C++11新特性解析与应用(1)
目录
一、C++11简介
二、统一的列表初始化
2.1{}初始化
2.2initializer_list
三、decltype
四、nullptr
五、array
六、左值和右值
七、左值引用和右值引用
八、移动拷贝
一、C++11简介
相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个重点去学习
由于c++11的新特性比较多,所以小编部分讲解一下c++11标准中比较常用的一些语法
二、统一的列表初始化
2.1{}初始化
- C++98
98允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定
struct Point
{int _x;int _y;
};
int main()
{int arr1[] = { 1, 2, 3, 4, 5 };int arr2[5] = { 0 };Point p = { 1, 2 };return 0;
}- C++11
C++11想统⼀数据的初始化⽅式,想实现⼀切对象皆可⽤{}初始化 ,所以ta扩大了用大括号{}括起的列表(也叫做列表初始化)的使用范围,使其可用于所有的内置类型和用户自定义的类型(本质是类型的转换,中间会产⽣临时对象,最后编译器会优化,变成直接构造),使用初始化列表时,可添加等号(=),也可不添加(小编建议添加)
class Date
{
public:Date(int year, int month, int day):_year(year),_month(month),_day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month; int _day;};int main(){// C++11支持的列表初始化,这里会调用构造函数初始化Date d1(2025, 10, 1); // 调用d1的构造函数Date d2{ 2025, 10, 2 };//调用d2的构造函数Date d3 = { 2025, 10, 3 };//调用d3的构造函数//用引⽤,引用的是{ 2025, 10, 1 }构造的临时对象,所以必须加constconst Date& d4={2025,10 1};vector<Date> ve;ve.push_back({2025,10,1});return 0;
} Date d1 = { 2025, 10, 11 };vector<int> ve = { 1,2,3,4,5 };
这两种初始化的原理是不一样的,d1是调用了拷贝构造 ,而ve则是用了initializer_list对vector的初始化
2.2initializer_list
- initializer_list是模板类,用于访问{}列表中的值,该{}列表是由类型为const T的元素组成的列表
int main()
{auto arr = { 1, 2, 3, 4, 5 };cout << typeid(arr).name() << endl;cout << sizeof(arr) << endl;return 0;
}

- initializer_list的底层
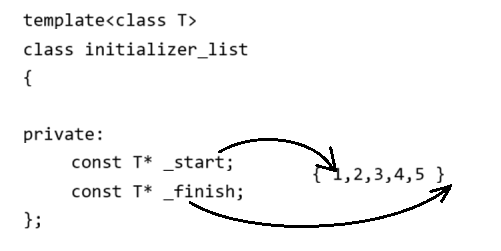
template<class T>
class initializer_list
{private:const T* _start;const T* _finish;
};
- 在c++11中使用花括号括起来的列表的类型会被编译器识别为initializer_list类型
Date d1 = { 2025, 10, 11 };vector<int> ve = { 1,2,3,4,5 };
在这里
- nitializer_list的私有成员变量只有两个const T*的指针,分别指向{}花括号括起来的列表的开头和结尾的下一个位置
- 编译器会将花括号括起来的列表的类型进行特殊处理为initializer_list
- 分别将initializer_list中两个指针分别指向{}列表的开头的地址和结尾的下一个位置的地址
- 这样支持了迭代器的begin和end,并且两个指针相减 ,就是size() :元素的个数
然后initializer_list再去初始化ve ,vector中构造函数:
template<class T>
vector
{
public:vector(initializer_list<T> lt){reserve(lt.size());//initializer_list支持了size(),可以获取initializer_list的元素个数for(auto e : lt)//initializer_list支持迭代器,所以可以使用范围for{push_back(e);//调用尾插将列表中的元素逐个插入即可}}
};
因为vector中,或者说不少容器中都增加了用initializer_list的构造函数,如 initializer_list构造map对象:
int main()
{//map<string, string> dict = { "sort","排序","left","左边" };//{{"sort","排序"},{"left","左边"}}被识别成了initializer_list<pair>map<string, string> dict = { {"sort","排序"},{"left","左边"} };//这里调了pair的拷贝构造return 0;
