13.排序(上)
begin和max重叠了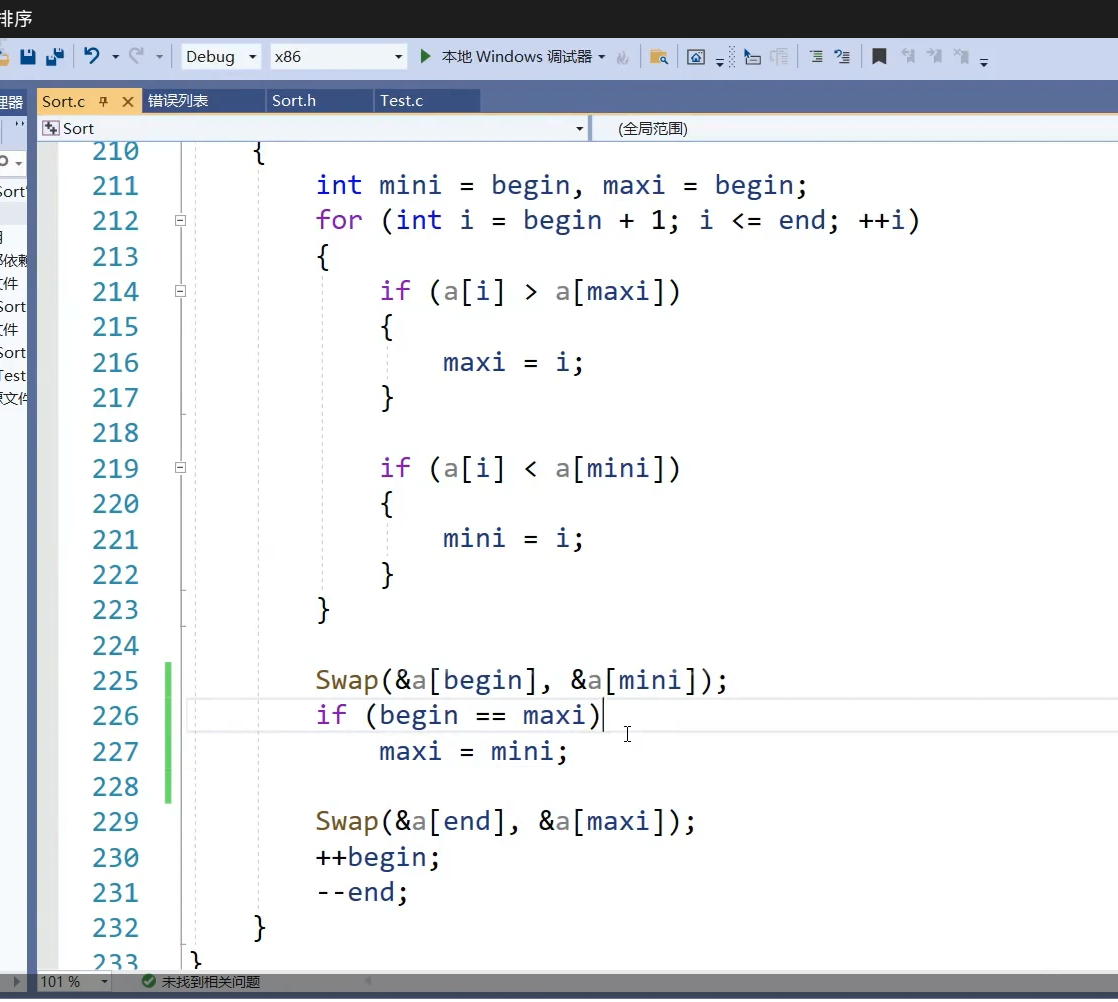 最坏n方最好n方比冒泡排序还不足
最坏n方最好n方比冒泡排序还不足 如果有序,冒泡是0,选择还是那些,选择排序是最没用的排序
如果有序,冒泡是0,选择还是那些,选择排序是最没用的排序
 通常选一个作为关键字,一般是第一个或最后一个,比他小放左边,大放右边
通常选一个作为关键字,一般是第一个或最后一个,比他小放左边,大放右边
