爬虫数据采集(实例分析1)
最近接了人生第一次独立编程商单,这里简单总结一下爬虫技巧。
原始需求是从某些网页获取所有文章列表数据,希望后续能够基于这些数据展开数据分析。
第一次做完整的爬虫尝试,所以总体整理一下思路。(之前课设做过类似涉及,但是没有批量采集过数据)。
一、需求分析
根据业务方需求,需要抓取并该媒体所有涉华报道(搜索【الصين】),输出 Excel/CSV 文件(每篇一行),包含:media(媒体),date(发布时间),title(文章标题),url(文章地址),summary(文章摘要),category(报道源)等相关字段,如图所示。
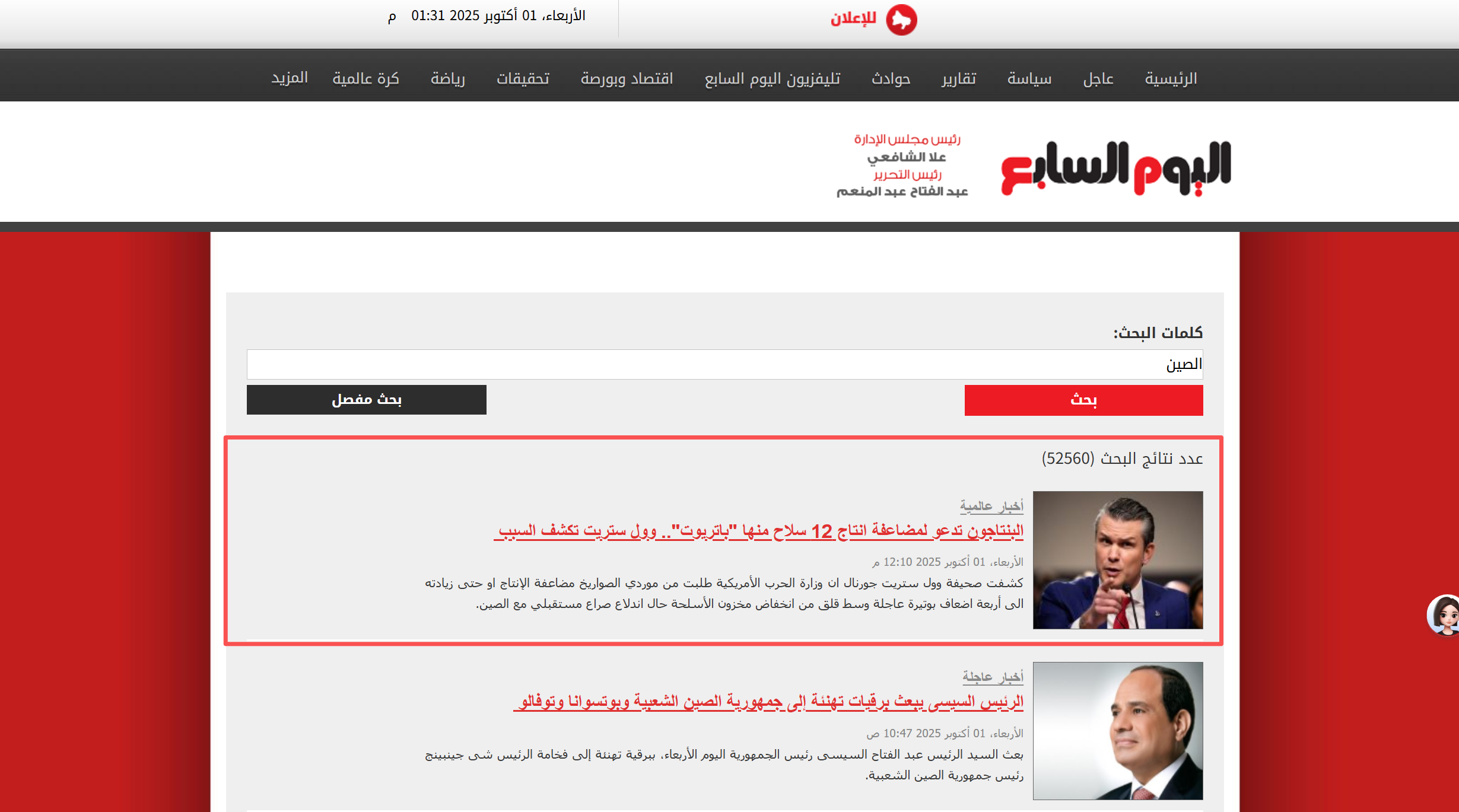
首先是分析网址。我收到的基础网址是:https://www.youm7.com/,然后通过搜索进入上述页面后,通过浏览并翻页我发现了网址规律。
关键词和页码数都在url中有体现,因此实现起来会更加方便一些。

搜索发现,该数据的总量是固定的,累计页面共有1752页。点击对应页码数量,或者直接更改url中的page参数可以实现翻页。
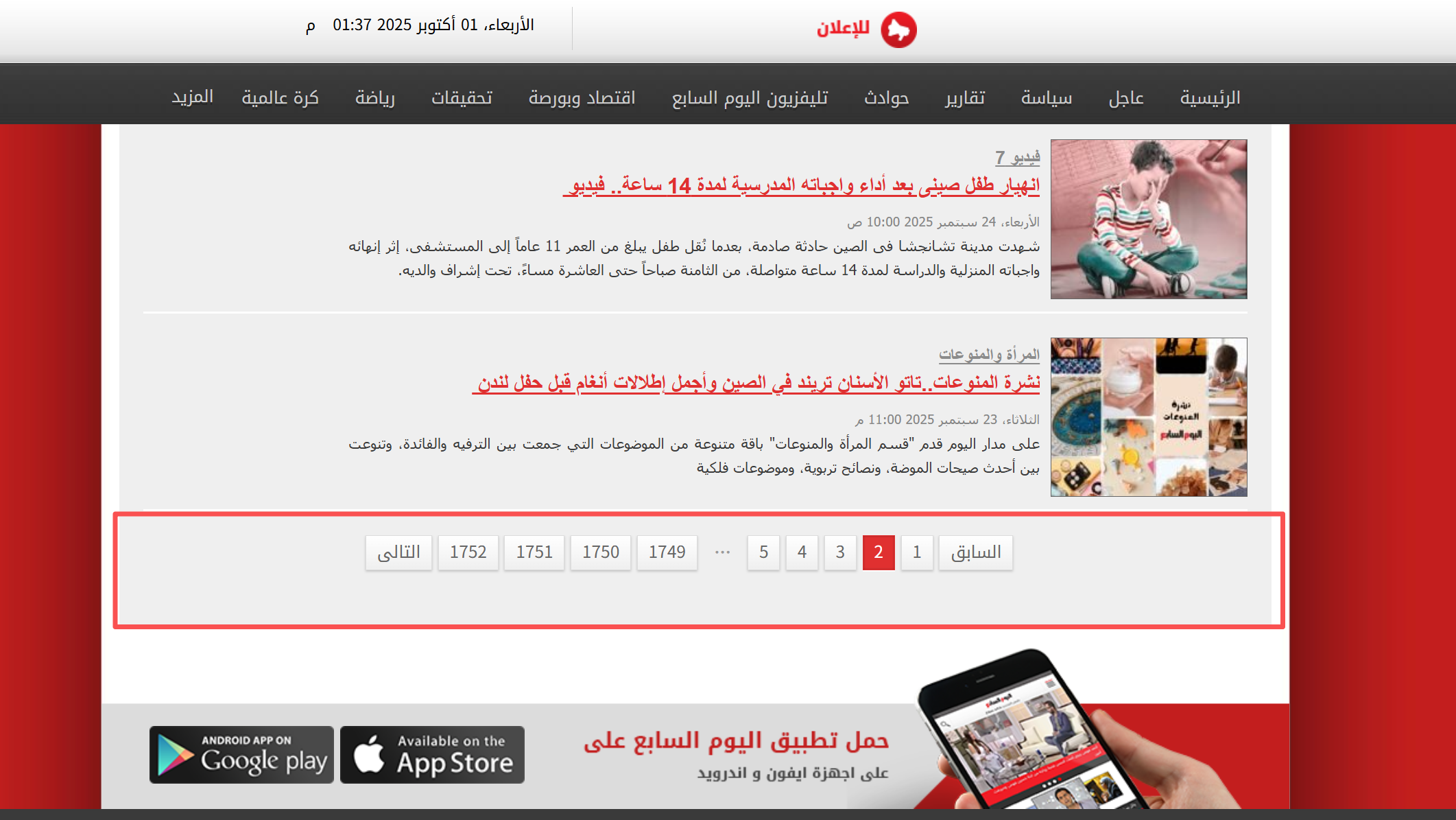
因此基于上述分析,展开代码实现编写。
二、代码实现
1. 固定参数
根据之前的项目习惯,还是先把固定字段敲定。在config文件或者文件开始时,将基础配置写入。该网页所有的文章数据源都是youm7,网址固定变换。
# youm7
BASE_URL_youm7 ="https://www.youm7.com/"
MEDIA_NAME_youm7 = 'youm7'
base_url_youm7 = BASE_URL_youm7 + 'home/Search?Drpcallist=&Drpseclist=&allwords={keyword}&page={page}'
2. 获取网页
(从网址到网页信息,url to html)
在这一步我之前做了很多尝试,通常可以直接采用requests模拟浏览器直接发送post或者get请求到网址,但是在做这个项目的时候请求一直403,查询发现应该是网站防御做的比较完善。
经过多次尝试最终选择了模拟实际浏览器访问这一操作,但是这样操作起来就非常费时,所以在过程中还加入了计时等操作。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import randomfrom datetime import datetime
import pandas as pd
import os# 等待页面稳定
def wait_for_page_stable(driver, check_interval=2, max_wait=60):elapsed = 0last_len = 0while elapsed < max_wait:time.sleep(check_interval)current_len = len(driver.page_source)if current_len != last_len:last_len = current_lenelapsed += check_intervalelse:breakreturn driver.page_source# 保存html到本地
