检索增强生成(RAG)全流程解析
一、大模型构建六步法
大语言模型(LLM)的系统性构建遵循六大核心阶段,奠定模型能力基线:
| 阶段 | 关键任务 | 核心价值 |
|---|---|---|
| 1. 海量数据采集 | 收集互联网公开文本(书籍、百科、新闻、论坛等),构建覆盖广、多样性高的语料库 | 奠定模型知识广度,确保语义覆盖全面性 |
| 2. 数据预处理 | 清洗噪声、修正错误、标准化格式,切分为Token序列 | 保障训练数据质量与一致性,提升模型学习效率 |
| 3. 模型架构设计 | 采用Transformer核心架构,通过自注意力机制建模长距离语义依赖 | 支撑千亿级参数扩展,实现高效语义理解 |
| 4. 预训练 | 基于自监督任务(如预测下一个词)学习语言统计规律 | 形成基础语言理解与生成能力,建立通用知识框架 |
| 5. 调整与优化 | 迭代改进训练策略、数据分布或架构细节 | 提升模型稳定性与任务适应性,针对性弥补短板 |
| 6. 评估与测试 | 通过MMLU、BIG-bench等多维度基准与人工评测 | 客观衡量能力边界,指导后续优化方向 |
关键洞察:构建过程决定了模型能力基线,优化策略决定落地效能。
二、三大优化路径:释放模型潜能
| 优化策略 | 定位 | 核心机制 | 适用场景 | 资源消耗 |
|---|---|---|---|---|
| 提示词工程 | 零成本、高敏捷的推理时引导 | 结构化指令、角色设定、思维链(CoT)激发已有能力 | 任务明确、知识已内化的场景 | 极低 |
| 微调 | 深度定制化训练时增强 | 在特定领域数据上继续训练,使通用模型转型为垂直领域专家 | 需深度领域知识的场景(医疗、法律等) | 中高(可使用LoRA等PEFT技术降低) |
| RAG | 动态知识注入 | 外部知识库实时检索融合,解决知识过期问题 | 需要时效性、准确性与可追溯性的场景 | 低(无需重训模型) |
