Spring cloud快速入门
Spring cloud快速入门
说明
本文章是作者的学习笔记,基于尚硅谷的教学来写的。
源码地址:YoyuDev/springCloudLearn: 作者的学习笔记
学习中遇到需要的服务(sentinel,seata,nacos),可以去官网下载,下文有教学。
作者也将其上传到了git仓库,
1、可以利用lfs拉取到本地:
git lfs install
git clone <repo_url>
拉取后,Git LFS 会自动下载大文件的实际内容到本地:
git lfs pull
这样tools 压缩包就会出现在本地仓库。
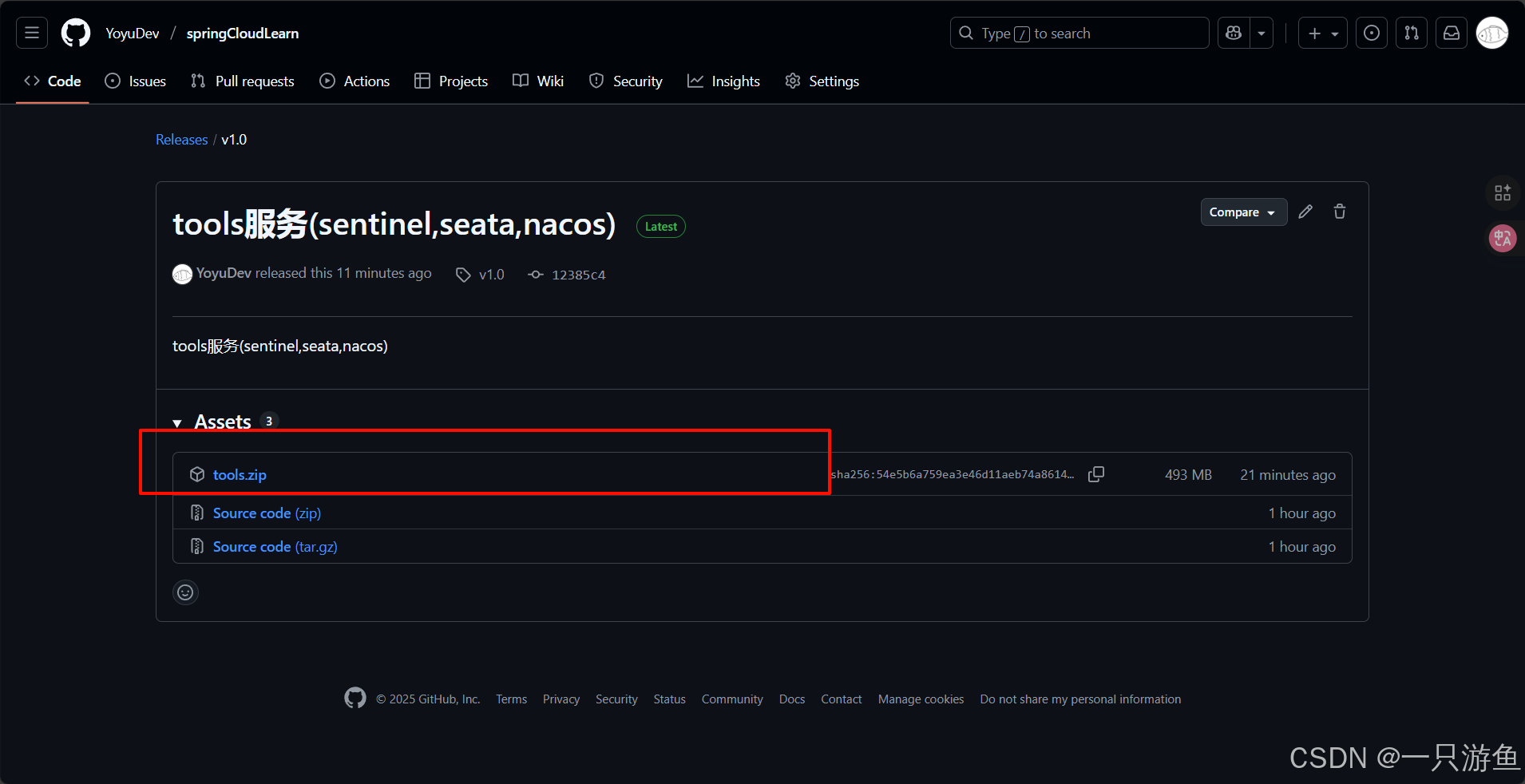
2、直接去 Releases 下载:
或者直接访问Release tools服务(sentinel,seata,nacos) · YoyuDev/springCloudLearn
下载tools.zip
一、简介
1. 微服务(Microservices)
微服务是指一个大型应用程序中的小型、独立的功能单元。每个微服务:
- 专注单一职责:完成特定业务功能(例如用户管理、订单处理)。
- 独立运行:拥有自己的进程、数据库(可选)和技术栈。
- 轻量级通信:通过API(如REST、gRPC)或消息队列(如Kafka)与其他服务交互。
- 独立部署:无需整体重新部署,可单独更新或扩展。
示例:电商系统可能拆分为商品服务、支付服务、物流服务等。
2. 微服务架构(Microservices Architecture)
微服务架构是一种将应用程序构建为一组微服务的系统设计风格,其核心特征包括:
- 服务自治:每个服务独立开发、部署、扩展,团队可专注特定服务。
- 去中心化治理:不同服务可用不同技术(如Java、Go、Python)。
- 分布式系统:服务通常运行在不同服务器或容器中(如Docker、Kubernetes)。
- 容错设计:通过熔断(Hystrix)、重试等机制处理服务故障。
- 独立数据存储:每个服务拥有自己的数据库(如MySQL、MongoDB),避免共享数据库的耦合。
3. 微服务架构 vs 单体架构
| 对比维度 | 单体架构 | 微服务架构 |
| 代码库 | 单一代码库,耦合度高 | 多代码库,低耦合 |
| 部署 | 整体部署,影响范围大 | 独立部署,影响局部 |
| 扩展性 | 横向扩展整个应用 | 按需扩展特定服务 |
| 技术栈 | 统一技术 | 混合技术(更灵活) |
| 开发团队 | 大团队协作 | 小团队负责独立服务 |
4. 微服务架构的优缺点
优点:
- 敏捷性:快速迭代,独立发布。
- 弹性:单个服务故障不影响整体系统。
- 技术多样性:可选用最适合的技术栈。
- 可扩展性:针对高负载服务单独扩展。
缺点:
- 复杂性:分布式系统的网络延迟、事务管理(需Saga模式)、数据一致性。
- 运维成本:需要CI/CD、服务网格(如Istio)、监控(如Prometheus)等工具支持。
- 调试困难:跨服务调用链追踪(需Zipkin、Jaeger)。
5. 适用场景
- 大型复杂应用,需长期迭代。
- 团队规模大,需独立协作。
- 需要快速扩展特定功能(如促销活动的秒杀服务)。
二、spring cloud简介
什么是spring cloud?
Spring Cloud 是一套基于 Spring Boot 的 微服务架构开发工具集,它提供了在分布式系统(如微服务)中快速构建常见模式的工具和组件,简化了微服务架构的开发、部署和运维。
1. Spring Cloud 的核心功能
Spring Cloud 提供了微服务架构所需的多种关键组件,主要包括:
(1)服务注册与发现(Service Discovery)
- 问题:在微服务架构中,服务实例动态变化(扩容、缩容、故障),如何让服务之间互相发现?
- 解决方案:
- Eureka(Netflix 开源):服务注册中心,服务启动时注册自己,其他服务通过 Eureka 查询可用服务实例。
- Consul(HashiCorp):支持服务发现、健康检查、KV 存储。
- Nacos(Alibaba):支持服务注册、配置管理,适用于云原生环境。
(2)客户端负载均衡(Load Balancing)
- 问题:一个服务可能有多个实例,如何均衡地分配请求?
- 解决方案:
- Ribbon(Netflix):客户端负载均衡器,从 Eureka 获取服务列表并按规则(轮询、随机、权重)分发请求。
- Spring Cloud LoadBalancer(替代 Ribbon):Spring 官方提供的负载均衡方案。
(3)API 网关(API Gateway)
- 问题:微服务众多,客户端如何统一访问?如何实现鉴权、限流、路由?
- 解决方案:
- Spring Cloud Gateway(Spring 官方):基于异步非阻塞模型的高性能网关。
- Zuul(Netflix 旧版):早期网关,性能较低,已逐渐被替代。
(4)配置中心(Configuration Management)
- 问题:微服务配置分散,如何统一管理并动态更新?
- 解决方案:
- Spring Cloud Config:支持 Git、SVN 存储配置,可动态刷新。
- Nacos Config:支持配置管理、动态更新。
(5)熔断与容错(Circuit Breaker & Fault Tolerance)
- 问题:某个服务故障,如何防止雪崩效应(级联故障)?
- 解决方案:
- Hystrix(Netflix):熔断、降级、请求缓存(已停止维护)。
- Resilience4J(替代 Hystrix):轻量级容错库,支持熔断、限流、重试。
- Sentinel(Alibaba):流量控制、熔断降级、系统保护。
(6)分布式链路追踪(Distributed Tracing)
- 问题:微服务调用链复杂,如何追踪请求路径、分析性能瓶颈?
- 解决方案:
- Sleuth:生成唯一请求 ID(TraceID、SpanID),集成日志系统。
- Zipkin:可视化调用链路,分析延迟问题。
- SkyWalking(Apache):更强大的 APM(应用性能监控)工具。
2. Spring Cloud 的优缺点
✅ 优点
- 标准化:提供微服务架构的通用解决方案,避免重复造轮子。
- 集成 Spring 生态:与 Spring Boot、Spring Security 无缝协作。
- 社区活跃:丰富的组件和文档,适合企业级开发。
❌ 缺点
- 依赖复杂:组件众多,学习成本较高。
- 版本兼容性问题:Spring Cloud 与 Spring Boot 版本需严格匹配。
- 部分 Netflix 组件过时:如 Eureka、Hystrix 已不推荐使用。
三、项目实战
1、创建项目
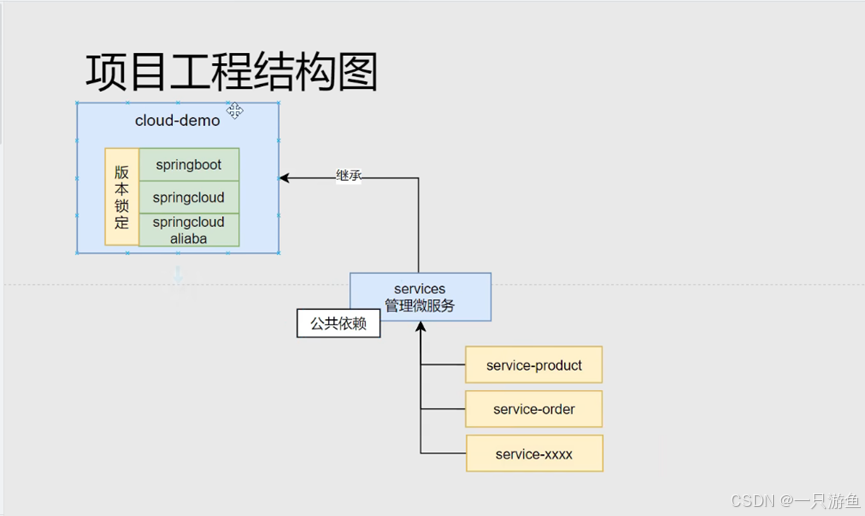
创建项目demo1作为父项目,
写入以下pom依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope>
</dependency>
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version><type>pom</type><scope>import</scope>
</dependency>在demo1下创建model与 服务项目services
Demo1
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>Services
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>annotationProcessor</scope>
</dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope>
</dependency>继续在其下创建项目:
service-order
service-product
service-order 依赖
<dependency><groupId>com.bbs</groupId><artifactId>model</artifactId><version>0.0.1-SNAPSHOT</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.5.6</version></dependency>
<!-- 负载均衡--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>service-product依赖
<dependency><groupId>com.bbs</groupId><artifactId>model</artifactId><version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.5.6</version>
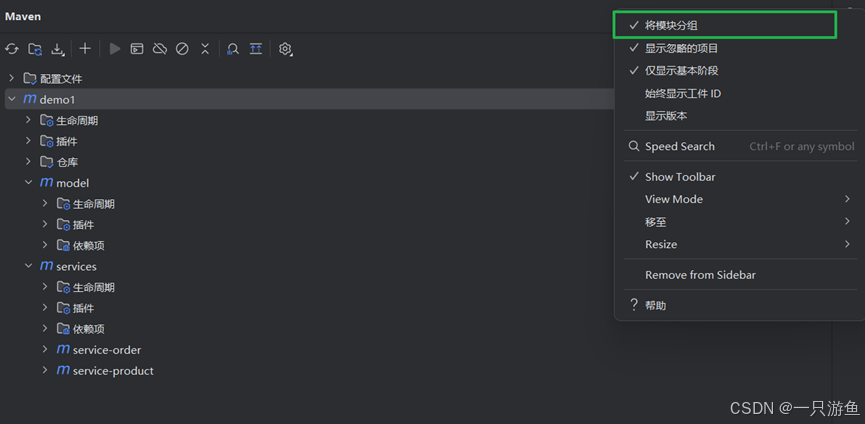
</dependency>刷新maven 仓库,将模块分组,可以看到以下结构:
2、nacos集成
(1)nacos安装
官方网址: Nacos Server 下载 | Nacos 官网
作者下载的是2.4.3版本,建议使用相同的,防止有冲突。
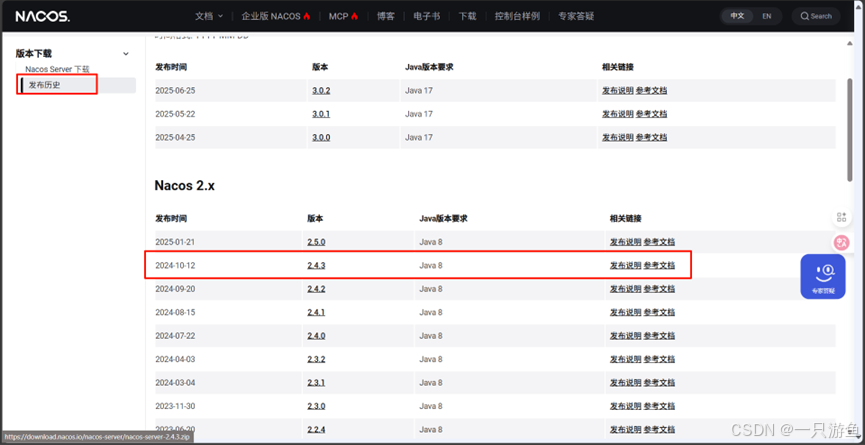
下载后解压到本地,
打开cmd窗口,进入到nacos根目录:
cd nacos-server-2.4.3\nacos\bin运行nacos单机模式:
startup.cmd -m standalone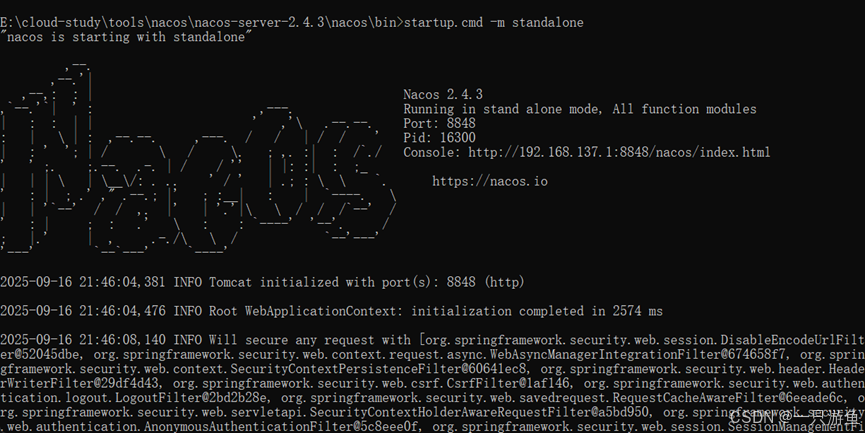
如此启动成功,打开其UI管理界面:
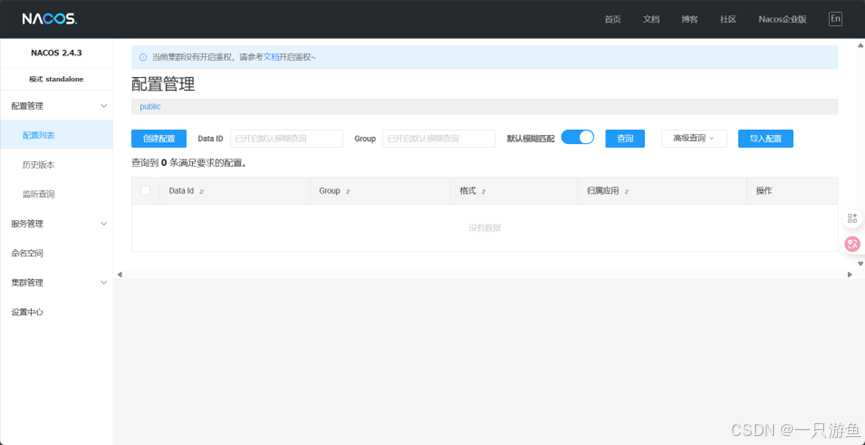
在浏览器输入
http://localhost:8848/nacos
打开如图:
(2)服务注册
添加service-order 与 service-product的启动类与配置文件:
两个的启动类:
@SpringBootApplication
public class OrderMainApplication {public static void main(String[] args) {SpringApplication.run(OrderMainApplication.class, args);}
}Service-order 的application.properties
spring.application.name=order-service
server.port=8000
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848service-product 的application.properties
spring.application.name=product-service
server.port=9000
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848然后分别启动两个项目,,,(前提是nacos服务已经启动)
打开ui管理界面可以看到我们注册的服务:
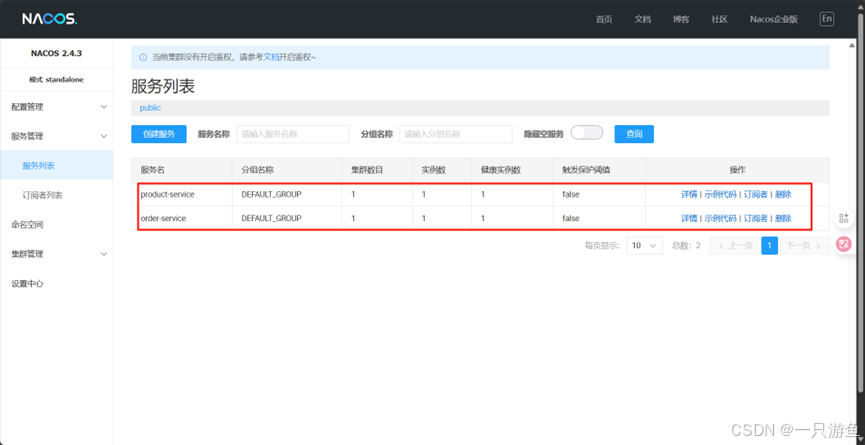
在这里我们利用idea模拟几个端口:
在项目上复制配置
修改选项,程序实参
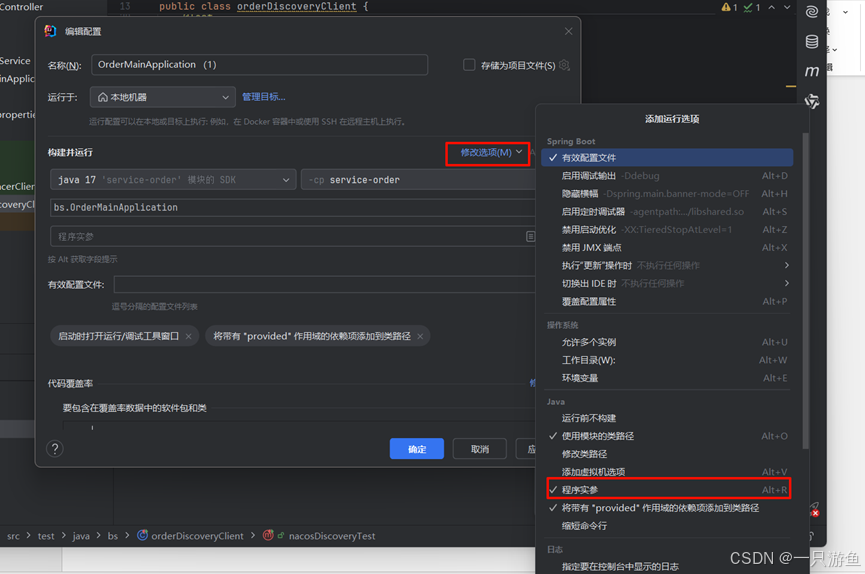
输入—server.port=8001
应用并确定后,启动每个项目

