从语言到向量:自然语言处理中的核心转换技术与实践
引言
在人工智能浪潮席卷全球的今天,自然语言处理(NLP)作为连接人类语言与计算机智能的关键桥梁,始终是学术界与工业界关注的焦点。无论是智能客服的语义理解、机器翻译的精准表达,还是情感分析的用户意图捕捉,其底层逻辑都离不开一个核心命题——如何将离散的人类语言符号转化为计算机可处理的连续向量表示。
本文将从技术演进的视角,系统梳理自然语言处理中语言转换方法的底层逻辑,深入解析传统统计模型的局限性与突破路径,并聚焦词嵌入(Word Embedding)与word2vec模型的核心原理,结合实际训练场景探讨其工程价值。(PPT1:人工智能--深度学习 自然语言处理NLP 封面图)

一、从语言到模型:自然语言处理的第一步转换
人类语言的本质是一套离散的符号系统——汉字、单词、标点构成基本单元,通过语法规则组合成句,传递复杂语义。但对计算机而言,这些符号不过是二进制世界中的“异类”:它无法直接理解“苹果”与“水果”的包含关系,也无法感知“开心”与“高兴”的情感相似性。因此,将人类语言转化为计算机可处理的向量表示,成为自然语言处理所有任务的第一步,也是最基础的挑战。
(PPT2:语言转换方法 01 标题页)

1.1 早期尝试:基于规则的符号映射
