【MySQL|第二篇】基础篇下
四、约束
4.1 概述
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确、有效性和完整性。
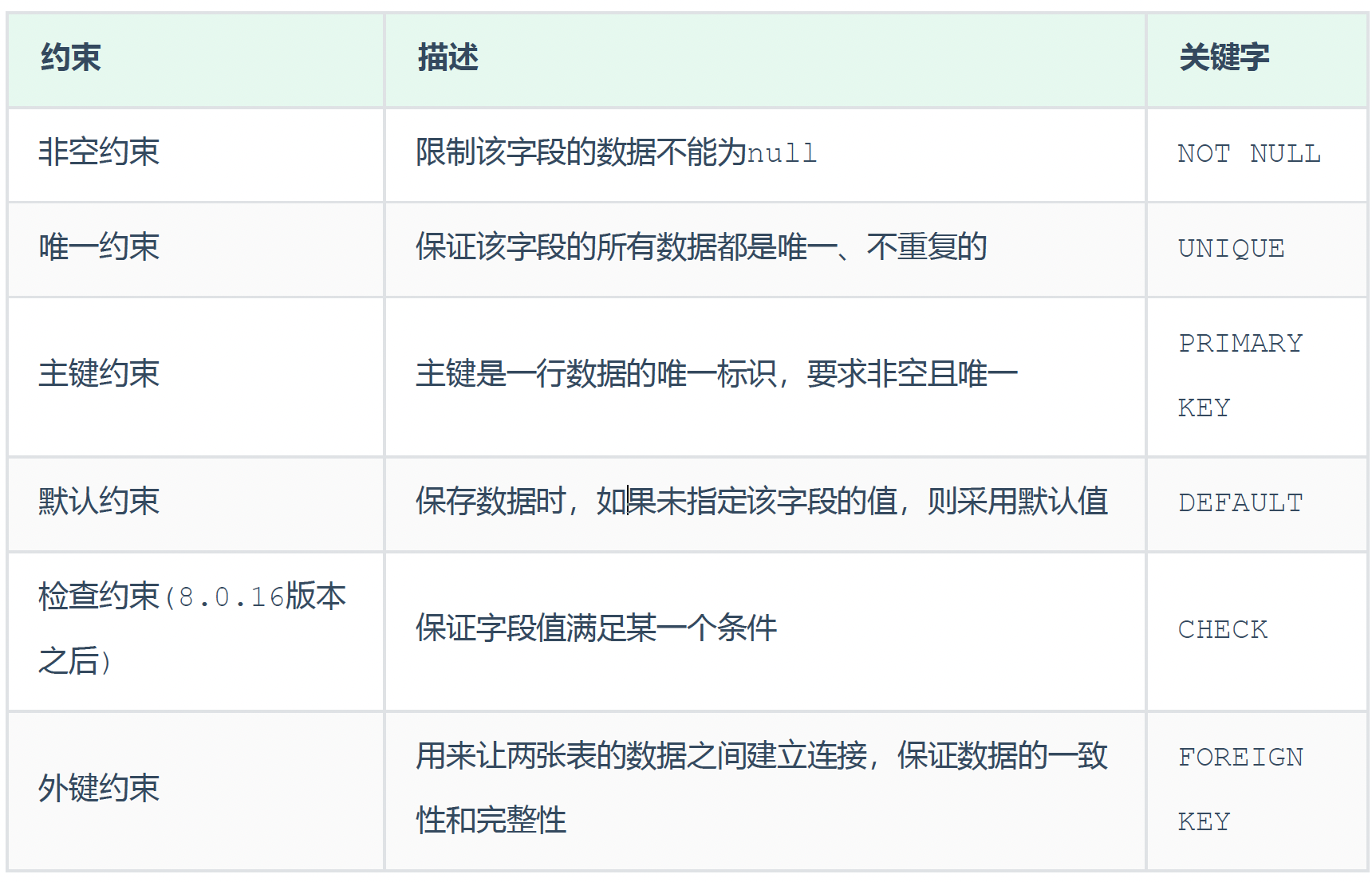
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
4.2 约束演示
案例需求: 根据需求,完成表结构的创建。需求如下:
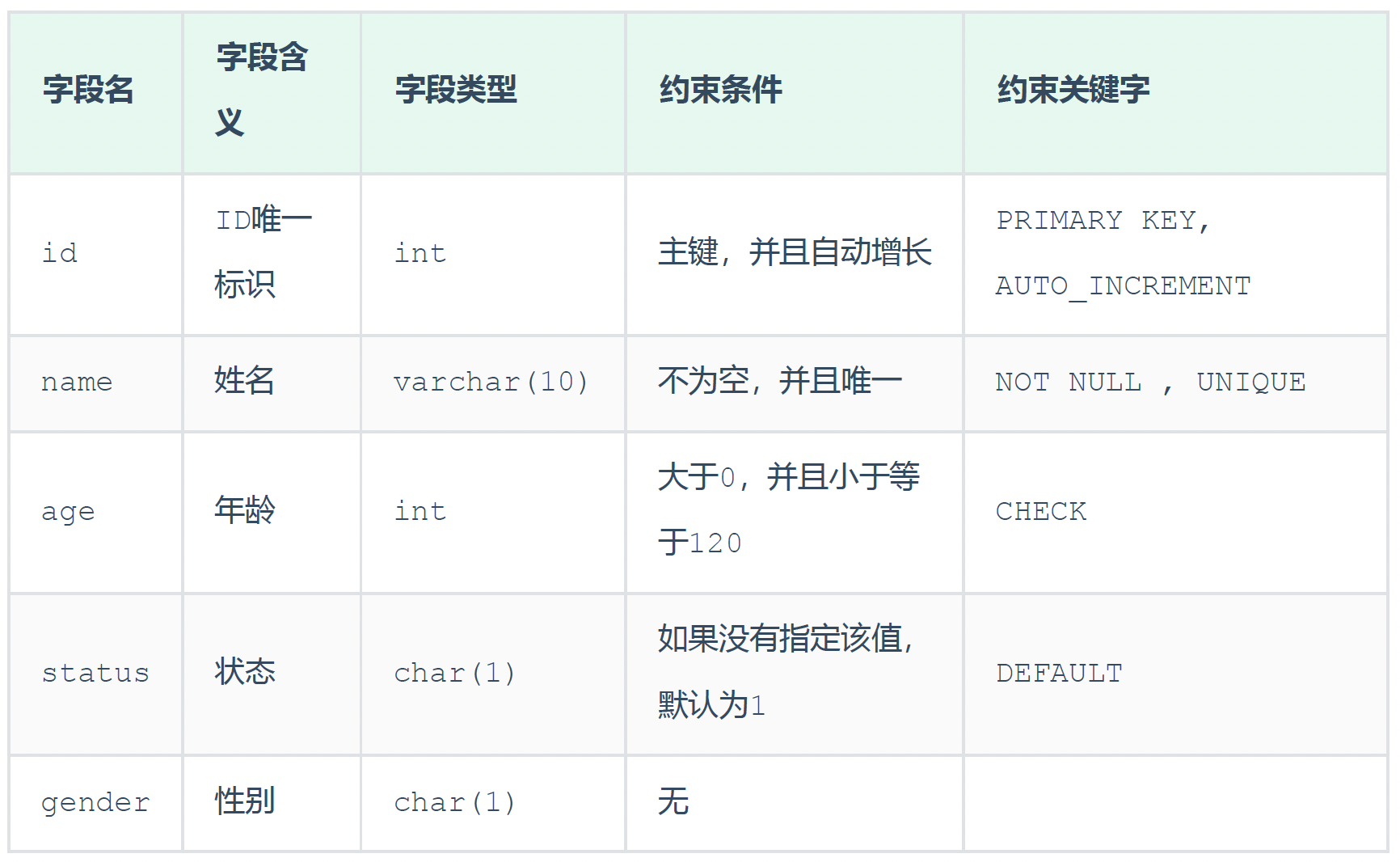
对应的建表语句为:
CREATE TABLE tb_user(id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识',name varchar(10) NOT NULL UNIQUE COMMENT '姓名' ,age int check (age > 0 && age <= 120) COMMENT '年龄' ,status char(1) default '1' COMMENT '状态',gender char(1) COMMENT '性别'
);
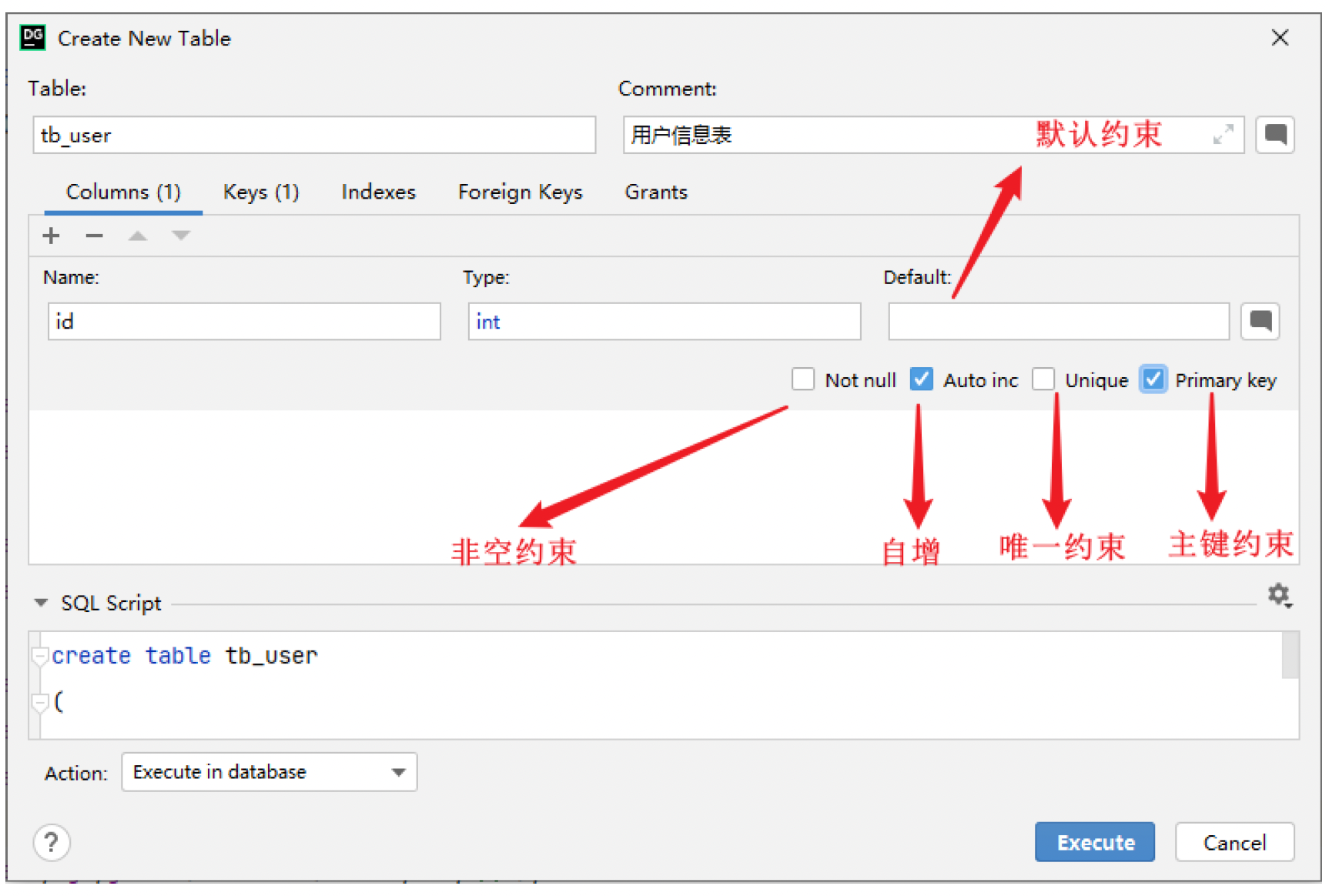
4.3 外键约束
4.3.1 介绍
外键:用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。
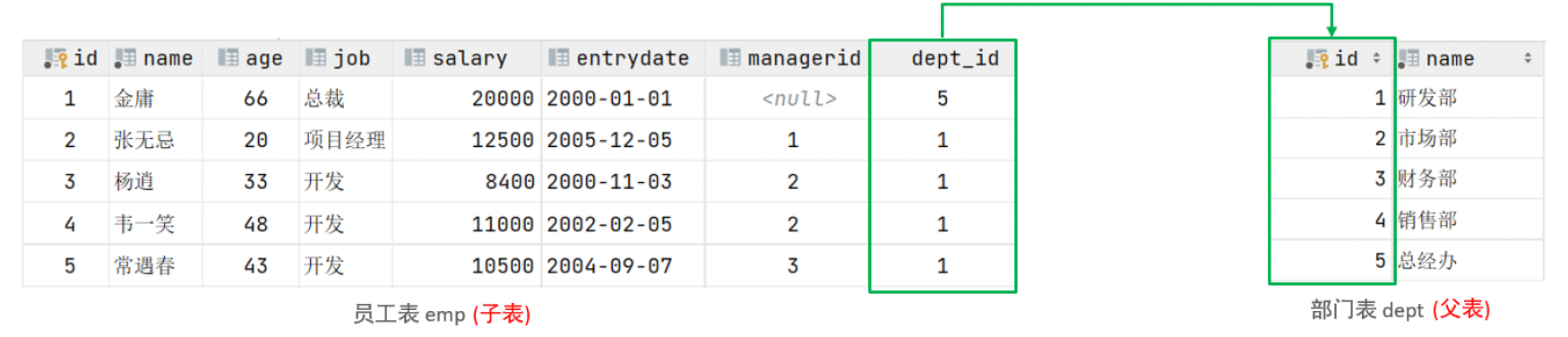
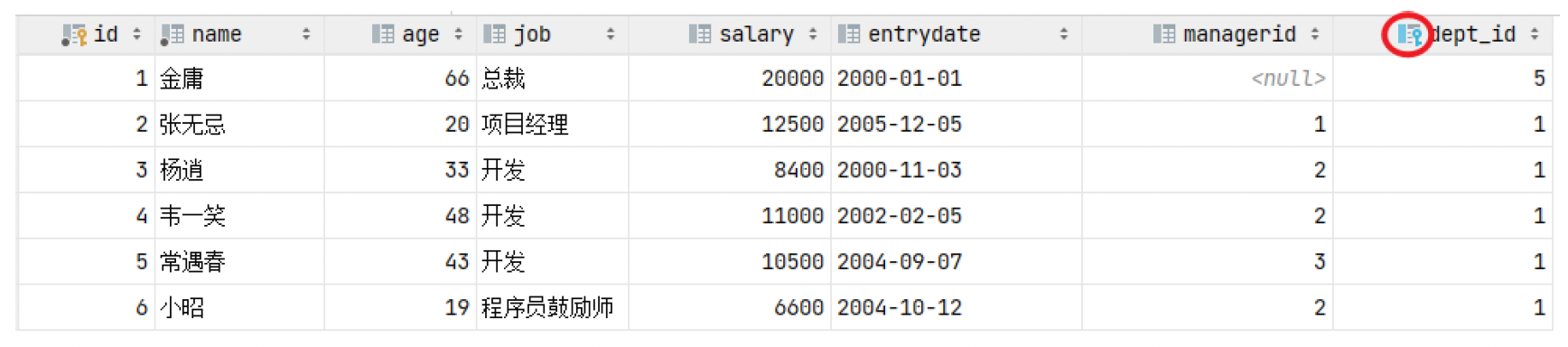
左侧的emp表是员工表,里面存储员工的基本信息,包含员工的ID、姓名、年龄、职位、薪资、入职日期、上级主管ID、部门ID,在员工的信息中存储的是部门的ID dept_id,而这个部门的ID是关联的部门表dept的主键id,那emp表的dept_id就是外键,关联的是另一张表的主键。
注意:目前上述两张表,只是在逻辑上存在这样一层关系;在数据库层面,并未建立外键关联,所以是无法保证数据的一致性和完整性的。
不存在外键时:
我们可以做一个测试,删除id为1的部门信息。结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
4.3.2 语法
1). 添加外键
CREATE TABLE 表名(字段名 数据类型,...[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名)
);
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
案例:
为emp表的dept_id字段添加外键约束,关联dept表的主键id。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
添加了外键约束之后,我们再到dept表(父表)删除id为1的记录,然后看一下会发生什么现象。 此时将会报错,不能删除或更新父表记录,因为存在外键约束。
2). 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
案例:
删除emp表的外键fk_emp_dept_id。
alter table emp drop foreign key fk_emp_dept_id;
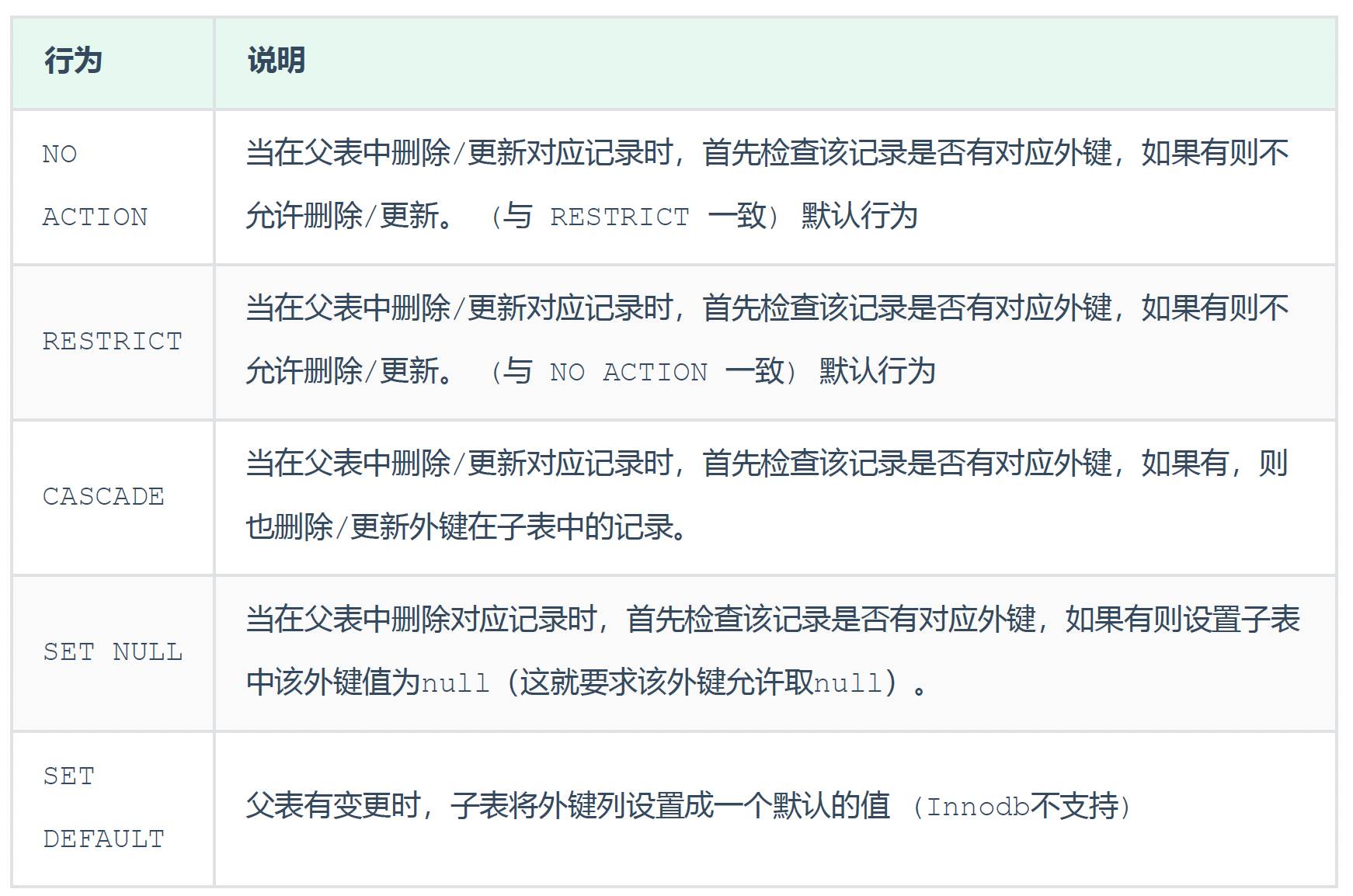
4.3.3 删除/更新行为
添加了外键之后,再删除父表数据时产生的约束行为,我们就称为删除/更新行为。具体的删除/更新行为有以下几种:
具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
演示如下:
由于NO ACTION 是默认行为,我们前面语法演示的时候,已经测试过了,就不再演示了,这里我们再演示其他的两种行为:CASCADE、SET NULL。
1). CASCADE
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
A. 修改父表id为1的记录,将id修改为6
