【完整源码+数据集+部署教程】无人机场景城市环境图像分割系统: yolov8-seg-timm
背景意义
研究背景与意义
随着城市化进程的加速,城市环境的复杂性和多样性日益增加,这对无人机在城市环境中的应用提出了更高的要求。无人机作为一种新兴的技术手段,因其灵活性和高效性,广泛应用于城市监测、交通管理、环境保护等领域。然而,传统的图像处理技术在面对复杂的城市环境时,往往难以满足实时性和准确性的双重需求。因此,基于深度学习的图像分割技术逐渐成为研究的热点,其中YOLO(You Only Look Once)系列模型因其高效的目标检测能力而备受关注。
YOLOv8作为YOLO系列的最新版本,进一步提升了目标检测的精度和速度,但在特定的应用场景中,仍存在一定的局限性。特别是在城市环境中,建筑物、车辆、树木和电线等多种目标的复杂交互,使得图像分割任务变得更加困难。因此,针对这一问题,改进YOLOv8以适应无人机场景的城市环境图像分割显得尤为重要。
本研究旨在构建一个基于改进YOLOv8的无人机场景城市环境图像分割系统。该系统将利用2400张图像的数据集,涵盖建筑物、车辆、树木和电线四个类别。这些类别不仅是城市环境中常见的元素,也是影响城市管理和监测的重要因素。通过对这些目标的精确分割,能够为城市规划、交通流量分析和环境监测提供更为详实的数据支持。
在技术层面,本研究将通过对YOLOv8模型的改进,优化其在城市环境中图像分割的性能。具体而言,将结合深度学习中的最新技术,如特征金字塔网络(FPN)、注意力机制等,提升模型对复杂背景和目标遮挡的鲁棒性。此外,针对数据集中的多样性和复杂性,将采用数据增强技术,提升模型的泛化能力,确保其在不同城市环境下的适用性。
本研究的意义不仅在于技术层面的创新,更在于其对城市管理和环境保护的实际应用价值。通过高效的图像分割系统,无人机能够实时获取城市环境的变化信息,帮助决策者及时调整城市规划和管理策略。同时,该系统还可以为环境监测提供重要的数据支持,助力可持续发展目标的实现。
综上所述,基于改进YOLOv8的无人机场景城市环境图像分割系统的研究,不仅填补了现有技术在城市环境应用中的空白,也为未来无人机技术的发展提供了新的思路和方向。通过这一研究,我们期待能够推动无人机在城市管理、交通监测和环境保护等领域的广泛应用,为智慧城市的建设贡献力量。
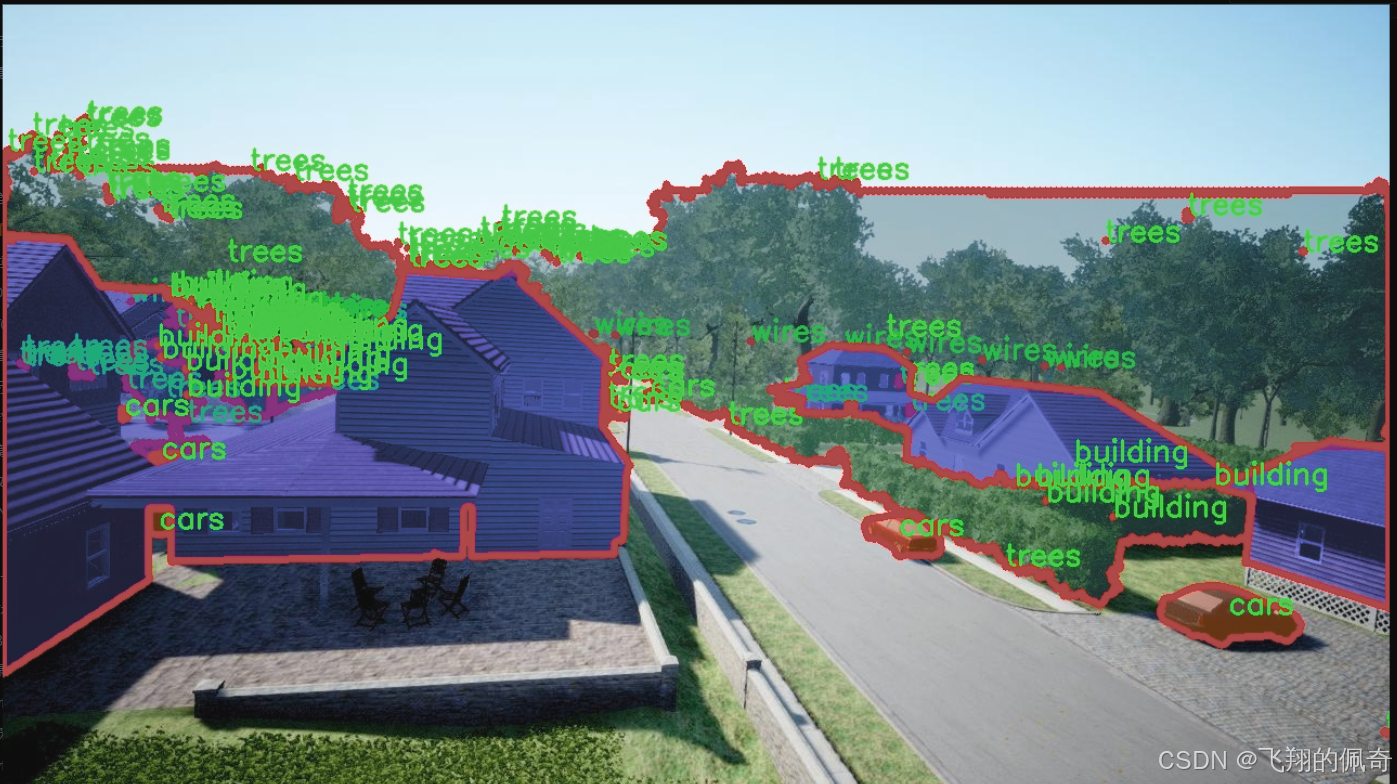
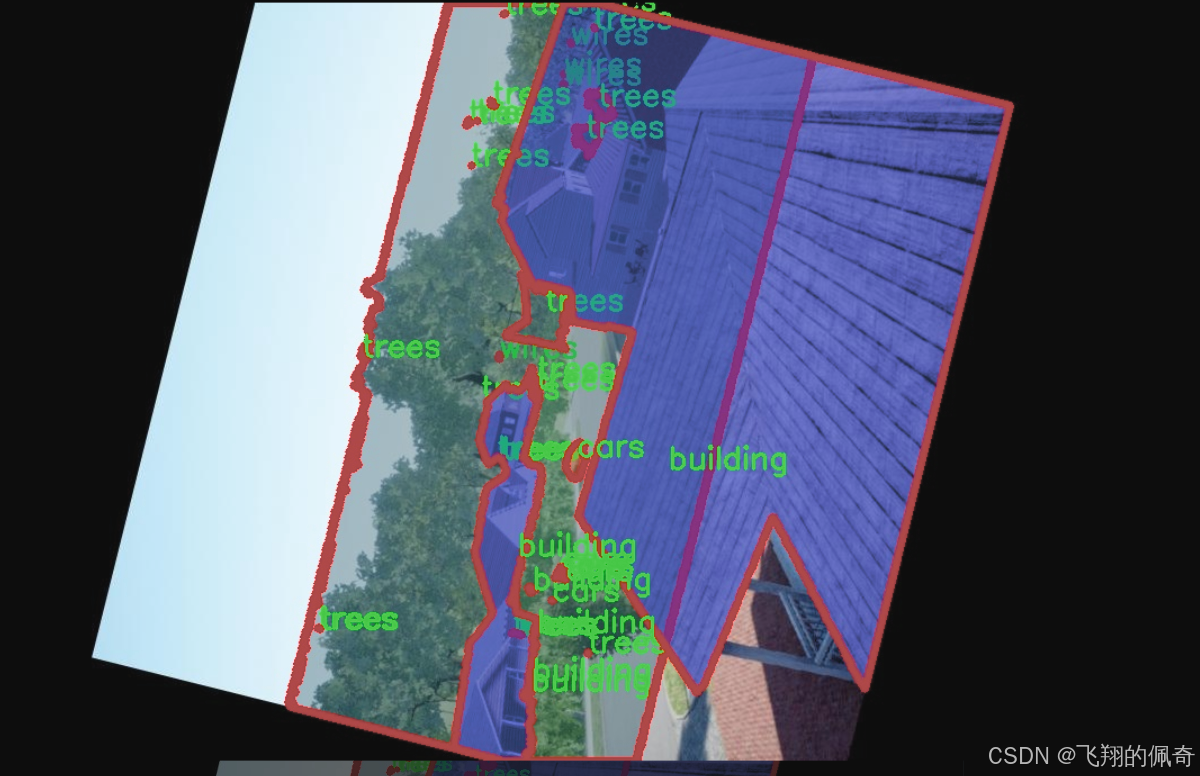
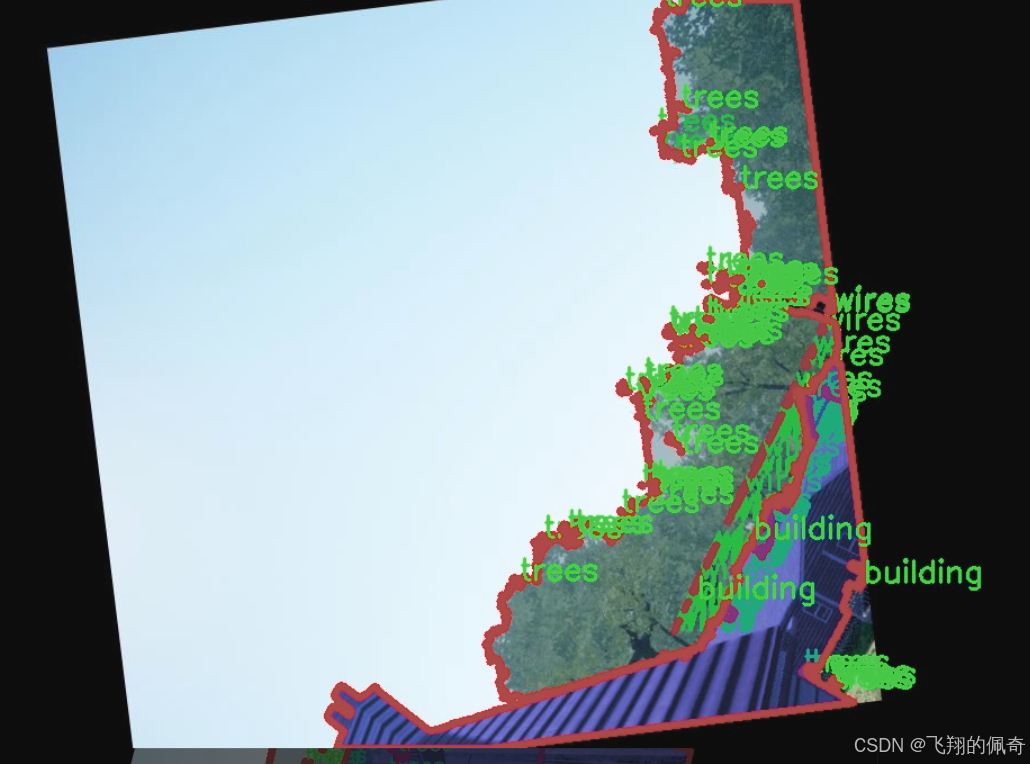
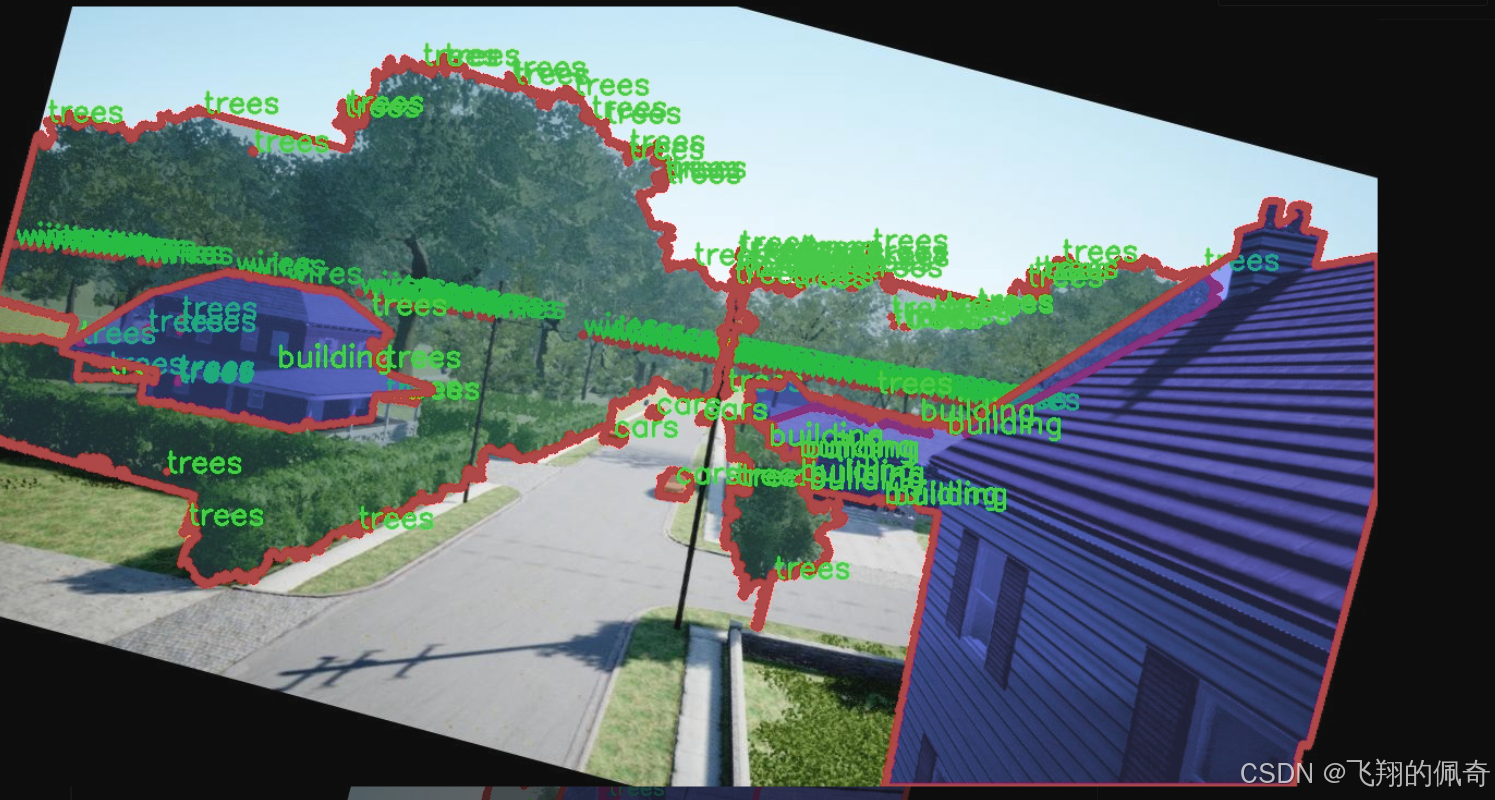
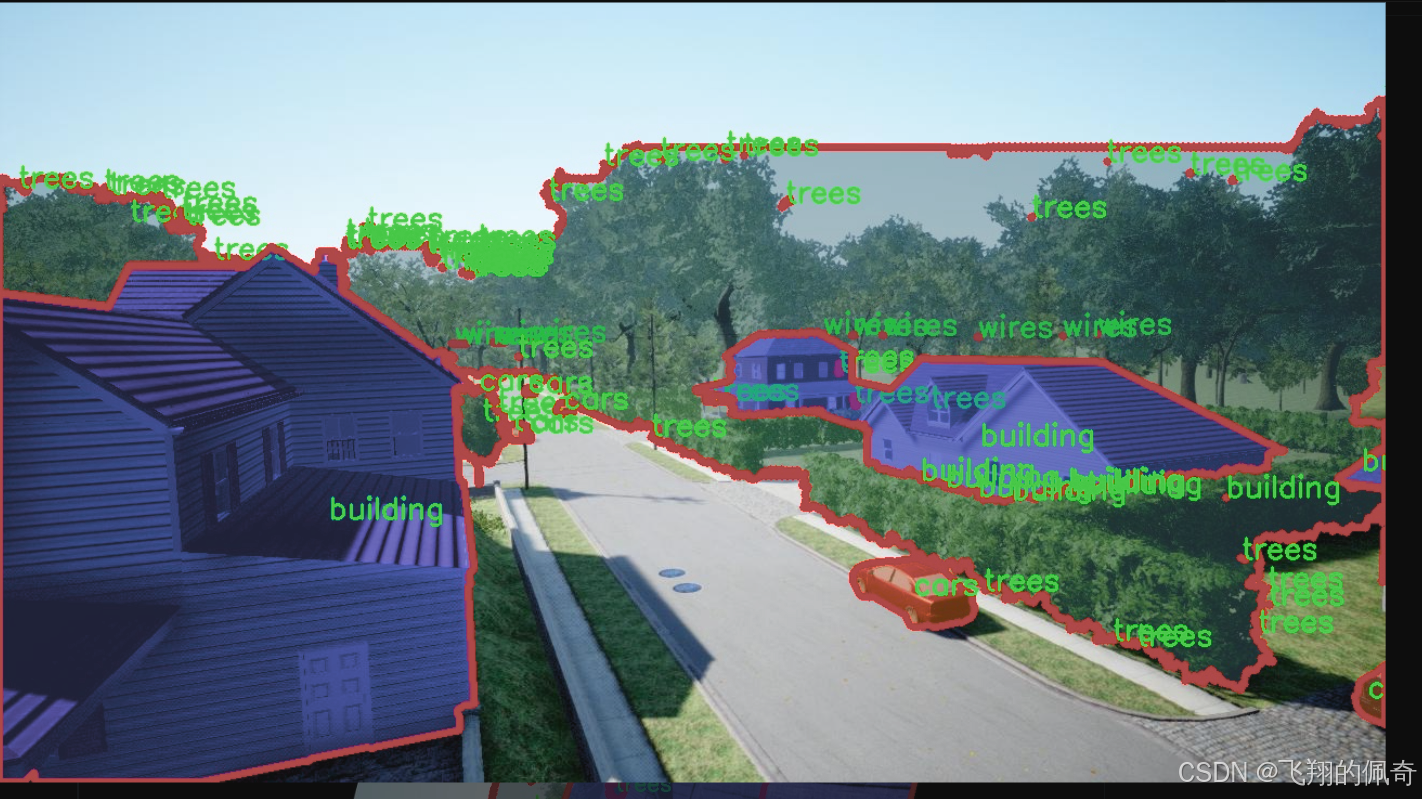
图片效果
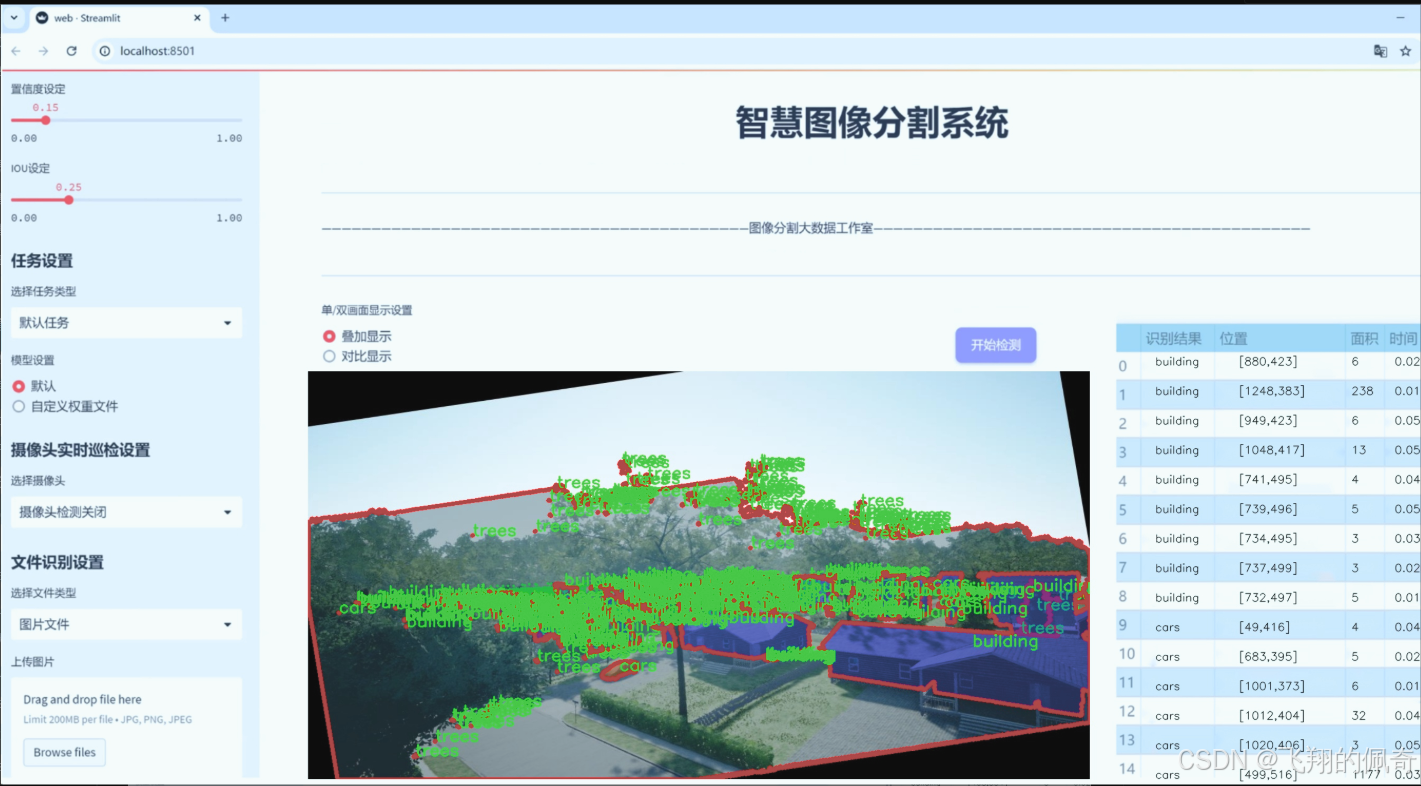
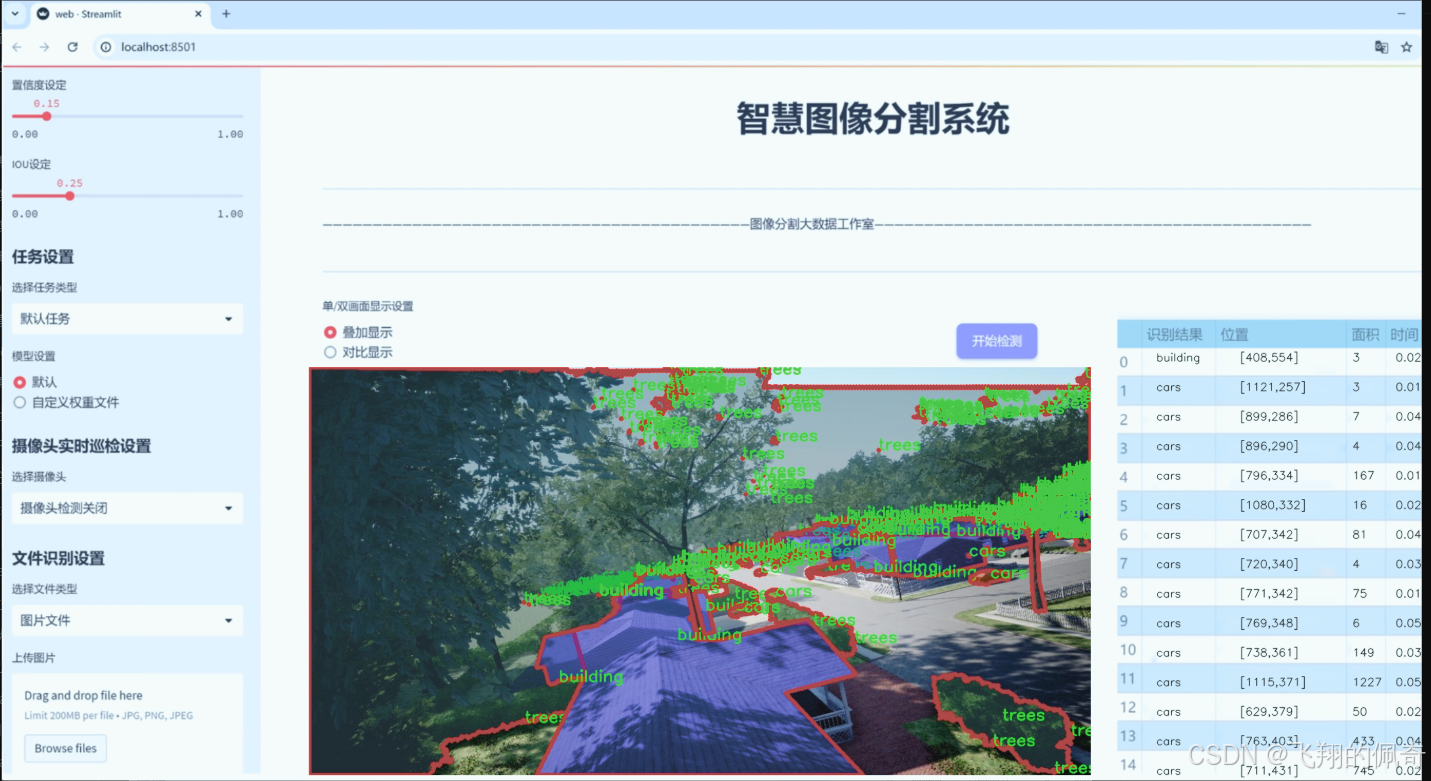
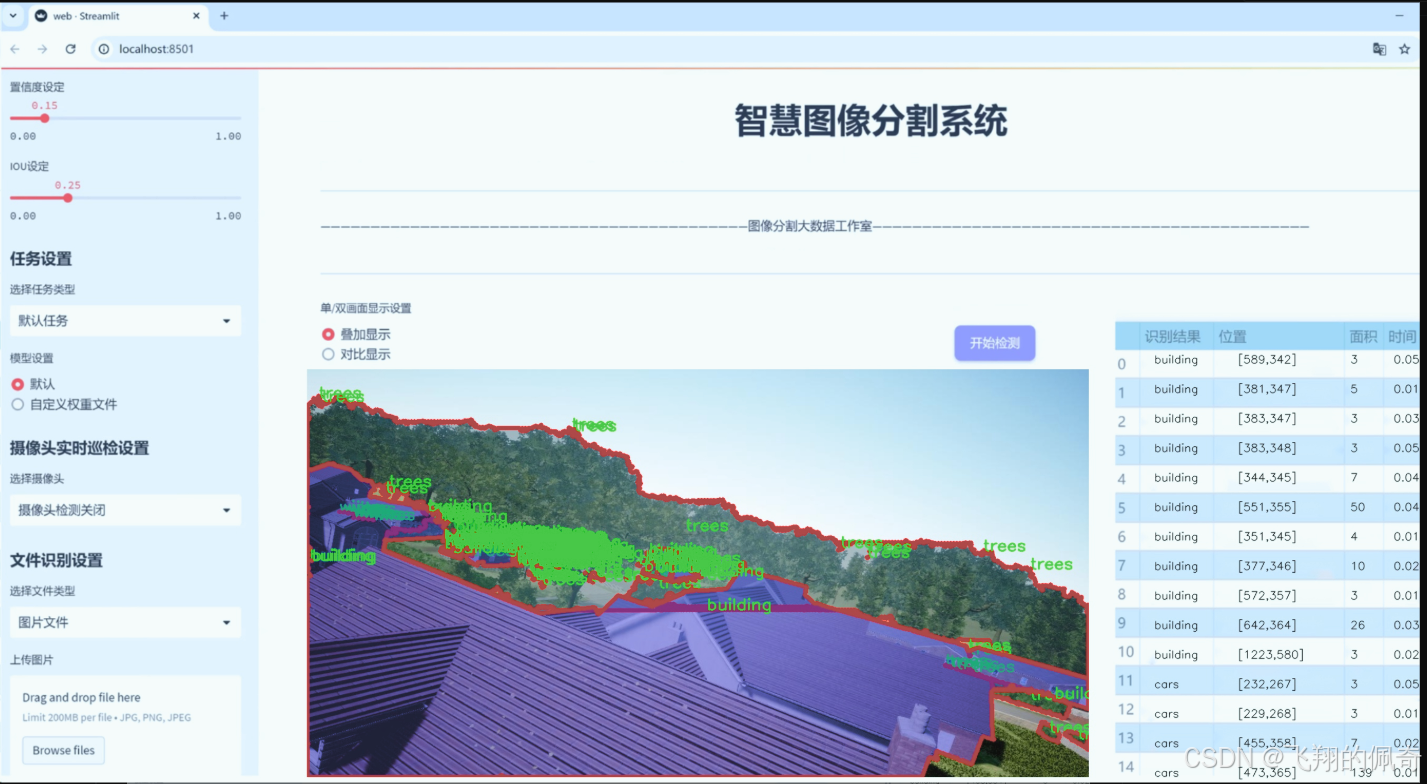
数据集信息
数据集信息展示
在现代城市环境中,无人机的应用日益广泛,尤其是在图像分割任务中,准确识别和分离不同物体的能力至关重要。为此,我们构建了一个名为“DDOS-YOLO”的数据集,旨在为改进YOLOv8-seg的无人机场景图像分割系统提供高质量的训练数据。该数据集专注于城市环境中的特定物体,包含四个主要类别:建筑物、汽车、树木和电线。这些类别的选择不仅反映了城市环境的典型特征,也为无人机在执行任务时提供了必要的上下文信息。
“DDOS-YOLO”数据集的设计考虑到了城市环境的复杂性和多样性。建筑物作为城市的主要构成部分,其形状、颜色和高度各异,能够在图像中形成显著的视觉特征。数据集中包含的建筑物图像涵盖了不同风格和年代的建筑,从现代摩天大楼到传统的低层建筑,确保了模型在各种建筑类型上的适应性和准确性。
汽车是城市交通的重要组成部分,数据集中包括了多种类型的汽车,从小型轿车到大型货车,甚至是公共交通工具。这种多样性使得模型能够学习到不同汽车在不同场景下的特征,从而提高其在动态城市环境中的检测能力。此外,汽车的颜色和形状变化也为图像分割提供了丰富的样本,增强了模型的泛化能力。