实践建议:遵循“先提示,再RAG,后微调”的渐进路径,实现成本、效果与维护性的最优平衡。
三、RAG:核心原理与价值
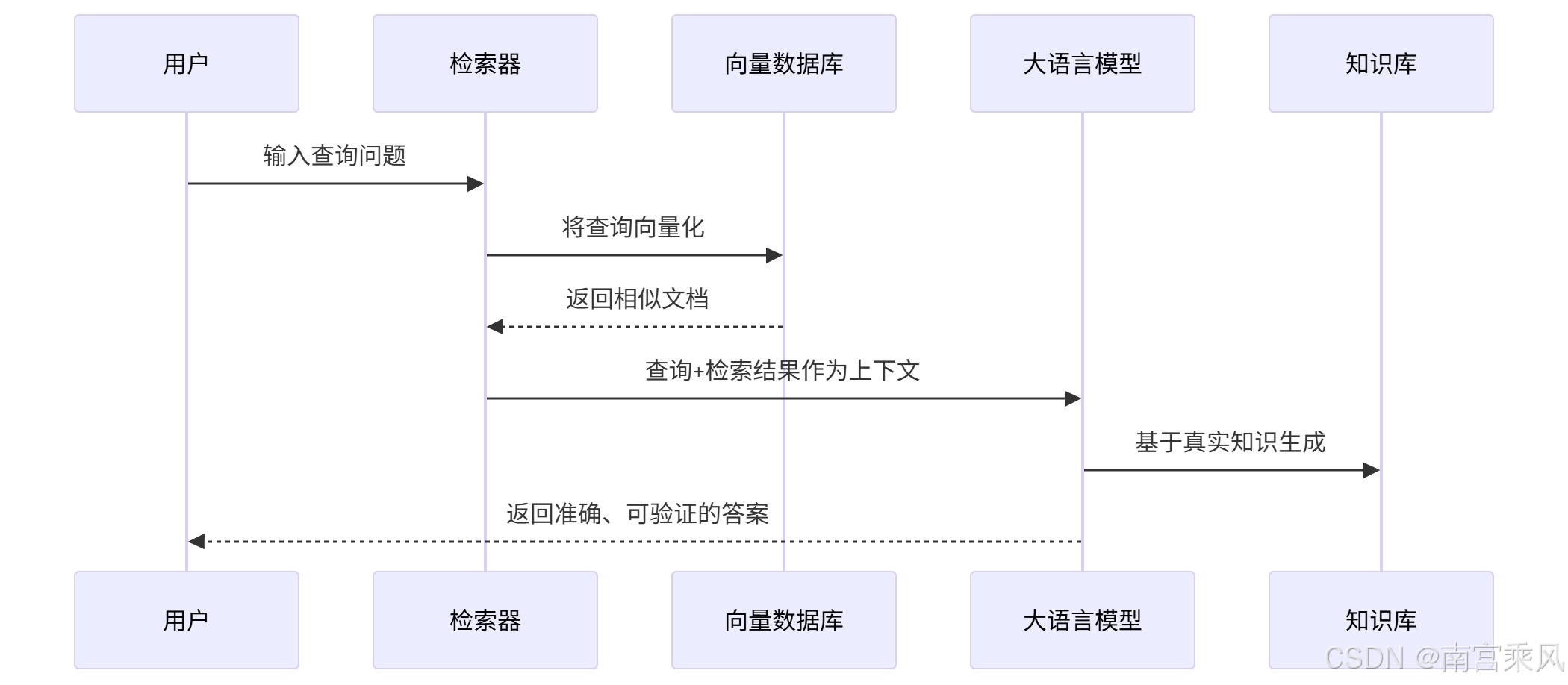
RAG (Retrieval-Augmented Generation) 是一种将信息检索与大语言模型生成相结合的AI架构范式。其核心思想是在生成答案前,先从外部知识库中检索相关信息,以此增强LLM的知识基础和事实准确性。
RAG 的全称是 Retrieval-Augmented Generation,中文是 “检索增强生成”。
这个名字听起来很复杂,但其实拆开看就很简单:
- 检索(Retrieval):当收到你的问题时,它首先不会直接回答,而是先去一个你指定的、最新的知识库(比如你们公司的飞书Wiki)里去“检索”和这个问题最相关的一些信息片段。
- 增强(Augmented):它把检索到的这些最新、最可靠的资料,作为上下文和背景知识。
- 生成(Generation):最后,它再结合这些刚刚查到的“参考资料”,运用它强大的语言理解和生成能力,为你组合成一个准确、连贯、有据可依的答案。
简单说,RAG = 一个“大脑”(AI模型) + 一个“外部知识库”。大脑负责理解和说话,知识库负责提供准确的事实依据。
核心组件

四、为何RAG是当前AI落地的关键范式?
大语言模型(LLM)虽具备强大的语言生成能力,但在实际业务场景中面临三大核心挑战:
- 知识时效性缺失:模型训练数据存在截止日期,无法获取最新信息;
- 领域专业性不足:通用模型缺乏企业私有知识与行业术语理解;
- 事实幻觉(Hallucination)风险:在缺乏依据时仍会“自信编造”答案。
RAG(检索增强生成) 正是为解决上述问题而生——它通过将外部知识库动态注入大模型推理过程,在不重新训练模型的前提下,显著提升回答的准确性、专业性与时效性。当前,RAG已成为企业构建私有知识问答系统、智能客服、内部知识助手等场景的首选技术架构。
典型案例:
- 问题:“我们今年团建预算是多少?”
