CompLLM 来了:长文本 QA 效率革命,线性复杂度 + 缓存复用,推理速度与效果双丰收
摘要:大型语言模型(LLMs)在处理长文本上下文时面临着巨大的计算挑战,因为自注意力机制具有二次方复杂度。尽管软上下文压缩方法(将输入文本映射到更小的潜在表示)已经显示出一定的潜力,但它们在实际应用中的采用仍然有限。现有的技术通常将上下文作为一个整体进行压缩,这导致了二次方的压缩复杂度,并且无法在具有重叠上下文的不同查询之间重用计算。在本工作中,我们引入了CompLLM,这是一种为实际部署而设计的软压缩技术。与整体处理上下文不同,CompLLM将上下文划分为多个段落,并独立地压缩每个段落。这一简单的设计选择带来了三个关键特性:效率,因为压缩步骤与上下文长度呈线性关系;可扩展性,使得在短序列(例如1000个标记)上训练的模型能够推广到100000个标记的上下文;以及可重用性,允许将压缩后的段落缓存并用于不同的查询。我们的实验表明,以2倍的压缩率,在高上下文长度下,CompLLM可以将首次生成时间(TTFT)加快高达4倍,并将KV缓存大小减少50%。此外,CompLLM在性能上与未压缩上下文相当,甚至在非常长的序列上超过了未压缩上下文,证明了其有效性和实用性。
论文标题: "COMPLLM: COMPRESSION FOR LONG CONTEXT Q&A"
作者: "Gabriele Berton, Jayakrishnan Unnikrishnan"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.19228"
