数据集制作--easy-dataset
一、概述
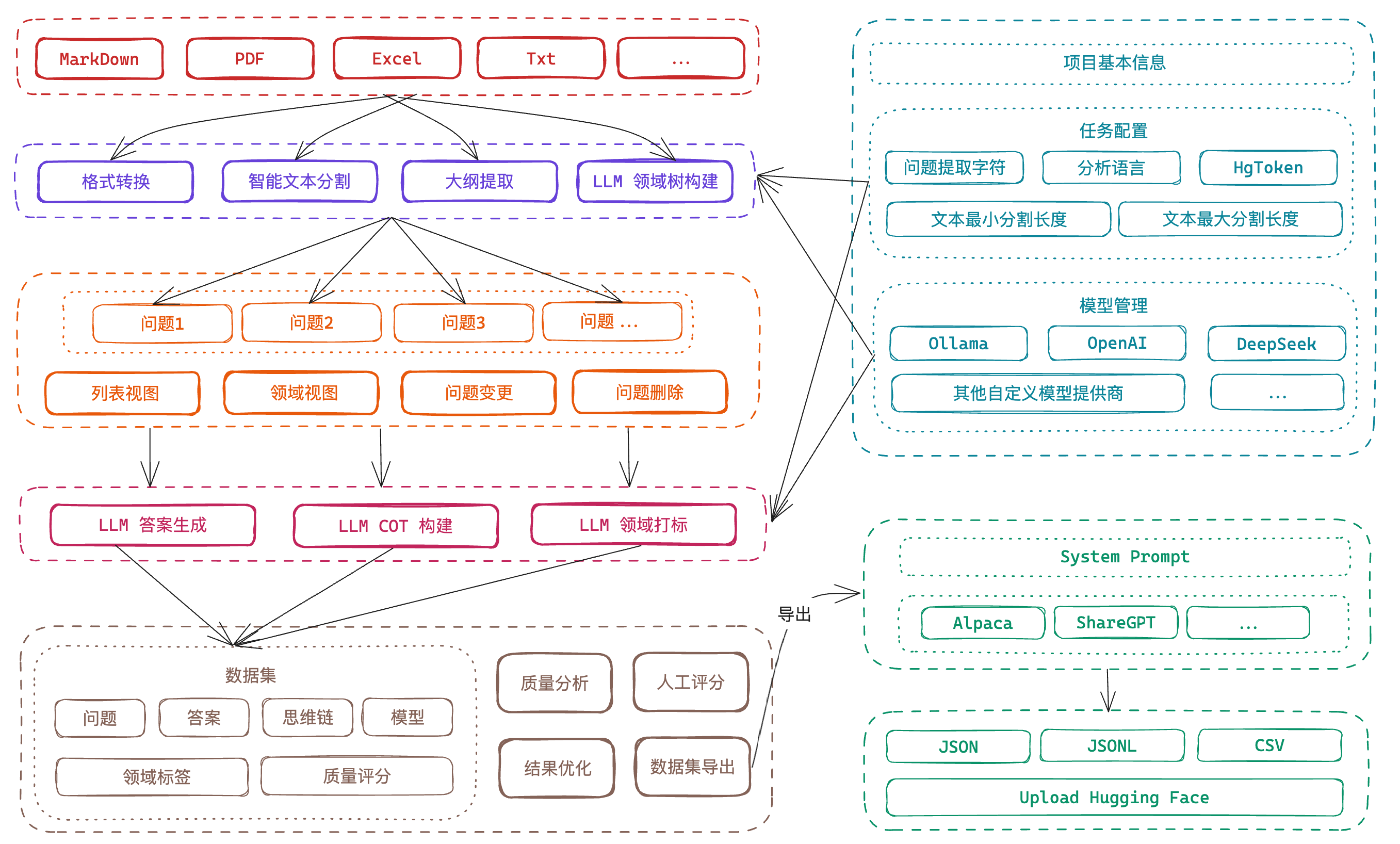
Easy Dataset 是一个专为创建大型语言模型(LLM)微调数据集而设计的应用程序。它提供了直观的界面,用于上传特定领域的文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。
通过 Easy Dataset,您可以将领域知识转化为结构化数据集,兼容所有遵循 OpenAI 格式的 LLM API,使微调过程变得简单高效。
二、安装
2.1、Docker安装
1、克隆仓库
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
2、构建Docker镜像
docker build -t easy-dataset .