我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
注意:在一般的业务系统中,不会修改一张表的主键值。
B. 删除父表id为6的记录
我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
2). SET NULL
在进行测试之前,我们先需要删除上面建立的外键 fk_emp_dept_id。然后再通过数据脚本,将emp、dept表的数据恢复了。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null ;
接下来,我们删除id为1的数据,我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
五、多表查询
之前讲解的查询都是单表查询
5.1 多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结
构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
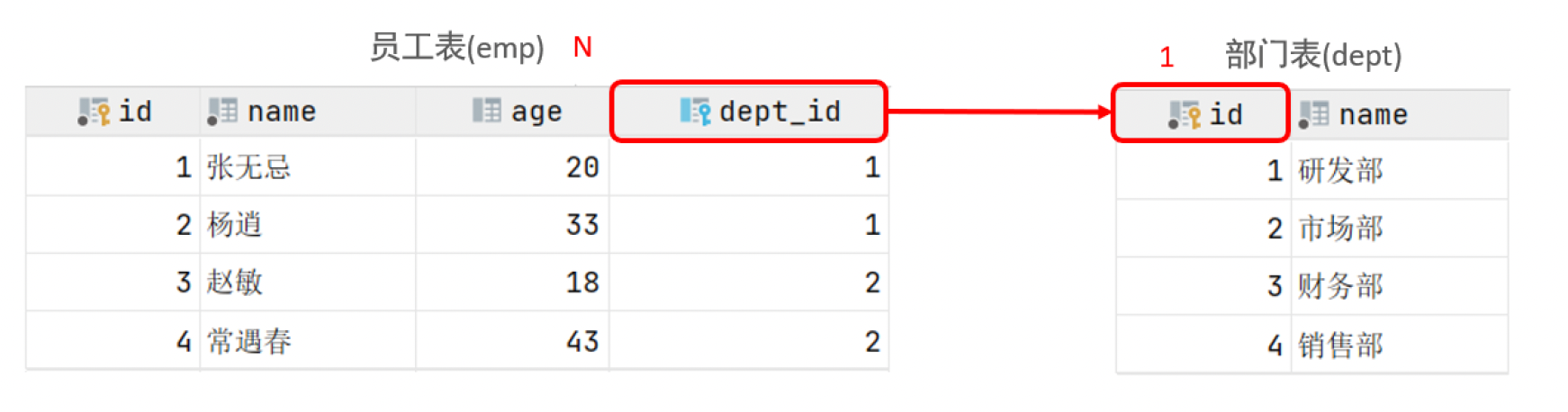
5.1.1 一对多
案例: 部门 与 员工的关系
关系: 一个部门对应多个员工,一个员工对应一个部门
实现: 在多的一方建立外键,指向一的一方的主键
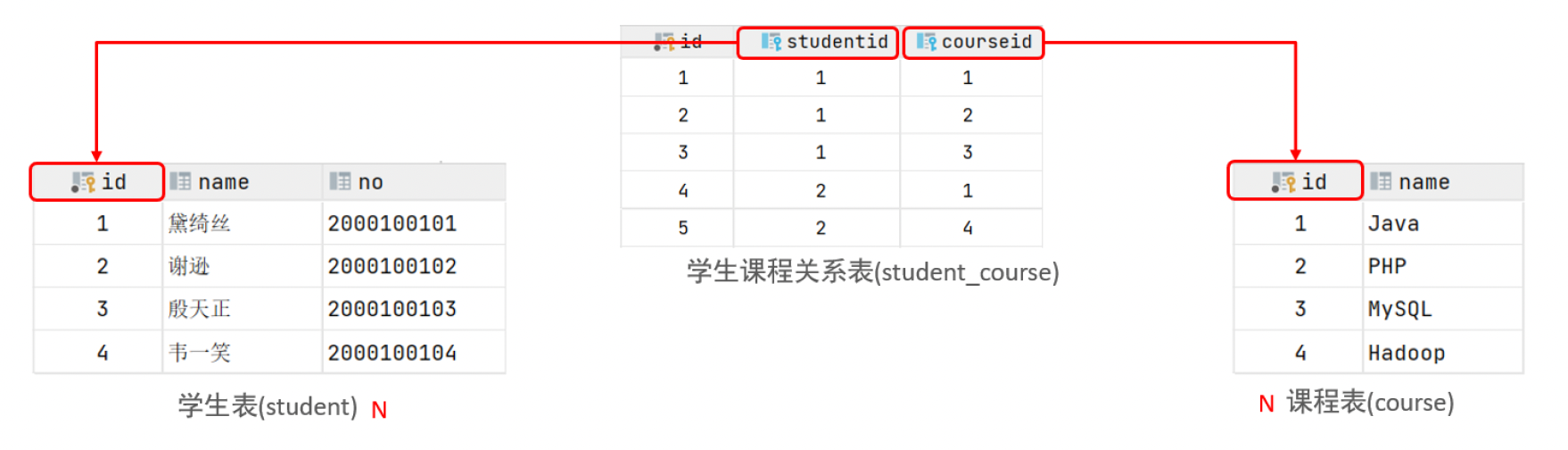
5.1.2 多对多
案例: 学生 与 课程的关系
关系: 一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现: 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
create table student(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',no varchar(10) comment '学号'
) comment '学生表';
insert into student values (null, '黛绮丝', '2000100101'),(null, '谢逊', '2000100102'),(null, '殷天正', '2000100103'),(null, '韦一笑', '2000100104');create table course(id int auto_increment primary key comment '主键ID',name varchar(10) comment '课程名称'
) comment '课程表';
insert into course values (null, 'Java'), (null, 'PHP'), (null , 'MySQL') , (null, 'Hadoop');create table student_course(id int auto_increment comment '主键' primary key,studentid int not null comment '学生ID',courseid int not null comment '课程ID',constraint fk_courseid foreign key (courseid) references course (id),constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';
insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2), (null,2,3),(null,3,4);
5.1.3 一对一
案例: 用户 与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
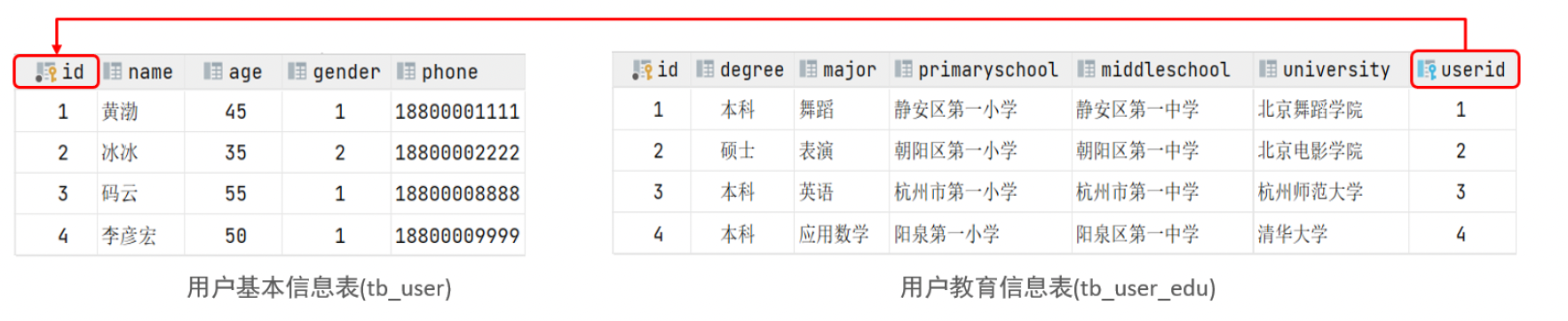
create table tb_user(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '1: 男 , 2: 女',phone char(11) comment '手机号'