树木作为城市绿化的重要元素,其在图像中的表现同样多样。数据集中收录了不同种类和形态的树木,包括高大的乔木和矮小的灌木。这些树木不仅在视觉上提供了丰富的背景信息,也在无人机的飞行路径规划和障碍物检测中起到了关键作用。通过对树木的准确分割,模型能够更好地理解环境,避免潜在的碰撞风险。
电线是城市环境中常见但容易被忽视的元素,尤其是在无人机飞行时,电线的存在可能会对飞行安全造成威胁。因此,在“DDOS-YOLO”数据集中,电线的图像样本被精心挑选,以确保模型能够准确识别并避开这些潜在的障碍。电线的多样性和复杂性为图像分割任务增加了挑战,但同时也提升了模型的实用性。
总的来说,“DDOS-YOLO”数据集通过涵盖建筑物、汽车、树木和电线四个类别,为改进YOLOv8-seg的无人机场景图像分割系统提供了丰富的训练素材。该数据集不仅关注物体的视觉特征,还考虑了它们在城市环境中的实际应用场景,旨在提升无人机在复杂城市环境中的智能识别和分割能力。通过对这些类别的深入学习,模型将能够在实际应用中更好地执行任务,确保无人机在城市环境中的安全与效率。
核心代码
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules.conv import Conv
class BasicBlock(nn.Module):
“”“基本块,包含两个卷积层和残差连接”“”
def init(self, filter_in, filter_out):
super(BasicBlock, self).init()
# 第一个卷积层,使用3x3卷积
self.conv1 = Conv(filter_in, filter_out, 3)
# 第二个卷积层,使用3x3卷积,不使用激活函数
self.conv2 = Conv(filter_out, filter_out, 3, act=False)
def forward(self, x):residual = x # 保存输入以便进行残差连接out = self.conv1(x) # 通过第一个卷积层out = self.conv2(out) # 通过第二个卷积层out += residual # 添加残差return self.conv1.act(out) # 通过激活函数并返回
class Upsample(nn.Module):
“”“上采样模块,使用1x1卷积和双线性插值”“”
def init(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).init()
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1), # 1x1卷积
nn.Upsample(scale_factor=scale_factor, mode=‘bilinear’) # 双线性插值上采样
)
def forward(self, x):return self.upsample(x) # 执行上采样
class Downsample_x2(nn.Module):
“”“下采样模块,使用2x2卷积”“”
def init(self, in_channels, out_channels):
super(Downsample_x2, self).init()
self.downsample = Conv(in_channels, out_channels, 2, 2, 0) # 2x2卷积
def forward(self, x):return self.downsample(x) # 执行下采样
class ASFF_2(nn.Module):
“”“自适应特征融合模块,处理两个输入特征图”“”
def init(self, inter_dim=512):
super(ASFF_2, self).init()
self.inter_dim = inter_dim
compress_c = 8 # 压缩通道数
