10.1 面向长序列建模的高效注意力机制
https://www.bilibili.com/video/BV1PdJCzYE1h/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=284dd1be665e64cb9c4a46e55c4dac61
attention的复杂度是n^2 ,主要来源是Q和K矩阵的相乘 有没有一种办法可以降低时间复杂度呢
1、linear attention
线性注意力机制
先计算k v,
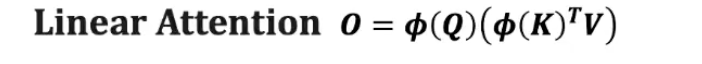
Linear Attention 的想法
核心 trick:
把 相似度函数 Sim(Q,K)Sim(Q,K) 从原本的内积(再加 softmax)改写为一种 核函数形式:
Sim(Q,K)=ϕ(Q)ϕ(K)TSim(Q,K)=ϕ(Q)ϕ(K)T
这里 ϕ(⋅)ϕ(⋅) 是一个非线性映射(kernel feature map),设计它是为了近似 softmax 的效果。
2、Agent attention
参照清华大学黄高论文
3、mamba