AI模型测评平台工程化实战十二讲(第六讲:大模型测评系统:智能模型管理模块的设计与实现)
引言
在大模型快速发展的今天,如何高效管理和调度各种AI模型已成为企业级应用的核心挑战。不同的模型提供商、不同的API接口、不同的功能特性,如何在统一的框架下实现即插即用的模型管理?本文将深入探讨我们在大模型测评系统中设计的智能模型管理模块,从架构设计、功能特性到即插即用模式,全面解析这一核心模块的技术实现和业务价值。
图1:模型管理模块概览
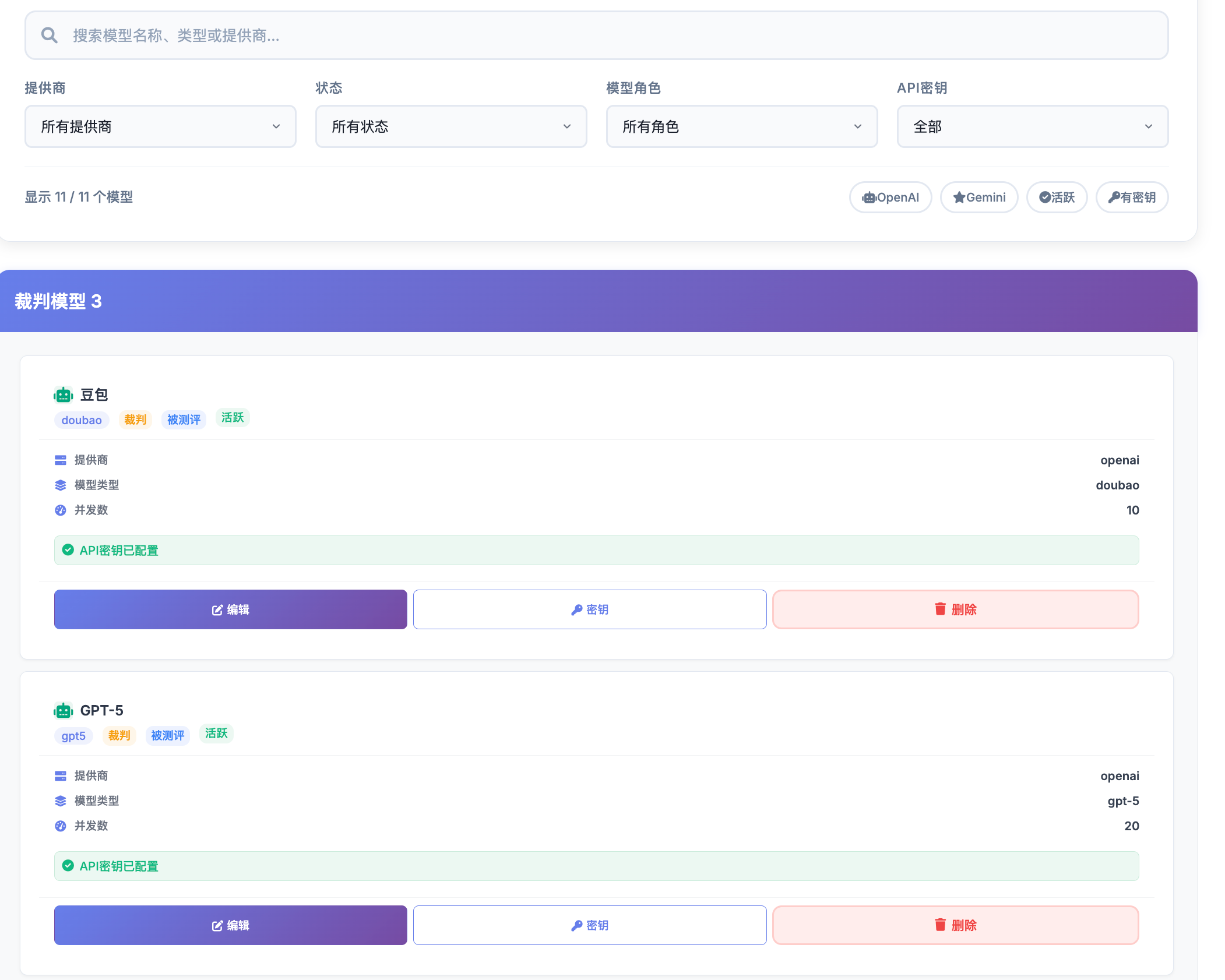
上图展示了模型管理模块的整体架构,包括统一的模型工厂、多样化的模型客户端、以及丰富的功能模块配置。
一、模型管理模块的核心价值
1.1 统一接口,差异实现
在AI模型生态中,每个厂商都有自己独特的API设计、认证方式和功能特性。传统的做法是为每个模型编写独立的调用代码,这不仅增加了维护成本,还使得系统难以扩展。我们的模型管理模块通过工厂模式实现了统一的接口设计:
class EnhancedModelFactory:"""增强版模型工厂类"""def __init__(self):self.clients = {'copilot': copilot_client, # HK Copilot API'legacy': legacy_client, # HK Legacy API 'doubao': doubao_client, # 字节跳动豆包'gpt5': gpt5_client, # OpenAI GPT-5'gemini': GeminiClient() # Google Gemini}
这种设计使得系统能够:
- 统一调用接口:所有模型都通过相同的
query_model方法调用 - 差异化管理:每个模型可以有自己的配置、认证和功能特性
- 动态扩展:新增模型只需实现标准接口即可无缝集成
1.2 配置驱动的灵活性
模型管理模块采用配置驱动的设计理念,通过数据库存储模型配置,实现动态管理。这种设计理念的核心在于将业务逻辑与配置数据分离,使得系统具有极高的灵活性和可维护性。
配置驱动的优势:
-
热更新能力:无需重启服务即可修改模型配置,这对于生产环境中的模型切换和参数调优至关重要。当发现某个模型的性能不佳时,管理员可以立即调整其配置参数,而不需要中断服务。
-
版本控制:每个配置变更都会记录在数据库中,支持配置的版本控制和回滚。当新配置出现问题时,可以快速回滚到之前的稳定版本。
-
环境隔离:不同环境(开发、测试、生产)可以使用完全不同的模型配置,确保环境间的隔离和一致性。
-
权限控制:可以精确控制哪些用户能够访问和修改哪些模型配置,实现细粒度的权限管理。
配置存储架构:
系统采用分层配置存储架构,包括环境变量层、数据库层和缓存层:
- 环境变量层:存储敏感的API密钥和基础配置
- 数据库层:存储模型的基础配置和功能特性
- 缓存层:提供高性能的配置读取能力
CREATE TABLE model_configs (id VARCHAR(255) PRIMARY KEY,model_key VARCHAR(100) NOT NULL UNIQUE,display_name VARCHAR(200) NOT NULL,provider VARCHAR(100) NOT NULL,model_type VARCHAR(100) NOT NULL,api_endpoint TEXT,max_concurrent INT DEFAULT 5,max_tokens INT DEFAULT 4096,temperature DECIMAL(3,2) DEFAULT 0.7,timeout_seconds INT DEFAULT 300,is_judge_model BOOLEAN DEFAULT FALSE,is_evaluation_model BOOLEAN DEFAULT TRUE,configuration JSON COMMENT '其他配置参数'
