解锁数据湖潜力:Databricks Photon引擎的技术深度剖析
在大数据时代,数据湖已成为企业存储和分析海量数据的核心架构。然而,随着数据规模的爆炸式增长,如何高效处理查询、降低成本并保持性能,成为了每一个数据工程师和架构师的痛点。今天,我们深入探讨Databricks的Photon引擎——一个革命性的矢量化查询引擎,它不仅能加速SQL工作负载,还能显著降低总拥有成本(TCO)。如果你正在构建或优化数据湖,这篇文章将为你提供实操insights,帮助你实现“更快、更便宜、更兼容”的数据处理目标。
1. Photon引擎简介:从Spark到矢量化的飞跃
Photon是Databricks原生的矢量化查询引擎,专为Azure Databricks设计。它以C++编写,从底层重构了查询执行逻辑,能够在不修改现有代码的情况下,提升SQL查询和DataFrame API调用的性能。简单来说,Photon让你的数据湖从“慢吞吞的批处理”转向“闪电般的实时分析”。
为什么Photon如此强大?传统Apache Spark引擎依赖于JVM的行式处理,而Photon采用矢量化执行,能一次性处理成千上万的记录。这意味着在聚合、联接和过滤等操作上,Photon可以实现高达12倍的加速,同时将TCO降低高达80%。更重要的是,它兼容Apache Spark API,支持SQL、Python、R、Scala和Java——无需重写代码,就能无缝集成到你的数据湖管道中。
2. Photon的底层原理:矢量化执行的秘密
要真正理解Photon的强大之处,我们需要深入其底层架构和技术原理。Photon并非简单地优化Spark,而是从零构建了一个C++原生执行引擎,集成到Databricks Runtime(DBR)中——这是Spark的一个性能增强分支。不同于Spark的JVM依赖(会导致垃圾回收暂停和开销),Photon直接利用CPU指令执行,减少了40-60%的处理延迟,并完全消除了GC暂停。
2.1 架构概述
Photon采用共享无(shared-nothing)的多线程执行模型,每个任务在数据分区上单线程运行。它通过Java Native Interface(JNI)与Java组件交互,支持部分执行:查询可以部分在Photon中运行,不支持的操作则回退到Spark SQL。这种混合模式确保了兼容性,同时允许渐进式采用。
