DeepSeek-V3.2:DSA稀疏注意力的降本增效
引言
之前看到 DeepSeek 发布了 DeepSeek-V3.1-Terminus,以为 V3 走到了尽头,下面应该发 V4 了。
然而,DeepSeek 在国庆前突然发布 DeepSeek-V3.2,这是一个小版本升级,新的内容不多,主要内容是在 V3.1-Terminus 的基础上引入了DSA(一种稀疏注意力机制)。
本文来详细阅读一下。
论文标题:DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention
论文地址:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
1. 具体方法
这篇文章除去参考论文外,正文才 5 页,不像其它文章从“背景”还是讲故事,上来就直接开始讲具体方法,简明扼要,阅读友好。
从文章的标题就可以看出,这篇文章的核心是它提出了一种新的稀疏注意力机制 DSA(DeepSeek Sparse Attention),主要解决的是训练和推理的效率问题。
DSA 主要由两个部分组成:
-
- 闪电索引器(lightning indexer)
-
- 细粒度 token 选择机制(fine-grained token selection
mechanism)
- 细粒度 token 选择机制(fine-grained token selection
闪电索引器会计算查询 token ht∈Rdh_t \in \mathbb{R}^dht∈Rd 与先前 token hs∈Rdh_s \in \mathbb{R}^dhs∈Rd 之间的索引分数 It,sI_{t,s}It,s,从而决定查询 token 需要选择哪些 token:
It,s=∑j=1HIwt,jI⋅ReLU(qt,jI⋅ksI) I_{t,s} = \sum_{j=1}^{H_I} w^I_{t,j} \cdot \text{ReLU}\left(q^I_{t,j} \cdot k^I_s\right)It,s=j=1∑HIwt,jI⋅ReLU(qt,jI⋅ksI)
其中:
- HIH_IHI 表示索引器的头数;
- qt,jI∈RdIq^I_{t,j} \in \mathbb{R}^{d_I}qt,jI∈RdI 和 wt,jI∈Rw^I_{t,j} \in \mathbb{R}wt,jI∈R 由查询 token hth_tht 派生;
- ksI∈RdIk^I_s \in \mathbb{R}^{d_I}ksI∈RdI 由先前 token hsh_shs 派生。
由于闪电索引器的头数较少,并且可用 FP8 实现,因此它的计算效率非常高。
在获得每个查询 token hth_tht 的索引分数 {It,s}\{I_{t,s}\}{It,s} 后,细粒度 token 选择机制只会检索 top-k 的 key-value 条目 {cs}\{c_s\}{cs}。
然后,通过将查询 token hth_tht 与选出的稀疏 key-value 条目计算注意力,得到注意力输出:
ut=Attn(ht,{cs∣It,s∈Top-k(It,:)}) u_t = \text{Attn}\Big(h_t, \{c_s \mid I_{t,s} \in \text{Top-k}(I_{t,:})\}\Big) ut=Attn(ht,{cs∣It,s∈Top-k(It,:)})
为了能够在 DeepSeek-V3.1-Terminus 的基础上继续训练,DeepSeek-V3.2-Exp 中在 MLA 的基础上实现了 DSA。
其中,MLA 采用的是 MQA 模式,在这种模式下,每个潜在向量(即 MLA 的 key-value 条目)会在查询 token 的所有注意力头之间共享。
整个框架图如下图所示:
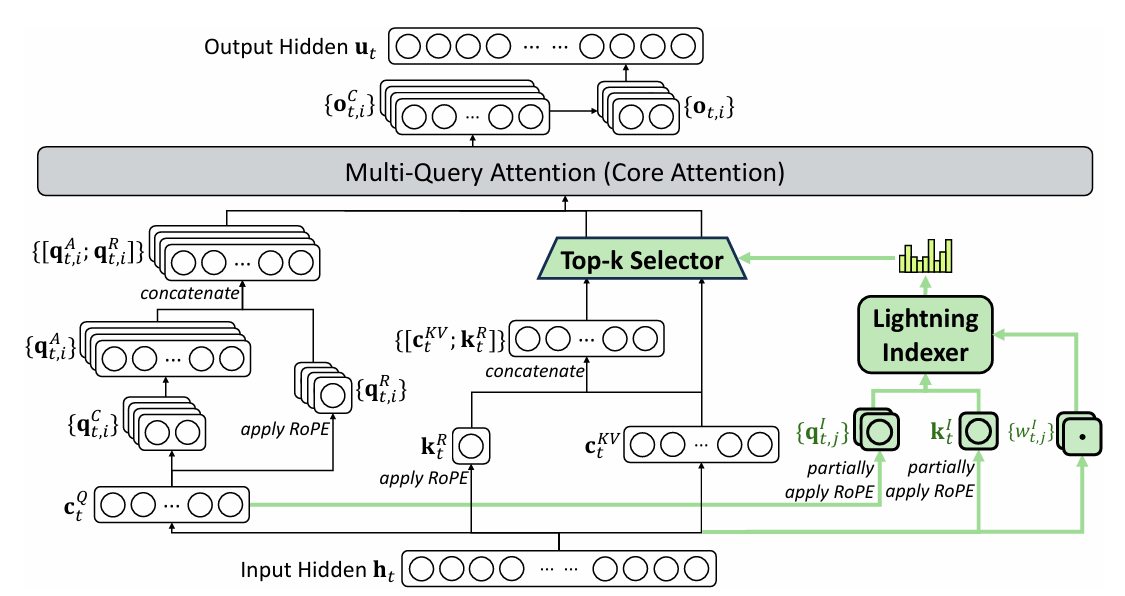
2. MLA相关知识回顾
上面这段看着有点绕,需要回顾一下 MLA,才能理解清楚。
2.1 问题背景
在标准 多头注意力 (MHA) 中,每个注意力头都会独立存储一份 Key 和 Value,如果上下文长度为 (L),隐藏维度为 (d),注意力头数为 (H),则 KV 缓存的大小是:
O(H×L×d) O(H \times L \times d) O(H×L×d)
在大模型和超长上下文场景下,这个显存/内存消耗非常惊人,成为部署和训练的瓶颈。
2.2 MQA 和 GQA
为了压缩 KV 缓存,MQA(Multi-Query Attention)直接让所有的注意力头共享一个同一个K、V,这样就把 KV 缓存的大小减小到 1/H1/H1/H,但是这样做也会带来一定的性能损失。
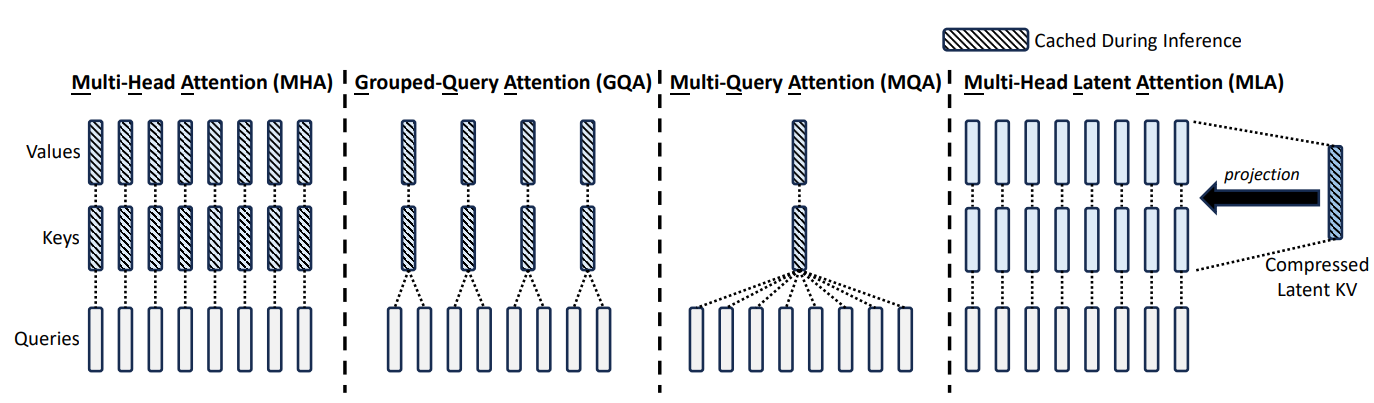
GQA(Grouped-Query Attention)是将所有的注意力头分成g个组,每组共享同一对K、V。
因此,g = H 时,MHA = GQA; g = 1 时,MQA = GQA。
2.3 MLA 具体方法
MLA 的核心思想是将所有注意力头的 Key 和 Value 映射到一个 共享的低秩潜在空间 (latent space),和 VAE 的思路有点相似。
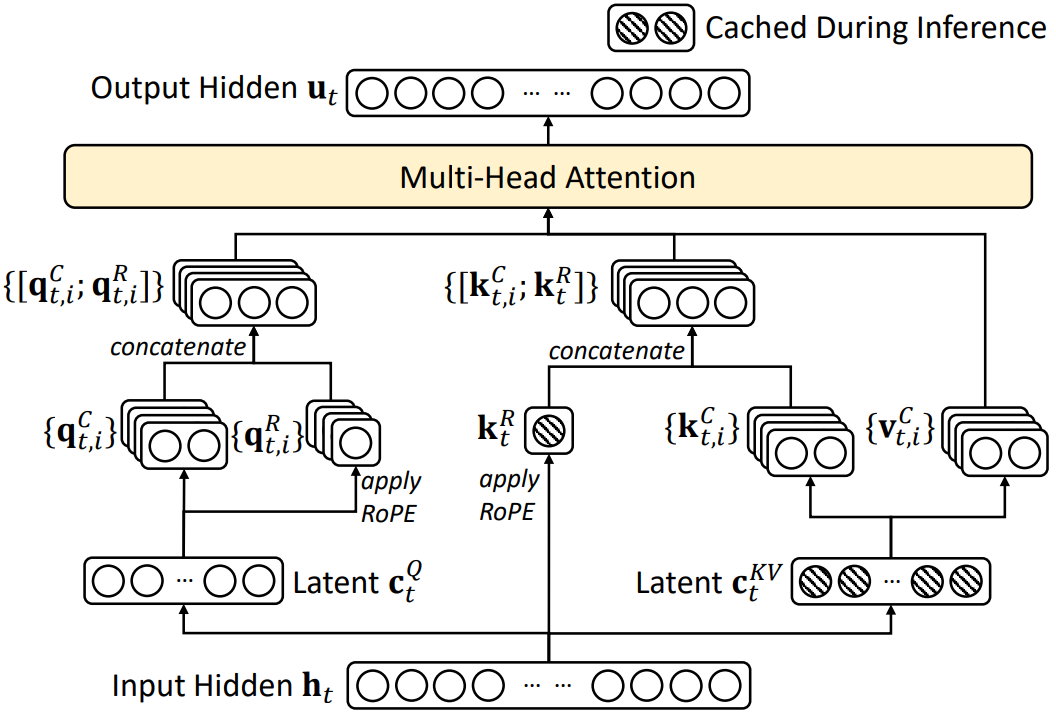
如图所示,具体的计算流程如下:
-
输入隐藏状态 (h_t)
-
输入的隐层表示会被映射到两个潜在空间:
- Latent (ctQc^Q_tctQ) (Query 潜在向量)
- Latent (ctKVc^{KV}_tctKV) (Key/Value 潜在向量)
-
-
Query 路径
-
从 (ctQc^Q_tctQ) 生成两类 Query:
- 内容相关的 Query:(qt,iC{q^C_{t,i}}qt,iC)
- 位置相关的 Query:(qt,iR{q^R_{t,i}}qt,iR),并施加 RoPE 旋转位置编码
-
两者拼接后形成最终的 Query 表示 ([;qt,iC;qt,iR;][;q^C_{t,i}; q^R_{t,i};][;qt,iC;qt,iR;])。
-
-
Key/Value 路径
-
从 (ctKVc^{KV}_tctKV) 生成:
- 内容相关的 Key/Value:(kt,iC,vt,iC{k^C_{t,i}, v^C_{t,i}}kt,iC,vt,iC)
- 位置相关的 Key:(ktRk^R_tktR),并施加 RoPE
-
拼接得到最终的 Key 表示 ([;kt,iC;ktR;][;k^C_{t,i}; k^R_t;][;kt,iC;ktR;])。
-
-
Multi-Head Attention
- 最终的注意力是标准的 MHA,但输入不是原始的 KV,而是来自 共享潜在空间解码出来的 KV,通过这种方式能够有效减少 KV 缓存。
有一个小点需要注意,在 MLA 里:
- Key/Value 不是每个 head 独立生成的,而是从共享的 潜在向量 (ctKV)(c^{KV}_t)(ctKV) 派生。
- 如果直接对 (ctKV)(c^{KV}_t)(ctKV) 应用 RoPE,那么所有 head 都共享相同的位置旋转,会丧失多头的作用。
MLA 的解决方式是单独引入 (ktR)(k^R_t)(ktR):
- MLA 把 Key 拆成 内容 Key ((kt,iC)(k^C_{t,i})(kt,iC)) 和 位置 Key ((ktR)(k^R_t)(ktR));
- (ktRk^R_tktR) 专门经过 RoPE 处理,负责携带位置信息;
- 最后拼接得到完整的 Key,拼接后的 Key 既有语义信息,又有位置信息。
2.4 MLA 与 MQA 结合
了解完 MLA 计算过程后,就可以发现,其实最后面的 MHA 是相对独立的,完全可以换成 MQA,因此在 DeepSeek-V3.2 文章的附录,展现了 MLA 的 MHA 模式和 MQA 模式的对比。
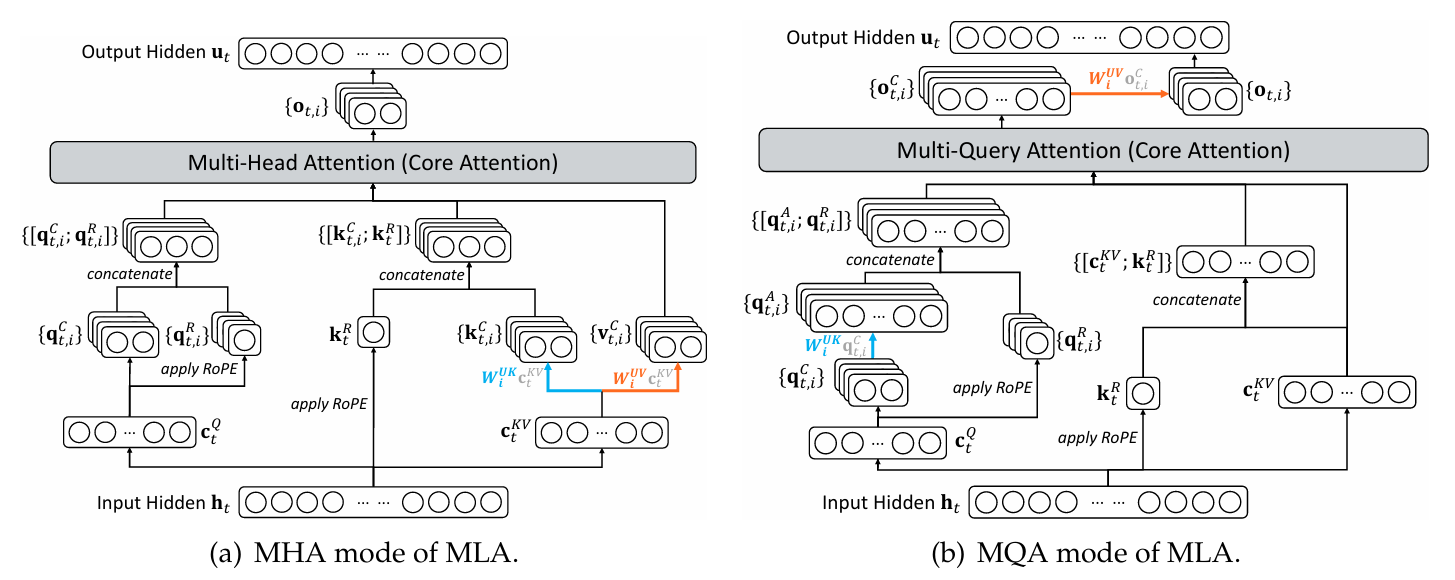
图中,左侧是 MHA 模式,和上一节的图基本一样,MQA 模式则是又额外做了简化, V 不在单独建模,而是和潜在向量绑定,进一步优化缓存占用。
补充完前置知识后,再回头看 DSA。
DSA 就是在 MLA 的 MQA 模式上,不再对所有历史 token 做全量注意力,而是从历史序列里选择 Top-k 个最相关的 key-value,然后在这部分子集上计算注意力。
因此,DSA 实现了**「共享 + 压缩 + 稀疏」**三重极致优化。
3. 训练流程
DeepSeek-V3.2 是在 V3.1-Terminus(128K 上下文)的检查点上继续训练,主要分继续预训练和后训练两个阶段。
3.1 继续预训练(Continued Pre-Training)
继续预训练又分为密集预热阶段和稀疏训练阶段两个阶段。
密集预热阶段(Dense Warm-up Stage)
我们首先进行一个简短的 warm-up 阶段,用来初始化闪电索引器。在该阶段中,冻结模型所有参数,只训练索引器。
为了让索引器输出与主注意力分布对齐,对于第 (t) 个查询 token:
- 先对所有注意力头的主注意力分数进行求和;
- 然后在序列维度上进行 L1 归一化,得到目标分布 (pt,:∈Rt)(p_{t,:} \in \mathbb{R}^t)(pt,:∈Rt)。
索引器的训练目标是最小化 KL 散度:
LI=∑tDKL(pt,: ∣ Softmax(It,:)) L_I = \sum_t D_{KL}\Big(p_{t,:} \ |\ \text{Softmax}(I_{t,:}) \Big) LI=t∑DKL(pt,: ∣ Softmax(It,:))
该阶段超参数:
- 学习率:10−310^{-3}10−3;
- 训练 1000 步,每步包含 16 个序列,每个序列长度为 128K;
- 共计 21 亿 tokens。
稀疏训练阶段(Sparse Training Stage)
在索引器 warm-up 完成后:
- 引入 top-k 细粒度 token 选择机制;
