MySQL新学知识(一)
MySQL新学知识(一)
- 前言
- 一、3个函数
- 1.COALESCE
- 2.GROUP_CONCAT
- (1)先来一个简单的SQL如下:
- (2)再来一个SQL去掉country列中重复值如下:
- (4)在简单的SQL的基础上根据profit排序如下:
- (5)在简单的SQL的基础上先排序后去重如下:
- 3.ROW_NUMBER
- 二、GROUP聚合的附带功能
- 1.WITH ROLLUP
- 2.GROUPING
前言
👨💻👨🌾📝记录学习成果,以便温故而知新 本专题把一阶段学到知识MySQL做一个总结
本篇的4项是最近学习的,有的以前可能看到过,但是并没有深入学习了解,这次对照文档稍微深入地学习了一下。在MySQL文档中归属于Built-In Function and Operator Reference和Aggregate Functions下的GROUP BY Modifiers。其中有的功能5.7是支持的,有的功能要到8才支持,需要注意。
一、3个函数
1.COALESCE
MySQL文档https://dev.mysql.com/doc/refman/8.0/en/comparison-operators.html#function_coalesce
功能说明如下:
Returns the first non-NULL value in the list, or NULL if there are no non-NULL values.
The return type of COALESCE() is the aggregated type of the argument types.
很简短,意思也不难理解,就不翻译了。
示例如下:
mysql> SELECT COALESCE(NULL,1);
-> 1
mysql> SELECT COALESCE(NULL,NULL,NULL);
-> NULL
也很简短。
以前要是想实现这样的功能,一般都是用 CASE WHEN 来实现的。现在有了COALESCE,很简短。
以上只能说是“一顾倾人城”,用在表连接上才是“再顾倾人国”。
假定有x、y与z三个作业表,其中y表的in_id是x表的out_id,z表的in_id是y表的out_id或x表的out_id。
x表结构与数据如下:
CREATE TABLE `x` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`in_id` varchar(100) DEFAULT NULL COMMENT '输入ID',`out_id` varchar(100) DEFAULT NULL COMMENT '输出ID',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
| id | in_id | out_id |
|---|---|---|
| 1 | T1 | T1X1 |
| 2 | T2 | T2X1 |
| 3 | T2 | T2X2 |
| 4 | T3 | T3X1 |
| 5 | T4 | T4X1 |
y表结构与数据如下:
CREATE TABLE `y` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`in_id` varchar(100) DEFAULT NULL COMMENT '输入ID',`out_id` varchar(100) DEFAULT NULL COMMENT '输出ID',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
| id | in_id | out_id |
|---|---|---|
| 1 | T1X1 | T1X1Y1 |
| 2 | T2X1 | T2X1Y1 |
y表结构与数据如下:
CREATE TABLE `z` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`in_id` varchar(100) DEFAULT NULL COMMENT '输入ID',`out_id` varchar(100) DEFAULT NULL COMMENT '输出ID',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
| id | in_id | out_id |
|---|---|---|
| 1 | T1X1Y1 | T1X1Y1Z1 |
| 2 | T3X1 | T3X1Z1 |
| 3 | T4X1 | T4X1Z1 |
| 4 | T4X1 | T4X1Z2 |
对x、y与z表做关联查询SQL如下:
SELECT x.id AS X_ID, x.in_id AS X_IN_ID, x.out_id AS X_OUT_ID,
y.id AS Y_ID, y.in_id AS Y_IN_ID, y.out_id AS Y_OUT_ID,
z.id AS Z_ID, z.in_id AS Z_IN_ID, z.out_id AS Z_OUT_ID
FROM x LEFT JOIN y ON x.out_id = y.in_id LEFT JOIN z ON COALESCE(y.out_id, x.out_id) = z.in_id
ORDER BY x.id
查询结果如下图:
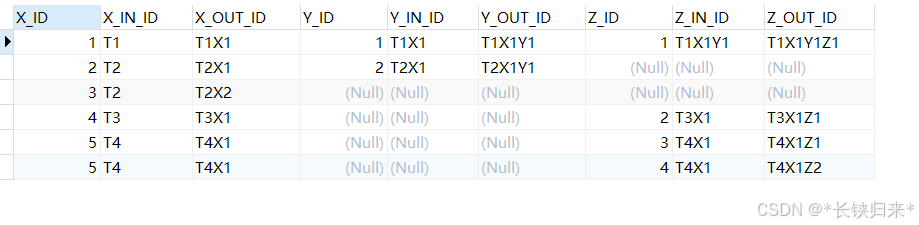
对于上述业务模式,COALESCE用在表关联上使得查询语句变得很简洁。
2.GROUP_CONCAT
MySQL文档https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_group-concat
功能说明如下:
This function returns a string result with the concatenated non-NULL values from a group. It returns NULL if there are no non-NULL values
语法如下:
GROUP_CONCAT([DISTINCT] expr [,expr …]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name …]]
[SEPARATOR str_val])
The result is truncated to the maximum length that is given by the group_concat_max_len system variable, which has a default value of 1024.