早期的自然语言处理依赖人工定义的规则与词典。例如,通过构建同义词词典实现语义替换,或利用语法规则模板解析句子结构。这种方法在小范围、强约束场景(如专业术语翻译)中曾发挥过作用,但其局限性也随需求复杂度提升而暴露:规则的覆盖度难以穷尽,跨领域迁移能力几乎为零,更无法处理语言中的隐含语义(如反讽、比喻)。
1.2 统计语言模型:概率视角下的符号关联
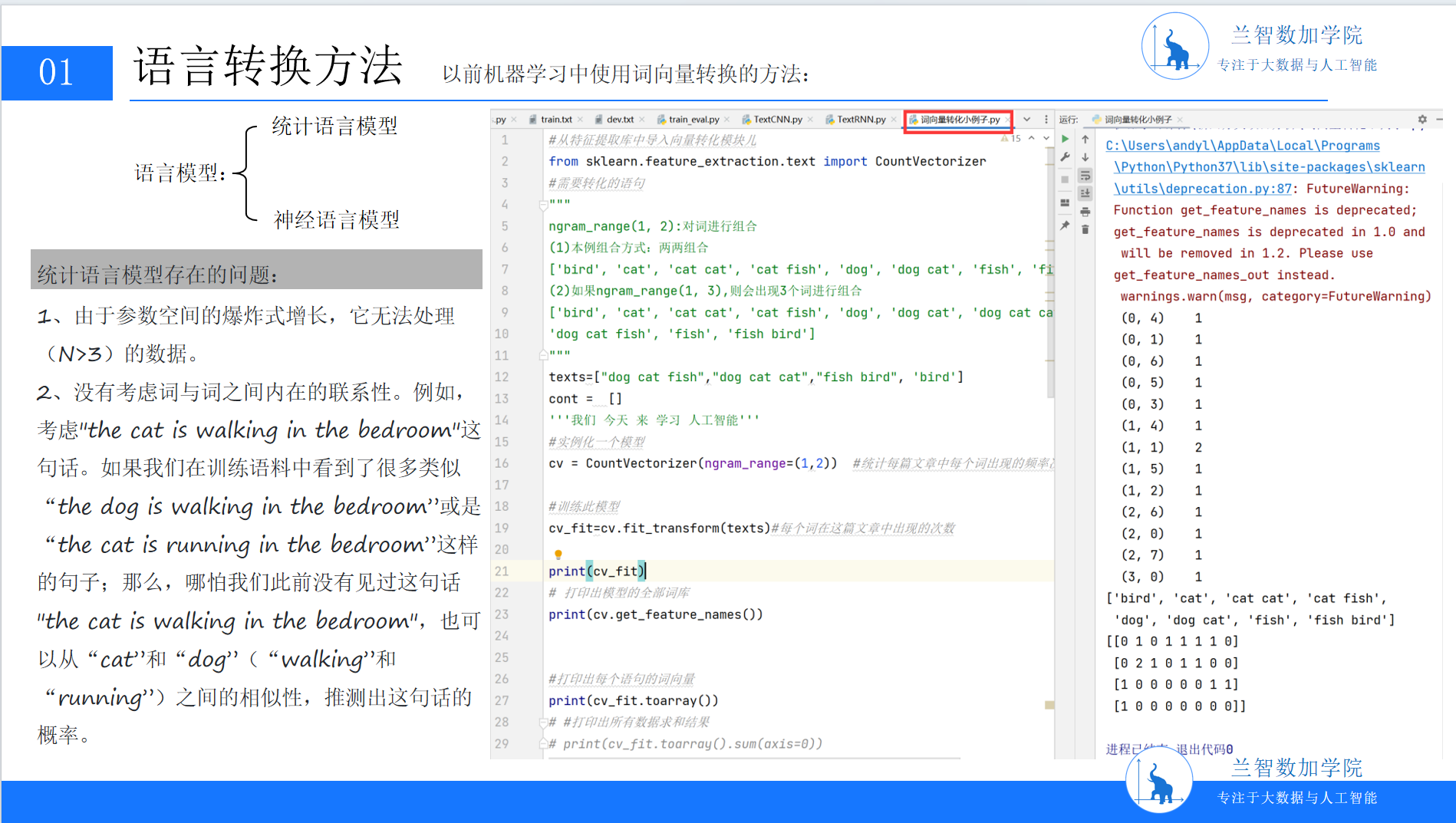
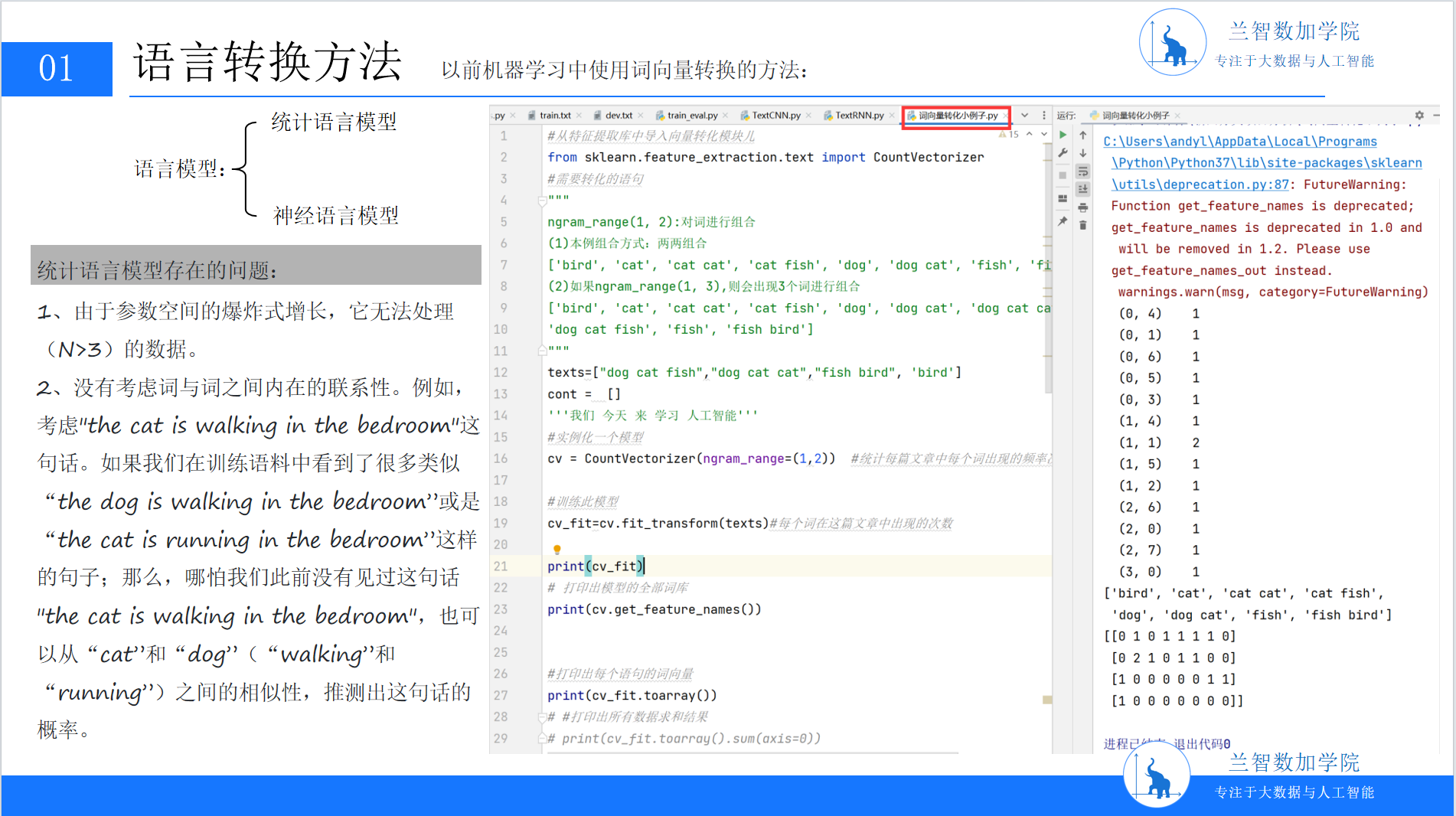
随着语料库技术的发展,统计语言模型(Statistical Language Model, SLM)成为主流。其核心思想是:通过大规模语料的统计规律,捕捉词语间的共现概率,从而量化语言的“合理性”。
统计语言模型的典型代表是n-gram模型。它假设一个词的出现概率仅依赖于其前n-1个词(如二元模型bigram关注前1个词,三元模型trigram关注前2个词)。例如,对于句子“the cat is walking in the bedroom”,trigram模型会计算“is walking”在“the cat”之后的出现概率,“walking in”在“is”之后的出现概率,最终通过链式法则累乘得到整句的概率。
这种基于局部上下文的统计方法,首次让计算机“学会”了语言的表层模式。例如,当输入“the cat is”时,模型能根据语料库中“is”后高频出现的动词(如“walking”“sleeping”),预测下一个词的可能性。