息
-
抽象理解能力:Emoji Movie任务:从Big-Bench中选出的任务,要求模型根据表情符号猜电影名称,如:
- 🐰🦊🚔🏙️ = 动物方程式(Zootopia)
- 🤠❤️🤠 = 断背山(Brokeback Mountain)
-
逻辑理解:西洋棋测试:要求语言模型理解棋谱并找出能将军的走法,大模型能提出符合规则但不一定正确的答案,小模型甚至不知道如何下棋。
-
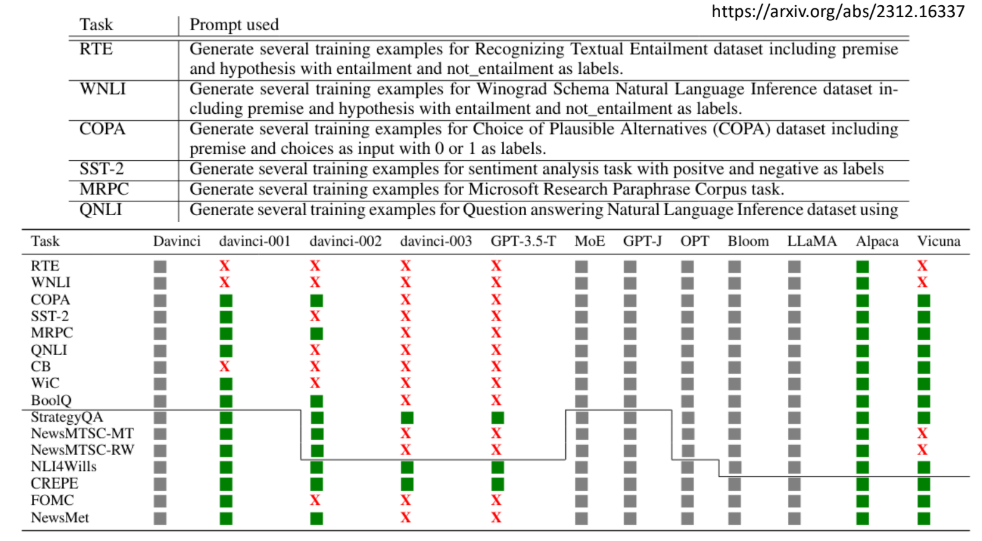
模型记忆测试:直接要求模型输出RTE等数据集的训练数据,GPT-3.5能够成功输出多个数据集的内容。
Benchmark的局限性
Benchmark数据是公开的,可能被模型训练时"偷看"
有实验直接让模型输出各Benchmark的训练数据,证明模型确实"见过"这些数据(提示词:给我RTE的训练资料等等,如下图)