为 CPU 减负:数据中心网络卸载技术的演进
上一篇文章我们梳理了当前数据中心网络的核心矛盾:Scale-Out 架构的胜利将性能压力转移至网络,而传统数据中心网络中,TCP/IP 协议栈处理、数据拷贝、远程 CPU 参与通信这三大环节,正持续 “吞噬” 本应用于计算的 CPU 资源。当 AI 训练、云计算等业务对 “CPU 算力纯度” 的需求越来越高时,“为 CPU 减负” 成为本阶段技术演进的核心目标 —— 从软件层面的协议栈优化,到硬件层面的功能卸载,一系列尝试虽显著提升了网络性能,却始终未能撼动 “数据拷贝” 与 “远程 CPU 参与” 的根本性瓶颈。
一、软件卸载:DPDK 的 “内核绕开” 策略 —— 用 CPU 效率换性能
在硬件卸载技术成熟前,行业首先尝试从 “软件层面优化协议栈处理效率”,DPDK(Data Plane Development Kit,数据平面开发工具包)便是这一阶段的核心成果。它的本质不是 “卸载”,而是 “重构”—— 通过绕开 Linux 内核协议栈的冗余环节,让 CPU 以更高效率处理网络数据包,间接为计算任务 “腾出” 资源。
传统网络数据处理需经过 “网卡→内核协议栈→用户态应用” 的路径,其中内核的 “被动中断触发→系统调用调度→多次内存拷贝→冗余协议校验” 等环节存在大量上下文切换与资源浪费,一台 8 核服务器处理 10Gbps 流量时,协议栈可能占用 60% 以上 CPU,直接挤压计算任务的资源空间。DPDK 通过三个关键设计重构了这一数据路径:它借助用户态驱动直接在应用层实现网卡操控逻辑,跳过内核态与用户态的上下文切换(单次切换耗时约 1-2 微秒,高频通信场景下累积延迟显著);采用 2MB/1GB 大页内存分配数据缓存区,减少 CPU 内存管理单元(MMU)的 TLB(转译后备缓冲器)缺失率,大幅降低内存访问延迟;同时用 “主动轮询模式(Poll-Mode Driver,PMD)” 替代内核的 “被动中断机制”,避免频繁中断导致的 CPU 上下文切换(中断处理单次耗时约 10 微秒,高流量下每秒中断次数可达数十万次),让 CPU 能专注于数据包处理而非中断响应。
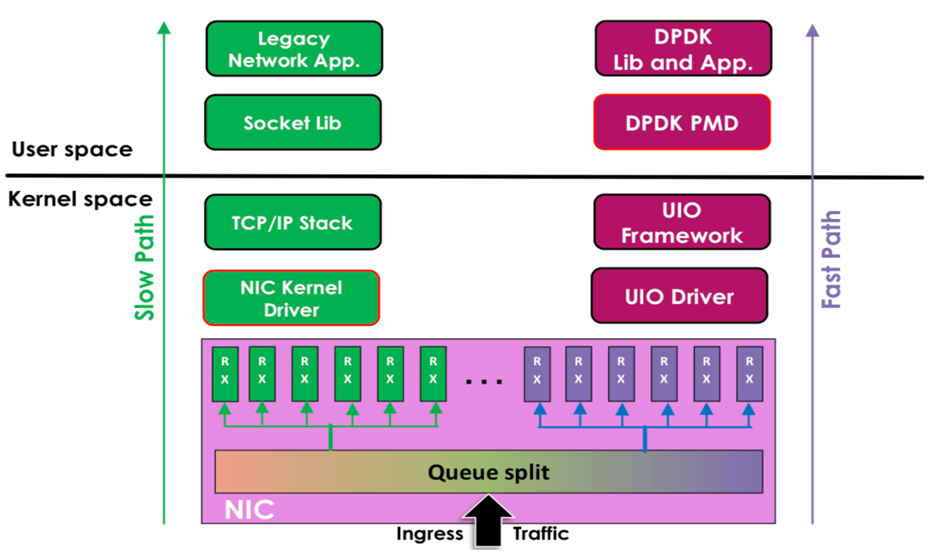
- Slow Path(慢路径,左侧绿色部分):传统网络数据处理路径,数据需经过内核态的网卡内核驱动、TCP/IP 协议栈,再到用户态的套接字库,最终给传统网络应用,过程中内核态处理开销大,速度慢。
- Fast Path(快路径,右侧紫色部分):基于 DPDK 的高速数据处理路径,利用 UIO 框架、UIO 驱动,结合 DPDK轮询模式驱动和DPDK 库及应用,绕过传统内核态的部分复杂处理,直接在用户态高效处理网络数据,大幅提升数据平面的处理性能。
通过上述优化,DPDK 可将单核心数据包处理能力从内核协议栈的 10 万 PPS(数据包每秒)提升至 100 万 PPS 以上,10Gbps 网卡的 CPU 占用率从 60% 降至 20% 以下,成功为 CPU “释放” 了大量计算资源,支撑了 SDN(软件定义网络)、NFV(网络功能虚拟化)等场景的早期落地 —— 例如在 OpenStack 云平台中,基于 DPDK 的虚拟交换机可将虚拟机间通信延迟降低 40%,同时减少 50% 的 CPU 占用。