) comment '用户基本信息表';create table tb_user_edu(id int auto_increment primary key comment '主键ID',degree varchar(20) comment '学历',major varchar(50) comment '专业',primaryschool varchar(50) comment '小学',middleschool varchar(50) comment '中学',university varchar(50) comment '大学',userid int unique comment '用户ID',constraint fk_userid foreign key (userid) references tb_user(id)
) comment '用户教育信息表';insert into tb_user(id, name, age, gender, phone) values(null,'黄渤',45,'1','18800001111'),(null,'冰冰',35,'2','18800002222'),(null,'码云',55,'1','18800008888'),(null,'李彦宏',50,'1','18800009999');insert into tb_user_edu(id, degree, major, primaryschool, middleschool, university, userid) values(null,'本科','舞蹈','静安区第一小学','静安区第一中学','北京舞蹈学院',1),(null,'硕士','表演','朝阳区第一小学','朝阳区第一中学','北京电影学院',2),(null,'本科','英语','杭州市第一小学','杭州市第一中学','杭州师范大学',3),(null,'本科','应用数学','阳泉第一小学','阳泉区第一中学','清华大学',4);
5.2 多表查询概述
5.2.1 数据准备
1). 删除之前 emp, dept表的测试数据
2). 执行如下脚本,创建emp表与dept表并插入测试数据
-- 创建dept表,并插入数据
create table dept(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '部门名称'
)comment '部门表';
INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'), (6, '人事部');-- 创建emp表,并插入数据
create table emp(id int auto_increment comment 'ID' primary key,name varchar(50) not null comment '姓名',age int comment '年龄',job varchar(20) comment '职位',salary int comment '薪资',entrydate date comment '入职时间',managerid int comment '直属领导ID',dept_id int comment '部门ID'
)comment '员工表';
-- 添加外键
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES(1, '金庸', 66, '总裁',20000, '2000-01-01', null,5),(2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1),(3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1),(4, '韦一笑', 48, '开发',11000, '2002-02-05', 2,1),(5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1),(6, '小昭', 19, '程序员鼓励师',6600, '2004-10-12', 