}三、decltype
int main()
{int i = 10;auto p = &i;//auto自动推导类型,但不能定义变量//auto x;cout << typeid(p).name() <<endl;//获取变量的类型cout << typeid(i).name() << endl;//只能看,不能用///typeid(i).name() ai;decltype(i) p1;//可以自己推导类型,并且不初始化 ,//这不和auto p2 = i;一个意思吗, 不是的 ,p1想当与 int p1 ,p1没有值,auto p2 = i ,p2是int p2=10 ;//decltype(i) p1;可以单纯定义一个变量//auto只能用来自动推导类型定义变量//typeid(i).name() 只能用来推导类型 ,不能定义变量//decltype(i)既可以自动推导类型定义变量,还可以只用来推导类型 或作模板实参: vector<decltype(i)> ve;//还可以推导一个表达式 : vector<decltype(x*y)> ve;return 0;
}- autoauto只能用来自动推导类型定义变量,但不能定义变量
- typeid(i).name() 只能用来推导类型 ,不能定义变量如: typeid(i).name() ai;
- decltype(i) p1;可以单纯定义一个变量 ,而不初始化如:decltype(i) p1 ,既可以自动推导类型定义变量,还可以只用来推导类型 或作模板实参: vector<decltype(i)> ve; 还可以推导一个表达式 : vector<decltype(x*y)> ve;
四、nullptr
//nullptr
int main()
{//由于NULL不够”专一“ ,ta既可以表示空指针 又可以表示0//而这里的nullptr只用来表示空指针int* p = NULL;//被替换成了 int* p=0,0可以用来赋值指针 ,但0依旧是整型return 0;
}- 由于NULL不够”专一“ ,ta既可以表示空指针 又可以表示0 ,当NULL用作空指针时,直接就替换成了0
- nullptr只用来表示空指针
五、array
//array (ps: 鸡肋)
int main()
{//array为了弥补c语言的数组中对越界的不检查, array[15]在这里调用operator[] 中会强制检查array<int, 10> a1;int a2[10];a1[15] = 10;a2[15] = 10;//array[15]在这里调用operator[] 中会强制检查数字小于size()return 0;
}- 比上不足,比下有余
六、左值和右值
int main()
{//左值和右值的最大区别 :左值可以取地址,右值不能被取地址//左值一个表示数据的表达式和变量名或解引用的指针//右值也是一个表示数据的表达式,如字面常量,表达式返回值 ,函数返回值//右值可以出现在赋值符号的右边,但是不能出现在赋值符号的左边,左值可以出现在赋值符号的右边,也可以出现在左边常见左值int* p = new int(0);int b = 1;const int c = 2;double x = 1.1, y = 2.2;常见右值10;字面常量x + y;表达式返回值func(x, y);函数返回值"xxxxx"是左值,表达式本身是首元素地址return 0;
}- 左值和右值的最大区别 :左值可以取地址,右值不能被取地址
- 左值一个表示数据的表达式和变量名或解引用的指针
- 右值也是一个表示数据的表达式,如字面常量(10),表达式返回值 (x+y),函数返回值func()
- 右值可以出现在赋值符号的右边,但是不能出现在赋值符号的左边,左值可以出现在赋值符号的右边,也可以出现在左边
七、左值引用和右值引用
//左值引用和右值引用
int main()
{//左值引用 : 给左值取别名//右值引用 :给右值取别名//左值引用int a = 0;int& r1 = a;//右值引用int&& r5 = 10;double x = 1.1, y = 2.2;double&& r6 = x + y;//x+y的临时变量是右值//左值引用不能直接给右值取别名 : int& z=10;(X) //要加const修饰 : const int& z=10 ,这里也可以看到实参传给函数的形参时,函数的形参要加const的修饰,这样既可以右值传过来,也可以左值传过来//右值引用不能直接给左值取别名 ,右值引用可以引用move以后的左值:int&& r7=move(a)//a(0)// move : 把左值变成右值return 0;
}- 左值引用 : 给左值取别名 ,右值引用 :给右值取别名
- 左值引用不能直接给右值取别名 : int& z=10;(X) ,要加const修饰 : const int& z=10 ,(这里也可以看到实参传给函数的形参时const的作用,函数的形参要加const的修饰,这样既可以右值传过来,也可以左值传过来)
- 右值引用不能直接给左值取别名 ,右值引用可以引用move以后的左值:int&& r7=move(a)//a(0)
- move : 把左值变成右值
左值引用的使用场景和价值是什么?
