【完整源码+数据集+部署教程】工厂工人操作机械工作图像分割系统: yolov8-seg-RepHGNetV2
背景意义
研究背景与意义
随着工业自动化和智能制造的快速发展,工厂安全管理和生产效率的提升愈发受到重视。在这一背景下,工人操作机械的安全性和规范性成为了企业管理者和研究者关注的焦点。工人在进行机械操作时,佩戴合适的安全防护装备(如安全帽、手套、反光背心等)是确保其人身安全的重要措施。然而,工人是否正确佩戴这些防护装备,以及在工作过程中是否遵循安全操作规程,直接影响到工厂的安全生产环境。因此,开发一套高效的图像分割系统,以实时监测工人在操作机械时的安全状态,具有重要的现实意义。
近年来,深度学习技术的迅猛发展为图像处理领域带来了革命性的变化。尤其是目标检测和图像分割技术的进步,使得对复杂场景中目标的识别和分割变得更加高效和准确。YOLO(You Only Look Once)系列模型作为当前流行的目标检测算法,凭借其高效性和实时性,在多个应用场景中取得了显著的成果。YOLOv8作为该系列的最新版本,进一步提升了检测精度和速度,适用于复杂的工业环境。通过对YOLOv8进行改进,结合工厂工人操作机械的特定需求,可以构建一个高效的图像分割系统,以实现对工人及其防护装备的实时监测。
本研究将基于改进的YOLOv8模型,开发一套工厂工人操作机械工作图像分割系统。该系统将利用包含1300张图像的数据集,涵盖10个类别,包括工人及其防护装备(如安全帽、手套、反光背心等)以及工作机械。这些类别的细分将有助于系统在实际应用中进行更为精确的识别和分析。通过对图像数据的深度学习训练,系统能够有效识别工人在操作机械时的安全状态,并及时发出警示,从而降低工伤事故的发生率。
此外,研究还将探讨图像分割技术在工厂安全管理中的应用潜力。通过对工人佩戴防护装备的监测,企业可以及时发现安全隐患,采取相应措施,提升整体安全管理水平。同时,该系统还可以为工人提供实时反馈,增强其安全意识,促进安全文化的建设。
综上所述,基于改进YOLOv8的工厂工人操作机械工作图像分割系统的研究,不仅具有重要的理论价值,也具有广泛的实际应用前景。通过该系统的开发与应用,能够有效提升工厂的安全管理水平,保障工人的人身安全,为智能制造的可持续发展提供有力支持。
图片效果
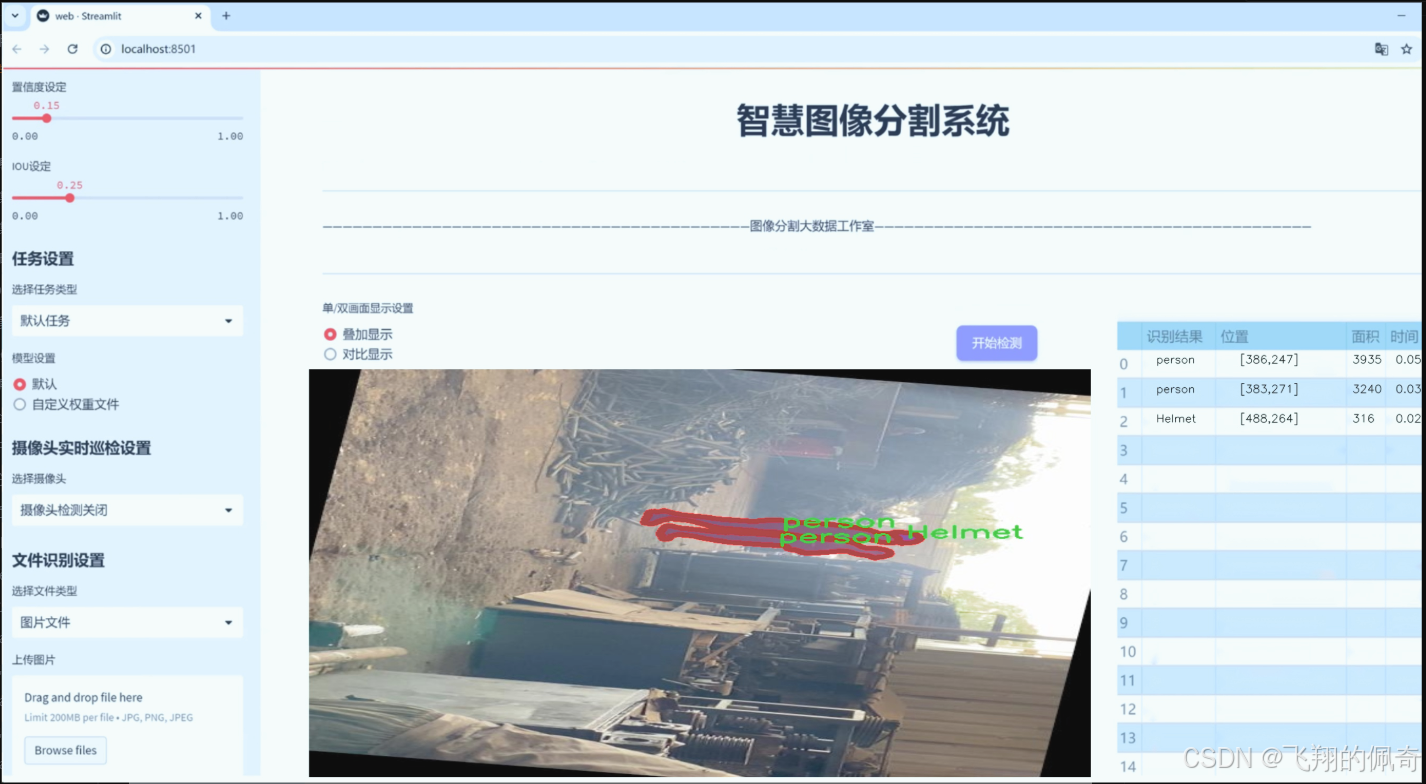
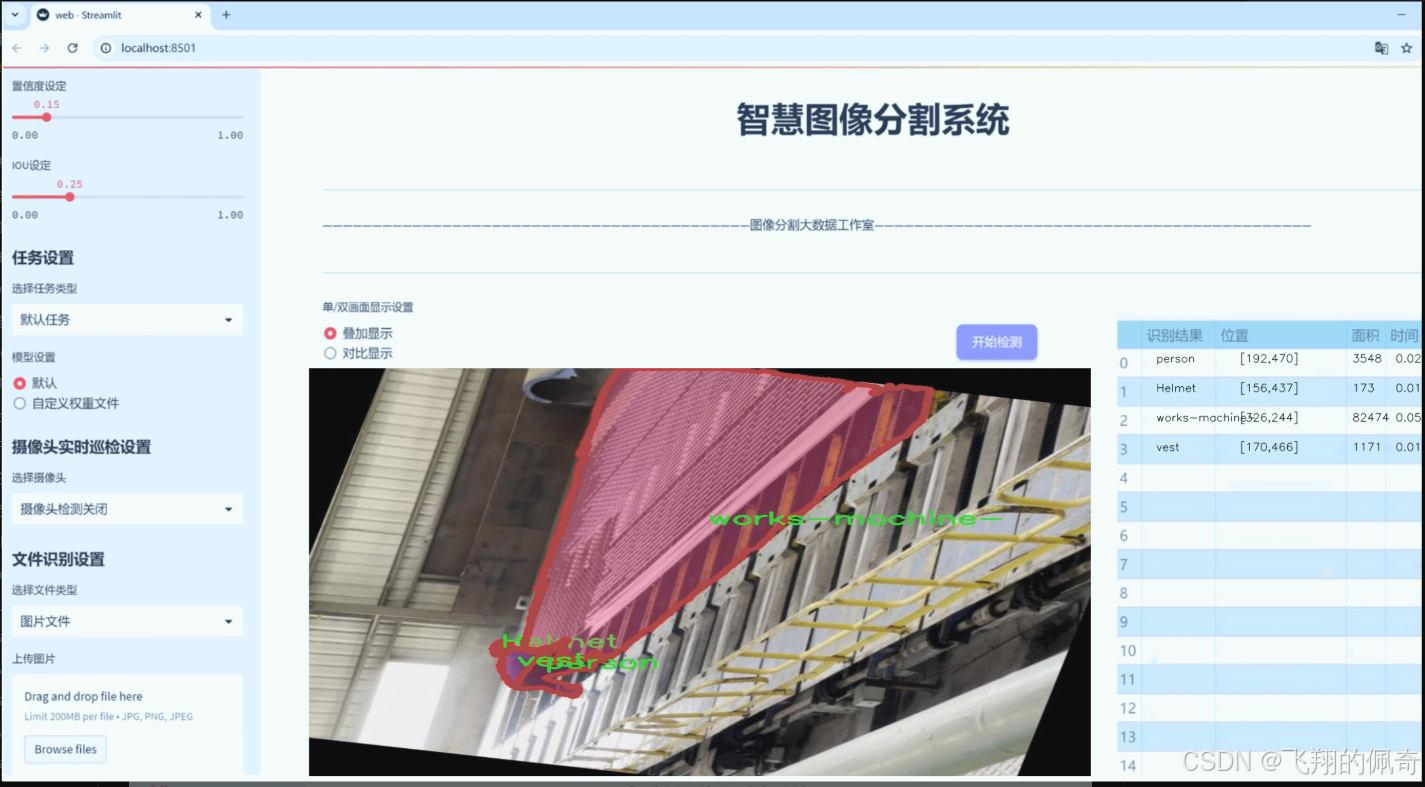
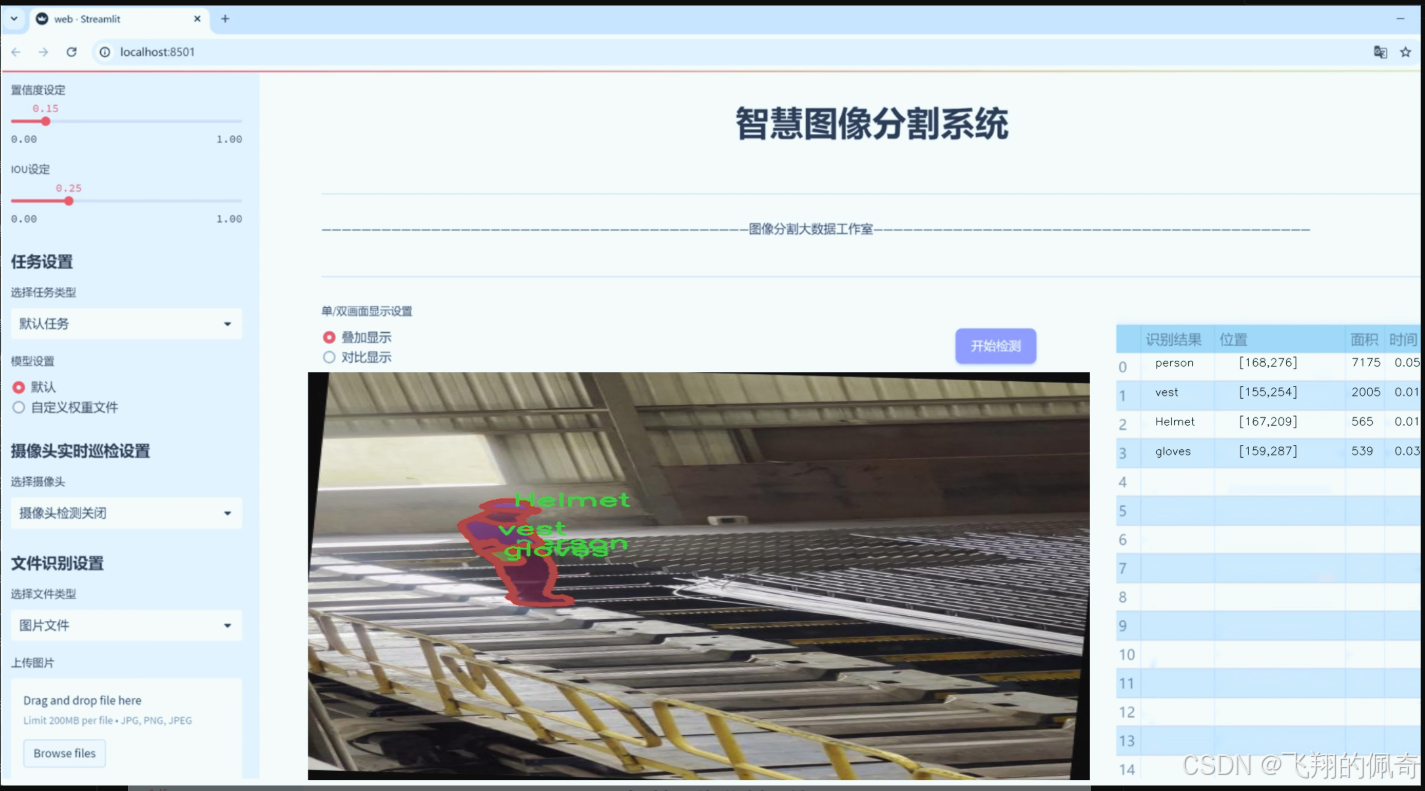
数据集信息
数据集信息展示
在现代工业环境中,工人安全是一个至关重要的议题。为了提高工人的安全意识和工作效率,图像分割技术在监控和分析工人操作机械的场景中发挥着越来越重要的作用。本研究旨在改进YOLOv8-seg模型,以实现对工厂工人操作机械时的图像分割。为此,我们构建了一个名为“3mr-7a7a”的数据集,专门用于训练和评估该系统的性能。
“3mr-7a7a”数据集包含了9个类别,涵盖了工人在工作环境中可能穿戴的各种安全装备及其缺失情况。这些类别包括:头盔(Helmet)、手套(gloves)、无手套(no-gloves)、无头盔(no-helmet)、无安全背心(no-vest)、工人(person)、安全鞋(safety shoes)、安全背心(vest)以及工作机械(works-machine)。这些类别的设计不仅考虑到了工人安全的基本要求,也反映了工人在实际工作中可能面临的各种风险。
在数据集的构建过程中,我们收集了大量的图像数据,这些图像展示了工人在不同工况下的操作场景。每张图像都经过精心标注,确保每个类别的物体都能被准确识别。这样的标注工作不仅提高了数据集的质量,也为后续的模型训练提供了坚实的基础。通过对这些图像的分析,模型能够学习到不同类别之间的特征差异,从而在实际应用中更好地识别和分割出工人及其所穿戴的安全装备。
在实际应用中,工人安全装备的佩戴情况直接影响到工人的安全。因此,数据集中包括了“无手套”、“无头盔”、“无安全背心”等类别,旨在帮助模型识别工人在工作中可能存在的安全隐患。这种对安全隐患的自动检测,不仅可以提高安全监管的效率,还能在一定程度上减少人为疏忽带来的风险。此外,数据集中还包含了“安全鞋”和“安全背心”等类别,以确保工人在工作时的全面保护。
为了确保数据集的多样性和代表性,我们在不同的工厂环境中进行了数据采集。这些环境包括制造业、建筑工地以及其他高风险作业场所。通过多样化的场景设置,数据集能够更好地适应不同的应用需求,提高模型的泛化能力。
在模型训练过程中,我们将“3mr-7a7a”数据集与YOLOv8-seg模型相结合,利用其强大的特征提取和实时检测能力,力求实现高效的图像分割效果。通过不断的迭代和优化,我们期望最终能够构建出一个能够实时监控工人安全装备佩戴情况的系统,从而为工人的安全保驾护航。
总之,“3mr-7a7a”数据集的构建和应用,不仅为改进YOLOv8-seg模型提供了丰富的训练素材,也为提升工人安全管理水平提供了新的技术手段。随着研究的深入,我们期待该系统能够在实际应用中发挥重要作用,为工人的安全保障贡献力量。





核心代码
以下是经过简化和注释的核心代码部分:
import os
import torch
from ultralytics.engine.validator import BaseValidator
from ultralytics.utils import LOGGER, ops
from ultralytics.utils.metrics import DetMetrics, box_iou
from ultralytics.utils.plotting import output_to_target, plot_images
class DetectionValidator(BaseValidator):
“”"
继承自BaseValidator类,用于基于检测模型的验证。
“”"
def __init__(self, dataloader=None, save_dir=None, args=None):"""初始化检测模型所需的变量和设置。"""super().__init__(dataloader, save_dir, args)self.metrics = DetMetrics(save_dir=self.save_dir) # 初始化检测指标self.iouv = torch.linspace(0.5, 0.95, 10) # 定义IOU向量,用于计算mAPdef preprocess(self, batch):"""对YOLO训练的图像批次进行预处理。"""# 将图像移动到设备上并进行归一化处理batch['img'] = batch['img'].to(self.device, non_blocking=True) / 255# 将其他数据也移动到设备上for k in ['batch_idx', 'cls', 'bboxes']:batch[k] = batch[k].to(self.device)return batchdef postprocess(self, preds):"""对预测输出应用非极大值抑制(NMS)。"""return ops.non_max_suppression(preds, self.args.conf, self.args.iou)def update_metrics(self, preds, batch):"""更新检测指标。"""for si, pred in enumerate(preds):idx = batch['batch_idx'] == si # 获取当前批次的索引cls = batch['cls'][idx] # 获取当前批次的类别bbox = batch['bboxes'][idx] # 获取当前批次的边界框npr = pred.shape[0] # 预测的数量if npr == 0:continue # 如果没有预测,跳过# 处理预测结果predn = pred.clone() # 克隆预测结果ops.scale_boxes(batch['img'][si].shape[1:], predn[:, :4], batch['ori_shape'][si]) # 缩放预测框# 计算IOU并更新指标if cls.shape[0] > 0:correct_bboxes = self._process_batch(predn, torch.cat((cls, bbox), 1))self.metrics.process(predn, cls) # 更新指标def _process_batch(self, detections, labels):"""返回正确的预测矩阵。"""iou = box_iou(labels[:, 1:], detections[:, :4]) # 计算IOUreturn self.match_predictions(detections[:, 5], labels[:, 0], iou) # 匹配预测与标签def print_results(self):"""打印每个类别的训练/验证集指标。"""LOGGER.info('Results: %s', self.metrics.mean_results()) # 打印平均结果def plot_predictions(self, batch, preds, ni):"""在输入图像上绘制预测的边界框并保存结果。"""plot_images(batch['img'], *output_to_target(preds), paths=batch['im_file'],fname=self.save_dir / f'val_batch{ni}_pred.jpg')
代码说明:
导入必要的库:导入处理数据、模型验证和绘图所需的库。
DetectionValidator类:该类继承自BaseValidator,用于实现YOLO模型的验证功能。
__init__方法:初始化检测指标和IOU向量,设置保存目录。
preprocess方法:对输入的图像批次进行预处理,包括将图像归一化和将数据移动到指定设备上。
postprocess方法:应用非极大值抑制(NMS)来过滤掉冗余的预测框。
update_metrics方法:更新检测指标,计算每个预测的IOU,并将结果与真实标签进行比较。
_process_batch方法:计算预测框与真实框之间的IOU,并返回正确的预测矩阵。
print_results方法:打印每个类别的验证结果。
plot_predictions方法:在图像上绘制预测的边界框,并将结果保存为图像文件。
这些核心部分展示了如何进行YOLO模型的验证和指标更新,同时提供了必要的预处理和后处理步骤。
这个程序文件 val.py 是 Ultralytics YOLO 模型的一部分,主要用于对目标检测模型进行验证。文件中定义了一个名为 DetectionValidator 的类,继承自 BaseValidator,该类实现了对 YOLO 模型的验证流程。
在类的初始化方法中,设置了一些必要的变量和参数,包括数据加载器、保存目录、进度条、命令行参数等。它还初始化了一些用于评估的指标,比如检测精度和混淆矩阵,并定义了一个用于计算 mAP(平均精度)的 IoU(交并比)向量。
preprocess 方法用于对输入的图像批次进行预处理,包括将图像数据转移到指定设备(如 GPU),并进行归一化处理。同时,如果启用了混合保存模式,还会生成用于自动标注的标签。
init_metrics 方法用于初始化评估指标,包括判断数据集是否为 COCO 格式,并根据模型的类别名称设置相应的指标。
get_desc 方法返回一个格式化的字符串,用于总结 YOLO 模型的类指标。
postprocess 方法应用非极大值抑制(NMS)来处理模型的预测输出,以去除重复的检测框。
update_metrics 方法负责更新评估指标,计算每个批次的预测结果与真实标签之间的匹配情况,并将结果保存到统计信息中。
finalize_metrics 方法用于设置最终的指标值,包括速度和混淆矩阵。
get_stats 方法返回指标统计信息和结果字典,计算每个类别的目标数量。
print_results 方法打印训练或验证集的每个类别的指标结果,并在必要时绘制混淆矩阵。
_process_batch 方法用于返回正确的预测矩阵,通过计算预测框与真实框之间的 IoU 来判断预测的准确性。
build_dataset 方法用于构建 YOLO 数据集,支持不同的增强方式。
get_dataloader 方法构建并返回数据加载器,以便在验证过程中按批次加载数据。
plot_val_samples 和 plot_predictions 方法用于绘制验证样本和预测结果,并将其保存为图像文件。
save_one_txt 方法将 YOLO 检测结果保存为特定格式的文本文件,包含归一化的坐标。
pred_to_json 方法将 YOLO 的预测结果序列化为 COCO JSON 格式,以便于后续的评估。
eval_json 方法用于评估 YOLO 输出的 JSON 格式结果,并返回性能统计信息,特别是计算 mAP 值。
整体来看,这个文件实现了 YOLO 模型在验证阶段的各项功能,包括数据预处理、指标计算、结果输出和可视化等,是目标检测模型评估的重要组成部分。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是 Ultralytics YOLO 项目的一个重要组成部分,主要用于目标检测和图像分割任务。它包含多个模块,每个模块负责特定的功能,整体构架清晰,便于扩展和维护。以下是各个模块的功能概述:
convnextv2.py:实现了 ConvNeXt V2 模型的结构,提供了构建卷积神经网络的基本组件,包括层归一化、全局响应归一化和残差块等,适用于计算机视觉任务。
atss.py:实现了自适应训练样本选择(ATSS)算法,主要用于目标检测中的锚框与真实框的匹配,提升模型训练的效率和准确性。
predict.py:定义了用于图像分割的预测器,负责处理输入图像并返回经过后处理的分割结果,适用于分割任务的推理阶段。
checks.py:提供了一系列工具函数,用于检查和验证环境配置、依赖关系、版本兼容性等,确保模型能够顺利运行。
val.py:实现了目标检测模型的验证流程,包括数据预处理、指标计算、结果输出和可视化等,评估模型在验证集上的性能。
文件功能整理表
文件路径 功能描述
ultralytics/nn/backbone/convnextv2.py 实现 ConvNeXt V2 模型的结构,包括层归一化、全局响应归一化和残差块,适用于计算机视觉任务。
ultralytics/utils/atss.py 实现自适应训练样本选择(ATSS)算法,用于目标检测中的锚框与真实框匹配,提升训练效率和准确性。
ultralytics/models/yolo/segment/predict.py 定义图像分割的预测器,处理输入图像并返回经过后处理的分割结果,适用于分割任务的推理阶段。
ultralytics/utils/checks.py 提供工具函数,检查和验证环境配置、依赖关系和版本兼容性,确保模型顺利运行。
ultralytics/models/yolo/detect/val.py 实现目标检测模型的验证流程,包括数据预处理、指标计算、结果输出和可视化,评估模型性能。
这个表格总结了每个文件的主要功能,便于理解整个程序的结构和功能模块。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