2,1),(7, '灭绝', 60, '财务总监',8500, '2002-09-12', 1,3),(8, '周芷若', 19, '会计',48000, '2006-06-02', 7,3),(9, '丁敏君', 23, '出纳',5250, '2009-05-13', 7,3),(10, '赵敏', 20, '市场部总监',12500, '2004-10-12', 1,2),(11, '鹿杖客', 56, '职员',3750, '2006-10-03', 10,2),(12, '鹤笔翁', 19, '职员',3750, '2007-05-09', 10,2),(13, '方东白', 19, '职员',5500, '2009-02-12', 10,2),(14, '张三丰', 88, '销售总监',14000, '2004-10-12', 1,4),(15, '俞莲舟', 38, '销售',4600, '2004-10-12', 14,4),(16, '宋远桥', 40, '销售',4600, '2004-10-12', 14,4),(17, '陈友谅', 42, null,2000, '2011-10-12', 1,null);
5.2.2 概述
多表查询就是指从多张表中查询数据。
原来查询单表数据,执行的SQL形式为:select * from emp;
那么我们要执行多表查询,就只需要使用逗号分隔多张表即可,如: select * from emp , dept
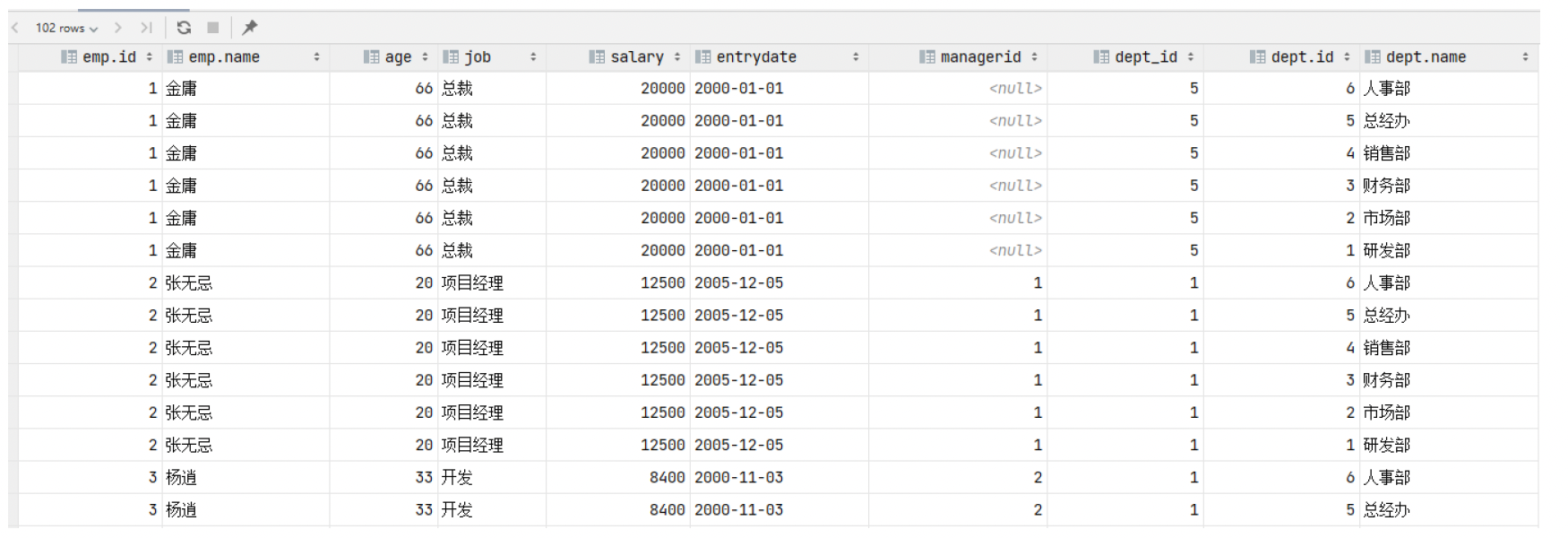
此时,我们看到查询结果中包含了大量的结果集,总共102条记录,而这其实就是员工表emp所有的记录(17) 与 部门表dept所有记录(6) 的所有组合情况,这种现象称之为笛卡尔积。接下来,就来简单介绍下笛卡尔积。
笛卡尔积: 笛卡尔乘积是指在数学中,两个集合 A集合 和 B集合 的所有组合情况。
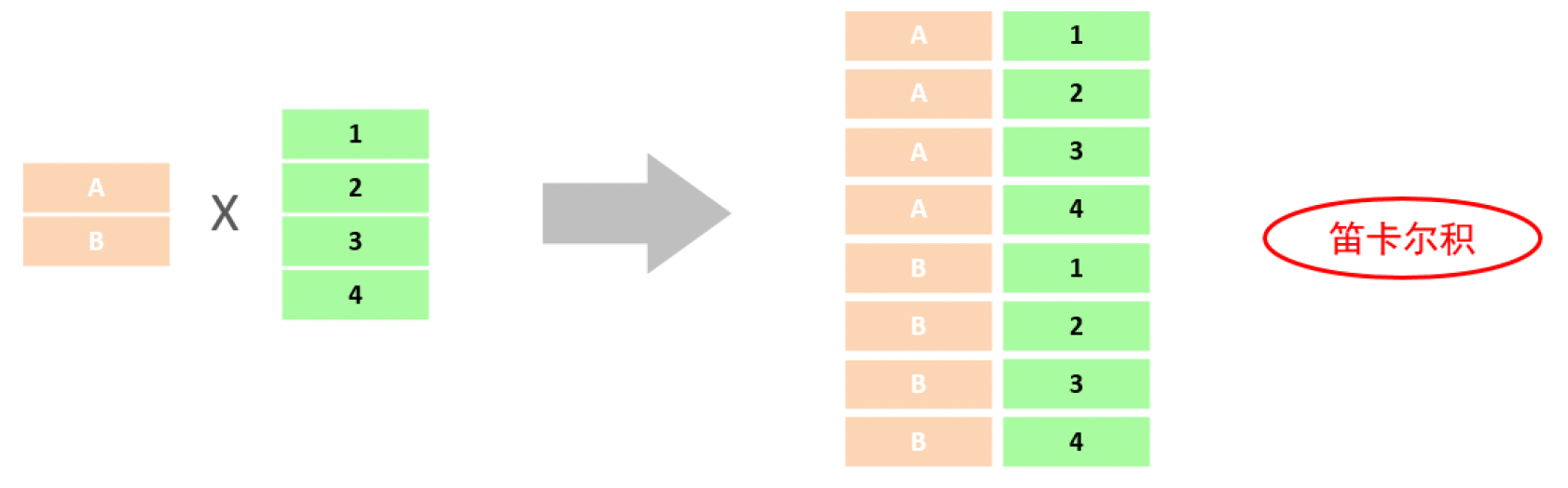
而在多表查询中,我们是需要消除无效的笛卡尔积的,只保留两张表关联部分的数据。
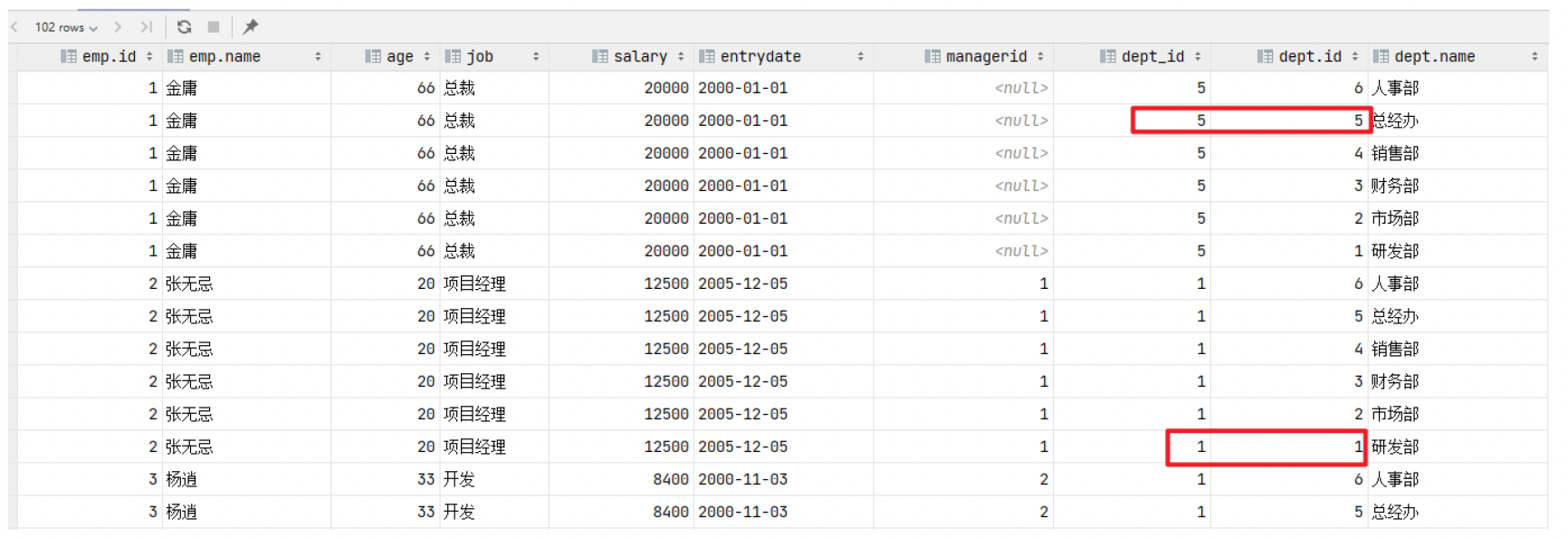
在SQL语句中,如何来去除无效的笛卡尔积呢? 我们可以给多表查询加上连接查询的条件即可。
select * from emp , dept where emp.dept_id = dept.id;
而由于id为17的员工,没有dept_id字段值,所以在多表查询时,根据连接查询的条件并没有查询到。
5.2.3 分类
- 连接查询
- 内连接:相当于查询A、B交集部分数据
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
- 子查询
5.3 内连接
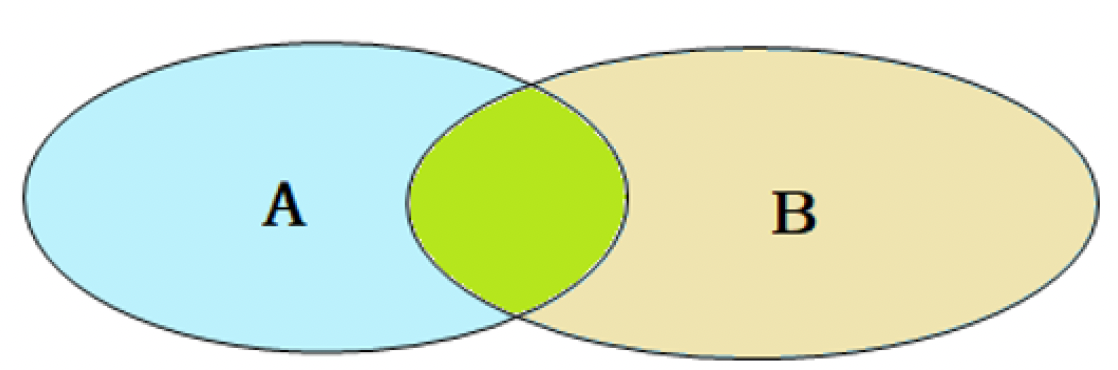
内连接查询的是两张表交集部分的数据。(也就是绿色部分的数据)
内连接的语法分为两种: 隐式内连接、显式内连接。先来学习一下具体的语法结构。
1). 隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
2). 显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;
案例:
A. 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
表结构: emp , dept
连接条件: emp.dept_id = dept.id
select emp.name , dept.name from emp , dept where emp.dept_id = dept.id ;
-- 为每一张表起别名,简化SQL编写
select e.name,d.name from emp e , dept d where e.dept_id = d.id;
B. 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现) — INNER JOIN … ON …