# 为每个输入特征图创建权重卷积self.weight_level_1 = Conv(self.inter_dim, compress_c, 1)self.weight_level_2 = Conv(self.inter_dim, compress_c, 1)self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1) # 计算融合权重self.conv = Conv(self.inter_dim, self.inter_dim, 3) # 融合后的卷积def forward(self, input1, input2):# 计算每个输入的权重level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)# 合并权重并计算最终权重levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1) # 归一化权重# 融合输入特征图fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced) # 通过卷积层return out # 返回融合后的特征图
class BlockBody_P345(nn.Module):
“”“特征块体,处理三个不同尺度的特征图”“”
def init(self, channels=[64, 128, 256, 512]):
super(BlockBody_P345, self).init()
# 定义不同尺度的卷积块self.blocks_scalezero1 = nn.Sequential(Conv(channels[0], channels[0], 1))self.blocks_scaleone1 = nn.Sequential(Conv(channels[1], channels[1], 1))self.blocks_scaletwo1 = nn.Sequential(Conv(channels[2], channels[2], 1))# 定义下采样和上采样模块self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)# 定义自适应特征融合模块self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])self.asff_scaleone1 = ASFF_2(inter_dim=channels[1])# 定义后续的卷积块self.blocks_scalezero2 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone2 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)def forward(self, x):x0, x1, x2 = x # 输入特征图# 处理每个尺度的特征图x0 = self.blocks_scalezero1(x0)x1 = self.blocks_scaleone1(x1)x2 = self.blocks_scaletwo1(x2)# 进行自适应特征融合scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))scaleone = self.asff_scaleone1(self.downsample_scalezero1_2(x0), x1)# 通过后续卷积块处理融合后的特征图x0 = self.blocks_scalezero2(scalezero)x1 = self.blocks_scaleone2(scaleone)return x0, x1 # 返回处理后的特征图
class AFPN_P345(nn.Module):
“”“自适应特征金字塔网络,处理三个输入特征图”“”
def init(self, in_channels=[256, 512, 1024], out_channels=256, factor=4):
super(AFPN_P345, self).init()