);
这种设计带来的优势:
- 热更新:无需重启服务即可修改模型配置
- 版本管理:支持模型配置的版本控制和回滚
- 环境隔离:不同环境可以使用不同的模型配置
- 权限控制:可以控制哪些用户能够访问哪些模型
二、即插即用的模块化架构
2.1 模型客户端标准化
每个模型客户端都实现统一的接口标准,确保即插即用。这种标准化设计是即插即用架构的核心基础,它确保了不同厂商的模型能够在统一的框架下协同工作。
标准化接口设计:
系统定义了严格的模型客户端接口规范,所有模型客户端都必须实现以下核心方法:
is_available():检查客户端是否可用,包括API密钥配置、网络连接等query_model():执行模型查询的核心方法,支持统一的参数传递get_model_config():获取模型配置信息validate_model():验证模型配置的有效性
接口设计的考虑因素:
- 异步支持:所有接口都支持异步调用,确保高并发性能
- 错误处理:统一的错误处理机制,便于问题排查和监控
- 参数标准化:统一的参数格式,简化调用方的使用复杂度
- 扩展性:接口设计考虑了未来功能的扩展需求
实现示例:
以豆包模型客户端为例,展示了标准化的实现方式。豆包模型是字节跳动推出的AI模型,具有独特的功能特性和API设计。通过标准化接口,我们将其无缝集成到系统中:
class BaseModelClient:"""模型客户端基类"""def is_available(self) -> bool:"""检查客户端是否可用"""passasync def query_model(self, prompt: str, api_key: str = None, retry_count: int = 3, is_judge: bool = False) -> str:"""查询模型"""pass
以豆包模型为例,展示了标准化的实现:
class DoubaoClient:"""豆包模型客户端"""def __init__(self):self.api_key = os.getenv("ARK_API_KEY")self.base_url = "https://ark.cn-beijing.volces.com/api/v3/bots"self.model_name = "bot-20250905095221-hmr9n"self.timeout = REQUEST_TIMEOUTdef is_available(self) -> bool:"""检查豆包客户端是否可用"""return self.api_key is not Noneasync def query_model(self, prompt: str, api_key: str = None, retry_count: int = 3, is_judge: bool = False) -> str:"""查询豆包模型"""# 实现具体的API调用逻辑pass
2.2 功能模块的即插即用
不同模型支持不同的功能特性,系统通过配置化的方式实现功能模块的即插即用。这种设计使得系统能够灵活地支持各种模型的特有功能,而不需要修改核心代码。
功能模块化设计理念:
