【PostgreSQL内核学习:哈希聚合(HashAgg)执行流程与函数调用关系分析】
PostgreSQL内核学习:HashAgg
- 引言
- 简单案例描述:使用哈希聚合处理 DISTINCT 查询
- 背景
- SQL 查询和数据集
- 执行计划分解
- 哈希聚合的工作原理总结
- 关键观察点:为什么选择 HashAgg?
- 源码解读
- create_agg_plan 函数
- 查询计划与函数的对应关系
- 总结
- ExecInitAgg 函数
- `ExecInitAgg` 函数的大致流程
- `ExecInitAgg` 函数的细化流程
- Mermaid 流程图
- ExecAgg 函数
- `ExecAgg` 函数的细化流程
- 示例查询关联
- Mermaid 流程图(细化分支逻辑)
- agg_fill_hash_table 函数
- 示例查询关联
- Mermaid 流程图(细化分支逻辑)
- lookup_hash_entries 函数
- 示例查询关联
- Mermaid 流程图(原始逻辑)
- hashagg_finish_initial_spills 函数
- 示例查询关联
- Mermaid 流程图(原始逻辑)
- agg_retrieve_hash_table 函数
- 示例查询关联
- Mermaid 流程图(原始逻辑)
- agg_retrieve_hash_table_in_memory 函数
- 示例查询关联
- Mermaid 流程图(原始逻辑)
- agg_retrieve_direct 函数
- 示例查询关联
- Mermaid 流程图(原始逻辑)
- 总结
- 函数名称与中文操作解释
- 示例查询关联(`SELECT DISTINCT a FROM t1 LIMIT 10`)
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-18 beta2 的开源代码和《PostgresSQL数据库内核分析》一书
引言
在关系型数据库的世界中,高效处理涉及分组和聚合的查询对于性能至关重要,尤其是在处理大规模数据集时。PostgreSQL 作为一个强大的开源数据库,提供了多种执行聚合查询的策略,其中之一就是哈希聚合(Hash Aggregation,通常称为 HashAgg)。这种机制通过使用内存中的哈希表来处理 GROUP BY、DISTINCT 以及聚合函数(如 COUNT、SUM、AVG 等),在特定场景下展现出卓越的性能。
哈希聚合在分组数量相对较少、输入数据量较大的情况下表现尤为出色,相比其他策略(如基于排序的 GroupAggregate),它在某些场景下能够显著提升性能。然而,其效率受到内存可用性、数据分布以及查询特性的影响。深入理解哈希聚合的工作原理、内部实现以及优缺点,对于数据库开发者、管理员以及希望优化查询性能的用户来说至关重要。
本文档旨在为 PostgreSQL 的哈希聚合提供一个全面的介绍。我们将探讨其核心概念、PostgreSQL 源代码中的实现细节、执行流程以及调优和优化的实际建议。无论你是 PostgreSQL 的贡献开发者、优化查询的数据库管理员,还是对数据库内部机制感兴趣的学习者,本文档都将为你提供深入理解和有效利用 HashAgg 的知识。
简单案例描述:使用哈希聚合处理 DISTINCT 查询
背景
在 PostgreSQL 中,SELECT DISTINCT 是一种常见的查询操作,用于从数据集中提取唯一值。当查询涉及 DISTINCT 且不包含 ORDER BY 或复杂的聚合函数时,PostgreSQL 优化器通常会选择哈希聚合(HashAgg) 策略,通过构建内存中的哈希表来高效去除重复值。本案例将通过一个具体的 SQL 查询,展示哈希聚合的工作原理,并分析其查询计划。
SQL 查询和数据集
DROP TABLE IF EXISTS t1;
CREATE TABLE t1 (a int, b text);INSERT INTO t1
SELECT (i % 100), md5(i::text)
FROM generate_series(1, 1000) g(i);
ANALYZE t1;-- 查询 SELECT DISTINCT a FROM t1 LIMIT 10 的目标是从 t1 表中提取 a 列的唯一值,并限制返回前 10 个结果。
-- 预期结果:返回 10 个不同的 a 值(例如 0 到 9),具体顺序可能因哈希聚合的无序性而变化。
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT DISTINCT a FROM t1 LIMIT 10;
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9Planning:Buffers: shared hit=5Planning Time: 0.131 msExecution Time: 0.767 ms
执行计划分解
-
顶层节点:
Limit- 作用:限制输出结果为前
10行。 - 成本:估计成本为
21.50..21.60,实际执行时间为0.723..0.728ms,返回 10 行。 - 说明:
Limit节点从其子节点(HashAggregate)获取数据,一旦收集到10行就停止处理,体现了PostgreSQL的优化能力(避免处理不必要的数据)。
- 作用:限制输出结果为前
-
中间节点:
HashAggregate- 作用:执行
DISTINCT操作,通过哈希聚合去除a列的重复值。 - 成本:估计成本为
21.50..22.50,实际执行时间为0.721..0.725 ms。 - 关键信息:
Group Key:t1.a:聚合基于a列进行,哈希表以a的值作为键。Batches: 1:表示所有数据都在内存中处理,未发生磁盘溢出(spill to disk)。Memory Usage: 24kB:哈希表使用了24kB的内存,远低于默认的work_mem(通常为4MB),说明数据量较小,内存足以容纳所有唯一值。
- 说明:
HashAggregate构建一个哈希表,将a列的每个唯一值存储为键。由于Limit节点限制了输出,HashAggregate在收集到10个唯一值后可能提前终止(如果优化器支持早停优化)。
- 作用:执行
-
底层节点:
Seq Scan- 作用:对表
t1执行顺序扫描,读取所有1000行数据。 - 成本:估计成本为
0.00..19.00,实际执行时间为0.018..0.198 ms。 - 缓冲区:
Buffers: shared hit=9表示读取了9个缓冲块(每个块8kB),数据可能已缓存。 - 说明:顺序扫描适合小表或无索引的场景,这里从
t1读取所有行并传递给HashAggregate。
- 作用:对表
-
规划和执行时间
Planning Time: 0.131 ms:查询规划时间短,表明优化器快速选择了合适的计划。Execution Time: 0.767 ms:总执行时间非常短,适合小规模数据。
哈希聚合的工作原理总结
哈希聚合(HashAgg)是 PostgreSQL 处理 GROUP BY 或 DISTINCT 查询的一种高效策略,通过在内存中构建哈希表来实现快速分组和去重。以示例查询 SELECT DISTINCT a FROM t1 LIMIT 10 为例,HashAgg 的工作机制包括以下步骤:首先,底层 Seq Scan 节点顺序读取表 t1 的 1000 行数据,提取 a 列值;然后,HashAggregate 节点为 a 列的每个值计算哈希值,插入到一个以 a 值作为键的哈希表中,若值已存在则跳过,从而实现去重;最后,Limit 节点从哈希表中获取前 10 个唯一值后停止处理。本例中,哈希表仅占用 24kB 内存(远低于 work_mem),无需磁盘溢出,执行时间仅为 0.725 毫秒,展现了哈希聚合在小规模唯一值场景下的高效性。
关键观察点:为什么选择 HashAgg?
优化器选择 HashAgg 的原因在于其对 DISTINCT 查询的高效支持和本例查询特性的契合。首先,查询使用 DISTINCT 且无 ORDER BY,适合用哈希表快速去重,而非基于排序的 GroupAggregate。其次,统计信息(通过 ANALYZE t1)显示 a 列有约 100 个唯一值,数量较小,哈希表内存占用低(24kB),无需磁盘溢出。此外,Limit 10 允许提前终止,进一步减少处理开销。相比排序策略,HashAgg 在无序输出和小规模分组场景下具有更低的计算复杂度和内存需求,因此成为优化器的首选。
源码解读
create_agg_plan 函数
以下是为 create_agg_plan 函数添加中文注释的代码版本,并结合示例查询 EXPLAIN (ANALYZE, BUFFERS, VERBOSE) SELECT DISTINCT a FROM t1 LIMIT 10; 解释每行代码的作用。注释将清晰说明函数的逻辑,并与查询计划关联,帮助大家来理解哈希聚合(HashAgg)计划的生成过程。
/** create_agg_plan** 创建一个 Agg 计划节点,用于实现最佳路径(best_path)及其子路径的递归计划。* 参数:* root - 规划器的全局信息,包含查询上下文和统计信息。* best_path - 优化器选择的最佳聚合路径(AggPath)。* 返回值:* Agg* - 创建的聚合计划节点。* * 作用:create_agg_plan 是优化器中生成聚合计划的入口函数。root 包含查询的全局上下文(如 t1 表的统计信息),best_path 是优化器选择的最佳路径(本例中为 AggPath,指定了 HashAggregate 策略)。* 查询关联:对于 SELECT DISTINCT a FROM t1 LIMIT 10,优化器分析查询后确定使用 HashAggregate(因为 DISTINCT 无 ORDER BY),并通过 AggPath 传递聚合策略和子路径(Seq Scan)。*/
static Agg *
create_agg_plan(PlannerInfo *root, AggPath *best_path)
{Agg *plan; // 聚合计划节点Plan *subplan; // 子计划(底层扫描或连接计划)List *tlist; // 目标列表(输出列)List *quals; // 限定条件(WHERE 或 HAVING 子句)/** Agg 节点可以投影输出,因此对子计划的目标列表要求不严格,* 但需要确保分组列(grouping columns)在子计划中可用。*/subplan = create_plan_recurse(root, best_path->subpath, CP_LABEL_TLIST);/** 构建 Agg 计划节点的目标列表,基于最佳路径的输出列。*/tlist = build_path_tlist(root, &best_path->path);/** 对限定条件(qual)进行排序和优化,确保执行时高效。*/quals = order_qual_clauses(root, best_path->qual);/** 调用 make_agg 创建 Agg 计划节点,设置聚合策略、分组列等属性。* 参数说明:* tlist - 目标列表,定义输出列。* quals - 限定条件(如 HAVING)。* aggstrategy - 聚合策略(例如 AGG_HASHED 或 AGG_SORTED)。* aggsplit - 聚合拆分级别(例如普通聚合或最终聚合)。* list_length(best_path->groupClause) - 分组列数量。* extract_grouping_cols - 提取分组列的索引。* extract_grouping_ops - 提取分组操作符(如 =)。* extract_grouping_collations - 提取分组列的排序规则。* NIL - 分组集(grouping sets),本例中为空。* NIL - 链式聚合节点(chained agg nodes),本例中为空。* numGroups - 估计的分组数量。* transitionSpace - 聚合过渡状态的内存需求。* subplan - 子计划(例如 Seq Scan)。*/plan = make_agg(tlist, quals,best_path->aggstrategy,best_path->aggsplit,list_length(best_path->groupClause),extract_grouping_cols(best_path->groupClause,subplan->targetlist),extract_grouping_ops(best_path->groupClause),extract_grouping_collations(best_path->groupClause,subplan->targetlist),NIL,NIL,best_path->numGroups,best_path->transitionSpace,subplan);/** 将最佳路径的通用信息(如成本、行数估计)复制到 Agg 计划节点。*/copy_generic_path_info(&plan->plan, (Path *) best_path);/** 返回创建的 Agg 计划节点。*/return plan;
}
打印堆栈信息:
(gdb) bt
#0 create_agg_plan (root=0x1bed5e8, best_path=0x1cea0e0) at createplan.c:2313