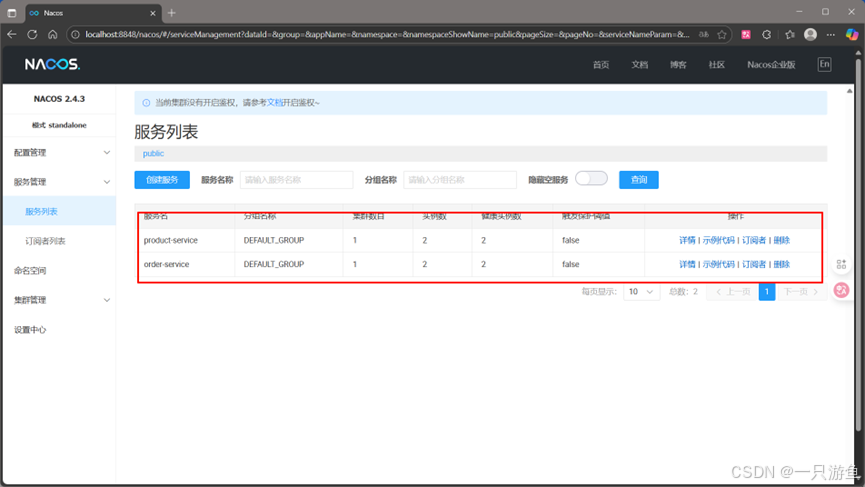
打开UI页面。可以看到注册的实例数发生了改变:
(3)服务发现
在两个项目的启动类中添加服务发现注解:
@EnableDiscoveryClient//开启服务发现功能@SpringBootApplication
public class OrderMainApplication {public static void main(String[] args) {SpringApplication.run(OrderMainApplication.class, args);}
}在test中新建测试类,用来测试服务发现:
/** 输出服务列表信息Test*/
// 利用springcloud输出@AutowiredDiscoveryClient discoveryClient;@Testvoid discoveryTest(){for (String service : discoveryClient.getServices()) {System.out.println("services=" + service);//获取ip+ portList<ServiceInstance> instances = discoveryClient.getInstances(service);for (ServiceInstance instance : instances) {System.out.println("ip:" + instance.getHost() + " port=" + instance.getPort());}}}
// 利用nacos输出@AutowiredNacosServiceDiscovery nacosServiceDiscovery;@Testvoid nacosDiscoveryTest() throws Exception {for (String service : nacosServiceDiscovery.getServices()) {System.out.println("nacos service=" + service);List<ServiceInstance> instances = nacosServiceDiscovery.getInstances(service);for (ServiceInstance instance : instances) {System.out.println("ip:" + instance.getHost() + " port=" + instance.getPort());}}}由此可以看到输出成功