但统计语言模型的缺陷也同样明显:其一,随着n增大(如n=4的四元模型),参数空间呈指数级爆炸——“the cat is walking”与“the dog is running”需要完全独立的参数存储,导致模型无法处理长距离依赖;其二,它仅关注表层共现,无法捕捉词语间的深层语义关联(如“猫”与“犬”同属哺乳动物,但统计模型可能因共现频率低而忽略这种联系)。
(PPT3:统计语言模型)
二、维度灾难:传统方法的瓶颈与突破方向
2.1 One-Hot编码的困境
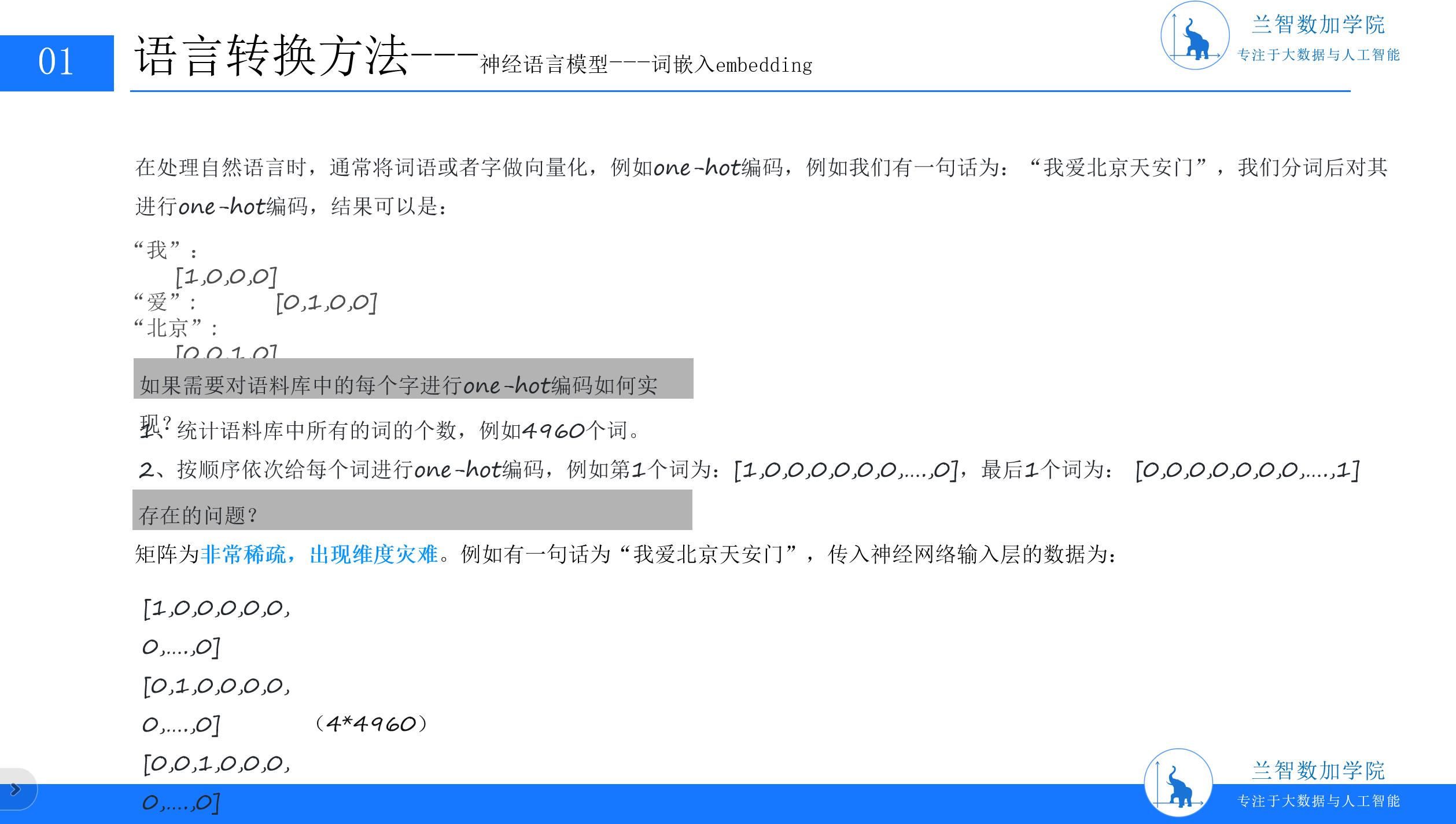
为了将词语输入模型,计算机需要为每个词语分配一个唯一的数字标识。最直接的方案是One-Hot编码:假设有一个包含V个不同词语的语料库,每个词语对应一个长度为V的0-1向量,仅在自身位置为1,其余为0。例如,语料库包含“我”“爱”“北京”“天安门”4个词时,“我”的编码是[1,0,0,0],“爱”是[0,1,0,0],以此类推。
但这种编码方式很快暴露了致命问题:维度灾难(Curse of Dimensionality)。当语料库规模扩大(如包含4960个词),每个词语的向量维度将飙升至4960维,且其中99.99%的元素是0。高维稀疏向量不仅占用大量存储资源,更会导致模型训练效率低下——梯度下降时,大量零值梯度无法有效更新参数,模型难以捕捉词语间的潜在关联。(PPT4:语言转换方法中的one-hot编码示例)
2.2 从统计到语义:我们需要怎样的向量表示?
