DAY 39 图像数据与显存-2025.10.3
图像数据与显存
知识点回顾
- 图像数据的格式:灰度和彩色数据
- 模型的定义
- 显存占用的4种地方
a. 模型参数+梯度参数
b. 优化器参数
c. 数据批量所占显存
d. 神经元输出中间状态 - batchisize和训练的关系
作业:今日代码较少,理解内容即可
笔记:
1. 图像数据的格式:灰度和彩色数据
1.1 灰度图像(MONO)
- 数据结构:单通道,每个像素仅包含一个亮度值,范围通常为 0(黑)到 255(白)。例如,医学影像(如 X 光片)和边缘检测任务常用此格式。
- 存储效率:每像素占 8 位(1 字节),1024×1024 分辨率的图像仅需 1MB 内存,比彩色图像节省 2/3 空间。
- 处理特点:
- 数据访问:二维数组(如 OpenCV 的Mat类型),直接通过坐标获取像素值。
- 转换方式:可通过加权平均(如
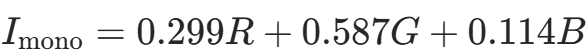 将 RGB 转为灰度,但会丢失色彩信息。
将 RGB 转为灰度,但会丢失色彩信息。 - 计算优势:单通道处理速度更快,适合实时系统(如工业检测)。
1.2 彩色图像(RGB/RGBA)
- 数据结构:
- RGB:三通道,每个像素由红(R)、绿(G)、蓝(B)三个分量组成,每个通道取值 0-255,总占 24 位(3 字节)。
- RGBA:在 RGB 基础上增加透明度通道(Alpha),用于控制图像的透明度,总占 32 位(4 字节)。
- 存储效率:相同分辨率下,RGB 图像占用 3MB 内存,是灰度图的 3 倍。
- 处理特点:
- 数据访问:三维数组,需分别访问 R、G、B 通道。
- 应用场景:适用于需要色彩还原的任务,如图像渲染、物体分类。
- 硬件依赖:更依赖 GPU 的并行计算能力,需匹配特定内存布局(如 Vulkan 的
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL)。
2. 模型的定义
在深度学习中,模型是由神经网络架构、训练流程和超参数组成的计算系统,其核心要素包括:
- 架构选择:
- 网络类型:如卷积神经网络(CNN,用于图像)、循环神经网络(RNN,用于序列)、Transformer(用于自然语言处理)。
- 层结构:包含输入层、隐藏层(如卷积层、全连接层)和输出层,层间通过权重和偏置连接。
- 训练流程:
- 前向传播:输入数据通过网络计算输出预测值。
- 反向传播:根据损失函数(如交叉熵)计算梯度,更新模型参数以最小化损失。
- 超参数配置:
- 学习率、批量大小(batch size)、迭代次数(epoch)等,直接影响模型的收敛速度和性能。
- 优化目标:
- 通过调整参数使模型在训练集上的误差最小化,同时通过正则化(如 L2 正则、Dropout)避免过拟合。
3. 显存占用的 4 种地方
3.1 模型参数 + 梯度参数
- 模型参数:神经网络的权重(weights)和偏置(bias),存储精度(如 FP32、FP16)直接影响显存占用。例如,6B 参数的模型使用 FP16 存储需 12GB 显存。
- 梯度参数:反向传播中计算的参数梯度,与模型参数维度相同。同样使用 FP16 时,6B 模型的梯度占用 12GB。
3.2 优化器参数
- 存储内容:优化器(如 Adam)需存储一阶动量(m)和二阶动量(v),通常以 FP32 精度存储以保证稳定性。例如,AdamW 优化器的状态对 6B 模型需 48GB 显存。
- 内存占比:优化器状态可能占总显存的 50% 以上,是显存消耗的最大头。
3.3 数据批量所占显存
- 输入数据:每个 batch 的图像数据及其预处理结果(如归一化、增强)。例如,32 个 512×512×3 的 RGB 图像需约 24MB 内存。
- 扩展影响:数据批量越大,显存占用线性增加,可能导致显存溢出(OOM)。
3.4 神经元输出中间状态
- 激活值存储:前向传播中每层的输出(如 ReLU 激活值)需暂存以支持反向传播。例如,Transformer 模型的中间扩展层和注意力机制(Q、K、V 矩阵)占用大量显存。
- 优化策略:
- 梯度检查点:通过重新计算部分激活值减少显存占用,但会增加 20-30% 计算时间。例如,6B 模型使用梯度检查点后,激活值内存可从 40-100GB 降至 5-20GB。
- 显存优化工具:如 PyTorch 的
