MinerU2.5:一种用于高效高分辨率文档解析的解耦视觉-语言模型

介绍
MinerU2.5 是一个具有 12 亿参数的视觉-语言模型,用于文档解析,它在保持高计算效率的同时实现了最先进的准确性。它采用两阶段解析策略:首先对下采样的图像进行高效的全局布局分析,然后对文本、公式和表格的原分辨率裁剪部分进行细粒度的内容识别。通过大规模、多样化的数据引擎支持预训练和微调,MinerU2.5 在多个基准测试中始终优于通用模型和特定领域模型,同时保持较低的计算开销。
主要改进
- 全面且细致的布局分析: 不仅保留了页眉、页脚和页码等非主体元素以确保内容完整性,还采用了更精细和标准化的标注方案。这使得列表、引用和其他元素的表示更加清晰和结构化。
- 公式解析的突破: 高质量地解析复杂的长数学公式,并准确识别混合语言(中文-英文)的方程。
- 增强的表格解析鲁棒性: 轻松处理包括旋转表格、无边框表格和部分边框表格在内的挑战性情况。
快速开始
为了方便起见,我们提供了 mineru-vl-utils,这是一个 Python 包,简化了向 MinerU2.5 视觉-语言模型发送请求和处理响应的过程。这里给出一些使用 MinerU2.5 的示例。更多信息和用法,请参阅 mineru-vl-utils。