显然,One-Hot编码无法满足自然语言处理对语义理解的需求。理想的语言表示应具备两个特性:
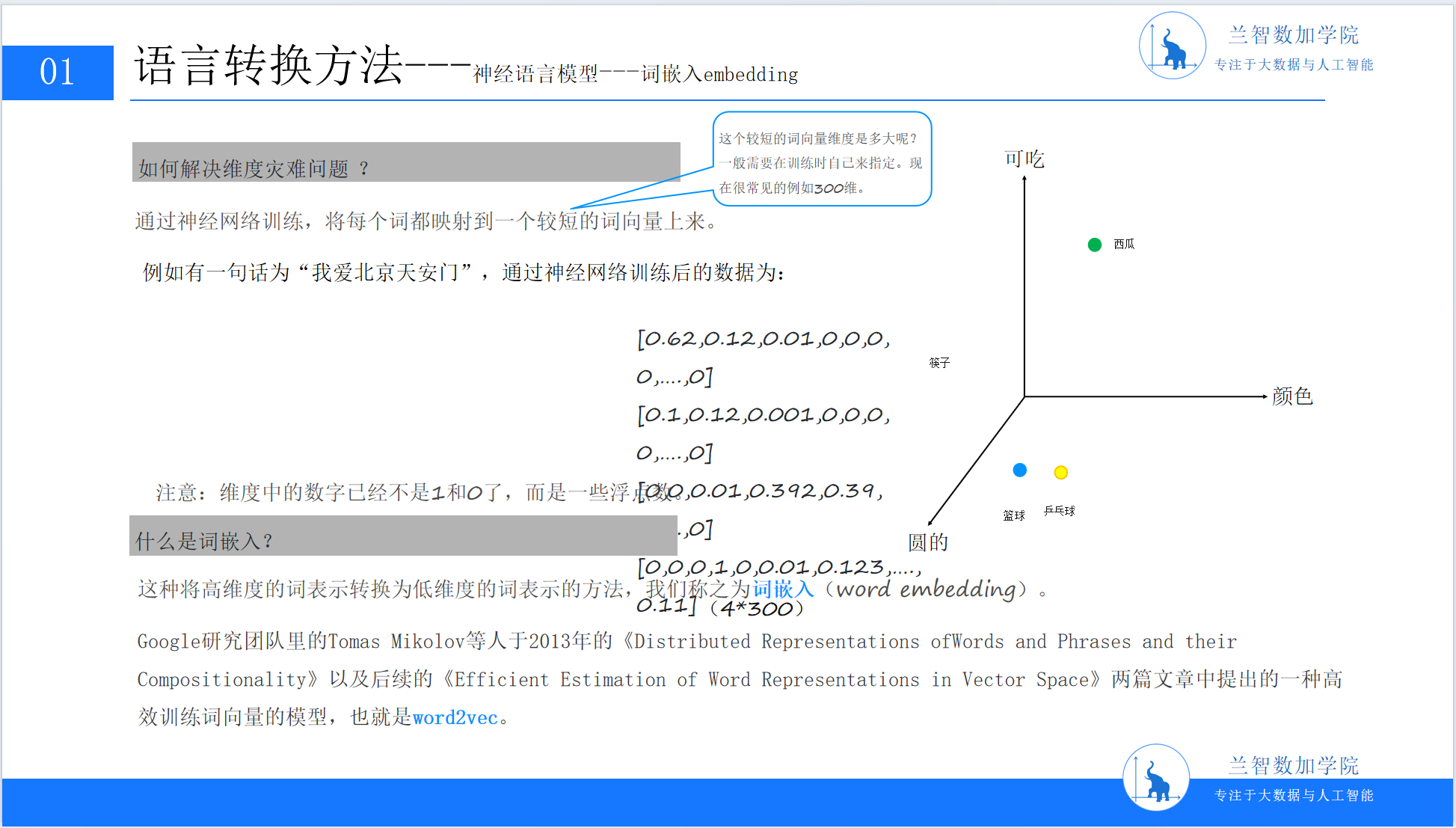
低维稠密:用较少的维度(如100维、300维)存储词语信息,向量中大部分元素为非零实数;
语义可计算:向量间的距离(如余弦相似度)能反映词语的语义相似性(如“猫”与“犬”的向量距离应小于“猫”与“桌子”)。
这一目标推动自然语言处理进入“词嵌入(Word Embedding)”时代——一种将高维稀疏的One-Hot向量映射到低维稠密语义空间的技术。(PPT5:词嵌入概念示意图,含维度对比与示例)

三、词嵌入:让词语在向量空间中“对话”
3.1 词嵌入的核心思想:分布式假设
词嵌入的理论基础是“分布式假设(Distributional Hypothesis)”:语言中词语的语义由其上下文决定。换句话说,经常出现在相似上下文中的词语,其语义也相似。例如,“苹果”常与“水果”“甜”“红色”共现,而“香蕉”也常与这些词共现,因此它们的词嵌入向量应具有较高的相似度。
基于这一假设,词嵌入技术通过神经网络学习一个映射函数,将One-Hot向量转换为低维稠密的嵌入向量。这个过程不仅压缩了维度,更将语义信息编码到了向量的每个维度中。
(PPT6:统计语言模型的问题与词嵌入引入)

3.2 从理论到实践:词嵌入的技术路径
早期的词嵌入方法(如LSA、LDA)依赖矩阵分解技术,虽能降低维度,但对语义的捕捉能力有限。真正让词嵌入走进大众视野的,是2013年Google团队提出的word2vec模型。它通过浅层神经网络(仅需1个隐藏层),在大规模语料上高效训练词向量,不仅大幅提升了训练速度,更显著增强了向量的语义表达能力。