def save_html(html_content, media_name, html_dir ="../output/html/"):# 创建HTML保存目录os.makedirs(html_dir, exist_ok=True)# 构建文件名filename = f"{html_dir}/{media_name}.html"# 保存HTML内容with open(filename, 'w', encoding='utf-8') as f:f.write(html_content)print(f"已保存HTML到: {filename}")# 主体逻辑
def main(keyword):print("开始计时!")start_time = time.time()global_index = 0 # 全局索引# 配置浏览器options = Options()options.headless = Falseoptions.add_argument("--disable-blink-features=AutomationControlled")options.add_argument("--start-maximized")driver = webdriver.Chrome(options=options)try:print(f"\n开始抓取关键词:{keyword}")# 构造网址start_page= 1url = base_url_ahram.format(keyword=keyword, page=start_page)# 加载网页driver.get(url)html_content = wait_for_page_stable(driver, check_interval=8, max_wait=60)# 保存HTML到本地————便于解析网页save_html(html_content, MEDIA_NAME)except Exception as e:print(f"抓取过程中出现错误: {e}")finally:driver.quit()elapsed = time.time() - start_timeprint(f"运行结束,累计用时 {elapsed:.1f} 秒")if __name__ == "__main__":keyword = "الصين" # 关键词main(keyword)上述网页解析将会获取到查询结果第一页,并生成html文件,便于数据解析。事实上,其实直接采用F12或者检查网页源码,捕捉该元素位置也可以得到html源码,这里保存的步骤只是方便检查我们是否正确获取到网页数据,并不是必须保存数据。通过:
html_content = wait_for_page_stable(driver, check_interval=8, max_wait=60)
这一步获取到的就已经是完整的html页面数据。
3. 解析数据
(从网页信息到获取所需准确信息,html to data)
通过解析网页(检查),可以发现我们所需要的数据保存在一个id="NewsSectionPaging"的<div>中,这个块中包含了所有的文章数据。而每个文章又独立存储于class="info section news-item" 的<div>中。
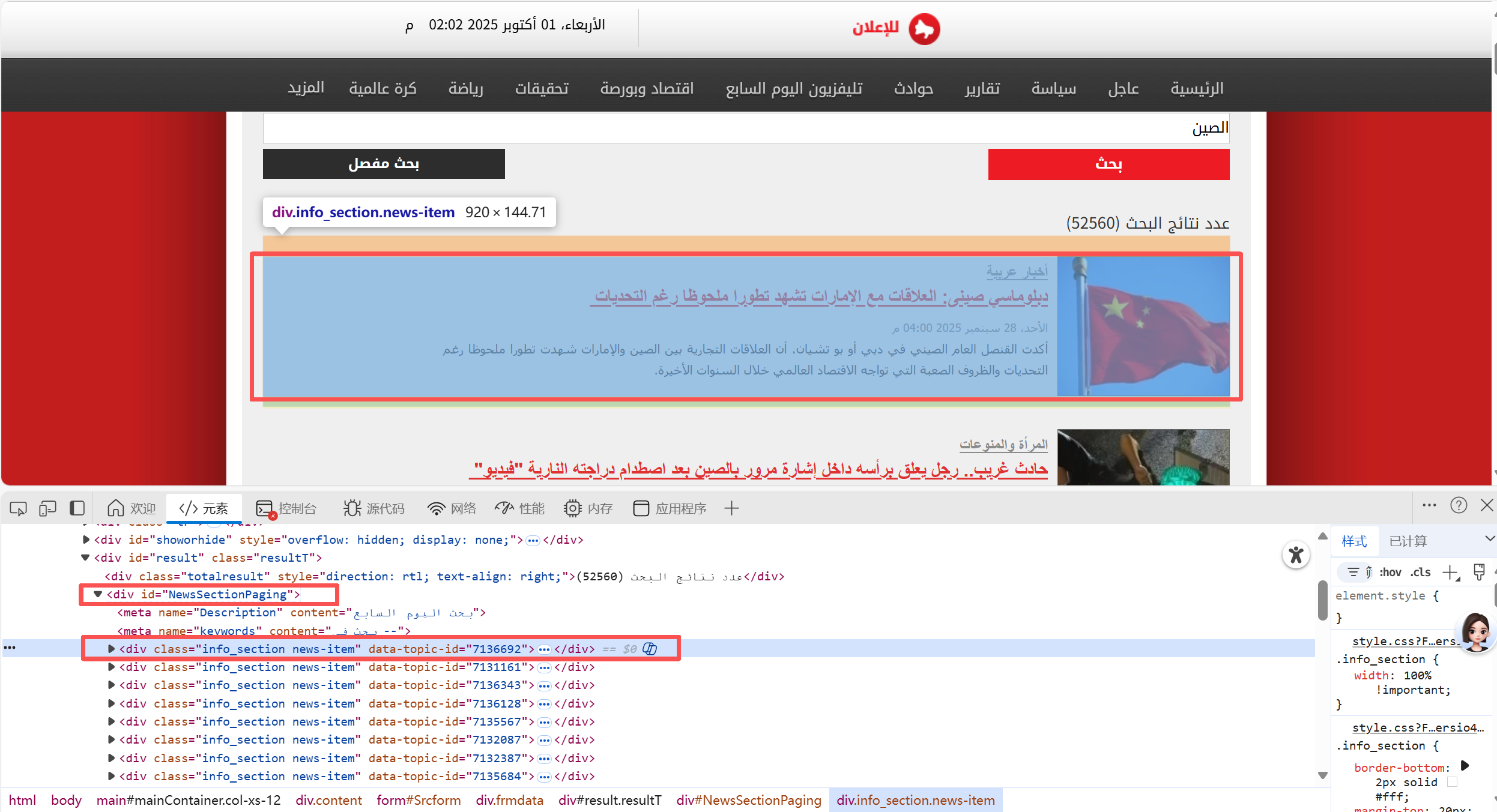
详细解析每个文章块的数据,可以发现:
media(媒体)由于网页不变,为固定参数;
category(报道源)在class="secref"的<span>中;
title(文章标题)包含在<h2>中;
url(文章地址)也存在于<h2>中的的块<a>的href中,但是观察可以看出是一个相对地址,需要和源地址拼接访问;
date(发布时间)位于第一个span中的<h3>;