# 定义输入特征图的卷积层self.conv0 = Conv(in_channels[0], in_channels[0] // factor, 1)self.conv1 = Conv(in_channels[1], in_channels[1] // factor, 1)self.conv2 = Conv(in_channels[2], in_channels[2] // factor, 1)# 定义特征块体self.body = BlockBody_P345([in_channels[0] // factor, in_channels[1] // factor, in_channels[2] // factor])# 定义输出特征图的卷积层self.conv00 = Conv(in_channels[0] // factor, out_channels, 1)self.conv11 = Conv(in_channels[1] // factor, out_channels, 1)self.conv22 = Conv(in_channels[2] // factor, out_channels, 1)def forward(self, x):x0, x1, x2 = x # 输入特征图# 通过卷积层处理输入特征图x0 = self.conv0(x0)x1 = self.conv1(x1)x2 = self.conv2(x2)# 通过特征块体处理特征图out0, out1, out2 = self.body([x0, x1, x2])# 通过输出卷积层处理特征图out0 = self.conv00(out0)out1 = self.conv11(out1)out2 = self.conv22(out2)return [out0, out1, out2] # 返回输出特征图
代码说明:
BasicBlock: 定义了一个基本的卷积块,包含两个卷积层和残差连接。
Upsample 和 Downsample: 定义了上采样和下采样模块,分别用于特征图的尺寸调整。
ASFF_2: 自适应特征融合模块,能够融合两个输入特征图,输出融合后的特征图。
BlockBody_P345: 处理三个不同尺度的特征图,包含卷积块和自适应特征融合模块。
AFPN_P345: 自适应特征金字塔网络,处理三个输入特征图并输出融合后的特征图。
这些模块共同构成了一个特征提取和融合的深度学习模型,适用于图像处理任务。
这个程序文件实现了一个名为“AFPN”的模块,主要用于深度学习中的特征金字塔网络(FPN)结构。文件中定义了多个类,每个类代表网络中的不同组件,使用了PyTorch框架来构建神经网络。
首先,文件引入了一些必要的库,包括OrderedDict、torch、torch.nn和torch.nn.functional,并从其他模块导入了一些自定义的卷积和块结构。
接下来,定义了多个类,其中BasicBlock类实现了一个基本的残差块,包含两个卷积层和残差连接。Upsample和Downsample_x2/x4/x8类分别实现了上采样和不同倍数的下采样操作。这些操作在特征金字塔网络中非常重要,因为它们帮助网络在不同的尺度上处理特征。
ASFF_2/3/4类实现了自适应特征融合模块(ASFF),用于在不同层次的特征之间进行加权融合。每个ASFF模块根据输入特征计算权重,并通过加权和的方式融合不同层次的特征。
BlockBody_P345和BlockBody_P2345类则是特征金字塔网络的主体部分,包含多个卷积块和ASFF模块,负责处理不同尺度的特征。它们通过上下采样和特征融合,逐步构建出最终的特征表示。
AFPN_P345和AFPN_P2345类是整个网络的主要入口,负责接收输入特征并通过一系列卷积和块体处理,最终输出经过处理的特征。这些类还包括初始化权重的代码,以确保网络在训练开始时具有良好的性能。
最后,AFPN_P345_Custom和AFPN_P2345_Custom类允许用户自定义块类型,以便在特定任务中使用不同的网络结构。
整体来看,这个文件实现了一个灵活且可扩展的特征金字塔网络结构,适用于多种计算机视觉任务,如目标检测和图像分割。通过不同的块类型和参数设置,用户可以根据具体需求调整网络的架构。
11.3 ui.py
import sys
import subprocess
def run_script(script_path):
“”"
使用当前 Python 环境运行指定的脚本。