#1 0x000000000088f61f in create_plan_recurse (root=0x1bed5e8, best_path=0x1cea0e0, flags=1) at createplan.c
:510
#2 0x00000000008939d8 in create_limit_plan (root=0x1bed5e8, best_path=0x1cea470, flags=1) at createplan.c:2
914
#3 0x000000000088f6cd in create_plan_recurse (root=0x1bed5e8, best_path=0x1cea470, flags=1) at createplan.c
:537
#4 0x000000000088f277 in create_plan (root=0x1bed5e8, best_path=0x1cea470) at createplan.c:350
#5 0x00000000008a2f2b in standard_planner (parse=0x1becbd8, query_string=0x1bebc30 "SELECT DISTINCT a FROM
t1 LIMIT 10;", cursorOptions=2048, boundParams=0x0) at planner.c:421
#6 0x00000000008a2c84 in planner (parse=0x1becbd8, query_string=0x1bebc30 "SELECT DISTINCT a FROM t1 LIMIT
10;", cursorOptions=2048, boundParams=0x0) at planner.c:282
#7 0x00000000009e3cfb in pg_plan_query (querytree=0x1becbd8, query_string=0x1bebc30 "SELECT DISTINCT a FROMt1 LIMIT 10;", cursorOptions=2048, boundParams=0x0) at postgres.c:912
#8 0x00000000009e3e8e in pg_plan_queries (querytrees=0x1bed598, query_string=0x1bebc30 "SELECT DISTINCT a F
ROM t1 LIMIT 10;", cursorOptions=2048, boundParams=0x0) at postgres.c:1006
#9 0x00000000009e420d in exec_simple_query (query_string=0x1bebc30 "SELECT DISTINCT a FROM t1 LIMIT 10;") a
t postgres.c:1203
#10 0x00000000009e8cb9 in PostgresMain (dbname=0x1c24050 "postgres", username=0x1c24038 "kuchiki") at postgr
es.c:4766
#11 0x00000000009e089e in BackendMain (startup_data=0x7fff47d0585c "", startup_data_len=4) at backend_startu
p.c:107
#12 0x000000000090d681 in postmaster_child_launch (child_type=B_BACKEND, startup_data=0x7fff47d0585c "", sta
rtup_data_len=4, client_sock=0x7fff47d05880) at launch_backend.c:274
#13 0x0000000000912a76 in BackendStartup (client_sock=0x7fff47d05880) at postmaster.c:3414
#14 0x0000000000910549 in ServerLoop () at postmaster.c:1648
#15 0x000000000090ff12 in PostmasterMain (argc=3, argv=0x1be67e0) at postmaster.c:1346
#16 0x00000000007d1de4 in main (argc=3, argv=0x1be67e0) at main.c:197
以下是 create_agg_plan 函数中每行代码如何与该查询的计划生成相关联的详细解释:
-
函数签名和参数:
static Agg *create_agg_plan(PlannerInfo *root, AggPath *best_path)- 作用:
create_agg_plan是优化器中生成聚合计划的入口函数。root包含查询的全局上下文(如t1表的统计信息),best_path是优化器选择的最佳路径(本例中为AggPath,指定了HashAggregate策略)。 - 查询关联:对于
SELECT DISTINCT a FROM t1 LIMIT 10,优化器分析查询后确定使用HashAggregate(因为DISTINCT无ORDER BY),并通过AggPath传递聚合策略和子路径(Seq Scan)。
- 作用:
-
变量声明:
Agg *plan; Plan *subplan; List *tlist; List *quals;- 作用:声明变量用于存储聚合计划节点 (
plan)、子计划 (subplan)、目标列表 (tlist) 和限定条件 (quals)。 - 查询关联:
plan将成为HashAggregate节点,subplan对应Seq Scan on public.t1,tlist包含输出列a,quals本例中为空(无HAVING或WHERE)。
- 作用:声明变量用于存储聚合计划节点 (
-
创建子计划:
subplan = create_plan_recurse(root, best_path->subpath, CP_LABEL_TLIST);- 作用:递归调用
create_plan_recurse为子路径(best_path->subpath)生成计划。CP_LABEL_TLIST确保子计划的目标列表包含分组所需的列(本例中为t1.a)。 - 查询关联:子路径是一个
Seq Scan路径,生成Seq Scan on public.t1节点,读取表t1的1000行数据(rows=1000),输出列a和b(尽管b未在DISTINCT中使用)。
- 作用:递归调用
-
构建目标列表:
tlist = build_path_tlist(root, &best_path->path);- 作用:基于
best_path的路径信息,构建Agg计划节点的目标列表,定义输出列。 - 查询关联:目标列表包含
t1.a(Output: a),因为查询仅需要DISTINCT a的结果。build_path_tlist确保输出符合SELECT DISTINCT a的要求。
- 作用:基于
-
优化限定条件:
quals = order_qual_clauses(root, best_path->qual);- 作用:对限定条件(
best_path->qual)进行排序和优化,确保执行时高效。本例中qual为空(无WHERE或HAVING)。 - 查询关联:查询没有限定条件,因此
quals为空,HashAggregate直接处理Seq Scan的输出。
- 作用:对限定条件(
-
创建 Agg 节点:
plan = make_agg(tlist, quals,best_path->aggstrategy,best_path->aggsplit,list_length(best_path->groupClause),extract_grouping_cols(best_path->groupClause, subplan->targetlist),extract_grouping_ops(best_path->groupClause),extract_grouping_collations(best_path->groupClause, subplan->targetlist),NIL,NIL,best_path->numGroups,best_path->transitionSpace,subplan);- 作用:调用
make_agg创建Agg计划节点,设置聚合策略、分组列、操作符、排序规则、分组数量、过渡空间等属性。 - 查询关联:
tlist:包含t1.a。quals:为空。aggstrategy:AGG_HASHED(对应HashAggregate)。aggsplit:普通聚合(无拆分)。list_length(best_path->groupClause):分组列数量为 1(t1.a)。extract_grouping_cols:提取t1.a的列索引(Group Key: t1.a)。extract_grouping_ops:分组操作符为=。extract_grouping_collations:排序规则(本例中为默认)。NIL:无分组集或链式聚合。numGroups:估计100个唯一值(rows=100)。transitionSpace:聚合过渡状态的内存需求(本例中较小)。subplan:Seq Scan节点。
- 结果:生成
HashAggregate节点,计划输出100行(rows=100),实际因Limit 10仅输出10行。
- 作用:调用
-
复制路径信息:
copy_generic_path_info(&plan->plan, (Path *) best_path);- 作用:将
best_path的通用信息(如成本、行数估计)复制到Agg计划节点,确保计划的成本和行数预测准确。 - 查询关联:
HashAggregate的成本为21.50..22.50,行数估计为100,与best_path的估计一致。
- 作用:将
-
返回计划节点:
return plan;- 作用:返回创建的
Agg计划节点,供上层节点(如Limit)使用。 - 查询关联:
HashAggregate节点被Limit节点包裹,最终形成查询计划。
- 作用:返回创建的
查询计划与函数的对应关系
-
整体流程:
create_agg_plan是优化器中生成HashAggregate节点的核心函数。示例查询的DISTINCT a触发了AggPath的选择(AGG_HASHED策略),create_agg_plan将其转换为可执行的Agg计划节点。- 查询计划的
HashAggregate节点由make_agg创建,Seq Scan节点由create_plan_recurse生成。
-
关键点:
- 子计划生成:
create_plan_recurse生成了Seq Scan on public.t1,读取1000行数据。 - 目标列表:
tlist确保HashAggregate输出t1.a,符合SELECT DISTINCT a。 - 聚合策略:
best_path->aggstrategy = AGG_HASHED决定了使用哈希表去重,计划显示Batches: 1, Memory Usage: 24kB。
- 子计划生成:
总结
通过为 create_agg_plan 添加中文注释,并结合示例查询 SELECT DISTINCT a FROM t1 LIMIT 10,我们可以清晰地看到 PostgreSQL 如何将优化器的 AggPath 转换为可执行的 HashAggregate 计划节点。
ExecInitAgg 函数
ExecInitAgg 是 PostgreSQL 中用于初始化聚合节点(Agg)运行时状态(AggState)的核心函数,负责为聚合操作(如 GROUP BY、DISTINCT 或聚合函数)设置执行环境。它处理哈希聚合(HashAgg)、排序聚合(SortedAgg)或混合模式(MixedAgg),并初始化子计划、表达式上下文、哈希表和聚合函数的运行时数据。以下是为 ExecInitAgg 函数添加中文注释的代码版本
/** ExecInitAgg** 创建聚合节点的运行时状态(AggState),并初始化其子计划树。* 参数:* node - 规划器生成的聚合计划节点(Agg)* estate - 执行状态,包含查询的全局上下文* eflags - 执行标志,控制节点行为* 返回值:* AggState* - 初始化的聚合节点运行时状态*/
AggState *
ExecInitAgg(Agg *node, EState *estate, int eflags)