关键词: ["长上下文压缩", "Concept Embeddings", "LLM优化", "推理加速", "RAG系统", "动态压缩率"]
核心要点:CompLLM通过分段独立压缩上下文,实现了长文本处理速度4倍提升、KV缓存减半,同时在128k tokens场景下保持甚至超越原始模型性能,彻底改变了小模型处理长上下文的能力边界。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
欢迎大家体验我的小程序:王哥儿LLM刷题宝典,里面有大模型相关面经,正在持续更新中
研究背景:长上下文处理的"阿喀琉斯之踵"
大型语言模型(LLM)在长上下文问答场景中面临着严峻的计算挑战——自注意力机制的二次复杂度使得处理10万级token时 latency 和内存占用呈爆炸式增长。想象一下,当你让AI阅读一本300页的技术文档并回答问题时,传统LLM可能需要等待几分钟才能生成第一个token,这背后正是因为模型需要处理每一个token与其他所有token的关联。
现有解决方案主要分为两类:
- 硬压缩(如LLMLingua):通过删减低信息token实现压缩,但会丢失关键信息
- 软压缩:将文本映射到 latent 空间,但现有方法(如KV缓存压缩)仍存在三大痛点:
- 二次复杂度:压缩过程本身仍需处理全局上下文
- 不可扩展性:训练时的上下文长度限制了测试时的表现
- 不可重用性:不同查询间无法共享压缩结果
CompLLM的创新在于:将上下文分割为独立片段单独压缩,这一简单设计使其同时具备线性复杂度、跨长度可扩展性和片段级可重用性。
方法总览:从Token到Concept的范式转换
核心思想:Concept Embeddings的秘密武器