Args:script_path (str): 要运行的脚本路径Returns:None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable# 构建运行命令,使用 streamlit 运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'# 执行命令
result = subprocess.run(command, shell=True)
# 检查命令执行结果,如果返回码不为0,表示出错
if result.returncode != 0:print("脚本运行出错。")
实例化并运行应用
if name == “main”:
# 指定要运行的脚本路径
script_path = “web.py” # 这里可以直接指定脚本路径
# 运行脚本
run_script(script_path)
代码注释说明:
导入模块:
sys:用于访问与 Python 解释器紧密相关的变量和函数。
subprocess:用于执行外部命令和程序。
run_script 函数:
该函数接收一个脚本路径作为参数,并使用当前 Python 环境运行该脚本。
使用 sys.executable 获取当前 Python 解释器的路径,以确保使用正确的 Python 环境。
构建一个命令字符串,使用 streamlit 模块运行指定的脚本。
使用 subprocess.run 执行命令,并检查返回码以判断脚本是否成功运行。
主程序块:
通过 if name == “main”: 确保该代码块仅在直接运行脚本时执行。
指定要运行的脚本路径(这里直接指定为 “web.py”)。
调用 run_script 函数来执行指定的脚本。
这个程序文件的主要功能是通过当前的 Python 环境来运行一个指定的脚本,具体是一个名为 web.py 的文件。程序首先导入了必要的模块,包括 sys、os 和 subprocess,以及一个自定义的路径处理函数 abs_path。
在 run_script 函数中,程序接受一个参数 script_path,这是要运行的脚本的路径。函数内部首先获取当前 Python 解释器的路径,这样可以确保在正确的环境中运行脚本。接着,程序构建了一个命令字符串,该命令使用 streamlit 来运行指定的脚本。streamlit 是一个用于构建数据应用的流行库。
使用 subprocess.run 方法,程序执行构建好的命令,并通过 shell=True 参数允许在 shell 中执行该命令。执行后,程序检查返回码,如果返回码不为零,表示脚本运行出错,则打印出相应的错误信息。
在文件的最后部分,程序通过 if name == “main”: 语句来确保只有在直接运行该文件时才会执行后面的代码。在这里,程序调用 abs_path 函数来获取 web.py 的绝对路径,并将其传递给 run_script 函数以启动脚本的运行。
总的来说,这个程序的设计目的是为了方便地在指定的 Python 环境中运行一个 Streamlit 应用脚本,确保用户能够轻松启动和管理数据应用。
11.4 ultralytics\trackers_init_.py
以下是代码中最核心的部分,并附上详细的中文注释:
导入所需的跟踪器类
from .bot_sort import BOTSORT # 导入BOTSORT类,用于目标跟踪
from .byte_tracker import BYTETracker # 导入BYTETracker类,用于目标跟踪
from .track import register_tracker # 导入注册跟踪器的函数
定义模块的公开接口,允许用户更简单地导入这些类和函数
all = ‘register_tracker’, ‘BOTSORT’, ‘BYTETracker’
注释说明:
导入部分:
from .bot_sort import BOTSORT:从当前模块的 bot_sort 文件中导入 BOTSORT 类,该类可能实现了一种基于SORT(Simple Online and Realtime Tracking)算法的目标跟踪方法。
from .byte_tracker import BYTETracker:从当前模块的 byte_tracker 文件中导入 BYTETracker 类,该类可能实现了一种基于BYTE(ByteTrack)算法的目标跟踪方法。