{AggState *aggstate; // 聚合节点的运行时状态AggStatePerAgg peraggs; // 每个聚合函数的状态数组AggStatePerTrans pertransstates; // 每个转换状态的状态数组AggStatePerGroup *pergroups; // 每个分组的状态数组Plan *outerPlan; // 子计划(外层计划)ExprContext *econtext; // 表达式上下文TupleDesc scanDesc; // 输入元组的描述符int max_aggno; // 最大聚合函数编号int max_transno; // 最大转换状态编号int numaggrefs; // 聚合函数引用总数int numaggs; // 唯一聚合函数数量int numtrans; // 唯一转换状态数量int phase; // 当前阶段int phaseidx; // 阶段索引ListCell *l; // 列表迭代器Bitmapset *all_grouped_cols = NULL; // 所有分组列的位图集int numGroupingSets = 1; // 分组集数量,默认为 1int numPhases; // 阶段总数int numHashes; // 哈希聚合阶段数量int i = 0; // 循环计数器int j = 0; // 循环计数器bool use_hashing = (node->aggstrategy == AGG_HASHED ||node->aggstrategy == AGG_MIXED); // 是否使用哈希聚合/* 检查不支持的执行标志 */Assert(!(eflags & (EXEC_FLAG_BACKWARD | EXEC_FLAG_MARK)));/** 创建聚合状态结构*/aggstate = makeNode(AggState); // 分配并初始化 AggState 节点aggstate->ss.ps.plan = (Plan *) node; // 设置计划节点aggstate->ss.ps.state = estate; // 设置执行状态aggstate->ss.ps.ExecProcNode = ExecAgg; // 设置执行函数为 ExecAggaggstate->aggs = NIL; // 初始化聚合函数列表为空aggstate->numaggs = 0; // 初始化聚合函数数量为 0aggstate->numtrans = 0; // 初始化转换状态数量为 0aggstate->aggstrategy = node->aggstrategy; // 设置聚合策略(如 AGG_HASHED)aggstate->aggsplit = node->aggsplit; // 设置聚合拆分模式aggstate->maxsets = 0; // 初始化最大分组集数量aggstate->projected_set = -1; // 初始化当前投影分组集aggstate->current_set = 0; // 初始化当前分组集aggstate->peragg = NULL; // 初始化每个聚合函数的状态aggstate->pertrans = NULL; // 初始化每个转换状态aggstate->curperagg = NULL; // 初始化当前聚合函数aggstate->curpertrans = NULL; // 初始化当前转换状态aggstate->input_done = false; // 初始化输入未完成aggstate->agg_done = false; // 初始化聚合未完成aggstate->pergroups = NULL; // 初始化分组状态数组aggstate->grp_firstTuple = NULL; // 初始化分组的首元组aggstate->sort_in = NULL; // 初始化排序输入aggstate->sort_out = NULL; // 初始化排序输出/** phases[0] 在排序/普通模式下为虚拟阶段,哈希模式下为实际阶段*/numPhases = (use_hashing ? 1 : 2); // 哈希模式为 1 阶段,排序模式为 2 阶段numHashes = (use_hashing ? 1 : 0); // 哈希模式为 1 个哈希阶段,否则为 0/** 计算最大分组集数量,决定内存分配大小,并计算阶段总数。* 哈希/混合模式的节点只贡献一个阶段。*/if (node->groupingSets){numGroupingSets = list_length(node->groupingSets); // 获取分组集数量foreach(l, node->chain){Agg *agg = lfirst(l); // 获取链式聚合节点numGroupingSets = Max(numGroupingSets,list_length(agg->groupingSets)); // 更新最大分组集数量/** 额外的 AGG_HASHED 节点属于阶段 0,其他节点增加一个阶段*/if (agg->aggstrategy != AGG_HASHED)++numPhases; // 非哈希策略增加阶段else++numHashes; // 哈希策略增加哈希阶段}}aggstate->maxsets = numGroupingSets; // 设置最大分组集数量aggstate->numphases = numPhases; // 设置阶段总数aggstate->aggcontexts = (ExprContext **)palloc0(sizeof(ExprContext *) * numGroupingSets); // 为每个分组集分配表达式上下文数组/** 创建表达式上下文:包括输入元组处理、输出元组处理、哈希表和每个分组集的上下文。* 使用 ExecAssignExprContext 统一创建。*/ExecAssignExprContext(estate, &aggstate->ss.ps); // 创建主表达式上下文aggstate->tmpcontext = aggstate->ss.ps.ps_ExprContext; // 保存临时上下文for (i = 0; i < numGroupingSets; ++i){ExecAssignExprContext(estate, &aggstate->ss.ps); // 为每个分组集创建上下文aggstate->aggcontexts[i] = aggstate->ss.ps.ps_ExprContext; // 存储上下文}if (use_hashing)aggstate->hashcontext = CreateWorkExprContext(estate); // 为哈希聚合创建专用上下文ExecAssignExprContext(estate, &aggstate->ss.ps); // 创建额外的表达式上下文/** 初始化子节点。* 若为哈希聚合,子计划无需高效支持 REWIND(重置)。*/if (node->aggstrategy == AGG_HASHED)eflags &= ~EXEC_FLAG_REWIND; // 禁用 REWIND 标志outerPlan = outerPlan(node); // 获取外层计划outerPlanState(aggstate) = ExecInitNode(outerPlan, estate, eflags); // 初始化子计划/** 初始化输入元组类型*/aggstate->ss.ps.outerops =ExecGetResultSlotOps(outerPlanState(&aggstate->ss),&aggstate->ss.ps.outeropsfixed); // 获取子计划的结果槽操作aggstate->ss.ps.outeropsset = true; // 标记结果槽操作已设置ExecCreateScanSlotFromOuterPlan(estate, &aggstate->ss,aggstate->ss.ps.outerops); // 创建扫描槽scanDesc = aggstate->ss.ss_ScanTupleSlot->tts_tupleDescriptor; // 获取输入元组描述符/** 如果阶段数超过 2(包含虚拟阶段 0),需要排序元组,分配排序槽*/if (numPhases > 2){aggstate->sort_slot = ExecInitExtraTupleSlot(estate, scanDesc,&TTSOpsMinimalTuple); // 创建排序用的额外元组槽/** 子计划输出可能与排序输出槽类型不同,调整 outerops 设置*/if (aggstate->ss.ps.outeropsfixed &&aggstate->ss.ps.outerops != &TTSOpsMinimalTuple)aggstate->ss.ps.outeropsfixed = false; // 禁用固定操作标志}/** 初始化结果类型、槽和投影信息*/ExecInitResultTupleSlotTL(&aggstate->ss.ps, &TTSOpsVirtual); // 初始化结果元组槽ExecAssignProjectionInfo(&aggstate->ss.ps, NULL); // 设置投影信息/** 初始化子表达式。* 确保没有嵌套聚合函数(由解析器检查),并查找限定条件中的 Aggref。*/aggstate->ss.ps.qual =ExecInitQual(node->plan.qual, (PlanState *) aggstate); // 初始化限定条件/** 计算唯一聚合函数和转换状态数量*/numaggrefs = list_length(aggstate->aggs); // 获取聚合函数引用总数max_aggno = -1; // 初始化最大聚合函数编号max_transno = -1; // 初始化最大转换状态编号foreach(l, aggstate->aggs){Aggref *aggref = (Aggref *) lfirst(l); // 获取聚合函数引用max_aggno = Max(max_aggno, aggref->aggno); // 更新最大聚合函数编号max_transno = Max(max_transno, aggref->aggtransno); // 更新最大转换状态编号}numaggs = max_aggno + 1; // 计算唯一聚合函数数量numtrans = max_transno + 1; // 计算唯一转换状态数量/** 为每个阶段准备分组集数据和比较函数的查找数据,同时累积分组列*/aggstate->phases = palloc0(numPhases * sizeof(AggStatePerPhaseData)); // 分配阶段数据数组aggstate->num_hashes = numHashes; // 设置哈希阶段数量if (numHashes){aggstate->perhash = palloc0(sizeof(AggStatePerHashData) * numHashes); // 分配哈希阶段数据aggstate->phases[0].numsets = 0; // 初始化阶段 0 的分组集数量aggstate->phases[0].gset_lengths = palloc(numHashes * sizeof(int)); // 分配分组集长度数组aggstate->phases[0].grouped_cols = palloc(numHashes * sizeof(Bitmapset *)); // 分配分组列位图数组}phase = 0; // 初始化阶段索引for (phaseidx = 0; phaseidx <= list_length(node->chain); ++phaseidx){Agg *aggnode; // 当前聚合节点Sort *sortnode; // 排序节点(若有)if (phaseidx > 0){aggnode = list_nth_node(Agg, node->chain, phaseidx - 1); // 获取链式聚合节点sortnode = castNode(Sort, outerPlan(aggnode)); // 获取排序节点}else{aggnode = node; // 使用当前聚合节点sortnode = NULL; // 阶段 0 无排序}Assert(phase <= 1 || sortnode); // 确保非阶段 0 有排序节点if (aggnode->aggstrategy == AGG_HASHED || aggnode->aggstrategy == AGG_MIXED){AggStatePerPhase phasedata = &aggstate->phases[0]; // 阶段 0 数据AggStatePerHash perhash; // 哈希阶段数据Bitmapset *cols = NULL; // 分组列位图Assert(phase == 0); // 哈希聚合只在阶段 0i = phasedata->numsets++; // 增加分组集计数perhash = &aggstate->perhash[i]; // 获取哈希阶段数据phasedata->aggnode = node; // 设置阶段 0 的聚合节点phasedata->aggstrategy = node->aggstrategy; // 设置聚合策略perhash->aggnode = aggnode; // 保存实际聚合节点phasedata->gset_lengths[i] = perhash->numCols = aggnode->numCols; // 设置分组列数量for (j = 0; j < aggnode->numCols; ++j)cols = bms_add_member(cols, aggnode->grpColIdx[j]); // 添加分组列phasedata->grouped_cols[i] = cols; // 保存分组列位图all_grouped_cols = bms_add_members(all_grouped_cols, cols); // 累积所有分组列continue;}else{AggStatePerPhase phasedata = &aggstate->phases[++phase]; // 下一个阶段数据int