【大模型实战笔记 2】基于讯飞星火大模型与 Streamlit 的多风格智能翻译助手项目实现
《多风格翻译助手项目实现》
【注:代码附于文章末尾,代码简单容易入手】
- 《多风格翻译助手项目实现》
- 基于讯飞星火大模型与 Streamlit 的多风格智能翻译系统设计与实现
- 一、项目简介
- 1.1 项目目标与核心功能
- 1.2 技术栈选型
- 二、逻辑实现
- 2.1 后端模型调用模块:`my_SparkLLM_Thread.py`
- (1)鉴权机制
- (2)WebSocket 通信流程
- 2.2 前端交互界面模块:`main_translator.py`
- Session State 状态管理
- (1)用户交互与请求处理
- (2)对话历史展示
- 三、总结与展望
- 四、项目代码实现
- 4.1 项目代码实现
- (1)my_SparkLLM_Thread.py
- (2)my_main_translate.py
- 4.2 项目实现效果展示
基于讯飞星火大模型与 Streamlit 的多风格智能翻译系统设计与实现
在大语言模型(LLM)技术日益成熟的今天,如何将强大的模型能力与简洁友好的用户界面相结合,成为开发者构建 AI 应用的关键课题。本文将深入剖析一个完整的“多风格智能翻译助手”项目,该项目以讯飞星火大模型 v3.1 作为后端推理引擎,前端采用 Streamlit 框架构建交互式 Web 界面,实现了将英文文本翻译为中文,并支持默认、古文、学术、琼瑶四种风格的智能切换。项目结构清晰、逻辑严谨,兼具实用性与教学价值。
一、项目简介
1.1 项目目标与核心功能
本项目旨在打造一个轻量级、高可用的多风格翻译服务,用户只需输入一段英文文本,即可获得符合指定语体风格的中文译文。其核心功能包括:
- 多风格翻译:支持四种差异化翻译风格,满足不同场景下的语言表达需求;
- 实时交互:通过 WebSocket 流式接口与大模型通信,实现低延迟响应;
- 对话历史管理:完整记录用户输入与模型输出,支持上下文回溯;
- 零部署前端:基于 Streamlit 快速构建美观、响应式的 Web 界面,无需前端开发经验。
1.2 技术栈选型
- 后端模型服务:讯飞星火大模型 Spark API(WebSocket 协议,v3.1 版本)
- 前端框架:Streamlit(Python 原生 Web 应用框架)
- 辅助组件:
streamlit-chat(美化对话消息)、websocket-client(WebSocket 通信) - 开发语言:Python 3.x
该技术组合充分发挥了 Python 在 AI 与 Web 快速原型开发中的优势,极大降低了项目实现门槛。
二、逻辑实现
2.1 后端模型调用模块:my_SparkLLM_Thread.py
该模块是整个系统与讯飞星火大模型通信的核心,负责完成鉴权、连接、请求发送与流式响应处理。
(1)鉴权机制
讯飞 Spark API 采用基于 HMAC-SHA256 的动态签名鉴权。Ws_Param 类封装了完整的 URL 生成逻辑:
- 获取当前时间并格式化为 RFC1123 标准;
- 构造签名原文(包含
host、date和request-line); - 使用
APISecret对原文进行 HMAC-SHA256 加密; - 将加密结果与
APIKey组合成authorization字符串,并进行 Base64 编码; - 最终拼接为带鉴权参数的完整 WebSocket URL。
(2)WebSocket 通信流程
- 通过
websocket.WebSocketApp建立连接,并注册on_open、on_message、on_error、on_close四个回调函数; - 连接成功后,在新线程中调用
run()发送格式化后的 JSON 请求(由gen_params()生成); - 服务器以流式方式返回数据,
on_message()持续拼接文本片段,直至收到结束标志(status == 2); - 最终返回完整译文字符串,供前端使用。
此设计确保了在 Streamlit 单线程环境下,模型调用不会阻塞 UI 响应。
2.2 前端交互界面模块:main_translator.py
前端模块基于 Streamlit 构建,核心在于状态管理与用户交互逻辑。
Session State 状态管理
由于 Streamlit 每次用户交互都会从头重跑脚本,普通变量无法跨轮次保持。项目通过 st.session_state 实现持久化存储:
if 'generated' not in st.session_state:st.session_state['generated'] = []
if 'past' not in st.session_state:st.session_state['past'] = []
past:存储用户历史输入;generated:存储模型历史回复。
这种初始化是避免 KeyError 的关键,符合 Streamlit 官方最佳实践。
(1)用户交互与请求处理
- 用户通过
st.text_input输入英文文本; - 通过