但 DPDK 的本质是 “软件层面的效率优化”,而非 “硬件层面的负担转移”:它依然依赖 CPU 处理数据包,只是减少了冗余开销,当流量达到 25Gbps 以上,或通信频率极高(如 AI 训练的跨卡参数传输),CPU 仍会被数据包处理 “拉满”;更关键的是,它未能解决两个核心问题 —— 数据包仍需从网卡缓冲区(DMA 区域)拷贝到用户态应用内存,虽通过零拷贝技术可减少一次拷贝,但跨节点通信时的远程数据拷贝无法避免;跨节点通信时,即使本地 CPU 通过 DPDK 高效处理了协议栈,远程节点的 CPU 仍需参与连接建立、流量控制等环节,无法绕开。这意味着,DPDK 只是 “缓解” 了 CPU 负担,并未从根本上 “消除” 网络对 CPU 的依赖,当业务对延迟与 CPU 纯度的要求进一步提升,软件优化的天花板便清晰显现。
二、硬件卸载第一阶段:TOE 与 RSS—— 把 “协议栈” 搬进网卡
当软件优化触及天花板,行业开始转向 “硬件卸载”:将原本由 CPU 处理的协议栈任务,转移到网卡内置的专用硬件引擎中,实现 “CPU 彻底不参与协议处理”。这一阶段的核心技术是 TOE(TCP Offload Engine,TCP 卸载引擎)与 RSS(Receive Side Scaling,接收端缩放),标志着 “协议处理” 正式从 CPU 剥离,开启了硬件减负的序幕。
TOE 的核心思路是在网卡硬件中集成 TCP 协议处理引擎,将 TCP 的 “连接管理、三次握手、流量控制、重传机制” 等核心逻辑全部交由硬件完成 —— 传统场景下,CPU 处理一个 TCP 数据包需完成 “解析 IP 头→解析 TCP 头→校验和验证→流量控制判断→数据提取”5 个步骤,耗时约 5-10 微秒,且全程占用 CPU 资源;而 TOE 通过硬件电路并行处理这些步骤,耗时可压缩至 1 微秒以内,处理完成后直接通过 DMA 方式将 “干净数据”(无需再解析协议头)放入主机内存,供应用程序直接访问。早期 TOE 主要支持 TCP 协议(部分支持 UDP),广泛应用于存储网络(如 iSCSI)、数据库集群等场景,以 Oracle RAC 集群为例,采用 TOE 网卡后,跨节点数据库同步的 CPU 占用率降低 40%,延迟减少 30%,有效提升了数据库的事务处理能力。
但 TOE 的单核心适配能力存在局限:当网卡带宽提升至 25Gbps 以上,单块 TOE 网卡的数据包处理能力可能超过单核心 CPU 的数据接收能力 ——25Gbps 网卡每秒可传输约 1400 万 PPS,而单核心 CPU 每秒最多处理 1200 万 PPS,若数据集中涌向单个 CPU 核心,仍会形成性能瓶颈。RSS 技术正是为解决这一问题而生:它通过 “哈希算法”(基于 IP 地址、端口号等关键字段)对网卡接收的数据包进行分类,将不同流的数据包均匀分发到 CPU 的多个核心,实现 “多核心并行接收数据”,避免单核心过载。例如,4 核 CPU 配合 RSS,可将 25Gbps 网卡的 PPS 处理能力提升至 4000 万以上,完美匹配 TOE 的硬件处理能力,让硬件卸载的性能潜力充分释放。
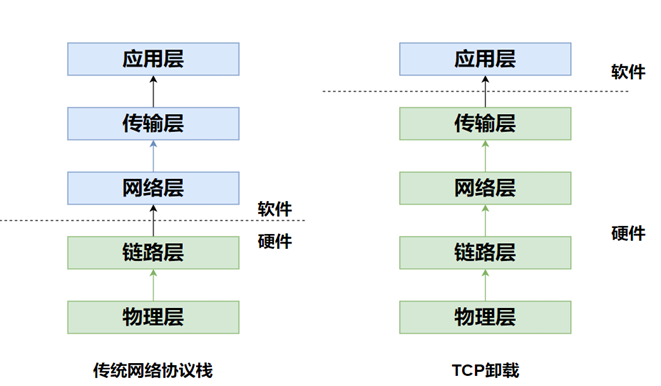
尽管 TOE 与 RSS 的组合成功将 “协议栈处理” 的负担从 CPU 转移到网卡硬件,支撑了 40Gbps/100Gbps 网卡的大规模应用,但这一阶段的硬件卸载仍存在明显局限:
- 早期 TOE 仅支持 TCP/UDP 的核心协议,对 TLS(加密解密)、VXLAN(虚拟化隧道)等复杂协议仍需 CPU 处理,无法覆盖云环境中的多样化网络需求;
