LLM模型kv cache的估计和应用
transformer模型加速生成式推理的常用策略是KV cache。具体为:
1)预填充阶段,依据prompt为每个transformer层生成key cache和value cache,即kv cache;
2)解码阶段,使用并更新kv cache,依次生成输出,当前生成的token依赖之前生成的token。
这里通过示例第i个transformer的运行过程,分析为什么是kv cache,而不是kq或vq cache。然后,以此为基准,分析和估计kv cache的显存占用量。
1 transformer架构
生成式LLM的transformer架构如下图所示。左边encoder,右边decoder,采用cross attention。
decoder的multi head attention的K和V来自于encoder,而Q则来自于decoder。
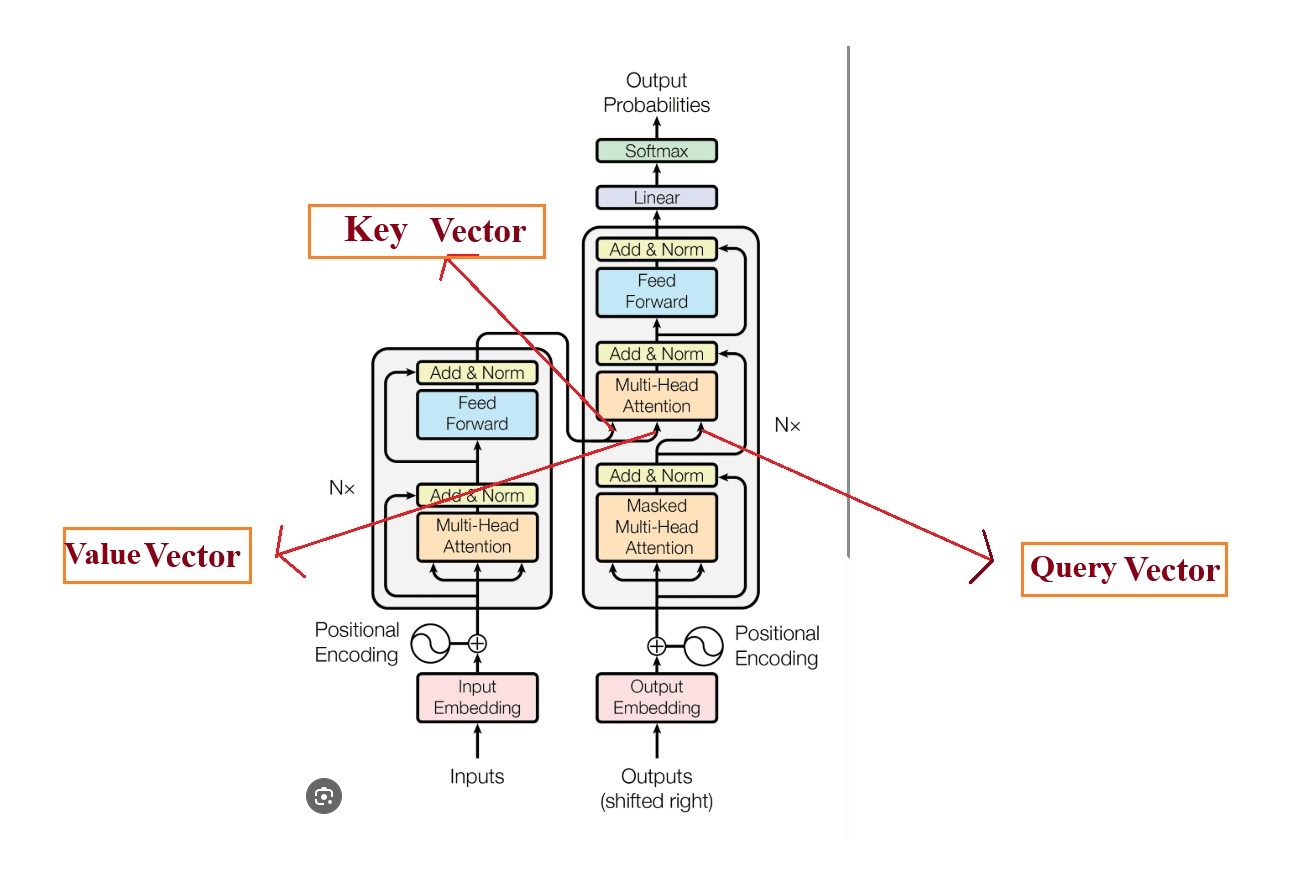
KV cache计算过程设计到transformer的权重矩阵,具体如下。
第i个transformer层的权重矩阵
其中,self-attention块的4个权重矩阵
mlp块的2个权重矩阵
2 预填充阶段
预填充阶段,即直接基于prompt输入计算第i个transformer层的kv cache的过程。
假设第i个transformer层的输入为,self-attention块的query,key,value和output表示为
针对xi,key cache和value cache的计算过程为
第i个transformer层剩余计算过程为
3 解码阶段
3.1 cross attention
结合上文提到的transformer架构,在decoder阶段,key vector和value vector来自于对encoder输出的拼接可以累积,而xQ则来自于decoder的实时在线计算,这也是为什么是KV cache,而不是QKV或QV cache的原因。示例图如下。
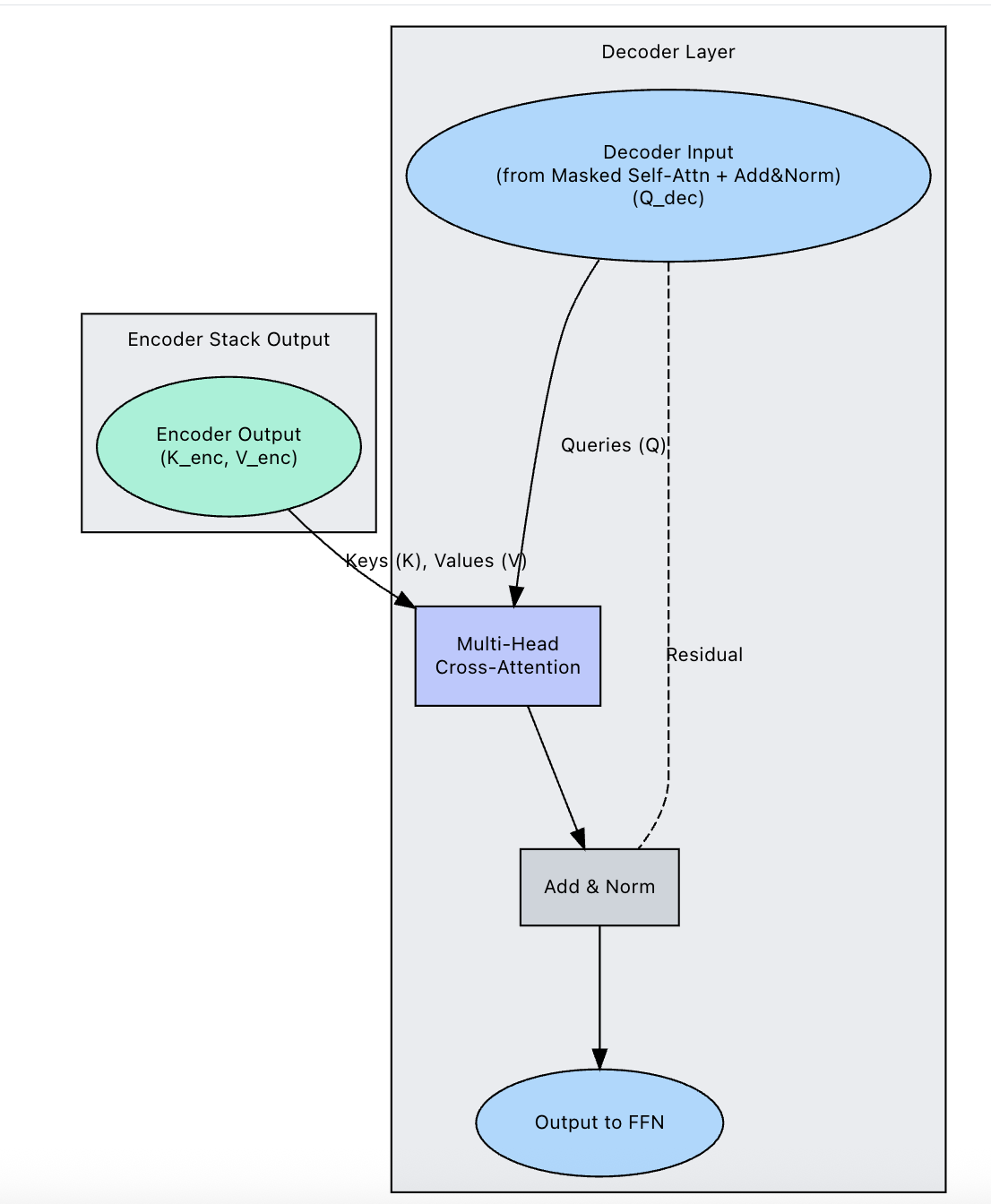
示例decoder cross attention代码如下所示。
