NeurIPS 2025 | 北大等提出C²Prompt:解耦类内与类间知识,攻克FCL遗忘难题!
在联邦持续学习场景中,模型需同时应对跨任务的时间遗忘和跨客户端数据异构性引发的空间遗忘。现有的基于提示学习的FCL方法虽表现优异,但普遍忽视了客户端之间提示(prompt)的类感知知识一致性问题。具体而言,这包括客户端间的“类内分布差异”和提示间的“跨类知识混淆”。这种不一致性在提示通信(聚合)过程中会加剧新旧知识的冲突,从而激化遗忘问题。
为应对此挑战,本文提出了一种名为 C²Prompt (Class-aware Client Knowledge Interaction) 的新方法。该方法通过显式地增强提示通信中的类感知知识一致性来缓解时空遗忘。C²Prompt设计了两大核心模块:1) **局部类分布补偿(Local Class Distribution Compensation, LCDC)**机制,通过估计全局类分布并补偿本地分布,以减少客户端间的类内语义差异。2) **类感知提示聚合(Class-aware Prompt Aggregation, CPA)**方案,利用提示与类别的关联性来指导聚合过程,选择性地加强相关知识,减轻跨类知识冲突。通过这种方式,C²Prompt 实现了更精准高效的知识迁移与整合,在多个 FCL 基准测试中取得了当前最佳性能。
另外我整理了NeurIPS 2025 CV 相关论文+源码合集,一共200+篇。感兴趣的dd!
原文、姿 料,这儿~
一、论文基本信息

基本信息
- 论文标题: C²Prompt: Class-aware Client Knowledge Interaction for Federated Continual Learning
- 作者:Kunlun Xu, Yibo Feng, Jiangmeng Li, Yongsheng Qi, Jiahuan Zhou
- 作者单位:Peking University, University of Chinese Academy of Sciences, Inner Mongolia University of Technology
- 代码链接:https://github.com/zhoujiahuan1991/NeurIPS2025-C2Prompt
- 论文链接:https://arxiv.org/abs/2509.19674
摘要精炼
本文旨在解决 FCL 场景下,现有基于提示学习的方法因忽略客户端间“类感知知识一致性”而加剧时空遗忘的问题。具体挑战源于两个方面:客户端间的“类内分布差异”导致语义不一致,以及提示间的“跨类知识混淆”在聚合时引发冲突。
为解决此问题,本文提出了 C²Prompt 方法,其核心技术贡献在于设计了两个协同工作的模块:1) 局部类分布补偿 (LCDC) 机制,通过估计全局类分布并补偿本地数据,加强了类内知识的一致性;2) 类感知提示聚合 (CPA) 方案,通过计算提示与类的关联度,动态加权聚合过程,以增强相关知识并抑制冲突。实验结果表明,该方法在多个 FCL 基准测试中均达到了业界领先水平,证明了显式建模类感知知识交互的有效性。