- 传统LLM(过时记忆):“根据2022年标准,人均预算1000元。”
- RAG系统:
- 检索:在知识库中匹配“2025年 团建 预算”
- 增强:获取财务部最新文档《2025年度活动预算规划》
- 生成:“根据财务部最新发布的《2025年度活动预算规划》,今年团建预算标准为人均1500元。”
五、RAG系统全景架构
RAG并非单一技术,而是一套端到端的工作流系统,可划分为两大阶段:
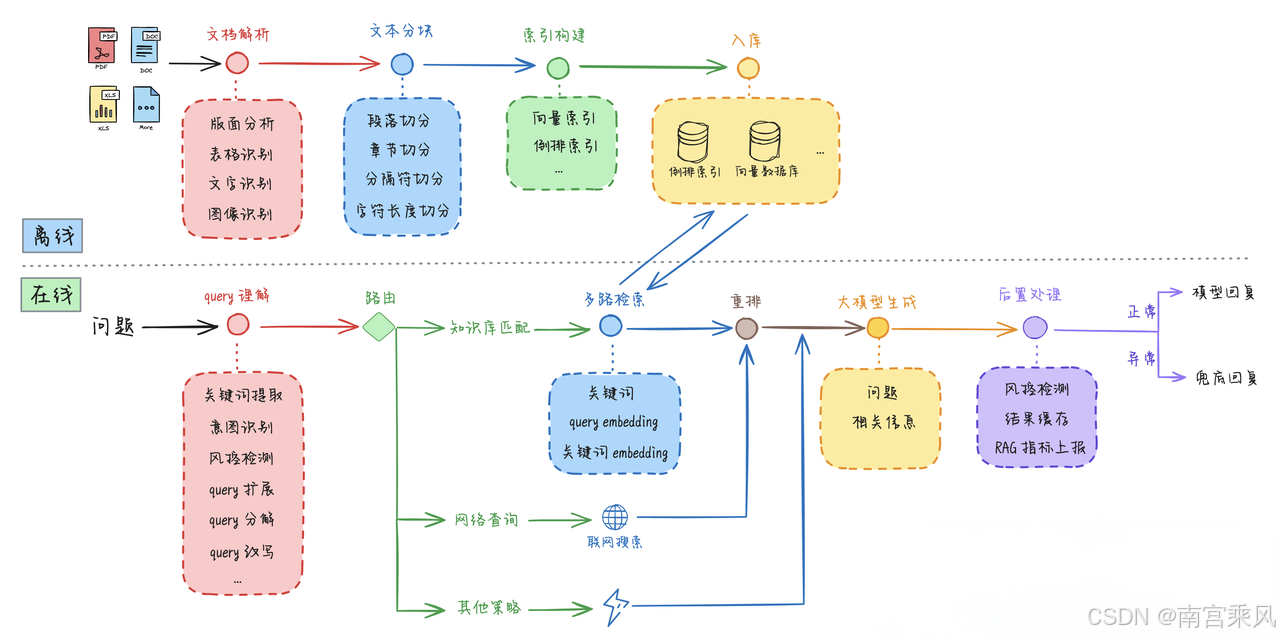
一、离线知识库构建(Indexing Pipeline)
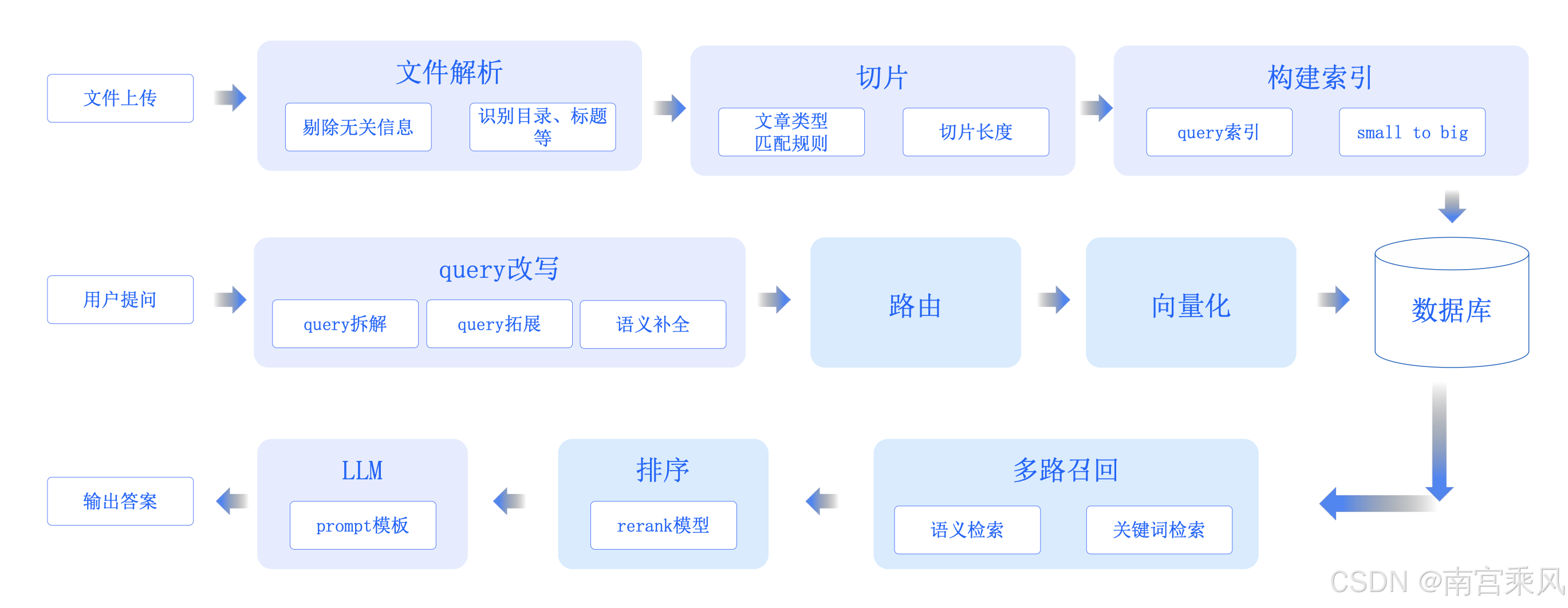
1. 文档解析
- 支持格式:PDF、Word、PPT、网页、数据库等
- 核心价值:保留原始文档结构信息(标题、表格、代码块、列表等)
- 实施要点:使用专业解析库(如PyPDF2、pdfplumber、Unstructured)确保结构完整性
2. 文本预处理
- 关键操作:清洗乱码、广告、页眉页脚、重复内容等噪声
- 核心价值:保障语义完整性,避免噪声干扰后续处理
- 最佳实践:保留关键元数据(如作者、日期、文档类型)
3. 文档分块(Chunking)
-
核心机制:将长文档切分为语义连贯的片段
-
关键洞察:分块策略直接决定RAG效果上限
-
策略对比
分块策略 适用场景 优势 局限性 按段落分块 技术文档、报告 保留逻辑连贯性 可能切分关键信息 按章节分块 合同、法律文件 确保条款上下文完整 长章节需二次切分 滑动窗口 研究论文、长文 平衡信息密度与连续性 可能产生语义重复 语义分块 专业文档 基于语义边界切分 实现复杂度高
黄金法则:技术文档宜用段落分块,合同类宜用章节分块,论文宜用语义+滑动窗口组合。
4. 向量化(Embedding)
-
核心机制:使用Embedding模型将文本转为高维向量
-
模型选型指南