(4)远程调用
为了测试远程调用,我们创建一个场景:用户下单
在之前创建的model项目中创建实体类:
Order
@Data
public class Order {private Long id;private Long userId;private BigDecimal totalAmount;private String nickName;private String address;private List<Product> productList;}Product
@Data
public class Product {private Long id;private BigDecimal price;private String productName;private int num;
}注意要在用户和订单的项目中引入项目;
<dependency><groupId>com.bbs</groupId><artifactId>model</artifactId><version>0.0.1-SNAPSHOT</version>
</dependency>在service-product项目中,
ProductServiceImpl
@Service
public class ProductServiceImpl implements ProductService {@Overridepublic Product getProductById(Long productId) {Product product = new Product();product.setId(productId);product.setPrice(new BigDecimal(50));product.setProductName("测试商品");product.setNum(100);return product;}
}ProductService
public interface ProductService {Product getProductById(Long productId);
}productController
@Autowired
ProductService productService;//查询商品信息
@GetMapping("/product/{id}")
public Product getProduct(@PathVariable("id") Long productId) {Product product = productService.getProductById(productId);return product;
}Config
@Bean
public RestTemplate restTemplate() {return new RestTemplate();
}在service-order中
Config
@Bean
public RestTemplate restTemplate() {return new RestTemplate();
}orderService
public interface OrderService {Order createOrder(Long productId, Long userId);
}orderServiceImpl(实现负载均衡)
@Autowired
DiscoveryClient discoveryClient;
@Autowired
RestTemplate restTemplate;
@Autowired
LoadBalancerClient loadBalancerClient;//负载均衡调用
@Override
public Order createOrder(Long productId, Long userId) {Product product = getProductFromRemote(productId);Order order = new Order();order.setId(productId);order.setUserId(userId);// 总金额order.setTotalAmount(product.getPrice().multiply(new BigDecimal(product.getNum())));order.setNickName("张三");order.setAddress("上海");// 获取商品信息order.setProductList(Arrays.asList(product));return order;
}private Product getProductFromRemote(Long productId) {// 获取商品信息所在的IP与端口ServiceInstance instance = loadBalancerClient.choose("product-service");//远程URLString url = "http://" + instance.getHost() + ":" + instance.getPort() + "/product/" + productId;log.info("远程请求:{}",url);//给远程发送请求Product product = restTemplate.getForObject(url, Product.class);return product;
}orderController
@Autowired
OrderService orderService;// 创建订单
@GetMapping("/create")
public Order createOrder(@RequestParam("userId") Long userId, @RequestParam("productId") Long productId) {Order order = orderService.createOrder(productId, userId);return order;
}启动后,在浏览器中测试输入
localhost:8000/create?userId=123&productId=456
来查看输出结果:
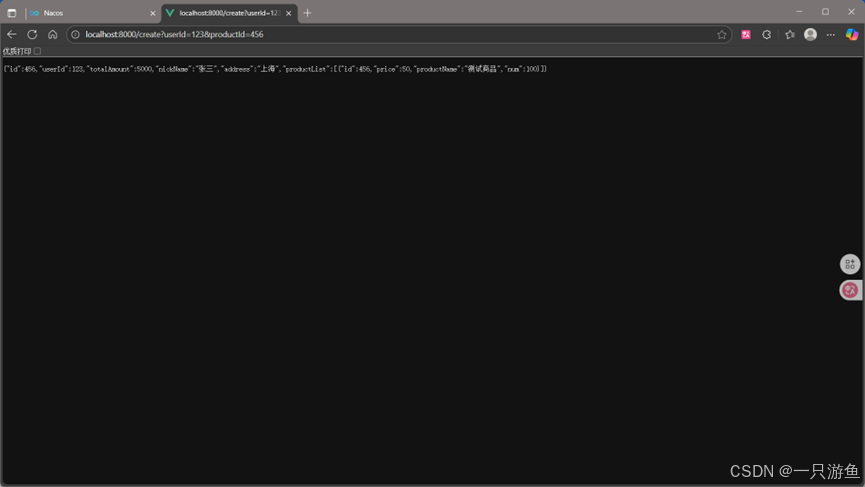
在控制台中查看打印:
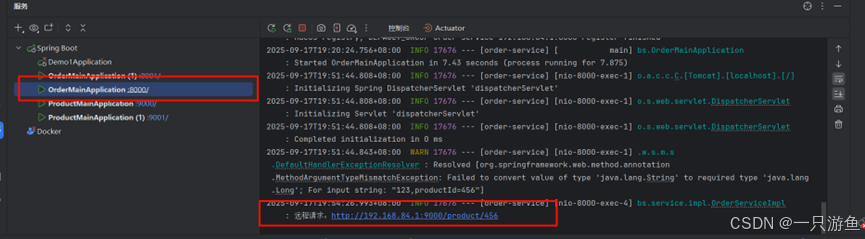
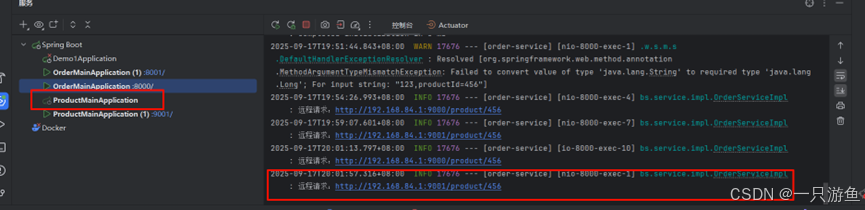
可以看到,默认选择9000这台服务器来服务,这里我们将9000关掉,再次请求,可以看到,nacos自动帮我们选择了正常的服务:9001
进阶:利用注释@LoadBalanced实现负载均衡
在config文件中,添加注释:
@Bean
@LoadBalanced // 注释负载均衡
public RestTemplate restTemplate() {return new RestTemplate();
}//进阶3:注释负载均衡@Overridepublic Order createOrder(Long productId, Long userId) {Product product = getProductFromRemoteZhuShi(productId);Order order = new Order();order.setId(productId);order.setUserId(userId);// 总金额order.setTotalAmount(product.getPrice().multiply(new BigDecimal(product.getNum())));order.setNickName("张三");order.setAddress("上海");// 获取商品信息order.setProductList(Arrays.asList(product));return order;}private Product getProductFromRemoteZhuShi(Long productId) {String url = "http://product-service/product/" + productId;//给远程发送请求(product-service会被动态替换为ip+port)Product product = restTemplate.getForObject(url, Product.class);return product;}(5)配置中心
简介
Spring Cloud Nacos 配置中心是阿里巴巴开源的一个动态服务发现、配置管理和服务管理平台,作为配置中心时主要提供以下核心功能和作用:
1. 集中化管理配置
- 将应用程序的所有配置(如数据库连接、服务端口、业务参数等)集中存储在Nacos服务器
- 实现配置的统一管理和维护,避免配置分散在各个应用中的问题
2. 动态配置更新
- 支持配置的动态更新,无需重启应用即可生效
- 通过监听机制实时获取配置变更,实现"热更新"
- 特别适合需要频繁调整参数的场景(如秒杀活动参数调整)
3. 环境隔离
- 提供Namespace(命名空间)概念,实现开发、测试、生产等多环境配置隔离
- 支持Group(分组)概念,可对同一环境下的不同应用或组件进行分组管理
4. 版本管理和历史记录
- 记录配置的变更历史,支持配置回滚
- 可查看配置的修改记录和差异比较
5. 多格式支持
- 支持多种配置格式:Properties、YAML、JSON、XML等
- 满足不同技术栈的需求
6. 高可用和集群
- 支持集群部署,保证配置中心的高可用性
- 配置数据持久化存储,防止丢失
7. 权限控制
- 提供配置的读写权限管理
- 可控制不同团队或成员对配置的访问权限
8. 与Spring Cloud生态集成
- 无缝集成Spring Cloud应用
- 通过@Value注解或@ConfigurationProperties轻松获取配置
- 与Spring Cloud其他组件(如Gateway、Feign等)协同工作
典型应用场景
- 微服务架构中的统一配置管理
- 多环境部署时的配置切换
- 需要动态调整系统参数的场景
- 大规模分布式系统的配置分发
通过Nacos配置中心,开发者可以更高效地管理应用配置,提高系统的灵活性和可维护性,同时降低因配置错误导致的生产事故风险。
例子
在service项目导入依赖:
<!-- 配置中心--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency>在oder-service项目中application.properties文件添加配置:
spring.cloud.nacos.server-addr=127.0.0.1:8848
spring.config.import=nacos:order-service.properties在nacos UI 界面中添加配置并发布:
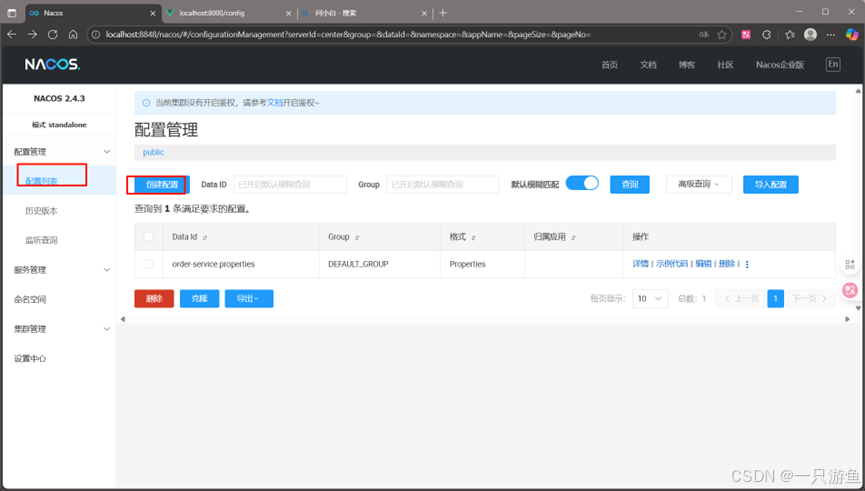
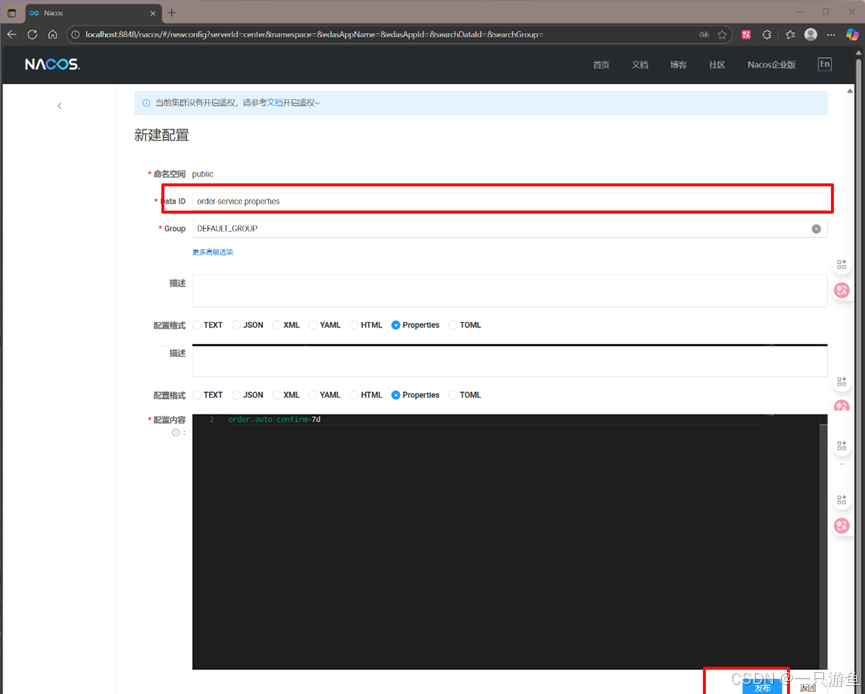
可以看到:
Data ID 为spring.config.import的内容
在控制层中:
添加注解:
@RefreshScope // 动态刷新配置中心//配置中心
@Value("${order.timeout}")
String orderTimeout;
@Value("${order.auto-confirm}")
String orderAutoConfirm;// 获取配置信息
@GetMapping("/config")
public String getConfig() {return "timeout:" + orderTimeout + " autoConfirm:" + orderAutoConfirm;
}重新运行项目,访问
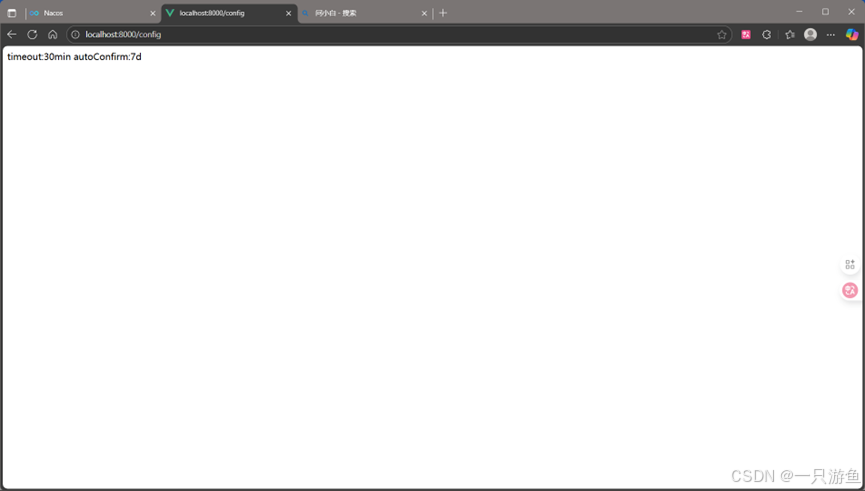
localhost:8000/config
可以看到配置中心 的配置:
注意:添加了配置中心的 依赖后,每个添加的项目都现需要import入配置,
否则运行会报错,,这样就可以在application.properties文件中禁用:
#禁用配置中心
spring.cloud.nacos.config.import-check.enabled=false(6)实现无感动态刷新配置
以上实现的刷新的方法需要配置多个Value ,比较麻烦
这里我们可以使用@ConfigurationProperties注解实现,
创建一个orderProperties类,
@Component
@ConfigurationProperties(prefix = "order") // 批量 绑定在nacos下,配置文件前缀为order
@Data
public class orderProperties {String timeout;String autoConfirm;
}在控制层中:去除@RefreshScope // 动态刷新配置中心注解,
@Autowired
orderProperties OrderProperties;// 获取配置信息
@GetMapping("/config")
public String getConfig() {return "timeout:" + OrderProperties.getTimeout() + " autoConfirm:" + OrderProperties.getAutoConfirm();
}(7)配置监听
在order-service 项目中的启动类中:
@Bean
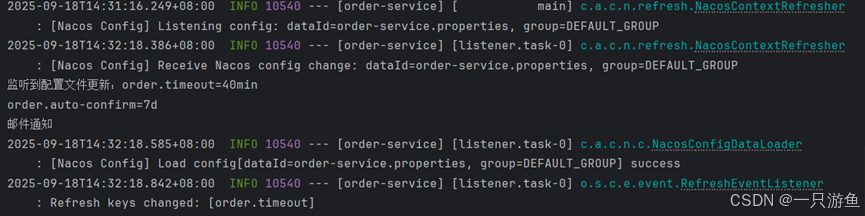
ApplicationRunner applicationRunner(NacosConfigManager nacosConfigManager){return args -> {ConfigService configService = nacosConfigManager.getConfigService();configService.addListener("order-service.properties","DEFAULT_GROUP", new Listener() {@Overridepublic Executor getExecutor() {// 创建线程池return Executors.newFixedThreadPool(4);}@Overridepublic void receiveConfigInfo(String s) {System.out.println("监听到配置文件更新:" + s);System.out.println("邮件通知");}});System.out.println("================================");};
}运行项目,打开nacos UI界面,修改之前的配置,
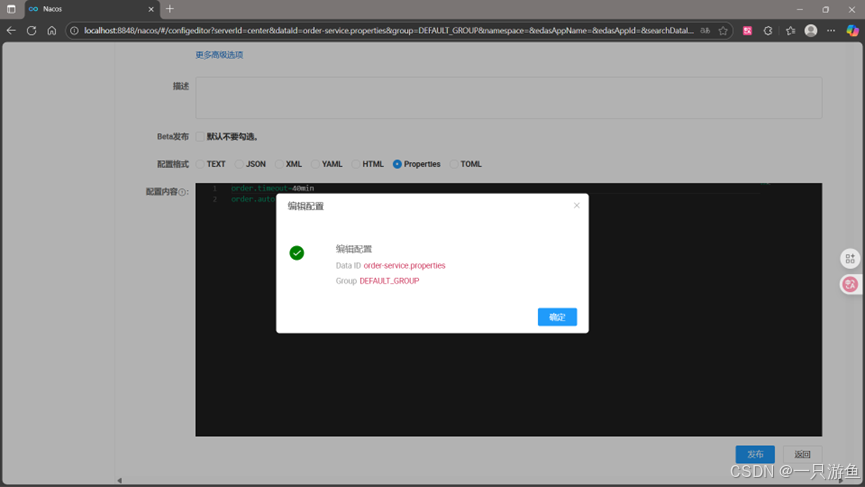
在控制台中可以看到监听的信息:
(7)数据隔离
简介
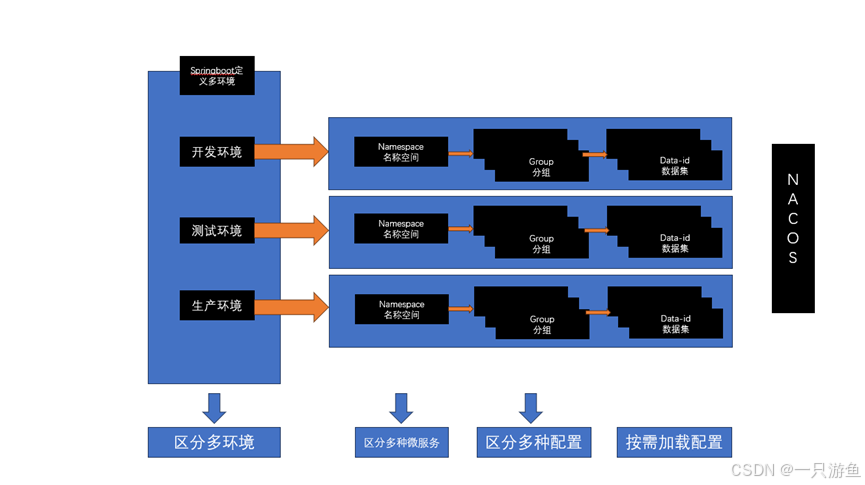
Nacos 的数据隔离是指在不同环境、不同团队或不同业务之间对配置和服务的隔离机制,主要包含以下几种隔离方式:
1. 命名空间 (Namespace) 隔离
- 最高级别的隔离,不同命名空间下的服务注册和配置完全隔离
- 典型应用场景:环境隔离(dev/test/prod)、租户隔离
- 默认使用 "public" 命名空间
2. 分组 (Group) 隔离
- 在同一个命名空间内,通过 Group 进行逻辑分组
- 适用于:不同应用、不同模块的隔离
- 默认分组为 "DEFAULT_GROUP"
3. 服务/配置 (Data ID) 隔离
- 最细粒度的隔离,通过唯一的 Data ID 区分
- 对于配置中心,Data ID 通常是配置文件的名称
- 对于服务发现,Data ID 是服务名称
4. 集群 (Cluster) 隔离
- 在服务注册发现中,可以将服务实例划分到不同集群
- 常用于:同机房优先调用、灰度发布等场景
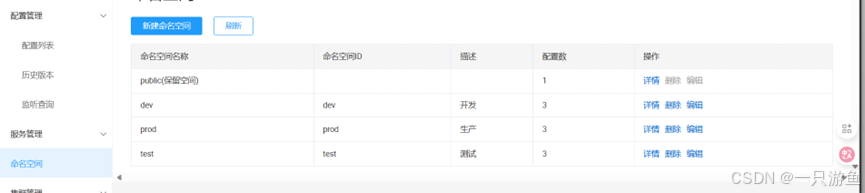
示例:
打开nacosUI界面,命名空间,创建几个命名空间:
新建配置,填入以下信息:
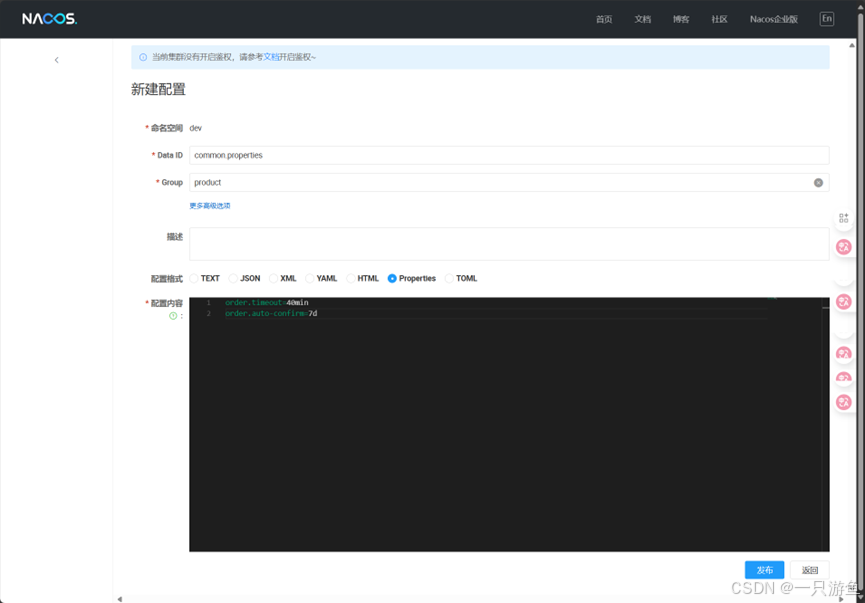
发布完成后,可以进行克隆到其他命名空间来快速创建配置:
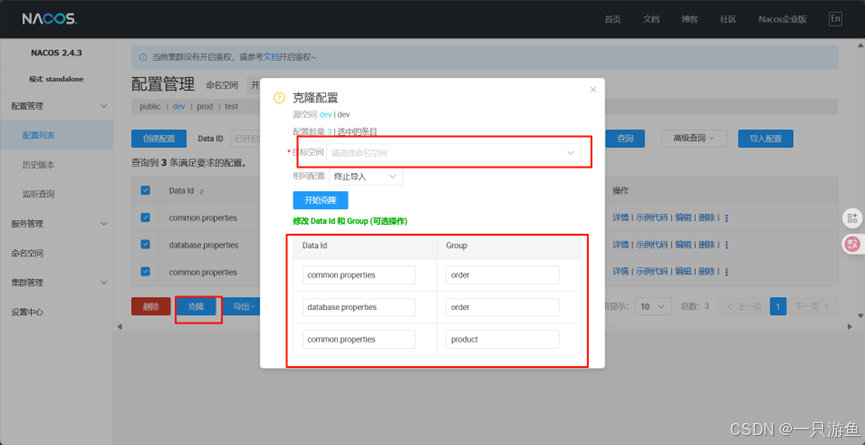
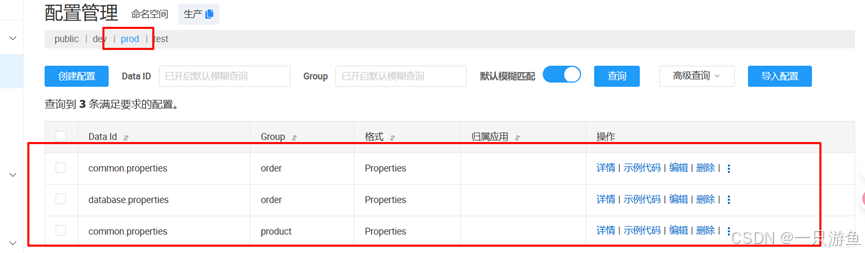
改为使用application.yml文件,添加以下配置:
server:port: 8000spring:application:name: order-servicecloud:nacos:server-addr: 127.0.0.1:8848config:# 指定配置集的命名空间namespace: ${spring.profiles.active:public}# 禁用配置集的导入检查import-check:enabled: false# 使用命名空间profiles:active: prod---# 引入配置指定分组spring:config:import:- nacos:common.properties?group=order- nacos:database.properties?group=order# 指定环境activate:on-profile: dev---
spring:config:import:- nacos:common.properties?group=order- nacos:database.properties?group=order- nacos:common.properties?group=productactivate:on-profile: prod---
spring:config:import:- nacos:common.properties?group=order- nacos:database.properties?group=orderactivate:on-profile: test其中
import:
- nacos:common.properties?group=order
- nacos:database.properties?group=order
- nacos:common.properties?group=product
配置与其命名空间对应的nacos配置相同:
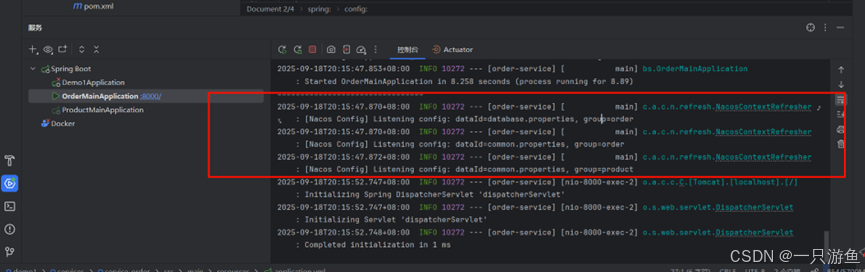
重新运行项目,可以发现配置成功:
3、集成open feign
简介
OpenFeign 是一个声明式的 HTTP 客户端库,主要用于极大地简化在 Java 应用中编写 HTTP 客户端代码,尤其是在微服务架构中进行服务间调用(Service-to-Service Communication)。
作用
1. 声明式 API 定义 (核心)
- 核心思想: 你只需要定义一个 Java 接口,并使用简单的注解(如 @FeignClient, @GetMapping, @PostMapping, @RequestParam, @PathVariable, @RequestBody 等)来描述这个接口应该如何映射到一个 HTTP API。
- 无需实现: 你不需要编写这个接口的实现类。OpenFeign 会在运行时动态生成这个接口的代理实现。
- 简化开发: 将开发者从繁琐的 HTTP 连接管理、参数序列化/反序列化、异常处理等底层细节中解放出来。
2. 简化服务间调用 (主要应用场景)
- 在微服务架构中,服务 A 需要调用服务 B 提供的 RESTful API。
- 使用 OpenFeign,服务 A 的开发人员只需:
- 定义一个接口(例如 UserServiceClient)。
- 用 @FeignClient(name = "user-service") 注解该接口,告诉 OpenFeign 这个客户端要调用哪个服务(user-service 是服务在注册中心的名字)。
- 在接口方法上使用 Spring MVC 风格的注解(如 @GetMapping("/users/{id}"))声明要调用的具体端点、HTTP 方法、路径、参数等。
- 然后,可以像调用本地 Spring Bean 的方法一样,注入并使用这个 UserServiceClient 接口来发起对服务 B 的远程调用。OpenFeign 会自动处理网络通信。
3. 与 Spring Cloud 生态深度集成
- 服务发现: 无缝集成 Spring Cloud Service Discovery(如 Eureka, Consul, Nacos)。通过服务名(name = "user-service")调用,无需硬编码目标服务的 IP 和端口。
- 负载均衡: 自动集成客户端负载均衡(如 Ribbon 或 Spring Cloud LoadBalancer)。当有多个 user-service 实例时,OpenFeign 客户端会自动将请求分发到不同的实例上。
- 熔断与容错: 可以方便地集成 Spring Cloud Circuit Breaker(如 Hystrix, Resilience4j, Sentinel)为调用添加熔断、降级、超时控制等容错能力。
- 编码器/解码器: 内置支持 JSON(如 Jackson, Gson)、XML 等格式的序列化(将 Java 对象转为请求体)和反序列化(将响应体转为 Java 对象)。可以轻松扩展以支持其他格式。
- 请求/响应拦截器: 允许在发送请求前或收到响应后执行自定义逻辑(如添加认证头、记录日志)。
- 错误解码器: 自定义如何处理 HTTP 错误响应(如将非 2xx 状态码转换为特定异常)。
- 日志: 可以配置记录请求和响应的详细信息,方便调试。
4. 类型安全
- 接口方法定义了明确的参数类型和返回值类型。编译器可以进行类型检查,相比手动拼接 URL 字符串和使用 RestTemplate 等方法,大大减少了因类型不匹配或路径错误导致的运行时错误。
5. 集中管理 API 定义
- 将与外部服务交互的 API 定义(接口)集中在一个地方,使代码结构更清晰,更容易维护和重用。
实战
1.声明式调用
依赖
在service项目中引入依赖:
<!-- 远程调用--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId></dependency>启动类添加标注
在service-order项目启动类中添加注释
@EnableFeignClients // 开启feign远程调用功能创建open feign类
@FeignClient(name = "product-service") // 指定服务名称(feign客户端)
public interface ProductFeignClient {// 指定远程服务调用的接口//MVC注解的两套使用逻辑// 1. 标注在Controller上,是接受这样的请求// 2. 标注在FeignCLient上,是发送这样的请求@GetMapping("/product/{id}")Product getProductById(@PathVariable("id") Long id);}调用
在serviceImpl中注释掉使用restTemplate获取商品信息的调用方法,添加:
@Autowired
ProductFeignClient productFeignClient;@Overridepublic Order createOrder(Long productId, Long userId) {// 使用restTemplate获取商品信息
// Product product = getProductFromRemoteZhuShi(productId);Product product = productFeignClient.getProductById(productId);Order order = new Order();order.setId(productId);order.setUserId(userId);// 总金额order.setTotalAmount(product.getPrice().multiply(new BigDecimal(product.getNum())));order.setNickName("张三");order.setAddress("上海");// 获取商品信息order.setProductList(Arrays.asList(product));return order;}注意:open feign不仅可以实现远程调用还可以实现负载均衡的调用,,
为了直观的演示,我们在product-servce项目中的控制层中添加输出:
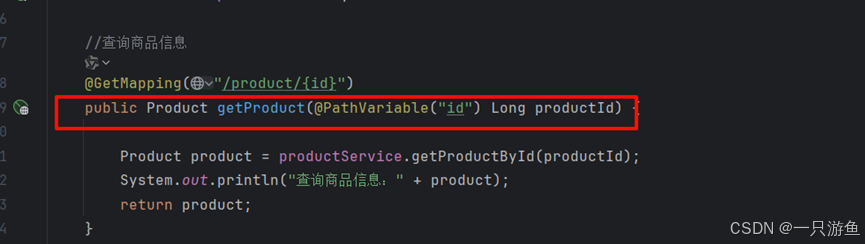
//查询商品信息
@GetMapping("/product/{id}")
public Product getProduct(@PathVariable("id") Long productId) {Product product = productService.getProductById(productId);System.out.println("查询商品信息:" + product);return product;
}启动项目后,在本地请求多次:
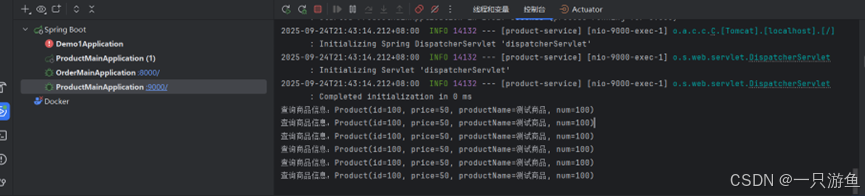
localhost:8000/create?userId=100&productId=100