- 使用场景:
1:做参数
2: 做返回值 - 价值:减少拷贝
- 左值引用的缺陷 : 局部变量不能用引用返回,局部变量的生命周期结束了
为了解决左值引用的缺陷,有了移动拷贝(将左值变成右值)
八、移动拷贝
我们来看一段代码:
string& func()
{string str;cin >> str;//...return str;//此时str是临时变量,函数栈帧销毁,str变成野指针所以不能用string& 作返回值 ,要不然就给野指针取别名了//那返回值只能是string 要创建一个临时变量拷贝str返回
}
int main()
{string ret = func();//编译器在这里会优化,会在函数栈帧销毁前str变成野指针前,会直接用str去拷贝retreturn 0;
}
- str是临时变量,不能够传引用返回 ,因为函数栈帧销毁,str变成野指针所以不能用string& 作返回值 ,要不然就给野指针取别名了
- 那返回值只能是string 要创建一个临时变量拷贝str返回, 此处是深拷贝 ,在这里就会产生空间的消耗
- 好在编译器看不下这种拷贝又拷贝的情况 ,此处编译器会优化

在有了左值和右值的知识基础上,我们来看左值和右值的函数匹配:
void func(int& r)
{cout << "func(int& r)" << endl;
}
void func(int&& r)
{cout << "func(int&& r)" << endl;
}
int main()
{ int a = 0;int b = 1;func(a);//func(a + b);//会走更匹配的func(int&& r)return 0;
}- 此处a+b是右值,它会走更匹配的右值参数的函数func
string func1()
{string str("xxxxxxxxxx");//...return str;
}
int main()
{string ret = func1();// ,//移动拷贝:直接将str与ret发生swap(),不仅得到str的值,而且还把ret的值了str(str反正要销毁)/*移动拷贝的实现:string中重载operator=(string&& s)string& operator=(string&& s){swap(s);return *this;}*///以前的operator=就像是只写了void func(int& r),无论是左值还是右值,都调用这个函数,//而现在如果是右值就会调用更适合的void func(int&& r)//回到string str ,str是函数的返回值是右值,自定义类型的右值就是将亡值, 那么有了operator=(string&& s)之后//会去调用operator=(string&& s),就直接将str与ret发生swap(),不仅得到str的值,而且还把ret的值了str(str反正要销毁)//这个过程叫移动拷贝//移动拷贝降低了原来的拷贝的次数return 0;
}- 内置类型的右值 : 纯右值 ,自定义类型的右值: 将亡值
- 当func1返回的是左值时是深拷贝,到ret要三次深拷贝

- 而func1返回的是右值时是移动拷贝 ,移动拷贝:会直接将str与ret发生swap(),不仅得到str的值,而且还把ret的值了str(str反正要销毁),这样只用拷贝一次

移动拷贝的实现:在string类中重载了operator=(string&& s) (原先的operator=是针对左值,这个是针对右值)
在string中重载operator=(string&& s)
string& operator=(string&& s)
{swap(s);return *this;
}以前的operator=就像是只写了void func(int& r),无论是左值还是右值,都调用这个函数,而现在如果是右值就会调用更适合的void func(int&& r) ,回到string str ,str是函数的返回值是右值,自定义类型的右值就是将亡值, 那么有了operator=(string&& s)之后 ,会去调用operator=(string&& s),就直接将str与ret发生swap(),不仅得到str的值,而且还把ret的值了str(str反正要销毁) ,这个过程叫移动拷贝 ,移动拷贝降低了原来的拷贝的次数
那么,函数的返回值能是string&& 吗,str不是被识别成了右值吗
string&& func1()
{string str("xxxxxxxxxx");//...return str;//识别str是右值
}
int main()
{string ret = func1();return 0;
}- 答案是不行
- func1 返回值不能是string&& , 如果是,那么编译器就会去取别名,str是临时变量,函数栈帧销毁,str变成野指针所以不能用string&& 作返回值 ,要不然就给野指针取别名了
- 编译器看返回值是string,要传值拷贝才回去优化,编译器才会把str强行识别成右值,并且直接把str识别成右值 ,如果不优化,则会把返回值产生的临时变量识别成右值
总体来说:
1.编译器优化掉临时变量,直接把str当作返回值
2.把str当作返回值以后 ,有了移动拷贝,会把str强行看作右值
所以如果一开始传的string&& ,则就没有编译器的优化,不会把str当作返回值,更没有移动拷贝
为什么是强行 : move的作用是将左值转换成右值 ,这里可没写move哦 ,但都被强行识别成了右值 ,免得去原来写好的代码中加上move,那样太麻烦了