第十八周周报
文章目录
- 摘要
- Abstract
- Theory behind GAN
- GAN训练的小技巧(Tips for GAN)
- 总结
摘要
本周学习了GAN的基本理论,其训练过程可视为生成器与判别器之间的动态博弈:生成器致力于生成足以乱真的数据,而判别器则力求精准分辨真实数据与生成数据;二者这种相互对抗与竞争的关系使得GAN的训练极具挑战性,为此也催生出了如WGAN、Conditional GAN和CycleGAN等一系列旨在优化训练过程的方法。
Abstract
This week, I learned the basic theory of Gan, and its training process can be seen as a dynamic game between the generator and the discriminator: the generator is committed to generating enough false data, while the discriminator strives to accurately distinguish the real data from the generated data; This relationship of confrontation and competition between the two makes the training of Gan very challenging. Therefore, a series of methods to optimize the training process, such as wgan, conditional Gan and cyclegan, have also emerged.
Theory behind GAN
将Distribution中sample出来的向量丢到generator里面,会产生一个比较复杂的Distribution PG,而真正的data也形成了一个Distribution Pdata,我们希望 PG和Pdata越接近越好。
我们这里举一个例子加以理解:假设输入分布、输出分布、真实数据的分布都是一维的;输入分布的数据主要集中在中间、输出分布可能向两边分散,而真实数据可能更加极端地分散在两端。
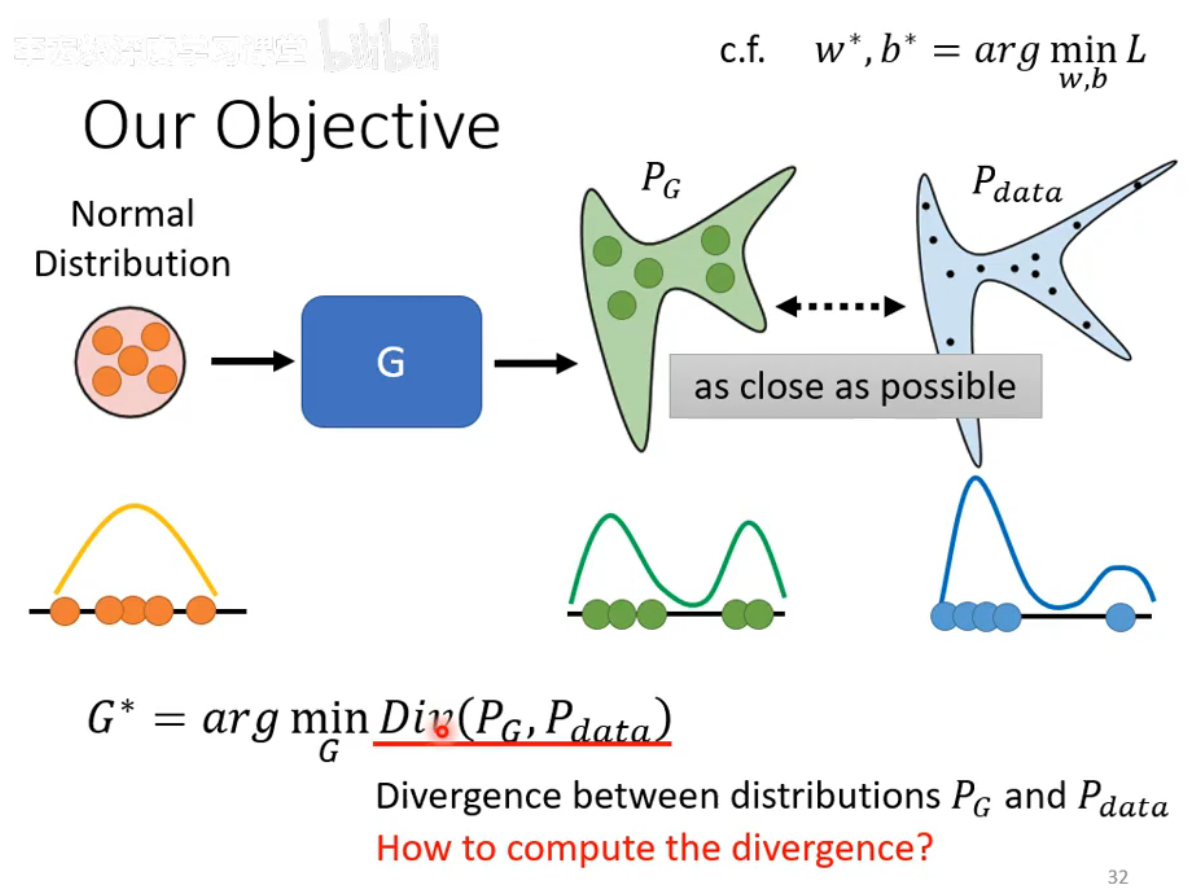
Divergence
Div( PG,Pdata)即Divergence,是衡量两个Distribution相似度的一个major,当Divergence的值越大就代表这两个Distribution越不像。Divergence的值越小就代表这两个Distribution越相近。
那么我们应该如何计算divergence?