可以看到成功调用,返回查看控制台:
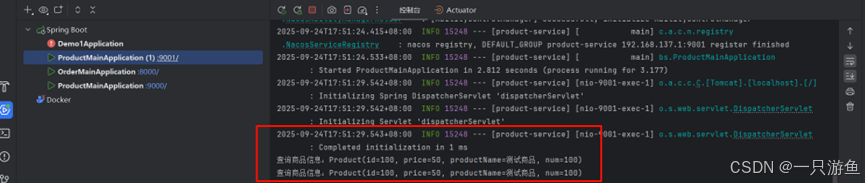
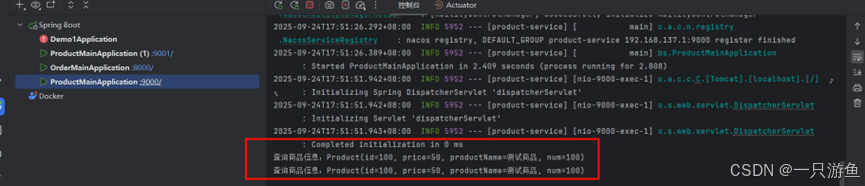
可以看到实现了负载均衡。。。。。。
2.API调用
这里用阿里云的一个天气服务来举一个例子:
首先去查询/购买它的服务,接着找他的接口文档:
创建一个FeignClient
//这里只是做一个演示,并非真的
@FeignClient(value = "weather-client", url = "http://aliv18.data.moji.com")
public interface WeatherFeignClient {@PostMapping("/api/weather/v1/getWeather")String getWeather(@RequestHeader("Authorization") String auth,@RequestParam("token") String token,@RequestParam("cityId") String cityId);
}测试调用
@Autowiredprivate WeatherFeignClient weatherFeignClient;// 测试(这里只是做一个演示)@Testpublic void test() {String weather = weatherFeignClient.getWeather("auth", "token", "cityId");System.out.println(weather);}- 技巧
当你要写一个FeignClient时,只需要复制粘贴对应服务的签名就可以。
例如:

进阶配置
1.日志记录
这里我们直接在product-service服务上测试:
在项目的.yml 配置里配置:
# FeignClient日志级别 bs.feign 是服务fedin的路径
logging:level:bs.feign: debug写一个日志工具:
// feign日志级别@BeanLogger.Level feignLoggerLevel() {return Logger.Level.FULL;}运行项目,并请求,可以看到日志:
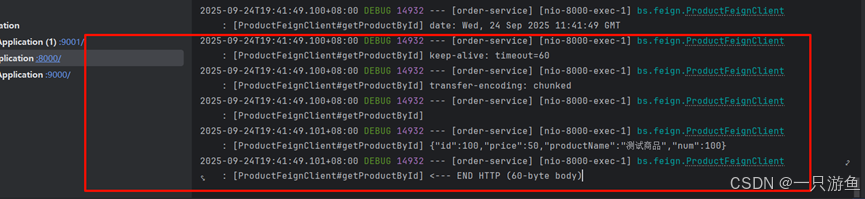
2.超时配置
介绍
场景:在进行服务调用时,会出现 服务器宕机,api读取熟读慢不返回的问题,这样为了防止服务雪崩我们通常用超时控制来实现。。。
一般来说超时控制返回的结果有三种:
- 未超时 -> 返回正确结果
- 超时 -> 中断调用 -> 返回错误信息
- 超时 -> 中断调用 -> 返回兜底数据
然而,Feign设置了默认的配置,这里我们可以做一个测试:
实战
我们先不做任何配置,在商品服务中设置睡眠时间70秒,(读取时间默认是60秒),然后进行请求:
@Override
public Product getProductById(Long productId) {Product product = new Product();product.setId(productId);product.setPrice(new BigDecimal(50));product.setProductName("测试商品");product.setNum(100);//模拟睡眠70 stry {TimeUnit.SECONDS.sleep(70);}catch (InterruptedException e) {e.printStackTrace();}return product;
}运行项目,请求,等待70秒后查看控制台:
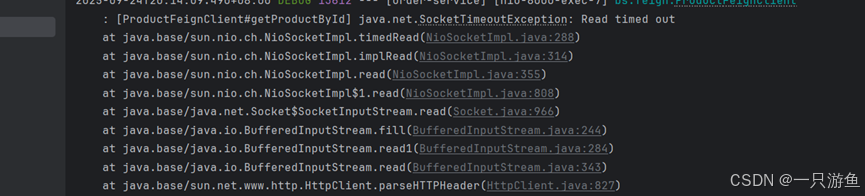
显示超时断开。。
3.自定义配置
在.yml文件里添加:
Spring.profiles.include: feign
来引入配置,创建一个新的.yml: application-feign.yml
spring:cloud:openfeign:client:config:# feign 默认配置defoult:logger-level: fullconnect-timeout: 5000read-timeout: 5000# feign其中的服务配置service-product:#日志级别logger-level: full#连接超时时间connect-timeout: 5000#读取超时read-timeout: 50004.超时重连
在application-feign.yml 里添加:
#超时重连
retryer: feign.Retryer.Default
或者在配置类里:
// feign重试
@Bean
Retryer retryer() {return new Retryer.Default();
}沿用超时配置的睡眠,配置好(3) 超时重连后,请求api,可以看到,控制台重新请求了次:
5.fallback兜底回调
当远程调用失败时,服务端不会返回失败,而是返回默认设置的信息。
实战
创建fallback
@Component
public class ProductFeignClientFallback implements ProductFeignClient {@Overridepublic Product getProductById(Long id) {System.out.println("商品服务调用失败,返回默认商品信息(兜底回调)");Product product = new Product();product.setId(id);product.setProductName("未知商品");product.setNum(0);product.setPrice(new BigDecimal(0));product.setNum(0);return product;}
}在指定的服务名称中设置兜底回调:
@FeignClient(name = "product-service", fallback = ProductFeignClientFallback.class) // 指定服务名称(feign客户端) 兜底回调类
public interface ProductFeignClient {// 指定远程服务调用的接口//MVC注解的两套使用逻辑// 1. 标注在Controller上,是接受这样的请求// 2. 标注在FeignCLient上,是发送这样的请求@GetMapping("/product/{id}")Product getProductById(@PathVariable("id") Long id);}这里需要配合Sentinel来实现,,
加入依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>在application-feign.yml 中配置:
#Feign Sentinel 配置
feign:sentinel:enabled: true为了更好的测试兜底回调,我们现在将所有的商品服务关掉,关闭失败重连,重启项目并请求:

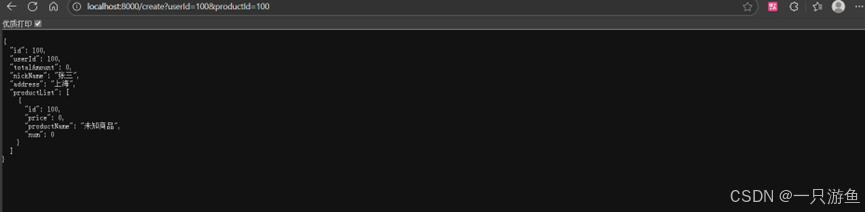
如图,兜底成功。。。
4、集成Sentinel
简介
Sentinel 是阿里巴巴开源的一套 流量控制、熔断降级、系统保护 的组件。
它主要用于微服务架构中,对调用链路进行保护,防止雪崩效应。
在 Spring Cloud 体系里,Sentinel 常作为 服务保护层,和 Spring Cloud Alibaba 集成使用。
主要功能
-
流量控制 (Rate Limiting)
- 按 QPS(每秒请求数)、并发线程数 等指标限流。
- 支持 按调用关系限流(比如 A 调用 B,可以限制 B 在被 A 调用时的流量)。
- 可以设置 匀速排队、预热模式 等。
-
熔断降级 (Circuit Breaking)
- 当调用链路中的某个服务出现不稳定时,自动进行熔断。
- 常见触发条件:
- 异常比例 超过阈值。
- 异常数 超过阈值。
- 平均响应时间 过长。
- 熔断后自动恢复。
-
系统保护
- 从系统整体维度出发,根据 CPU 使用率、内存、平均响应时间、入口 QPS 等指标进行保护,防止服务被压垮。
-
实时监控
- 提供 控制台 (Sentinel Dashboard),可以实时查看调用链路的 QPS、响应时间、限流/熔断情况。
核心流程
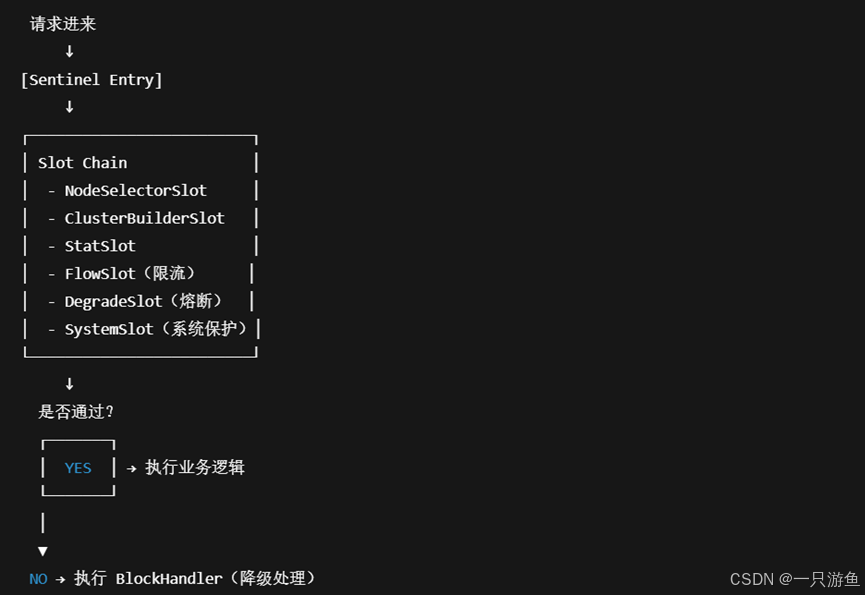
Sentinel 的核心思想是:
所有需要保护的调用,都要经过 Sentinel 的“流量规则检查” → 再决定是否放行。可以类比成一个“流量哨兵”:请求进来时,先经过 Sentinel 的 Slot Chain(插槽链)。
每个 Slot 负责一个功能(比如统计、流控、熔断、系统保护)。
最终根据规则决定:
允许通过(正常调用业务逻辑)
拒绝访问(触发限流/降级/熔断处理逻辑)
实战
(1)sentinel-dashboard的下载 与基础实例
下载网址:sentinel-dashboard
点击这个jar包下载到本地
到其目录上运行,
java -jar sentinel-dashboard-1.8.8.jar
打开其工作台:localhost://8080 他的初始账号和密码都是sentinel


在service项目中添加依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>分别在订单和商品项目中application.properties文件添加配置:
#sentinel
spring.cloud.sentinel.transport.dashboard=localhost:8080
#启动时提前加载
spring.cloud.sentinel.eager=true运行项目后打开sentinel UI 页面,可以看到订单和商品服务成功载入sentinel中:
在订单服务中,控制层里,我们给创建订单的api添加注解:
@SentinelResource("createOrder") // sentinel重启项目后,请求创建订单的api,刷新sentinel UI界面,,可以看到已经监控到它的簇点链路:
(2)异常处理
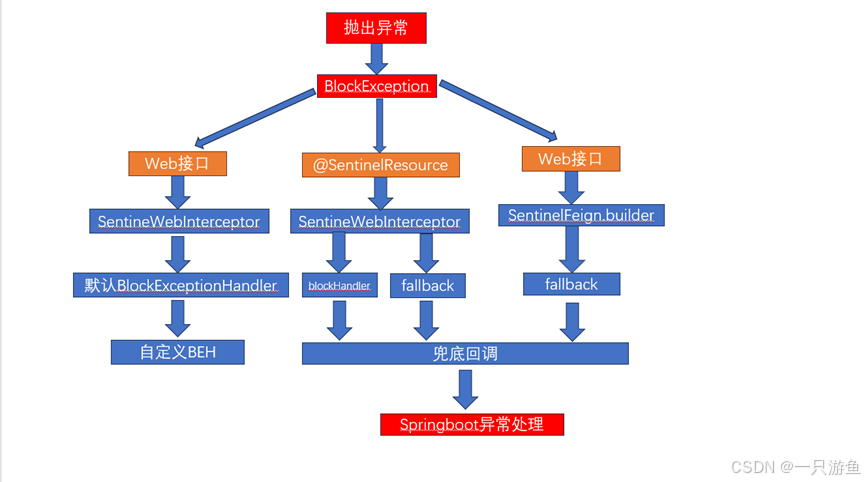
A.Web接口
在model项目中创建Result类,用来封装返回数据
public class Result<T> {private String code;private String msg;private T data;public String getCode() {return code;}public void setCode(String code) {this.code = code;}public String getMsg() {return msg;}public void setMsg(String msg) {this.msg = msg;}public T getData() {return data;}public void setData(T data) {this.data = data;}// 默认构造函数public Result() {}// 带数据的构造函数(用于自定义构造Result对象)public Result(T data) {this.data = data;}// 成功响应的静态方法,不带数据public static Result<?> success() {Result result = new Result<>();result.setCode("200");result.setMsg("成功");return result;}// 成功响应的静态方法,带数据public static <T> Result<T> success(T data) {Result<T> result = new Result<>(data);result.setCode("200");result.setMsg("成功");return result;}// 错误响应的静态方法
// public static Result<?> error(String code, String msg) {
// Result result = new Result<>();
// result.setCode(code);
// result.setMsg(msg);
// return result;
// }
//错误响应的静态方法(支持泛型)public static <T> Result<T> error(String code, String msg) {Result<T> result = new Result<>();result.setCode(code);result.setMsg(msg);return result;}}在订单服务中创建MyBlockException,来处理异常
@Component
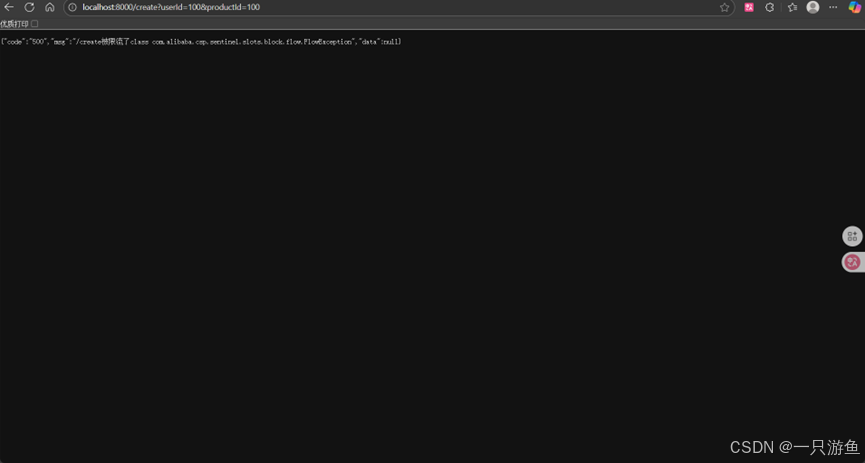
public class MyBlockException implements BlockExceptionHandler {private ObjectMapper objectMapper = new ObjectMapper();@Overridepublic void handle(HttpServletRequest request, HttpServletResponse response,String resourceName, BlockException e) throws Exception {response.setContentType("application/json;charset=utf-8");PrintWriter writer = response.getWriter();Result<Object> error = Result.error("500", resourceName + "被限流了" + e.getClass());String s = objectMapper.writeValueAsString(error);writer.write(s);writer.flush();}
}重启服务,
为了模拟异常,我们重置请求一次/create api
在UI 界面,点击新增流控
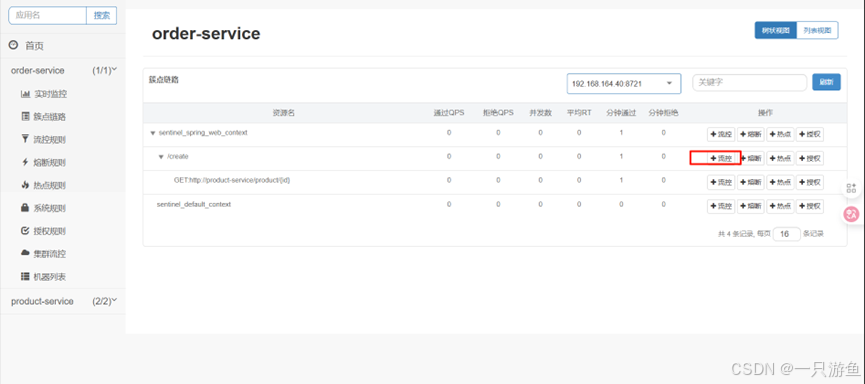
设置单机阈值为1(每秒只能接受1个请求),新增。