torch.autograd.grad_checkpointing可动态管理激活值存储。
4. batch size 和训练的关系
4.1 核心影响机制
- 梯度计算稳定性:
- 大 batch size:使用更多样本计算梯度,波动小,训练曲线更平滑,但可能陷入局部最优。
- 小 batch size:梯度估计噪声大,更新方向随机性强,可能跳出局部最小值,但训练过程不稳定。
- 内存与计算效率:
- 大 batch size:显存占用高,但可充分利用 GPU 并行性,减少迭代次数(epoch),适合大规模模型。
- 小 batch size:内存需求低,但需更多迭代完成训练,硬件利用率可能不足。
4.2 实际权衡建议
- 硬件限制优先:根据 GPU 显存容量选择最大可行的 batch size,避免 OOM 错误。
- 学习率调整:
- 增大 batch size 时,按比例提高学习率(如线性缩放规则)以保持梯度估计方差稳定。
- 例如,batch size 从 32 增至 128(4 倍),学习率可同步扩大 4 倍。
- 泛化能力平衡:
- 小 batch size 通过引入噪声起到正则化作用,降低过拟合风险,尤其适用于数据量有限的场景。
- 大 batch size 需结合 L2 正则或早停技术以避免过拟合。
- 实验验证:
- 通过交叉验证比较不同 batch size 下的验证集性能,寻找最优平衡点。
- 例如,在 CIFAR-10 数据集上,batch size=128 可能比 batch size=256 的泛化能力更好。
4.3 极端情况分析
- batch size=1(随机梯度下降,SGD):
- 优点:更新频繁,适合在线学习;随机性强,泛化能力好。
- 缺点:训练时间长,梯度波动大,收敛路径曲折。
- batch size = 全量数据(批量梯度下降):
- 优点:梯度计算精确,收敛方向稳定。
- 缺点:内存需求极高,仅适用于小型数据集。
总结
- 图像格式:灰度图节省内存但丢失色彩信息,彩色图需更多显存但支持复杂任务。
- 模型定义:需明确架构、训练流程和超参数,平衡拟合能力与泛化能力。
- 显存管理:优化器状态和中间激活值是显存消耗的主要来源,需通过梯度检查点等技术优化。
- batch size:权衡内存、计算效率和泛化能力,结合学习率调整和正则化策略实现最优训练效果。
作业
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset
from torchvision import datasets , transforms
import matplotlib.pyplot as plttorch.manual_seed(42)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))
])train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)
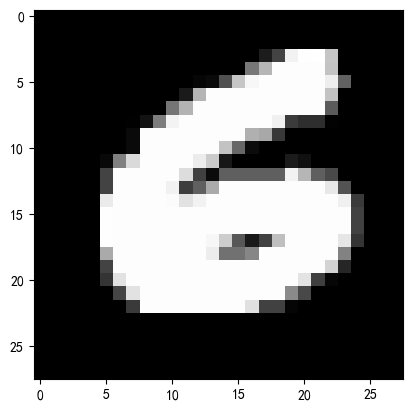
sample_idx = torch.randint(0,len(train_dataset),size=(1,)).item()image,label = train_dataset[sample_idx]def imshow(img):img = img *0.3081 + 0.1307npimg = img.numpy()plt.imshow(npimg[0],cmap='gray')plt.show()print(f'Lable:{label}')
imshow(image)
Lable:6
# 打印下图片的形状
image.shape
torch.Size([1, 28, 28])
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as nptorch.manual_seed(42)
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True
)classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')sample_idx = torch.randint(0,len(trainset),size=(1,)).item()