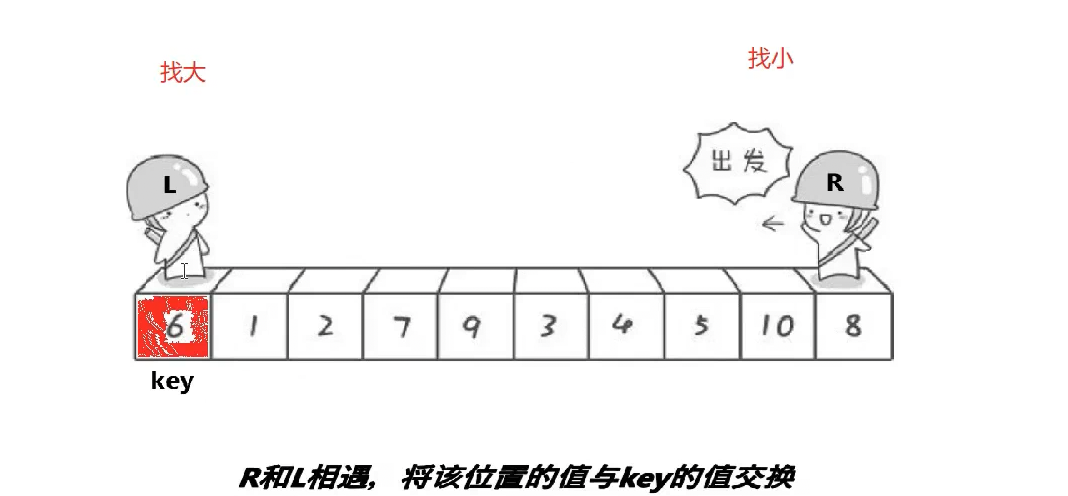
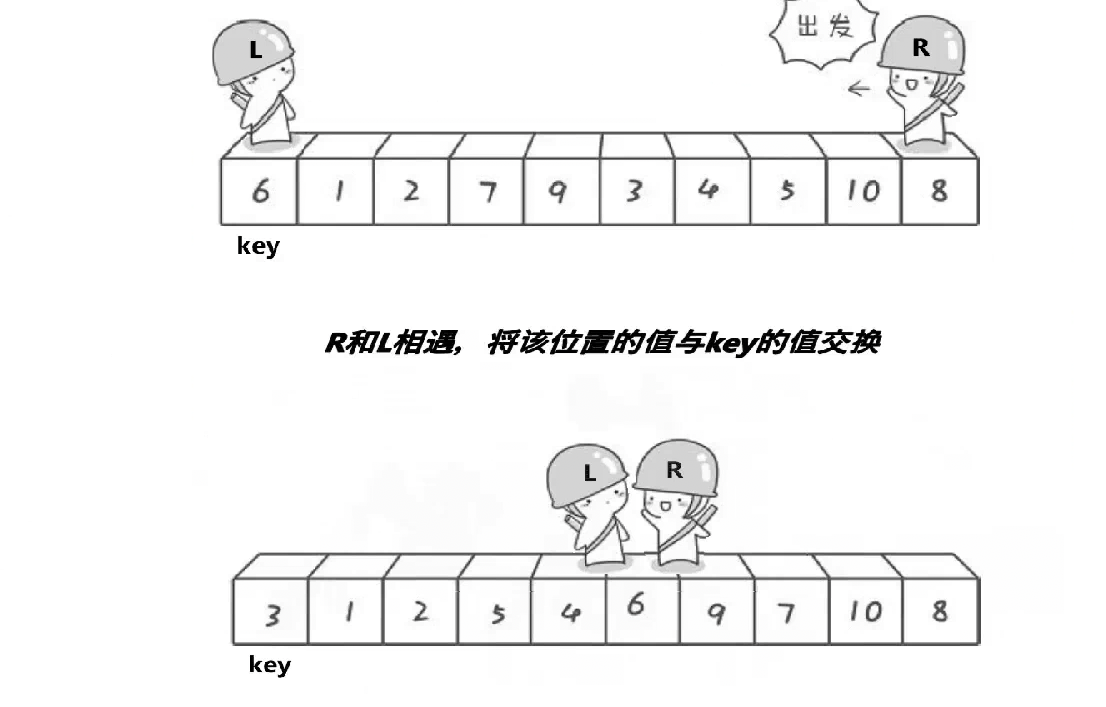
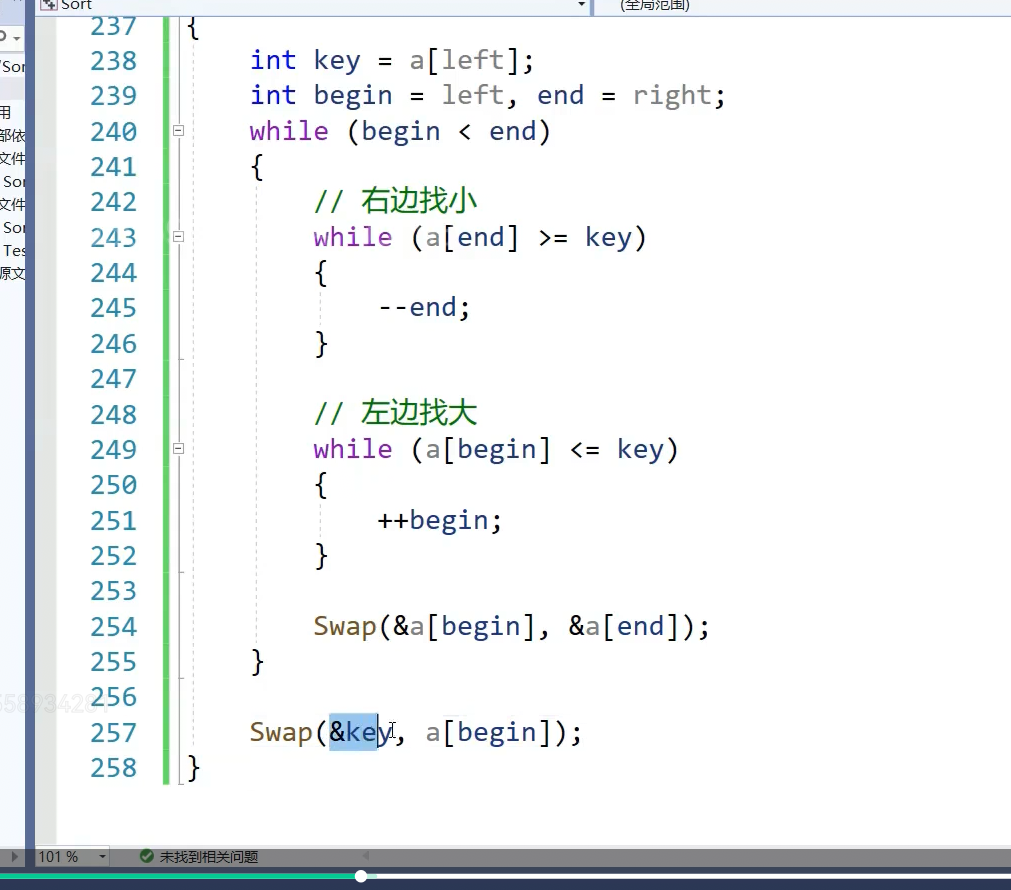
相遇的位置一定比key小,为什么后面讲,这是单趟排序,这个6就排好了不需要动了,如果左区间有序右区间有序就拍好了,3为key,右找小左找大,没找到在2相遇了,换一下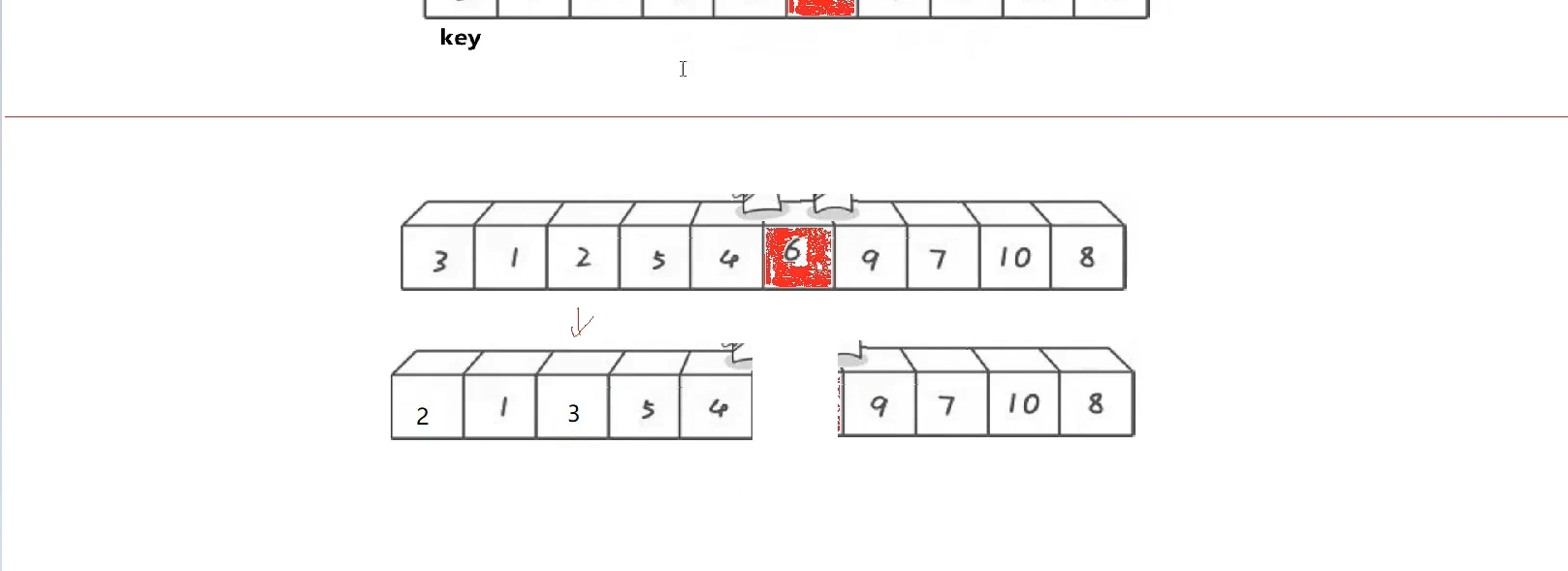
