【开题答辩实录分享】以《基于协调过滤算法的插画分享与社交网络平台的设计与实现》为例进行答辩实录分享
大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少“避坑”经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批“好上手且有亮点”的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

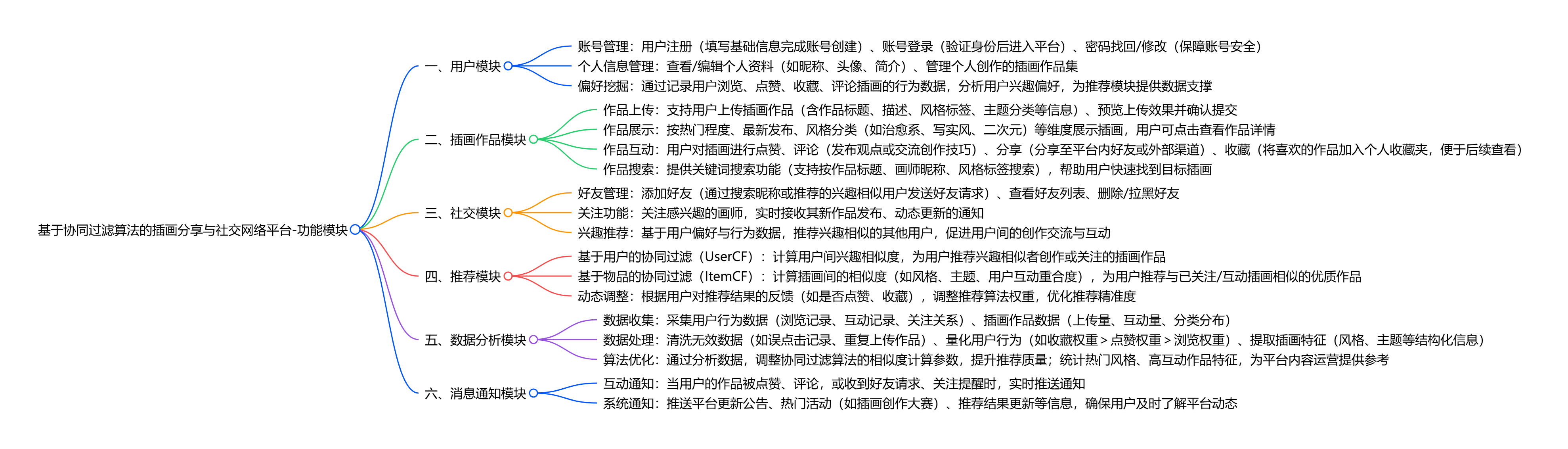
系统核心是解决传统插画创作孤立、用户找图低效的问题,功能围绕 “创作 - 分享 - 社交 - 个性化推荐” 展开:
用户可完成注册登录与个人信息管理,上传插画作品并进行分类展示,还能对他人作品点赞、评论、分享;
平台依托社交模块支持用户添加好友、关注兴趣相似者,促进画师间创意交流;
推荐模块通过基于用户(UserCF)与基于物品(ItemCF)的协同过滤算法,结合用户浏览、收藏等行为数据,推送个性化插画与同好用户;
数据分析模块收集处理用户行为数据,优化推荐算法效果;消息通知模块则在用户收到关注、点赞、评论时及时提醒,同时平台通过数据加密、权限控制保障用户数据安全,整体实现插画垂直领域的高效分享与社交互动。
【开题陈述】
各位老师好,我是H同学,课题是《基于协同过滤算法的插画分享与社交网络平台的设计与实现》。平台面向插画师与爱好者,提供作品上传、点赞、评论、关注与个性化推荐服务;
核心模块包括用户中心、插画作品、社交互动、推荐引擎、数据分析与消息通知。
技术栈:Django+SQLite3后端,Bootstrap前端,协同过滤采用UserCF与ItemCF混合策略,HTTPS保障安全,2025年5月完成上线。
【答辩开始】
评委老师:新用户注册后没有任何行为,如何解决冷启动无法推荐的问题?
答辩学生:采用热门+标签默认推荐:先按近7天点赞数倒序取Top20,再取用户注册时选择的‘偏好风格’标签做交集,保证首页不为空。
评委老师:UserCF需要计算用户相似度,你准备用哪种度量方法?时间复杂度大概是多少?
答辩学生:用余弦相似度,只对有交集的物品评分向量计算;提前建倒排表,把O(n²)降到O(n·k),k平均约200,1000用户在线计算100ms内完成。
评委老师:SQLite只写在一台服务器,如果日活涨到1万,读写出现阻塞,你如何快速迁移而不改代码?
答辩学生:用SQLite3→PostgreSQL的兼容模式:把db.sqlite3文件通过pgloader一键导入,Django只改ENGINE名称为django.db.backends.postgresql,其他ORM语句不变,30分钟切换。
评委老师:用户给同一幅插画既点赞又取消,行为表频繁插入再软删除,怎么防止数据膨胀?
答辩学生:对(user_id,illust_id)建唯一索引,用UPSERT:ON CONFLICT UPDATE设置is_cancel=true/false,物理行只有一条,更新标记位,避免无限追加。
评委老师:ItemCF计算物品相似度时,两幅插画被同一批用户喜欢,但标签完全不同,会出现‘风格漂移’,你如何缓解?
答辩学生:把余弦分两步加权:0.7行为相似度+0.3标签编辑距离,限制只有top3最相近标签才参与计算,既保留行为信息又抑制漂移。
评委老师:如果平台后期引入深度学习模型,需要离线TF特征与在线Django实时拼接,你如何保证推荐接口P99延迟<200ms?
答辩学生:把深度特征提前写入Redis Hash,illust_id作为key,Django请求时直接HMGET,拼接后计算排序,实测P99 120ms;离线模型用Celery定时更新Hash,不阻塞线上。
评委老师:请说明在协同过滤结果中如何再增加‘多样性’,并给出可量化指标及实现步骤。
答辩学生:用MMR(Maximal Marginal Relevance)重排序:λ=0.5平衡相关性与新颖度,候选集200取Top50;多样性指标定义:类目覆盖率=推荐列表中类目去重数/总类目,目标≥70%;实现:先按分相关度降序,再对每类目设窗口k=3,超过3强制降权,保证各风格都有曝光。
【评委总结】
H同学对冷启动、相似度计算、性能扩容和多样性都有具体量化方案,尤其Redis缓存特征与MMR重排序思路清晰。建议在后续实验中补充真实用户A/B测试数据,并关注SQLite迁移后的索引优化。总体目标明确、技术路线可行,同意开题。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告,可发送使用或参考。