四、word2vec:神经语言模型的工程典范
word2vec是词嵌入技术的集大成者,其核心设计是用神经网络模拟语言模型的训练过程,将词向量作为训练的副产物。具体来说,word2vec包含两种主流架构:CBOW(连续词袋模型)与Skip-Gram(跳字模型)。
(PPT7神经语言模型)
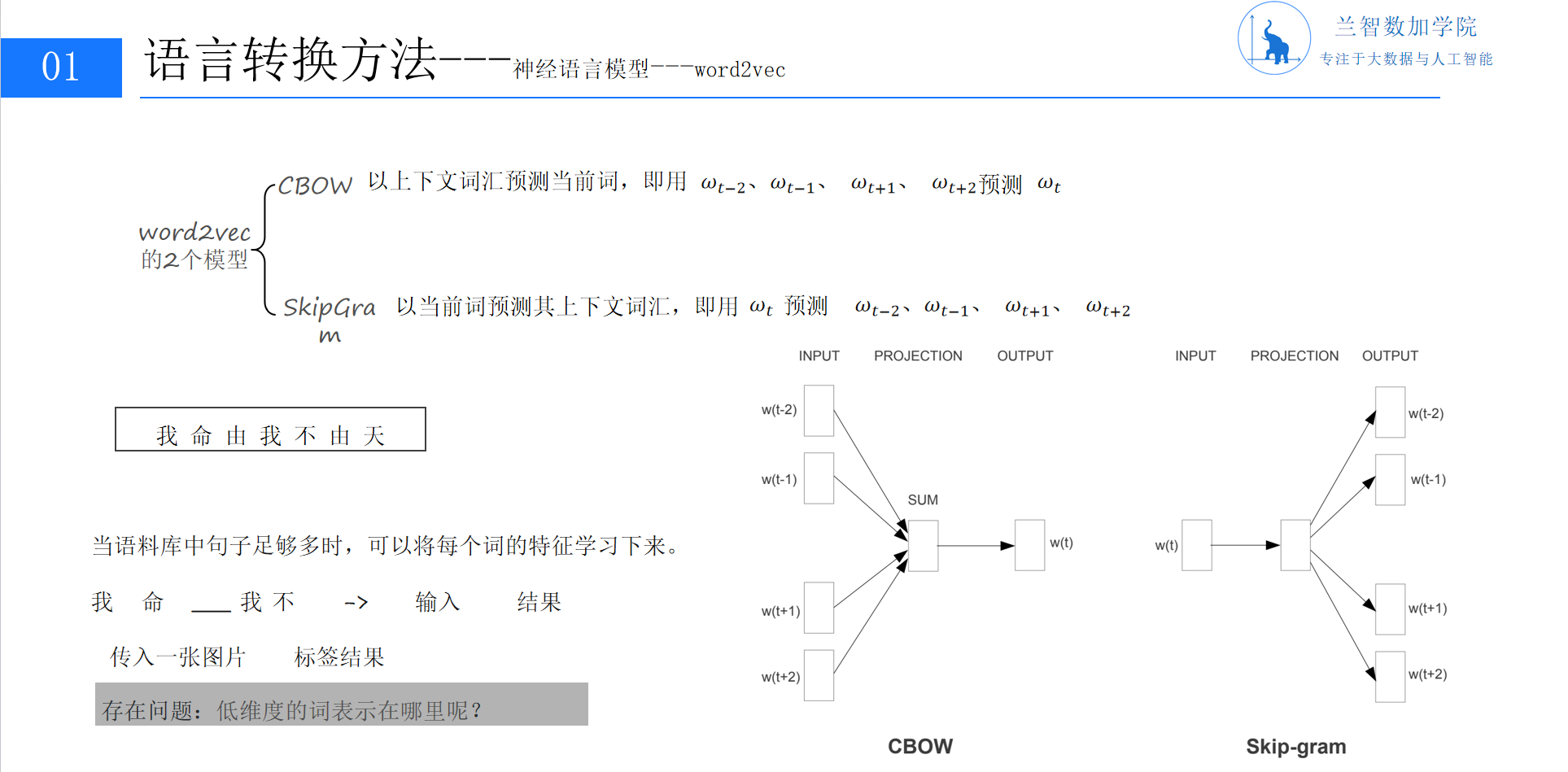
4.1 CBOW模型:用上下文预测目标词
CBOW模型的目标是:给定一个词的上下文(如前C个词),预测该词本身。例如,对于句子“我命由我不由天”,若窗口大小C=2,当输入上下文“我命”““我不”时,模型需预测目标词“由”(实际应用中窗口随机采样,此处为简化说明)。
4.1.1 模型结构与训练流程
CBOW的神经网络结构包含三层:输入层、隐藏层、输出层(见图7)。
输入层:将上下文词的One-Hot向量输入,每个向量维度为V(词汇表大小)。例如,窗口内有C个词,输入层接收C个V维的One-Hot向量。
隐藏层:将输入层的C个向量分别与同一个权重矩阵WV×N相乘(WV×N是关键参数矩阵,维度为词汇表大小×嵌入维度N),得到C个N维向量,再对它们取平均,形成最终的N维隐藏层向量。这一步的本质是将上下文信息压缩到一个低维的语义空间中。
输出层:将隐藏层向量与另一个权重矩阵WN×V′相乘,得到一个V维向量,再通过Softmax函数归一化,输出词汇表中每个词作为预测目标的概率。