然后快速请求 /create 接口,可以发现返回我们自定义的值:
B. SentinelResource
如何在服务层里添加呢?
在OrderServiceImpl.java文件里,添加SentinelResource注解,
@SentinelResource(value = "createOrder",blockHandler = "createOrderFallback") // sentinel添加兜底回调的方法:
@SentinelResource(value = "createOrder",blockHandler = "createOrderFallback") // sentinel@Overridepublic Order createOrder(Long productId, Long userId) {// 使用restTemplate获取商品信息
// Product product = getProductFromRemoteZhuShi(productId);Product product = productFeignClient.getProductById(productId);Order order = new Order();order.setId(productId);order.setUserId(userId);// 总金额order.setTotalAmount(product.getPrice().multiply(new BigDecimal(product.getNum())));order.setNickName("张三");order.setAddress("上海");// 获取商品信息order.setProductList(Arrays.asList(product));return order;}//兜底回调public Order createOrderFallback(Long productId, Long userId, Throwable e) {Order order = new Order();order.setId(productId);order.setUserId(userId);order.setTotalAmount(new BigDecimal(0));order.setNickName("未知用户");order.setAddress("异常信息" + e.getClass());return order;}C.openFeign
当使用了@SentinelResource(value = "createOrder",blockHandler = "createOrderFallback") // sentinel 注解时,如果openFeign 设置了兜底回调, Sentinel会自动调用。
(3)流量控制(FlowRule)
简介
流量控制是指sentinel 限制多余的请求,从而保护系统资源不被耗尽。
流程
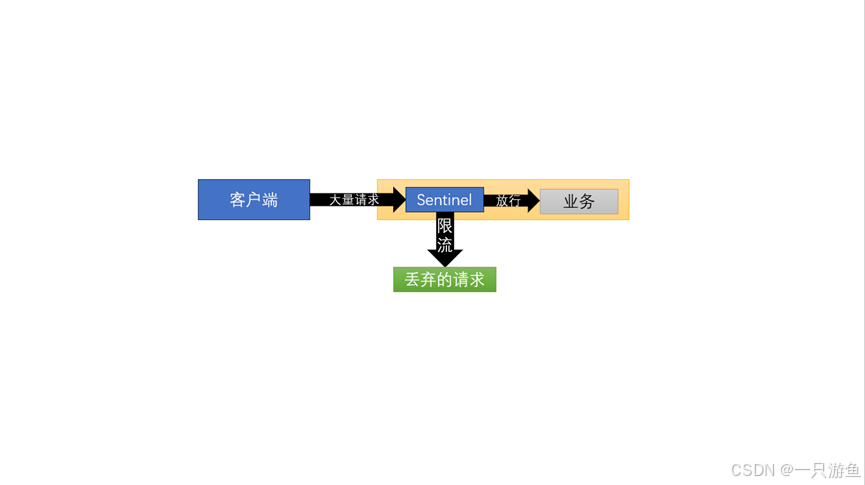
实战
(1)阈值类型
A. QPS 阈值模式(每秒请求数)(默认)(轻量)
- 定义:限制某个资源的 每秒通过的请求数(Queries Per Second)。
- 特点:
- 常用于接口限流,确保在高并发下不会被大量请求压垮。
- 比较适合对 突发流量敏感的系统,比如下单接口、热点数据接口。
- 如果超过阈值,多余的请求会被拒绝或走降级逻辑。
- 适用场景:
- API 网关
- 高频访问接口
B. 线程数阈值模式
- 定义:限制某个资源的 并发线程数,即同时进入方法的线程数量。
- 特点:
- 常用于 后端服务保护,防止某个方法/资源执行耗时较长,导致线程数堆积,从而拖垮整个服务。
- 和 QPS 限流不同,它更关注执行中的并发数,而不是请求速率。
- 适用场景:
- 执行耗时较长的查询/调用(例如调用第三方接口、数据库操作)。
- 服务资源有限时(线程池有限)。
如图:
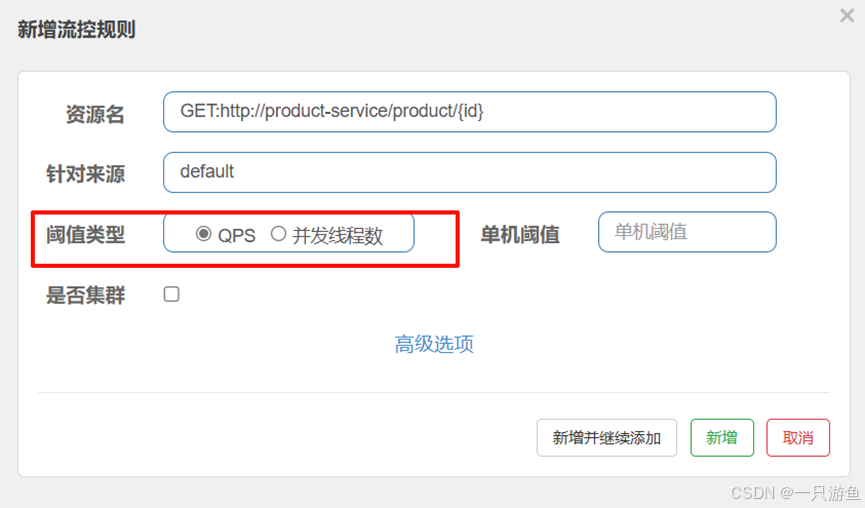
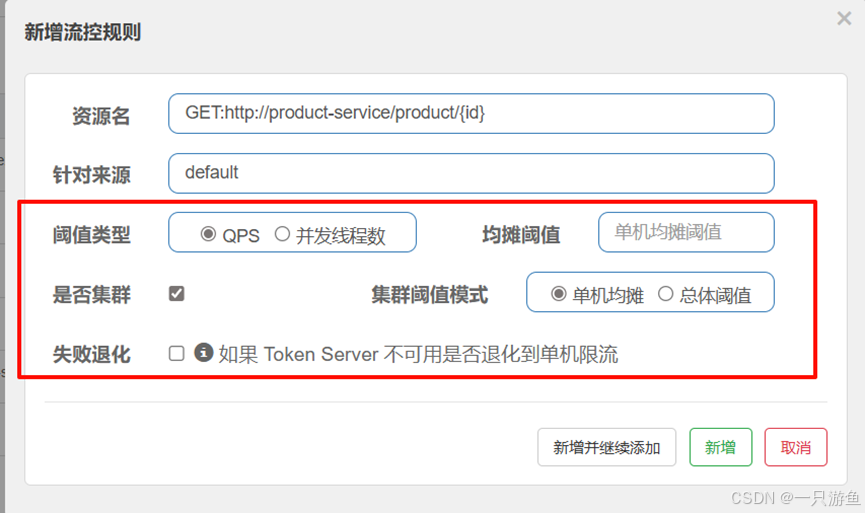
是否集群:
单机均摊:如果设置为1,那么集群的每台机器每秒都只能处理一个请求。
总体阈值:如果设置为1,那么集群的所有机器每秒都只能处理一个请求。
(2)流控模式
简介
流控模式有三种直接模式、关联模式、链路模式
A. 直接模式(默认模式)
- 定义:针对当前资源本身限流。
- 特点:
- 最常见、最简单。
- 超过阈值后,直接对当前请求进行限流处理(拒绝 / 降级)。
- 适用场景:
- 普通接口的限流保护。
B. 关联模式
- 定义:当某个资源 A 的访问量超限时,会对 另一个资源 B 进行限流。
- 特点:
- 主要用来保护“核心资源”。
- 可以防止非核心接口的高流量拖垮核心业务。
- 适用场景:
- 比如:当商品详情接口流量过大时,限制它以保证下单接口的正常可用。
C. 链路模式
- 定义:只针对某个调用链路下的请求进行限流。
- 特点:
- Sentinel 会区分不同的调用链路,限流时只影响某条链路上的请求。
- 适合微服务场景下,不同调用来源需要差异化限流。
- 适用场景:
- 同一个方法可能被多个接口调用,但你只想限制某个接口下的调用量。
| 流控模式 | 控制逻辑 | 特点 | 适用场景 |
| 直接模式 | 针对当前资源本身限流 | 简单直观,使用最广 | 普通接口限流 |
| 关联模式 | 受其他资源访问量影响 | 保护核心资源优先 | 核心/非核心接口保护 |
| 链路模式 | 只针对特定调用链路限流 | 精细化控制,避免误伤 | 多调用源场景 |
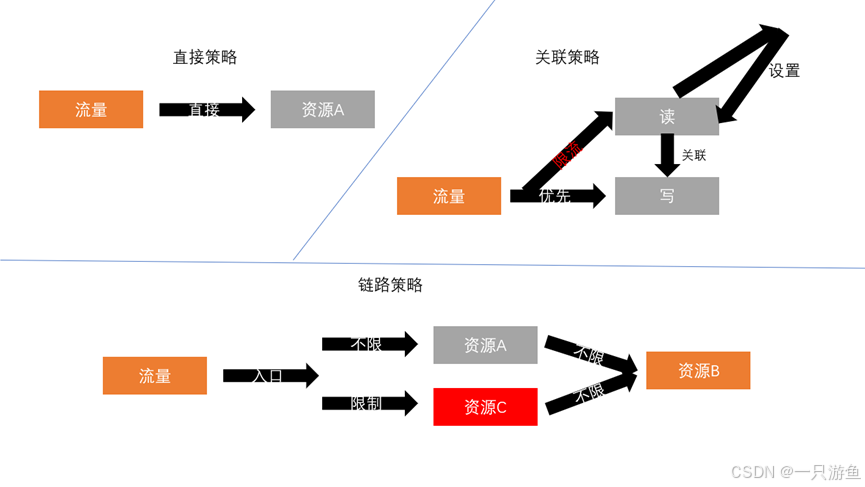
链路模式实例
链路模式是根据链路来控制的,
我们在order控制层里创建一个秒杀api:
//创建秒杀订单
@GetMapping("/create_kill")
public Order createOrderKill(@RequestParam("userId") Long userId, @RequestParam("productId") Long productId) {Order orderKill = orderService.createOrder(productId, userId);orderKill.setId(Long.MAX_VALUE); // 设置订单id为最大值return orderKill ;
}在application.yml文件中禁用上下文:
# sentinel
sentinel:transport:dashboard: localhost:8080# sentinel 提前加载eager: true# 禁用上下线web-context-unify: false新增/create链路流控规则:
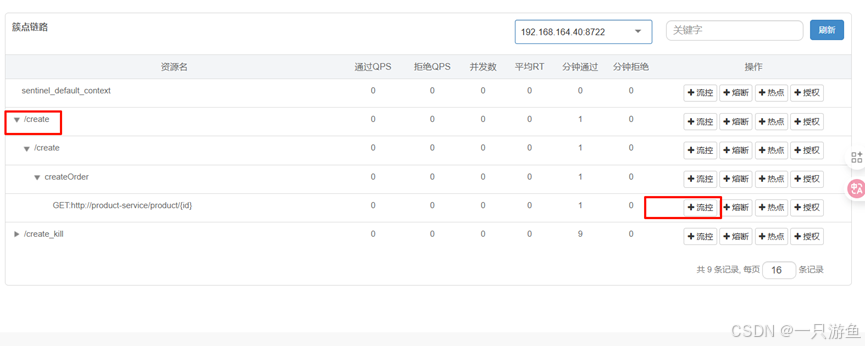
输入入口资源为/create_kill
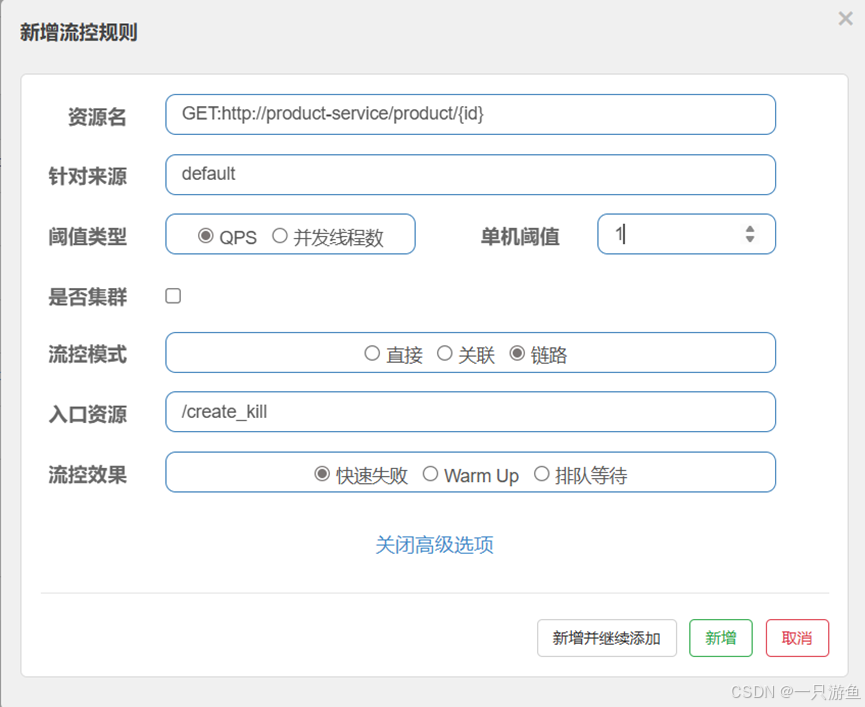
在浏览器请求,可以看到/create 不限流,而/ create_kill限流,返回了兜底回调:


关联模式
这里我们设置一个读、写数据库的场景,设置关联模式,当写的续修多时,设置读的限流,优先保证写入。
在订单控制层中创建读写api:
在readDb中新增流控规则:关联,关联资源为 /writeDb
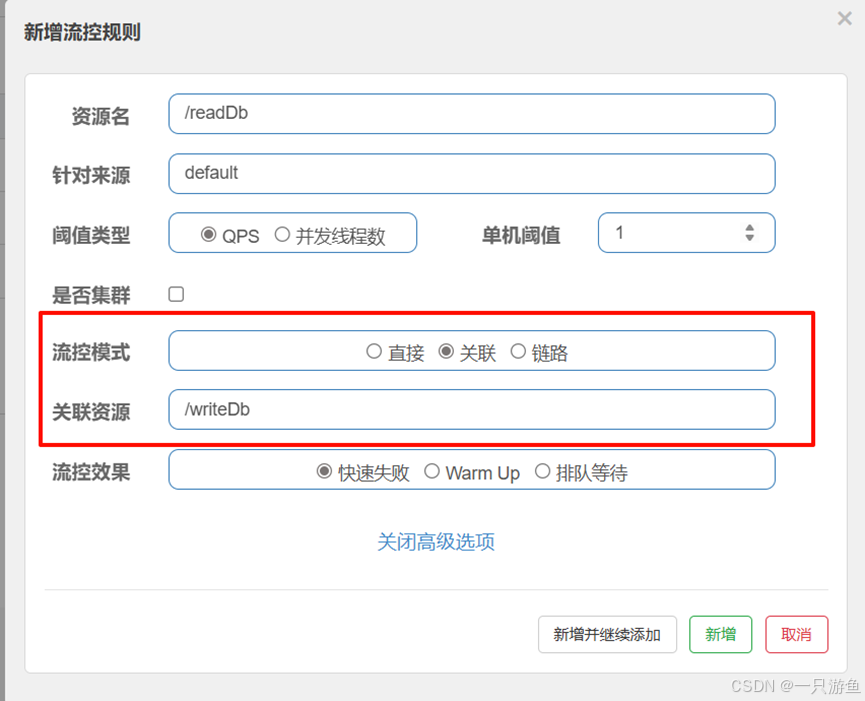
快速请求/writeDb 再次请求/readDb 可以发现/readDb 被限流:

(4)流控效果
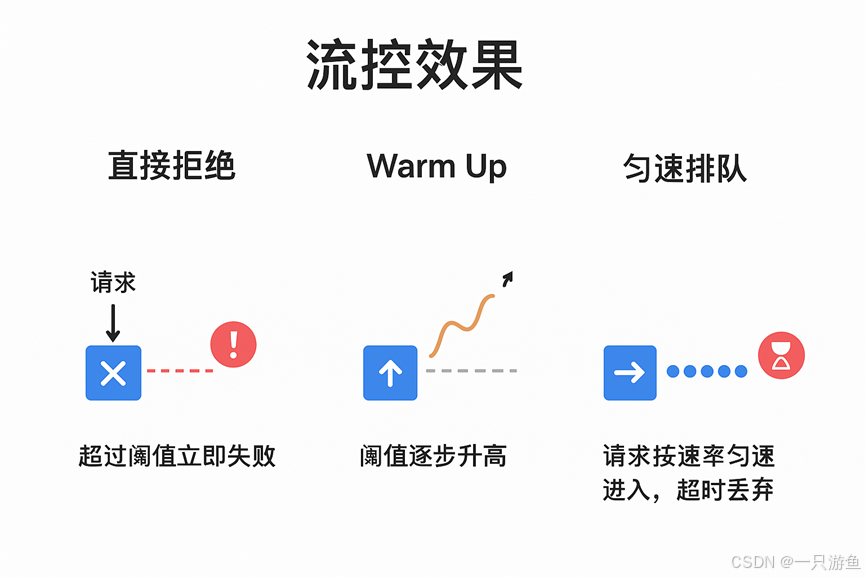
简介
1. 直接拒绝(快速失败)
- 说明:当请求超过阈值时,直接抛出 FlowException,快速失败,不会进入方法逻辑。
- 特点:
- 最简单、最常见。
- 适合核心接口,避免过载。
- 用户体验上可能直接返回“系统繁忙”。
2. Warm Up(预热模式)
- 说明:流量刚开始进入系统时,阈值会从较小值逐渐升到配置的最大阈值。
- 原理:通过 冷加载因子(默认 3),让系统在一段时间内逐渐“热身”,避免冷系统被突发流量压垮。
- 场景:
- 系统刚启动时需要预热。
- 后端依赖服务(如缓存、线程池)还没准备好时。
3. 匀速排队(排队等待)
- 说明:请求会按照设定的 QPS(每秒请求数) 匀速通过,超过的请求会排队等待。
- 特性:
- 请求不会被直接拒绝,而是等待执行。
- 有一个最大等待时长(超过会抛出异常)。
- 场景:
- 适合“削峰填谷”,让突发流量变得平滑。
- 比如秒杀场景:限制请求进入核心逻辑的速度,保证系统稳定。
实战
- Warm Up(预热模式)
修改流控效果为Warm Up, 单机阈值为10, 预热时长为4(刚开始只能处理四分之一的请求,阈值会在4秒内上升到10)
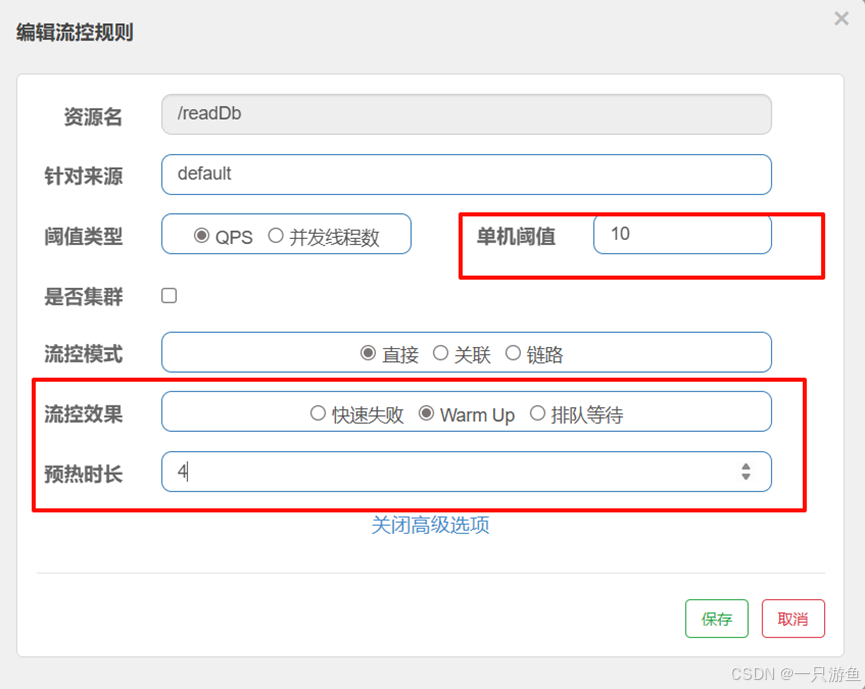
在MyBlockException文件中添加:
response.setStatus(429); // 429 Too Many Requests打开压测工具:(这里我用的是apipost)
设置并发数和时长:
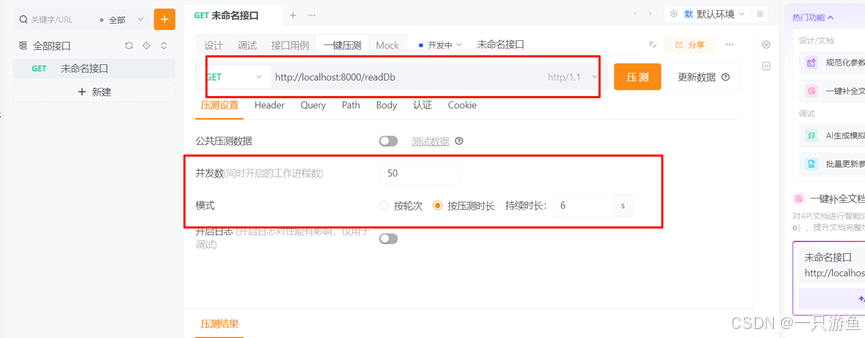
压测后可以看到结果:
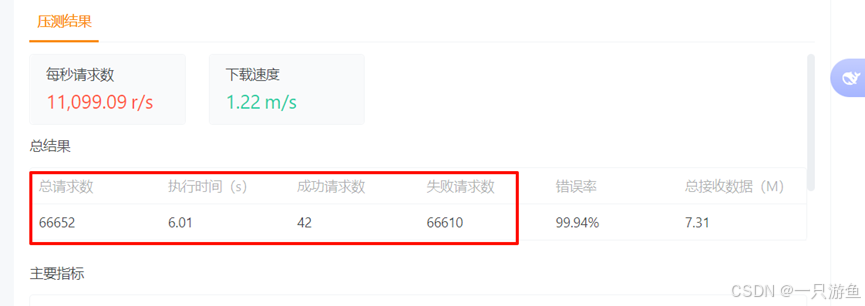
(5)熔断降级
A.作用
熔断主要是针对调用链中的 不稳定调用(比如远程服务、数据库、第三方接口等),当这些资源出现异常时,自动 熔断(中断调用),避免故障扩散。
- 流控 → 关注的是 请求量 是否超过阈值。
- 熔断 → 关注的是 调用是否异常(慢/错/超时)。
B.Sentinel 熔断策略
Sentinel 提供了三种熔断策略,可以通过配置 降级规则(DegradeRule) 来启用:
- 慢调用比例 (SLOW_REQUEST_RATIO)
- 统计一段时间内的请求响应时间,如果超过设定的最大响应时间(RT),并且慢调用的比例大于阈值,就触发熔断。
- 适用于:接口响应过慢 的场景。
- 异常比例 (ERROR_RATIO)
- 统计一段时间内的调用异常比例,如果超过阈值(比如 0.5 = 50%),就触发熔断。
- 适用于:大量错误请求 的场景。
- 异常数 (ERROR_COUNT)
- 统计一段时间内的异常总数,如果超过设定值,就触发熔断。
- 适用于:低并发但容易出错 的场景。
C.熔断过程
- 探测状态机:熔断分为三种状态:
- Closed(关闭) → 正常运行
- Open(打开) → 熔断,不再调用下游服务,直接走降级逻辑
- Half-Open(半开) → 经过熔断时间窗口后,允许部分流量尝试调用,如果恢复正常则关闭熔断,否则继续打开
- 恢复机制:熔断时间窗口过后,会进入 Half-Open 状态,如果探测调用成功,则恢复到 Closed 状态。
D.熔断器(断路器)
熔断器是什么?
熔断器(Circuit Breaker)是一种 保护机制,用于分布式系统中防止 雪崩效应。
类似家里的电闸保险丝:
- 电流过大 → 熔断 → 停止供电 → 避免电器烧毁
- 系统调用异常过多/过慢 → 熔断 → 暂停调用 → 避免拖垮整个系统
一句话总结:
熔断器就是当下游服务频繁失败时,临时“切断”请求,直接返回降级结果,防止影响整个系统。
熔断器的工作原理
熔断器一般基于 状态机,有三种核心状态:
- Closed(关闭状态)
- 默认状态
- 所有请求正常通过
- 如果请求连续失败(比如异常比例超过设定阈值),进入 Open 状态
- Open(打开状态)
- 熔断器打开,所有请求 立即失败/走降级逻辑
- 不再调用下游服务
- 经过一段 冷却时间窗口(比如 10 秒)后,进入 Half-Open 状态
- Half-Open(半开状态)
- 允许 少量请求 探测下游服务是否恢复
- 如果探测请求成功率达到标准 → 恢复到 Closed
- 如果探测仍然失败 → 回到 Open 状态
触发熔断的条件(常见规则)
熔断器一般根据以下指标判断是否“熔断”:
- 异常比例:失败请求数 / 总请求数 > 阈值
- 异常数:固定时间窗口内失败请求数超过阈值
- 慢调用比例:超过设定的最大响应时间的请求比例太高
工作原理
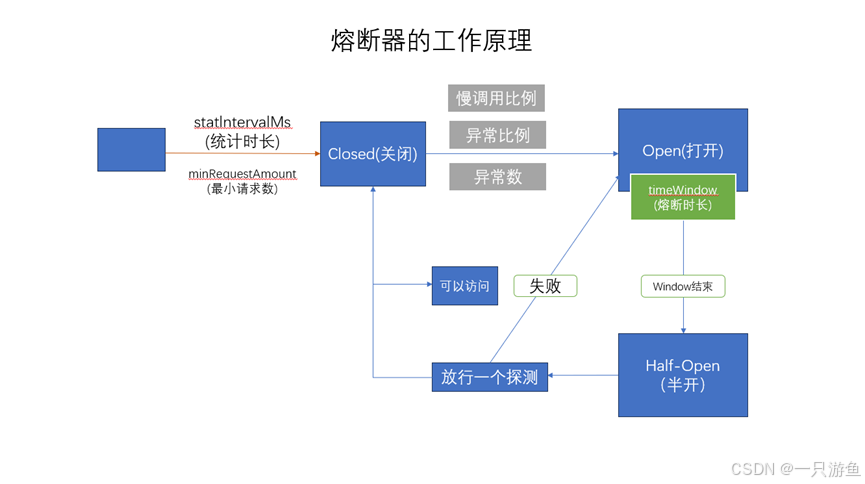
没有配置熔断器时,订单服务都会向商品服务发送请求然后等待其回应,
配置熔断器时,当超过了最大RT、比例阈值时,订单服务会在熔断时长中直接返回兜底或者错误,不会再发送请求。
实例
A. 慢调用比例
我们给/create api设置熔断规则,如图:
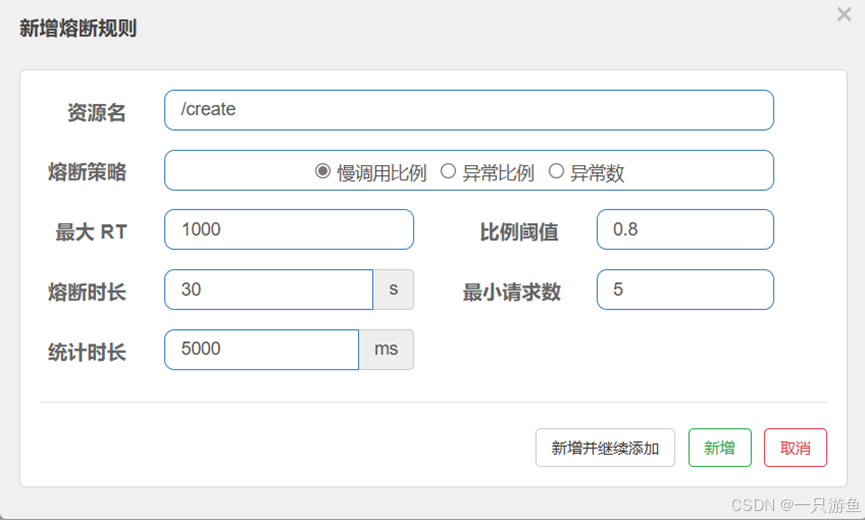
为了试验,在商品服务中设置睡眠时间两秒:
// //模拟睡眠2 stry {TimeUnit.SECONDS.sleep(7);}catch (InterruptedException e) {e.printStackTrace();}快速请求/create api ,可以看到,接下来的30秒内,一直返回兜底数据:
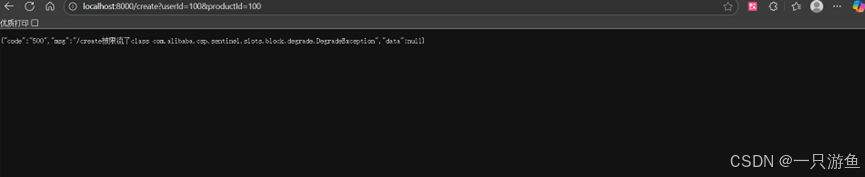
说明被熔断,30秒后,可以继续返回商品信息。
A.异常比例
创建一个熔断规则:
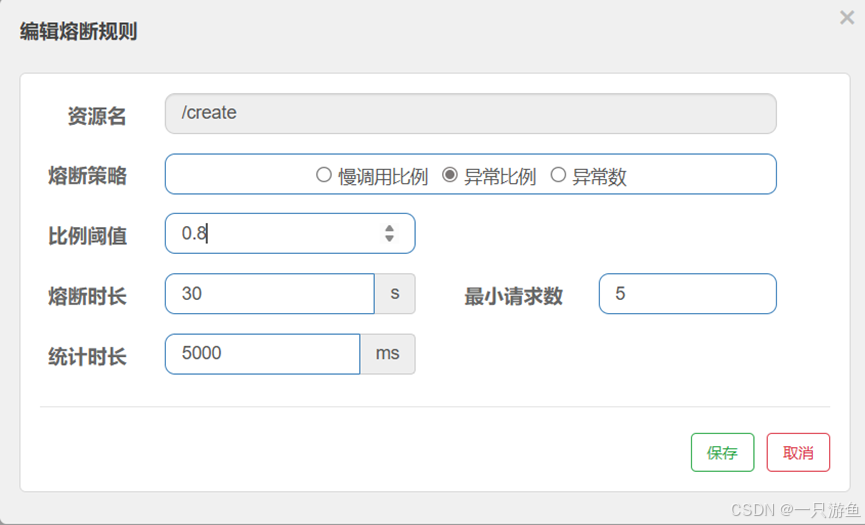
当返回的异常数占总共的0.8时,会触发熔断。。
B.异常数
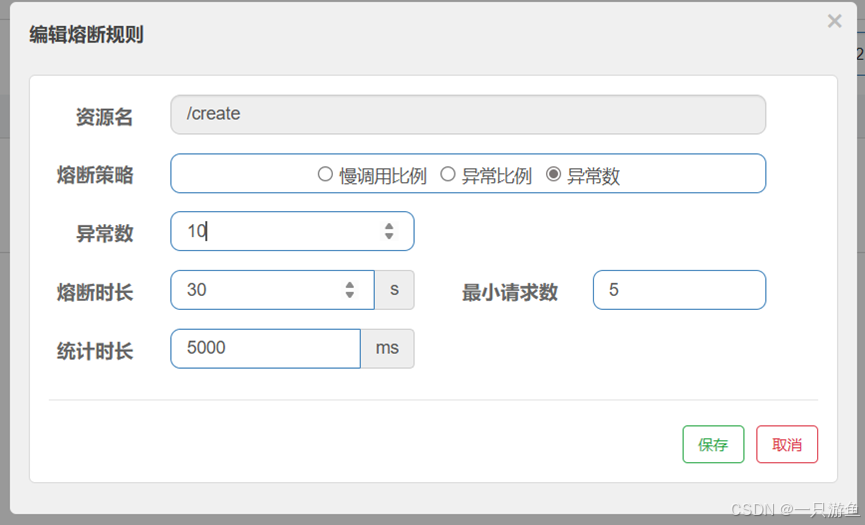
当返回的异常数有10个时,会触发熔断。。
C.热点规则
简介
热点规则(HotSpot Parameter Flow Control)是 Sentinel 提供的一种 参数级别的限流 策略。
普通的限流(QPS 限流)是针对 某个资源整体 的,比如接口 /create 每秒最多 100 次请求。
但有时候我们需要 按参数值区分限流,比如:
- /order?id=1001 被频繁请求
- /order?id=2002 很少被请求
如果只做整体限流,就可能导致 热门参数请求把冷门参数挤掉。
所以热点规则就是为了解决 参数热点问题。
实例
创建秒杀订单api
//创建秒杀订单
@GetMapping("/create_kill")
@SentinelResource( value = "createKill", blockHandler = "createOrderKillBack")public Order createOrderKill(@RequestParam("userId") Long userId, @RequestParam("productId") Long productId) {Order order = orderService.createOrder(productId, userId);order.setId(Long.MAX_VALUE); // 设置订单id为最大值return order;
}
public Order createOrderKillBack(Long userId,Long productId, BlockException e) {System.out.println("兜底回调 ");Order order = new Order();order.setUserId(userId);order.setNickName("未知用户");order.setId(productId);order.setAddress("限流异常: " + e.getClass());order.setTotalAmount(new BigDecimal(0));order.setProductList(null);return order;
}创建热点规则:
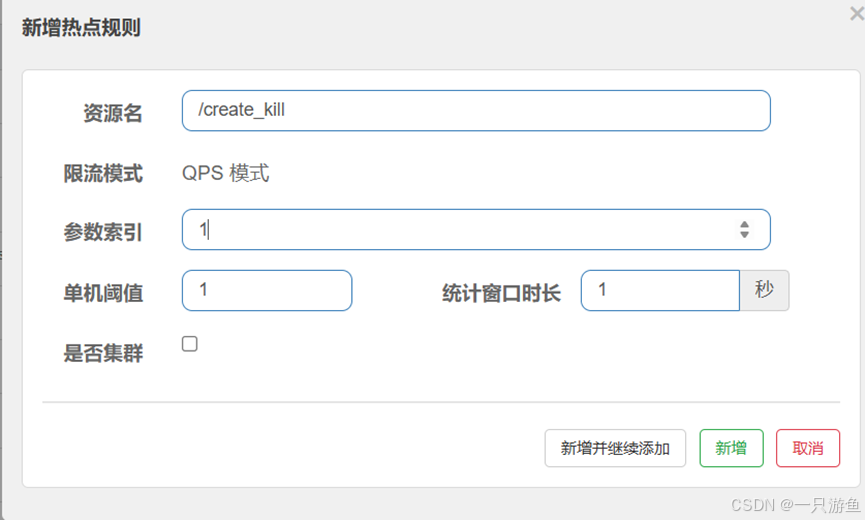
参数索引指的是索引的位置,
比如我们的接口写的是
@RequestParam("userId") Long userId, @RequestParam("productId") Long productid
那么索引0是userId ,索引1指的是productId,(我们设的是1)
如果设置 阈值=1,统计窗口=1秒,那么:
- 当 productId=1001 在 1 秒内被请求 2 次,就会触发限流(返回降级结果)。
- 而 productId=2002 可能还可以继续正常访问,因为 Sentinel 是 按参数值分别统计 的。
当然,也可以通过筛选索引的值来区分限制,
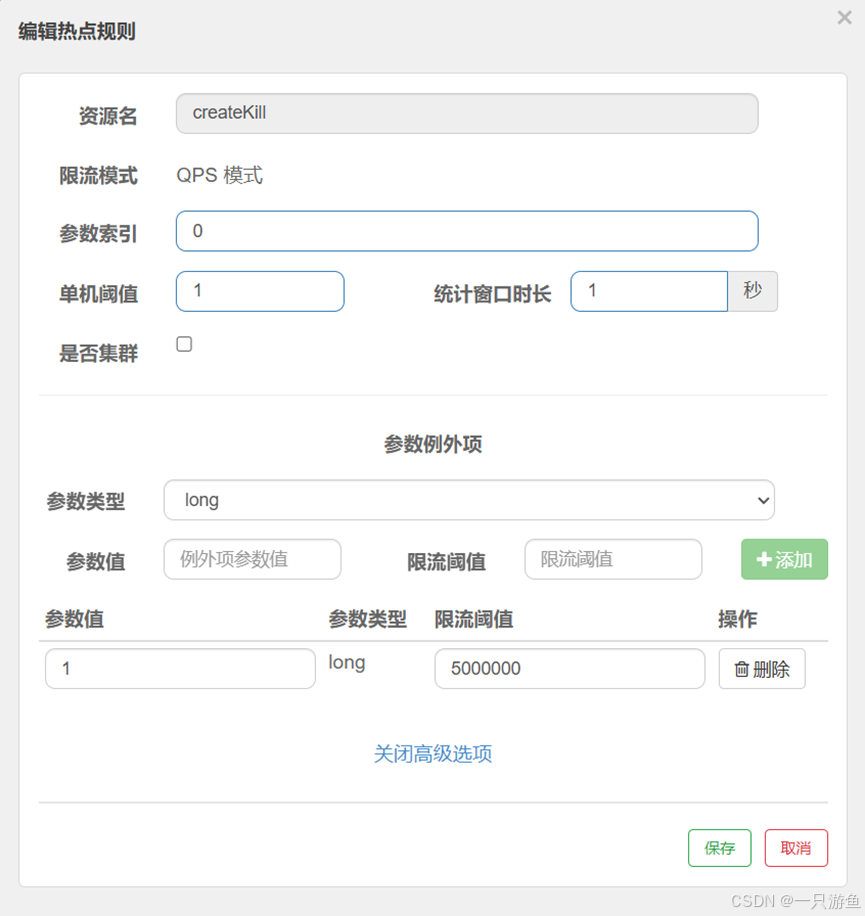
其中限流阈值为0,代表不可以访问,反之越大则不限流。。
正常请求,会被限制:

当productId = 1时,不会被限制

5、集成Gateway(网关)
简介
网关(API Gateway)就是所有客户端(浏览器、APP、小程序等)访问后端服务的 统一入口。
在 Spring Cloud 里,常用的网关实现有:
- Spring Cloud Gateway(官方推荐,新一代网关)
- Zuul(Netflix 开源的网关,早期常用,现在逐渐被 Gateway 替代)
网关的作用
1. 统一入口
- 所有请求都必须先经过网关,再转发到后端对应的微服务。
- 好处:前端不需要关心具体哪个服务处理,只管请求网关。
2. 路由转发
- 网关的核心功能就是 智能路由,根据请求路径/规则,把请求转发到对应的微服务。
- /api/user/** → 转发到 用户服务
- /api/order/** → 转发到 订单服务
3. 负载均衡
- 如果后端某个服务有多个实例,网关可以帮你做 负载均衡,把请求分散到不同实例上。
4. 安全控制
- 网关可以统一做 认证鉴权,比如 JWT 校验、OAuth2、权限拦截。
- 避免每个微服务都要单独实现一套登录校验逻辑。
5. 流量控制
- 配合 Sentinel、RateLimiter,可以在网关层做 限流、熔断、降级。
- 保护下游服务不被高并发压垮。
6. 日志 & 监控
- 可以在网关层统一收集请求日志、监控调用链路,方便排查问题。
7. 协议适配
- 网关可以做 协议转换,比如:
- 前端发 HTTP 请求 → 网关转发成 gRPC 给后端
- 把 WebSocket、REST 等不同请求方式进行适配
实战
(1)创建网关
创建项目gateway,
添加以下依赖:
<!--注册中心--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency>
<!--网关 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><!--负载均衡 --><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId></dependency>(2)规则配置
编辑配置:
spring:application:name: gatewayprofiles:include: gatewaymain:web-application-type: reactiveserver:port: 80创建配文件:application-gateway.yml
s
pring:cloud:gateway:# 路由配置routes:- id: order-routeuri: http://localhost:8000# 匹配规则predicates:- Path=/order/**- id: product-routeuri: lb://product-servicepredicates:- Path=/product/**在订单服务和商品服务:确保api与编辑对应。
@RequestMapping("/order")@RequestMapping("/product")重启项目,在浏览器输入
localhost/order/readDb
发送请求,查看控制台打印情况:


可以看到网关已经负载均衡的向两台服务器发送了请求。。
网关的三个核心
A.Route(路由)
-
- 网关的最基本构建块。
- 一个路由包含 ID、目标 URI、断言(Predicates)、过滤器(Filters)。
- 作用:告诉网关“哪些请求要转发到哪个服务”。
- 举例:
- - id: order-route
- uri: http://localhost:8000
- predicates:
- - Path=/order/**
把所有 /order/** 的请求转发到 order-service。
B.Predicate(断言)
-
- 判断请求是否符合某个规则,只有符合的请求才会路由到目标服务。
- 相当于路由的匹配条件。
- 内置的断言有很多,比如:
- Path:按路径匹配
- Method:按请求方法匹配(GET/POST)
- Host:按域名匹配
- After/Before/Between:按时间匹配
- 举例:
- predicates:
- - Path=/product/**
- - Method=GET
只允许 GET 请求 /product/** 才会命中路由。
断言的长短写法:
短:

长:
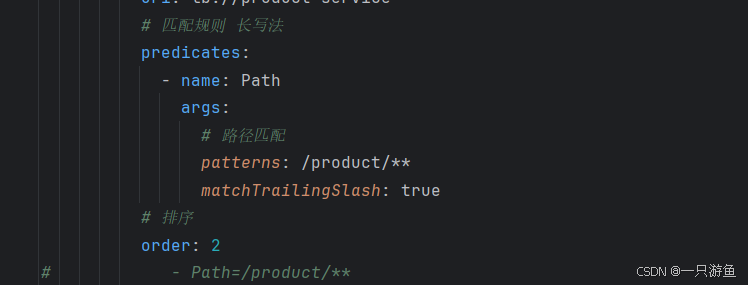
常用断言
| 断言类型 | 配置示例 | 说明 |
| Path | - Path=/order/** | 按路径匹配,请求路径以 /order/ 开头才会命中 |
| Method | - Method=GET | 按 HTTP 请求方法匹配 |
| Host | - Host=**.example.com | 按域名匹配,例如 api.example.com |
| Query | - Query=type, vip | 按请求参数匹配,支持正则 |
| Header | - Header=X-Request-Id, \d+ | 按请求头匹配,支持正则 |
| Cookie | - Cookie=sessionId, abc.* | 按 cookie 匹配,支持正则 |
| After | - After=2025-09-29T00:00:00+08:00[Asia/Shanghai] | 在指定时间之后的请求才生效 |
| Before | - Before=2025-12-31T23:59:59+08:00[Asia/Shanghai] | 在指定时间之前的请求才生效 |
| Between | -Between=2025-09-29T00:00:00+08:00[Asia/Shanghai], 2025-12-31T23:59:59+08:00[Asia/Shanghai] | 在某个时间区间内的请求才生效 |
-
C.Filter(过滤器)
- 在请求转发前后进行处理(责任链模式)。
- 分为 全局过滤器 和 局部过滤器。
- 作用场景:
- 鉴权、校验 token
- 日志打印
- 请求头 / 响应头修改
- 跨域处理
- 限流、熔断
- 举例:
- filters:
- - AddRequestHeader=X-Request-Id, 12345
给请求加一个头。
基本使用
在application-gateway.yml 配置中编写:
spring:cloud:gateway:# 路由配置routes:- id: order-routeuri: lb://order-service# 匹配规则 短写法predicates:- Path=/api/order/**order: 1# 过滤器 匹配的路径是 /api/order/xxxfilters:- RewritePath=/api/?(?<segment>.*), /${segment}注意这时我们的订单、商品api为/order/readDb 这样的(没有api)
在浏览器中请求:
localhost/api/order/readDb
可以看到请求成功

默认filter
在application-gateway.yml 配置中编写:
spring:cloud:gateway:# 默认过滤器default-filters:- AddResponseHeader=X-Response-Abc, 123这样就可以在订单和商品的请求头都加上了123
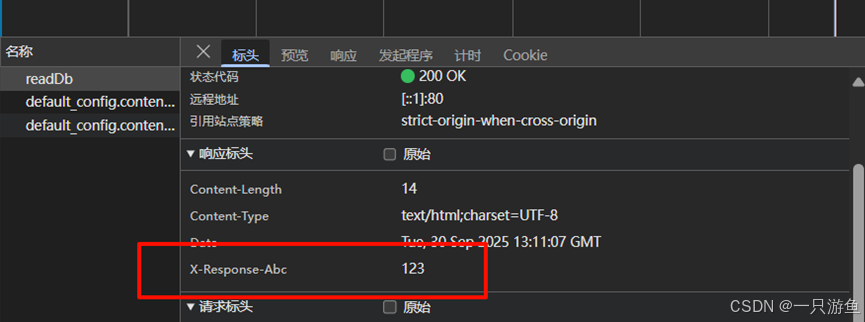
GlobalFilter
可以设置一个全局filter:
我们做一个全局过滤器用来输出请求路径,开始时间,结束,耗时的日志
创建RtGlobalFilter文件
@Component
@Slf4j
public class RtGlobalFilter implements GlobalFilter, Ordered {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {ServerHttpRequest request = exchange.getRequest();ServerHttpResponse response = exchange.getResponse();String uri = request.getURI().toString() ;long start = System.currentTimeMillis();log.info("请求路径:{},开始时间:{}", uri, start);//=============================以上是前置逻辑==============================Mono<Void> filter = chain.filter(exchange).doFinally(signalType -> {//===========================以下是后置逻辑==============================long end = System.currentTimeMillis();log.info("请求结束:{},结束时间:{},耗时:{}ms", uri,end, end-start);}); // 返回结果return filter;}@Overridepublic int getOrder() {return 0;}
}重启项目后,请求localhost/api/order/readDb
可以看到控制台打印的日志:
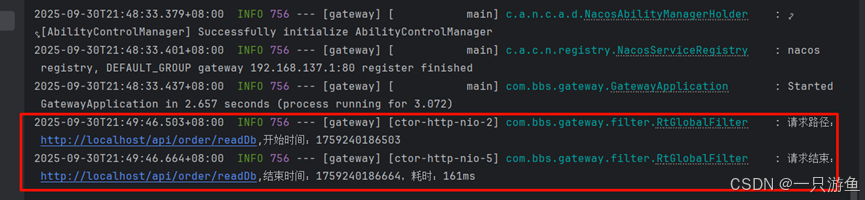
如此,全局过滤器设置成功。
自定义fliter
这里我们举个例子:一次性令牌网关过滤器工厂类用于在响应中添加一次性令牌头信息,支持UUID和JWT两种令牌类型
创建OnceTokenGatewayFilterFactory文件
@Component
public class OnceTokenGatewayFilterFactory extends AbstractNameValueGatewayFilterFactory {/*** 应用过滤器配置,创建网关过滤器实例* @param config 名称值配置对象,包含令牌类型配置信息* @return 网关过滤器实例,用于在响应中添加令牌头信息*/@Overridepublic GatewayFilter apply(NameValueConfig config) {return new GatewayFilter() {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 在请求处理完成后,向响应头中添加一次性令牌return chain.filter(exchange).then(Mono.fromRunnable(() -> {ServerHttpResponse response = exchange.getResponse();HttpHeaders headers = response.getHeaders();String value = config.getValue() ;// 根据配置值生成对应的UUID令牌if ("uuid".equalsIgnoreCase(value)){value = UUID.randomUUID().toString();}// 根据配置值生成对应的JWT令牌if ("jwt".equalsIgnoreCase(value)){//模拟生成jwtvalue ="eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiJtb2NrLXVzZXItaWQiLCJ1c2VybmFtZSI6InRlc3RVc2VyIiwicm9sZSI6IlVTRVIiLCJpYXQiOjE3MDM2NzQ4NTksImV4cCI6MTcwMzc2MTI1OX0.mock-signature-for-testing\n";}headers.add(config.getName(),value);}));}};}
}然后我们将添加好的自定义配置:- OnceToken=X-Response-Token, uuid
spring:cloud:gateway:# 默认过滤器default-filters:- AddResponseHeader=X-Response-Abc, 123# 路由配置routes:- id: order-routeuri: lb://order-service# 匹配规则 短写法predicates:- Path=/api/order/**order: 1# 过滤器 匹配的路径是 /api/order/xxxfilters:- RewritePath=/api/?(?<segment>.*), /${segment}- OnceToken=X-Response-Token, uuid现在添加到了order模块中我们可以请求订单api:
localhost/api/order/readDb
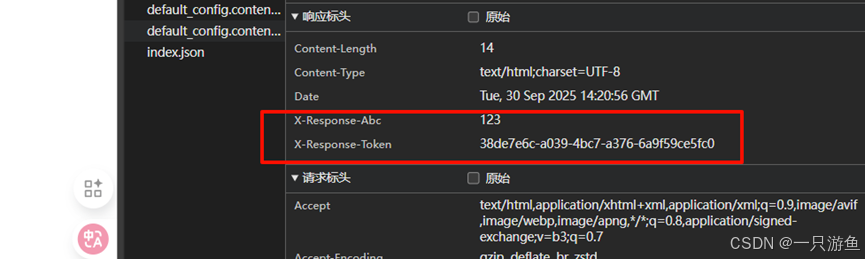
可以看到添加token 成功。
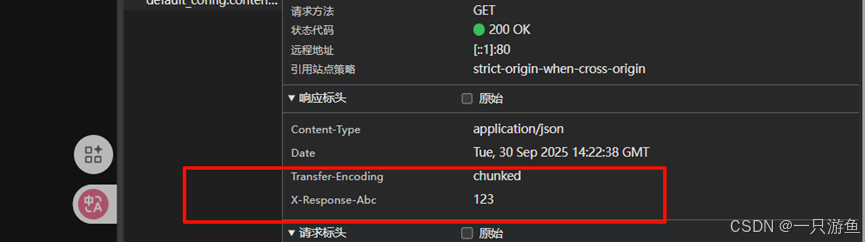
而商品模块并没有:
localhost/api/product/product/1
全局跨域
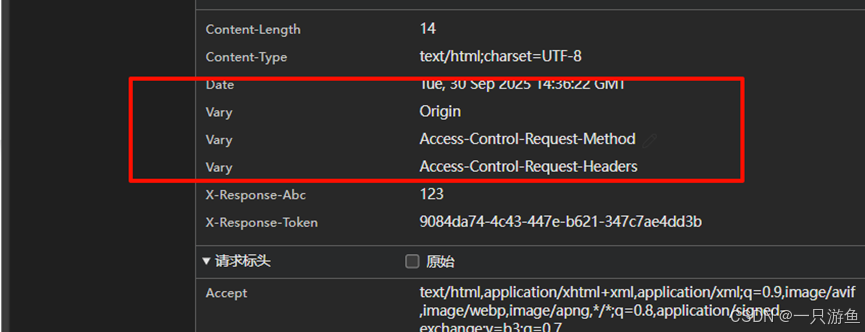
在配置中添加全局跨域:
spring:cloud:gateway:# 全局跨域globalcors:corsConfigurations:'[/**]':allowed-origin-patterns: '*'allowed-methods: '*'allowed-headers: '*'再次请求api,可以看到跨域的相关配置:
6、seata集成
简介
Seata 是 一款开源的分布式事务解决方案,最早由阿里巴巴开源,它专门用来解决 微服务架构或分布式系统中的分布式事务一致性问题。
为什么需要 Seata?
在微服务/分布式系统里,一个业务操作往往会跨多个服务、多个数据库完成。
例如:
电商下单流程
- 订单服务:生成订单
- 库存服务:扣减库存
- 支付服务:扣减余额
如果某一步失败(比如支付失败),就需要回滚整个业务,保持数据一致。这就是 分布式事务 问题。
传统的单体应用可以用本地事务(如数据库的事务机制),但在分布式场景下已经不够用了,这时就需要 Seata。
Seata 的作用
- 分布式事务协调器
- 统一管理事务的开始、提交、回滚。
- 确保跨服务、跨数据库操作的一致性。
- 多种事务模式支持
- AT 模式(自动事务模式):对业务无侵入,适合绝大多数场景。
- TCC 模式:需要开发者提供 try-confirm-cancel 三个接口,适合灵活控制的业务。
- Saga 模式:长事务补偿模式,适合长时间业务(比如机票、酒店预订)。
- XA 模式:基于数据库 XA 协议的分布式事务。
- 透明化使用
- 开发者只需要在代码里加上 @GlobalTransactional 注解(类似 Spring 的 @Transactional),Seata 就能帮忙管理整个分布式事务。
Seata 的核心
- TC(Transaction Coordinator,事务协调器)
管理全局事务的状态,协调提交或回滚。 - TM(Transaction Manager,事务管理器)
负责开启和提交/回滚全局事务(一般由业务代码调用)。 - RM(Resource Manager,资源管理器)
管理分支事务(比如数据库操作),向 TC 注册并汇报状态。
实战
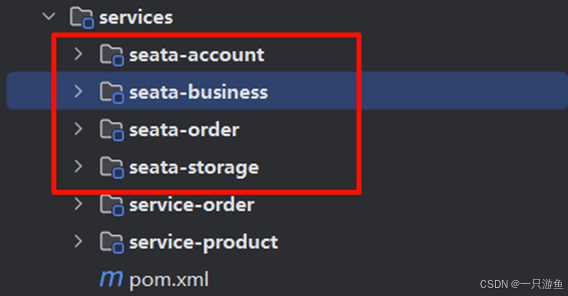
1.环境的搭建
为了测试,我们新建几个模块,将其放到services模块下:
模块下载链接:
https://www.yuque.com/attachments/yuque/0/2025/zip/35412186/1739259105487-126a00e0-82d3-4a6f-983a-f628bce80862.zip
如图:
在services的pom文件下作为services的模块:
注意:新创建的模块的父类一定要和自己的一样:(可以复制service-order项目的)

在mysql中执行sql语句创建库和表:(作者用到了navcat工具)
CREATE DATABASE IF NOT EXISTS `storage_db`;
USE `storage_db`;
DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
UNIQUE KEY (`commodity_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO storage_tbl (commodity_code, count) VALUES ('P0001', 100);
INSERT INTO storage_tbl (commodity_code, count) VALUES ('B1234', 10);
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE DATABASE IF NOT EXISTS `order_db`;
USE `order_db`;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE DATABASE IF NOT EXISTS `account_db`;
USE `account_db`;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO account_tbl (user_id, money) VALUES ('1', 10000);
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
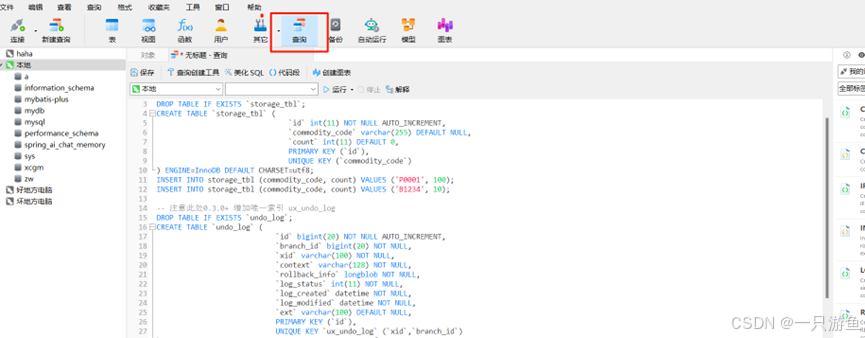
运行后可以看到创建了三个数据库:
在services 模块的pom文件里添加依赖:
<!-- seata--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId></dependency>下载运行Seata服务,
下载链接:
Seata Java Download | Apache Seata
下载其二进制文件:
解压后打开apache-seata-2.5.0-incubating-bin\seata-server\bin
点击.bat文件启动服务,
在service-order与service-product 模块添加application.yml配置:
# Seata
seata:enabled: trueapplication-id: order-service # 当前应用的唯一标识tx-service-group: default_tx_group # 事务分组名service:vgroup-mapping:default_tx_group: default # 映射 default_tx_group 到集群 defaultgrouplist:default: 127.0.0.1:8091 # Seata Server 地址(IP:Port)enable-degrade: falsedisable-global-transaction: false接着启动所有服务。。
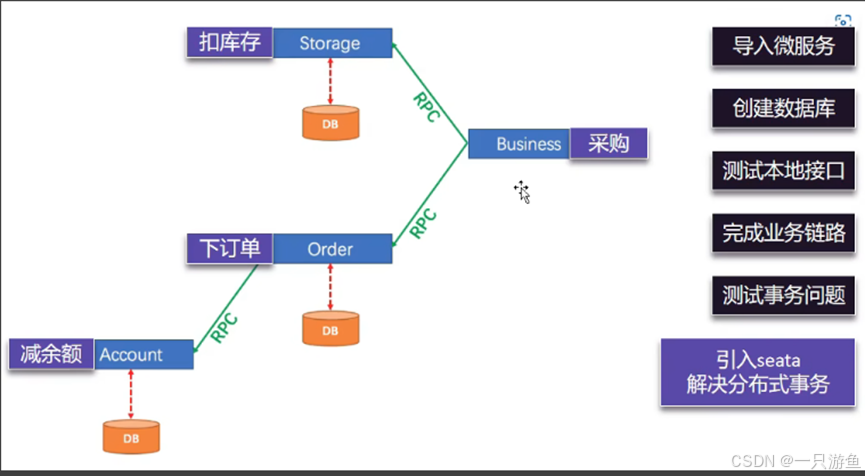
2.接口测试
实例过程如下图:
启动所有模块服务:
对api发起请求看看是否能请求成功:
订单:创建订单
localhost:5500/create?userId=18&commodityCode=P0001&count=2

