深度学习基础知识-深度神经网络基础
Batch Normalization (BN) 和 Layer Normalization (LN) 的区别
本文较长,建议点赞收藏,以免遗失。更多AI大模型开发 学习视频/籽料/面试题 都在这>>Github<< >>Gitee<<
- Batch Normalization (BN) 与 Layer Normalization (LN) 定义:
- BN 和 LN 都是通过以下公式进行计算,只是作用的维度不一样,Batch Normalization 是对这批样本的同一维度特征做规范化处理, Layer Normalization 是对这单个样本的所有维度特征做规范化处理
y=x−E(x)Var(x)+ϵ⋅γ+βy = \frac{x-E(x)}{\sqrt{\text{Var}(x) + \epsilon}} \cdot \gamma + \betay=Var(x)+ϵx−E(x)⋅γ+β
其中 γ\gammaγ 和 β\betaβ 是可学习参数 - 通过以下图片可以对 BN、LN 有更好的理解,其中蓝色元素都放在一起,计算 mean 和 var,带入上式计算,其中 。
- BN 和 LN 都是通过以下公式进行计算,只是作用的维度不一样,Batch Normalization 是对这批样本的同一维度特征做规范化处理, Layer Normalization 是对这单个样本的所有维度特征做规范化处理
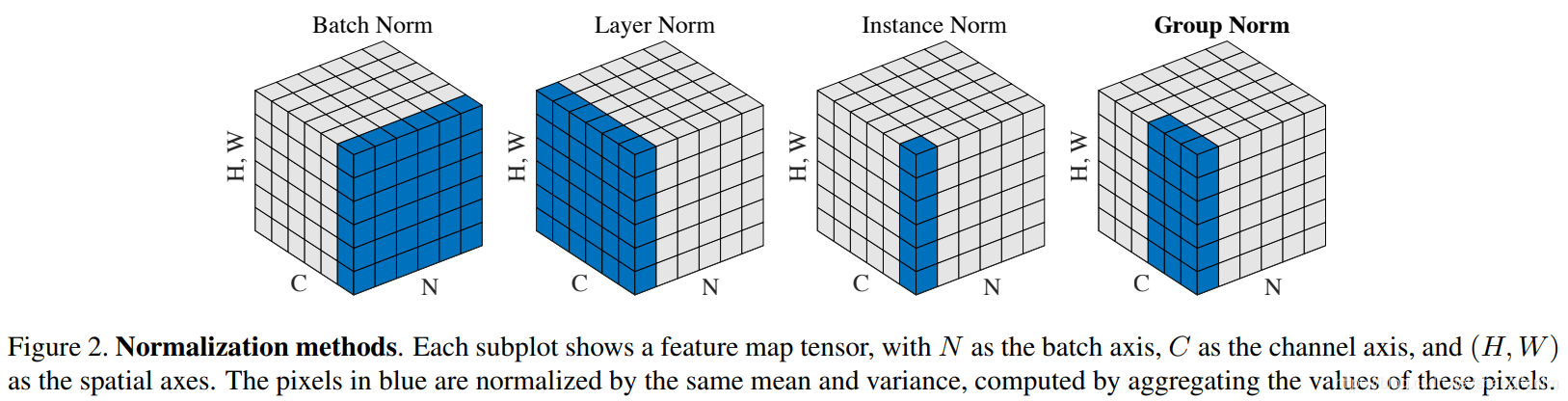
- BN 与 LN 区别介绍:
- 区别:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差
- 为什么 NLP 使用 LN 而不是 BN?