num_sets; // 分组集数量phasedata->numsets = num_sets = list_length(aggnode->groupingSets); // 设置分组集数量if (num_sets){phasedata->gset_lengths = palloc(num_sets * sizeof(int)); // 分配分组集长度数组phasedata->grouped_cols = palloc(num_sets * sizeof(Bitmapset *)); // 分配分组列位图数组i = 0;foreach(l, aggnode->groupingSets){int current_length = list_length(lfirst(l)); // 当前分组集的列数Bitmapset *cols = NULL; // 分组列位图for (j = 0; j < current_length; ++j)cols = bms_add_member(cols, aggnode->grpColIdx[j]); // 添加分组列phasedata->grouped_cols[i] = cols; // 保存分组列位图phasedata->gset_lengths[i] = current_length; // 保存分组集长度++i;}all_grouped_cols = bms_add_members(all_grouped_cols,phasedata->grouped_cols[0]); // 累积分组列}else{Assert(phaseidx == 0); // 阶段 0 无分组集phasedata->gset_lengths = NULL; // 无分组集长度phasedata->grouped_cols = NULL; // 无分组列位图}/** 为排序聚合预计算比较函数的查找数据*/if (aggnode->aggstrategy == AGG_SORTED){phasedata->eqfunctions =(ExprState **) palloc0(aggnode->numCols * sizeof(ExprState *)); // 分配比较函数数组for (int k = 0; k < phasedata->numsets; k++){int length = phasedata->gset_lengths[k]; // 分组集列数if (length == 0)continue; // 空分组集跳过if (phasedata->eqfunctions[length - 1] != NULL)continue; // 已存在的长度跳过phasedata->eqfunctions[length - 1] =execTuplesMatchPrepare(scanDesc,length,aggnode->grpColIdx,aggnode->grpOperators,aggnode->grpCollations,(PlanState *) aggstate); // 准备比较函数}if (aggnode->numCols > 0 &&phasedata->eqfunctions[aggnode->numCols - 1] == NULL){phasedata->eqfunctions[aggnode->numCols - 1] =execTuplesMatchPrepare(scanDesc,aggnode->numCols,aggnode->grpColIdx,aggnode->grpOperators,aggnode->grpCollations,(PlanState *) aggstate); // 为所有分组列准备比较函数}}phasedata->aggnode = aggnode; // 设置阶段的聚合节点phasedata->aggstrategy = aggnode->aggstrategy; // 设置聚合策略phasedata->sortnode = sortnode; // 设置排序节点}}/** 将所有分组列转换为降序列表*/i = -1;while ((i = bms_next_member(all_grouped_cols, i)) >= 0)aggstate->all_grouped_cols = lcons_int(i, aggstate->all_grouped_cols); // 添加分组列到列表/** 设置聚合结果存储和每个聚合函数的工作存储*/econtext = aggstate->ss.ps.ps_ExprContext; // 获取表达式上下文econtext->ecxt_aggvalues = (Datum *) palloc0(sizeof(Datum) * numaggs); // 分配聚合值存储econtext->ecxt_aggnulls = (bool *) palloc0(sizeof(bool) * numaggs); // 分配聚合空值标志peraggs = (AggStatePerAgg) palloc0(sizeof(AggStatePerAggData) * numaggs); // 分配每个聚合函数状态pertransstates = (AggStatePerTrans) palloc0(sizeof(AggStatePerTransData) * numtrans); // 分配每个转换状态aggstate->peragg = peraggs; // 设置聚合函数状态数组aggstate->pertrans = pertransstates; // 设置转换状态数组aggstate->all_pergroups =(AggStatePerGroup *) palloc0(sizeof(AggStatePerGroup)* (numGroupingSets + numHashes)); // 分配所有分组状态pergroups = aggstate->all_pergroups; // 设置分组状态指针if (node->aggstrategy != AGG_HASHED){for (i = 0; i < numGroupingSets; i++){pergroups[i] = (AggStatePerGroup) palloc0(sizeof(AggStatePerGroupData)* numaggs); // 为每个分组集分配状态}aggstate->pergroups = pergroups; // 设置分组状态数组pergroups += numGroupingSets; // 更新指针}/** 为哈希聚合初始化哈希表相关结构*/if (use_hashing){Plan *outerplan = outerPlan(node); // 获取外层计划uint64 totalGroups = 0; // 总分组数aggstate->hash_metacxt = AllocSetContextCreate(aggstate->ss.ps.state->es_query_cxt,"HashAgg meta context",ALLOCSET_DEFAULT_SIZES); // 创建哈希聚合元上下文aggstate->hash_spill_rslot = ExecInitExtraTupleSlot(estate, scanDesc,&TTSOpsMinimalTuple); // 创建溢出读取槽aggstate->hash_spill_wslot = ExecInitExtraTupleSlot(estate, scanDesc,&TTSOpsVirtual); // 创建溢出写入槽aggstate->hash_pergroup = pergroups; // 设置哈希分组状态aggstate->hashentrysize = hash_agg_entry_size(aggstate->numtrans,outerplan->plan_width,node->transitionSpace); // 计算哈希表条目大小/** 综合所有分组集设置内存限制和分区估计*/for (int k = 0; k < aggstate->num_hashes; k++)totalGroups += aggstate->perhash[k].aggnode->numGroups; // 累积分组数hash_agg_set_limits(aggstate->hashentrysize, totalGroups, 0,&aggstate->hash_mem_limit,&aggstate->hash_ngroups_limit,&aggstate->hash_planned_partitions); // 设置哈希表限制find_hash_columns(aggstate); // 查找哈希列/* 仅在非 EXPLAIN 模式下分配哈希表 */if (!(eflags & EXEC_FLAG_EXPLAIN_ONLY))build_hash_tables(aggstate); // 构建哈希表aggstate->table_filled = false; // 标记哈希表未填充aggstate->hash_batches_used = 1; // 初始化批次为 1(未溢出)}/** 初始化当前阶段,哈希模式为阶段 0,排序模式为阶段 1*/if (node->aggstrategy == AGG_HASHED){aggstate->current_phase = 0; // 设置哈希模式为阶段 0initialize_phase(aggstate, 0); // 初始化阶段 0select_current_set(aggstate, 0, true); // 选择当前分组集}else{aggstate->current_phase = 1; // 设置排序模式为阶段 1initialize_phase(aggstate, 1); // 初始化阶段 1select_current_set(aggstate, 0, false); // 选择当前分组集}/** 查找聚合函数信息,初始化每个聚合和转换状态的不变字段*/foreach(l, aggstate->aggs){Aggref *aggref = lfirst(l); // 获取聚合函数引用AggStatePerAgg peragg; // 当前聚合函数状态AggStatePerTrans pertrans; // 当前转换状态Oid aggTransFnInputTypes[FUNC_MAX_ARGS]; // 聚合输入类型int numAggTransFnArgs; // 转换函数参数数量int numDirectArgs; // 直接参数数量HeapTuple aggTuple; // 聚合函数元组Form_pg_aggregate aggform; // 聚合函数元数据AclResult aclresult; // 权限检查结果Oid finalfn_oid; // 最终函数 OIDOid serialfn_oid, deserialfn_oid; // 序列化/反序列化函数 OIDOid aggOwner; // 聚合函数所有者Expr *finalfnexpr; // 最终函数表达式Oid aggtranstype; // 转换状态类型/* 规划器应确保聚合在正确级别 */Assert(aggref->agglevelsup == 0);/* 拆分模式应匹配 */Assert(aggref->aggsplit == aggstate->aggsplit);peragg = &peraggs[aggref->aggno]; // 获取聚合函数状态/* 检查是否已初始化该聚合状态 */if (peragg->aggref != NULL)continue;peragg->aggref = aggref; // 设置聚合函数引用peragg->transno = aggref->aggtransno; // 设置转换状态编号/* 获取 pg_aggregate 元数据 */aggTuple = SearchSysCache1(AGGFNOID, ObjectIdGetDatum(aggref->aggfnoid));if (!HeapTupleIsValid(aggTuple))elog(ERROR, "cache lookup failed for aggregate %u", aggref->aggfnoid);aggform = (Form_pg_aggregate) GETSTRUCT(aggTuple); // 获取聚合元数据/* 检查调用聚合函数的权限 */aclresult = object_aclcheck(ProcedureRelationId, aggref->aggfnoid, GetUserId(),ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_AGGREGATE, get_func_name(aggref->aggfnoid));InvokeFunctionExecuteHook(aggref->aggfnoid); // 调用执行钩子/* 从 Aggref 获取转换状态类型 */aggtranstype = aggref->aggtranstype;Assert(OidIsValid(aggtranstype));/* 如果不需要最终化,则无需最终函数 */if (DO_AGGSPLIT_SKIPFINAL(aggstate->aggsplit))peragg->finalfn_oid = finalfn_oid = InvalidOid;elseperagg->finalfn_oid = finalfn_oid = aggform->aggfinalfn; // 设置最终函数serialfn_oid = InvalidOid; // 初始化序列化函数deserialfn_oid = InvalidOid; // 初始化反序列化函数/** 检查是否需要序列化/反序列化,仅对 INTERNAL 类型有效*/if (aggtranstype == INTERNALOID){if (DO_AGGSPLIT_SERIALIZE(aggstate->aggsplit)){Assert(DO_AGGSPLIT_SKIPFINAL(aggstate->aggsplit)); // 序列化时不应最终化if (!OidIsValid(aggform->aggserialfn))elog(ERROR, "serialfunc not provided for serialization aggregation");serialfn_oid = aggform->aggserialfn; // 设置序列化函数}if (DO_AGGSPLIT_DESERIALIZE(aggstate->aggsplit)){Assert(DO_AGGSPLIT_COMBINE(aggstate->aggsplit)); // 反序列化时需组合if (!OidIsValid(aggform->aggdeserialfn))elog(ERROR, "deserialfunc not provided for deserialization aggregation");deserialfn_oid = aggform->aggdeserialfn; // 设置反序列化函数}}/* 检查聚合函数所有者对组件函数的权限 */{HeapTuple procTuple; // 函数元组procTuple = SearchSysCache1(PROCOID, ObjectIdGetDatum(aggref->aggfnoid));if (!HeapTupleIsValid(procTuple))elog(ERROR, "cache lookup failed for function %u", aggref->aggfnoid);aggOwner = ((Form_pg_proc) GETSTRUCT(procTuple))->proowner; // 获取函数所有者ReleaseSysCache(procTuple);if (OidIsValid(finalfn_oid)){aclresult = object_aclcheck(ProcedureRelationId, finalfn_oid, aggOwner,ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_FUNCTION, get_func_name(finalfn_oid));InvokeFunctionExecuteHook(finalfn_oid);}if (OidIsValid(serialfn_oid)){aclresult = object_aclcheck(ProcedureRelationId, serialfn_oid, aggOwner,ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_FUNCTION, get_func_name(serialfn_oid));InvokeFunctionExecuteHook(serialfn_oid);}if (OidIsValid(deserialfn_oid)){aclresult = object_aclcheck(ProcedureRelationId, deserialfn_oid, aggOwner,ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_FUNCTION, get_func_name(deserialfn_oid));InvokeFunctionExecuteHook(deserialfn_oid);}}/** 获取聚合函数的实际输入类型,可能与声明类型不同*/numAggTransFnArgs = get_aggregate_argtypes(aggref, aggTransFnInputTypes);/* 计算直接参数数量 */numDirectArgs = list_length(aggref->aggdirectargs);/* 计算最终函数的参数数量 */if (aggform->aggfinalextra)peragg->numFinalArgs = numAggTransFnArgs + 1;elseperagg->numFinalArgs = numDirectArgs + 1;/* 初始化直接参数表达式 */peragg->aggdirectargs = ExecInitExprList(aggref->aggdirectargs,(PlanState *) aggstate);/** 为最终函数构建表达式树(如果需要)*/if (OidIsValid(finalfn_oid)){build_aggregate_finalfn_expr(aggTransFnInputTypes,peragg->numFinalArgs,aggtranstype,aggref->aggtype,aggref->inputcollid,finalfn_oid,&finalfnexpr);fmgr_info(finalfn_oid, &peragg->finalfn); // 设置最终函数信息fmgr_info_set_expr((Node *) finalfnexpr, &peragg->finalfn); // 设置最终函数表达式}/* 获取输出值的数据类型信息 */get_typlenbyval(aggref->aggtype,&peragg->resulttypeLen,&peragg->resulttypeByVal);/** 为转换函数构建工作状态(如果尚未初始化)*/pertrans = &pertransstates[aggref->aggtransno];if (pertrans->aggref == NULL){Datum textInitVal; // 初始值文本Datum initValue; // 初始值bool initValueIsNull; // 初始值是否为空Oid transfn_oid; // 转换函数 OID/* 根据聚合模式选择转换或组合函数 */if (DO_AGGSPLIT_COMBINE(aggstate->aggsplit)){transfn_oid = aggform->aggcombinefn;if (!OidIsValid(transfn_oid))elog(ERROR, "combinefn not set for aggregate function");}elsetransfn_oid = aggform->aggtransfn;/* 检查转换函数权限 */aclresult = object_aclcheck(ProcedureRelationId, transfn_oid, aggOwner, ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_FUNCTION, get_func_name(transfn_oid));InvokeFunctionExecuteHook(transfn_oid);/* 获取初始值 */textInitVal = SysCacheGetAttr(AGGFNOID, aggTuple,Anum_pg_aggregate_agginitval,&initValueIsNull);if (initValueIsNull)initValue = (Datum) 0;elseinitValue = GetAggInitVal(textInitVal, aggtranstype);if (DO_AGGSPLIT_COMBINE(aggstate->aggsplit)){Oid combineFnInputTypes[] = {aggtranstype, aggtranstype}; // 组合函数输入类型pertrans->numTransInputs = 1; // 组合模式下仅一个输入/* 构建组合函数状态 */build_pertrans_for_aggref(pertrans, aggstate, estate,aggref, transfn_oid, aggtranstype,serialfn_oid, deserialfn_oid,initValue, initValueIsNull,combineFnInputTypes, 2);/* 确保 INTERNAL 类型的组合函数非严格 */if (pertrans->transfn.fn_strict && aggtranstype == INTERNALOID)ereport(ERROR,(errcode(ERRCODE_INVALID_FUNCTION_DEFINITION),errmsg("combine function with transition type %s must not be declared STRICT",format_type_be(aggtranstype))));}else{/* 计算转换函数参数数量 */if (AGGKIND_IS_ORDERED_SET(aggref->aggkind))pertrans->numTransInputs = list_length(aggref->args);elsepertrans->numTransInputs = numAggTransFnArgs;/* 构建转换函数状态 */build_pertrans_for_aggref(pertrans, aggstate, estate,aggref, transfn_oid, aggtranstype,serialfn_oid, deserialfn_oid,initValue, initValueIsNull,aggTransFnInputTypes,numAggTransFnArgs);/* 检查严格函数和初始值的兼容性 */if (pertrans->transfn.fn_strict && pertrans->initValueIsNull){if (numAggTransFnArgs <= numDirectArgs ||!IsBinaryCoercible(aggTransFnInputTypes[numDirectArgs],aggtranstype))ereport(ERROR,(errcode(ERRCODE_INVALID_FUNCTION_DEFINITION),errmsg("aggregate %u needs to have compatible input type and transition type",aggref->aggfnoid)));}}}elsepertrans->aggshared = true; // 标记共享转换状态ReleaseSysCache(aggTuple); // 释放元数据缓存}/** 更新唯一聚合函数和转换状态数量*/aggstate->numaggs = numaggs;aggstate->numtrans = numtrans;/** 检查是否存在嵌套聚合函数(非法情况)*/if (numaggrefs != list_length(aggstate->aggs))ereport(ERROR,(errcode(ERRCODE_GROUPING_ERROR),errmsg("aggregate function calls cannot be nested")));/** 为每个阶段构建转换函数表达式*/for (phaseidx = 0; phaseidx < aggstate->numphases; phaseidx++){AggStatePerPhase phase = &aggstate->phases[phaseidx]; // 当前阶段数据bool dohash = false; // 是否执行哈希聚合bool dosort = false; // 是否执行排序聚合if (!phase->aggnode)continue; // 跳过不存在的阶段 0if (aggstate->aggstrategy == AGG_MIXED && phaseidx == 1){dohash = true; // 混合模式阶段 1 执行哈希和排序dosort = true;}else if (aggstate->aggstrategy == AGG_MIXED && phaseidx == 0){continue; // 混合模式阶段 0 无需转换函数}else if (phase->aggstrategy == AGG_PLAIN || phase->aggstrategy == AGG_SORTED){dohash = false; // 普通或排序模式dosort = true;}else if (phase->aggstrategy == AGG_HASHED){dohash = true; // 哈希模式dosort = false;}elseAssert(false); // 非法策略phase->evaltrans = ExecBuildAggTrans(aggstate, phase, dosort, dohash, false); // 构建转换函数表达式phase->evaltrans_cache[0][0] = phase->evaltrans; // 缓存转换表达式}return aggstate; // 返回初始化的聚合状态