3、运行容器
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset
4、打开浏览器,访问 http://localhost:1717
2.2、使用 NPM 安装
1. 克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
2. 安装依赖:
npm install
3. 启动开发服务器:
npm run build
npm run start
4. 打开浏览器并访问 http://localhost:1717
三、使用方法
3.1、创建项目
1. 在首页点击"创建项目"按钮;
2. 输入项目名称和描述;
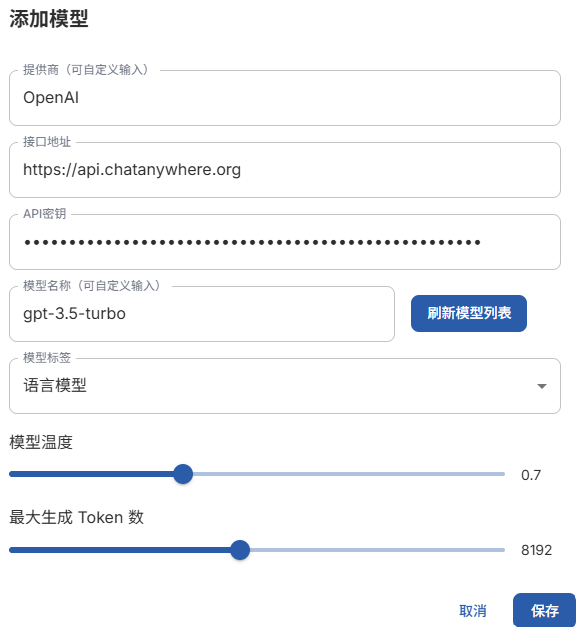
3. 添加模型,测试模型
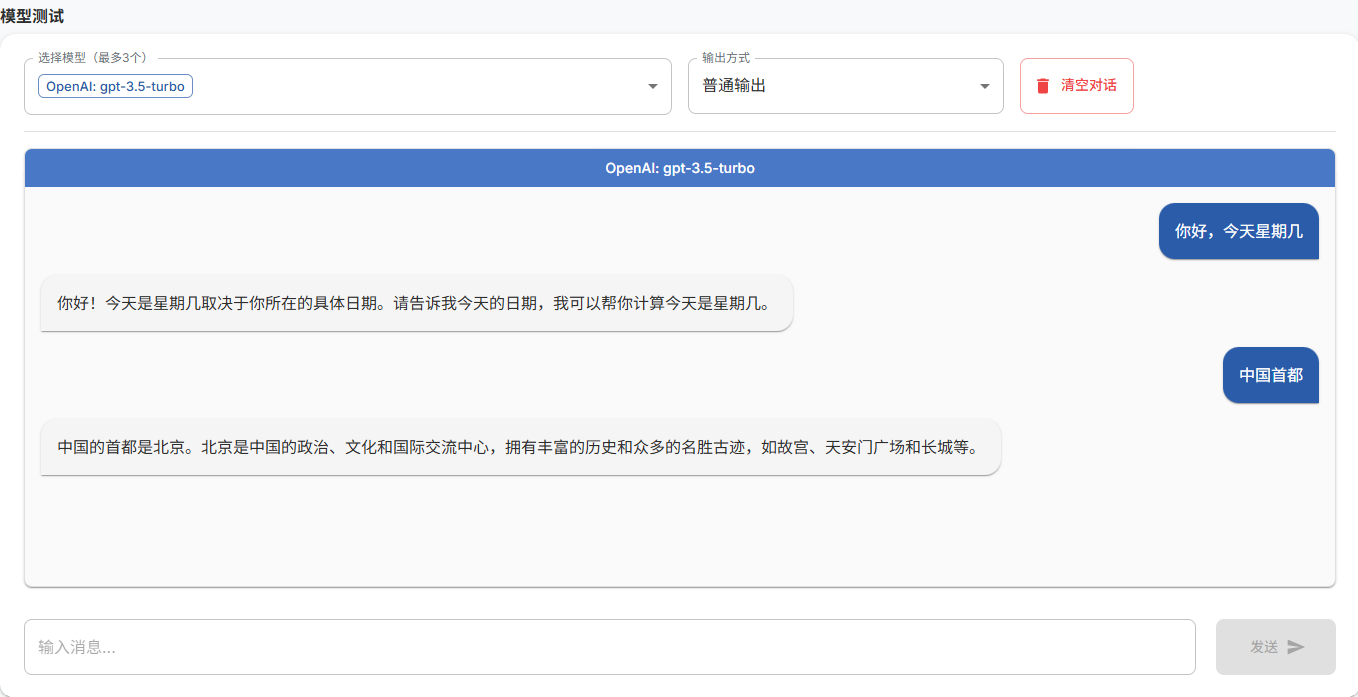