📌 我们强烈建议使用 vllm 进行推理,因为 vllm-async-engine 可以在单个 A100 上实现 2.12 fps 的并发推理速度。
安装包
# For `transformers` backend
pip install "mineru-vl-utils[transformers]"
# For `vllm-engine` and `vllm-async-engine` backend
pip install "mineru-vl-utils[vllm]"
transformers 示例
from modelscope import AutoProcessor, Qwen2VLForConditionalGeneration
from PIL import Image
from mineru_vl_utils import MinerUClient# for transformers>=4.56.0
model = Qwen2VLForConditionalGeneration.from_pretrained("OpenDataLab/MinerU2.5-2509-1.2B",dtype="auto", # use `torch_dtype` instead of `dtype` for transformers<4.56.0device_map="auto"
)processor = AutoProcessor.from_pretrained("OpenDataLab/MinerU2.5-2509-1.2B",use_fast=True
)client = MinerUClient(backend="transformers",model=model,processor=processor
)image = Image.open("/path/to/the/test/image.png")
extracted_blocks = client.two_step_extract(image)
print(extracted_blocks)
vllm-engine 示例(推荐!)
from vllm import LLM
from PIL import Image
from mineru_vl_utils import MinerUClient
from mineru_vl_utils import MinerULogitsProcessor # if vllm>=0.10.1llm = LLM(model="OpenDataLab/MinerU2.5-2509-1.2B",logits_processors=[MinerULogitsProcessor] # if vllm>=0.10.1
)client = MinerUClient(backend="vllm-engine",vllm_llm=llm
)image = Image.open("/path/to/the/test/image.png")
extracted_blocks = client.two_step_extract(image)
print(extracted_blocks)
vllm-async-engine 示例(推荐!)
import io
import asyncio
import aiofilesfrom vllm.v1.engine.async_llm import AsyncLLM
from vllm.engine.arg_utils import AsyncEngineArgs
from PIL import Image
from mineru_vl_utils import MinerUClient
from mineru_vl_utils import MinerULogitsProcessor # if vllm>=0.10.1async_llm = AsyncLLM.from_engine_args(AsyncEngineArgs(model="OpenDataLab/MinerU2.5-2509-1.2B",logits_processors=[MinerULogitsProcessor] # if vllm>=0.10.1)
)client = MinerUClient(backend="vllm-async-engine",vllm_async_llm=async_llm,
)async def main():image_path = "/path/to/the/test/image.png"async with aiofiles.open(image_path, "rb") as f:image_data = await f.read()image = Image.open(io.BytesIO(image_data))extracted_blocks = await client.aio_two_step_extract(image)print(extracted_blocks)asyncio.run(main())async_llm.shutdown()