select e.name, d.name from emp e inner join dept d on e.dept_id = d.id;
-- 为每一张表起别名,简化SQL编写
select e.name, d.name from emp e join dept d on e.dept_id = d.id;
表的别名:
①. tablea as 别名1 , tableb as 别名2 ;
②. tablea 别名1 , tableb 别名2 ;
注意事项:一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
5.4 外连接
外连接分为两种,分别是:左外连接 和 右外连接。具体的语法结构为:
1). 左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;
左外连接相当于查询表1(左表)的所有数据,当然也包含表1和表2交集部分的数据。
2). 右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
案例:
A. 查询emp表的所有数据, 和对应的部门信息
由于需求中提到,要查询emp的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件: emp.dept_id = dept.id
select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id;
select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
B. 查询dept表的所有数据, 和对应的员工信息(右外连接)
由于需求中提到,要查询dept表的所有数据,所以是不能内连接查询的,需要考虑使用外连接查询。
表结构: emp, dept
连接条件: emp.dept_id = dept.id
select d.*, e.* from emp e right outer join dept d on e.dept_id = d.id;
select d.*, e.* from dept d left outer join emp e on e.dept_id = d.id;
注意事项:
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中,表结构的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
5.5 自连接
5.5.1 自连接查询
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。我们先来学习一下自连接的查询语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;
而对于自连接查询,可以是内连接查询,也可以是外连接查询。
案例:
A. 查询员工 及其 所属领导的名字
表结构: emp
select a.name , b.name from emp a , emp b where a.managerid = b.id;
B. 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来
表结构: emp a , emp b
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id;
注意事项:
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底是哪一张表的字段。
5.5.2 联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A ...
UNION [ ALL ]
SELECT 字段列表 FROM 表B ....;
- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
- union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
案例:
A. 将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
当前对于这个需求,我们可以直接使用多条件查询,使用逻辑运算符 or 连接即可。 那这里呢,我们也可以通过union/union all来联合查询.
select * from emp where salary < 5000
union all
select * from emp where age > 50;
union all查询出来的结果,仅仅进行简单的合并,并未去重。
select * from emp where salary < 5000
union
select * from emp where age > 50;
union 联合查询,会对查询出来的结果进行去重处理。
注意:如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union all联合查询时,将会报错。
5.6 子查询
5.6.1 概述
1). 概念
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
2). 分类
-
根据子查询结果不同,分为:
A. 标量子查询(子查询结果为单个值)
B. 列子查询(子查询结果为一列)
C. 行子查询(子查询结果为一行)
D. 表子查询(子查询结果为多行多列) -
根据子查询位置,分为:
A. WHERE之后
B. FROM之后
C. SELECT之后
5.6.2 标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符:= <> > >= < <=
案例:
A. 查询 “销售部” 的所有员工信息
完成这个需求时,我们可以将需求分解为两步:
①. 查询 “销售部” 部门ID
select id from dept where name = '销售部';
②. 根据 “销售部” 部门ID, 查询员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');
B. 查询在 “方东白” 入职之后的员工信息
完成这个需求时,我们可以将需求分解为两步:
①. 查询 方东白 的入职日期
select entrydate from emp where name = '方东白';
②. 查询指定入职日期之后入职的员工信息
select * from emp where entrydate > (select entrydate from emp where name = '方东白');
5.6.3 列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
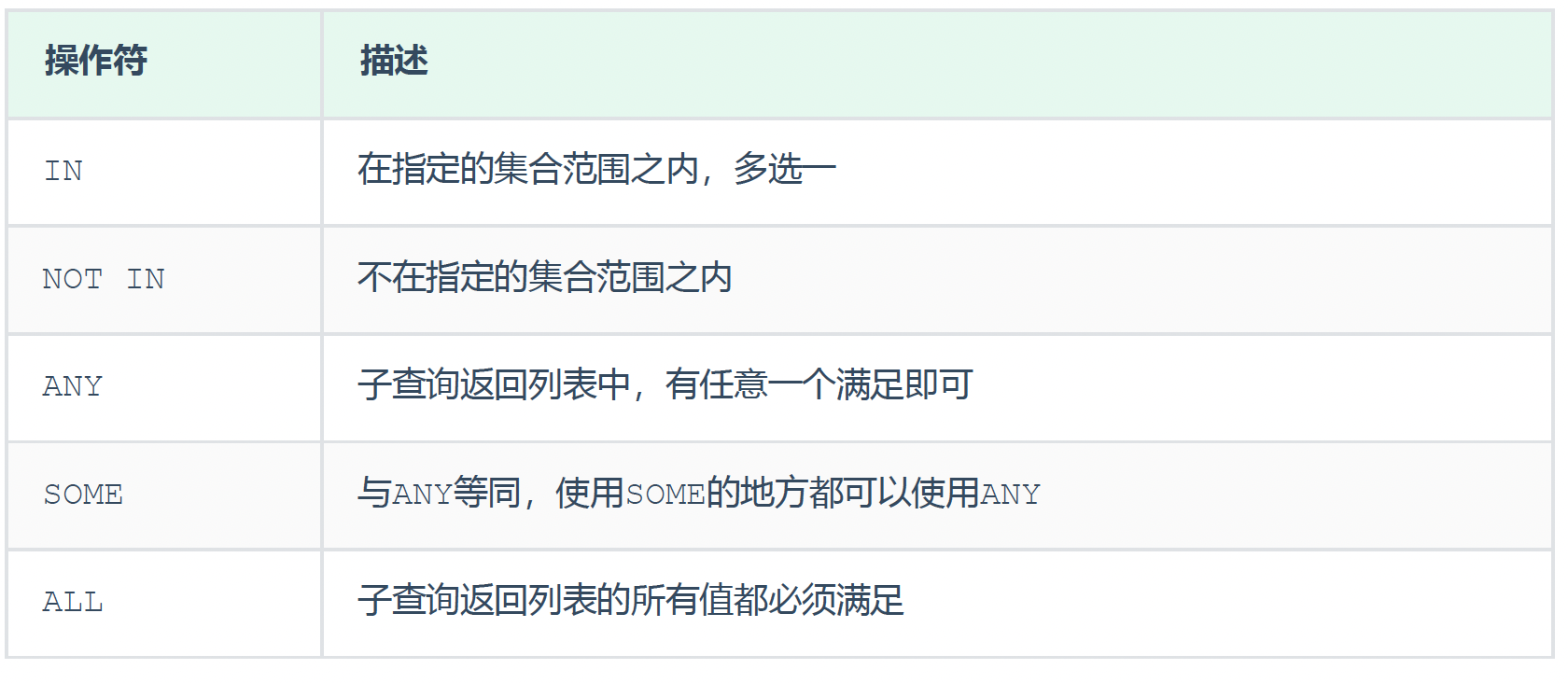
案例:
A. 查询 “销售部” 和 “市场部” 的所有员工信息
分解为以下两步:
①. 查询 “销售部” 和 “市场部” 的部门ID
select id from dept where name = '销售部' or name = '市场部';
②. 根据部门ID, 查询员工信息
select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部');
B. 查询比 财务部 所有人工资都高的员工信息
分解为以下两步:
①. 查询所有 财务部 人员工资
select id from dept where name = '财务部';
select salary from emp where dept_id = (select id from dept where name = '财务部');
②. 比 财务部 所有人工资都高的员工信息
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') );
C. 查询比研发部其中任意一人工资高的员工信息
分解为以下两步:
①. 查询研发部所有人工资
select salary from emp where dept_id = (select id from dept where name = '研发部');
②. 比研发部其中任意一人工资高的员工信息