二、研究背景与相关工作
研究背景
随着边缘计算和物联网设备的普及,在保护数据隐私的前提下,让分布式设备持续从数据流中学习变得至关重要。联邦持续学习(FCL)正是在此背景下应运而生。然而,FCL 面临着双重挑战:模型不仅要克服在连续任务中发生的灾难性遗忘(catastrophic forgetting)(时间维度),还必须适应不同客户端之间非独立同分布(non-IID)的数据(空间维度)。传统的持续学习或联邦学习方法单独应用时,难以有效解决这种叠加的遗忘问题。
近期,基于提示学习的方法因其高效性成为 FCL 的一个热门方向,但它们在客户端知识交互(即提示聚合)过程中的有效性和精确性仍有待提升,尤其是在处理类相关的知识冲突方面存在明显瓶颈。
相关工作
当前 FCL 领域的主流方法可分为数据合成、参数正则化和高效微调三类。数据合成方法存在隐私泄露风险;参数正则化方法则常因过于保守而牺牲新知识的学习能力。高效微调方法,特别是基于提示学习的方法(如 Fed-L2P, Fed-CODA, Powder),通过冻结预训练模型主干、仅微调少量提示参数来平衡新旧知识,展现了巨大潜力。
这些方法通过在客户端之间传递和聚合任务相关的提示来共享知识。然而,现有工作大多采用简单的平均或相似度聚合策略,未能充分考虑不同客户端学习到的提示在类别语义上的差异性和关联性。这种“无差别”的聚合方式容易导致知识冲突,即不相关的知识被错误融合,相关知识被稀释,最终损害了全局模型的性能并加剧遗忘。本文正是针对这一局限性,提出更精细化的类感知交互机制。
三、主要贡献与创新
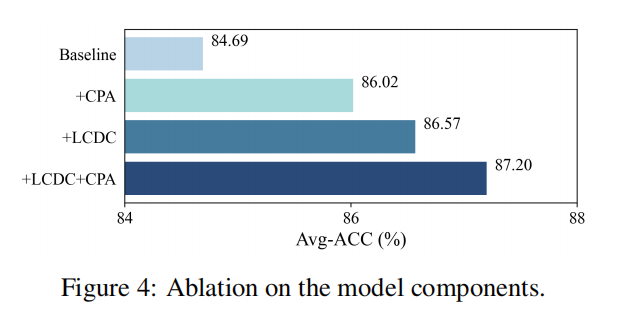
- 提出 C²Prompt 框架:设计了一个无需样本回放的 FCL 方法,通过创新的“类感知客户端知识交互”机制,同时缓解时间和空间遗忘。
- 局部类分布补偿 (LCDC):开发了一种新颖的补偿机制,通过建模并对齐全局与局部类分布,有效提升了跨客户端的类内语义一致性。
- 类感知提示聚合 (CPA):提出了一种基于类知识关联性评估的提示聚合方案,能够动态加权聚合过程,从而增强类内知识的整合,并有效缓解知识冲突。
- SOTA 性能验证:在多个具有挑战性的 FCL 基准测试上进行了大量实验,证明了 C²Prompt 方法相较于现有最先进方法的显著优越性。
四、研究方法与原理
总体框架与核心思想
C²Prompt 的核心思想是在 FCL 的提示通信过程中,显式地建模并利用类级别的知识,以实现更精准、冲突更少的知识聚合。其总体框架(如下图所示)包含两个阶段的交互:数据分布层面的补偿和模型参数(提示)层面的聚合。
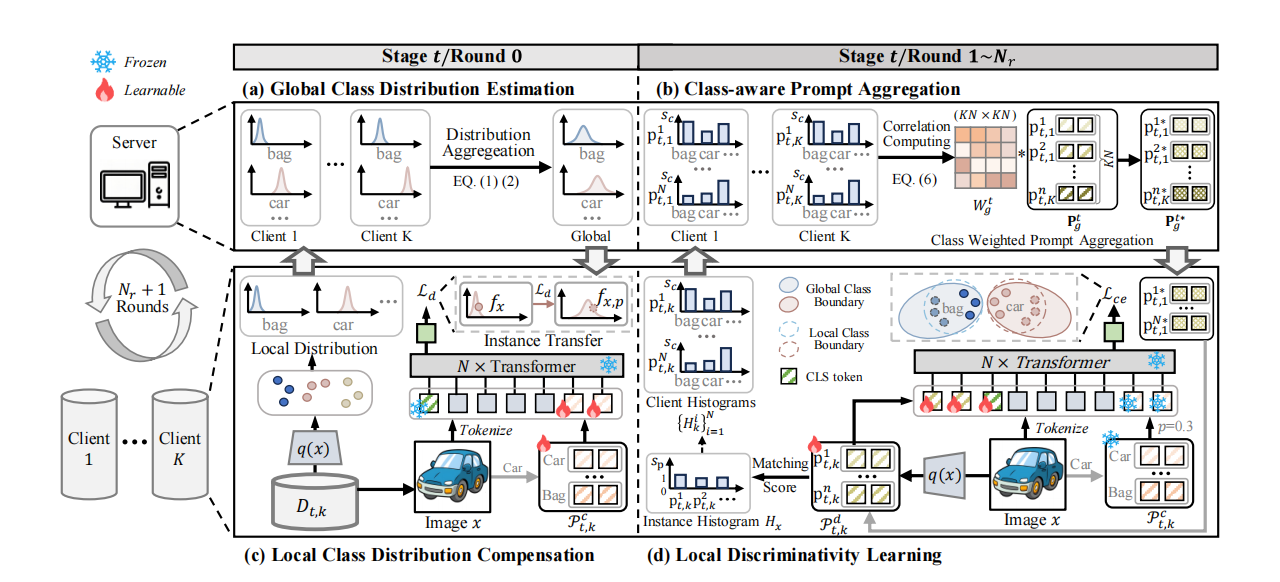
- 全局分布估计与局部补偿:在学习新任务的初始阶段,各客户端首先统计本地数据的类分布信息(均值和方差)并上传至服务器。服务器聚合这些信息,估计出每类的全局分布,再将其分发回客户端。客户端利用这个全局分布来训练一组“类分布补偿提示”,其目标是将本地特征“迁移”到全局语义空间,从而在源头上对齐知识。