}
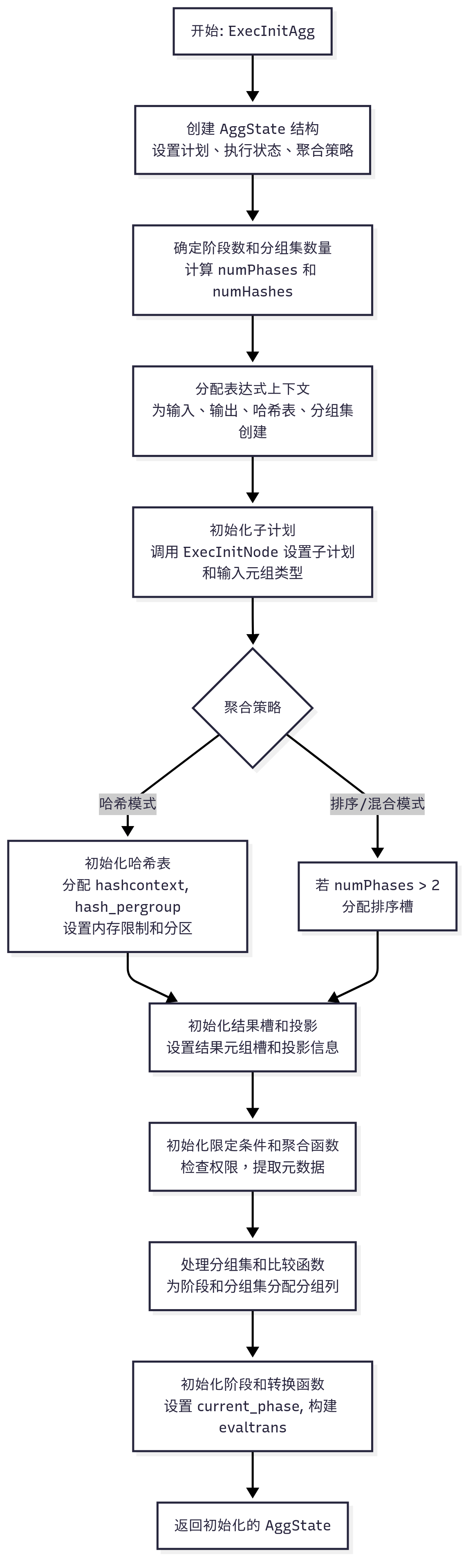
ExecInitAgg 函数的大致流程
- 创建并初始化
AggState:分配AggState结构,设置计划节点、执行状态和聚合策略(如AGG_HASHED)。初始化状态变量(如numaggs、early_stop_limit)。 - 确定阶段和分组集:根据聚合策略(哈希或排序)和分组集(
groupingSets)计算阶段数量(numPhases)和哈希阶段数量(numHashes)。 - 分配表达式上下文:为输入、输出、哈希表和分组集创建表达式上下文(
aggcontexts),用于存储临时数据和聚合结果。 - 初始化子计划:调用
ExecInitNode初始化子计划(如Seq Scan),并设置输入元组的类型和扫描槽。 - 处理多阶段和排序:若阶段数超过
2(排序模式),分配排序槽;为哈希聚合初始化哈希表相关结构(如hashcontext、hash_pergroup)。 - 初始化结果槽和投影:设置结果元组槽和投影信息,确保输出格式正确。
- 初始化表达式和聚合函数:初始化限定条件(
qual)和聚合函数(Aggref),检查权限并提取聚合函数元数据(如转换函数、最终函数)。 - 处理分组集和哈希表:为每个阶段和分组集分配分组列和比较函数,初始化哈希表(包括内存限制和分区估计)。
- 设置阶段和转换函数:根据聚合策略(哈希或排序)初始化当前阶段,构建转换函数表达式(
evaltrans)并缓存。 - 返回
AggState:返回完全初始化的AggState,供执行阶段使用。
ExecInitAgg 函数的细化流程
以下是对 ExecInitAgg 函数的更细化流程描述,深入剖析其分支逻辑,并结合查询 SELECT DISTINCT a FROM t1 LIMIT 10 的上下文,进一步细化条件分支和关键决策点。
ExecInitAgg 函数负责初始化聚合节点的运行时状态(AggState),为 GROUP BY、DISTINCT 或聚合函数的执行准备环境。它根据聚合策略(哈希、排序或混合)、分组集(groupingSets)和链式聚合(chain)进行复杂的分支处理。以下是细化的流程描述,重点突出分支逻辑:
-
创建并初始化
AggState:- 分配
AggState结构,设置计划节点(node)、执行状态(estate)和执行函数(ExecAgg)。 - 初始化状态变量:聚合函数列表(
aggs)、数量(numaggs、numtrans)、策略(aggstrategy)、拆分模式(aggsplit)、早停限制(early_stop_limit)等。 - 分支:检查执行标志(
eflags),确保不支持BACKWARD或MARK扫描。
- 分配
-
确定阶段和分组集数量:
- 判断是否使用哈希聚合(
AGG_HASHED或AGG_MIXED),设置numPhases(哈希模式为1,排序模式为2)和numHashes。 - 分支:若存在
groupingSets,遍历groupingSets和链式聚合(chain):- 计算最大分组集数量(
numGroupingSets)。 - 对链式聚合节点,若策略为
AGG_HASHED,增加numHashes;否则,增加numPhases。
- 计算最大分组集数量(
- 设置
maxsets和numphases。
- 判断是否使用哈希聚合(
-
分配表达式上下文:
- 创建主表达式上下文(
ps_ExprContext)和临时上下文(tmpcontext)。 - 为每个分组集分配上下文(
aggcontexts)。 - 分支:若为哈希聚合,额外创建哈希表上下文(
hashcontext)。 - 创建额外的表达式上下文用于输出处理。
- 创建主表达式上下文(
-
初始化子计划:
- 获取外层计划(
outerPlan)并调用ExecInitNode初始化。 - 分支:若为
AGG_HASHED,禁用REWIND标志以优化重置。 - 设置输入元组的操作(
outerops)和扫描槽(ss_ScanTupleSlot)。
- 获取外层计划(
-
处理多阶段和排序槽:
- 分支:若
numPhases > 2(排序模式多阶段),分配排序槽(sort_slot)并调整outerops。 - 否则,跳过排序槽分配。
- 分支:若
-
初始化结果槽和投影:
- 初始化结果元组槽(
TTSOpsVirtual)和投影信息,确保输出格式正确。
- 初始化结果元组槽(
-
初始化表达式和聚合函数:
- 初始化限定条件(
qual),查找其中的Aggref。 - 遍历
aggs,计算唯一聚合函数(numaggs)和转换状态(numtrans)数量。 - 分支:为每个
Aggref:- 检查权限(
ACL_EXECUTE)和聚合函数元数据(pg_aggregate)。 - 子分支:根据
aggsplit模式(SKIPFINAL、SERIALIZE、DESERIALIZE):- 设置最终函数(
finalfn)、序列化(serialfn)、反序列化(deserialfn)函数。 - 若
aggtranstype = INTERNALOID,验证序列化/反序列化函数。
- 设置最终函数(
- 初始化直接参数(
aggdirectargs)和最终函数表达式。 - 子分支:根据
aggsplit(COMBINE或普通模式):- 使用组合函数(
aggcombinefn)或转换函数(aggtransfn)。 - 设置初始值(
initValue)和输入参数数量(numTransInputs)。
- 使用组合函数(
- 检查严格函数(
fn_strict)与初始值的兼容性。
- 检查权限(
- 初始化限定条件(
-
处理分组集和比较函数:
- 为每个阶段分配
AggStatePerPhaseData。 - 分支:根据聚合策略:
- 哈希模式(
AGG_HASHED或AGG_MIXED):- 设置阶段 0 数据,保存分组列(
grouped_cols)和长度(gset_lengths)。 - 累积所有分组列(
all_grouped_cols)。
- 设置阶段 0 数据,保存分组列(
- 排序模式(
AGG_SORTED或AGG_PLAIN):- 为每个分组集分配列和长度。
- 子分支:若为排序聚合,预计算比较函数(
eqfunctions)以优化元组比较。
- 哈希模式(
- 将
all_grouped_cols转换为降序列表。
- 为每个阶段分配
-
初始化哈希表(仅哈希模式):
- 分支:若
use_hashing:- 创建哈希表元上下文(
hash_metacxt)和溢出槽(hash_spill_rslot、hash_spill_wslot)。 - 计算哈希表条目大小(
hashentrysize)和总分组数(totalGroups)。 - 调用
hash_agg_set_limits设置内存限制(hash_mem_limit)和分区数(hash_planned_partitions)。 - 调用
find_hash_columns和build_hash_tables(非EXPLAIN模式)初始化哈希表。 - 设置初始状态(
table_filled = false,hash_batches_used = 1)。
- 创建哈希表元上下文(
- 分支:若
-
设置阶段和转换函数:
- 分支:根据
aggstrategy:AGG_HASHED:设置current_phase = 0,初始化阶段0。- 其他:设置
current_phase = 1,初始化阶段1。
- 调用
initialize_phase和select_current_set设置阶段和分组集。 - 为每个阶段构建转换函数表达式(
evaltrans)并缓存。
- 分支:根据
-
返回
AggState:- 返回完全初始化的
AggState,供执行阶段(如ExecAgg)使用。
- 返回完全初始化的
Mermaid 流程图
以下分别是 ExecInitAgg 函数的大致和细化流程图,使用 Mermaid 语法表示,清晰展示其主要步骤:
graph TDA[开始: ExecInitAgg] --> B[创建 AggState 结构<br>设置计划、执行状态、聚合策略]B --> C[确定阶段数和分组集数量<br>计算 numPhases 和 numHashes]C --> D[分配表达式上下文<br>为输入、输出、哈希表、分组集创建]D --> E[初始化子计划<br>调用 ExecInitNode 设置子计划和输入元组类型]E --> F{聚合策略}F -->|哈希模式| G[初始化哈希表<br>分配 hashcontext, hash_pergroup<br>设置内存限制和分区]F -->|排序/混合模式| H[若 numPhases > 2<br>分配排序槽]G --> I[初始化结果槽和投影<br>设置结果元组槽和投影信息]H --> II --> J[初始化限定条件和聚合函数<br>检查权限,提取元数据]J --> K[处理分组集和比较函数<br>为阶段和分组集分配分组列]K --> L[初始化阶段和转换函数<br>设置 current_phase, 构建 evaltrans]L --> M[返回初始化的 AggState]
graph TDA[开始: ExecInitAgg] --> B[创建 AggState<br>设置计划、执行状态、ExecAgg<br>初始化 aggstrategy, early_stop_limit]B --> C{检查 eflags}C -->|无 BACKWARD/MARK| D[确定阶段数<br>use_hashing = AGG_HASHED or AGG_MIXED?]D -->|是| E[numPhases = 1<br>numHashes = 1]D -->|否| F[numPhases = 2<br>numHashes = 0]E --> G{groupingSets 存在?}F --> GG -->|是| H[遍历 groupingSets 和 chain<br>计算 numGroupingSets<br>AGG_HASHED: 增加 numHashes<br>其他: 增加 numPhases]G -->|否| I[numGroupingSets = 1]H --> J[设置 maxsets, numphases]I --> JJ --> K[分配表达式上下文<br>创建主上下文、tmpcontext<br>为每个分组集分配 aggcontexts]K --> L{use_hashing?}L -->|是| M[创建 hashcontext]L -->|否| N[跳过 hashcontext]M --> O[初始化子计划<br>调用 ExecInitNode<br>AGG_HASHED: 禁用 REWIND]N --> OO --> P{numPhases > 2?}P -->|是| Q[分配 sort_slot<br>调整 outerops]P -->|否| R[跳过排序槽]Q --> S[初始化结果槽<br>设置 TTSOpsVirtual 和投影]R --> SS --> T[初始化 qual 和 Aggref<br>计算 numaggs, numtrans]T --> U{遍历 aggref}U -->|未初始化| V[检查权限<br>获取 pg_aggregate 元数据]V --> W{aggsplit 模式}W -->|SKIPFINAL| X[finalfn_oid = Invalid]W -->|其他| Y[finalfn_oid = aggfinalfn]X --> Z{aggtranstype = INTERNAL?}Y --> ZZ -->|是| AA{aggsplit}AA -->|SERIALIZE| AB[设置 serialfn_oid]AA -->|DESERIALIZE| AC[设置 deserialfn_oid]AA -->|其他| AD[跳过序列化]Z -->|否| ADAB --> AE[检查组件函数权限<br>初始化直接参数]AC --> AEAD --> AEAE --> AF{aggsplit = COMBINE?}AF -->|是| AG[使用 aggcombinefn<br>numTransInputs = 1]AF -->|否| AH{aggkind = ORDERED_SET?}AH -->|是| AI[numTransInputs = args 长度]AH -->|否| AJ[numTransInputs = numAggTransFnArgs]AI --> AK[构建 pertrans<br>设置 transfn, initValue<br>检查严格性兼容]AJ --> AKAG --> AKAK --> AL{pertrans 已初始化?}AL -->|是| AM[标记 aggshared]AL -->|否| UAM --> AN[更新 numaggs, numtrans]AN --> AO{检查嵌套 Aggref}AO -->|无嵌套| AP[为每个阶段构建 evaltrans]AP --> AQ{aggstrategy}AQ -->|AGG_MIXED, phase=1| AR[dohash = true<br>dosort = true]AQ -->|AGG_MIXED, phase=0| AS[跳过转换函数]AQ -->|AGG_PLAIN/SORTED| AT[dohash = false<br>dosort = true]AQ -->|AGG_HASHED| AU[dohash = true<br>dosort = false]AR --> AV[构建 evaltrans<br>缓存到 evaltrans_cache]AT --> AVAU --> AVAS --> AW{use_hashing?}AW -->|是| AX[创建 hash_metacxt<br>分配 spill_rslot, spill_wslot<br>计算 hashentrysize<br>设置 hash_mem_limit, hash_planned_partitions<br>构建哈希表]AW -->|否| AY[跳过哈希表]AX --> AZ{aggstrategy = AGG_HASHED?}AY --> AZAZ -->|是| BA[current_phase = 0<br>初始化阶段 0]AZ -->|否| BB[current_phase = 1<br>初始化阶段 1]BA --> BC[返回 AggState]BB --> BC