尽管我们不知道Pg和Pdata的分布,我们可以从中sample出来。

对于真实的数据Pdata从图片库里sample一些出来就可以得到了,而 PG的sample是可以通过Generaator产生得到的。
通过sample就可以计算Divergence,这就需要依靠Discriminator的力量了,Discriminator 就是要尽量把从PG里sample的数据与从Pdata里sample的数据分开。根据从 PG和Pdata中sample出来的data训练一个Discriminator,训练的目标就是看到real data就给它高分,看到generation data就给低分,也就是要分辨一个图片是真的图还是生成的图。
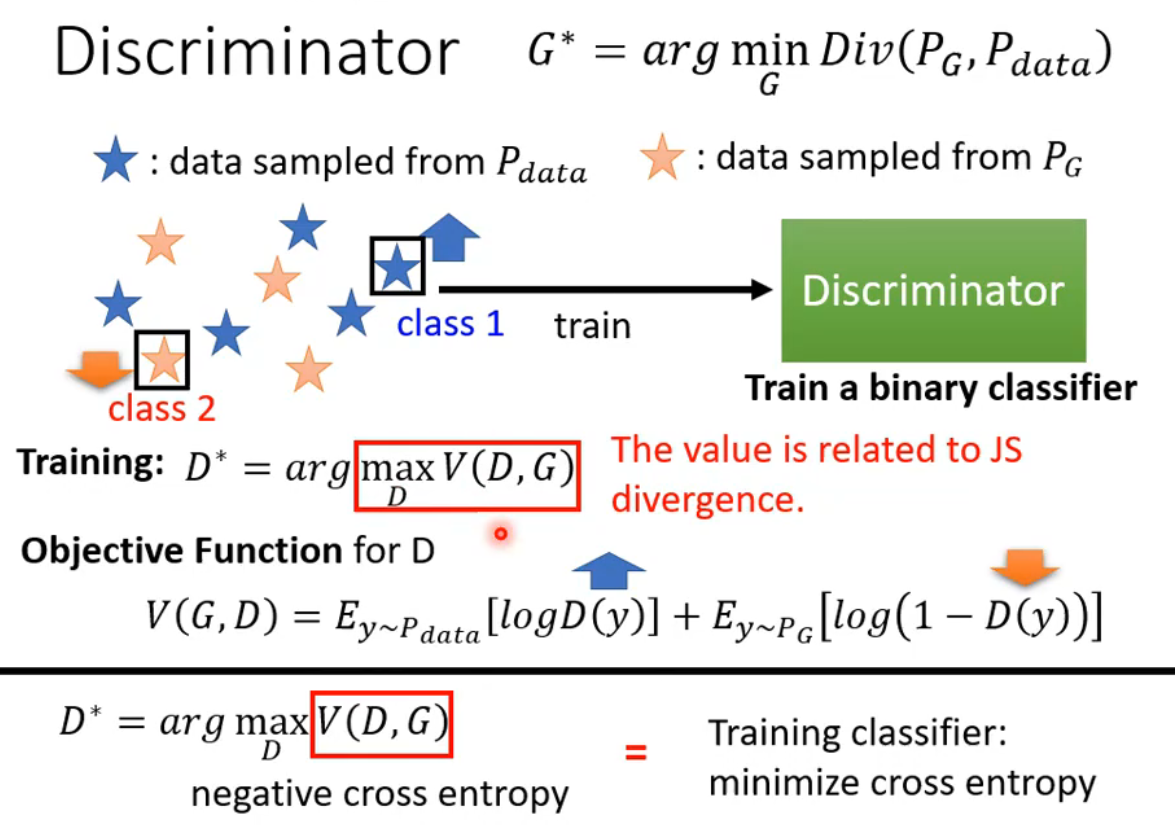
maxV(D,G)与JS divergence是有关的。
