Spark专题-第三部分:性能监控与实战优化(2)-分区优化
这一篇不同于之前理论层面的讲解,会直接引入前段时间在工作中发现的问题,并配上思路和解决办法
问题回顾
事情的起因是一个批处理作业,在9月24号当天疯狂报错,原本凌晨就该结束的作业愣是拖到晚上
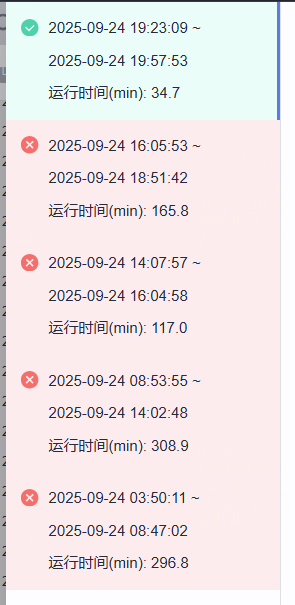
日志探查
那很自然会想到查看日志,找找报错的原因,这里就会通过之前提到的spark ui查看,也很自然的就能找到图中所提示的报错信息
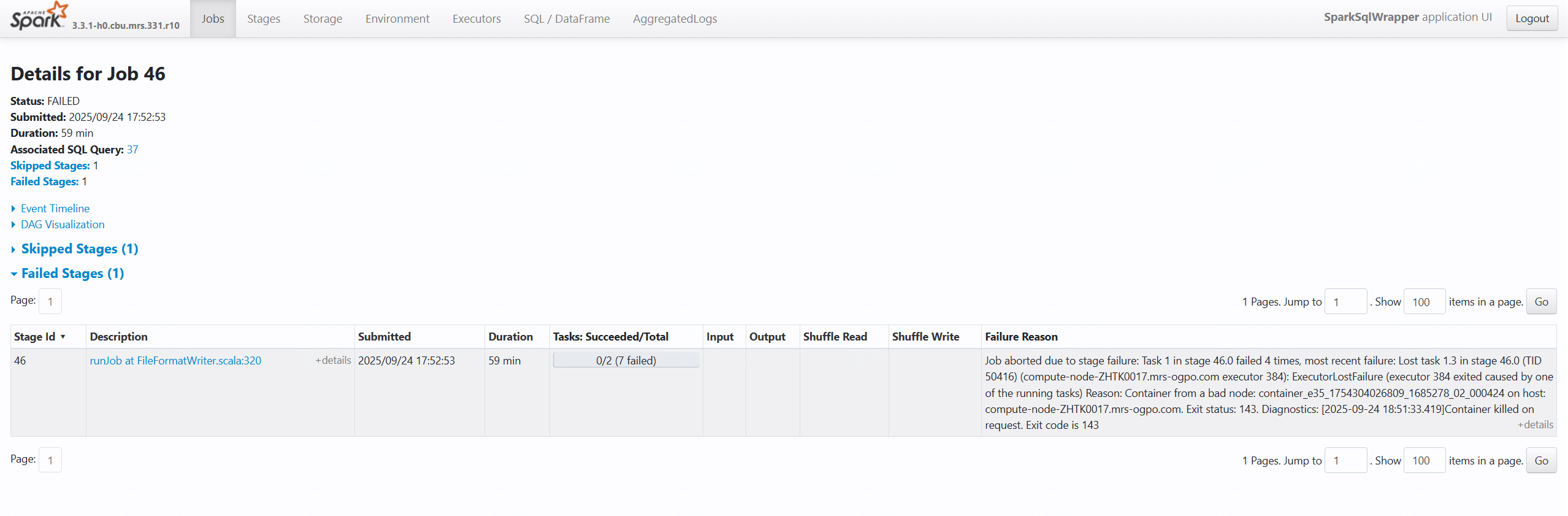
Failure Reason: Job aborted due to stage failure
Task 1 in stage 46.0 failed 4 times
Reason: Couldn't form a bad node; couldn't: ASI, Y15450404805, 1654378, Q0_00043