这里借用下面WITH ROLLUP这节的sales表来举例说明,因为sales是MySQL文档中WITH ROLLUP章节自带的,用在这里也挺合适。
(1)先来一个简单的SQL如下:
SELECT year, GROUP_CONCAT(country) AS country
FROM sales
GROUP BY year;
查询结果如下图:
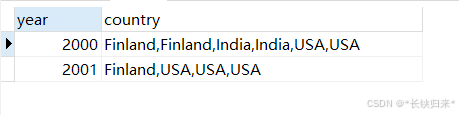
country列中有重复值。
(2)再来一个SQL去掉country列中重复值如下:
SELECT year, GROUP_CONCAT(DISTINCT country) AS country
FROM sales
GROUP BY year;
查询结果如下图:
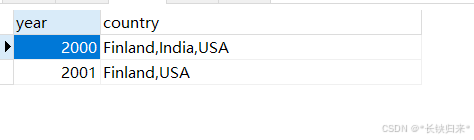
(4)在简单的SQL的基础上根据profit排序如下:
SELECT year, GROUP_CONCAT(country ORDER BY profit DESC) AS country
FROM sales
GROUP BY year;
查询结果如下图:

(5)在简单的SQL的基础上先排序后去重如下:
SELECT year, GROUP_CONCAT(DISTINCT country ORDER BY country DESC) AS country
FROM sales
GROUP BY year;
查询结果如下图:

3.ROW_NUMBER
MySQL文档https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html#function_row-number
这里还是借用下面WITH ROLLUP这节的sales表来举例说明。
SELECT
ROW_NUMBER() OVER w AS 'row_number',sales.*
FROM sales
WINDOW w AS (ORDER BY profit);
查询结果如下图:
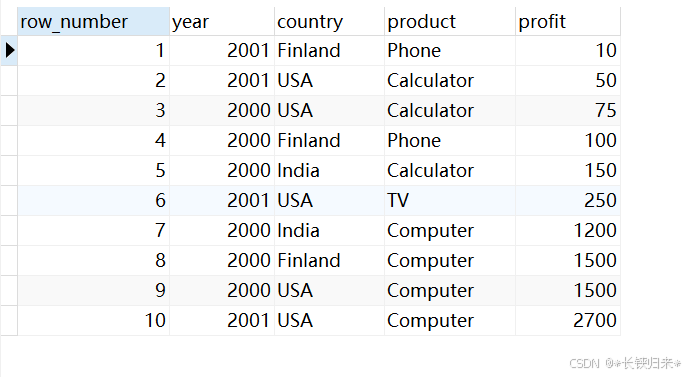
效果是有的,但是还需要增加一个“WINDOW”,使得语句变得复杂起来了。
二、GROUP聚合的附带功能
1.WITH ROLLUP
MySQL文档https://dev.mysql.com/doc/refman/8.0/en/group-by-modifiers.html