打印堆栈信息:
(gdb) bt
#0 ExecInitAgg (node=0x1cea958, estate=0x1ce6e20, eflags=32) at nodeAgg.c:3200
#1 0x000000000075cf03 in ExecInitNode (node=0x1cea958, estate=0x1ce6e20, eflags=32) at execProcnode.c:341
#2 0x000000000078e4ff in ExecInitLimit (node=0x1ceaa68, estate=0x1ce6e20, eflags=32) at nodeLimit.c:477
#3 0x000000000075cff5 in ExecInitNode (node=0x1ceaa68, estate=0x1ce6e20, eflags=32) at execProcnode.c:381
#4 0x000000000075268b in InitPlan (queryDesc=0x1cbea90, eflags=32) at execMain.c:966
#5 0x000000000075152a in standard_ExecutorStart (queryDesc=0x1cbea90, eflags=32) at execMain.c:261
#6 0x0000000000751279 in ExecutorStart (queryDesc=0x1cbea90, eflags=0) at execMain.c:137
#7 0x00000000009ea524 in PortalStart (portal=0x1c6a1b0, params=0x0, eflags=0, snapshot=0x0) at pquery.c:517
#8 0x00000000009e429a in exec_simple_query (query_string=0x1bebc30 "SELECT DISTINCT a FROM t1 LIMIT 10;") a
t postgres.c:1245
#9 0x00000000009e8cb9 in PostgresMain (dbname=0x1c24050 "postgres", username=0x1c24038 "kuchiki") at postgr
es.c:4766
#10 0x00000000009e089e in BackendMain (startup_data=0x7fff47d0585c "", startup_data_len=4) at backend_startu
p.c:107
#11 0x000000000090d681 in postmaster_child_launch (child_type=B_BACKEND, startup_data=0x7fff47d0585c "", sta
rtup_data_len=4, client_sock=0x7fff47d05880) at launch_backend.c:274
#12 0x0000000000912a76 in BackendStartup (client_sock=0x7fff47d05880) at postmaster.c:3414
#13 0x0000000000910549 in ServerLoop () at postmaster.c:1648
#14 0x000000000090ff12 in PostmasterMain (argc=3, argv=0x1be67e0) at postmaster.c:1346
#15 0x00000000007d1de4 in main (argc=3, argv=0x1be67e0) at main.c:197
ExecAgg 函数
ExecAgg 是 PostgreSQL 中执行聚合操作的核心函数,负责从外层子计划(如 Seq Scan)接收元组,根据聚合策略(AGG_HASHED、AGG_MIXED、AGG_PLAIN 或 AGG_SORTED)处理聚合,并返回结果元组槽。它在运行时状态(AggState)的指导下工作,处理 GROUP BY、DISTINCT 或聚合函数的逻辑。
以下是为 ExecAgg 函数添加中文注释的代码版本,并结合示例查询 SELECT DISTINCT a FROM t1 LIMIT 10 提供细化的流程描述和 Mermaid 流程图。注释清晰说明每行代码的作用,流程描述深入剖析函数逻辑和分支,流程图进一步细化策略分支,确保内容简洁且易于理解。
/** ExecAgg** 执行聚合操作,从外层子计划接收元组并按目标列表或限定条件中的聚合函数(Aggref 节点)进行聚合。* 分组聚合为每个分组生成一行结果;普通聚合为整个查询生成单行结果。* 聚合值存储在表达式上下文中,供 ExecProject 评估结果元组使用。* 参数:* pstate - 计划状态(此处为 AggState)* 返回值:* TupleTableSlot* - 聚合结果的元组槽,或 NULL(无更多结果)*/
static TupleTableSlot *
ExecAgg(PlanState *pstate)
{AggState *node = castNode(AggState, pstate); // 将计划状态转换为 AggStateTupleTableSlot *result = NULL; // 初始化结果元组槽为 NULLCHECK_FOR_INTERRUPTS(); // 检查查询中断信号if (!node->agg_done) // 检查聚合是否完成{/* 根据聚合策略分派执行 */switch (node->phase->aggstrategy){case AGG_HASHED: // 哈希聚合策略if (!node->table_filled) // 如果哈希表未填充agg_fill_hash_table(node); // 填充哈希表/* FALLTHROUGH */case AGG_MIXED: // 混合聚合策略result = agg_retrieve_hash_table(node); // 从哈希表检索结果break;case AGG_PLAIN: // 普通聚合策略case AGG_SORTED: // 排序聚合策略result = agg_retrieve_direct(node); // 直接检索结果break;}if (!TupIsNull(result)) // 如果结果元组不为空return result; // 返回结果元组槽}return NULL; // 无更多结果,返回 NULL
}
ExecAgg 函数的细化流程
-
转换计划状态:
- 将输入的
PlanState转换为AggState(node),获取运行时状态。
- 将输入的
-
检查中断:
- 调用
CHECK_FOR_INTERRUPTS检查是否有查询中断信号(如用户取消查询)。
- 调用
-
检查聚合完成状态:
- 检查
node->agg_done,若为true,表示聚合已完成,直接返回NULL。 - 分支:若
agg_done = false,继续处理聚合。
- 检查
-
根据聚合策略分派:
- 分支:
AGG_HASHED:- 子分支:检查
table_filled:- 若
false,调用agg_fill_hash_table填充哈希表,从子计划读取所有元组并构建哈希表。 - 继续执行(
FALLTHROUGH到AGG_MIXED)。
- 若
- 调用
agg_retrieve_hash_table从哈希表中检索结果元组。
- 子分支:检查
- 分支:
AGG_MIXED:- 直接调用
agg_retrieve_hash_table,处理哈希表结果(混合模式可能包含哈希和排序的组合)。
- 直接调用
- 分支:
AGG_PLAIN或AGG_SORTED:- 调用
agg_retrieve_direct,直接从子计划读取元组并处理(普通聚合为单行,排序聚合按组处理)。
- 调用
- 子分支:若
early_stop_limit已设置(如LIMIT 10),可能提前终止(取决于优化实现)。
- 分支:
-
返回结果:
- 分支:若
result不为空(!TupIsNull(result)),返回结果元组槽。 - 否则,返回
NULL(无更多结果或聚合完成)。
- 分支:若
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划:
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:
pstate转换为AggState,aggstrategy = AGG_HASHED。 - 步骤 2:检查中断,无中断继续执行。
- 步骤 3:
agg_done = false,进入策略分派。 - 步骤 4:
- 进入
AGG_HASHED分支。 - 初次调用时,
table_filled = false,调用agg_fill_hash_table,从Seq Scan读取1000行,构建哈希表(Memory Usage: 24kB,Batches: 1)。 - 调用
agg_retrieve_hash_table,检索前10个唯一值(受LIMIT 10影响,可能触发早停优化)。
- 进入
- 步骤 5:返回包含
t1.a的结果元组槽(10行),或NULL(完成后)。
Mermaid 流程图(细化分支逻辑)
以下是细化的 Mermaid 流程图,详细展示 ExecAgg 的分支逻辑,涵盖聚合策略和处理路径:
agg_fill_hash_table 函数
agg_fill_hash_table 是 PostgreSQL 中哈希聚合(HashAgg)的核心函数之一,负责从外层子计划(如 Seq Scan)读取输入元组,构建哈希表以存储分组键和聚合状态,为后续结果检索(如 agg_retrieve_hash_table)做准备。
/** agg_fill_hash_table** 为哈希聚合读取输入元组并构建哈希表。* 参数:* aggstate - 聚合节点的运行时状态(AggState)*/
static void
agg_fill_hash_table(AggState *aggstate)
{TupleTableSlot *outerslot; // 外层计划的输入元组槽ExprContext *tmpcontext = aggstate->tmpcontext; // 临时表达式上下文/** 循环处理外层计划的每个元组,直到耗尽输入。*/for (;;){outerslot = fetch_input_tuple(aggstate); // 从外层计划获取输入元组if (TupIsNull(outerslot)) // 如果元组为空(输入耗尽)break; // 退出循环/* 设置临时上下文的外部元组,用于哈希查找和聚合推进 */tmpcontext->ecxt_outertuple = outerslot;/* 查找或构建哈希表条目 */lookup_hash_entries(aggstate);/* 推进聚合函数或组合函数 */advance_aggregates(aggstate);/** 在每个元组处理后重置临时上下文(哈希查找已处理部分重置)*/ResetExprContext(aggstate->tmpcontext);}/* 完成所有溢出操作(如果有) */hashagg_finish_initial_spills(aggstate);aggstate->table_filled = true; // 标记哈希表已填充/* 初始化以遍历第一个哈希表 */select_current_set(aggstate, 0, true); // 选择当前分组集为哈希模式ResetTupleHashIterator(aggstate->perhash[0].hashtable,&aggstate->perhash[0].hashiter); // 重置哈希表迭代器
}
以下是细化的流程描述,突出分支逻辑:
-
初始化变量:
- 获取
AggState的临时表达式上下文(tmpcontext)和输入元组槽(outerslot)。
- 获取
-
循环读取输入元组:
- 调用
fetch_input_tuple从外层子计划获取元组。 - 分支:检查元组是否为空(
TupIsNull):- 若为空,表示输入耗尽,退出循环。
- 若不为空,继续处理。
- 调用
-
设置表达式上下文:
- 将当前元组设置为
tmpcontext->ecxt_outertuple,为哈希查找和聚合推进准备数据。
- 将当前元组设置为
-
查找或构建哈希表条目:
- 调用