compute-node-ZR1002T7.mm-sgps.com
Error code: I4E
这种类型的报错通常属于网络通信或资源管理类问题
resource_issues = ["内存不足导致GC overhead","磁盘空间耗尽","CPU资源竞争激烈", "网络带宽瓶颈","容器资源限制触发"
]
但如果是网络原因,不会只有这一个作业异常,于是我们便初步怀疑是资源不足导致的,而这些猜想需要继续通过spark ui找证据。
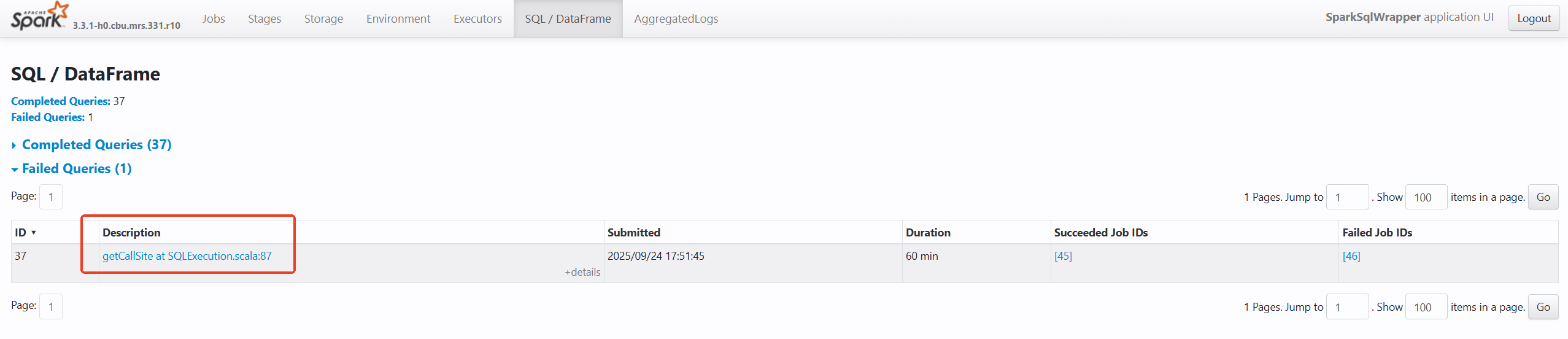
因为作业是通过提交spark sql的方式提交,所以我们当时想知道是哪段sql导致的报错,于是便去查看了SQL/DataFrame菜单,找到失败的语句
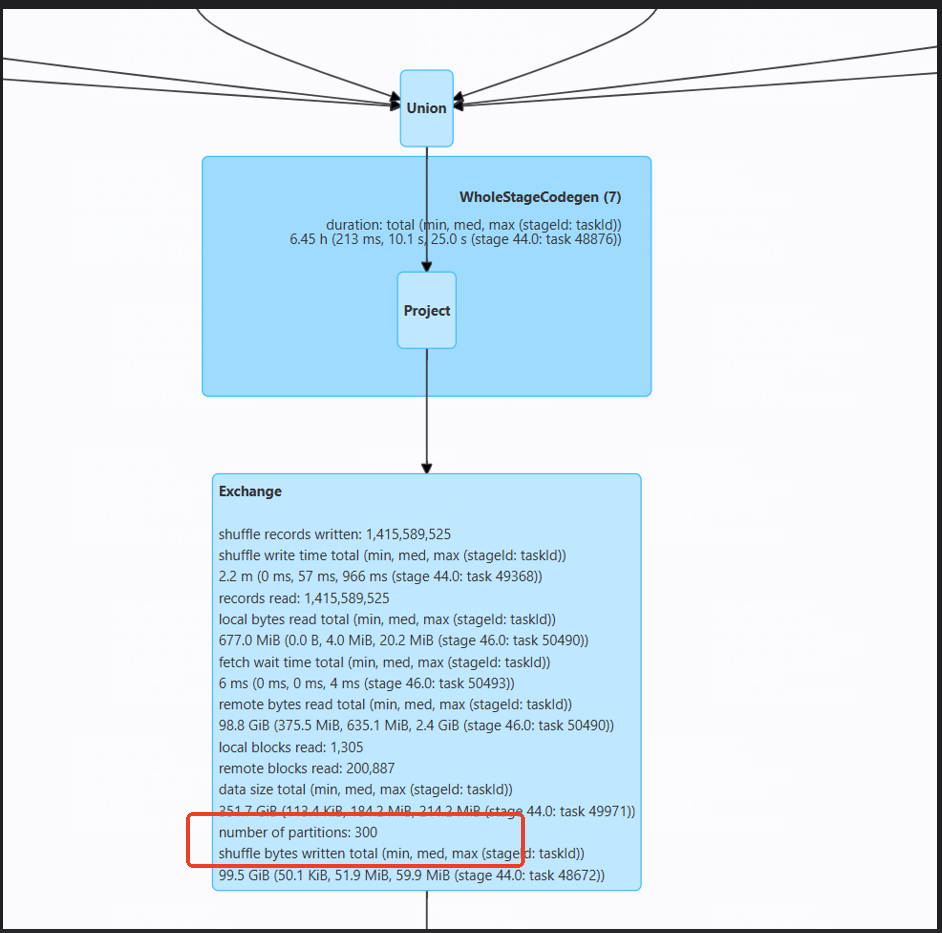
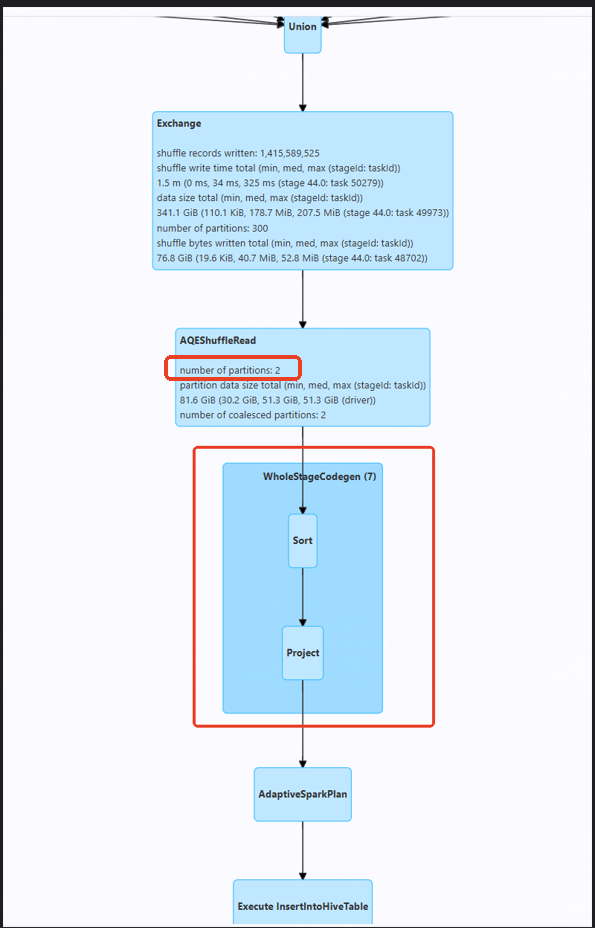
一路顺着数据流程往下找,发现了两个可疑的地方
- 14个亿的数据量,却只安排了2个partition处理,累死也算不出来
- 到sort算子部分就停止了
那此时的问题可能就出现在,用很少的分区去对极大的数据量进行排序,导致资源不足,出现报错
sql验证
当从日志里找出这些蛛丝马迹后,就该看看实际执行的sql能否和这些猜想对应上
where day between today(-2) and today(-1)
cluster by day
从执行的sql里,我们发现了这样一句,每天会更新最近2天的数据,所以day值只会有2个,而cluster by day 这句就是罪魁祸首了,将14亿的数据按2个day分组,调用sort算子,导致资源不足作业失败
性能优化
定位问题后,一切就好解决了,直接将最后一句改成
DISTRIBUTE BY day, ceil(rand() * 100)
虽然还是2个day,但通过ceil(rand() * 100) 起到稀释加盐的作用,将数据打散,优化后再查看日志就会发现这里的分区数已经变大,作业也就顺利执行完成