image,label = trainset[sample_idx]print(f'图像形状:{image.shape}')
print(f'图像类别:{classes[label]}')def imshow(img):img = img / 2 + 0.5npimg = img.numpy()plt.imshow(np.transpose(npimg,(1,2,0)))plt.axis('off')plt.show()# 显示图像
imshow(image)
图像形状:torch.Size([3, 32, 32])
图像类别:frog

transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))
])train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
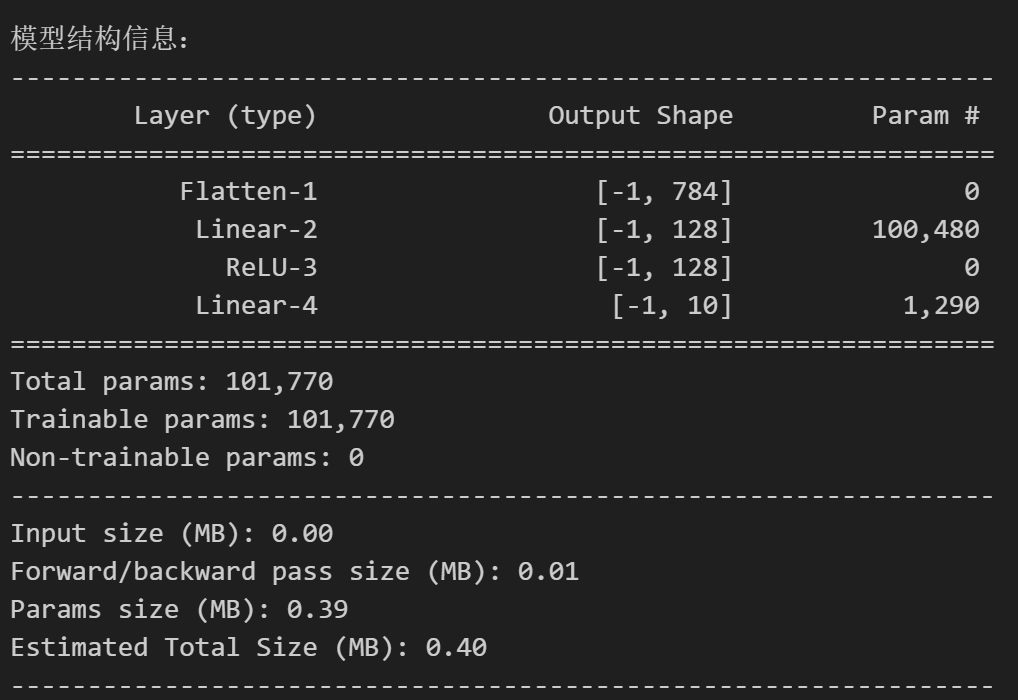
)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten()self.layer1 = nn.Linear(784,128)self.relu = nn.ReLU()self.layer2 = nn.Linear(128,10)def forward(self,x):x = self.flatten(x)x = self.layer1(x)x = self.relu(x)x = self.layer2(x)return xmodel = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸
class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size = 128 , num_classes=10):super(MLP,self).__init__()self.flatten = nn.Flatten()self.fc1 = nn.Linear(input_size,hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size,num_classes)def forward(self,x):x = self.flatten(x)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return xmodel = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32)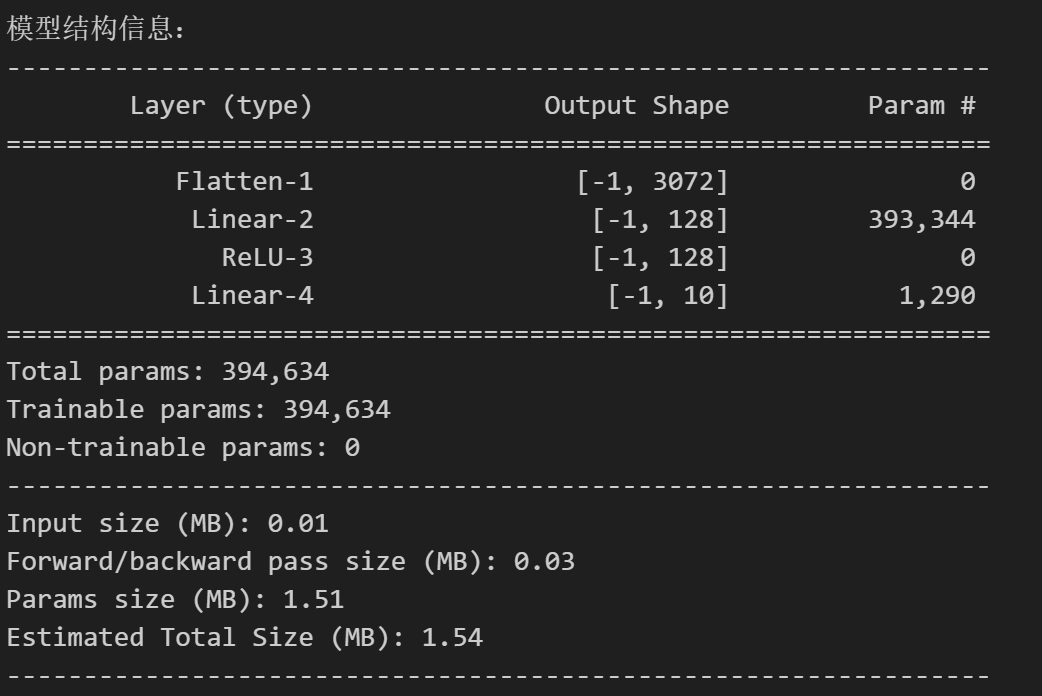
class MLP(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # nn.Flatten()会将每个样本的图像展平为 784 维向量,但保留 batch 维度。self.layer1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.layer2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x) # 输入:[batch_size, 1, 28, 28] → [batch_size, 784]x = self.layer1(x) # [batch_size, 784] → [batch_size, 128]x = self.relu(x)x = self.layer2(x) # [batch_size, 128] → [batch_size, 10]return x
from torch.utils.data import DataLoader# 定义训练集的数据加载器,并指定batch_size
train_loader = DataLoader(dataset=train_dataset, # 加载的数据集batch_size=64, # 每次加载64张图像shuffle=True # 训练时打乱数据顺序
)# 定义测试集的数据加载器(通常batch_size更大,减少测试时间)
test_loader = DataLoader(dataset=test_dataset,batch_size=1000,shuffle=False
)
@浙大疏锦行