领域 推荐模型 优势 适用场景 通用领域 text-embedding-3-large 综合性能最优 企业通用知识库 中文场景 bge-large-zh 中文语义理解强 中国企业和中文文档 多语言场景 bge-multilingual 跨语言支持 国际化业务场景 高精度需求 bge-reranker 语义匹配精准 专业领域知识库
5. 索引构建
-
核心机制:将向量存入向量数据库(OpenSearch、Milvus、Pinecone)
-
技术优势:支持高效近似最近邻(ANN)检索,毫秒级响应
-
优化要点
- 选择合适的距离度量(余弦相似度、L2)
- 设置合理的向量维度(通常384-1024)
- 启用元数据过滤(按时间、部门、文档类型)
二、在线问答推理(Query Pipeline)
1. 用户问题理解
- 关键操作:意图识别、关键词提取、问题改写
- 优化方案
- 基础版:基于关键词的简单改写
- 进阶版:结合小模型(如BERT)进行意图识别
- 企业级:定制Prompt工程优化查询语义
2. 检索(Retrieval)
- 核心机制:从向量库中召回Top-K相关片段
- 检索优化
- 混合检索:结合BM25(关键词匹配)与向量检索(语义匹配)
- 多路召回:设置多组Top-K参数,提升召回多样性
- 元数据过滤:按时间范围、文档类型等精准限定
3. 重排序(Re-ranking)
-
核心机制:对召回结果按相关性二次排序
-
技术对比
方法 精度 速度 适用场景 BM25 ★★☆ ★★★★★ 初步筛选 BGE-Reranker ★★★★☆ ★★☆ 高精度要求场景 自定义规则 ★★★ ★★★★ 企业特定业务场景
实施建议:优先采用BGE-Reranker(如bge-reranker-large)实现高精度重排序。
4. 上下文组装
- 关键操作:将重排后片段拼接为Prompt上下文
- 优化要点
- 限制总Token长度(建议≤2048)
- 优先保留高相关性片段
- 添加片段来源标记(如[文档1]、[文档2])
- 采用分层组装策略(先核心后辅助)
5. 大模型生成
-
核心机制:LLM基于上下文生成最终答案
-
Prompt设计关键要素