st.radio选择翻译风格,动态生成风格提示词(如“请按照古文风格进行翻译…”); - 拼接完整 Prompt:“{用户输入}\n请将上述英文内容翻译为中文{风格提示}”;
- 调用
my_SparkLLM_Thread.main()发起模型请求; - 将用户输入与模型回复分别追加至
st.session_state['past']和st.session_state['generated']。
(2)对话历史展示
使用 streamlit-chat 的 message() 组件渲染对话气泡。为实现最新对话置顶的聊天体验,采用倒序遍历:
for i in range(len(st.session_state['generated']) - 1, -1, -1):message(st.session_state['past'][i], is_user=True, key=f"user_{i}")message(st.session_state['generated'][i], key=f"bot_{i}")
每轮对话保持“用户 → AI”的自然顺序,整体列表按时间倒序排列,符合主流聊天应用交互习惯。
三、总结与展望
本项目成功将讯飞星火大模型的能力封装为一个易用的多风格翻译工具,展示了从底层 API 调用到上层 UI 构建的完整链路。其设计亮点在于:
- 模块解耦:后端通信与前端逻辑分离,便于维护与扩展;
- 状态安全:严格遵循 Streamlit Session State 初始化规范;
- 用户体验:通过流式响应与对话气泡,提供接近真实聊天的交互感。
未来可进一步优化的方向包括:引入 st.spinner 提升加载反馈、支持多轮上下文对话、增加翻译质量评估等。对于希望快速将大模型能力产品化的开发者而言,本项目提供了一个极具参考价值的实践范本。
四、项目代码实现
4.1 项目代码实现
(1)my_SparkLLM_Thread.py
# -*- coding: UTF-8 -*-
"""
讯飞星火大模型(Spark API)WebSocket 客户端
用于通过 WebSocket 流式调用星火 v3.1 对话接口(/v3.1/chat)
支持鉴权、连接、请求发送、流式响应拼接与会话管理
"""import _thread as thread # 低级线程模块,用于在连接建立后异步发送请求(避免阻塞)
import base64
import hashlib
import hmac
import json
import time
from urllib.parse import urlparse, urlencode
from datetime import datetime
from time import mktime
from wsgiref.handlers import format_date_time # 生成符合 HTTP RFC1123 标准的时间字符串
import websocket # 需安装: pip install websocket-client# 全局变量(仅用于单次调用示例;在多用户/并发场景中应避免使用)
answer = '' # 存储最终模型回复(不推荐在模块级使用,此处仅为示例)
tokens = 0 # 存储本次请求的 token 消耗量class Ws_Param(object):"""封装 WebSocket 连接所需的鉴权参数生成逻辑遵循讯飞 Spark API v3.1 的鉴权规范(HMAC-SHA256 + Base64)"""def __init__(self, APPID, APIKey, APISecret, gpt_url):"""初始化鉴权参数:param APPID: 讯飞控制台分配的应用 ID:param APIKey: 公钥(用于标识身份):param APISecret: 私钥(用于签名,切勿泄露):param gpt_url: 星火 API 的 WebSocket 地址(如 wss://spark-api.xf-yun.com/v3.1/chat)"""self.APPID = APPIDself.APIKey = APIKeyself.APISecret = APISecretself.host = urlparse(gpt_url).netloc # 提取主机名,如 'spark-api.xf-yun.com'self.path = urlparse(gpt_url).path # 提取路径,如 '/v3.1/chat'self.gpt_url = gpt_url # 原始 WebSocket URLdef create_url(self):"""根据讯飞官方文档生成带鉴权参数的完整 WebSocket URL鉴权流程:1. 构造签名原文(signature_origin)2. 使用 APISecret 对原文进行 HMAC-SHA256 加密3. 将加密结果 Base64 编码4. 构造 authorization 字符串并再次 Base64 编码5. 拼接为最终 URL"""# 1. 