select * from emp where salary > any ( select salary from emp where dept_id = (select id from dept where name = '研发部') );
5.6.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
A. 查询与 “张无忌” 的薪资及直属领导相同的员工信息 ;
这个需求同样可以拆解为两步进行:
①. 查询 “张无忌” 的薪资及直属领导
select salary, managerid from emp where name = '张无忌';
②. 查询与 “张无忌” 的薪资及直属领导相同的员工信息 ;
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌');
5.6.5 表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
案例:
A. 查询与 “鹿杖客” , “宋远桥” 的职位和薪资相同的员工信息
分解为两步执行:
①. 查询 “鹿杖客” , “宋远桥” 的职位和薪资
select job, salary from emp where name = '鹿杖客' or name = '宋远桥';
②. 查询与 “鹿杖客” , “宋远桥” 的职位和薪资相同的员工信息
select * from emp where (job,salary) in ( select job, salary from emp where name = '鹿杖客' or name = '宋远桥' );
B. 查询入职日期是 “2006-01-01” 之后的员工信息 , 及其部门信息
分解为两步执行:
①. 入职日期是 “2006-01-01” 之后的员工信息
select * from emp where entrydate > '2006-01-01'
②. 查询这部分员工, 对应的部门信息;
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
(跳过)5.7 多表查询案例
六、事务
6.1 事务简介
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
就比如: 张三给李四转账1000块钱,张三银行账户的钱减少1000,而李四银行账户的钱要增加1000。 这一组操作就必须在一个事务的范围内,要么都成功,要么都失败。
正常情况: 转账这个操作, 需要分为以下这么三步来完成 , 三步完成之后, 张三减少1000, 而李四增加1000, 转账成功
异常情况: 转账这个操作, 也是分为以下这么三步来完成 , 在执行第三步是报错了, 这样就导致张三减少1000块钱, 而李四的金额没变, 这样就造成了数据的不一致, 就出现问题了。
为了解决上述的问题,就需要通过数据的事务来完成,我们只需要在业务逻辑执行之前开启事务,执行完毕后提交事务。如果执行过程中报错,则回滚事务,把数据恢复到事务开始之前的状态。
注意: 默认MySQL的事务是自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式的提交事务。
6.2 事务操作
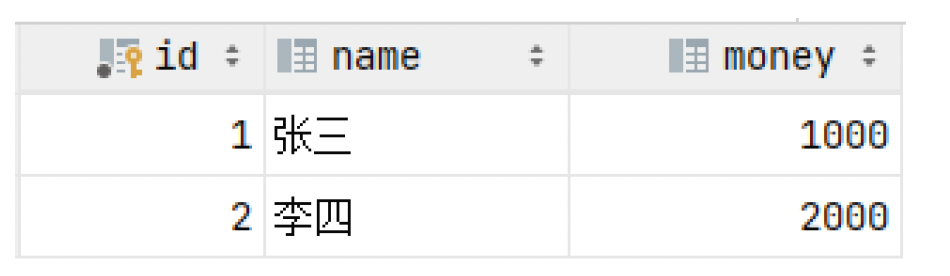
数据准备:
drop table if exists account;create table account(id int primary key AUTO_INCREMENT comment 'ID',name varchar(10) comment '姓名',money double(10,2) comment '余额'
) comment '账户表';insert into account(name, money) VALUES ('张三',2000), ('李四',2000);-- 恢复数据
update account set money = 2000 where name = '张三' or name = '李四';
6.2.1 未控制事务
1). 测试正常情况