现代AI模型往往具有丰富的功能特性,如联网搜索、代码生成、图像理解等。传统的硬编码方式无法适应这种多样性,因此我们采用了模块化的设计理念:
- 功能抽象:将各种功能抽象为独立的模块
- 配置驱动:通过配置控制功能的启用和禁用
- 动态加载:支持运行时动态加载和卸载功能模块
- 组合使用:不同功能模块可以灵活组合使用
HK模型功能特性:
HK是我们系统中的一个重要模型,它支持多种专业功能模块,每个模块都有其特定的应用场景:
- Web Search(联网搜索):能够实时获取网络信息,适用于需要最新数据的查询场景
- Legal(法律咨询):提供法律法规查询服务,适用于法律相关的专业咨询
- Weather(天气预报):集成天气数据API,提供准确的天气预报服务
- Bus(公交查询):支持公交路线和实时信息查询,适用于交通出行场景
- Thinking(思维链):展示模型的推理过程,提高答案的可解释性
- Finance(金融数据):提供金融数据查询和分析功能
- Sensitive(敏感过滤):自动识别和过滤敏感内容,确保内容安全
功能模块的实现机制:
每个功能模块都通过JSON配置进行管理,支持细粒度的控制:
# HK功能配置示例
features_config = {"web_search": False, # 联网搜索功能"legal": False, # 法律法规咨询"weather": True, # 天气预报查询"bus": False, # 公交路线查询"thinking": False, # 思维链展示"finance": False, # 金融数据查询"sensitive": True # 敏感内容过滤
}
这些功能模块通过数据库配置进行管理,支持:
- 动态开关:可以随时启用或禁用特定功能
- 组合使用:可以同时启用多个功能模块
- 条件控制:可以根据不同场景使用不同的功能组合
2.3 认证方式的统一管理
不同模型使用不同的认证方式,系统通过环境变量和数据库配置实现统一管理。这是模型管理模块的一个重要挑战,因为不同的AI服务提供商采用了完全不同的认证机制。
认证方式的多样性:
在AI模型生态中,不同的服务提供商采用了不同的认证方式:
- API Key认证:大多数服务使用API Key进行认证,如OpenAI、Google等
- Bearer Token认证:一些服务使用JWT或OAuth Token进行认证
- Cookie认证:某些服务使用Cookie进行会话管理
- 多因素认证:部分企业级服务支持多因素认证
- IP白名单:一些服务支持IP地址白名单认证
统一认证管理架构:
为了应对这种多样性,我们设计了一个统一的认证管理架构:
class AuthenticationManager:"""统一认证管理器"""def __init__(self):self.auth_handlers = {'api_key': APIKeyHandler(),'bearer_token': BearerTokenHandler(),'cookie': CookieHandler(),'oauth': OAuthHandler()}def get_credentials(self, model_name: str) -> dict:"""获取模型认证信息"""model_config = self.get_model_config(model_name)auth_type = model_config.get('auth_type', 'api_key')handler = self.auth_handlers.get(auth_type)if not handler:raise ValueError(f"不支持的认证类型: {auth_type}")return handler.get_credentials(model_name)def validate_credentials(self, model_name: str, credentials: dict) -> bool:"""验证认证信息"""# 实现认证验证逻辑pass