生成 RFC1123 格式的时间戳(HTTP 标准时间)now = datetime.now()date = format_date_time(mktime(now.timetuple()))# 2. 构造签名原文(必须严格按顺序:host \n date \n request-line)signature_origin = "host: " + self.host + "\n"signature_origin += "date: " + date + "\n"signature_origin += "GET " + self.path + " HTTP/1.1"print("signature_origin:\n" + str(signature_origin))# 3. 使用 APISecret 对签名原文进行 HMAC-SHA256 加密signature_sha = hmac.new(self.APISecret.encode('utf-8'),signature_origin.encode('utf-8'),digestmod=hashlib.sha256).digest()# 4. 将加密结果进行 Base64 编码signature_sha_base64 = base64.b64encode(signature_sha).decode('utf-8')# 5. 构造 authorization 字符串authorization_origin = (f'api_key="{self.APIKey}", 'f'algorithm="hmac-sha256", 'f'headers="host date request-line", 'f'signature="{signature_sha_base64}"')# 6. 对 authorization 字符串再次 Base64 编码(讯飞要求)authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode('utf-8')# 7. 拼接最终 URL(携带 authorization, date, host 三个查询参数)v = {"authorization": authorization,"date": date,"host": self.host}url = self.gpt_url + '?' + urlencode(v)return url# ========== WebSocket 回调函数 ==========def on_error(ws, error):"""WebSocket 连接或通信发生错误时的回调"""print("### WebSocket error:", error)def on_close(ws, close_status_code, close_msg):"""WebSocket 连接关闭时的回调注意:原函数参数名有误,已按 websocket-client 实际签名修正"""# print("### WebSocket connection closed ###")return 0 # 原代码保留,实际可省略def on_open(ws):"""WebSocket 连接成功建立后的回调启动一个新线程发送请求数据,避免阻塞主线程(尤其在 Streamlit 环境中至关重要)"""thread.start_new_thread(run, (ws,))def run(ws, *args):"""在新线程中向 WebSocket 服务器发送请求数据请求体由 gen_params() 生成,符合星火 API 规范"""data = json.dumps(gen_params(appid=ws.appid,question=ws.question,uid=ws.uid,chat_id=ws.chat_id))ws.send(data)def on_message(ws, message):"""收到 WebSocket 服务器流式返回消息时的回调每次返回一部分文本,需拼接成完整回复"""endTime = time.time()print(f"收到消息时间戳: {endTime}")# 解析 JSON 响应data = json.loads(message)print("原始返回数据:\n" + json.dumps(data, indent=2, ensure_ascii=False))# 检查请求是否成功code = data['header']['code']if code != 0:# code 非 0 表示错误(如鉴权失败、参数错误等)print(f'请求错误: {code}, 详情: {data}')ws.close()else:# 提取流式返回的文本片段choices = data["payload"]["choices"]status = choices["status"] # 0: 首包, 1: 中间包, 2: 尾包content = choices["text"][0]["content"]# 将当前片段追加到当前连接的 answer 属性中ws.answer += content# print(content, end='', flush=True) # 可选:实时打印流式输出# 若为尾包(status == 2),表示回复结束if status == 2:global tokenstokens = data["payload"]["usage"] # 记录 token 使用情况print("\n--- 模型回复结束 ---")ws.close() # 主动关闭连接def gen_params(appid, question, uid, chat_id):"""构造符合星火 API v3.1 要求的请求参数:param appid: 应用 ID:param question: 用户消息列表,格式为 [{"role": "user", "content": "xxx"}]:param uid: 用户唯一标识(用于业务层区分):param chat_id: 会话 ID(用于多轮对话上下文记忆):return: 符合 API 规范的 JSON 结构"""return {"header": {"app_id": appid,"uid": uid # 业务层用户 ID},"parameter": {"chat": {"domain": "generalv3", # 使用 v3.0 通用大模型"temperature": 0.8, # 生成多样性(0.0~1.0)"top_k": 6, # 候选词数量"max_tokens": 4096, # 最大输出长度"auditing": "default", # 内容安全审核策略"stream": True, # 启用流式输出(必须为 True)"chat_id": chat_id # 会话 ID,用于上下文关联}},"payload": {"message": {"text": question # 用户输入的消息列表}}}def main(uid, chat_id, appid, api_key, api_secret, gpt_url, question):"""主函数:完成从鉴权、连接、发送请求到接收完整回复的全过程:return: 模型生成的完整文本回复(字符串)"""# 1. 生成带鉴权参数的 WebSocket URLwsParam = Ws_Param(appid, api_key, api_secret, gpt_url)wsUrl = wsParam.create_url()# 2. 创建 WebSocketApp 实例,并绑定回调函数ws = websocket.WebSocketApp(wsUrl,on_message=on_message,on_error=on_error,on_close=on_close,on_open=on_open)# 3. 附加自定义属性,用于在回调函数中传递参数ws.appid = appidws.uid = uidws.chat_id = chat_idws.answer = '' # 用于累积流式返回的文本ws.question = question # 用户输入# 4. 启动 WebSocket 长连接(阻塞直到连接关闭)ws.run_forever()# 5. 返回完整回复return ws.answer# ========== 程序入口(独立运行测试用) ==========
if __name__ == '__main__':# 示例:查询“湖北襄阳唐城出现了什么舆论?”result = main(uid='XXXXXX', # 替换为你的用户 ID(可自定义)chat_id='XXXXXX', # 会话 ID(同一会话可保持上下文)appid='XXXXXXXX', # 替换为你的 APPID(来自讯飞控制台)api_key='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX', # 替换为你的 APIKeyapi_secret='XXXXXXXXXXXXXXXXXXXXXXXXXXXX', # 替换为你的 APISecretgpt_url='wss://spark-api.xf-yun.com/v3.1/chat',question=[{"role": "user", "content": "湖北襄阳唐城出现了什么舆论?"}])print()print("返回结果为:\n" + str(result))print("Token 使用情况:", tokens)
(2)my_main_translate.py
# -*- coding: utf-8 -*-
"""
多风格智能翻译助手前端界面
基于 Streamlit 构建,调用 SparkLLM_Thread 模块与讯飞星火大模型通信
支持四种翻译风格:默认、古文、学术、琼瑶
"""# 导入自定义后端模块(负责与讯飞星火大模型 WebSocket 通信)
import SparkLLM_Thread
# 导入 Streamlit 核心库
import streamlit as st
# 导入第三方对话气泡组件(美化消息展示)
from streamlit_chat import message# ========== 页面初始化与用户引导 ==========