下面通过例子从直观上来理解为什么Objective Function的最大值是和Divergence有关的,当 PG和Pdata两组sample出来的数据之间的divergence很小的时候,Discriminator 很难分辨两者,因此打的分数不准确,则maxV(G,D)的值小。反之当divergence很大的时候,Discriminator 很容易分辨两者,因此打的分数比较准确,则maxV(G,D)的值大。
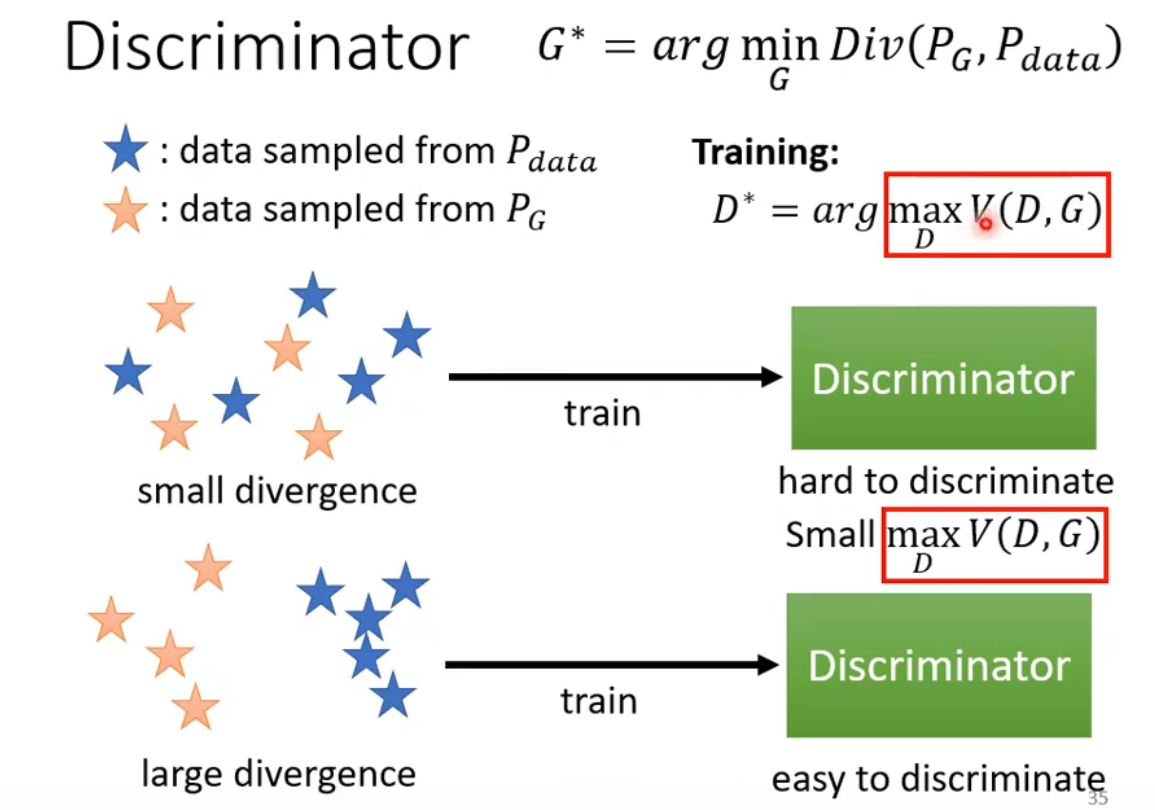
训练Discriminator的目标就是分辨出真正的Image和生成的Image,即使V(G,D)的值达到最大,而Generator的目标就是让生成的图片瞒过Discriminator,因此它的目标是让V(G,D)的值越小越好,因此G*等式右边既有min又有max。

GAN训练的小技巧(Tips for GAN)
为什么JS divergence不适合?