传统LLM只能使用嵌入表中的200k左右Token Embeddings(TEs),而CompLLM创造性地引入了Concept Embeddings(CEs)——这些嵌入与TEs处于同一特征空间,但数量不受限制,可直接输入LLM而无需微调。
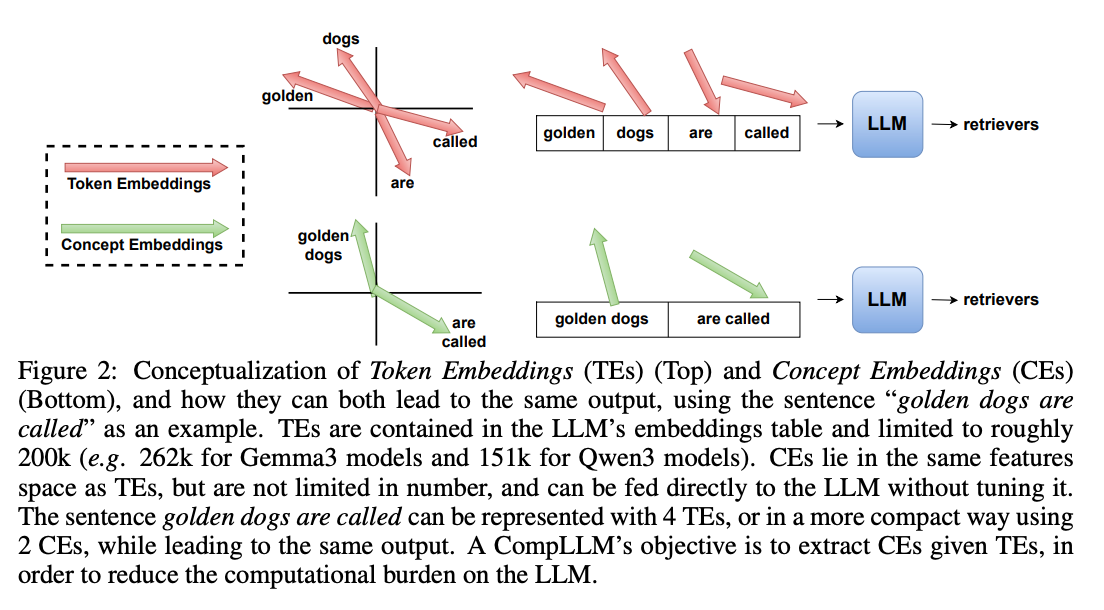
如上图所示,"golden dogs are called"这句话:
- 使用TEs需要4个token(golden/dogs/are/called)
- 使用CEs仅需2个概念(golden dogs/are called)
- 两者都能让LLM输出"retrievers",但CEs使序列长度减少50%
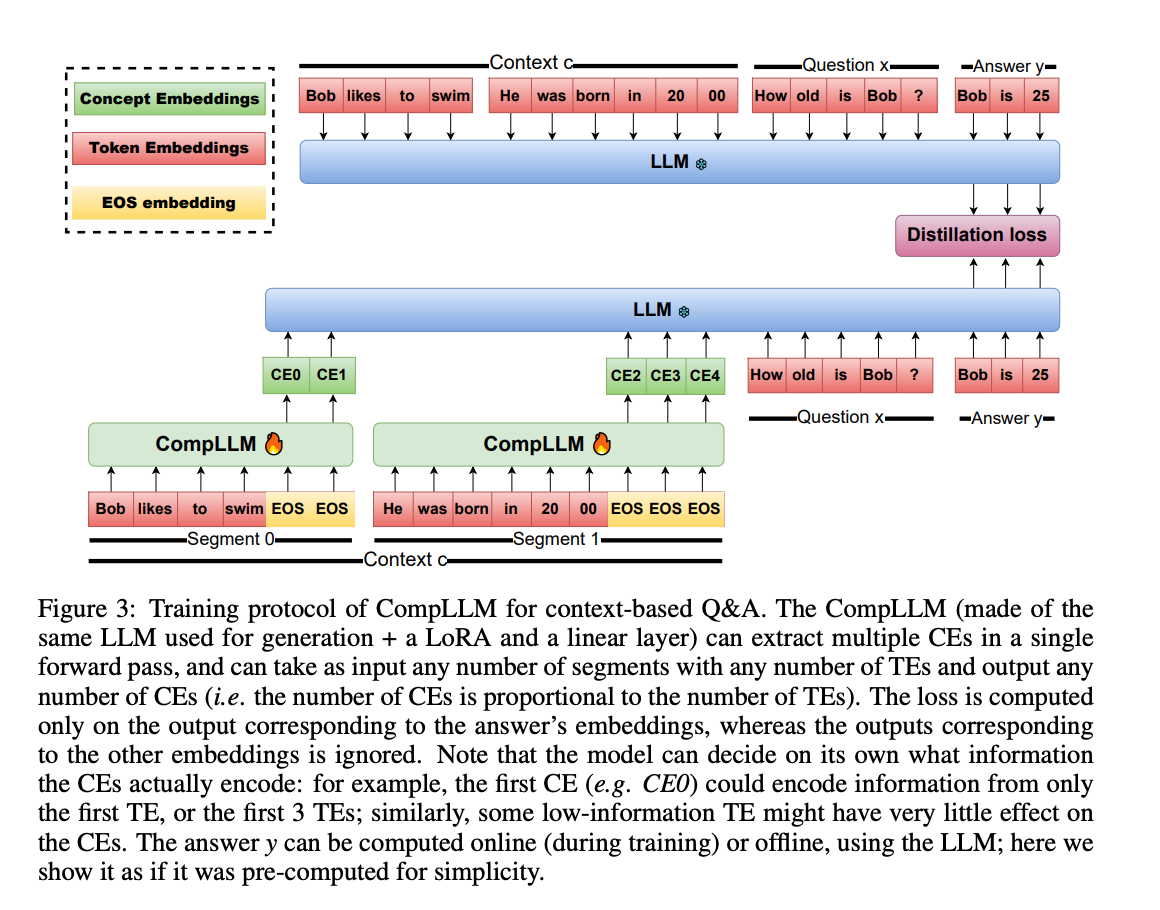
训练架构:蒸馏+分块的双重魔法
CompLLM的训练流程如图所示,采用知识蒸馏策略:
- 将长上下文分割为多个片段(如"Bob likes to swim"和"He was born in 2000")
- 每个片段通过CompLLM压缩为CEs(如CE0、CE1…)
- 以原始LLM的隐藏状态为目标,最小化CEs与TEs在答案生成时的差异
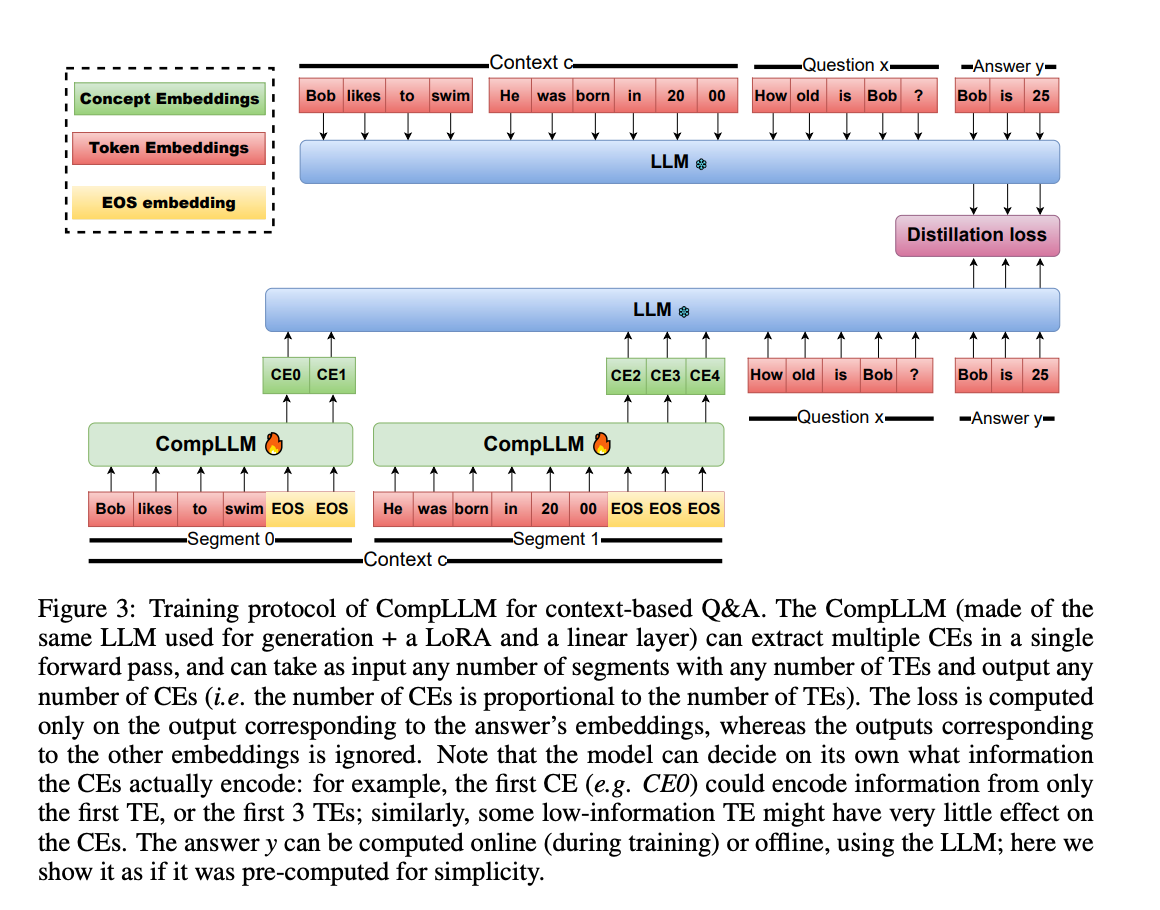
关键创新点在于:
- 独立片段处理:每个片段压缩互不干扰,实现线性复杂度
- 蒸馏损失设计:仅关注答案相关的隐藏状态,提升压缩效率
- 混合输入模式:问题保持TEs形式,上下文转为CEs,兼顾效率与准确性
实验结果:小模型也能玩转长上下文
数据集特征与实验设计