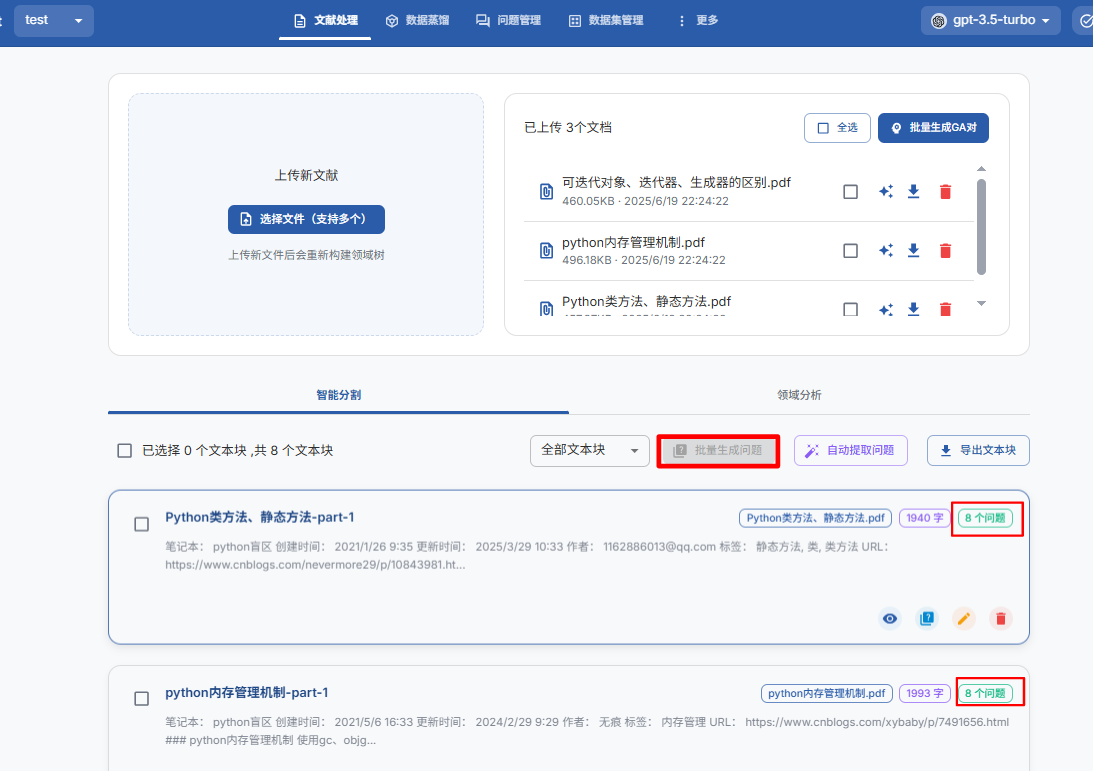
3.2、处理文档
1. 右上角选择模型
2. 在"文献处理"页面上传您的文件(支持 PDF、Markdwon、txt、DOCX);
3. 查看和调整自动分割的文本片段;
4. 查看和调整全局领域树
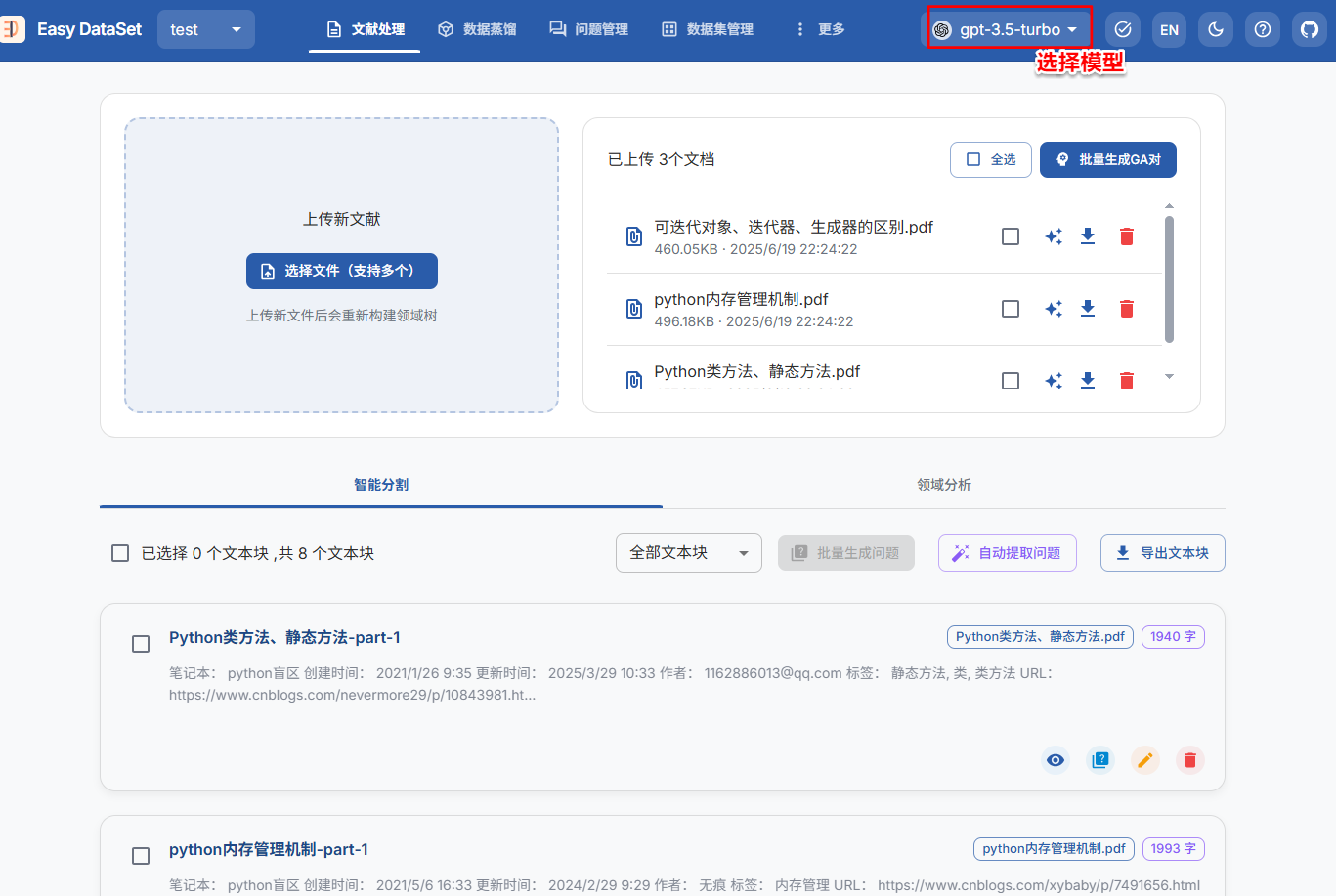