summary(文章摘要)位于l_info_section <div>内的h3。
网页源码:
<div class="info_section news-item" data-topic-id="7136692"><div class="r_info_section"><a href="/story/2025/9/28/دبلوماسي-صينى-العلاقات-مع-الإمارات-تشهد-تطورا-ملحوظا-رغم-التحديات/7136692"><img src="https://img.youm7.com/medium/12201412162545.jpg" title="أكدت القنصل العام الصيني في دبي أو بو تشيان، أن العلاقات التجارية بين الصين والإمارات شهدت تطورا ملحوظا رغم التحديات والظروف الصعبة التي تواجه الاقتصاد العالمي خلال السنوات الأخيرة." alt="دبلوماسي صينى: العلاقات مع الإمارات تشهد تطورا ملحوظا رغم التحديات " onerror="this.src='https://img.youm7.com/images/graphics/erorr-img-med.jpg'" _mstalt="40841671" style="direction: rtl; text-align: right;"></a></div><div class="l_info_section"><span class="secref"><a href="/أخبار عربية-88" style="direction: rtl; text-align: right;">أخبار عربية</a></span><h2><a href="/story/2025/9/28/دبلوماسي-صينى-العلاقات-مع-الإمارات-تشهد-تطورا-ملحوظا-رغم-التحديات/7136692" style="direction: rtl; text-align: right;">دبلوماسي صينى: العلاقات مع الإمارات تشهد تطورا ملحوظا رغم التحديات </a></h2><span><h3 style="direction: rtl; text-align: justify;">الأحد، 28 سبتمبر 2025 04:00 م</h3></span><h3 style="direction: rtl; text-align: justify;">أكدت القنصل العام الصيني في دبي أو بو تشيان، أن العلاقات التجارية بين الصين والإمارات شهدت تطورا ملحوظا رغم التحديات والظروف الصعبة التي تواجه الاقتصاد العالمي خلال السنوات الأخيرة.</h3></div>
</div>根据上述网页分析,完成网页解析代码如下:
from bs4 import BeautifulSoup
import re
from config.config import *def extract_news_from_html_youm7(html_content, current_page, global_index):soup = BeautifulSoup(html_content, 'html.parser')news_container = soup.find('div', {'id': 'NewsSectionPaging'})if not news_container:return [], global_indexnews_items = []news_divs = news_container.find_all('div', class_='info_section news-item')# # 正则表达式用于从URL中提取日期# date_pattern = re.compile(r'/story/(\d{4})/(\d{1,2})/(\d{1,2})/')for div in news_divs:try:# 提取标题和链接title_elem = div.find('h2').find('a')title = title_elem.get_text(strip=True)url = title_elem.get('href', '')# 确保URL是完整的绝对URLif not url.startswith(('http://', 'https://')):url = BASE_URL_youm7 + url if url.startswith('/') else BASE_URL_youm7 + '/' + url# # 从URL中提取日期# date_match = date_pattern.search(url)# if date_match:# year, month, day = date_match.groups()# # 格式化日期为 YYYY-MM-DD# date_str = f"{year}-{month.zfill(2)}-{day.zfill(2)}"# else:# date_str = ""# 尝试从HTML中提取日期作为备用# try:# l_info_section = div.find('div', class_='l_info_section')# if l_info_section:# date_span = l_info_section.find('span')# if date_span:# date_h3 = date_span.find('h3')# if date_h3:# html_date = date_h3.get_text(strip=True)# # 如果URL中没有日期,使用HTML中的日期# if not date_str:# date_str = html_date# except:# pass## # 提取文章摘要# all_h3 = div.find_all('h3')# summary = all_h3[1].get_text(strip=True) if len(all_h3) > 1 else ''# 找到第一个span内的h3(发布时间)date_str = soup.select_one('span h3').get_text(strip=True)# 找到直接位于l_info_section div内的h3(摘要)summary = soup.select_one('.l_info_section > h3').get_text(strip=True)# print(f"发布时间: {date_str}")# print(f"摘要: {summary}")# 提取出版物来源/类别category_elem = div.find('span', class_='secref')category = category_elem.find('a').get_text(strip=True) if category_elem and category_elem.find('a') else ''global_index += 1news_items.append({'index': global_index,'page': current_page,'media': MEDIA_NAME_youm7,'date': date_str,'title': title,'url': url,'summary': summary,'category': category,})except Exception as e:print(f"Error parsing news item: {e}")continuereturn news_items, global_index说明:
1、上述代码中注释掉的部分是采取了另一种提取发布日期的方式,通过分析网页数据可以发现,url中同样包含着发布时间(或创建时间),且其为便于处理的标准格式(年/月/日,阿拉伯数字),因此除了直接提取网页上的发布时间外,为便于后续处理也可以采用从url正则匹配的方式获取发布时间。
2、index和page是我希望给每个文章都编上索引并存上页码,便于后续返回查找对应页面数据校对,非必须参数。但page参数在补充中还会用到,因此建议保存,index无实意。
4. 保存数据
(data to csv)
通过前面获取并解析完数据后,逐页将数据存储到本地csv中,即可完成所有数据提取和保存。
# 保存数据到本地
def save_news_to_csv(news_data, filename): # ="temp/youm7_raw_all_data1-30.csv"if not news_data:returndf = pd.DataFrame(news_data)file_exists = os.path.isfile(filename)if file_exists:df.to_csv(filename, mode='a', header=False, index=False, encoding='utf-8-sig')else:# 确保目录存在os.makedirs(os.path.dirname(filename), exist_ok=True)df.to_csv(filename, index=False, encoding='utf-8-sig')print(f"已保存 {len(news_data)} 条数据到 {filename}")# 主函数追加调用
# 调用函数解析网页数据
news_items, global_index = extract_news_from_html_youm7(html_content, current_page, global_index)
if news_items:save_news_to_csv(news_items, filename)print(f"第 {current_page} 页抓取完成,获取了 {len(news_items)} 条新闻")
else:print(f"第 {current_page} 页没有找到新闻内容")5. 其他补充(断点重启)
其实基于前面的分析已经能够获取到对应的参数了,为什么还需要补充一点呢?因为模拟浏览器解析的过程可能由于一些主观或客观的原因中断或者未采集到某些网页的数据。当数据采集中断后,重启代码极有可能让所有数据从头开始采集,因此在实际采集过程中,我优化了代码逻辑,当出现采集断点时,自动从上次未采集过的页面开始采集,避免重复采集造成的数据重复和时间浪费。
def get_saved_pages(filename): # ="temp/youm7_raw_all_data1-30.csv""""获取已保存的页码"""saved_pages = set()# 检查文件是否存在if not os.path.isfile(filename):return saved_pagestry:# 读取CSV文件df = pd.read_csv(filename)# 获取所有不重复的页码if 'page' in df.columns:saved_pages = set(df['page'].unique())print(f"已发现 {len(saved_pages)} 个已保存的页面")except Exception as e:print(f"读取已保存页面时出错: {e}")return saved_pages# 在主函数调用前增加下述调用逻辑
def main(...):...# 获取已保存的页码filename = save_path+ f"{MEDIA_NAME_ahram}_news_data_page.csv"saved_pages = get_saved_pages(filename)# 确定需要抓取的页面all_pages = set(range(start_page, end_page + 1))pages_to_scrape = sorted(list(all_pages - saved_pages))if not pages_to_scrape:print(f"所有页面 {start_page} 到 {end_page} 都已抓取完成")returnprint(f"完成抓取页数: {len(saved_pages)}")print(f"待抓取页数: {len(pages_to_scrape)}")...此时pages_to_scrape中包含的即是未抓取到数据的所有页码数。
6. 主函数完整逻辑
基于前面所有函数的构造,下面是完整的从网页到数据逻辑,html可以选择不用保存(按需保存),总体逻辑是先确认需要获取信息的网页列表,然后根据待抓取的页面来提取信息。
数据流程大概经历了从url到html到data到csv四个流程,计时是为了中途测试中便于了解项目进程进行到何处了,也是非必须,仅作项目日志使用。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import random# 主体逻辑
def main(keyword, start_page=1, end_page=20, save_path=f"temp/"):print("开始计时!")start_time = time.time()global_index = 0 # 全局索引# 获取已保存的页码filename = save_path+ f"{MEDIA_NAME_ahram}_news_data_page.csv"saved_pages = get_saved_pages(filename)# 确定需要抓取的页面all_pages = set(range(start_page, end_page + 1))pages_to_scrape = sorted(list(all_pages - saved_pages))if not pages_to_scrape:print(f"所有页面 {start_page} 到 {end_page} 都已抓取完成")returnprint(f"完成抓取页数: {len(saved_pages)}")print(f"待抓取页数: {len(pages_to_scrape)}")print(pages_to_scrape)# 配置浏览器options = Options()options.headless = Falseoptions.add_argument("--disable-blink-features=AutomationControlled")options.add_argument("--start-maximized")driver = webdriver.Chrome(options=options)try:print(f"\n开始抓取关键词:{keyword}")for current_page in pages_to_scrape:# 构造网址start_row = (current_page - 1) * 10url = base_url_ahram.format(keyword=keyword, start_row=start_row)# 加载网页driver.get(url)html_content = wait_for_page_stable(driver, check_interval=8, max_wait=60)# # 如果需要保存HTML到本地————便于解析网页# if html_content:# save_html(html_content, MEDIA_NAME, "news_project/output/html/")# 提取信息(网页解析结构不同) #news_items, global_index = extract_news_from_html_ahram(html_content, current_page, global_index)# 保存信息if news_items:save_news_to_csv(news_items, filename)print(f"第 {current_page} 页抓取完成,获取了 {len(news_items)} 条新闻")else:print(f"第 {current_page} 页没有找到新闻内容")# 每10页输出一次耗时if current_page % 10 == 0:elapsed = time.time() - start_timeprint(f"关键词 {keyword} 已抓取到 {current_page} 页,用时 {elapsed:.1f} 秒")# 添加随机延迟,避免被反爬time.sleep(random.randint(1, 3))print("所有页面抓取完成")except Exception as e:print(f"抓取过程中出现错误: {e}")finally:driver.quit()elapsed = time.time() - start_timeprint(f"运行结束,累计用时 {elapsed:.1f} 秒")if __name__ == "__main__":keyword = "الصين" # 关键词.txtmax_page = 2048main(keyword, start_page=1, end_page=max_page, save_path=f"../temp/")以上基本上的整个网页解析的完整代码逻辑,大家做类似网页数据提取的时候思路可供参考。