- LN 不依赖于 batch 的大小和输入 sequence 的长度,因此可以用于 batchsize 为 1 和 RNN 中 sequence 的 normalize 操作
- BN 不适用于 batch 中 sequence 长度不一样的情况,有的靠后面的特征的均值和方差不能估算;另外 BN 在 MLP 中的应用对每个特征在 batch 维度求均值方差,比如身高、体重等特征,但是在 NLP 中对应的是每一个单词,但是每个单词表达的特征是不一样的
- 如果特征依赖于不同样本间的统计参数(比如 CV 领域),那么 BN 更有效(它抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系);NLP 领域 LN 更合适(抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系),因为对于 NLP 或序列任务来说,一条样本的不同特征其实就是时序上字符取值的变化,样本内的特征关系是非常紧密的
- 相同点:标准化技术目的是让每一层的分布稳定下来,让后面的层可以在前面层的基础上安心学习,加快模型收敛
- 区别:
BN 中的参数量与可学习参数量分析
-
对于一个NCHW(批次大小,通道数,高度,宽度)格式的输入张量,Batch Normalization(BN)层通常包含两组可学习参数:缩放因子(scale)和偏移(shift)。
- 缩放因子(scale)参数:对于每个通道,都有一个缩放因子参数。因此,缩放因子参数的数量等于通道数(C)。
- 偏移(shift)参数:同样,对于每个通道,都有一个偏移参数。因此,偏移参数的数量也等于通道数(C)。
- 均值参数 (mean):均值参数等于通道数 ©
- 方差参数 (var):方差参数等于通道数 ©
- 所以,总共的可学习参数数量等于缩放因子参数和偏移参数的数量之和,即 2C。总参数量是 4C
-
基于 pytorch 的 BN 示例代码
# CV Example
import torch
import torch.nn as nn
batch, channel, height, width = 20, 100, 35, 45
input = torch.randn(batch, channel, height, width)
m = nn.BatchNorm2d(channel)
output = m(input)
for k, v in m.named_parameters():print(k, v.shape)
# -> weight torch.Size([100])
# -> bias torch.Size([100])
LN 中的可学习参数量分析
- 在 Layer Normalization 中,同样有 scale 和 shift 这两个参数允许模型学习调整输入数据的缩放和偏置,以便更好地适应训练数据的统计分布
- 对于文本数据
- 输入 tensor size 为 BxSxD,一般只在 D 维度上做归一化计算,计算得到的均值和方差尺寸为 BxSx1,gamma 和 beta 的尺寸为 D,所以可学习参数量为 2xD
# NLP Example
import torch
import torch.nn as nn
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
output = layer_norm(embedding)
for k, v in layer_norm.named_parameters():print(k, v.shape)
# -> weight torch.Size([10])
# -> bias torch.Size([10])
- 对于图像数据
- 输入 tensor size 为 NxCxHxW,一般在 CxHxW 维度上进行归一化计算,计算得到的均值和方差尺寸为 Nx1x1x1,gamma 和 beta 的尺寸为 CxHxW,可学习参数量为 2xCxHxW
import torch
import torch.nn as nnN, C, H, W = 20, 5, 10, 15
input = torch.randn(N, C, H, W)
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
for k, v in layer_norm.named_parameters():print(k, v.shape)
# -> weight torch.Size([5, 10, 15])
# -> bias torch.Size([5, 10, 15])
优化方法:SGD、Adam、AdamW 对比
- SGD优化阶段的梯度参数量等于模型参数量,Adam在保存优化阶段的梯度参数量外还需要保存其它参数,模型的参数量会在优化区间翻 4 倍
- Adam 的参数是【梯度】的一阶矩和二阶矩,跟网络的【激活值】没啥关系
- 参考: pytorch中常见优化器的SGD,Adagrad,RMSprop,Adam,AdamW的总结
- Adam(Adaptive Moment Estimation)优化算法,整合了RMSprop中的自适应梯度机制和动量梯度机制。
- AdamW优化器修正了Adam中权重衰减的bug,Decoupled Weight Decay Regularization
- AdamW与Adam对比,主要是修改了权重衰减计算的方式,一上来直接修改了,而不是把权重衰减放到梯度里,由梯度更新间接缩小
- 显存/内存消耗等其他细节和Adam没有区别