排好一个数同时做好分割,左区间走递归,依次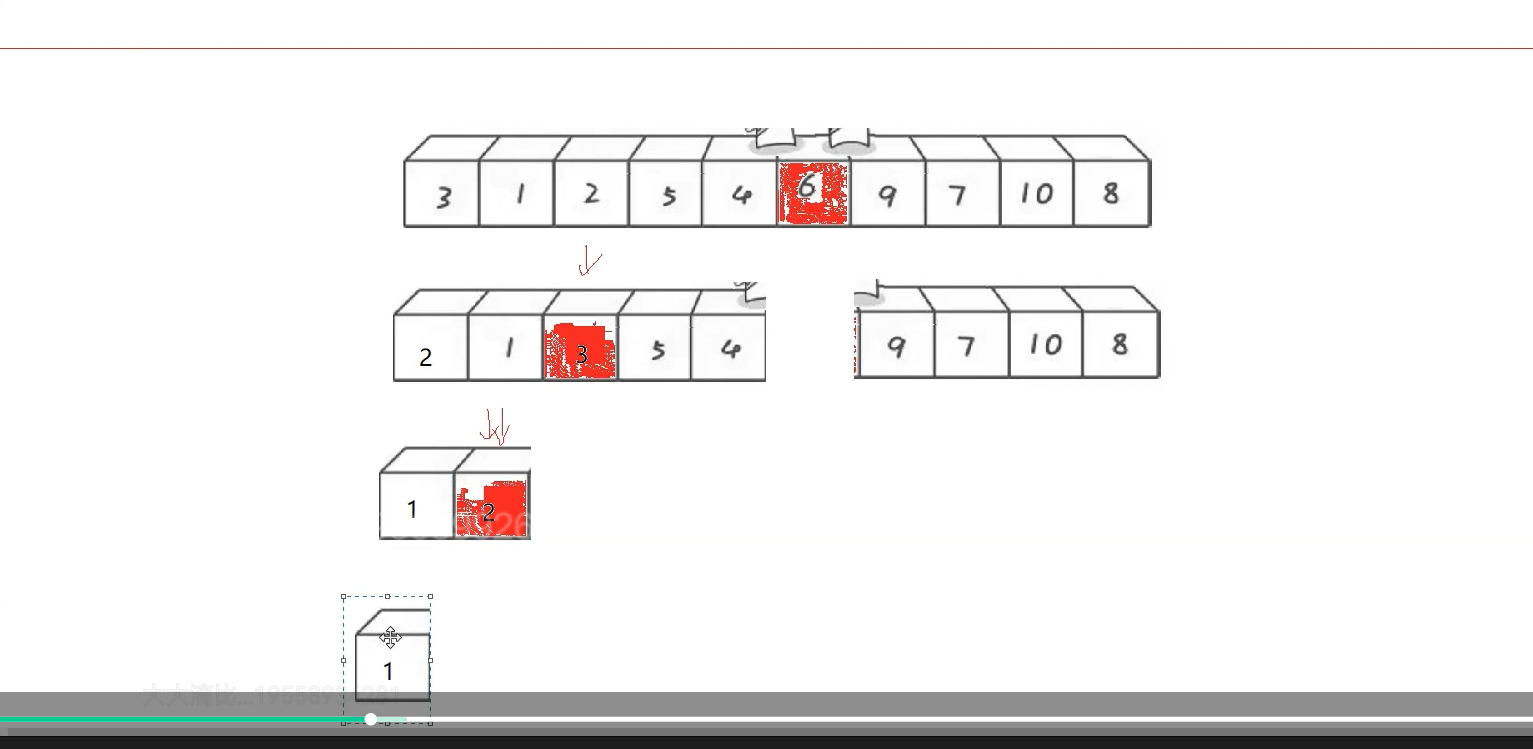
只有一个数就返回了,无值回来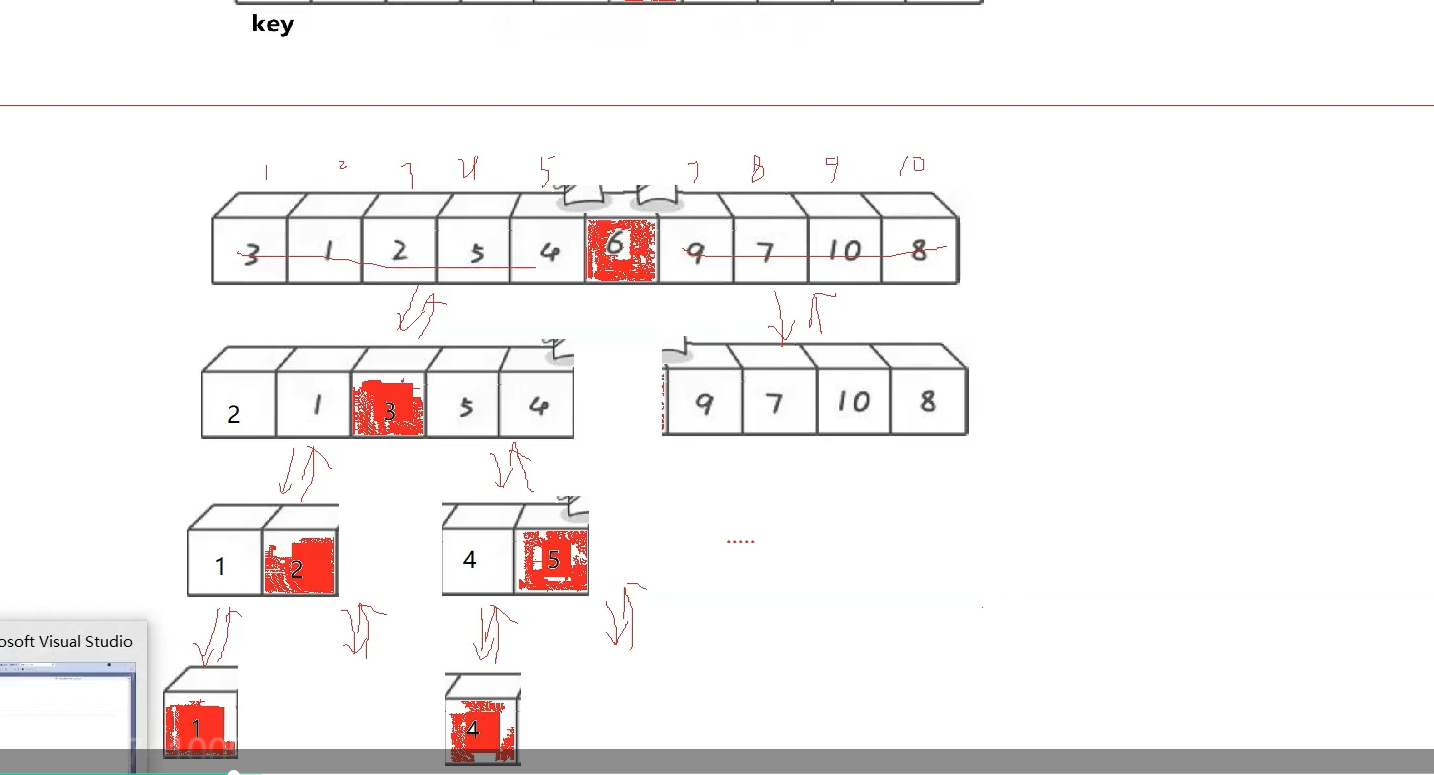
传left right 区间更容易控制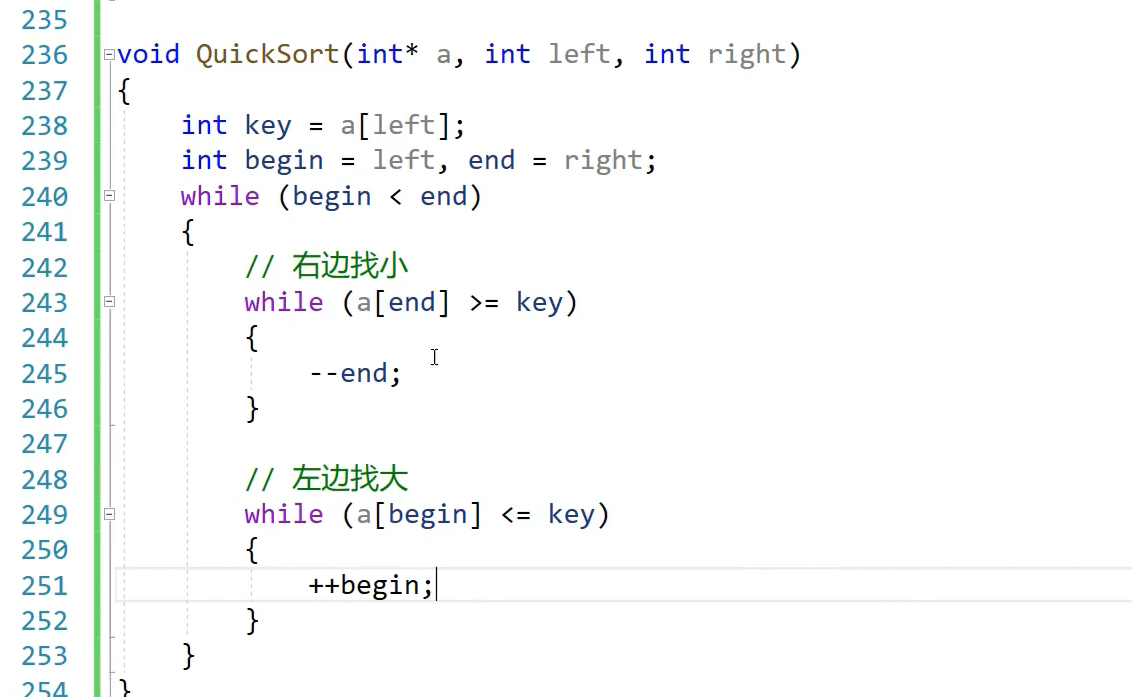
 测试以下
测试以下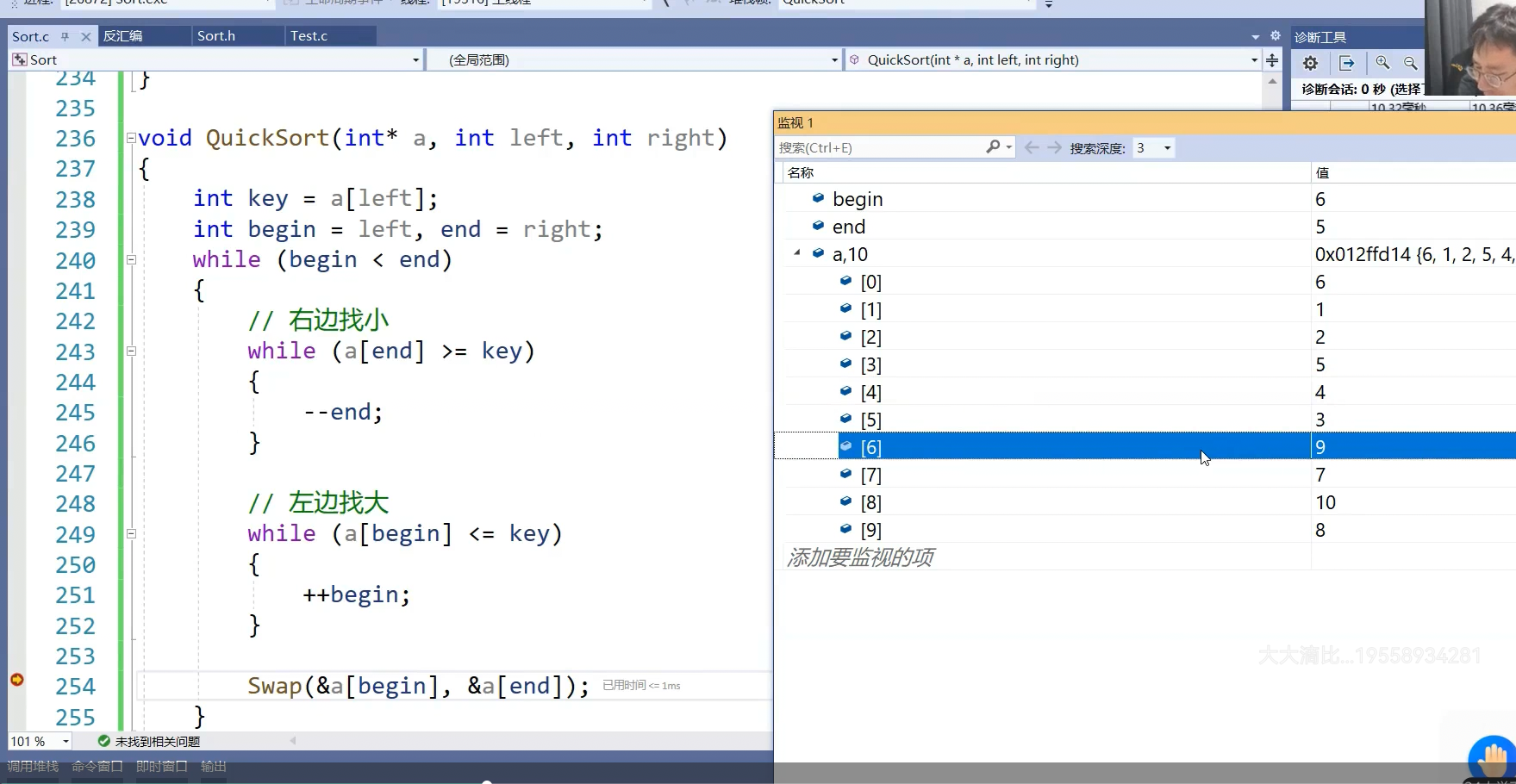