文档中附带一个表用来说明功能。建表语句如下:
CREATE TABLE sales
(year INT,country VARCHAR(20),product VARCHAR(32),profit INT
);
表内容如下:
| year | country | product | profit |
|---|---|---|---|
| 2000 | Finland | Computer | 1500 |
| 2000 | Finland | Phone | 100 |
| 2000 | India | Calculator | 150 |
| 2000 | India | Computer | 1200 |
| 2000 | USA | Calculator | 75 |
| 2000 | USA | Computer | 1500 |
| 2001 | Finland | Phone | 10 |
| 2001 | USA | Calculator | 50 |
| 2001 | USA | Computer | 2700 |
| 2001 | USA | TV | 250 |
WITH ROLLUP的功能就是加在GROUP BY子句后生成额外的汇总行,文档中的内容翻译起来感觉很拗口,就直接看下面的效果。
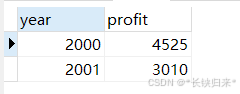
先看不加WITH ROLLUP的效果,语句如下:
SELECT year, SUM(profit) AS profit
FROM sales
GROUP BY year;
查询结果如下图:
加WITH ROLLUP的效果,语句如下:
SELECT year, SUM(profit) AS profit
FROM sales
GROUP BY year WITH ROLLUP;
查询结果如下图:
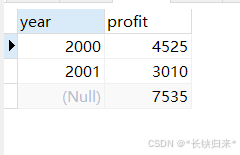
与不加WITH ROLLUP相比,多出了一行。
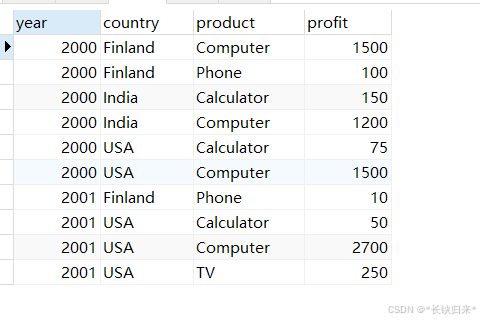
再看一个GROUP BY子句中3列情况,作为对比,先看不加WITH ROLLUP的效果,语句如下:
SELECT year, country, product, SUM(profit) AS profit