class DecoderLayer(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.self_attn = MultiHeadAttention(d_model, num_heads)self.cross_attn = MultiHeadAttention(d_model, num_heads)self.ffn = FeedForward(d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(0.1)def forward(self, x, enc_output, src_mask, tgt_mask):# Self attention (маскированное)attn_output = self.self_attn(x, x, x, tgt_mask)x = self.norm1(x + self.dropout(attn_output))# Cross attention (с выходом энкодера)# enc_output, enc_output 对应key vector和value vectorattn_output = self.cross_attn(x, enc_output, enc_output, src_mask)x = self.norm2(x + self.dropout(attn_output))# Feed forwardffn_output = self.ffn(x)x = self.norm3(x + self.dropout(ffn_output))return x3.2 kv cache
给定当前生成词在第i个transformer层的向量表示为。
推断计算分两部分:更新KV cache和计算第i个transformer层的输出。
更新key cache和value cache的计算过程如下,对于xk和xv,可以通过cache 缓存之前已经计算好的结果。
第i个transformer层剩余计算过程为:
4 KV cache估计
假设输入序列长度为s,输出序列长度为n,以float16精度保存KV cache。
参考上述分析过程,KV cache的峰值显存占用大小表示如下。
第一个2表示K cache和V的cache,第二个2表示float16占2个bytes。
以GPT3为例,对比KV cache与模型参数占用显存的大小。
GPT3模型占用显存大小为350GB。
假设批次大小b=64 ,输入序列长度s=512 ,输出序列长度 n=32 。
参考上说估计公式,KV cache占用显存 4blh(s+n)=164282499072 bytes ≈164 GB,大约是模型参数的1/2。
reference
---
LLM模型的计算量估计
https://blog.csdn.net/liliang199/article/details/152081156
LLM模型的参数量估计
https://blog.csdn.net/liliang199/article/details/151839842
分析transformer模型的参数量、计算量、中间激活、KV cache
https://zhuanlan.zhihu.com/p/624740065
LLM模型的计算量与参数量的关系
https://blog.csdn.net/liliang199/article/details/152095274
LLM模型的中间激活值估计
https://blog.csdn.net/liliang199/article/details/152140815
Why KVcache, not Qcache?
https://zhuanlan.zhihu.com/p/4590995054
transformer-cross-attention
https://www.praudyog.com/deep-learning-tutorials/transformers-cross-attention/
Encoder-Decoder Cross-Attention
https://apxml.com/courses/foundations-transformers-architecture/chapter-5-encoder-decoder-stacks/encoder-decoder-cross-attention