训练过程中,模型通过比较预测概率与真实标签(目标词的One-Hot向量)的损失值,反向传播更新WV×N和WN×V′。值得注意的是,WV×N矩阵本身就是最终的词嵌入矩阵——矩阵的第i行对应第i个词的嵌入向量。这是因为,隐藏层的N维向量本质上是输入词One-Hot向量与WV×N相乘的结果,直接编码了词语的语义信息。(PPT8:CBOW模型训练过程示意图,含权重矩阵与维度变换)
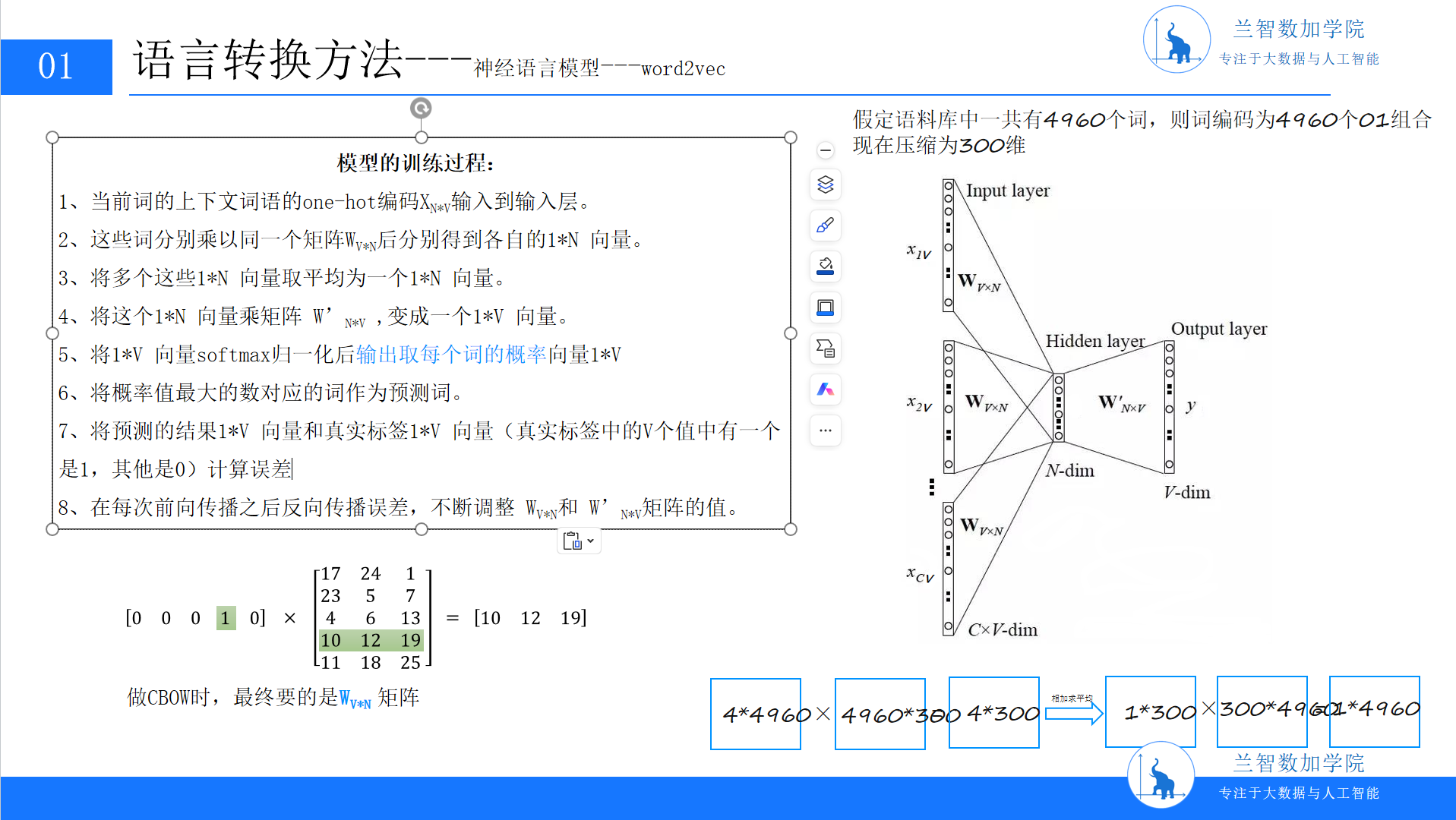
4.1.2 数学示例与直观理解
为了更清晰地理解,我们用一个简化的例子说明:假设词汇表V=5(词表为[“我”“爱”“北”“京”“天”]),嵌入维度N=3。输入上下文词的One-Hot向量为[0,0,1,0,0](对应“北”)和[0,0,0,1,0](对应“京”)。
输入层到隐藏层:每个One-Hot向量与W5×3相乘。例如,“北”的向量[0,0,1,0,0]与W相乘后得到W的第3行(假设W为[[17,24,1],[23,5,7],[4,6,13],[11,18,25],[10,12,19]]),即[4,6,13]。同理,“京”的向量得到[11,18,25]。两者取平均得到隐藏层向量[(4+11)/2, (6+18)/2, (13+25)/2] = [7.5, 12, 19]。
隐藏层到输出层:隐藏层向量与W3×5′相乘,得到5维向量,再通过Softmax归一化,输出每个词的概率。训练的目标是让目标词(如“安”)对应的概率最大。
4.2 Skip-Gram模型:用目标词预测上下文