FROM sales
GROUP BY year, country, product;
查询结果如下图:
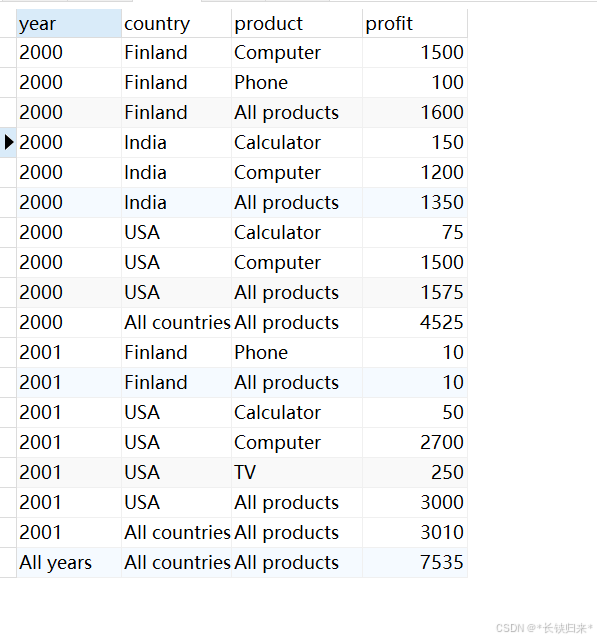
加WITH ROLLUP的效果,语句如下:
SELECT year, country, product, SUM(profit) AS profit
FROM sales
GROUP BY year, country, product WITH ROLLUP;
查询结果如下图:
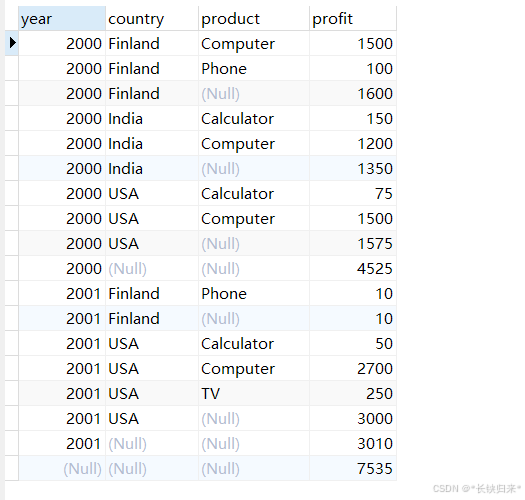
与不加WITH ROLLUP相比,多出了8行。
2组查询对比,感觉是GROUP BY子句中的列从右到左,每列在聚合的基础上再汇总。
2.GROUPING
GROUPING是一个函数,配合WITH ROLLUP用的。本文只简单介绍一下WITH ROLLUP文档中部分,更多GROUPING用法请参考GROUPING文档。
MySQL文档中如下语句:
SELECT
year, country, product, SUM(profit) AS profit,
GROUPING(year) AS grp_year,
GROUPING(country) AS grp_country,
GROUPING(product) AS grp_product
FROM sales
GROUP BY year, country, product WITH ROLLUP;
查询结果如下图:
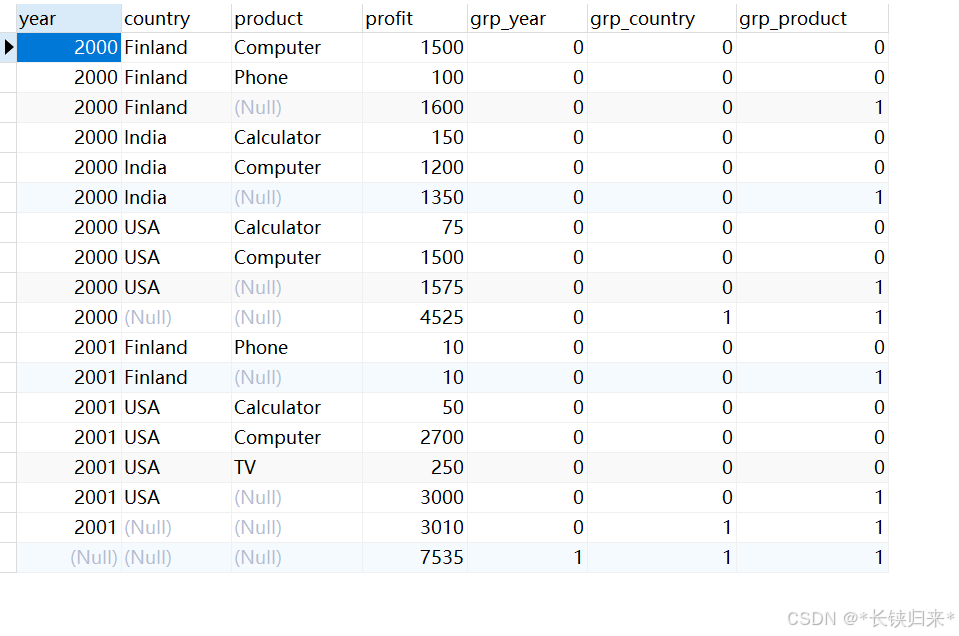
结果很显然如果参数是null返回1;其它返回0.
感觉作用并不明显,MySQL文档中如下的SQL能够体现出WITH ROLLUP的作用
SELECT
IF(GROUPING(year), 'All years', year) AS year,
IF(GROUPING(country), 'All countries', country) AS country,
IF(GROUPING(product), 'All products', product) AS product,
SUM(profit) AS profit
FROM sales
GROUP BY year, country, product WITH ROLLUP;
查询结果如图: