ollama离线部署加载Bge-M3向量模型
Ollama部署
ollama是一个开源工具(ollama.ai),允许用户在 本地设备(无需联网)运行 LLM。终端用户通过ollama低成本体验大模型能力
支持模型:
- llama2(7B/13B/70B 参数)
- mistral(7B 高效模型)
- codellama(代码生成专用)
- phi(微软轻量模型)
典型使用场景:
- 离线环境使用 LLM
- 数据敏感场景(避免云端传输)
- 开发者快速测试模型
Github下载
https://github.com/ollama/ollama/releases/tag/v0.11.6
根据所需环境下载,本文在linux下采用二进制文件直接部署,因此下载ollama-linux-amd64.tgz版本,解压后直接可运行;
# 官方提供的安装脚本 # curl -fsSL https://ollama.com/install.sh | sh #下载后解压 tar -zxvf ollama-linux-amd64.tgz #移动并重命名 mv ollama-linux-amd64 ollama
https://github.com/ollama/ollama/blob/main/docs/linux.md
启动Ollama服务
进入ollama本地bin目录下,通过命令ollama serve启动服务后。
设置ollama服务api其它主机可访问,默认为localhost只能本机访问api,设置OLLAMA_HOST环境变量:export OLLAMA_HOST=0.0.0.0,此为临时性环境变量配置(生产使用需配置到系统文件中)
执行结果
[root@centos72 bin]# export OLLAMA_HOST=0.0.0.0
[root@centos72 bin]# ./ollama serve
time=2025-08-25T20:11:28.551+08:00 level=INFO source=routes.go:1318 msg="server config" env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_CONTEXT_LENGTH:4096 OLLAMA_DEBUG:INFO OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NEW_ENGINE:false OLLAMA_NEW_ESTIMATES:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://* vscode-file://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2025-08-25T20:11:28.551+08:00 level=INFO source=images.go:477 msg="total blobs: 0"
time=2025-08-25T20:11:28.552+08:00 level=INFO source=images.go:484 msg="total unused blobs removed: 0"
time=2025-08-25T20:11:28.552+08:00 level=INFO source=routes.go:1371 msg="Listening on [::]:11434 (version 0.11.6)"
time=2025-08-25T20:11:28.552+08:00 level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2025-08-25T20:11:28.561+08:00 level=INFO source=gpu.go:379 msg="no compatible GPUs were discovered"
time=2025-08-25T20:11:28.561+08:00 level=INFO source=types.go:130 msg="inference compute" id=0 library=cpu variant="" compute="" driver=0.0 name="" total="15.5 GiB" available="13.4 GiB"
time=2025-08-25T20:11:28.561+08:00 level=INFO source=routes.go:1412 msg="entering low vram mode" "total vram"="15.5 GiB" threshold="20.0 GiB"
[GIN] 2025/08/25 - 20:12:36 | 200 | 311.063µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/08/25 - 20:12:36 | 200 | 581.712µs | 127.0.0.1 | GET "/api/tags"
[GIN] 2025/08/25 - 20:15:56 | 200 | 67.59µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/08/25 - 20:16:10 | 201 | 7.175086744s | 127.0.0.1 | POST "/api/blobs/sha256:9465e63a22add5354d9bb4b99e90117043c7124007664907259bd16d043bb031"
[GIN] 2025/08/25 - 20:16:10 | 200 | 473.445126ms | 127.0.0.1 | POST "/api/create"
[GIN] 2025/08/25 - 20:16:25 | 200 | 49.783µs | 127.0.0.1 | HEAD "/"
[GIN] 2025/08/25 - 20:16:25 | 200 | 778.794µs | 127.0.0.1 | GET "/api/tags"
...其它命令
#另起一个ssh窗口查看ollama版本
./ollama -v
#查看命令帮助
./ollama -h 或 ./ollama --help
#下载ollama平台模型(本地不存在,则会自动远程拉取)
ollama run MODEL_NAME
#查已下载的模型
./ollama list
#查看正在运行的模型
./ollama ps
#通过模型描述文件创建模型(注意文件绝对路径)
./ollama create MODEL_NAME -f Modelfile
#删除模型
./ollama rm MODEL_NAME集成BGE-M3向量模型
BGE-M3是由北京智源人工智能研究院(BAAI)开发并开源的一款多功能、多语言、多粒度的文本嵌入模型。
“M3”特性:代表 Multi-Functionality,即它能同时输出密集向量、稀疏向量(关键词权重) 和多向量(ColBERT式)。
BGE-M3核心特点:以多功能、多语言和多粒度的多功能性而著称。
多功能性:它可以同时执行嵌入模型的三种常见检索功能:密集检索、多向量检索和稀疏检索。
- 密集检索 (Dense Retrieval):通过计算向量之间的相似度(如余弦相似度)来找到相关文本。BGE-M3 生成的向量质量极高,在此项上达到了业界顶尖水平。
- 稀疏检索 (Sparse Retrieval):这类似于传统搜索引擎,能更好地捕获关键词匹配信号,对术语精确匹配的场景非常有效。
- 多向量检索 (Multi-Vector Retrieval):模型会对查询和文档生成一组向量(而不仅仅是一个),然后进行精细化的交互和匹配。
多语言性:它可以支持超过100种工作语言。
- 它不仅能够处理中文和英文的检索任务。
- 还能很好地支持其他语言(如法语、德语、阿拉伯语等)之间的跨语言检索。例如,可以用中文问题检索出相关的英文文档。
多粒度性:它能够处理不同粒度的输入,从短句到长达8192个token的长文档。
- 短文本:如搜索查询、产品标题、问答对。
- 长文档:如技术报告、新闻文章、维基百科页面。
- 这一特性使其非常适合需要对整个段落或文档进行编码的应用场景。
主要应用场景:BGE-M3 的强大能力使其适用于几乎所有需要文本理解和匹配的领域。
- 搜索引擎:提升搜索引擎的相关性,无论是站内搜索还是通用网页搜索。
- 检索增强生成 (RAG):为大语言模型(LLM)从知识库中精准检索相关上下文,是构建高质量 AI 应用的核心组件。
- 语义相似度计算:用于重复问题检测、论文去重、推荐系统等。
- 文本分类与聚类:通过比较嵌入向量,对文本进行自动归类。
- 跨语言搜索:构建支持多语言的搜索平台或内容推荐系统。
下载BGE-M3-GGUF模型
如果不使用Ollama官方平台提供的bge-m3模型,而是从Hugging Face的.bin或.safetensors平台获取的不同用户供献的调优模型,则Ollama并不能直接支持 Hugging Face的.bin或.safetensors格式类型的大模型文件,它需要一种名为 GGUF 的二进制格式。
可以从modelscope平台(一个提供大模型和训练数据集的公共平台)下载Bge-M3-GGUF模型。
模型下载平台地址:https://modelscope.cn/models/gpustack/bge-m3-GGUF/summary
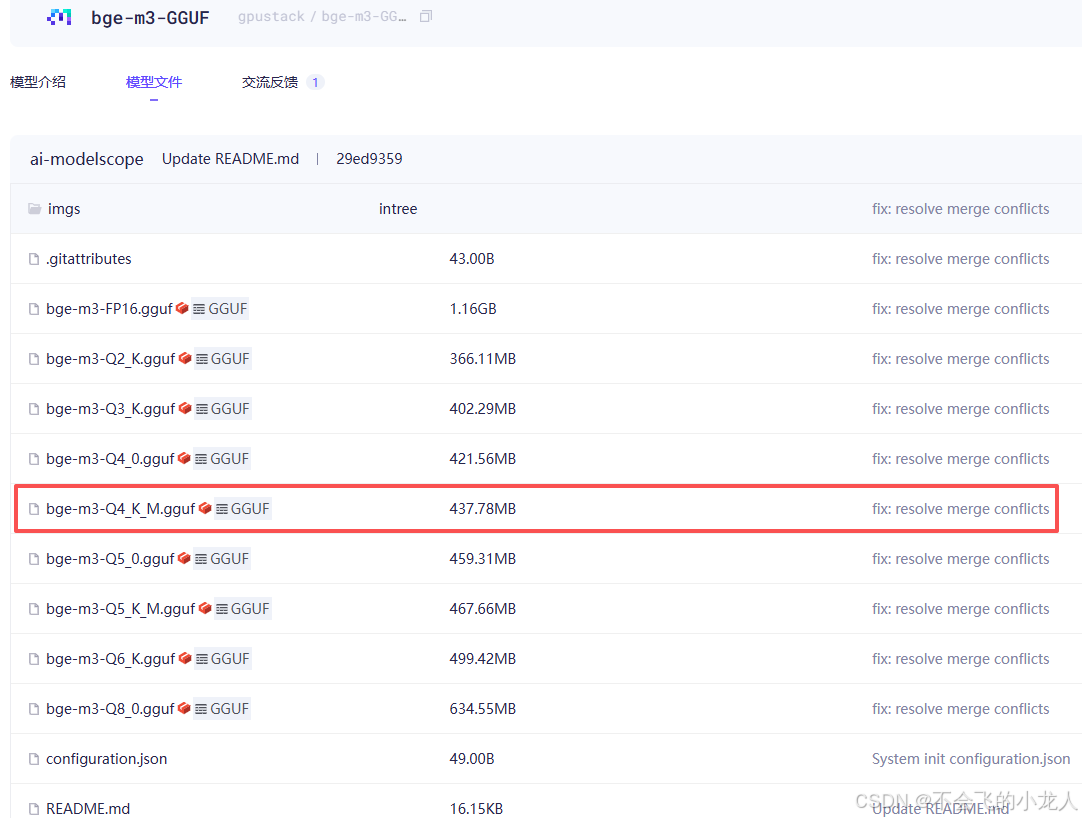
因有多个不同尺寸的模型文件,根据我们硬件条件配置,择优选择一个合适的模型单独下载或全部打包下载,本文选择bge-m3-Q4_K_M.gguf模型,因为Q4_K_M模型是考虑硬件比较差(无GPU),在4-bit量化系例中,它在压缩率、速度、精度损失之间取得最佳平衡(模型差异请自行百度或AI)。
#此处用git命令克隆
git clone https://www.modelscope.cn/gpustack/bge-m3-GGUF.git
#下载单个模型文件
wget -v https://modelscope.cn/models/gpustack/bge-m3-GGUF/resolve/master/bge-m3-Q4_K_M.gguf#也可以通过ollama远程拉取模型
ollama pull modelscope.cn/gpustack/bge-m3-GGUF
或直接通过ollama服务下载官方支持的bge-m3版本(ollama提供了各种大模型下载)
ollama pull bge-m3注意:ollama只支持非ollama服务架构运行的Qwen3下GGUF类型格式模型加载,请勿下错,否则需要额化转换成gguf才可以创建导入本地大模型
还需要注意的是在Ollama中运行Bge-M3-GGUF版本,此版本会存在一定的限制:GGUF版本目前仅支持密集检索,不支持原版的稀疏检索和多向量检索。
如果你的应用需要原版完整的 M3 功能(特别是高效的稀疏检索),应该使用 Hugging Face 的 sentence-transformers 或 FlagEmbedding 库,而不是 Ollama。
下载后,将Bge-M3-GGUF解压(如有压缩),并移动到合适目录。
创建Modelfile导入文件
进入到Bge-M3-GGUF目录下,创建一个名为Modelfile文件(无后缀名),此文件内容为导入GGUF格式模型到ollama的服务下配置。
#创建Modelfile文件,无后缀
touch Modelfile
#编辑模型配置
vim ModelfileModelfile配置
# Modelfile-bge
FROM ./bge-m3-Q4_K_M.gguf# 基本参数
# 使用的 CPU 线程数量
PARAMETER num_thread 4
# 尝试将模型指定数量的层加载到 GPU,为0则使用CPU加载所有层
PARAMETER num_gpu 99
# 单次处理的最大令牌(Token)数量
PARAMETER num_ctx 512
# 设置温度阈值(嵌入模型通常无需配置,默认0.0)
PARAMETER temperature 0.0
# 累计阈值(核)来限制采样范围,取值0.0到1.0(嵌入模型通常无需配置,默认0.0)
PARAMETER top_p 0.0# 系统提示
SYSTEM "BGE-M3 text embedding model. Generate embeddings for input text."Ollama导入本地GGUF模型
加载Modelfile配置执行创建本地模型服务,通过ollama命令执行:
ollama create MODEL_NAME -f ./Modelfile
[root@centos72 bin]# ./ollama create bge-m3-q4 -f /data/models/bge-m3-GGUF/Modelfile
gathering model components
copying file sha256:6d34681b26c61479ac1f82db35a04a05004e94c415b51c858ff571449a82fa06 100%
parsing GGUF
using existing layer sha256:1d39681b26c61279ae1f82db35a04a05009e94c415b51c857ff571489a82fc06
creating new layer sha256:3e28ab127fc5ff42b11dae5471b544f4e8eb27694137d911b250f03e3c4b7aa7
creating new layer sha256:e7ba2910c90fc3679f5fd400b0a451780bb5b6c2d720fc498a9f88d553364c06
writing manifest
success BGE-M3模型测试
BGE-M3 是一个 嵌入模型 (Embedding Model),而不是一个 生成模型 (Generative Model)
- 嵌入模型 (如 BGE-M3):不生成文本,而是“理解”文本并将其转换为一个数值向量(一串数字),这个向量代表了文本的语义。这个过程叫做“编码(Encoding)”。
- 不能用 ollama run 来交互式地使用它。必须通过 Ollama 的 API 来调用其 嵌入(Embedding) 功能。
- Ollama 提供了一个专门的 /api/embed 端点来处理嵌入请求。在编程中调用该 API,用于构建语义搜索、文本聚类、RAG等应用。
Ollama支持WEB服务API,可通过HTTP接口调用,如:http://localhost或ip:11434(默认端口)/api/端点
Ollama API端点示例
curl http://192.168.1.3:11434/api/embed -d '{"model": "bge-m3-q4","input": "人工智能技术发展迅速"
}'得到的结果,将是一串很长的数字
{"model":"bge-m3-q4","embeddings": [[-0.078855306,0.051303077,-0.019368684,-0.020158399... // 很长很长的一串数字(通常是1024维或更多)]]
}参考:
https://ollama.com/library/bge-m3
https://github.com/ollama/ollama/blob/main/docs/api.md#generate-embeddings
https://modelscope.cn/
以及deepseek或qwen3提问整理