from .track import register_tracker:从当前模块的 track 文件中导入 register_tracker 函数,该函数可能用于注册不同的跟踪器,以便在系统中使用。
all 定义:
all 是一个特殊变量,用于定义当使用 from module import * 语句时,哪些名称是可以被导入的。在这里,它包含了 register_tracker、BOTSORT 和 BYTETracker,这意味着这些是模块的公共接口,用户可以直接使用这些类和函数。
这个程序文件是一个Python模块的初始化文件,位于ultralytics/trackers目录下。文件的开头有一行注释,表明该模块是Ultralytics YOLO项目的一部分,并且遵循AGPL-3.0许可证。
接下来,文件通过相对导入的方式引入了三个组件:BOTSORT、BYTETracker和register_tracker。这些组件分别来自于同一目录下的bot_sort.py、byte_tracker.py和track.py文件。这种结构使得模块内的功能可以被其他模块或脚本轻松使用。
最后,__all__变量被定义为一个包含字符串的元组,列出了可以通过from module import *语句导入的公共接口。这意味着当其他模块使用这种方式导入时,只会导入register_tracker、BOTSORT和BYTETracker这三个组件,从而避免了不必要的名称冲突和保护内部实现细节。
总体而言,这个初始化文件的主要作用是组织和简化模块的导入,使得使用者能够方便地访问跟踪相关的功能。
11.5 ultralytics\utils\atss.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
def bbox_overlaps(bboxes1, bboxes2, mode=‘iou’, is_aligned=False, eps=1e-6):
“”"计算两个边界框集合之间的重叠程度。
Args:bboxes1 (Tensor): 第一个边界框集合,形状为 (M, 4)。bboxes2 (Tensor): 第二个边界框集合,形状为 (N, 4)。mode (str): 计算模式,可以是 'iou'(交并比),'iof'(前景交集),或 'giou'(广义交并比)。is_aligned (bool): 如果为 True,则 bboxes1 和 bboxes2 的大小必须相等。eps (float): 为了数值稳定性,添加到分母的值。Returns:Tensor: 重叠程度的张量,形状为 (M, N) 或 (M,)。
"""
assert mode in ['iou', 'iof', 'giou'], f'不支持的模式 {mode}'
assert (bboxes1.size(-1) == 4 or bboxes1.size(0) == 0)
assert (bboxes2.size(-1) == 4 or bboxes2.size(0) == 0)# 计算每个边界框的面积
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (bboxes1[..., 3] - bboxes1[..., 1])
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (bboxes2[..., 3] - bboxes2[..., 1])# 计算重叠区域的左上角和右下角坐标
lt = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # 左上角
rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # 右下角# 计算重叠区域的宽和高
wh = (rb - lt).clamp(min=0) # 确保宽高不为负
overlap = wh[..., 0] * wh[..., 1] # 重叠面积# 计算并集
union = area1 + area2 - overlap + eps # 添加 eps 避免除零错误
ious = overlap / union # 计算 IoUreturn ious # 返回 IoU 结果