begin走过了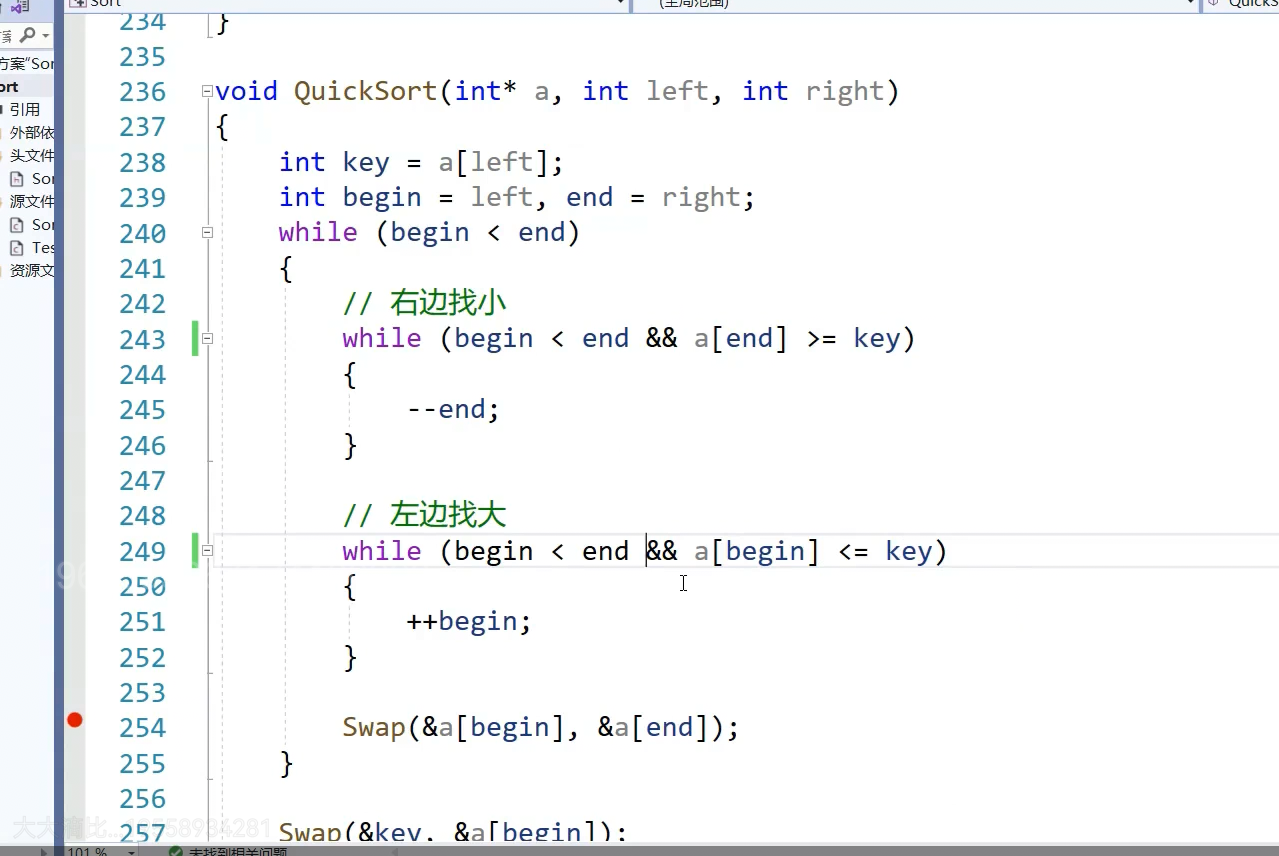 这里跟局部变量换了
这里跟局部变量换了

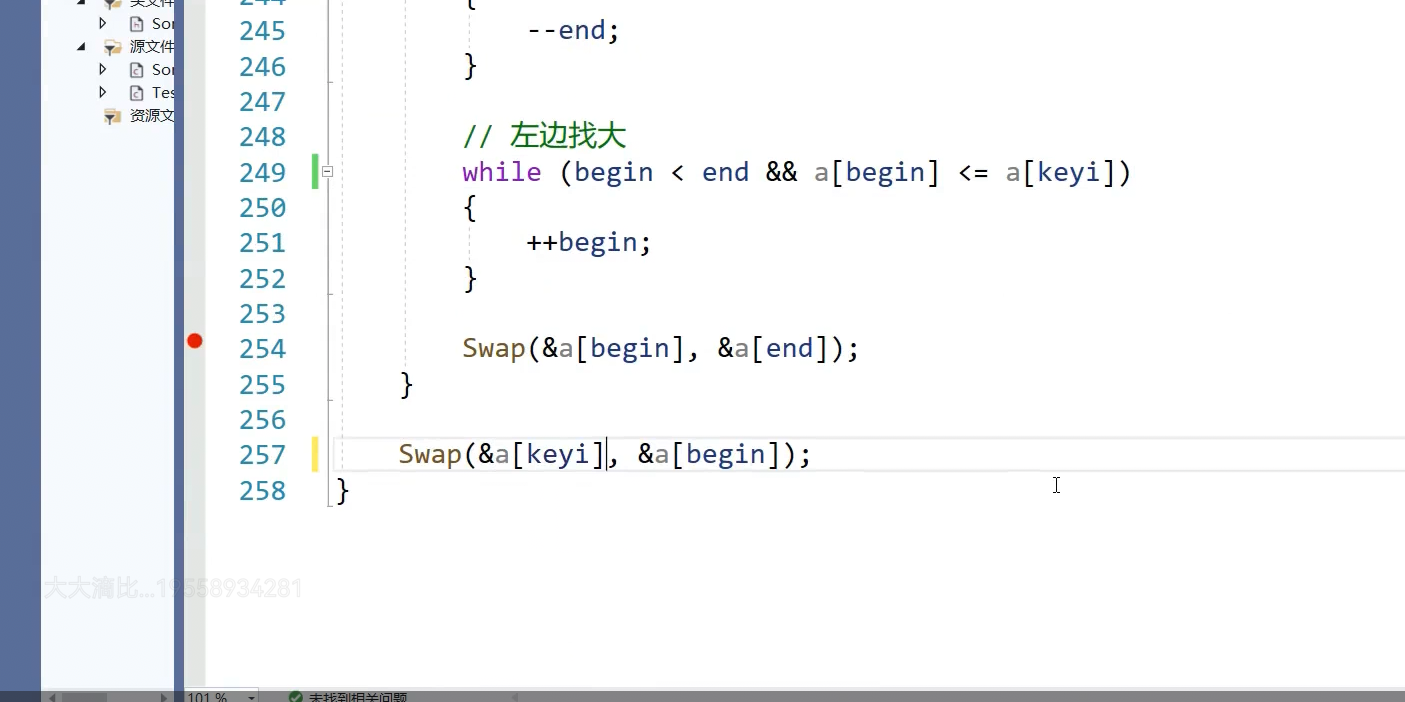
keyi就要指向begin,这样方便分割
为什么定义ubegin end 不用left right++ --,如果++ --就不好分割区间了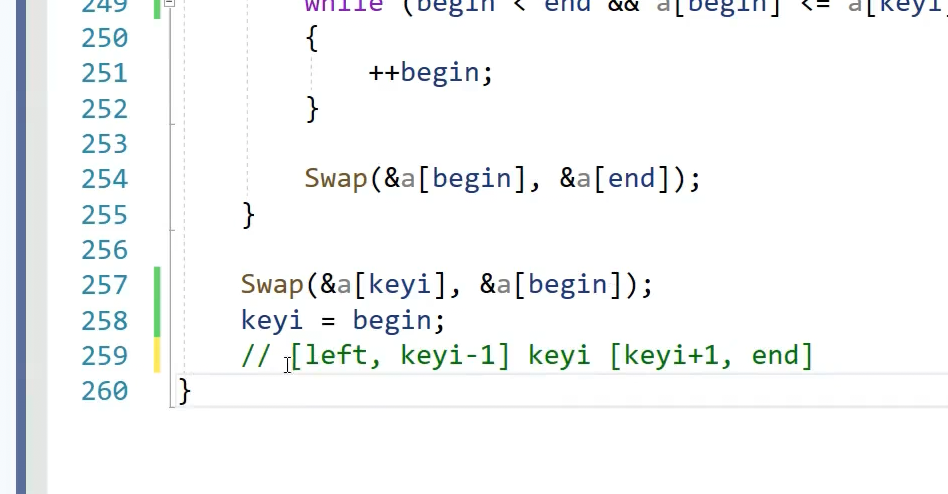