核心是树状操作符结构,使用HasNext()/GetNext() API处理数据批次。从文件扫描开始,Photon使用Catalyst规则将Spark计划转换为Photon计划,通过适配器节点实现零拷贝数据传递。
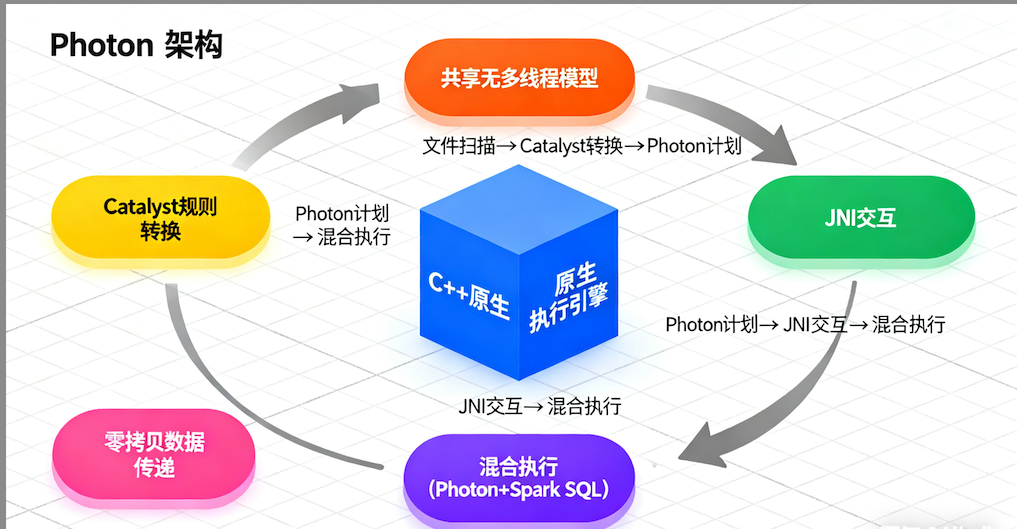
2.2 矢量化执行模型
Photon的核心原理是解释型矢量化执行:数据以列式批次(columnar batches)形式处理,每个批次包含连续值向量和NULL指示器,辅以位置列表跟踪活跃行。这种布局优化了SIMD(单指令多数据)矢量化,允许内核一次性处理多个值,提高CPU利用率。
- 内核优化:执行内核是针对向量优化的循环,使用手写SIMD intrinsics或编译器自动矢量化。内核根据批次属性(如NULL存在、稀疏性)自适应选择版本,例如针对ASCII字符串的专用处理,能将表达式评估加速4倍。
- 自适应执行:Photon在运行时构建元数据,根据数据特性(如UUID的整数表示)选择优化路径。这对缺乏统计信息的Lakehouse数据尤为重要,能动态压缩稀疏批次,提高哈希表探测效率。
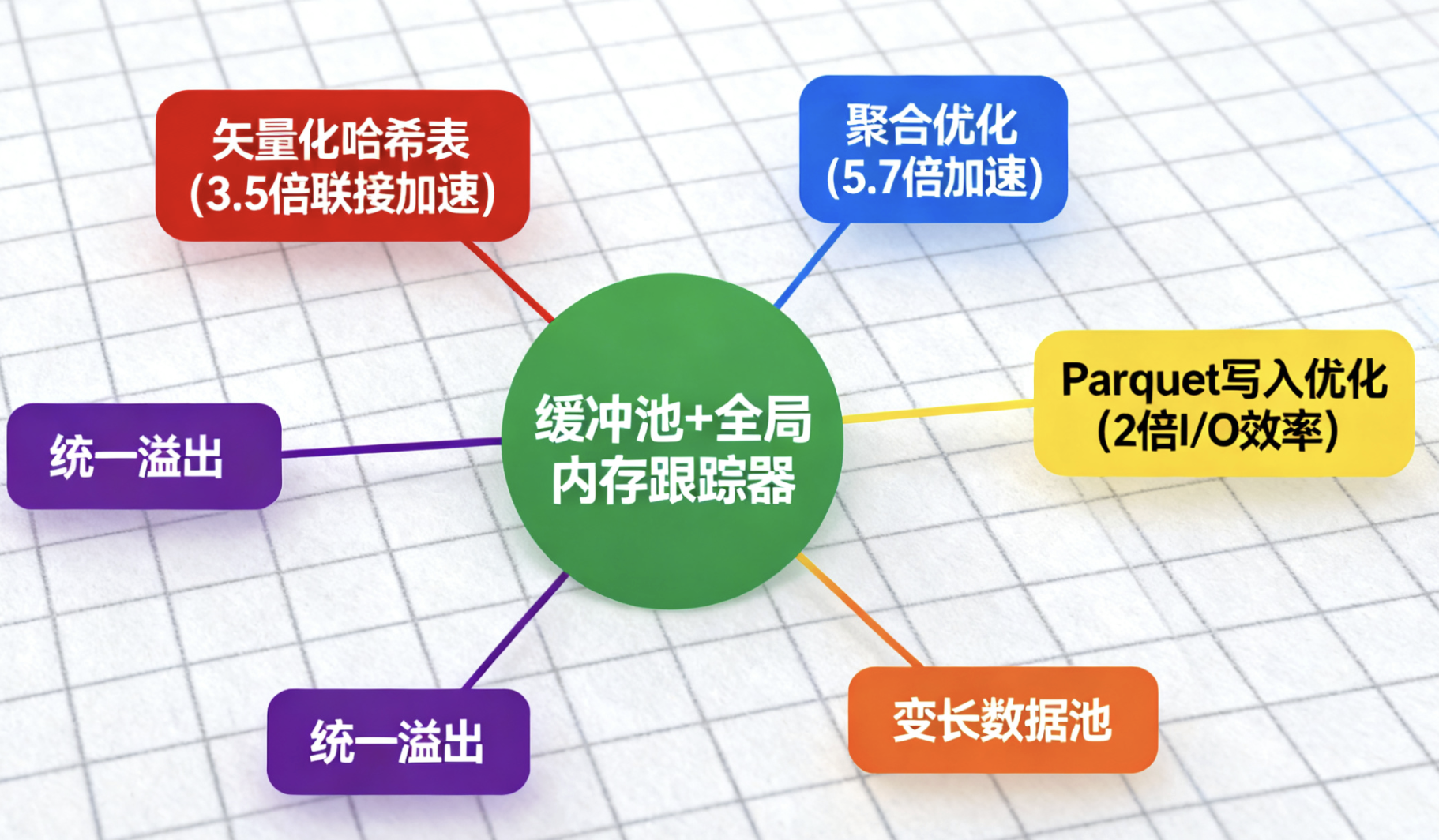
2.3 内存管理和优化
Photon使用内部缓冲池管理瞬时分配,缓存热内存以减少开销。变长数据采用追加式池,由全局内存跟踪器监控。它与Spark的内存管理器集成,支持统一溢出(spilling),并动态预留内存处理密集型查询。
关键优化包括:
- 矢量化哈希表:使用SIMD进行哈希和键比较,二次探测解决冲突,并并行加载以掩盖缓存缺失延迟。在联接操作上,比DBR快3.5倍。
- 聚合和表达式:自定义矢量化实现,减少分配开销,分组聚合加速5.7倍。
- Parquet写入:更快字典编码和位打包,I/O效率提高2倍。
在TPC-H基准(SF=3000)上,Photon平均加速4倍,最高23倍。它还创下TPC-DS 100TB世界纪录,展示了在Delta Lake和S3上的顶尖SQL性能。
3. 启用 Photon的建议场景
● 包含 Delta MERGE 操作的 ETL 流水线● 将大批量数据写入云存储(Delta/Parquet 格式)● 大型数据集的扫描、联接、聚合和小数运算● 使用 Auto Loader 增量、高效地处理存储中新增的数据● 使用 SQL 的交互式 / 临时查询