- 数据拷贝问题未被消除 ——TOE 虽处理了协议栈,但数据包仍需从网卡缓冲区(DMA 区域)拷贝到主机内存(CPU 可直接访问的内存),这一过程(DMA 拷贝)虽不占用 CPU,但仍存在 2-5 微秒的延迟,跨节点通信时需经过 “本地网卡→本地内存→远程内存→远程网卡” 四次拷贝,延迟累积效应显著;
- 远程 CPU 的参与也无法彻底绕开 ——TOE 仅负责本地协议处理,跨节点通信时,远程节点的 CPU 仍需参与 “连接建立确认”“数据接收确认” 等环节,例如本地 TOE 完成 TCP 三次握手的前两步,远程节点的 CPU 仍需处理第三步确认,无法实现 “无 CPU 干预” 的端到端通信。
- TOE 需要操作系统内核、应用程序与网卡驱动深度协同修改,破坏了网络的透明性,且硬件协议栈难以快速跟进 Linux 内核中 TCP 协议的迭代(如 BBR 等新型拥塞控制算法),同时将复杂协议处理移至网卡也扩大了受攻击面。
这些问题导致 TOE 未能成为通用场景的主流方案,却为后续硬件卸载的升级积累了关键经验。TOE是一次激进但略超前于时代的尝试。它的经验表明,“全量卸载” 一条复杂的、不断演进的协议栈是极其困难的,这也是TOE没能成为主流的原因。
三、硬件卸载第二阶段:智能网卡与 DPU—— 从 “协议卸载” 到 “功能集成”
随着云计算、AI 的发展,网络不仅需要处理基础协议,还需承担 “安全加密(TLS/IPsec)”“虚拟化隧道(VXLAN/GRE)”“存储卸载(NVMe over Fabrics)” 等复杂任务,第一阶段的 TOE 已无法满足需求,硬件卸载进入第二阶段:以 “智能网卡(Smart NIC)” 和 “数据处理单元(DPU)” 为核心,实现 “协议卸载 + 多功能集成”,进一步减少 CPU 参与,甚至让 CPU 脱离网络任务的处理链路。

智能网卡在 TOE 的基础上,集成了更多专用硬件引擎,可卸载的任务从 “TCP 协议处理” 大幅扩展:它内置 TLS/IPsec 加密解密引擎,能替代 CPU 处理 HTTPS 流量的加密计算;针对云环境的虚拟化需求,智能网卡集成 VXLAN/GRE 隧道封装 / 解封装引擎,替代 CPU 处理虚拟机流量转发;在存储领域,它支持 NVMe over Fabrics 协议,可直接将存储设备的数据流传输到主机内存,无需 CPU 参与存储 IO 处理,大幅提升分布式存储的性能。
DPU 则是智能网卡的进一步演进,它不再局限于 “专用硬件引擎 + 简单控制逻辑” 的架构,而是集成了独立的处理器(如 ARM 多核 CPU)和内存,可运行完整的操作系统(如 Linux),具备 “独立处理网络任务” 的能力,相当于在网卡中嵌入了一台 “小型服务器”。DPU 的核心优势是 “端到端任务卸载”:除了智能网卡的协议、安全、虚拟化卸载功能,它还能处理 “负载均衡”“流量调度”“数据压缩”“日志采集” 等复杂任务,甚至可运行轻量级的虚拟化管理软件(如 KVM)—— 例如 NVIDIA 的 BlueField DPU,可直接在硬件中运行 Kubernetes 网络插件(Calico),实现 “虚拟机 / 容器流量的全硬件转发”,CPU 完全不参与网络管理;在 AI 训练集群中,DPU 可独立完成跨节点的参数同步调度,无需 CPU 介入数据分发,进一步降低通信延迟。更关键的是,DPU 支持 “内存直接交互” 的初步探索,通过 PCIe 共享内存技术,可将数据拷贝路径从 “网卡→主机内存” 简化为 “DPU 内存→主机内存”,减少一次数据拷贝,在部分场景下将延迟再降低 1-2 微秒。
- 智能网卡是核心载体:数据平面卸载的理念,其物理实现就是智能网卡。它不再是简单的连接设备,而是一个集成了多核CPU、高性能网络接口及各类专用加速引擎的计算平台。