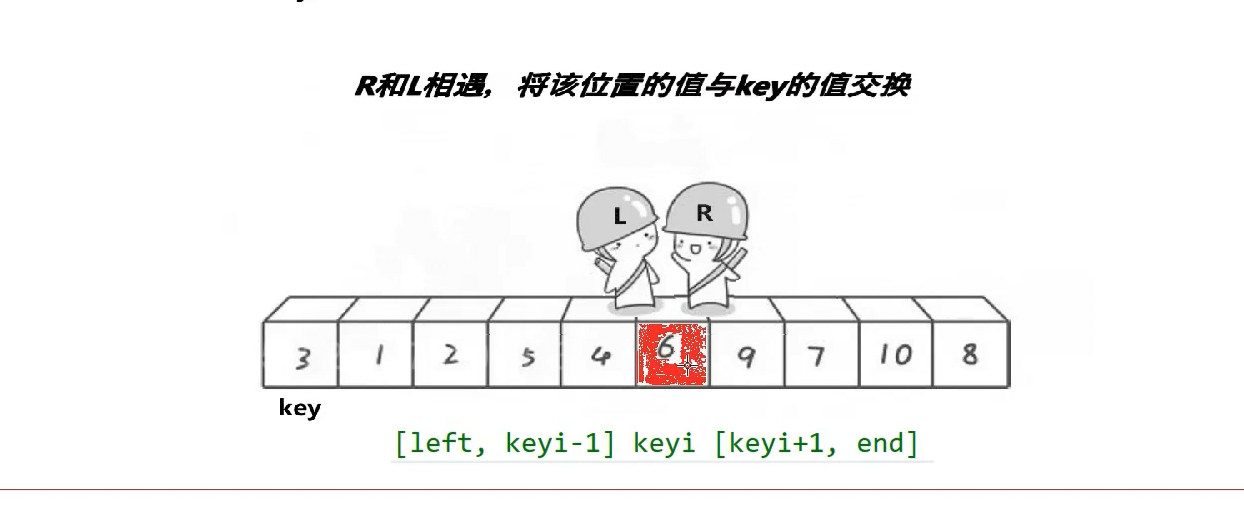 此时如果左区间有序右区间有序那么就有序了
此时如果左区间有序右区间有序那么就有序了 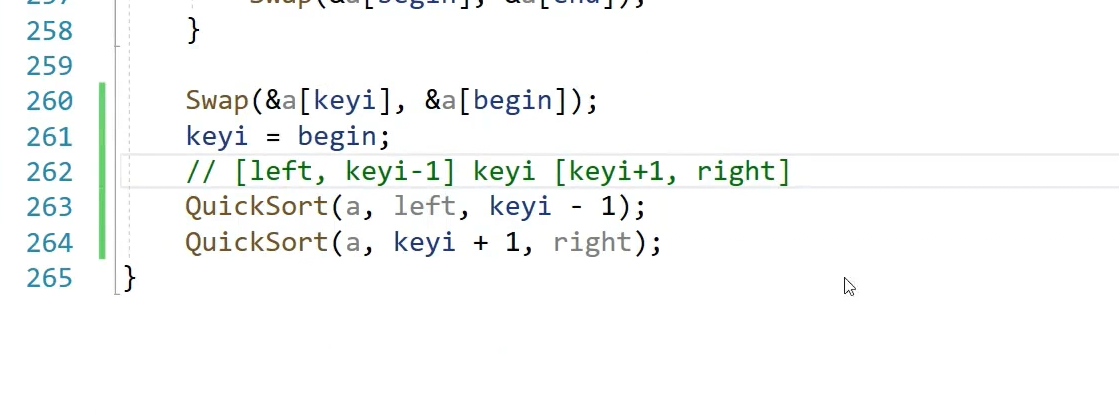
什么时候不需要分割了,区间一个值或不存在(left>right)下面右不存在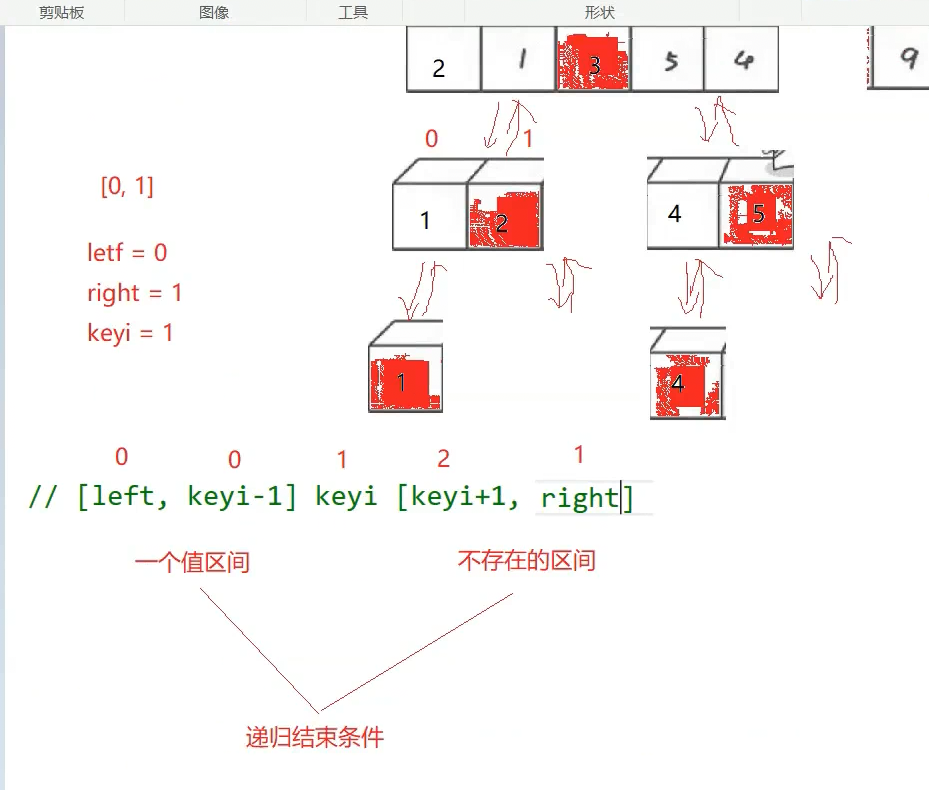
快排的时间复杂度怎么算,这里递归走了多少层,如果按每趟每个位置排好看,这n个数分成二叉树,