class ATSSAssigner(nn.Module):
‘’‘自适应训练样本选择分配器’‘’
def init(self, topk=9, num_classes=80):
super(ATSSAssigner, self).init()
self.topk = topk # 每个样本选择的候选框数量
self.num_classes = num_classes # 类别数量
self.bg_idx = num_classes # 背景类别索引
@torch.no_grad()
def forward(self, anc_bboxes, n_level_bboxes, gt_labels, gt_bboxes, mask_gt, pd_bboxes):"""分配目标标签和边界框。Args:anc_bboxes (Tensor): 形状为 (num_total_anchors, 4) 的锚框。n_level_bboxes (List): 每个层级的边界框数量。gt_labels (Tensor): 形状为 (bs, n_max_boxes, 1) 的真实标签。gt_bboxes (Tensor): 形状为 (bs, n_max_boxes, 4) 的真实边界框。mask_gt (Tensor): 形状为 (bs, n_max_boxes, 1) 的掩码。pd_bboxes (Tensor): 形状为 (bs, n_max_boxes, 4) 的预测边界框。Returns:target_labels (Tensor): 形状为 (bs, num_total_anchors) 的目标标签。target_bboxes (Tensor): 形状为 (bs, num_total_anchors, 4) 的目标边界框。target_scores (Tensor): 形状为 (bs, num_total_anchors, num_classes) 的目标分数。fg_mask (Tensor): 形状为 (bs, num_total_anchors) 的前景掩码。"""self.n_anchors = anc_bboxes.size(0) # 锚框数量self.bs = gt_bboxes.size(0) # 批次大小self.n_max_boxes = gt_bboxes.size(1) # 最大边界框数量if self.n_max_boxes == 0: # 如果没有真实边界框device = gt_bboxes.devicereturn (torch.full([self.bs, self.n_anchors], self.bg_idx).to(device),torch.zeros([self.bs, self.n_anchors, 4]).to(device),torch.zeros([self.bs, self.n_anchors, self.num_classes]).to(device),torch.zeros([self.bs, self.n_anchors]).to(device))# 计算重叠和距离overlaps = bbox_overlaps(gt_bboxes.reshape([-1, 4]), anc_bboxes)overlaps = overlaps.reshape([self.bs, -1, self.n_anchors])# 选择候选框# ...(省略选择候选框的详细实现)return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
代码注释说明:
bbox_overlaps 函数用于计算两个边界框集合之间的重叠程度,支持不同的计算模式(IoU、IoF、GIoU)。
ATSSAssigner 类是一个自适应训练样本选择分配器,主要用于将锚框与真实边界框进行匹配,并返回目标标签、边界框和分数。
在 forward 方法中,首先检查是否有真实边界框,然后计算锚框与真实边界框之间的重叠和距离,并进行候选框的选择。
该代码的核心功能是计算边界框之间的重叠和选择合适的锚框,以便在目标检测任务中进行训练。
这个程序文件ultralytics/utils/atss.py主要实现了与目标检测相关的功能,特别是自适应训练样本选择(ATSS)分配器。以下是对代码的详细说明。