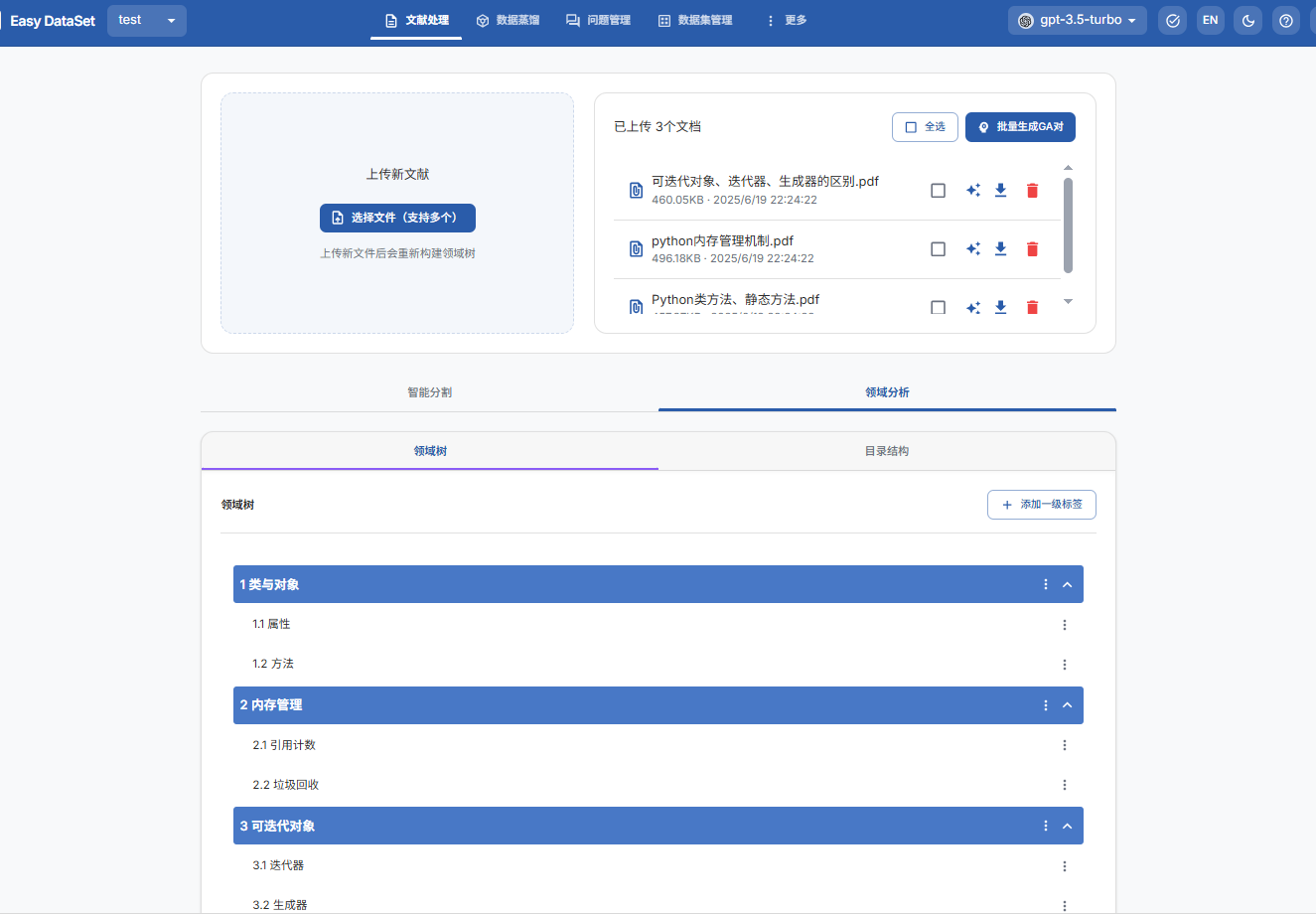
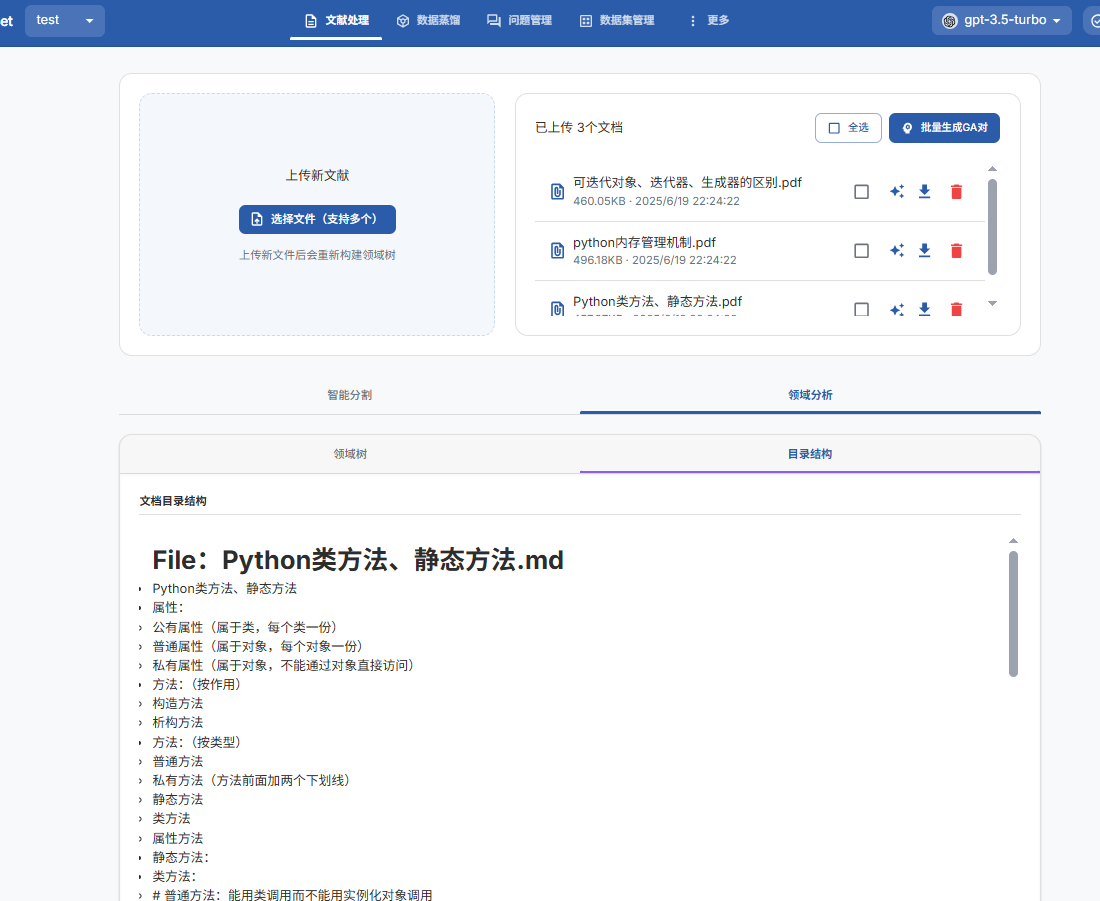
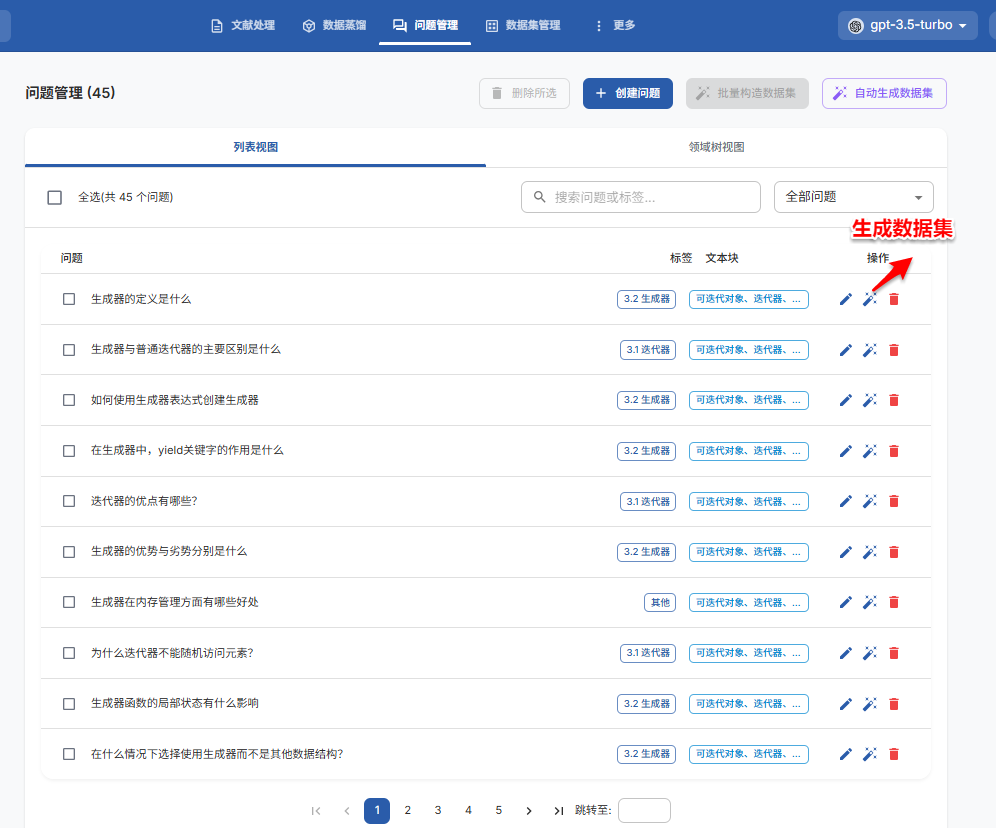
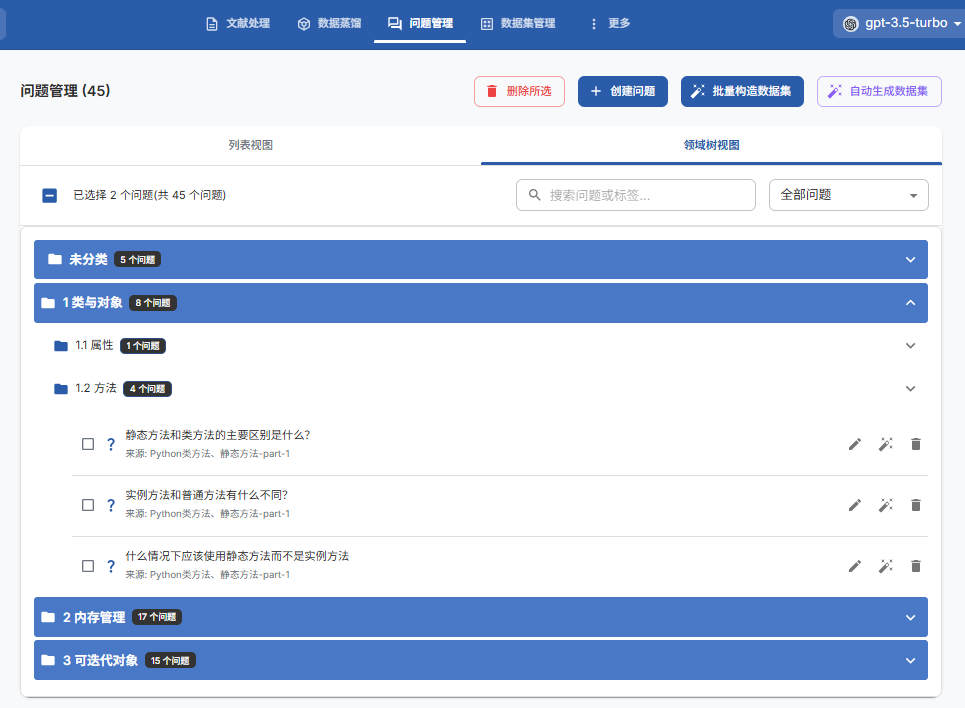
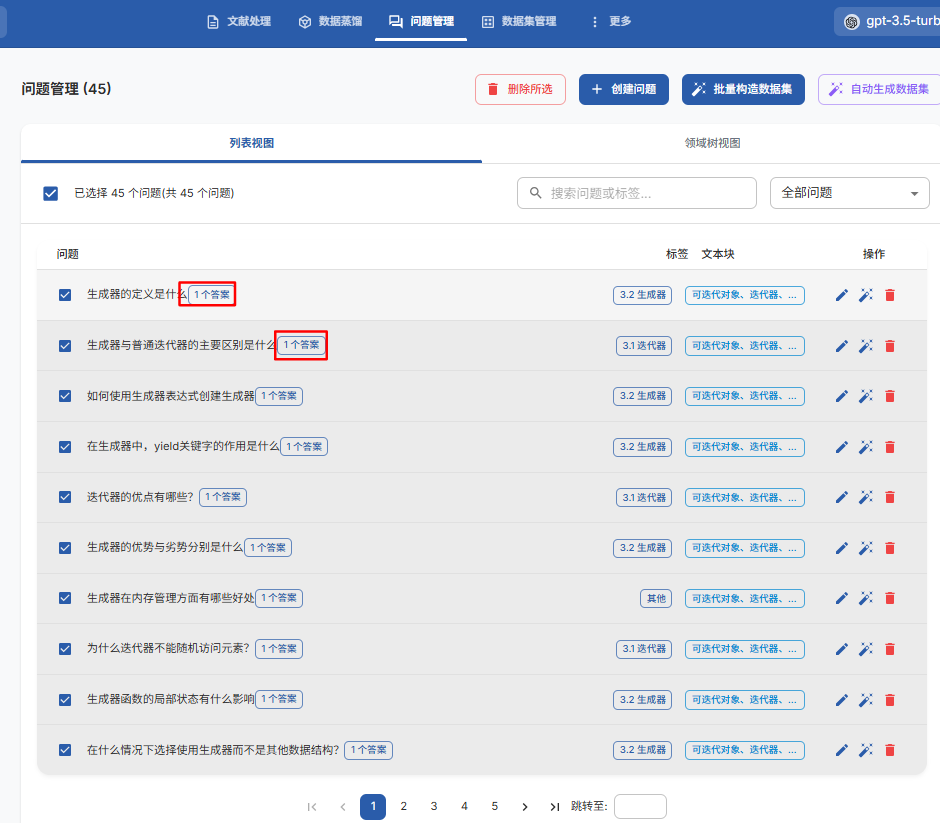
3.3、生成问题
1. 基于文本块“批量生成问题”;
2. 查看并编辑生成的问题;
3. 使用标签树组织问题
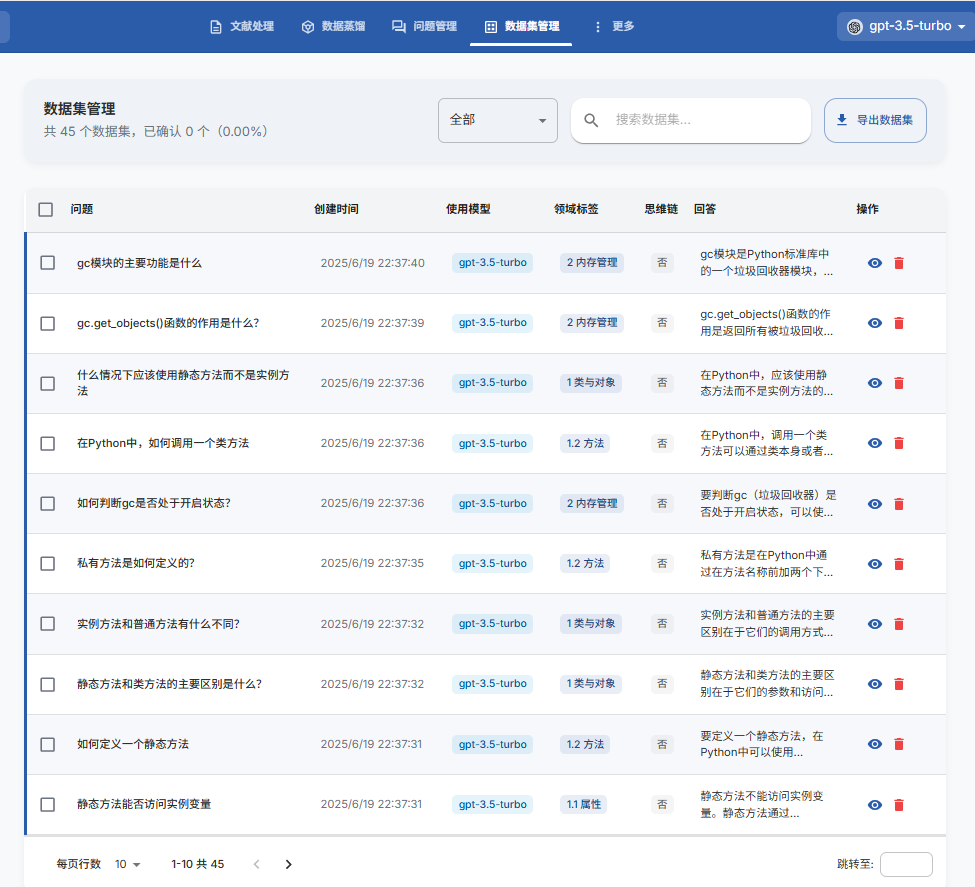
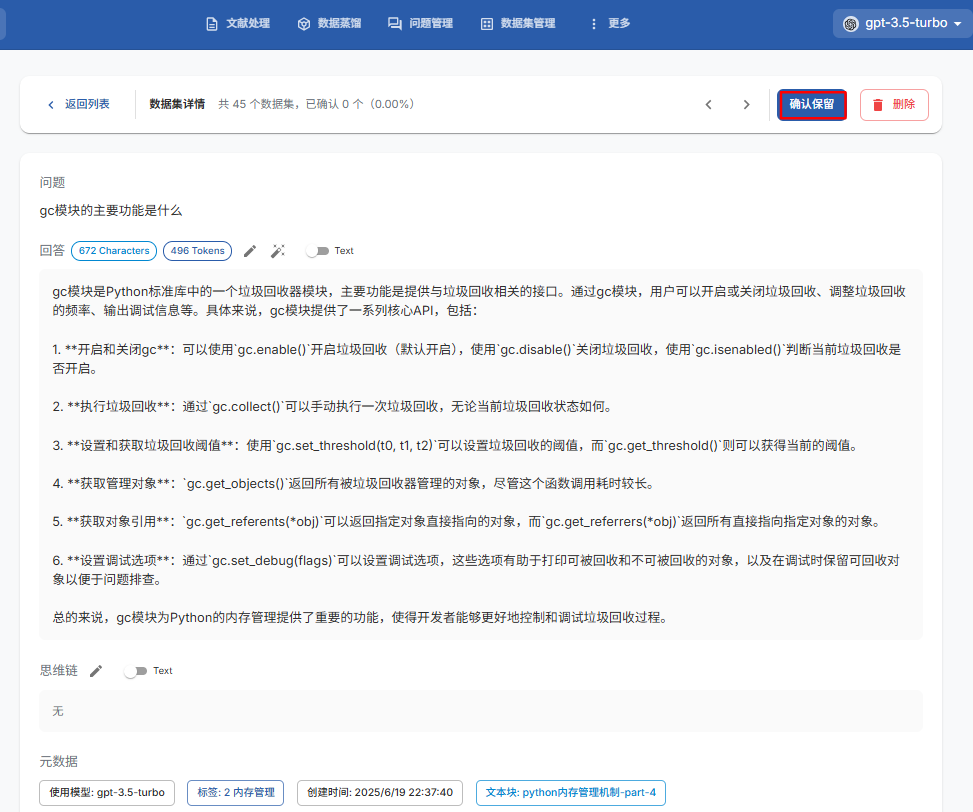
3.4、创建数据集
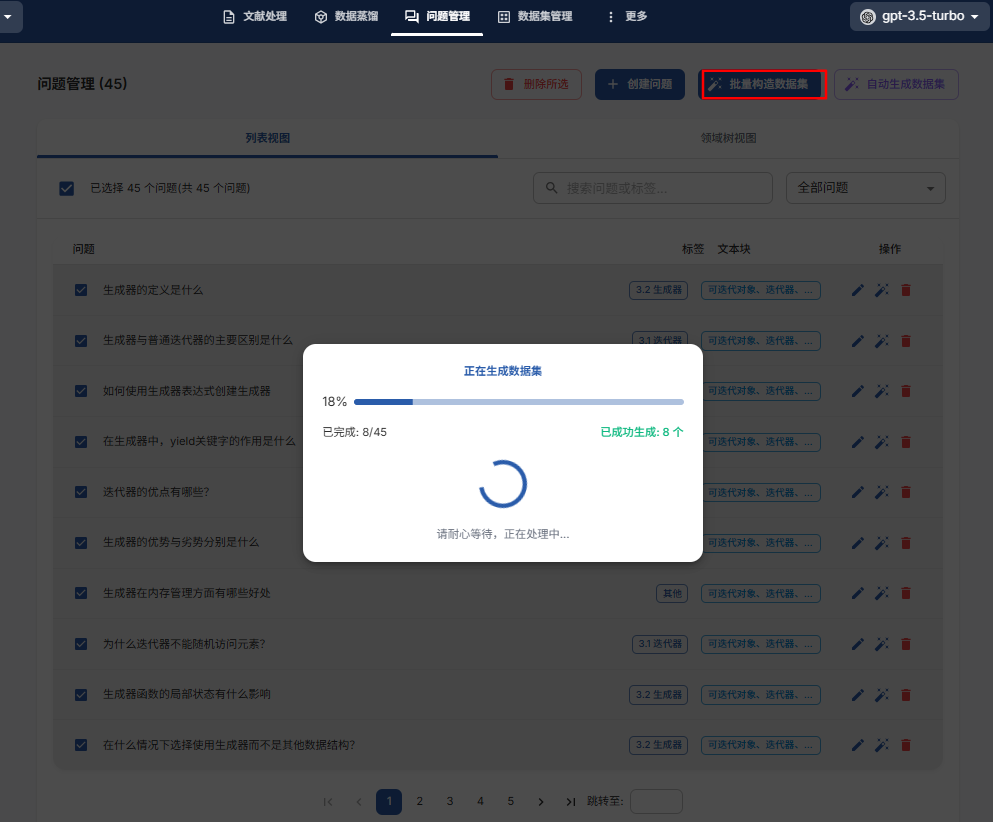
1. 基于问题“批量构造数据集”;