如果均分情况下非常接近满二叉树,完全二叉树,所以这里logN层,每一层是多少,begin end合计往中间走了N次,下一层n-1,但是我们大概估算N,所以是N×logN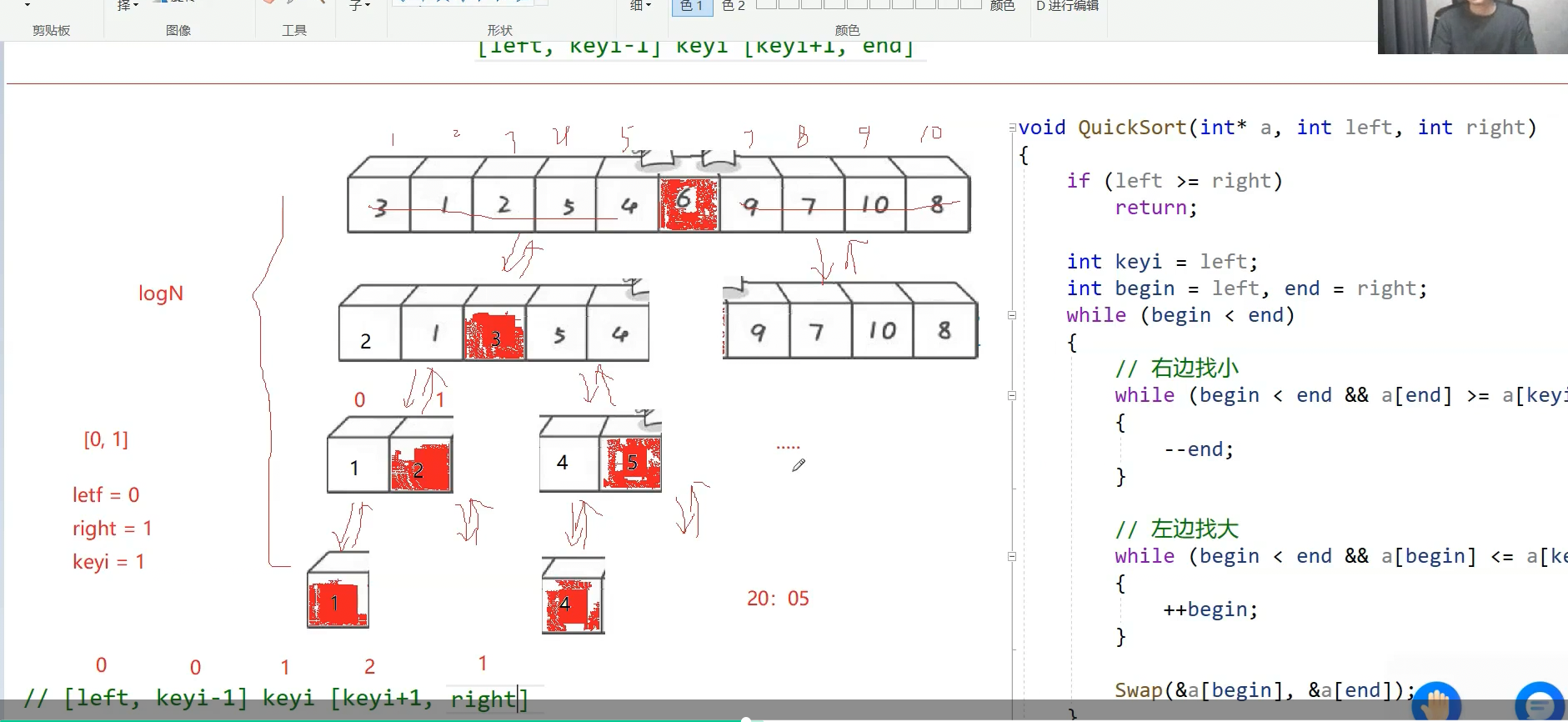
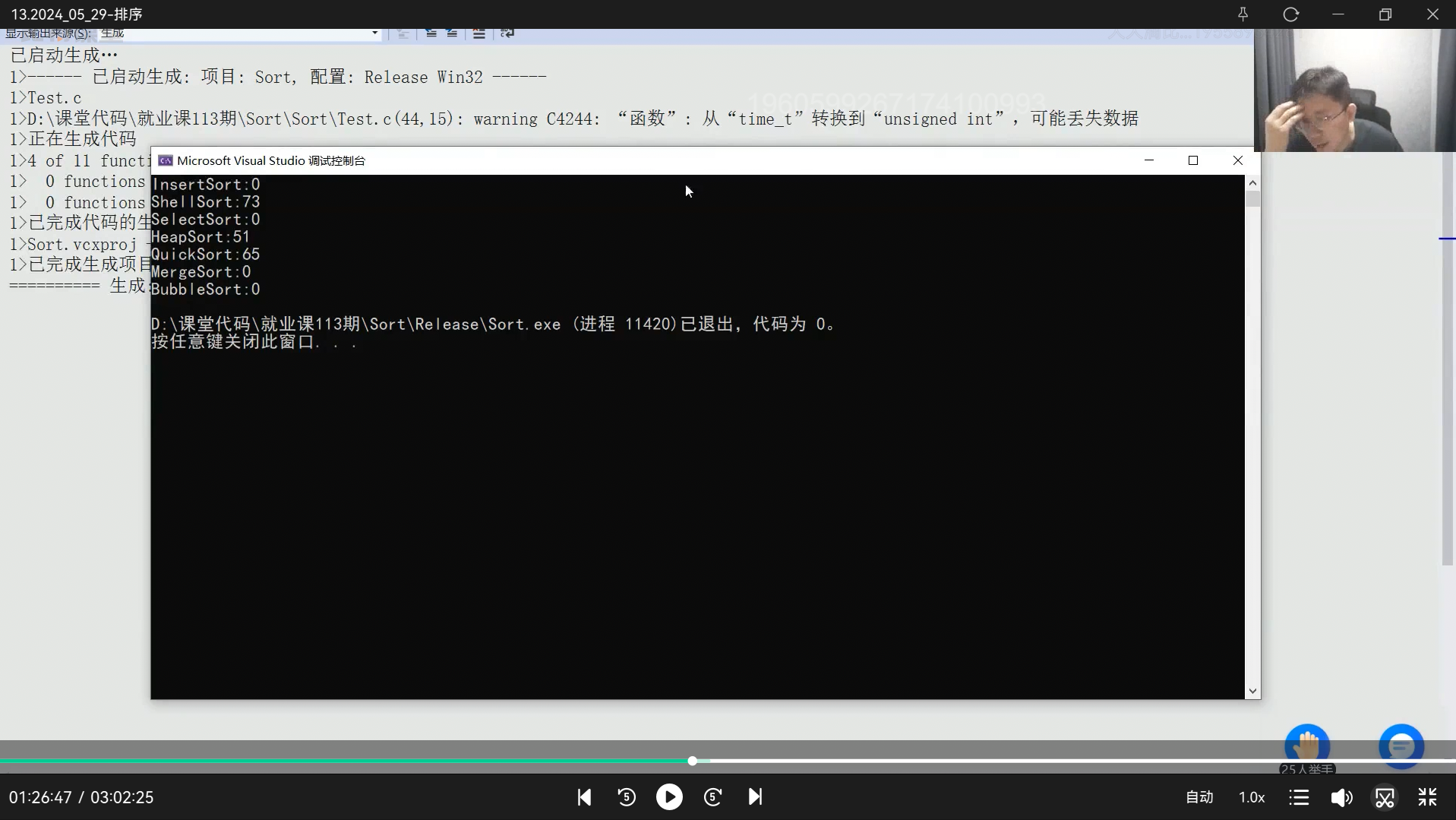
当前快排的缺陷:有序情况下栈溢出,key是1,右边开始找小一直找不到,key处相遇,key左边不存在,右边再选一个key.....