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
测试完毕之后检查数据的状态, 可以看到数据操作前后是一致的。
2). 测试异常情况
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
出错了....
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
我们把数据都恢复到2000(注意使用恢复语句后再返回到account表需要手动使用刷新), 然后再次一次性执行上述的SQL语句(出错了… 这句话不符合SQL语法,执行就会报错),检查最终的数据情况, 发现数据在操作前后不一致了。
6.2.2 控制事务一
1). 查看/设置事务提交方式
SELECT @@autocommit ; -- 如果为1就是自动提交,如果为0就是手动提交
SET @@autocommit = 0 ; -- 将事务的提交方式修改成手动提交
注意SET @@autocommit = 0 ;只对当前窗口、当前会话有效
在设置了SET @@autocommit = 0 ;之后,无论有多少句DML,没有COMMIT之前,表中的数据都不会更新
2). 提交事务
COMMIT;
3). 回滚事务
如果执行过程中报错, 则回滚事务。视频中演示的是报错后使用回滚。
ROLLBACK;
注意:上述的这种方式,我们是修改了事务的自动提交行为, 把默认的自动提交修改为了手动提交, 此时我们执行的DML语句都不会提交, 需要手动的执行commit进行提交。
6.2.3 控制事务二
SET @@autocommit = 1; -- 改回默认:自动提交
1). 开启事务
START TRANSACTION 或 BEGIN ;
2). 提交事务
COMMIT;
3). 回滚事务
ROLLBACK;
转账案例:
-- 开启事务
start transaction
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则回滚事务
-- rollback;
即使在中途出现异常,一旦使用开启事务,在没有commit之前,表中的数据都不会变化
6.3 事务四大特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
上述就是事务的四大特性,简称ACID。
一致性:不管是事务成功提交了还是异常执行完毕之后回滚了,最终张三和李四账户的钱加起来是一个恒定的值
事务的隔离性:有若干个并发的事务,比如两个,都在同时操作这个数据库。事务a在操作的时候不会影响并发的事务b的执行,反之也是。它们两个事务是在独立的环境下运行的
6.4 并发事务问题
1). 赃读:一个事务读到另外一个事务还没有提交的数据。
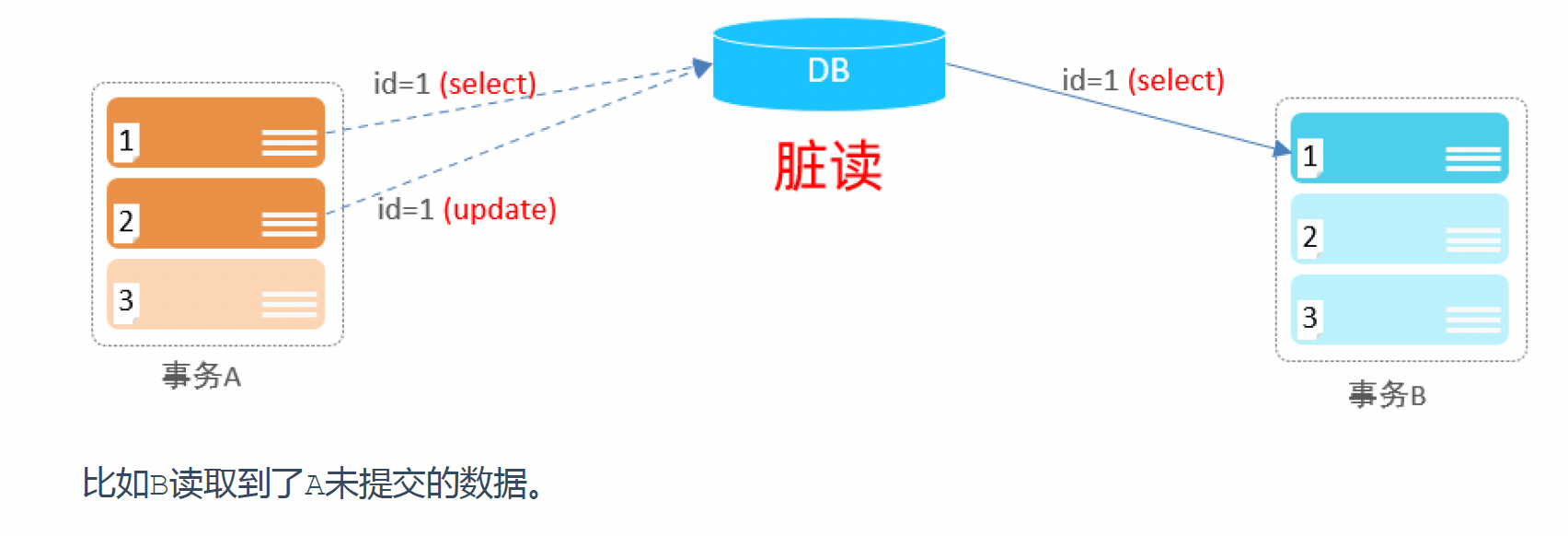
2). 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
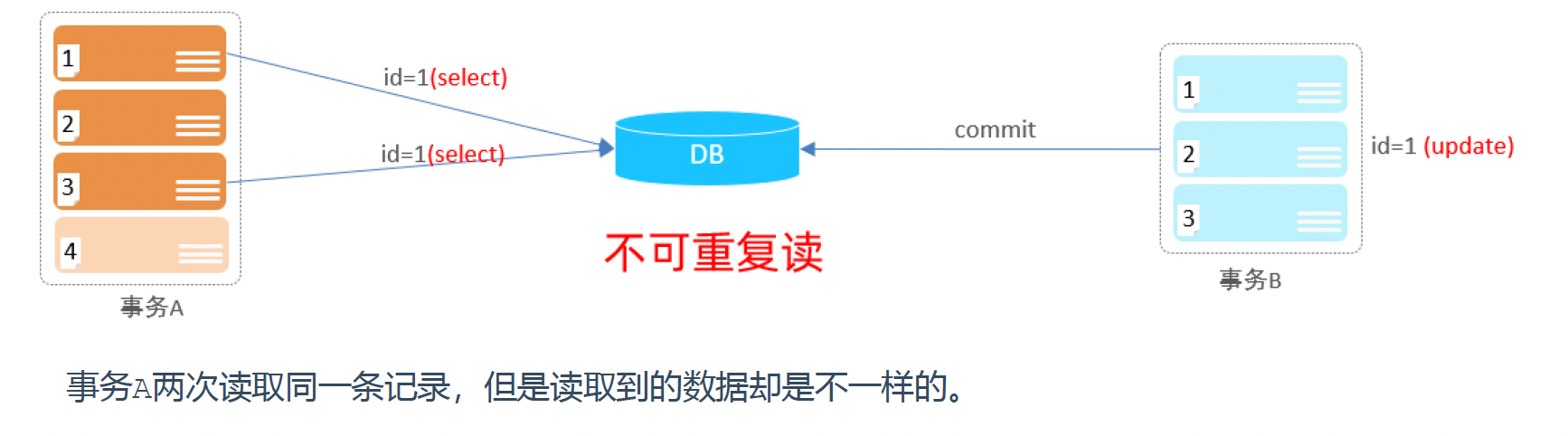
3). 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 “幻影”。
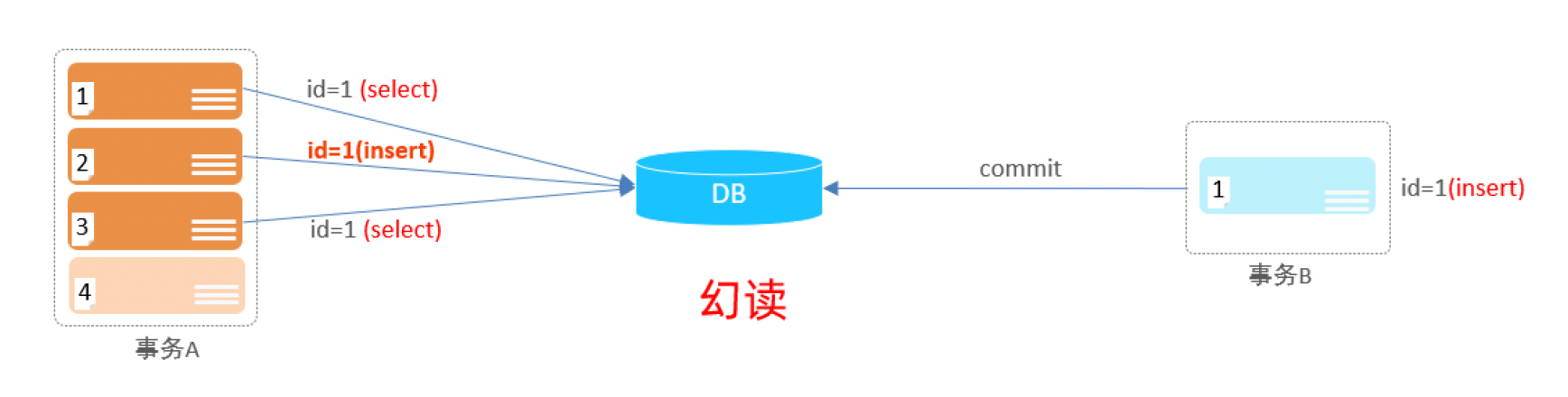
6.5 事务隔离级别
为了解决并发事务所引发的问题,在数据库中引入了事务隔离级别。主要有以下几种:
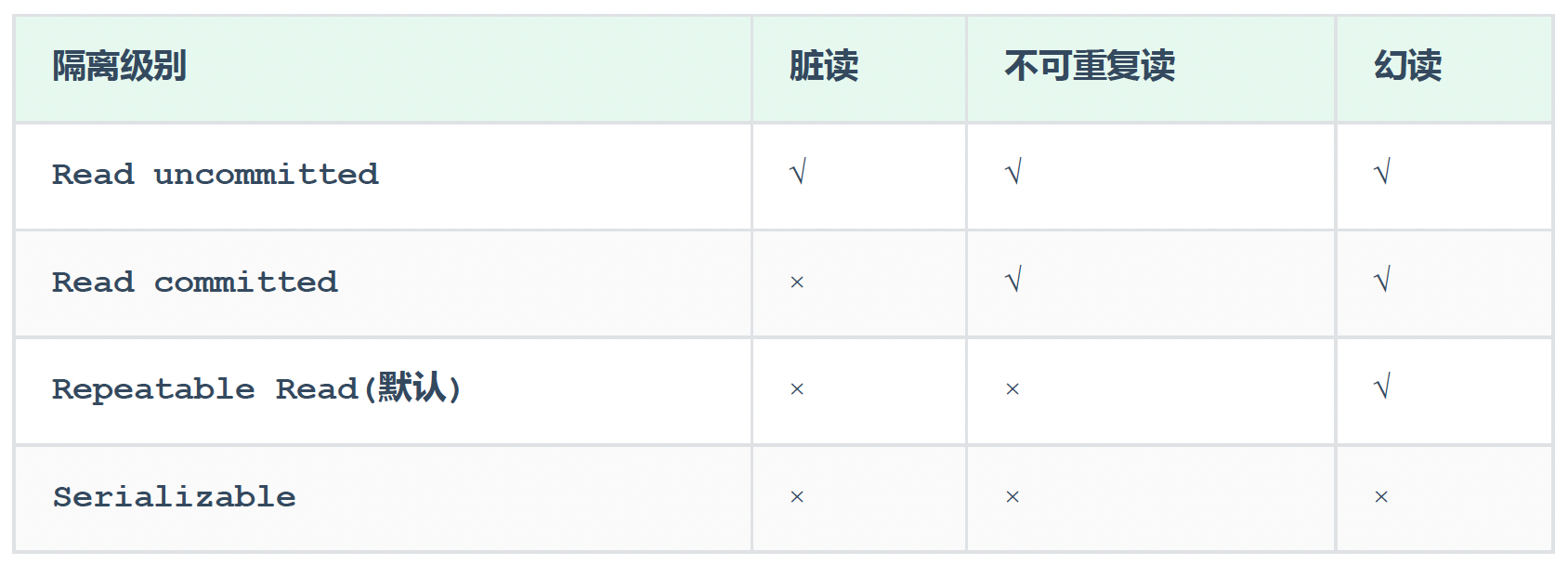
读未提交
读已提交
可重复读
串行化
MySQL的默认事务隔离级别是可重复读。Oracle的默认事务隔离级别是读已提交
1). 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
2). 设置事务隔离级别
SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL { READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE }
注意:事务隔离级别越高,数据越安全,但是性能越低。