与CBOW相反,Skip-Gram模型的目标是:给定一个目标词,预测其上下文词。例如,输入目标词“由”,模型需预测可能的上下文词“我”“不”“天”等。
Skip-Gram的结构与CBOW类似,但数据流方向相反:输入层是目标词的One-Hot向量,通过WV×N得到隐藏层向量(即目标词的嵌入),再通过WN×V′得到输出层向量,预测上下文词的概率。Skip-Gram的优势在于,当目标词较生僻时,其上下文词的多样性更高,能更充分地捕捉词语的语义边界。(PPT7:word2vec模型架构对比,含CBOW与Skip-Gram公式)
五、从训练到应用:词嵌入的工程实践与损失函数
5.1 深度学习中的损失函数:衡量语义相似性的标尺
无论采用CBOW还是Skip-Gram,词嵌入的训练都需要一个有效的损失函数来评估模型性能。在自然语言处理中,最常用的损失函数是交叉熵损失(Cross-Entropy Loss),尤其在多分类任务中(如预测上下文词)。
交叉熵损失的数学形式为:
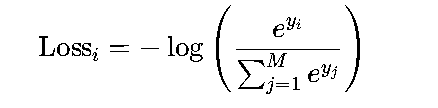
其中,yi是目标词的得分(隐藏层向量与W′相乘后的第i个元素),M是词汇表大小。该公式的本质是:真实目标词的得分越高,损失值越小。通过最小化损失,模型会调整权重矩阵,使语义相似的词语在嵌入空间中更接近。
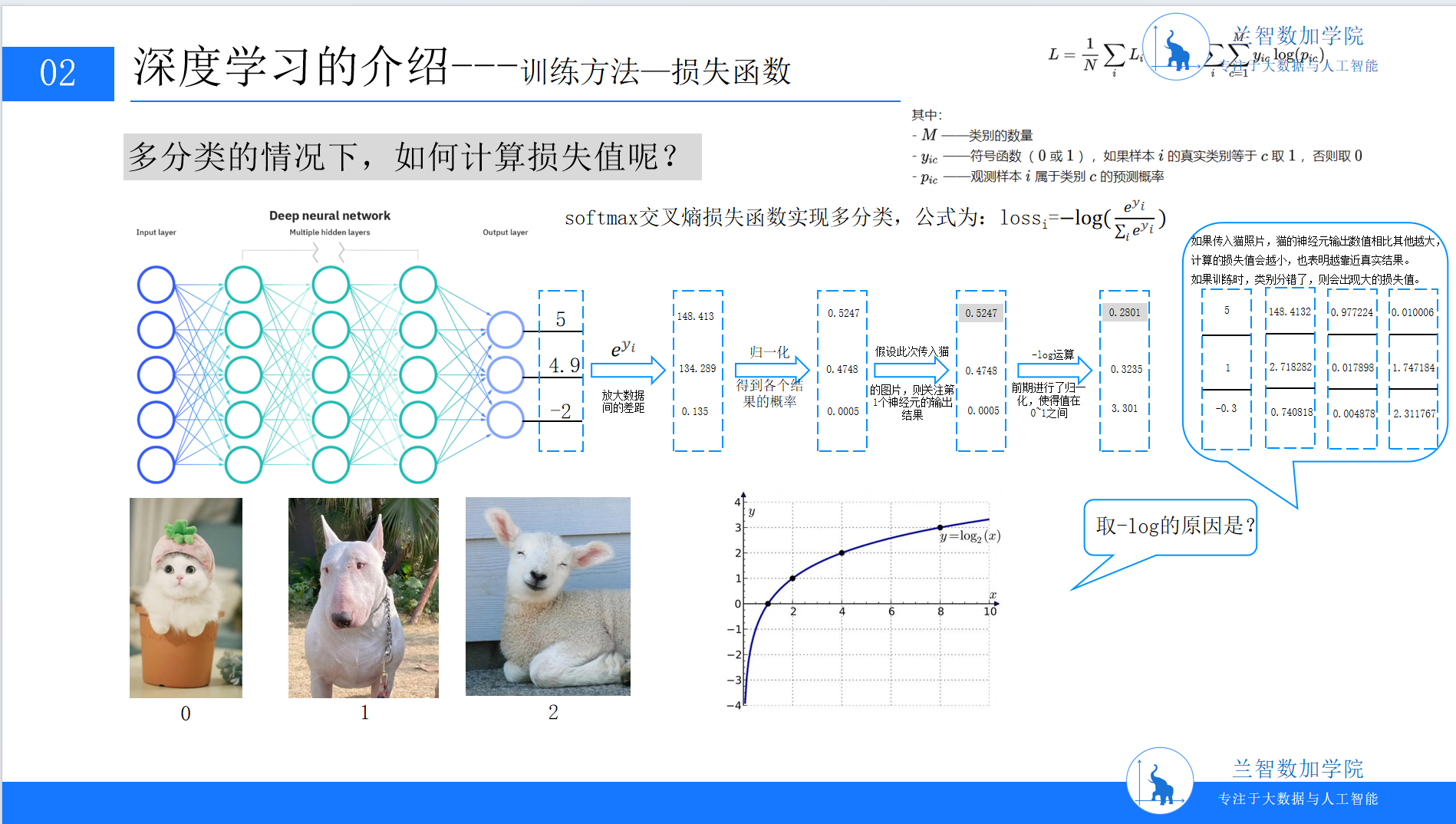