- DPU是智能网卡的更高级形态:当智能网卡的功能强大到可以独立运行一个轻量级操作系统,并完全接管主机的基础设施任务时,它就被称为DPU(数据处理单元) 或 IPU(基础设施处理单元),可以理解为 “服务器中的服务器”。
但即便智能网卡与 DPU 将硬件卸载的能力提升到新高度,本阶段的技术仍未解决两个根本性问题:数据拷贝依然存在 —— 无论是智能网卡还是 DPU,数据包仍需在 “网卡 / DPU 缓冲区” 与 “主机内存” 之间进行拷贝,即使通过 PCIe Gen5 的 DMA 拷贝,延迟仍需 1-2 微秒,跨节点通信时的四次拷贝(本地网卡→本地内存→远程内存→远程网卡)会让延迟累积至 10 微秒以上,无法满足 AI 训练(需微秒级延迟)、高频交易(需纳秒级延迟)的极致需求;远程 CPU 的 “隐性参与” 也未消除 —— 即使本地 DPU 能独立处理网络任务,远程节点的 CPU 仍需在 “连接初始化”“异常处理”(如数据包丢失重传的确认)等场景下参与通信,例如 AI 训练中,本地 DPU 将参数发送到远程节点,远程 CPU 仍需触发 “参数接收完成” 的信号,无法实现 “完全无 CPU 干预” 的通信,网络仍未成为 “独立于 CPU 的自主通信通道”。
四、总结:减负的收获与未破的瓶颈
本阶段围绕 “为 CPU 减负” 的技术探索,从软件卸载(DPDK)到硬件卸载两阶段(TOE→智能网卡 / DPU),在 CPU 资源释放与网络性能提升上取得了显著成果,也清晰暴露了未解决的核心瓶颈。
在已实现的收获层面,CPU 终于 “重获自由”—— 从 DPDK 的 “减少 CPU 占用” 到 DPU 的 “彻底不占用 CPU”,网络任务对 CPU 的消耗从 60% 以上降至 5% 以下,CPU 得以专注于计算任务,支撑了云计算的大规模虚拟化、AI 的千亿参数训等场景;网络性能实现跃升,吞吐量从 10Gbps 提升至 400Gbps,延迟从毫秒级降至微秒级,满足了绝大多数互联网服务、企业级应用的需求;硬件功能走向集成化,从 “仅处理协议” 的 TOE,升级为 “处理协议 + 安全 + 虚拟化 + 存储” 的智能网卡 / DPU,网络设备成为 “多功能平台”,减少了数据中心的硬件部署种类(无需单独部署防火墙、负载均衡器、存储控制器),降低了整体复杂度与成本。
但未突破的瓶颈同样关键:数据拷贝的 “物理壁垒” 仍未打破 —— 只要数据需要在 “网卡 / DPU” 与 “主机内存” 之间传输,拷贝延迟就无法消除,跨节点通信时的多次拷贝更是将延迟放大,成为微秒级延迟场景(如 AI 训练、HPC)的 “最后一道枷锁”;远程 CPU 的 “隐性依赖” 也未解除 —— 现有卸载技术仅能处理 “数据传输阶段” 的任务,而 “连接建立”“异常处理” 等控制面任务仍需远程 CPU 参与,无法实现 “端到端的无 CPU 通信”。这些问题注定了本阶段的技术只是 “过渡性方案”:它缓解了眼前的 CPU 负担,却未能从根本上重构数据中心的通信范式 —— 通信仍需依赖 “数据拷贝” 与 “CPU 参与”,无法实现 “直接、高效、无干预” 的节点间交互。
要突破这些瓶颈,需要一场更彻底的技术革命:绕开数据拷贝与远程 CPU,实现 “内存到内存” 的直接通信。这也正是下一篇文章将要探讨的核心 ——RDMA(远程直接内存访问)技术如何打破 “数据拷贝” 的壁垒,开启数据中心网络的 “无 CPU 通信” 时代,让节点间的交互真正摆脱对拷贝与 CPU 的依赖,迈向更高效率的通信范式。