退化成n方的算法(等差数列n方 )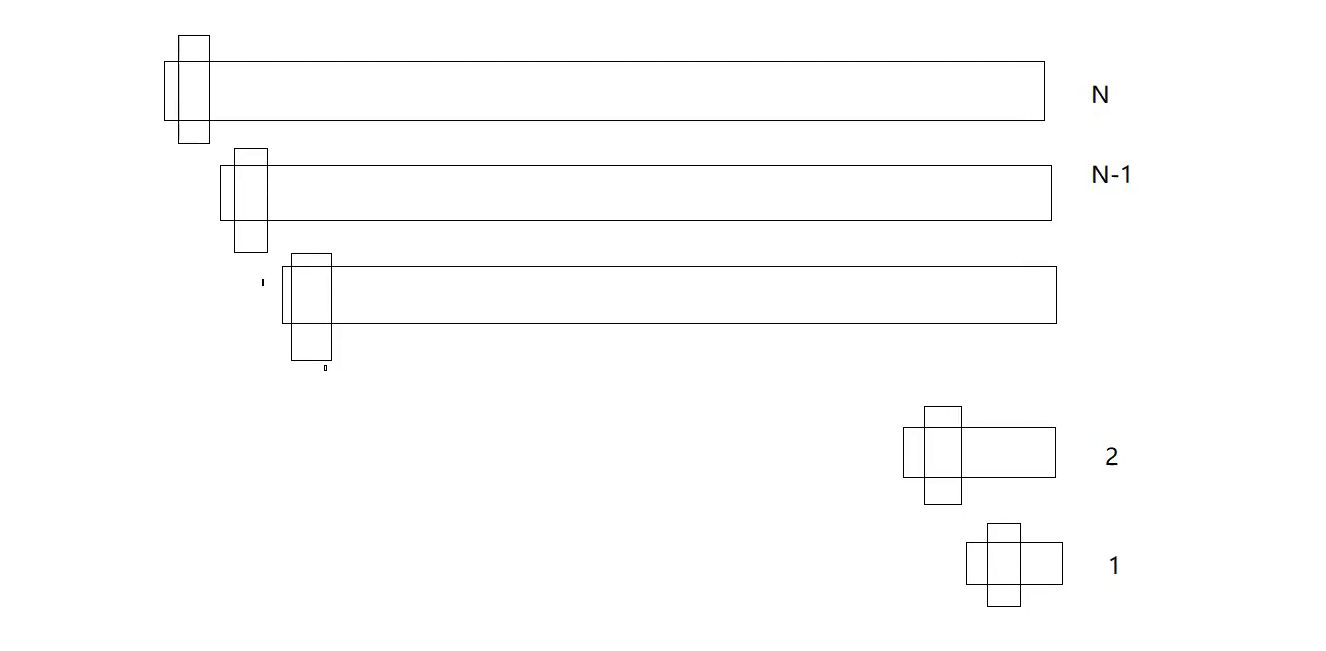 不断调用quick sort release下不会爆
不断调用quick sort release下不会爆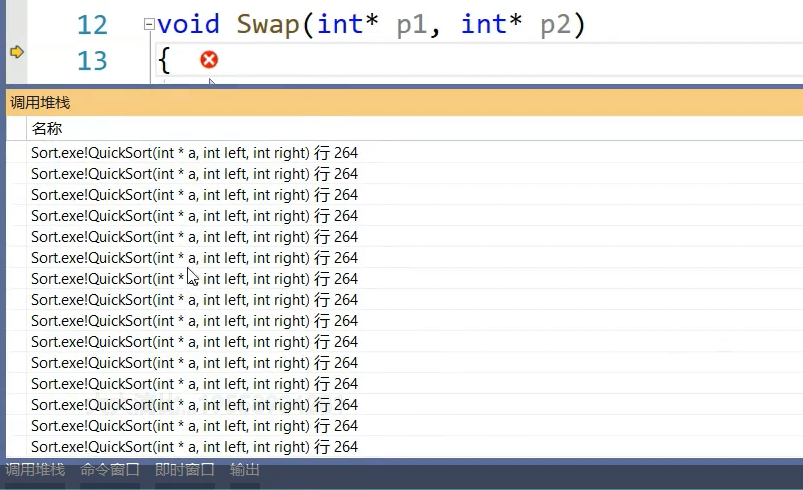
debug下面支持调试,优化开不了那么高,深度小 release递归深度还行,快排nlogN前提是每次选的key都接近中间位置,递归深度就是logn而上面那图深度变N,控不住了,快排在这还是有比较明显的缺陷
