GA论文阅读
2018

1.摘要
background
深度神经网络(特别是CNN)虽然性能强大,但通常参数量巨大,计算和存储开销高。这极大地限制了它们在手机、微型机器人等计算资源有限的移动设备上的部署和应用。因此,学术界迫切需要有效的方法来学习参数更少、更“便携”的深度网络,即模型压缩与加速。
innovation
创新点: 本文提出了一种全新的“学生-教师”学习范式。它没有使用预先固定的度量标准(如欧氏距离或KL散度)来衡量学生网络和教师网络的差异,而是引入了生成对抗网络 (GAN) 的思想。
学生网络 (Student Network) 扮演 生成器 (Generator) 的角色,其任务是学习生成与教师网络相似的特征分布。
引入一个额外的 判别器 (Discriminator) 作为 “教学助理 (Teaching Assistant)”,其任务是区分输入的特征是来自“教师网络”还是“学生网络”。
2. 方法 Method
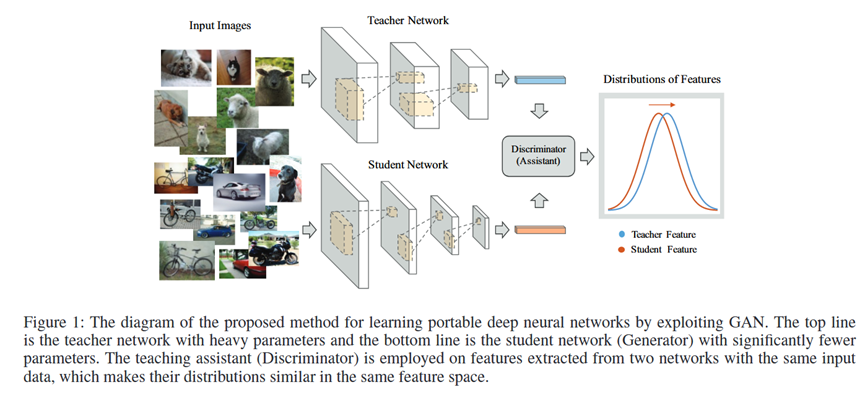
总体流程 (Pipeline)
该方法构建了一个GAN框架,其流程如论文图1所示:
1.输入: 将同一张输入图片分别送入一个预训练好的、固定的教师网络 (Teacher Network) 和一个正在被训练的学生网络 (Student Network / Generator)。
2.特征提取: 两个网络分别在倒数第二层(分类层前)提取出特征向量,记为教师特征 zT 和学生特征 zs。
3.对抗学习: 判别器 (Discriminator) 接收 zT 或 zs 作为输入,并判断该特征来自教师(真)还是学生(假)。学生网络(作为生成器)的目标是生成让判别器无法区分真假的特征 zs。
4.联合优化: 整个系统通过一个联合的损失函数进行端到端训练,同时优化学生网络和判别器。训练结束后,判别器被丢弃,训练好的学生网络即为最终得到的便携式模型。
各部分详解
输入: 训练数据 (x, y),其中 x 是图像,y 是真实标签。
教师网络 NT: 一个预训练好的大模型,在训练过程中其参数被冻结。输入 x,输出特征 zT = NT(x) 和分类结果 oT。
学生网络 NS (即生成器 G):
它被拆分为两部分:特征提取器 G1 和分类器 G2。
输入 x,G1 输出学生特征 zs = G1(x)。G2 接收 zs,输出分类结果 os = G2(zs)。
NS 的参数量远小于 NT。
判别器 D (教学助理):
一个二元分类器(通常是几层全连接网络)。
输入为特征向量(zT 或 zs),输出一个概率值,表示输入特征来自教师网络的可能性。
损失函数 (Loss Function):
最终的损失函数(论文中公式9)是几个部分的加权和,共同指导学生网络的学习:
1.标准分类损失: 学生网络自身的分类任务损失,采用交叉熵损失 H(os, y),确保学生能学会正确分类。
2.知识蒸馏损失: 借鉴Hinton的方法,让学生网络柔化的输出 τ(os) 模仿教师网络柔化的输出 τ(oT),通过交叉熵 H(τ(os), τ(oT)) 来实现。这部分传递了类别间的“暗知识”。
3.对抗损失: GAN的标准损失。学生网络 G 的目标是最小化 log(1 - D(zs))(等价于最大化 log(D(zs))),即让判别器相信其生成的特征是真的;判别器 D 的目标是最小化 -[log(D(zT)) + log(1 - D(zs))],即准确区分教师特征和学生特征。
3. 实验 Experimental Results
实验数据集: MNIST, CIFAR-10, CIFAR-100。
主要实验与结论:
1.MNIST特征可视化实验:
目的: 验证该方法是否能让学生网络的特征分布更接近教师网络。
结论: 从图2可以看出,标准方法训练的学生网络特征(b)混杂不清;而使用本文方法训练的学生网络特征(c)分布清晰,各个类别的边界明确,与教师网络(a)的特征分布非常相似,证明了方法的有效性。
2.MNIST分类错误率对比实验 (表1):
目的: 在MNIST上,将该方法与标准反向传播、知识蒸馏、FitNet等其他学生-教师学习范式进行性能比较。
结论: 本文提出的“助理辅助学习”方法取得了0.48%的错误率,优于其他所有学生-教师学习方法,并与当时最先进的方法性能相当。
3.CIFAR-10压缩/精度权衡实验 (表2):
目的: 探究不同规模的学生网络在压缩率、加速比和分类精度之间的权衡关系。
结论: 相比FitNet,本文方法在所有四种不同参数量的学生网络上都取得了更高的分类精度。证明了该方法的普适性和优越性。
4.CIFAR-10/CIFAR-100 SOTA对比实验 (表3):
目的: 在更复杂的数据集上,将最佳学生模型与教师模型、其他学生-教师方法以及当时的SOTA模型进行比较。
结论: 在CIFAR-10上,学生网络的性能(91.68%)甚至超越了教师网络(90.21%),同时参数量减少了超过3倍。在CIFAR-100上,性能也远超其他学生-教师学习方法,接近SOTA水平。
4. 总结 Conclusion
这篇论文的核心贡献是提出了一种基于生成对抗网络的新型知识蒸馏框架。它不再依赖固定的、手工设计的损失函数来迁移知识,而是通过引入一个“教学助理”(判别器),让学生网络在对抗中动态地、自适应地学习模仿教师网络的内部特征表达。实验证明,这种方法能够训练出性能更优的轻量级网络。