以“猫”图片分类为例,假设输出层有3个节点(猫、狗、鸟),真实标签是“猫”(对应One-Hot向量[1,0,0])。模型输出得分为[5, 2, 1],经过Softmax归一化后概率为[0.88, 0.11, 0.01]。此时损失值为−log(0.88)≈0.13,说明模型预测较准。若模型错误地将“猫”预测为“狗”(概率[0.1, 0.8, 0.1]),损失值升至−log(0.1)≈2.3,驱动模型调整参数以提升正确类别的得分。(此处可插入PPT9:深度学习训练方法-损失函数示意图,含softmax计算与对数函数图像)
5.2 工程落地:词嵌入的实际价值
词嵌入技术自提出以来,已在多个NLP任务中展现出强大能力:
文本分类:将文档的词嵌入向量取平均或加权求和,作为文档的表示,输入分类器(如SVM、神经网络),可有效捕捉文档的主题信息;
情感分析:通过比较评论中词语的嵌入向量与“正面”“负面”情感词的相似度,判断评论的情感倾向;
机器翻译:在编码器-解码器架构中,词嵌入作为输入输出的统一表示,降低语言差异带来的建模难度。
六、总结与展望:从词嵌入到通用语言理解
从统计语言模型的维度困境,到词嵌入的语义革命,再到word2vec的工程落地,自然语言处理的语言转换技术走过了一条从“符号统计”到“语义计算”的演进之路。如今,词嵌入已不再是孤立的技术,而是深度学习与自然语言处理融合的基础——BERT、GPT等预训练模型的核心,正是基于词嵌入的扩展与优化。
未来,随着多模态学习(文本、图像、语音的联合建模)与小样本学习的兴起,语言转换技术将进一步突破“仅从文本学习”的限制,向更通用、更智能的方向发展。但不变的是,如何让计算机真正“理解”语言背后的语义,始终是自然语言处理最根本的挑战,也是最激动人心的机遇。(此处可插入总结性图表,对比不同语言转换技术的优缺点)