2. 使用配置的 LLM 生成答案;
3. 查看、编辑并优化生成的答案
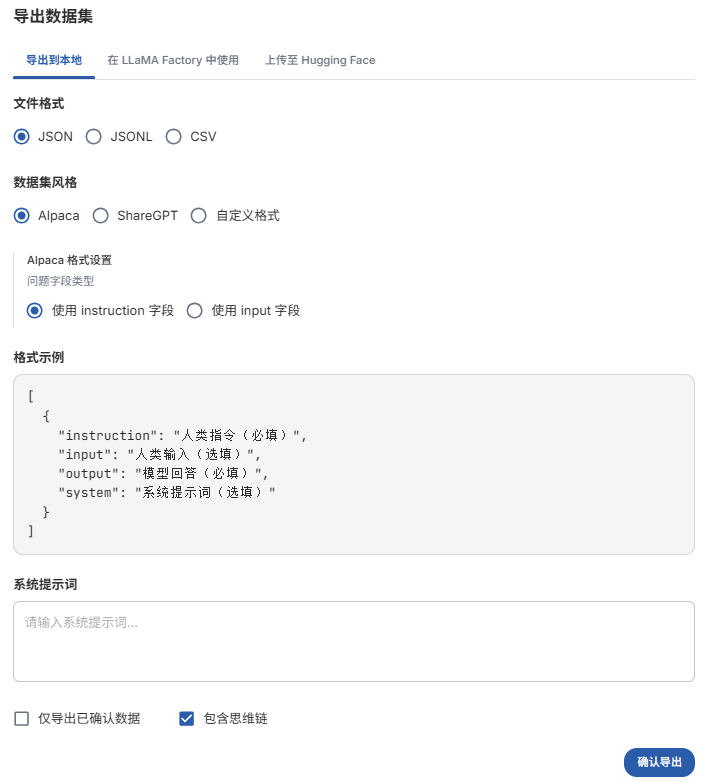
3.5、导出数据集
1. 在数据集管理页面,勾选问题,"导出数据集"按钮;
2. 选择您喜欢的格式(Alpaca 或 ShareGPT);
3. 选择文件格式(JSON 或 JSONL);
4. 根据需要添加自定义系统提示;
5. 导出您的数据集

四、参考
easy-dataset/README.zh-CN.md at main · ConardLi/easy-dataset
Easy Dataset × LLaMA Factory: 让大模型高效学习领域知识 - 飞书云文档
【2025最新】从0打造大模型 微调数据集,一键将领域知识转化为结构化数据集,使数据集构造过程变得简单高效!超详细讲解,原理详解+项目实战!_哔哩哔哩_bilibili