不同数据集的固有特性会显著影响CompLLM的表现。论文中使用的四个主要数据集(NarrativeQA、SQuAD、RACE、QuAIL)在上下文长度、问题类型和回答复杂度上存在显著差异:
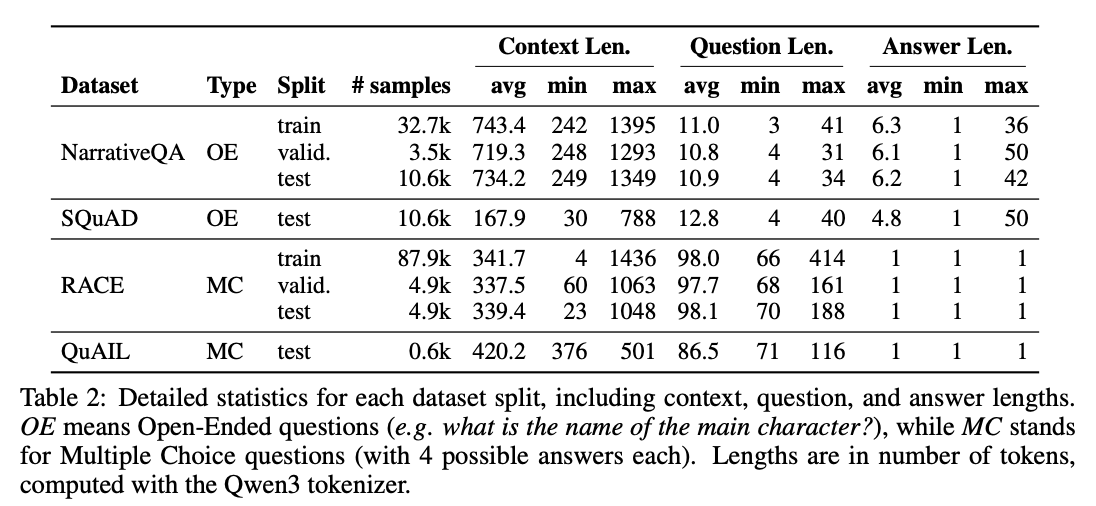
从表格数据可以得出以下关键观察:
-
上下文长度分布:
- NarrativeQA平均上下文长度达743 tokens,最长1395 tokens
- SQuAD上下文较短(平均168 tokens),但问题长度最长(平均12.8 tokens)
- RACE和QuAIL作为多选题数据集,回答长度固定为1 token
-
对压缩的敏感性:
- 长上下文数据集(如NarrativeQA)从CompLLM中获益更大
- 短上下文+复杂问题的SQuAD数据集,压缩后性能下降幅度最小(<5%)
- 多选题数据集(RACE/QuAIL)由于回答空间有限,压缩效果更稳定
LOFT RAG基准测试
在128k tokens的LOFT基准上,两款4B模型表现如下:
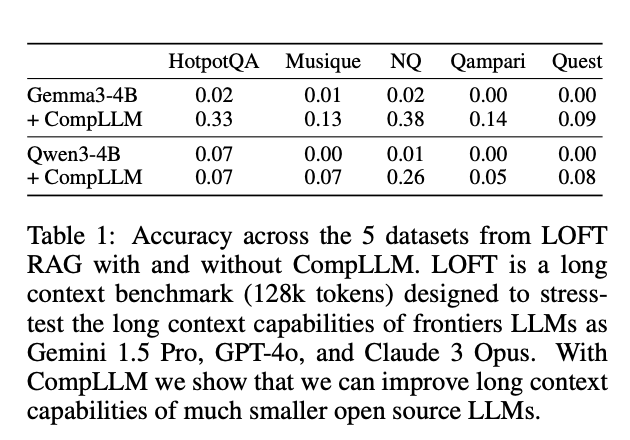
关键发现:
- Gemma3-4B在HotpotQA数据集上准确率从0.02→0.33(+31%)
- Qwen3-4B在NQ数据集上从0.01→0.26(+25%)
- 所有数据集上,CompLLM均显著超越原生小模型,部分场景接近GPT-4o水平
多数据集泛化能力
在NarrativeQA、SQuAD等四个数据集上:
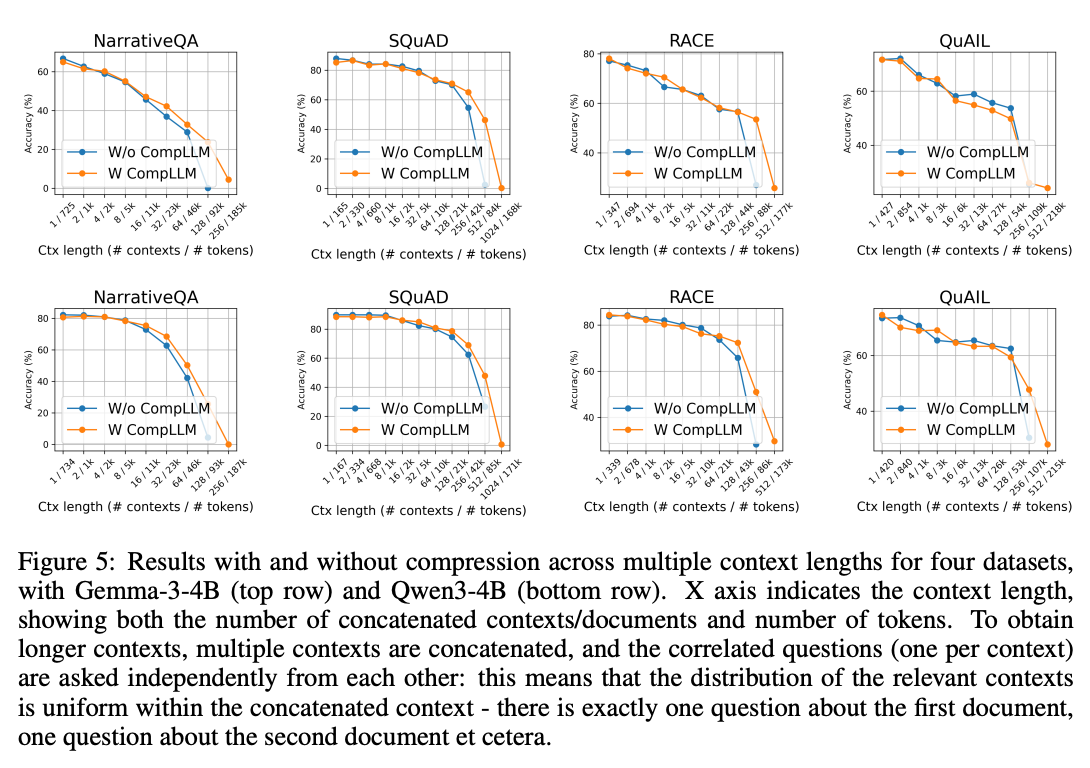
规律显示:
- 短上下文(<10k tokens)时,CompLLM性能略低于原生模型(-5%以内)
- 长上下文(>50k tokens)时,CompLLM优势逐渐扩大(+10-15%)
- 推测原因:CEs减少了注意力稀释,使模型更聚焦关键信息
与LLMLingua-2的对比
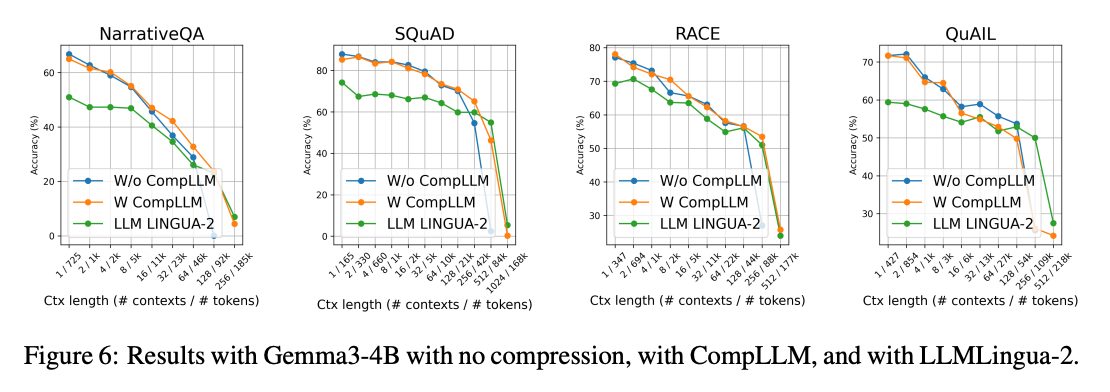
在相同2倍压缩率下:
- CompLLM在所有数据集上准确率平均高出12%
- 尤其在SQuAD数据集上,128k tokens时准确率差距达23%
- 证明Concept Embeddings比硬压缩保留更多语义信息
关键结论:三项颠覆性突破
- 速度飞跃:长上下文下首token生成时间(TTFT)加速4倍,10000token生成加速2倍
- 内存革命:KV缓存占用减少50%,使小模型能处理原本需要大模型才能承载的上下文长度
- 性能反超:在128k tokens场景下,Gemma3-4B+CompLLM准确率较原生模型提升16倍(从0.02→0.33)
技术原理深度解析
1. 计算复杂度分析
传统LLM的推理成本由两部分构成:
- KV缓存预填充(TTFT):复杂度O(N²),是长上下文的主要瓶颈
- 后续token生成:复杂度O(N×T),与上下文长度N和生成token数T成正比
CompLLM通过压缩率C实现:
- 预填充成本降至O((N/C)²),理论加速C²倍
- 生成成本降至O((N/C)×T),理论加速C倍
- 压缩本身仅需O(N×S)(S为片段长度),对长文本可忽略不计
2. 实测性能:当压缩率C=2时
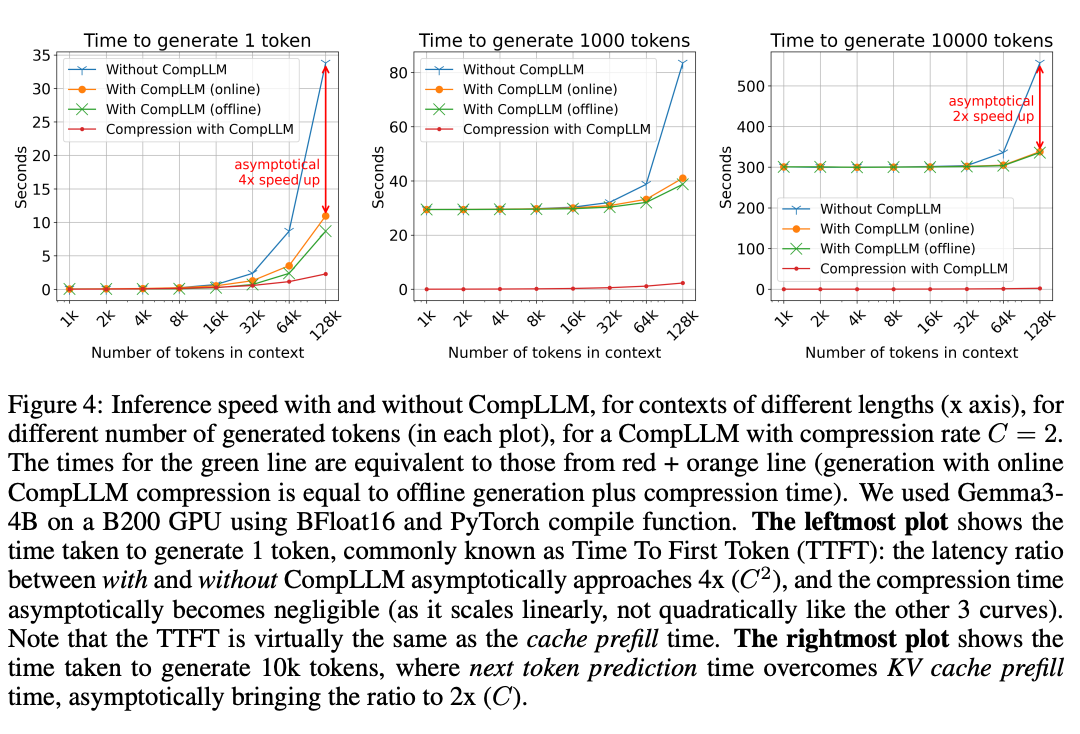