PG和Pdata有一个关键特性就是重叠部分非常少,从数据本身特性来说,PG和Pdata都是要产生图片,而图片就是在高维空间中一条低维的流行,以二维空间为例,那么图片的分布就是一条直线,因此重叠几乎可以忽略。另一种解释就是尽管PG和Pdata之间有重叠,但是我们在sample的时候sample的点不够多,不够密,会使我们认为PG和Pdata之间没有重叠。

JS divergence有一个特性就是两个分布没有重叠,那么算出来的divergence永远都是log2。为了解决这一问题,我们采用一种新的训练方式:WGAN。
Wasserstein distance就是将P推着移动到Q的平均距离,也就是图中的d
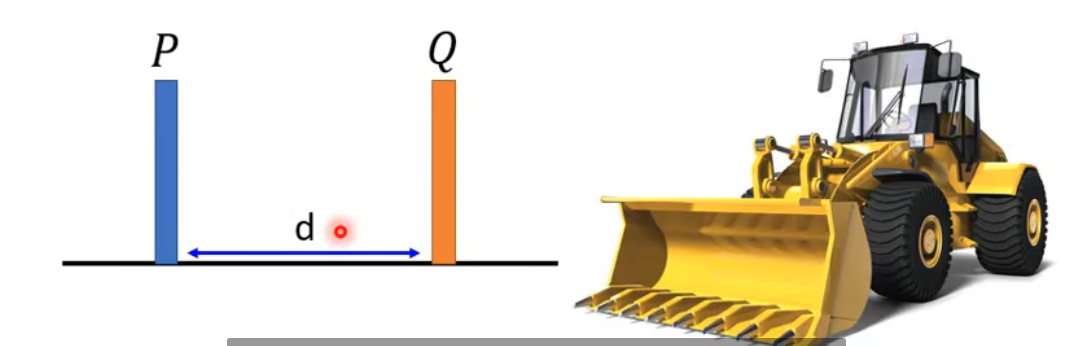
有P——>Q的方法有很多,自然移动的距离也不相同,穷举所有把P变成Q的方法,我们取平均移动距离最短的distance作为Wasserstein distance。当我们使用Wasserstein distance时,
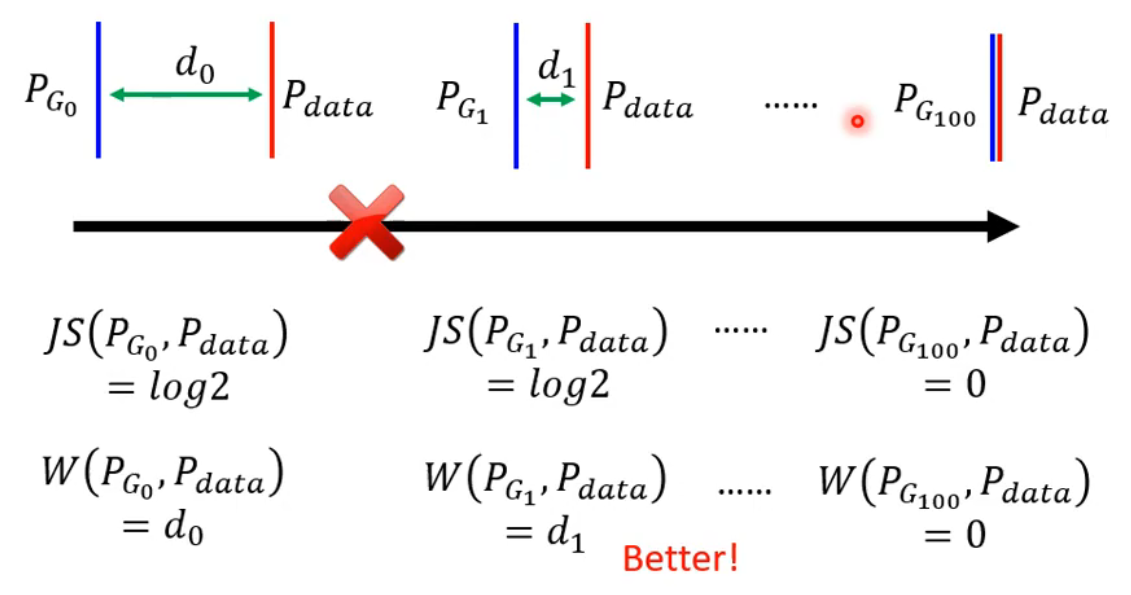
用Wasserstein distance代替JS divergence的GAN 就叫做WGAN。
w distance的计算如下:
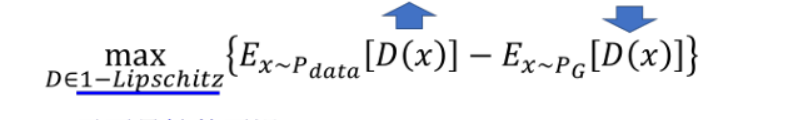
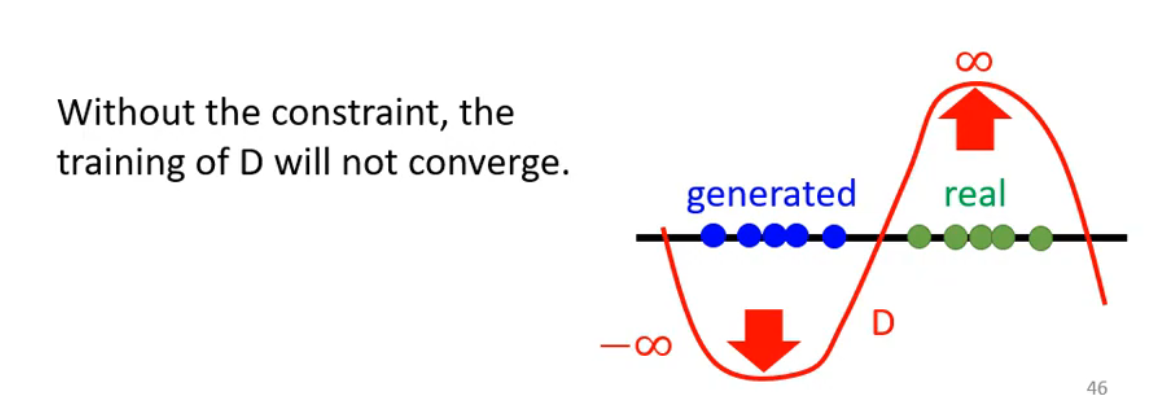
D必须是一个足够平滑的Function。当PG和Pdata没有重叠的时候,但两者相距很近的时候,要在Pdata上得分很高,就会取到正无穷,在PG取得分低就会到负无穷,那这个function的变化就会很大,D的训练就没办法收敛,因此在两组数据没有重叠的情况下,算出来的max值就会无限大。
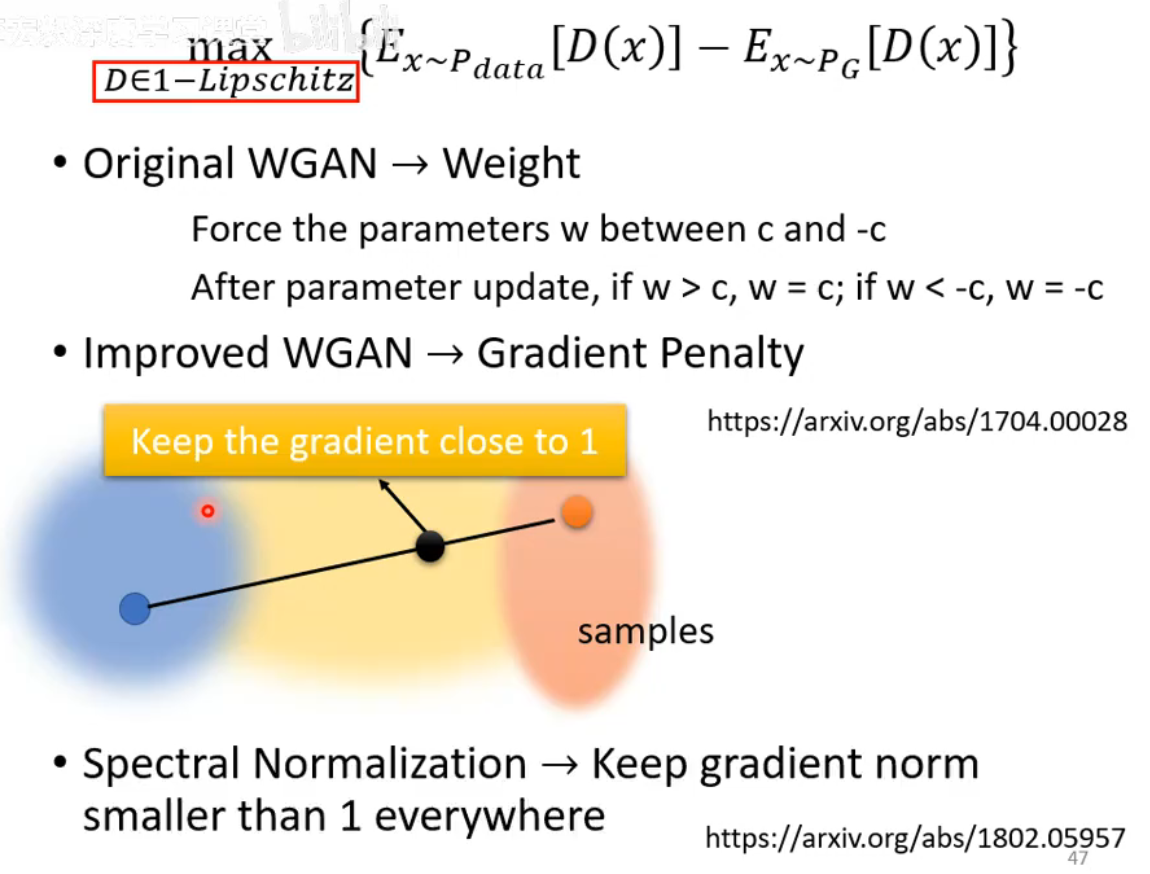
在Imprived WGAN中提到了Gradient Penalty的方法,在real data的分布与fake data的分布中各取sample,然后在两袋奶现在也有很多其他1-lipschitz的方法比谱归一化Spectral Normalization就是很好的例子,其有效的让梯度在各个地方都小于1防止梯度消失。虽然已经有了WGAN,并不意味着GAN就很好训练了,依旧很难训练。因为Generaator与Discriminator两个network是棋逢对手的关系,需要共同成长,一旦一个停止进步了,另一个也跟着再进步了。
总结
本周的学习让我对GAN的理论有了更深入的认识,为后续研究和应用奠定了基础;GAN的训练过程包含判别器与生成器的交替训练,其中生成器致力于生成足以以假乱真的样本,而判别器则力求准确区分真实样本与生成样本,后续我将继续学习GAN相关的内容。