首先,文件导入了必要的库,包括torch和torch.nn,这些库是PyTorch深度学习框架的核心部分。接着,定义了一些辅助函数和类,用于生成锚框、计算重叠度、计算距离等。
generate_anchors函数用于根据特征图生成锚框。它接受特征图、特征图的步幅、网格单元大小、网格偏移量等参数。在评估模式下,该函数生成锚点并返回它们的坐标和步幅张量。在训练模式下,它还生成锚框的坐标。锚框可以是基于锚点的(anchor-based)或无锚点的(anchor-free),具体取决于传入的模式参数。
fp16_clamp函数用于对浮点16(FP16)张量进行限制,以防止数值溢出。由于FP16在CPU上没有实现clamp操作,因此在CPU上需要将其转换为FP32进行处理。
bbox_overlaps函数计算两个边界框集合之间的重叠度,支持多种重叠度计算模式,如交并比(IoU)、前景交并比(IoF)和广义交并比(GIoU)。该函数还处理了对齐和非对齐的情况,并通过张量操作高效地计算重叠度。
cast_tensor_type和iou2d_calculator函数分别用于转换张量类型和计算2D边界框之间的重叠度。dist_calculator函数计算所有边界框与真实边界框之间的中心距离。
ATSSAssigner类是实现自适应训练样本选择的核心类。它的构造函数接受两个参数:topk(选择的候选框数量)和num_classes(类别数量)。在forward方法中,首先获取锚框和真实边界框的相关信息,然后计算重叠度和距离。接着,选择候选框并计算阈值,最后生成目标标签、目标边界框和目标分数。
在select_topk_candidates方法中,根据距离选择每个级别的前topk个候选框。thres_calculator方法计算每个真实框的重叠度阈值,并返回候选框的重叠度。get_targets方法根据选择的目标框生成目标标签、目标边界框和目标分数。
整个文件的实现逻辑清晰,充分利用了PyTorch的张量操作,旨在提高目标检测模型的训练效率和准确性。通过自适应选择训练样本,ATSS分配器能够更好地处理不同类别和不同难度的样本,从而提升模型的性能。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是Ultralytics YOLO项目的一部分,主要用于目标检测和计算机视觉任务。程序的整体架构由多个模块组成,每个模块负责特定的功能,以实现高效的模型训练、跟踪、特征提取和结果可视化。以下是各个模块的主要功能:
回调模块(comet.py):与Comet.ml集成,记录和可视化训练过程中的各种指标和结果,帮助用户监控模型性能。
特征金字塔网络模块(afpn.py):实现自适应特征融合和多尺度特征处理,以提高目标检测的准确性。
用户界面模块(ui.py):提供一个简单的接口,用于运行Streamlit应用,方便用户与模型进行交互。
跟踪模块(init.py):组织和导入与目标跟踪相关的功能,简化模块的使用。
自适应训练样本选择模块(atss.py):实现自适应训练样本选择(ATSS)策略,以提高目标检测模型的训练效率和准确性。
文件功能整理表
文件路径 功能描述
ultralytics/utils/callbacks/comet.py 与Comet.ml集成,记录和可视化训练过程中的指标和结果,支持实时监控模型性能。
ultralytics/nn/extra_modules/afpn.py 实现特征金字塔网络(FPN)结构,支持多尺度特征处理和自适应特征融合,提升目标检测准确性。
ui.py 提供用户界面,通过Streamlit运行应用,方便用户与模型进行交互和可视化结果。
ultralytics/trackers/init.py 初始化跟踪模块,组织和导入与目标跟踪相关的功能,简化模块的使用。
ultralytics/utils/atss.py 实现自适应训练样本选择(ATSS)策略,计算锚框重叠度和距离,优化目标检测模型的训练过程。
以上表格整理了每个文件的功能,帮助理解程序的整体架构和各个模块之间的关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