- 优化 全模型参数(包括索引器和主干),使其适应稀疏模式的 DSA。
在该阶段中,令索引器输出与主注意力分布对齐,
LI=∑tDKL(pt,St ∣ Softmax(It,St)) L_I = \sum_t D_{KL}\Big(p_{t,S_t} \ |\ \text{Softmax}(I_{t,S_t})\Big) LI=t∑DKL(pt,St ∣ Softmax(It,St))
该阶段超参数:
- 学习率:7.3×10−67.3 \times 10^{-6}7.3×10−6;
- 每个查询 token 选择 2048 个 key-value tokens;
- 训练 15000 步,每步包含 480 个 128K tokens 序列;
- 共计 9437 亿 tokens。
3.2 后训练(Post-Training)
为严格评估引入 DSA 的影响,保持了与 DeepSeek-V3.1-Terminus 相同的后训练流程、算法和数据,具体内容如下:
专家蒸馏(Specialist Distillation)
对于每个任务,首先训练一个专家模型(不同领域的专用模型,从 DeepSeek-V3.2 基础检查点微调得到),覆盖以下领域:
-
- 数学
-
- 竞赛编程
-
- 一般逻辑推理
-
- 智能体编程
-
- 智能体搜索
-
- 写作任务
-
- 通用问答
然后,专家模型进一步生成 长链式推理数据(thinking mode) 和 直接回答数据(non-thinking mode),拿这个数据再反过来去训 DeepSeek-V3.2。
这一步有点像“左脚踩右脚”,先用基础模型结合领域数据去微调成专家模型,再用专家模型蒸馏的合成数据反训基础模型。
混合 RL 训练(Mixed RL Training)
DeepSeek-V3.2 依然采用 GRPO 作为 RL 算法,不同于之前的多阶段 RL,这里把 推理、智能体、人类对齐 融合在一个 RL 阶段。
奖励设计:
- 推理 & 智能体任务:基于规则的结果奖励、长度惩罚、语言一致性奖励;
- 通用任务:使用生成式奖励模型,每个提示有自己的评分规则。
整体奖励设计权衡两个核心问题:
- 长度和准确率的平衡
- 语言一致性和准确率的平衡
4. 模型评估
拿 DeepSeek-V3.1-Terminus 和 DeepSeek-V3.2 进行对比,两者在不同领域的数据集上,评分如下表所示。
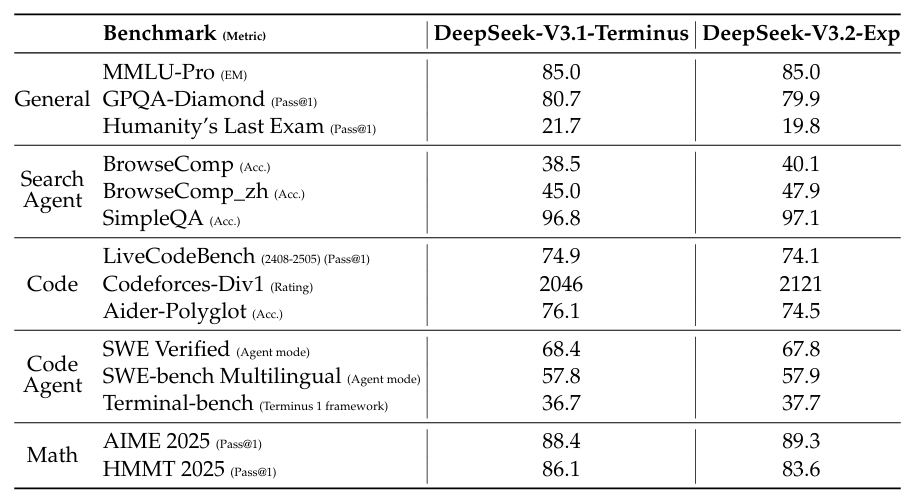
从数值来看,两者没有太大的差异,但要知道 DeepSeek-V3.2 的目的不是提升性能指标,而是降低推理成本。这结果说明,DSA 并没有导致模型性能的下滑。
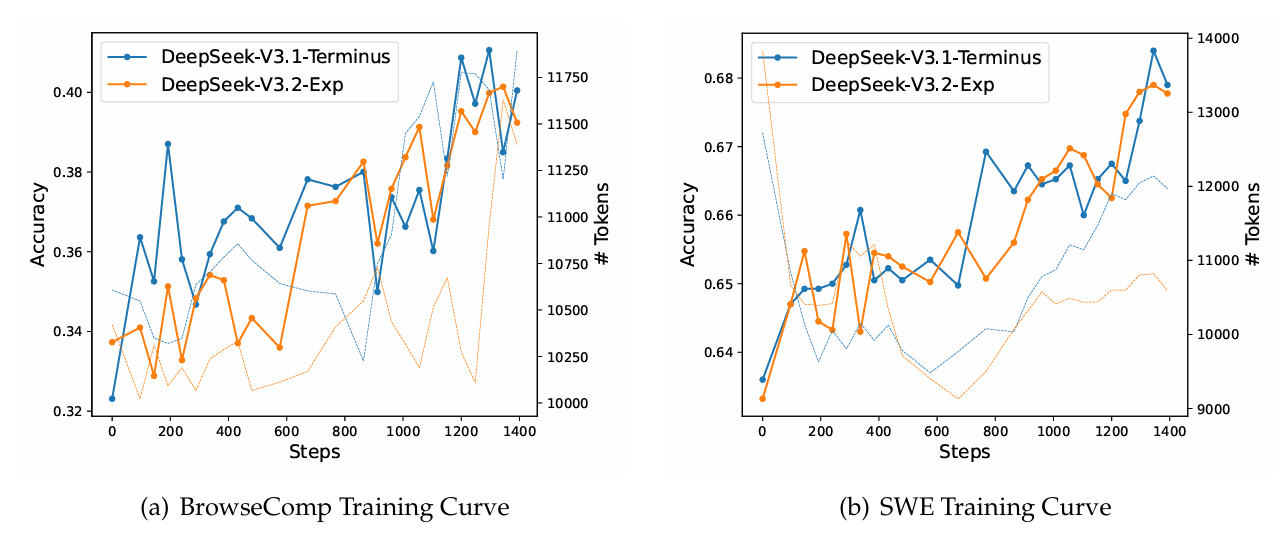
下图进一步展示了两个模型在不同数据集上,强化学习的波动曲线,发现两者走势也基本变化不大,说明了 DSA 具备一定稳定性。
最后,比较了两个模型的计算成本,发现随着上下文长度的增加,DeepSeek-V3.2 能够显著降低计算成本。
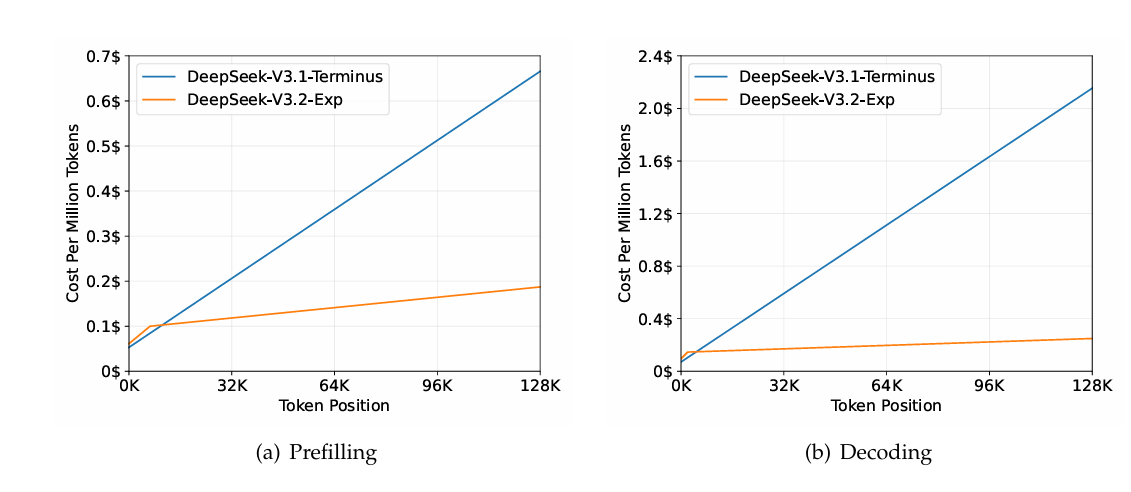
因此,DeepSeek 对 DeepSeek-V3.2 这个模型的 API 价格进行大幅降价,进一步击穿大模型的价格下限,对于一直在调用 DeepSeek 服务的开发者而言,可以开始换了。

5. 总结
一句话总结这项工作:DeepSeek-V3.2 通过 DSA,在不影响性能的情况下,大幅下降推理成本。
目前,DeepSeek 已将模型开源到 HuggingFace 和 ModelScope 上面,模型参数量是 685B,包含两个版本:
- DeepSeek-V3.2-Exp-Base:基础版本,指的是后训练之前的版本。
- DeepSeek-V3.2-Exp:最终完成的版本,Exp表示Experimental,实验性质,后续可能会有其它版本标识
此外,DeepSeek 还进一步 开源了 TileLang 和 CUDA 算子,对于推理加速的研究者来说,也是一个好消息。