# 使用 Markdown 渲染欢迎语,增强界面亲和力
st.markdown("### 您好,本项目是由小波进行实现的多风格翻译官Wilber,很荣幸为您服务。")# ========== 用户输入组件 ==========
# 创建文本输入框,key='input' 用于唯一标识该组件状态
# 用户每次输入会触发脚本重新执行
user_input = st.text_input("请输入您需要翻译的英文文本:", key='input')# ========== 翻译风格选择 ==========
# 创建横向单选按钮组,供用户选择翻译风格
but = st.radio("翻译风格:",('默认风格', '古文风格', '学术风格', '琼瑶风格'),horizontal=True # 水平排列选项
)# 根据用户选择动态生成风格提示词(将作为 Prompt 的一部分)
if but == '默认风格':style = '。' # 默认风格无额外要求
elif but == '古文风格':style = ', 请按照古文风格进行翻译, 用古诗词的行文风格, 做到辞藻精炼, 可用典故。'
elif but == '学术风格':style = ', 请按照学术风格进行翻译, 保持严谨认真的风格。'
elif but == '琼瑶风格':style = ', 请按照琼瑶风格进行翻译, 意境优美, 充满诗情画意, 或多愁善感, 或心花怒放。'
else:style = '。' # 安全兜底# ========== Session State 初始化 ==========
# Streamlit 每次交互都会重跑脚本,必须通过 st.session_state 持久化数据
# 初始化 'generated' 列表:存储模型历史回复
if 'generated' not in st.session_state:st.session_state['generated'] = []# 初始化 'past' 列表:存储用户历史输入
if 'past' not in st.session_state:st.session_state['past'] = []# ========== 用户输入处理逻辑 ==========
# 当 user_input 非空时(即用户提交了内容),执行以下逻辑
if user_input:# 构造完整 Prompt:用户输入 + 翻译指令 + 风格要求text = user_input + "\n请将上述英文内容翻译为中文" + style# 将当前用户输入保存到历史记录(用于后续展示)st.session_state['past'].append(user_input)# 调用后端模块,向讯飞星火大模型发起请求# 参数说明:# uid/chat_id: 用于区分用户和会话(可自定义)# appid/api_key/api_secret: 讯飞开放平台凭证(需替换为真实值)# gpt_url: 星火 v3.1 对话接口地址# question: 符合 API 规范的消息列表output = SparkLLM_Thread.main(uid='XXXXXX',chat_id='XXXXXX',appid='XXXXXX',api_key='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX',api_secret='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX',gpt_url='wss://spark-api.xf-yun.com/v3.1/chat',question=[{"role": "user", "content": text}])# 将模型返回的完整译文保存到历史记录st.session_state['generated'].append(output)# ========== 对话历史展示 ==========
# 仅当存在模型回复时才渲染历史消息
if st.session_state['generated']:# 倒序遍历:从最新一轮对话开始展示(实现“最新消息置顶”效果)for i in range(len(st.session_state['generated']) - 1, -1, -1):# 先显示 AI 的回复(非用户消息)message(st.session_state["generated"][i], key=str(i))# 再显示对应的用户输入(标记为 is_user=True)message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')# 注意:每轮对话内部顺序为 “AI → 用户”,但整体列表是倒序的,# 因此视觉上最新一轮(用户最新输入 + AI 最新回复)会显示在最上方
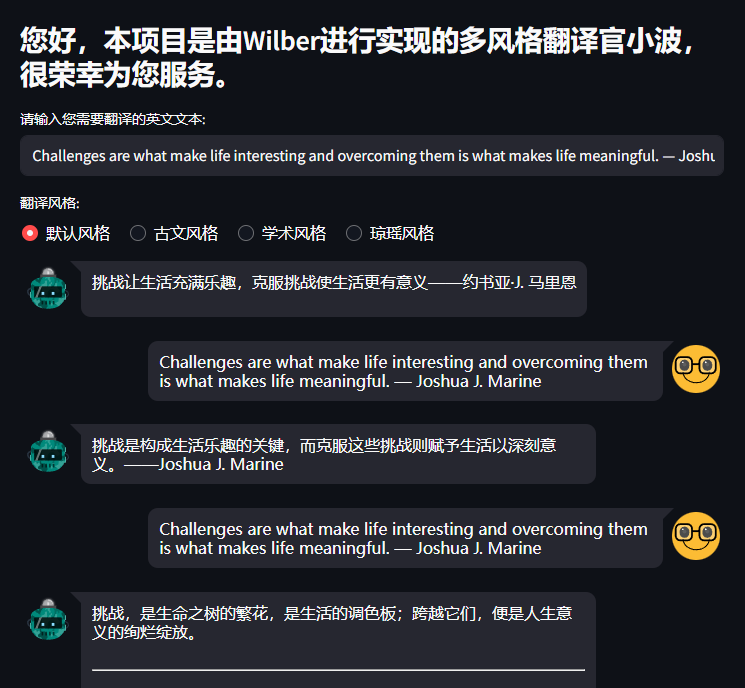
4.2 项目实现效果展示