腾讯 AudioStory:统一架构下的长篇叙事音频生成新标杆
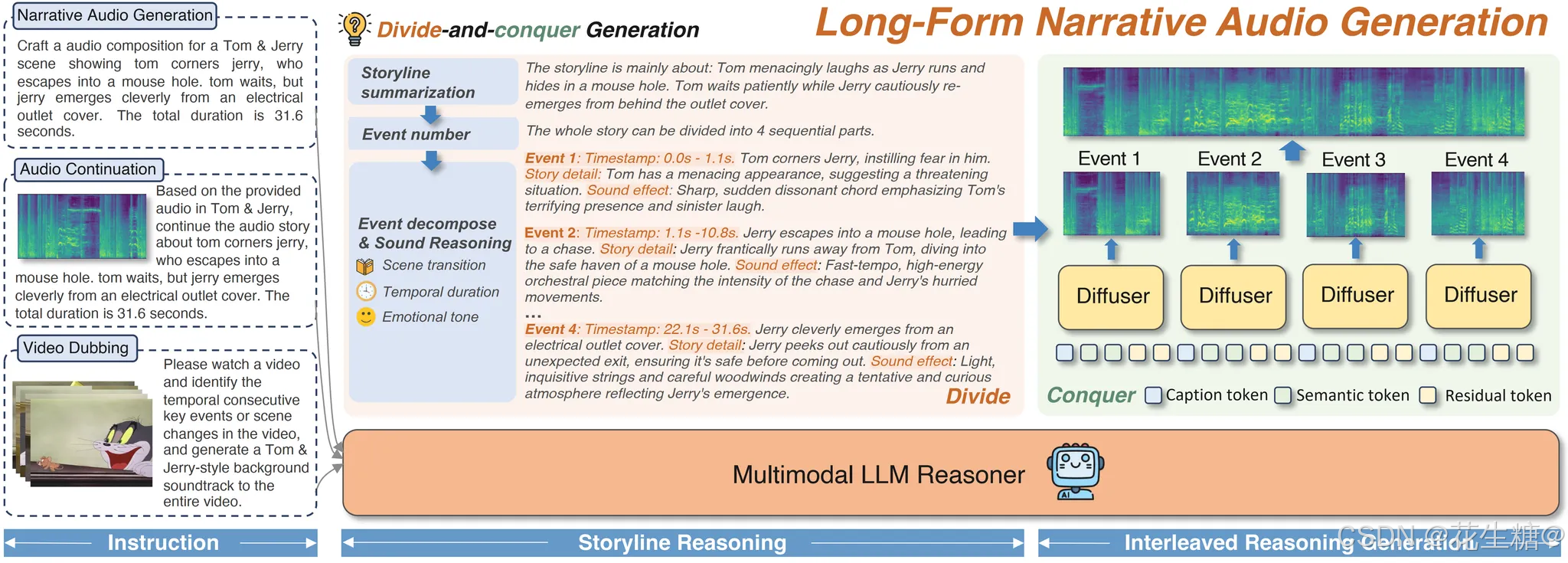 在生成式 AI 从图像、文本向多模态音频纵深发展的进程中,腾讯 ARC(AI Research Center)团队近日开源了其最新成果 —— AudioStory,一款面向长篇叙事场景的高质量音频生成模型。该模型不仅在场景过渡的连贯性与情感基调的一致性上实现显著突破,更以统一架构支持文本到音频、视频到配音、音频续写等多种任务,为有声小说、动画配音、互动叙事等应用开辟了全新可能。
在生成式 AI 从图像、文本向多模态音频纵深发展的进程中,腾讯 ARC(AI Research Center)团队近日开源了其最新成果 —— AudioStory,一款面向长篇叙事场景的高质量音频生成模型。该模型不仅在场景过渡的连贯性与情感基调的一致性上实现显著突破,更以统一架构支持文本到音频、视频到配音、音频续写等多种任务,为有声小说、动画配音、互动叙事等应用开辟了全新可能。
为什么长篇叙事音频生成如此困难?
与短音频合成(如语音播报)不同,长篇叙事音频需同时满足多重挑战:
- 时间跨度长:单段音频可达数分钟甚至更久,需维持整体节奏与情绪张力;
- 角色与场景多变:不同人物、环境音效、情绪转折需自然切换;
- 语义一致性高:音频必须忠实反映原文逻辑,避免“声画错位”或“情绪跳变”。
传统 TTS(文本到语音)系统往往局限于单说话人、短句合成,而基于扩散模型或 LLM+扩散混合架构的方案虽在音质上有所提升,却在长程一致性和多场景平滑过渡方面仍显不足。
AudioStory 正是在这一背景下应运而