环境变量管理:
系统使用环境变量存储敏感的认证信息,确保安全性:
# OpenAI API配置
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_BASE_URL=https://api.openai.com/v1# Google API配置
GOOGLE_API_KEY=AIzaSyxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
GOOGLE_BASE_URL=https://generativelanguage/v1beta# HK API配置
HK_API_KEY=hk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
HK_BASE_URL=https://api.hk.com/v1# 豆包API配置
ARK_API_KEY=ark-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ARK_BASE_URL=https://ark.cn-beijing.volces.com/api/v3
数据库配置管理:
非敏感的配置信息存储在数据库中,支持动态管理:
# 认证配置示例
AUTHENTICATION_CONFIG = {'HK-V1': {'type': 'copilot_api','env_key': 'HK_API_KEY','headers': {'Authorization': 'Bearer {api_key}'}},'GPT-5': {'type': 'openai_api', 'env_key': 'GPT5_API_KEY','headers': {'Authorization': 'Bearer {api_key}'}},'Gemini': {'type': 'google_api','env_key': 'GOOGLE_API_KEY', 'params': {'key': '{api_key}'}}
}
3.2 深度思考功能
深度思考功能是现代AI模型的一个重要特性,它能够展示模型的推理过程,提高答案的可解释性和可信度。HK模型通过Thinking模式实现了这一功能,让用户能够深入了解模型的思考过程。
深度思考功能的价值:
- 提高可解释性:用户可以看到模型的推理步骤,理解答案的来源
- 增强可信度:透明的推理过程让用户对答案更有信心
- 便于调试:开发者可以通过思考过程发现和修复问题
- 教育价值:用户可以从模型的思考过程中学习推理方法
- 质量控制:通过检查思考过程可以发现逻辑错误
技术实现原理:
深度思考功能通过以下技术手段实现:
- 思维链生成:模型在生成答案时,同时生成详细的推理步骤
- 结构化输出:将思考过程组织成结构化的格式,便于展示
- 步骤标记:为每个推理步骤添加标记,便于识别和跟踪
- 逻辑验证:对推理过程进行逻辑验证,确保合理性
配置管理:
深度思考功能通过配置进行控制,支持灵活的管理:
# 启用thinking功能的配置
thinking_config = {"features": {"thinking": True, # 启用思维链展示"web_search": False,"legal": False,"weather": True}
}# 在API请求中传递配置
payload = {"model": model_config["model"],"features": features_config,"history_messages": [],"query": query,"chat_id": ""
}
用户体验优化:
为了提供良好的用户体验,我们对深度思考功能进行了多项优化:
- 渐进式展示:逐步展示思考过程,避免信息过载
- 交互式控制:用户可以选择查看或隐藏思考过程
- 格式化显示:使用清晰的格式展示推理步骤
- 搜索功能:支持在思考过程中搜索特定内容
上图展示了HK模型在启用Thinking模式时的输出效果,可以看到模型的完整推理过程。
# 启用thinking功能的配置
thinking_config = {"features": {"thinking": True, # 启用思维链展示"web_search": False,"legal": False,"weather": True}
}# 在API请求中传递配置
payload = {"model": model_config["model"],"features": features_config,"history_messages": [],"query": query,"chat_id": ""
}
3.3 并发控制与性能优化
系统通过信号量机制控制并发数量,避免API限流:
class ConcurrentConfigManager:"""并发配置管理器"""def __init__(self):self.semaphores = {}self.configs = {}def get_semaphore(self, model_name: str) -> asyncio.Semaphore:"""获取模型的信号量"""if model_name not in self.semaphores:max_concurrent = self.get_max_concurrent(model_name)self.semaphores[model_name] = asyncio.Semaphore(max_concurrent)return self.semaphores[model_name]async def acquire(self, model_name: str):"""获取并发许可"""semaphore = self.get_semaphore(model_name)return await semaphore.acquire()
3.4 智能重试与错误处理
系统实现了智能重试机制,使用指数退避策略:
async def query_model_with_retry(self, prompt: str, retry_count: int = 3) -> str:"""带重试机制的模型查询"""last_error = Nonefor attempt in range(retry_count):try:# 执行API调用result = await self._make_api_call(prompt)return resultexcept Exception as e:last_error = eif attempt < retry_count - 1:# 指数退避wait_time = 2 ** attemptawait asyncio.sleep(wait_time)continueelse:# 记录错误并抛出log_model_error(f"模型调用失败: {str(e)}")raise e