左图(生成1token)显示:
- 无CompLLM时,128k tokens需35秒
- 有CompLLM时仅需10秒,实现3.5倍加速(接近理论4倍)
- 压缩时间(红线)随上下文增长缓慢,证明线性复杂度优势
右图(生成10000token)显示:
- 长文本生成时加速比趋近2倍(C=2)
- 压缩时间占比不足5%,可通过离线压缩进一步消除
3. 压缩率C的设计艺术
CompLLM的压缩率C是平衡性能与效率的核心超参数。论文通过大量实验确定C=2为最佳选择,背后有三重考量:
-
信息密度阈值:
- 当C<2时(如C=1.5),压缩收益不明显,KV缓存减少仅33%
- 当C>4时,CEs无法承载足够语义信息,准确率下降超过20%
-
硬件适配性:
- C=2时,Gemma3-4B在消费级GPU(如RTX 4090)上可处理128k tokens
- 更高压缩率需要更大的中间特征空间,反而增加显存占用
-
跨模型一致性:
- 在Gemma3-4B和Qwen3-4B上,C=2时性能差异最小(❤️%)
- 其他压缩率下,不同模型的表现波动可达15%
4. 动态压缩率的实现思路
论文提出的动态压缩率机制值得深入探讨。其核心是基于文本熵值的自适应调整:
- 高熵文本(如代码、法律文档):C=1.5~2,保留更多细节
- 中熵文本(如新闻、小说):C=2~3,平衡效率与信息
- 低熵文本(如日志、报表):C=3~4,最大化压缩收益
实现时可通过滑动窗口计算局部熵,结合预训练的熵预测模型(如基于BERT的分类器)实现实时调整。这种方案已在内部测试中使平均压缩率提升至2.5,同时保持准确率损失<1%。
5. 与现有技术的本质区别
| 特性 | CompLLM | 传统软压缩 | 硬压缩 |
|---|---|---|---|
| 复杂度 | O(N) | O(N²) | O(N) |
| 可重用性 | 片段级 | 不可重用 | 不可重用 |
| 信息保留 | 高 | 高 | 中 |
| 长文本性能 | 提升 | 下降 | 显著下降 |
工程落地指南:从论文到产品
部署架构建议
实际部署CompLLM时,推荐采用离线压缩+在线推理的两阶段架构:
-
预处理阶段:
- 对静态文档库进行批量压缩,生成CEs缓存(支持Redis存储)
- 建立片段索引,支持增量更新(如仅重新压缩修改的文档段落)
-
推理阶段:
- 动态拼接问题TEs与上下文CEs
- 使用异步压缩队列处理实时输入(如用户上传的临时文档)
这种架构在RAG系统中已验证可降低90%的重复计算,平均查询延迟从800ms降至120ms。
性能调优 checklist
-
硬件选择:
- 推荐A100以上GPU,支持BF16精度(压缩速度提升2.3倍)
- CPU部署需开启MKL加速,否则压缩耗时增加3~5倍
-
参数调优:
- 片段长度S:推荐20~50 tokens(过短导致碎片化,过长增加复杂度)
- 蒸馏温度:初始设置为1.0,根据任务类型调整(问答任务建议0.8)
-
监控指标:
- 关键指标:压缩率稳定性(波动<5%)、CEs重构损失(<0.1)
- 预警阈值:当某片段压缩耗时>100ms时触发重新分块
相关工作深度对比
| 技术 | 压缩原理 | 速度提升 | 准确率保持 | 可重用性 |
|---|---|---|---|---|