- 类感知判别性学习与聚合:在后续的多轮通信中,客户端在学习“判别性提示”的同时,会记录每个提示与各个类别的匹配分数(亲和度)。当需要聚合时,客户端将判别性提示和它们的类亲和度直方图上传。服务器利用这些亲和度信息计算提示间的“类知识相关性”,并以此为权重进行加权聚合。这种方式确保了语义相似的提示被有效融合,而语义冲突的提示则被抑制。
关键实现与评估原理
关键实现细节
- 全局分布聚合:服务器通过以下公式聚合来自所有 K 个客户端的局部类分布(均值
μ和标准差σ)来估计全局分布:
μig=∑k=1Kμi,ktpk,it\mu_i^g = \sum_{k=1}^{K} \mu_{i,k}^t p_{k,i}^t μig=k=1∑Kμi,ktpk,it
(σig)2=∑k=1K((μi,kt)2+(σi,kt)2)pk,it−(μig)2(\sigma_i^g)^2 = \sum_{k=1}^{K} \left( (\mu_{i,k}^t)^2 + (\sigma_{i,k}^t)^2 \right) p_{k,i}^t - (\mu_i^g)^2 (σig)2=k=1∑K((μi,kt)2+(σi,kt)2)pk,it−(μig)2
其中p代表样本比例。 - 分布补偿损失:客户端通过最小化一个分布交叉熵损失来训练补偿提示,使得经过补偿提示调整后的特征
f_x,p能够匹配全局高斯分布N(μ_i^g, (σ_i^g)^2):
Lc=−12(fx,p−μig)⊤(Σig)−1(fx,p−μig)\mathcal{L}_c = -\frac{1}{2} (f_{x,p} - \mu_i^g)^\top (\Sigma_i^g)^{-1} (f_{x,p} - \mu_i^g) Lc=−21(fx,p−μig)⊤(Σig)−1(fx,p−μig) - 类感知聚合权重:服务器收集所有客户端的提示-类亲和度直方图
H_g^t,并计算一个提示间的相关性矩阵W_g^t用于加权聚合:
Wgt=γ(Hgt(Hgt)⊤/τ)W_g^t = \gamma(\mathcal{H}_g^t (\mathcal{H}_g^t)^\top / \tau) Wgt=γ(Hgt(Hgt)⊤/τ)
最终更新的提示为P_g^{t*} = W_g^t P_g^t。 - 关键超参:补偿提示的使用概率
p设为0.5,补偿提示长度L_c设为3,判别性提示数量N为8,长度L_p为10。
核心评估原理与指标
为了全面评估模型在 FCL 场景下的性能,本文采用了多个指标:
- 平均准确率 (Avg):衡量模型在所有已见任务上的最终平均性能。
- 平均增量准确率 (AIA):衡量模型在整个学习过程中的平均性能。
- 遗忘度量 (FM):量化模型对旧任务知识的遗忘程度,值越低越好。
- 前向迁移 (FT) 与 后向迁移 (BT):分别衡量旧知识对新任务的促进作用和新知识对旧任务的巩固作用。
五、实验结果与分析
实验设置
- 数据集: ImageNet-R, DomainNet, CIFAR-100。
- 评估指标: Avg, AIA, FM, FT, BT, CT。
- 对比基线: 包括基于全模型微调的 FCL 方法 (如 GLFC, Fedspace) 和基于高效微调的方法 (如 Fed-L2P, Fed-CODA, Powder, PILoRA)。