库存:扣减库存
http://localhost:13000/deduct?commodityCode=P0001&count=2

账户:余额扣减
localhost:4000/debit?userId=1&money=9

可以查看数据库的情况来测试。
3.本地事务测试
具体实例流程如下:
添加声明事务:
在SeataOrder项目启动类中开启事务:
@EnableTransactionManagement // 开启事务在创建订单中的方法中添加注解,防止订单创建成功,库存扣减失败 无法回滚
@Transactional //本地事务 防止订单创建成功,库存扣减失败 无法回滚在seata account 模块中添加以上的事务。
本地事务在分布式部署上会出问题。
4.打通远程链路
在seata business 模块的启动类中开启feign
@EnableFeignClients(basePackages = "com.atguigu.business.feign") // 开启feign新建feign包,在包下创建两个接口:用来创建链接订单和扣减库存服务
@FeignClient(value = "seata-order")
public interface OrderFeignClient {/*** 创建订单* @param userId* @param commodityCode* @param orderCount* @return*/@GetMapping("/create")String create(@RequestParam("userId") String userId,@RequestParam("commodityCode") String commodityCode,@RequestParam("count") int orderCount);
}@FeignClient(value = "seata-storage")
public interface StorageFeignClient {/*** 扣减库存* @param commodityCode* @param count* @return*/@GetMapping("/deduct")String deduct(@RequestParam("commodityCode") String commodityCode,@RequestParam("count") Integer count);
}在服务层注入调用远程的服务:
@Autowired
StorageFeignClient storageFeignClient;@Autowired
OrderFeignClient orderFeignClient;@GlobalTransactional // 开启全局事务
@Override
public void purchase(String userId, String commodityCode, int orderCount) {//1. 扣减库存storageFeignClient.deduct(commodityCode, orderCount);//2. 创建订单orderFeignClient.create(userId, commodityCode, orderCount);
}同样金额的扣减依旧需要在seata order模块的启动类中开启feign
@EnableFeignClients(basePackages = "com.atguigu.order.feign") // 开启feign
链接远程服务,
@FeignClient(value = "seata-account")
public interface AccountFeignClient {/*** 扣减账户余额* @return*/@GetMapping("/debit")String debit(@RequestParam("userId") String userId,@RequestParam("money") int money);
}注入、调用服务:
@Autowired
AccountFeignClient accountFeignClient;@Transactional //本地事务 防止订单创建成功,库存扣减失败 无法回滚
@Override
public OrderTbl create(String userId, String commodityCode, int orderCount) {//1、计算订单价格int orderMoney = calculate(commodityCode, orderCount);//2、扣减账户余额accountFeignClient.debit(userId, orderMoney);//3、保存订单OrderTbl orderTbl = new OrderTbl();orderTbl.setUserId(userId);orderTbl.setCommodityCode(commodityCode);orderTbl.setCount(orderCount);orderTbl.setMoney(orderMoney);//3、保存订单orderTblMapper.insert(orderTbl);return orderTbl;
}当我们发送请求:创建订单后查看金额和库存的变化:
初始值:

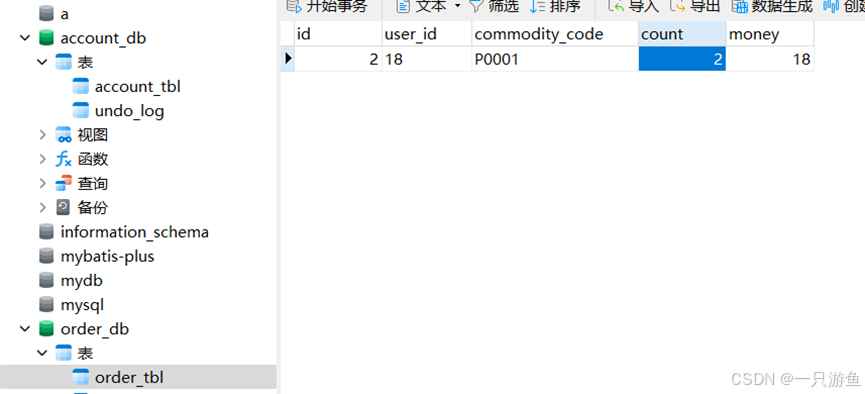
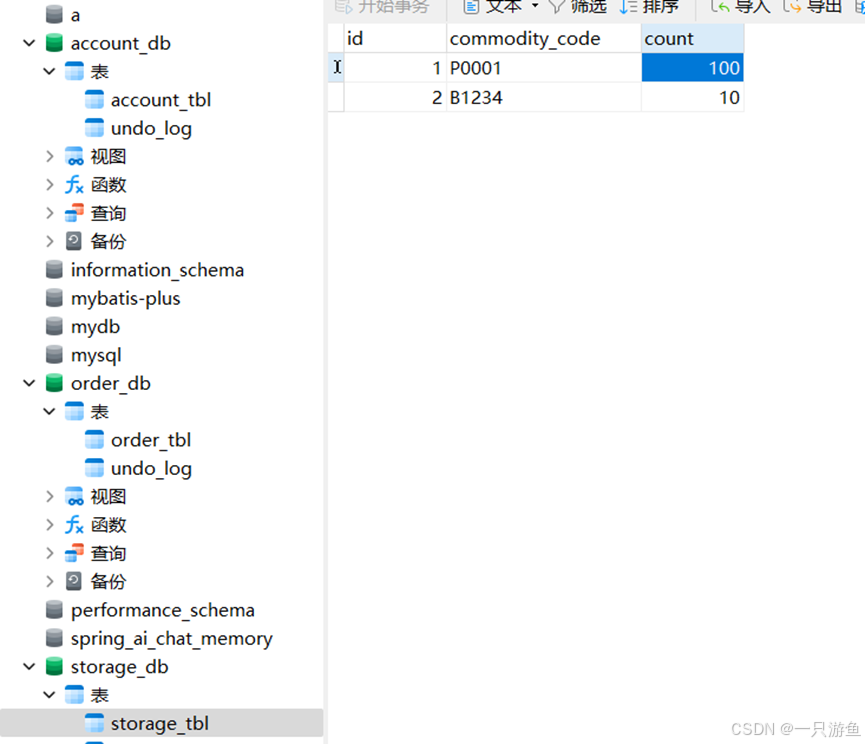
请求:
localhost:5500/create?userId=18&commodityCode=P0001&count=2

查看数据库:可以看到余额和库存都发生变化:
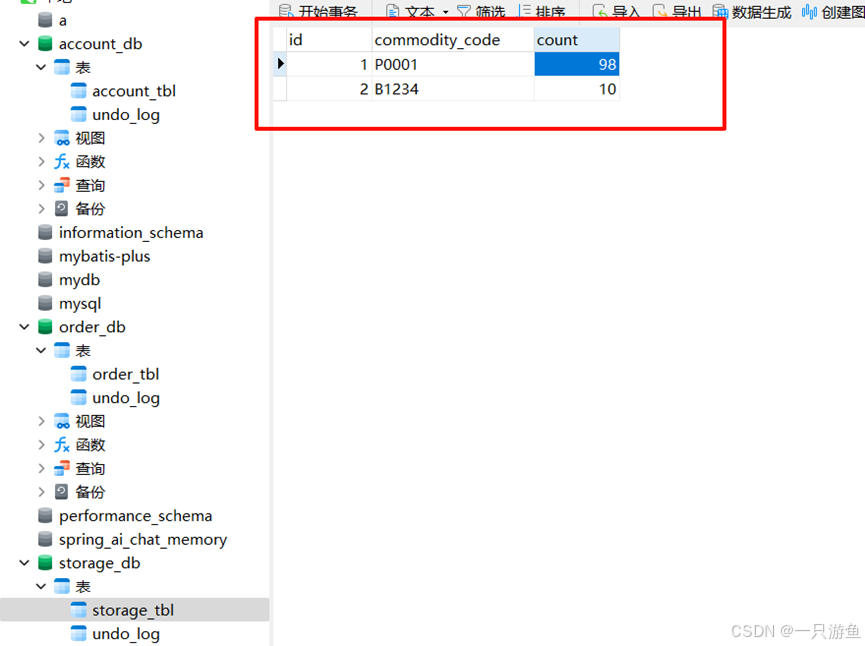

为了更好的理解回滚与数据不一致,我们在创建订单的方法中踢啊添加一个错误:
int i = 10/0;
再次请求,查看数据库,可以发现:订单没有创建成功,而金额和库存却发生了扣减。。
因为我们在创建订单的方法中添加了事务注解:
@Transactional当发生错误时,创建订单会发生回滚,而其他两个不会。。
5.整合seata
为了方便有UI界面管理,我们选择用2.1.0版本的seata(最新版2.5.0需要独立集成很麻烦)
网址:Seata-Server版本历史 | Apache Seata
选择这个,并按照之前的方法解压启动:
在浏览器打开UI页面:
http://127.0.0.1:7091
输入默认账号密码:
seata
seata
打开如下页面:
由于订单、库存余额都是分支事务,为了实现所有的模块都添加事务,可以在最大的分布式事务添加注解:
@GlobalTransactional // 开启全局事务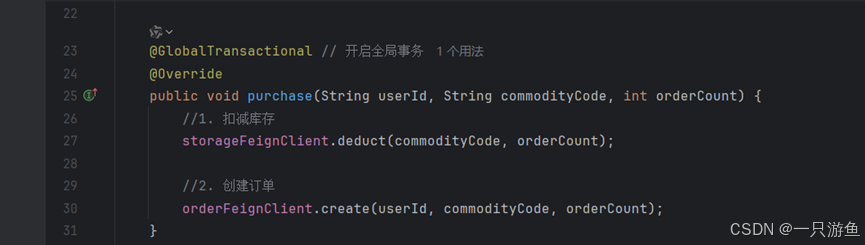
如此就算创建订单出现错误,所有的分支事务都可以实现回滚。。
6.二阶提交协议
Seata 的二阶段提交 (2PC) 背景
在分布式系统中,如果一个事务涉及 多个数据库/微服务,需要保证:
- 所有分支事务要么全部提交
- 要么全部回滚
否则就会出现 数据不一致。
Seata 提供了 全局事务管理器(TC, Transaction Coordinator) 和 事务分支(RM, Resource Manager) 来实现这个目标。
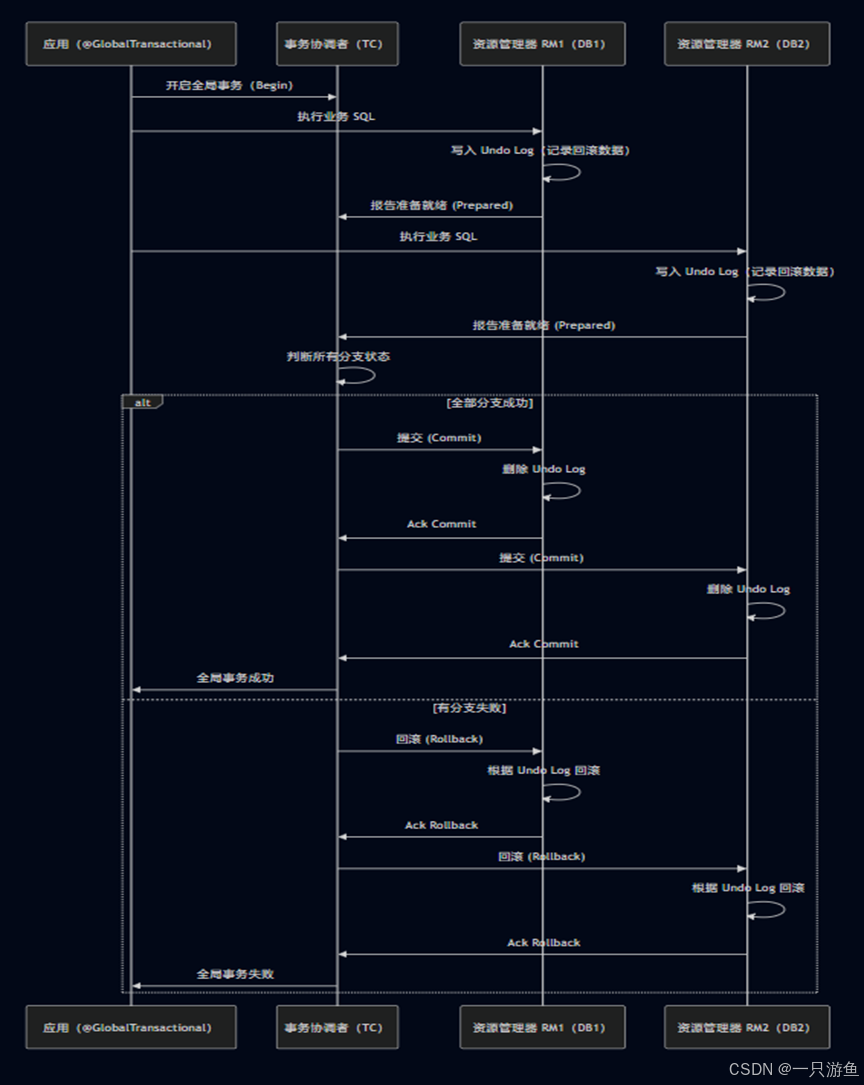
Seata 的二阶段提交流程(AT 模式)
Seata 的 AT 模式是基于数据库 undo log(回滚日志) 实现的,它分为两个阶段:
A.第一阶段:预提交(Prepare Phase)
- 全局事务开始
- 应用通过 @GlobalTransactional 或类似接口开启全局事务。
- 分支事务执行
- RM(资源管理器,比如某个微服务/数据库)执行 SQL 时,会生成 undo log(回滚数据)
- 事务不真正提交,而是准备好可以回滚或提交的数据
- RM 向 TC 报告准备状态
- 如果操作成功返回 prepared
- 如果操作失败返回 rollback
B.第二阶段:提交(Commit Phase)/回滚
- TC 收到所有 RM 的反馈:
- 如果全都 prepared → TC 下发 commit 指令
- 如果有一个 rollback → TC 下发 rollback 指令
- RM 执行实际提交或回滚
- 对于提交:正常提交数据库事务
- 对于回滚:使用 undo log 回滚之前的操作
- RM 向 TC 返回结果,完成全局事务
四种事务模式
A. AT 模式(Automatic Transaction,自动提交模式)
- 特点:
- 基于 数据库的行级锁和 undo 日志实现。
- 对业务方透明,不需要改造 SQL,只要是支持的数据库即可。
- 提供 最终一致性保障。
- 适用场景:
- 关系型数据库(MySQL、PostgreSQL 等)。
- 对性能要求高、希望尽量少改业务代码的场景。
- 原理:
- 在事务提交前,Seata 会生成 undo log(回滚日志)。
- 如果事务需要回滚,Seata 根据 undo log 还原数据。
B. TCC 模式(Try-Confirm-Cancel,二阶段提交模式)
- 特点:
- 需要开发者自己实现 Try / Confirm / Cancel 三个接口。
- 完全控制事务执行和回滚逻辑。
- 高可靠性,适合复杂业务场景。
- 适用场景:
- 业务操作复杂、非数据库操作(如调用第三方接口、消息队列等)。
- 原理:
- Try:资源预留或验证。
- Confirm:确认提交。
- Cancel:取消操作,回滚资源。
- 示意:
- Try -> Confirm (提交成功)
- Try -> Cancel (回滚)
C. SAGA 模式(基于事件的补偿事务)
- 特点:
- 通过 一系列本地事务 + 补偿事务 实现最终一致性。
- 不需要全局锁。
- 适合微服务异步业务场景。
- 适用场景:
- 跨服务操作,需要异步处理。
- 电商订单-库存-支付这种链式业务。
- 原理:
- 每个本地事务成功后触发下一个事务。
- 若中途失败,按顺序执行 补偿事务 回滚之前的操作。
- 优点:
- 异步,性能高。
- 缺点:
- 需要手动编写补偿逻辑。
D. XA 模式(基于二阶段提交的标准协议)
- 特点:
- 使用 XA 协议(两阶段提交,2PC)。
- 原子性强,支持分布式事务。
- 事务管理严格,性能相对低。
- 适用场景:
- 强一致性要求的场景。
- 多数据库操作,需要保证严格 ACID。
- 原理:
- Prepare 阶段:各资源管理器锁定资源并准备提交。
- Commit 阶段:事务管理器通知所有资源管理器正式提交。
- 若任何资源失败,则回滚所有资源。
| 模式 | 优点 | 缺点 | 适用场景 |
| AT | 透明、简单、自动回滚 | 对复杂业务不够灵活 | 关系型数据库 |
| TCC | 可控、可靠 | 开发成本高 | 复杂业务、非数据库操作 |
| SAGA | 异步、性能高 | 需要补偿逻辑 | 微服务链式业务 |
| XA | 严格 ACID | 性能低、实现复杂 | 多数据库、强一致性 |