四、管理界面与用户体验
4.1 可视化模型管理
系统提供了直观的Web管理界面,支持:
- 模型列表展示:显示所有可用模型及其状态
- 配置编辑:可视化编辑模型配置参数
- 功能开关:通过开关控制各种功能模块
- 实时监控:显示模型调用统计和性能指标
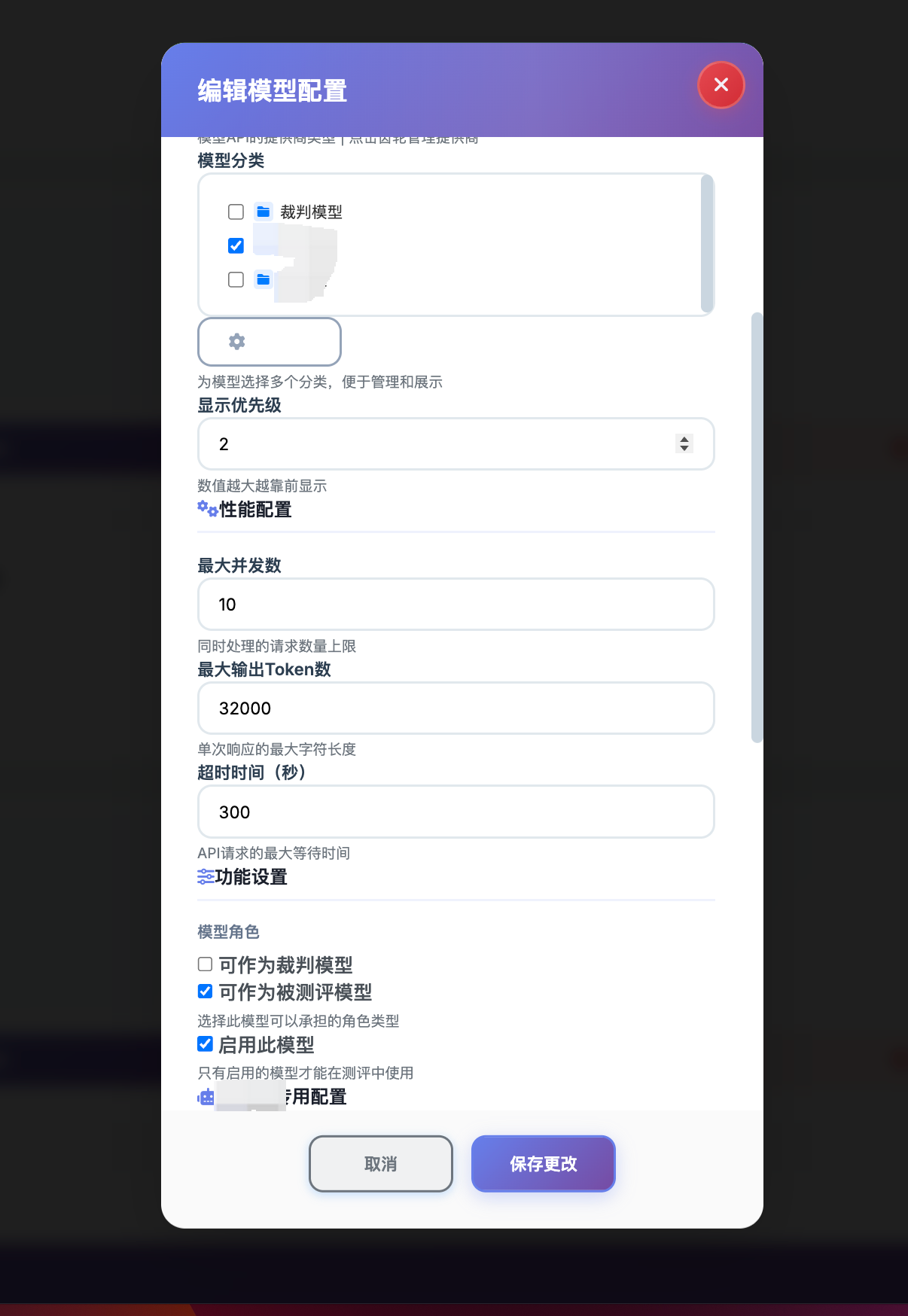
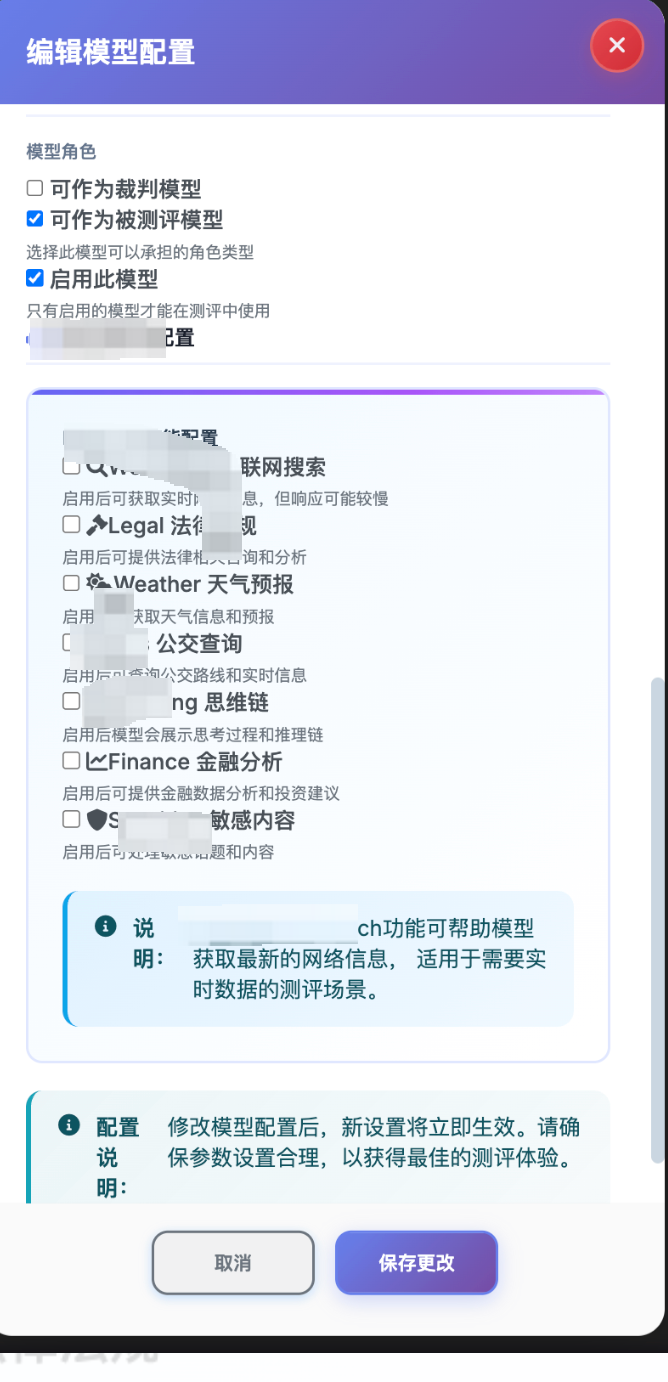
上图展示了模型管理界面的主要功能区域,包括模型列表、配置编辑面板、功能开关控制等。
4.2 配置模板与快速部署
系统提供了配置模板功能,支持快速部署新模型:
# 模型配置模板
MODEL_TEMPLATES = {'openai': {'provider': 'openai','api_endpoint': 'https://api.openai.com/v1','timeout_seconds': 60,'max_tokens': 4096,'temperature': 0.7},'gemini': {'provider': 'google','api_endpoint': 'https://generativelanguage.googleapis.com/v1beta','timeout_seconds': 300,'max_tokens': 8192,'temperature': 0.1}
}
4.3 批量操作与导入导出
支持批量操作和配置的导入导出:
- 批量启用/禁用:可以批量操作多个模型
- 配置导出:将模型配置导出为JSON文件
- 配置导入:从文件导入模型配置
- 配置同步:在不同环境间同步配置
五、安全性与合规性
5.1 API密钥管理
系统采用环境变量和数据库双重管理API密钥:
def get_api_key(model_name: str) -> str:"""安全获取API密钥"""# 从环境变量获取env_key = os.getenv(f"{model_name.upper()}_API_KEY")if env_key:return env_key# 从数据库获取(加密存储)encrypted_key = db.get_encrypted_api_key(model_name)if encrypted_key:return decrypt_key(encrypted_key)return None
5.2 访问控制与审计
实现了细粒度的访问控制:
- 角色权限:不同角色有不同的模型访问权限
- 操作审计:记录所有模型配置的修改操作
- 访问日志:记录模型调用的详细信息
- 敏感数据保护:API密钥等敏感信息加密存储
5.3 数据隐私保护
确保用户数据的安全:
- 数据隔离:不同用户的数据完全隔离
- 传输加密:所有API调用都使用HTTPS
- 存储加密:敏感配置信息加密存储
- 定期清理:自动清理过期的日志和缓存数据
六、性能监控与优化
6.1 实时性能监控
性能监控是模型管理模块的重要组成部分,它帮助我们了解系统的运行状态,及时发现和解决问题。我们构建了一个全面的性能监控体系,涵盖了从基础指标到高级分析的各个层面。
监控指标体系:
我们建立了多层次的监控指标体系:
-
基础性能指标:
- 响应时间:每个模型调用的平均响应时间
- 吞吐量:单位时间内的请求处理数量
- 成功率:成功请求占总请求的比例
- 错误率:失败请求的详细分类和统计
-
资源使用指标:
- CPU使用率:系统CPU资源的使用情况
- 内存使用率:内存资源的占用情况
- 网络带宽:网络流量的使用情况
- 存储空间:数据库和缓存的使用情况
-
业务指标:
- 模型调用次数:每个模型的调用频率
- 用户活跃度:活跃用户的数量和分布
- 功能使用率:各种功能模块的使用情况
- 成本分析:API调用的成本统计
监控数据收集:
系统采用多种方式收集监控数据:
class ModelPerformanceMonitor:"""模型性能监控器"""def __init__(self):self.metrics = defaultdict(list)self.alerts = []self.thresholds = {'response_time': 5.0, # 5秒'error_rate': 0.05, # 5%'success_rate': 0.95 # 95%}def record_call(self, model_name: str, duration: float, success: bool, tokens_used: int, error_type: str = None):"""记录模型调用"""timestamp = time.time()self.metrics[model_name].append({'timestamp': timestamp,'duration': duration,'success': success,'tokens_used': tokens_used,'error_type': error_type})# 检查是否需要告警self._check_alerts(model_name, duration, success)def _check_alerts(self, model_name: str, duration: float, success: bool):"""检查告警条件"""if duration > self.thresholds['response_time']:self._trigger_alert('slow_response', model_name, duration)if not success:self._trigger_alert('api_error', model_name, 'API调用失败')def get_performance_stats(self, model_name: str, time_range: int = 3600) -> dict:"""获取性能统计"""now = time.time()cutoff = now - time_rangestats = [s for s in self.metrics[model_name] if s['timestamp'] > cutoff]if not stats:return {}total_calls = len(stats)successful_calls = sum(1 for s in stats if s['success'])return {'total_calls': total_calls,'successful_calls': successful_calls,'success_rate': successful_calls / total_calls if total_calls > 0 else 0,'avg_duration': sum(s['duration'] for s in stats) / total_calls,'max_duration': max(s['duration'] for s in stats),'min_duration': min(s['duration'] for s in stats),'total_tokens': sum(s['tokens_used'] for s in stats),'avg_tokens_per_call': sum(s['tokens_used'] for s in stats) / total_calls}
实时监控仪表板:
我们开发了一个直观的监控仪表板,提供实时的性能数据展示:
- 实时图表:使用WebSocket推送实时数据更新
- 历史趋势:展示性能指标的历史变化趋势
- 对比分析:支持不同模型间的性能对比
- 告警管理:集中管理各种告警和通知
告警机制:
系统实现了智能的告警机制,能够及时发现和处理问题:
- 阈值告警:当性能指标超过预设阈值时触发告警
- 异常检测:使用机器学习算法检测异常模式
- 趋势告警:当性能指标出现异常趋势时触发告警
- 组合告警:多个指标组合触发复合告警
class ModelPerformanceMonitor:"""模型性能监控器"""def record_call(self, model_name: str, duration: float, success: bool, tokens_used: int):"""记录模型调用"""self.metrics[model_name].append({'timestamp': time.time(),'duration': duration,'success': success,'tokens_used': tokens_used})def get_performance_stats(self, model_name: str) -> dict:"""获取性能统计"""stats = self.metrics[model_name]return {'total_calls': len(stats),'success_rate': sum(1 for s in stats if s['success']) / len(stats),'avg_duration': sum(s['duration'] for s in stats) / len(stats),'total_tokens': sum(s['tokens_used'] for s in stats)}
结语
模型管理模块作为大模型测评系统的核心组件,通过其创新的设计理念、完善的技术实现和丰富的功能特性,为AI应用的快速发展提供了坚实的技术基础。我们相信,随着技术的不断发展和应用的不断深入,模型管理模块将在AI产业的发展中发挥越来越重要的作用,为人类社会的发展做出更大的贡献。
通过持续的创新和优化,我们将继续完善模型管理模块,为AI技术的普及和应用提供更好的技术支撑,推动AI产业向更高层次发展。我们期待与更多的开发者和企业合作,共同推动AI技术的发展和应用,为构建更美好的智能世界贡献力量。
本文详细介绍了大模型测评系统中模型管理模块的设计理念、技术实现和最佳实践。通过统一的接口设计、配置驱动的灵活性和即插即用的模块化架构,我们构建了一个强大而灵活的模型管理平台,为AI应用的快速发展提供了坚实的技术基础。我们期待与更多的开发者和企业合作,共同推动AI技术的发展和应用,为构建更美好的智能世界贡献力量。