- 关键超参: 客户端数量
K=5,每任务通信轮数N_r=3,优化器为 Adam,学习率为0.01。
核心实验与结论
【指令】: 仅选择一项最能体现本文贡献的核心实验进行阐述。
-
实验目的: 该实验旨在验证 C²Prompt 方法相较于现有最先进(SOTA)方法的综合性能,特别是在长期知识积累(Avg)和持续学习能力(AIA)方面的优势。
-
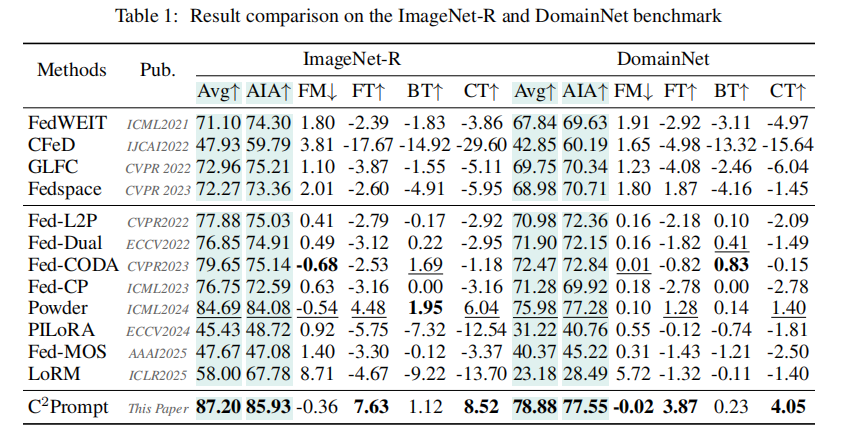
关键结果: 如下表所示,在 ImageNet-R 和 DomainNet 这两个大规模、高挑战性的基准上,C²Prompt 在所有关键指标上均显著优于现有方法。
- 在 ImageNet-R 上,C²Prompt 的 Avg 准确率达到 87.20%,比次优的 Powder 方法高出 2.51%。
- 在 DomainNet 上,C²Prompt 的 Avg 准确率为 78.88%,比 Powder 高出 2.90%。
- 在遗忘度量(FM)上,C²Prompt 在两个数据集上均表现出负遗忘,说明学习新任务甚至增强了旧任务的性能。
- 在知识迁移(FT, CT)方面,C²Prompt 同样取得了最佳表现。
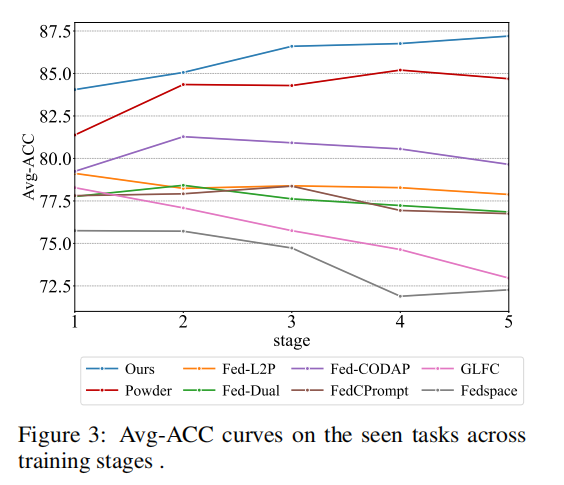
- 作者结论: 实验结果有力地证明了 C²Prompt 的优越性。Avg 和 AIA 指标的显著提升表明,通过类感知知识交互,模型能够更有效地整合来自不同客户端的知识,同时最大程度地减少知识冲突,从而实现更强大的长期知识积累能力。负遗忘的现象进一步验证了该方法在缓解灾难性遗忘方面的有效性。下图的性能趋势分析也显示,C²Prompt 的准确率在整个学习过程中稳定上升,而其他方法则出现波动或下降,这直观地展示了其鲁棒性。

六、论文结论与启示
总结
本文精准地指出了当前基于提示的联邦持续学习方法中的一个核心缺陷:即在客户端知识交互过程中忽略了“类感知知识一致性”,导致聚合效率低下和严重的知识冲突。
为解决此问题,本文提出了 C²Prompt 方法,通过创新的 局部类分布补偿 (LCDC) 和 类感知提示聚合 (CPA) 两个模块,分别从数据分布和模型参数两个层面实现了类感知的知识对齐与增强。LCDC 保证了不同客户端学习的知识具有一致的语义基础,而 CPA 则确保了在聚合过程中能够“取其精华、去其糟粕”。实验证明,这种精细化的交互机制能够显著提升模型的性能,在多个基准上刷新了记录,为解决 FCL 中的时空遗忘问题提供了新的有效途径。
展望
尽管 C²Prompt 取得了显著成功,但论文也指出了其局限性与未来可行的研究方向:
- 通信开销: 虽然新增的分布信息通信开销很小,但在超大规模客户端场景下仍有优化空间。未来可以研究更高效的分布信息压缩或表示方法。
- 计算与存储: 类感知聚合为每个客户端生成了特定的提示,略微增加了计算和存储负担。未来的工作可以探索如何在保持个性化的同时,实现更高效的提示管理和融合机制。
- 更复杂的场景: 可以将该方法的思想扩展到其他联邦学习场景,如联邦半监督学习或联邦无监督学习,在这些场景下,如何定义和利用“类”知识将是一个更有趣的挑战。