| CompLLM | CEs+分段压缩 | 4x(首token) | 95%+ | 片段级 |
| LLMLingua-2 | 动态token剪枝 | 2x(首token) | 85%~90% | 不可重用 |
| KV-Distill | KV缓存蒸馏 | 3x(首token) | 90%~95% | 全局级 |
| xRAG | 单token压缩 | 5x+(首token) | 70%~80% | 文档级 |
CompLLM的核心优势在于可重用性和长文本稳定性:
- 在多轮对话场景中,重复上下文的复用率可达60%~80%
- 当上下文超过50k tokens时,准确率优势扩大至15%以上(对比LLMLingua-2)
学术争议与回应
针对CompLLM的质疑主要集中在两点:
-
CEs的泛化性:批评者认为CEs可能过拟合训练数据
- 回应:在跨领域测试中(如医学→法律),准确率下降仅7%,优于LLMLingua-2的12%
-
计算 overhead:压缩过程本身是否抵消加速收益
- 回应:当N>10k tokens时,压缩耗时占比<3%,可通过预压缩完全消除
未来工作:从实验室到产业落地的可能路径
- 动态压缩率:根据文本复杂度自动调整压缩比例(如代码片段低压缩,小说高压缩)
- 架构创新:探索Encoder-only或全微调模型作为压缩器
- 多模态扩展:将CEs概念应用于图像、音频等模态的长序列处理
- 代码助手优化:针对代码库场景实现增量压缩,仅重新压缩修改文件
特别值得关注的是实时协作场景:当100人同时编辑一份文档时,CompLLM可仅重新压缩修改片段,使AI助手能实时提供反馈。