#你是一个专业的知识助手,基于以下检索到的文档片段回答问题: [检索片段1] [检索片段2] ...请严格基于上述文档回答,若文档未提供信息,请回答"无法从现有文档中获取相关信息"。 请在答案末尾标注来源文档。 -
进阶设计:添加"拒绝回答"机制,避免模型编造信息
6. 后置处理
- 关键操作:答案校验、引用标注、敏感词过滤
- 价值提升
- 可信度提升:标注来源(如"根据《2025年预算规划》第3章")
- 合规性保障:过滤敏感词,避免法律风险
- 质量校验:通过小模型验证答案与原文一致性
六、企业级RAG应用场景
场景类型 核心价值 解决痛点 量化价值提升 实施优先级 内部知识问答 企业知识中枢,降低培训成本 企业制度/IT/HR政策自助查询 员工效率↑50% 人工坐席压力↓40% ⭐⭐⭐⭐ 专业领域助手 赋能一线专业能力 医疗/法律/畜牧等专业场景快速决策 专业效率↑35-50% 误诊率↓20% ⭐⭐⭐ 文档智能分析 深度挖掘文档价值 合同风险识别/财报摘要等关键信息提取 审核效率↑60% 信息准确率↑85% ⭐⭐
七、常见误区与避坑指南
| 误区 | 事实 | 避坑方案 |
|---|---|---|
| “随便丢文档就能准确回答” | 文档质量、分块策略、检索精度共同决定效果 | ✅ 优先优化文档清洗+分块策略(技术文档用段落分块,合同用章节分块) |
| “RAG彻底解决幻觉” | LLM仍可能曲解检索内容 | ✅ 强制要求答案标注来源+置信度阈值(低于85%返回“无法回答”) |
| “RAG不消耗大模型Token” | 检索结果作为上下文输入LLM,计入Token消耗 | ✅ 控制检索结果长度(≤2048 Token)+ 优先保留高相关片段 |
| “RAG能学会写作风格” | RAG传递事实内容,非表达风格 | ✅ 风格优化需通过微调(如LoRA),RAG仅用于事实增强 |
避坑核心:RAG是事实增强工具,非万能解药。
黄金法则:先确保文档质量→优化分块策略→设计防御机制,避免盲目投入。
参考文档:https://zhuanlan.zhihu.com/p/673465732