解决:固定选最左边或最右边这个值为key就会存在这个问题,
三数取中最左边最右边中间选中间的值作key,把这个值和key位置换一下,保证逻辑不变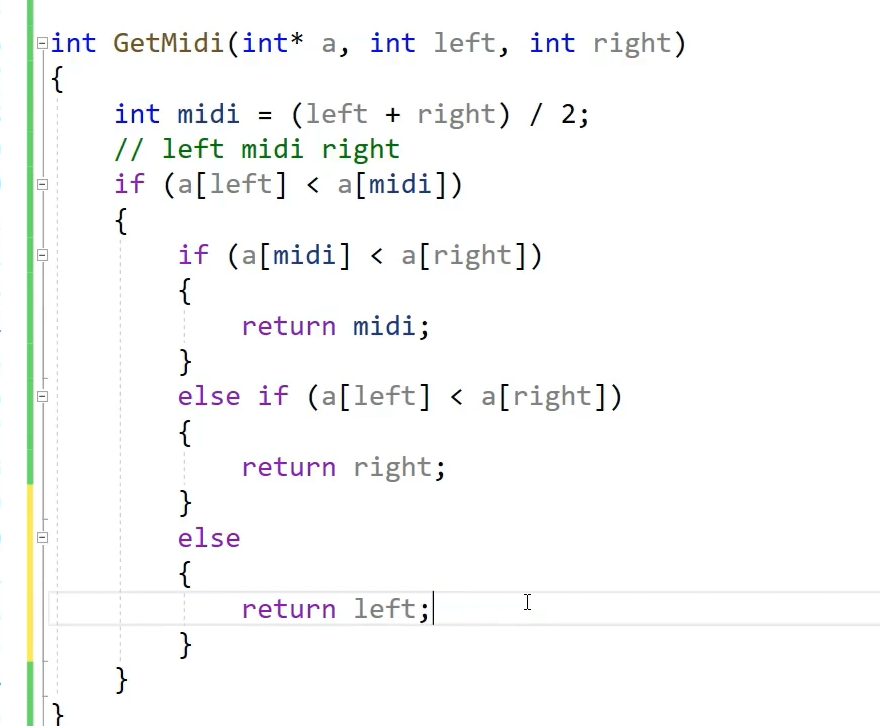 最小值出来最大值出来,中间值就出来
最小值出来最大值出来,中间值就出来
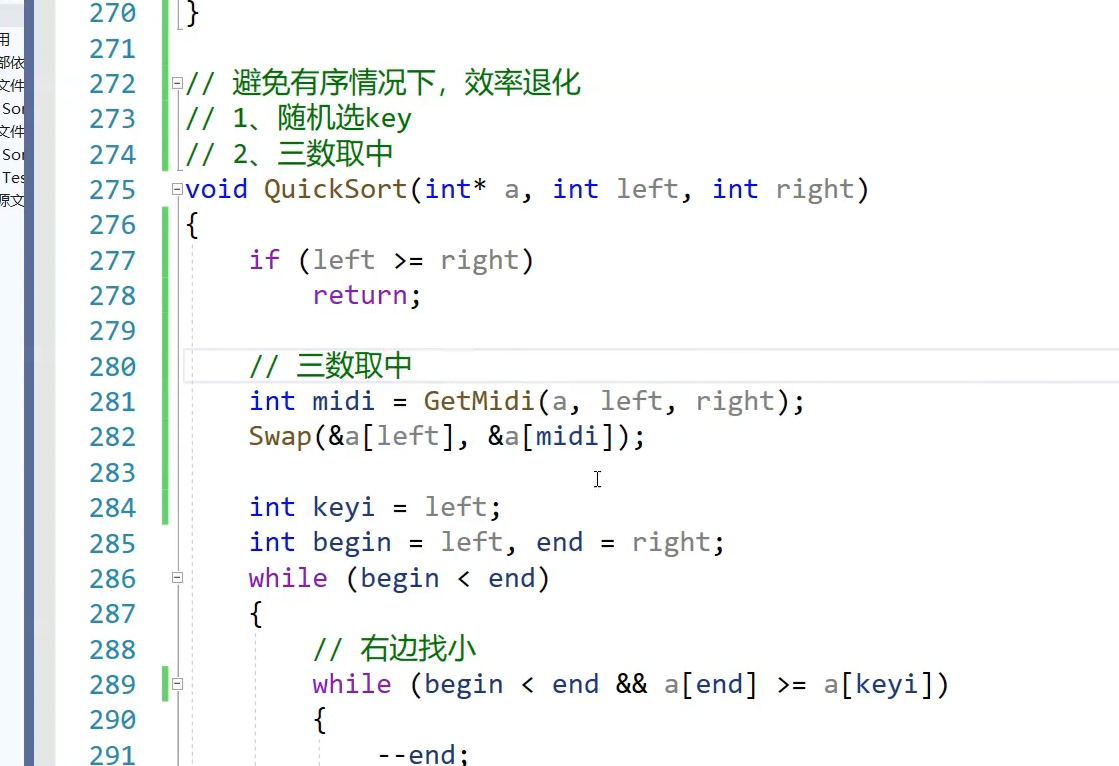
这是有序情况下前面改成a4了取中降低了排好序的概率