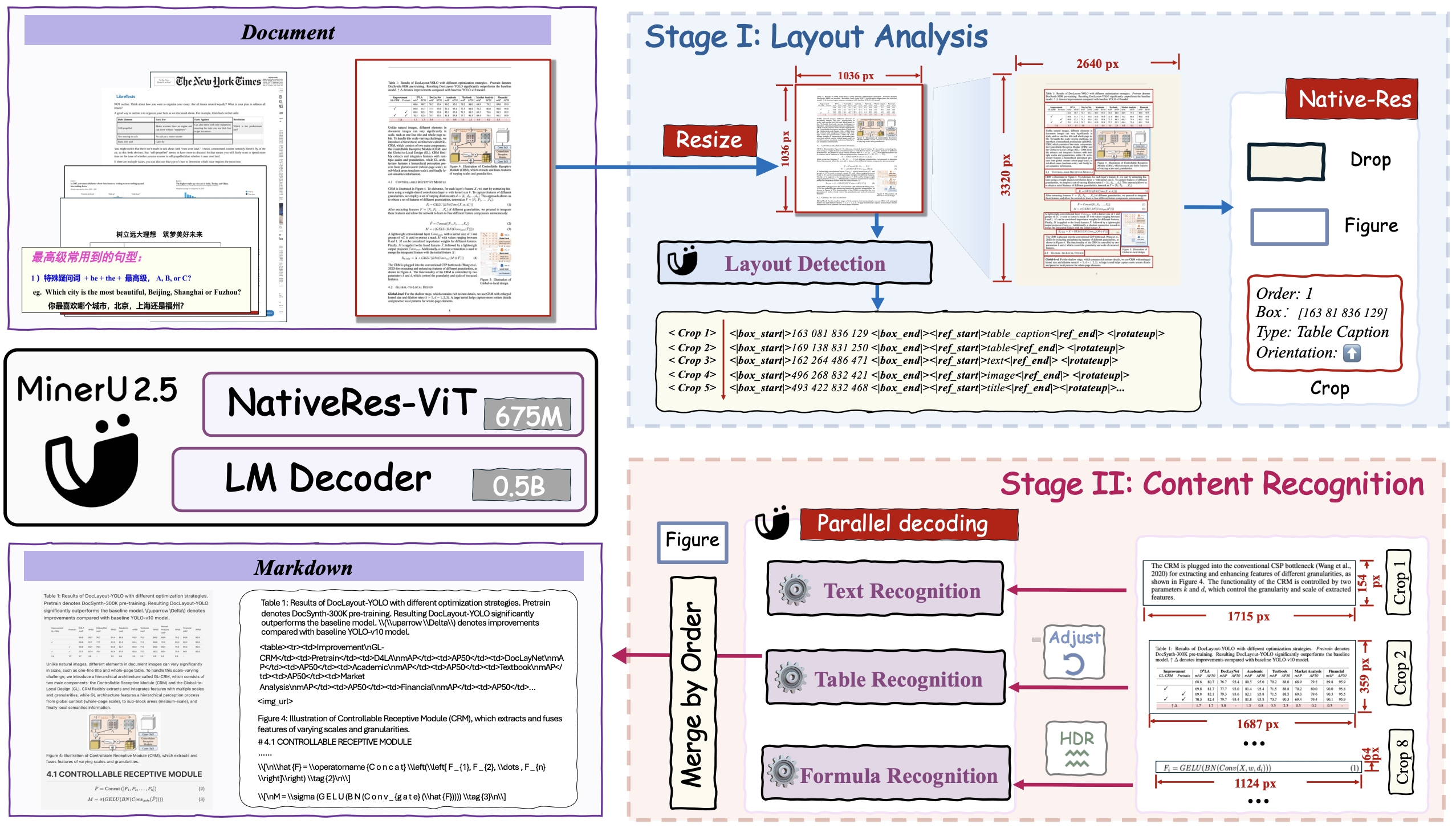
模型架构
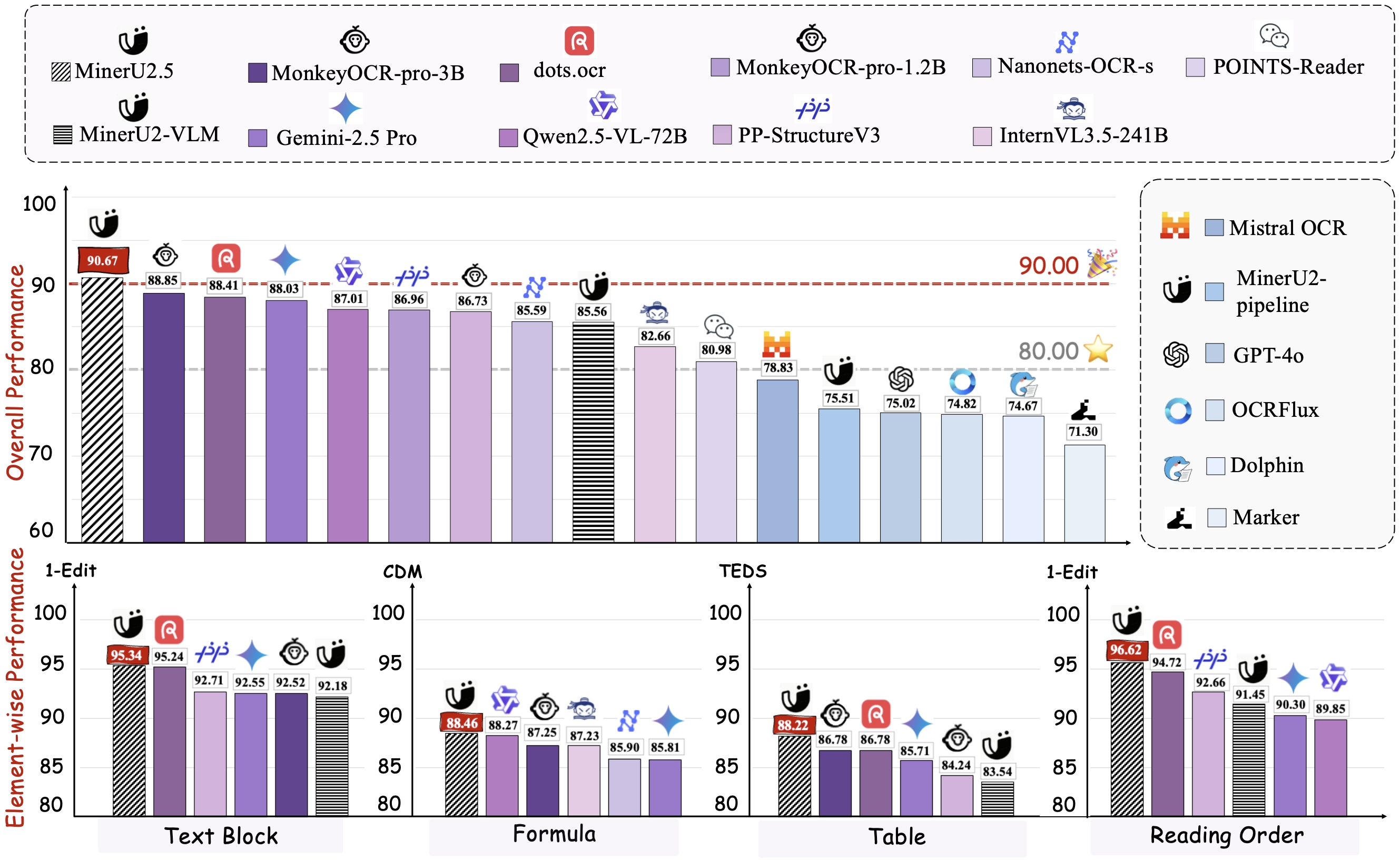
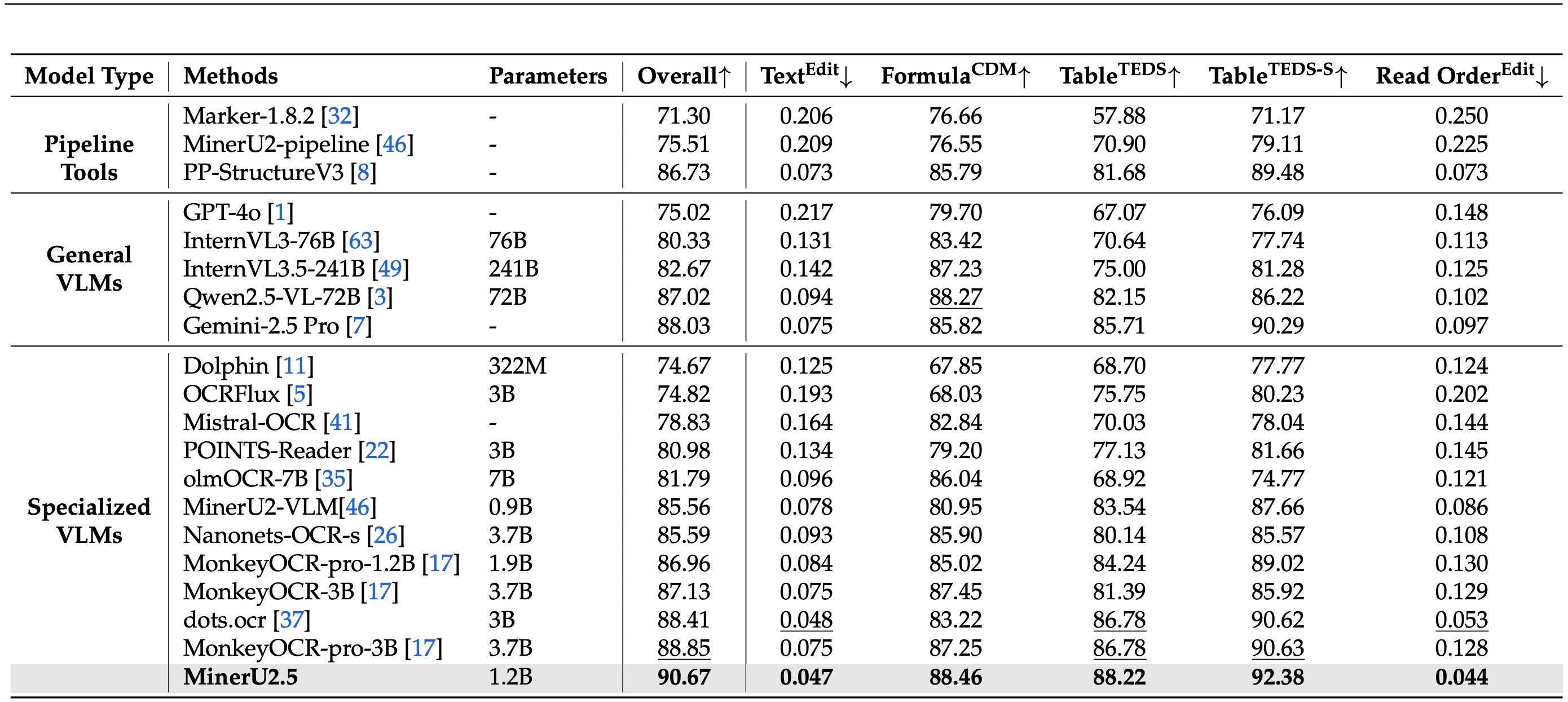
在 OmniDocBench 上的表现
不同元素上的表现
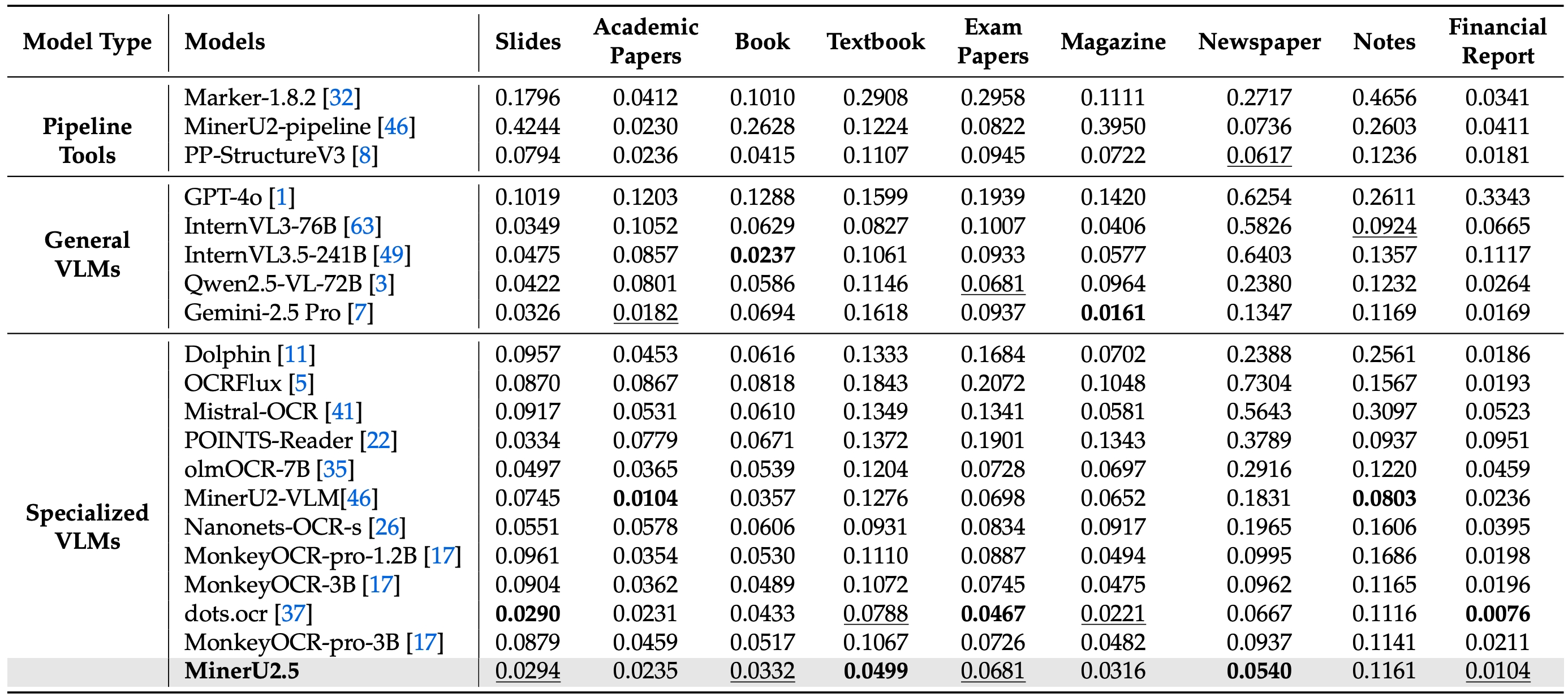
不同文档类型上的表现
案例演示
各种文档类型的全文档解析



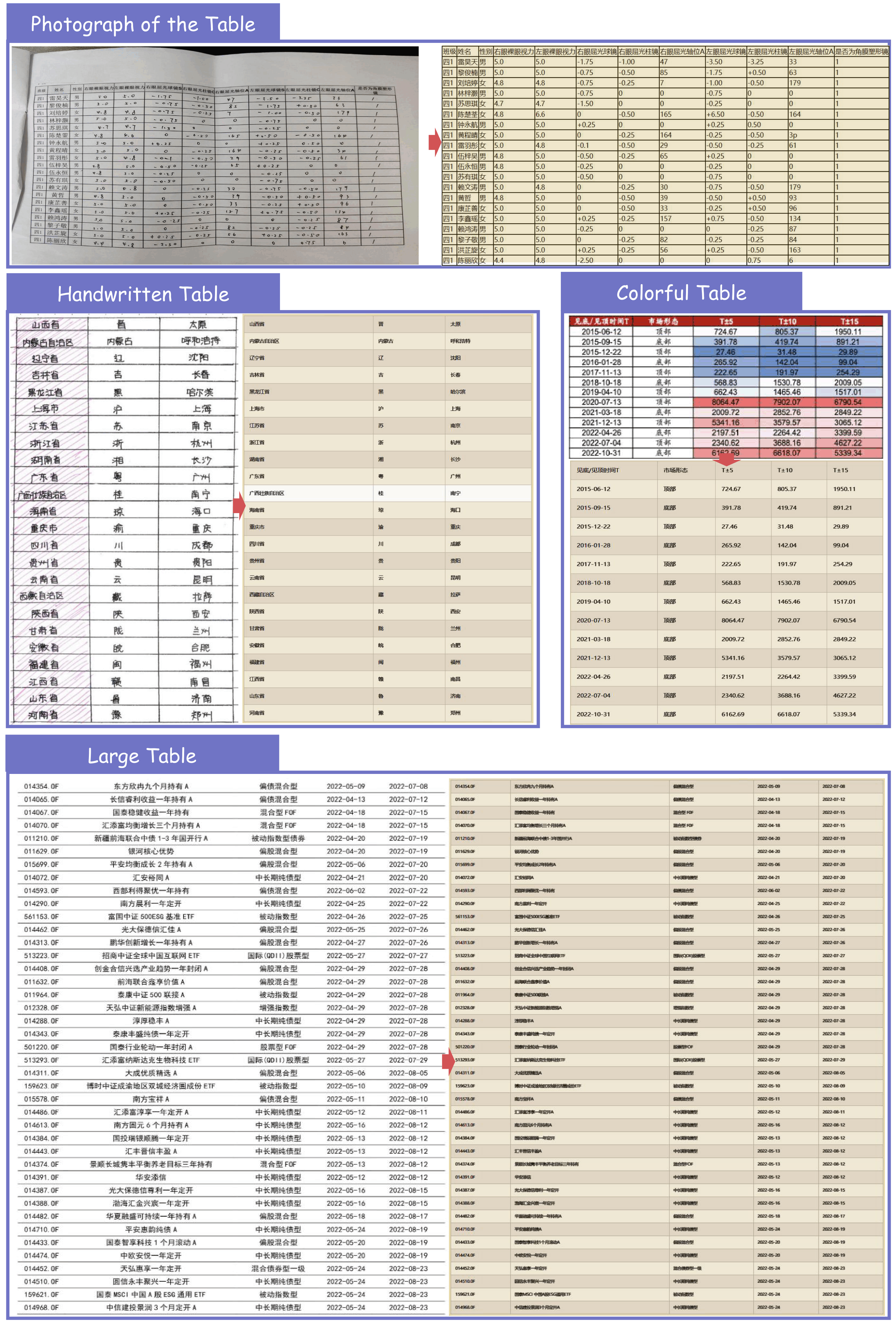
表格识别
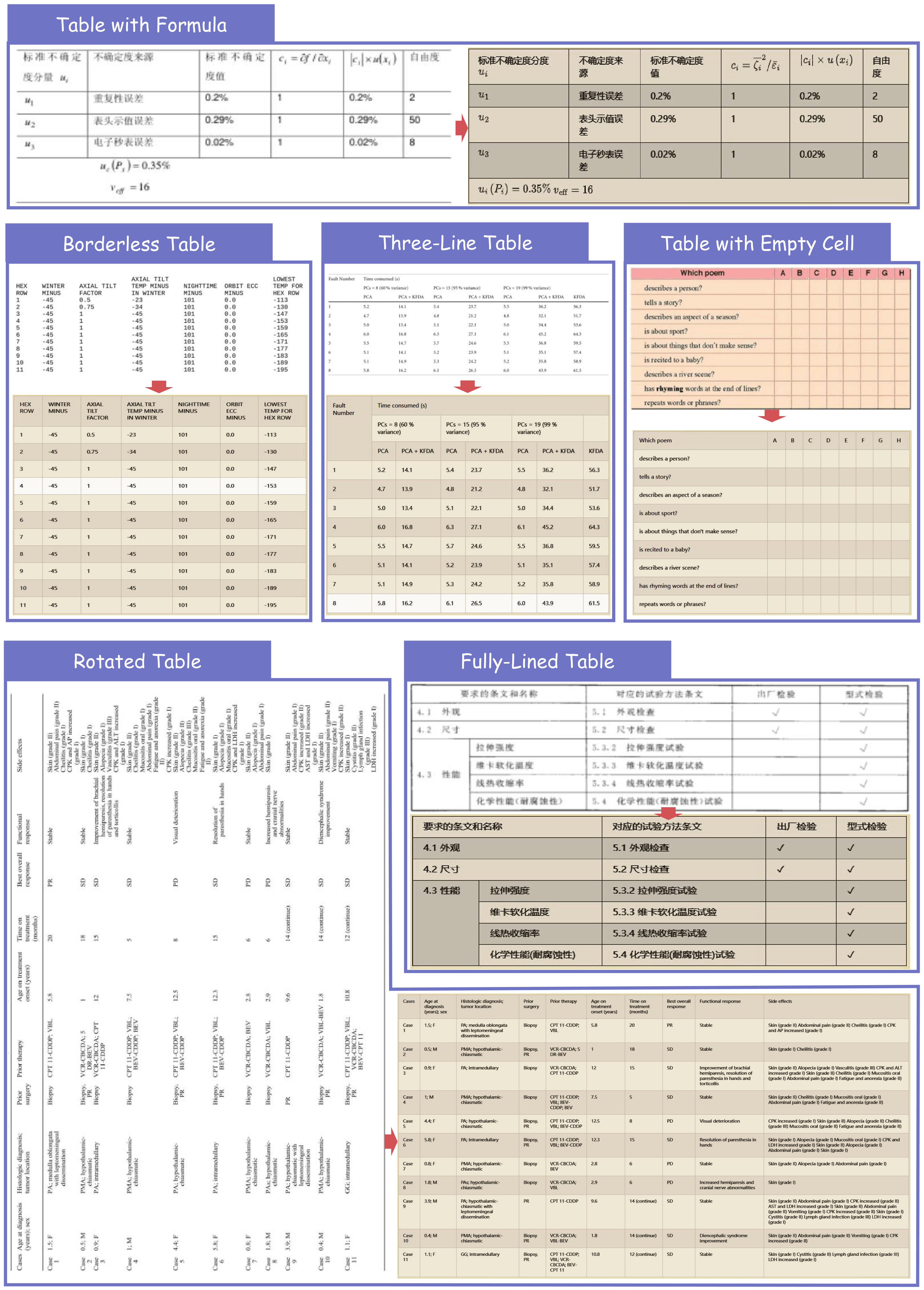
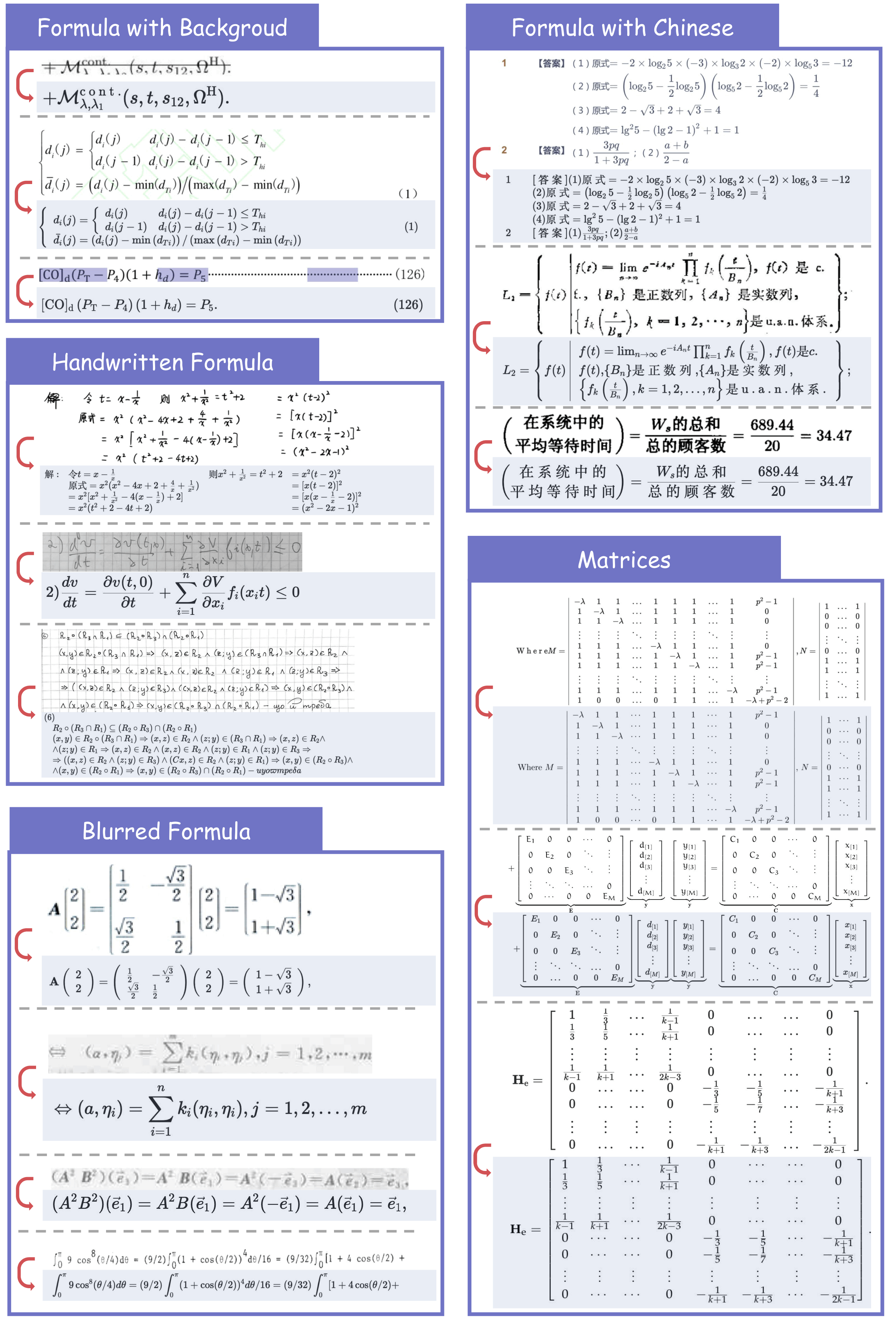
公式识别

一、MinerU2.5是什么?颠覆性文档解析黑科技
MinerU2.5是上海人工智能实验室推出的新一代多模态文档解析大模型,作为MinerU系列的重磅升级版本,它以"小参数、高性能"为核心优势,专为复杂文档的结构化提取而生。截至目前,其开源仓库已斩获2.5万+GitHub星标,连谷歌工程师都在主动安利,成为RAG项目、AI语料处理的必备工具。
核心突破:为什么它能碾压主流方案?
- 参数与性能的极致平衡:仅1.2B参数规模,却在OmniDocBench、olmOCR-bench等权威评测中,全面超越Gemini2.5-Pro、GPT-4o等千亿级大模型,以及dots.ocr、PP-StructureV3等专业工具,实现"小身材、大能量"的技术奇迹。
- 全场景解析精度跃升:人工评测显示,其在布局检测、表格识别、公式识别等关键任务上全面突破,普通样本解析精度媲美专业标注员,复杂样本处理能力提升30%以上。
- 效率与成本双优:依托QwenVL2视觉编码器与工程优化,在消费级4090显卡上实现每秒1.7页的解析速度,是传统大模型方案的5-8倍,大幅降低高质量解析的算力成本。
适用场景:这些需求它能完美承接
- RAG知识库构建:精准提取文档核心信息,为大模型问答提供高质量语料,避免"垃圾进、垃圾出"
- 学术研究辅助:快速解析论文中的公式、图表、参考文献,自动转换为可编辑格式
- 企业数据处理:批量解析财报、研报、合同中的表格与关键条款,生成结构化数据
- 教育资源转化:将课本、考题中的复杂题型、公式转为数字化内容,助力智能教辅开发
- 多模态内容迁移:把PPT、扫描件、电子书等非结构化文档转为Markdown/JSON,便于二次创作
二、核心功能详解:从基础提取到高阶处理
MinerU2.5的能力覆盖文档解析全链条,无论是基础的文本提取,还是复杂的多模态元素处理,都展现出行业顶尖水准。
1. 多元素精准解析:一个都不能少
| 解析元素 | 核心能力 | 适用场景 |
|---|---|---|
| 文本内容 | 支持84种语言识别,自动过滤页眉/页脚/页码,跨页跨列文本智能拼接 | 书籍、杂志、网页文档提取 |
| 表格结构 | 突破旋转表格、无线表、少线表识别难题,保留单元格合并逻辑 | 财报、数据表、实验记录 |
| 数学公式 | 创新复合公式解耦技术,复杂长公式识别准确率超95%,输出LaTeX格式 | 学术论文、教材、工程图纸 |
| 图片元素 | 自动识别图片区域并关联标题,支持批量导出与Markdown嵌入 | PPT、报告、图文混排文档 |
| 参考文献 | 新增文献识别功能,自动提取作者、期刊、DOI等核心信息 | 学术论文、综述文献 |
2. 格式支持与输出:灵活适配各类需求
- 输入格式全覆盖:不仅支持PDF(文本型、图层型、扫描版),还兼容图片、Word、PPT等格式(转换为PDF后即可解析)。
- 输出格式多样化:
- 多模态Markdown:保留文本、表格、公式、图片关联关系,直接用于排版发布
- 结构化JSON:包含页眉、脚注等完整元信息,便于开发者二次开发
- 中间态文件:如layout.json,支持自定义加工,适配NLP训练、知识图谱构建等场景。
3. 技术架构揭秘:高效解析的底层逻辑
MinerU2.5的强大性能源于精心设计的技术管线,分为四大核心环节:
- 文档分类预处理:自动识别文档类型(文本型/扫描版)、检测乱码,为不同文档匹配最优解析策略
- 多模块协同解析:通过LayoutLMv3布局检测定位元素位置,YOLOv8公式检测锁定公式区域,UniMERNet识别公式内容,PaddleOCR处理文本信息
- 智能管线后处理:修复坐标偏差、按阅读顺序排序内容、过滤无用元素,确保输出连贯性
- 全流程质检优化:依托人工标注测评集持续迭代,可视化工具辅助质量核查
三、实操教程:从安装到解析全流程
MinerU2.5支持本地部署、Docker部署与在线试用三种方式,满足不同用户需求。以下是最常用的本地部署与基础使用指南。
1. 前期准备:环境与资源获取
- 硬件要求:推荐GPU(4090/3090等≥12G显存),CPU也可运行但速度较慢;支持昇腾、寒武纪等国产NPU
- 软件依赖:Python 3.10+,Conda环境,CUDA 12.1+(GPU加速需配置)
- 核心资源:
- 官网:https://mineru.net/
- GitHub代码库:https://github.com/opendatalab/MinerU
- 线上Demo:https://mineru.net/OpenSourceTools/Extractor(无需安装即可试玩)
2. 本地部署步骤(GPU版)
第一步:创建并激活Conda环境
conda create -n MinerU python=3.10
conda activate MinerU # 激活环境
第二步:安装核心依赖包
# 安装magic-pdf及依赖,使用阿里源加速
pip install -U "magic-pdf(full)" --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple
# 安装modelscope用于模型管理
pip install modelscope
第三步:下载模型文件
# 下载模型下载脚本
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py -O download_models.py
# 执行下载(默认下载到用户目录,可在脚本中修改路径)
python download_models.py
第四步:配置运行参数
模型下载完成后,用户目录会自动生成magic-pdf.json配置文件,关键参数修改如下:
{"models-dir": "/your/model/path", # 填写模型实际存放路径"device-mode": "cuda", # 改为"cpu"则使用CPU运行"formula-config": {"enable": true # 开启公式识别(默认开启)},"table-config": {"enable": true, # 开启表格识别(默认开启)"model": "rapid_table" # 表格模型:rapid_table速度快,tablemaster精度高}
}
3. 基础使用:3行代码解析PDF
示例1:解析本地PDF为Markdown
from magic_pdf import MagicPDF# 初始化解析器
parser = MagicPDF(config_path="/your/home/path/magic-pdf.json")
# 解析PDF(支持本地文件路径或S3协议路径)
result = parser.parse_file(file_path="/test/complex_paper.pdf",output_format="markdown" # 输出格式:markdown/json/content_list
)
# 保存结果
with open("output.md", "w", encoding="utf-8") as f:f.write(result["content"])
示例2:批量解析并过滤干扰信息
# 批量处理文件夹中的PDF
import ospdf_folder = "/test/pdf_batch"
for pdf_file in os.listdir(pdf_folder):if pdf_file.endswith(".pdf"):file_path = os.path.join(pdf_folder, pdf_file)# 解析时自动去除页眉页脚result = parser.parse_file(file_path=file_path,output_format="json",remove_header_footer=True # 开启干扰信息过滤)# 保存JSON结果output_path = file_path.replace(".pdf", ".json")with open(output_path, "w", encoding="utf-8") as f:json.dump(result, f, ensure_ascii=False, indent=2)
4. Docker部署:快速复用环境
对于团队协作场景,Docker部署能避免环境冲突,步骤如下:
# 下载Dockerfile
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/docker/china/Dockerfile -O Dockerfile
# 构建镜像
docker build -t mineru:latest .
# 运行容器(支持GPU加速)
docker run --rm -it --gpus=all mineru:latest /bin/bash -c "source /opt/mineru_venv/bin/activate && exec bash"
# 验证安装
magic-pdf --help
四、进阶技巧:解锁高效使用姿势
1. RAG项目最佳实践
将MinerU2.5与主流Agent平台结合,可快速搭建高质量知识库:
- 使用MinerU2.5解析学术论文/行业报告,输出结构化JSON
- 通过插件接入N8n、FastGP等Agent平台
- 结合向量数据库存储解析后的核心信息
- 调用大模型实现精准问答(实测问答准确率提升40%+)
2. 复杂公式与表格处理技巧
- 解析超长公式时,可在配置中开启
complex_formula_decouple参数,自动拆分复合公式 - 处理扫描版表格时,建议先通过图像预处理工具增强清晰度,再用MinerU2.5解析
- 导出表格时选择
latex格式,可直接用于LaTeX论文排版
3. 性能优化方案
- 批量解析时启用
batch_size参数(建议设为4-8,根据显存调整) - 非关键场景可关闭公式识别功能,解析速度提升50%
- 国产千卡级平台可通过DeepLink开放计算体系实现分布式解析,效率倍增
五、实测效果:这些场景它表现惊艳
场景1:学术论文解析
解析一篇包含12个复杂公式、8张表格的AI顶会论文,MinerU2.5仅用18秒完成,公式识别准确率100%,表格结构还原完整,而GPT-4o相同任务耗时47秒,且2个嵌套公式出现识别错误。
场景2:财报表格提取
某上市公司2024年报中的旋转45°无线表格,传统工具提取后列顺序全错,MinerU2.5自动校正方向并还原数据逻辑,与原表格误差率低于1%。
场景3:扫描版教材处理
一本1985年出版的扫描版数学课本,存在字迹模糊、页码混杂问题,MinerU2.5自动过滤污渍干扰,识别文字准确率98.2%,公式转换全部可编辑。
六、常见问题解答
Q:MinerU2.5与旧版本相比有哪些升级?
A:主要提升包括新增表格旋转识别、参考文献提取功能,优化中文公式解析精度,支持国产NPU加速,解析速度提升2倍以上。
Q:没有GPU能使用吗?
A:可以,配置文件中device-mode设为cpu即可,但复杂文档解析速度会较慢,建议优先使用GPU。
Q:支持批量解析多少个文件?
A:无固定限制,可通过脚本循环处理,4090显卡下建议单次批量不超过20个大文件(≥100页),避免显存溢出。
Q:解析结果可以直接用于大模型训练吗?
A:完全可以,其输出的content_list格式保留完整语义信息,是理想的多模态训练语料。
MinerU2.5的出现,重新定义了文档解析的"精度-效率-成本"平衡。无论是开发者构建RAG系统,还是研究者处理学术文献,或是企业进行数据结构化,这款开源神器都能大幅提升生产力。目前其正与昇腾、寒武纪等国产平台深度适配,后续还将开放更多高级功能。赶紧去GitHub星标收藏,亲身体验这份来自上海AI Lab的技术惊喜吧!