lookup_hash_entries,根据分组键(Group Key)计算哈希值:- 子分支:若键已存在,更新对应条目。
- 若键不存在,创建新条目并初始化聚合状态。
- 调用
-
推进聚合状态:
- 调用
advance_aggregates,更新聚合函数或组合函数的状态(如累加COUNT、SUM或去重)。
- 调用
-
重置临时上下文:
- 调用
ResetExprContext重置tmpcontext,释放临时内存(哈希查找可能已部分重置)。
- 调用
-
完成溢出处理:
- 调用
hashagg_finish_initial_spills,处理可能发生的磁盘溢出(如哈希表超过work_mem)。
- 调用
-
标记哈希表完成:
- 设置
table_filled = true,表示哈希表构建完成。
- 设置
-
初始化哈希表迭代:
- 调用
select_current_set设置当前分组集(哈希模式)。 - 调用
ResetTupleHashIterator重置哈希表迭代器,准备后续结果检索。
- 调用
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划:
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:
aggstate包含HashAgg的运行时状态,tmpcontext用于临时处理。 - 步骤 2:
fetch_input_tuple从Seq Scan读取1000行(rows=1000),每次获取一个元组(t1.a值)。 - 步骤 3:设置
ecxt_outertuple为当前元组的t1.a值。 - 步骤 4:
lookup_hash_entries计算t1.a的哈希值(0到99),插入或更新哈希表,存储100个唯一值(rows=100)。 - 步骤 5:
advance_aggregates处理去重逻辑(DISTINCT无聚合函数,仅记录唯一键)。 - 步骤 6:重置
tmpcontext,释放内存。 - 步骤 7:
Batches: 1表示无溢出(Memory Usage: 24kB远低于work_mem),无需调用hashagg_finish_initial_spills。 - 步骤 8:设置
table_filled = true。 - 步骤 9:初始化哈希表迭代器,准备
agg_retrieve_hash_table检索10个结果。
Mermaid 流程图(细化分支逻辑)
以下是细化的 Mermaid 流程图,展示 agg_fill_hash_table 的详细逻辑和分支:
打印堆栈信息:
Breakpoint 1, agg_fill_hash_table (aggstate=0x1ce7358) at nodeAgg.c:2543
(gdb) bt
#0 agg_fill_hash_table (aggstate=0x1ce7358) at nodeAgg.c:2543
#1 0x000000000076f4e2 in ExecAgg (pstate=0x1ce7358) at nodeAgg.c:2172
#2 0x000000000075d202 in ExecProcNodeFirst (node=0x1ce7358) at execProcnode.c:469
#3 0x000000000078d90b in ExecProcNode (node=0x1ce7358) at ../../../src/include/executor/executor.h:274
#4 0x000000000078db10 in ExecLimit (pstate=0x1ce7068) at nodeLimit.c:95
#5 0x000000000075d202 in ExecProcNodeFirst (node=0x1ce7068) at execProcnode.c:469
#6 0x00000000007510eb in ExecProcNode (node=0x1ce7068) at ../../../src/include/executor/executor.h:274
#7 0x0000000000753bde in ExecutePlan (estate=0x1ce6e20, planstate=0x1ce7068, use_parallel_mode=false, opera
tion=CMD_SELECT, sendTuples=true, numberTuples=0, direction=ForwardScanDirection, dest=0x1cf71b8, execute_on
ce=true) at execMain.c:1646
#8 0x000000000075177e in standard_ExecutorRun (queryDesc=0x1cbea90, direction=ForwardScanDirection, count=0
, execute_once=true) at execMain.c:363
#9 0x0000000000751592 in ExecutorRun (queryDesc=0x1cbea90, direction=ForwardScanDirection, count=0, execute
_once=true) at execMain.c:304
#10 0x00000000009eae31 in PortalRunSelect (portal=0x1c6a1b0, forward=true, count=0, dest=0x1cf71b8) at pquer
y.c:924
#11 0x00000000009eaaef in PortalRun (portal=0x1c6a1b0, count=9223372036854775807, isTopLevel=true, run_once=
true, dest=0x1cf71b8, altdest=0x1cf71b8, qc=0x7fff47d05550) at pquery.c:768
#12 0x00000000009e4386 in exec_simple_query (query_string=0x1bebc30 "SELECT DISTINCT a FROM t1 LIMIT 10;") a
t postgres.c:1284
#13 0x00000000009e8cb9 in PostgresMain (dbname=0x1c24050 "postgres", username=0x1c24038 "kuchiki") at postgr
es.c:4766
#14 0x00000000009e089e in BackendMain (startup_data=0x7fff47d0585c "", startup_data_len=4) at backend_startu
p.c:107
#15 0x000000000090d681 in postmaster_child_launch (child_type=B_BACKEND, startup_data=0x7fff47d0585c "", sta
rtup_data_len=4, client_sock=0x7fff47d05880) at launch_backend.c:274
#16 0x0000000000912a76 in BackendStartup (client_sock=0x7fff47d05880) at postmaster.c:3414
#17 0x0000000000910549 in ServerLoop () at postmaster.c:1648
#18 0x000000000090ff12 in PostmasterMain (argc=3, argv=0x1be67e0) at postmaster.c:1346
#19 0x00000000007d1de4 in main (argc=3, argv=0x1be67e0) at main.c:197
lookup_hash_entries 函数
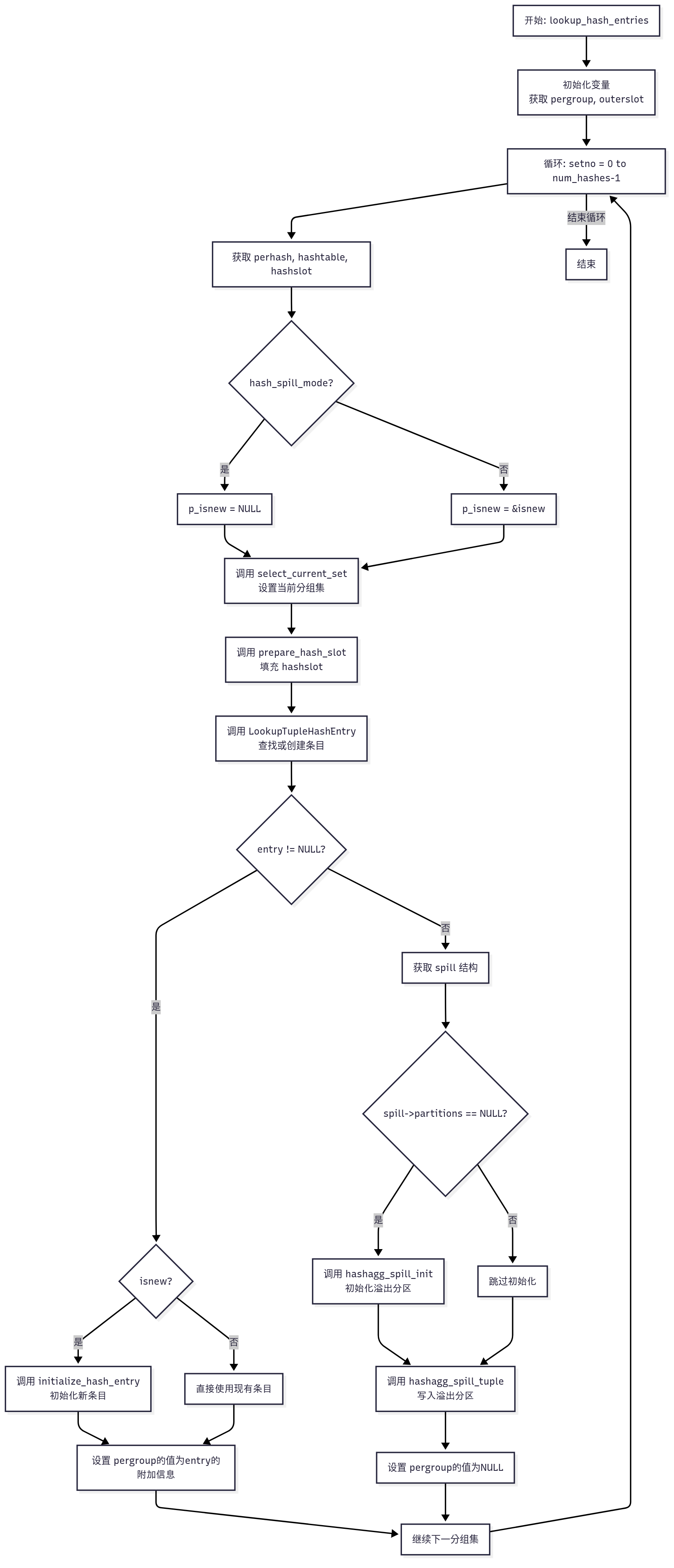
lookup_hash_entries 是 PostgreSQL 哈希聚合(HashAgg)的核心函数之一,负责为当前输入元组在所有哈希分组集(num_hashes)中查找或创建哈希表条目。它处理内存中的哈希表操作,并在溢出模式下将元组写入磁盘分区。
/** lookup_hash_entries** 为当前元组在所有哈希分组集中查找或创建哈希表条目。* 注意:本函数可能重置 tmpcontext。* 在“溢出模式”下,某些条目可能为 NULL。同一元组在不同分组集中可能属于不同组,* 某些分组集可能匹配内存中的组,而其他分组集可能需溢出到磁盘。* 即使多次溢出同一元组到不同分组集看似浪费,但通过为每个分组集分区,* 可提高哈希表重新填充的效率。* 参数:* aggstate - 聚合节点的运行时状态(AggState)*/
static void
lookup_hash_entries(AggState *aggstate)
{AggStatePerGroup *pergroup = aggstate->hash_pergroup; // 哈希分组状态数组TupleTableSlot *outerslot = aggstate->tmpcontext->ecxt_outertuple; // 当前输入元组槽int setno; // 分组集索引/* 遍历所有哈希分组集 */for (setno = 0; setno < aggstate->num_hashes; setno++){AggStatePerHash perhash = &aggstate->perhash[setno]; // 当前分组集的哈希数据TupleHashTable hashtable = perhash->hashtable; // 哈希表TupleTableSlot *hashslot = perhash->hashslot; // 哈希表槽TupleHashEntry entry; // 哈希表条目uint32 hash; // 哈希值bool isnew = false; // 标记是否为新条目bool *p_isnew; // 新条目指针(溢出模式下为 NULL)/* 如果哈希表已溢出,不创建新条目 */p_isnew = aggstate->hash_spill_mode ? NULL : &isnew;select_current_set(aggstate, setno, true); // 选择当前分组集(哈希模式)prepare_hash_slot(perhash, outerslot, hashslot); // 准备哈希表槽,填充分组键/* 查找或创建哈希表条目 */entry = LookupTupleHashEntry(hashtable, hashslot, p_isnew, &hash);if (entry != NULL) // 如果找到或创建了条目{if (isnew) // 如果是新条目initialize_hash_entry(aggstate, hashtable, entry); // 初始化条目pergroup[setno] = entry->additional; // 保存分组状态}else // 如果未找到且需溢出{HashAggSpill *spill = &aggstate->hash_spills[setno]; // 溢出数据结构TupleTableSlot *slot = aggstate->tmpcontext->ecxt_outertuple; // 当前元组/* 初始化溢出分区(如果尚未初始化) */if (spill->partitions == NULL)hashagg_spill_init(spill, aggstate->hash_tapeset, 0,perhash->aggnode->numGroups,aggstate->hashentrysize);/* 将元组写入溢出分区 */hashagg_spill_tuple(aggstate, spill, slot, hash);pergroup[setno] = NULL; // 设置分组状态为 NULL}}
}
以下是细化的流程描述,聚焦原始逻辑:
-
初始化变量:
- 获取
AggState的哈希分组状态数组(pergroup)和当前输入元组(outerslot)。
- 获取
-
遍历哈希分组集:
- 对每个分组集(
setno从0到num_hashes-1):- 获取当前分组集的哈希数据(
perhash)、哈希表(hashtable)和哈希表槽(hashslot)。
- 获取当前分组集的哈希数据(
- 对每个分组集(
-
设置溢出模式标志:
- 检查
hash_spill_mode:- 若为
true(溢出模式),设置p_isnew = NULL,不创建新条目。 - 若为
false,设置p_isnew = &isnew,允许创建新条目。
- 若为
- 检查
-
选择分组集并准备哈希槽:
- 调用
select_current_set设置当前分组集为哈希模式。 - 调用
prepare_hash_slot,将输入元组(outerslot)的分组键(如t1.a)填充到hashslot。
- 调用
-
查找或创建哈希表条目:
- 调用
LookupTupleHashEntry,根据hashslot计算哈希值(hash)并查找条目:- 分支:若找到条目或创建新条目(
entry != NULL):- 若
isnew = true,调用initialize_hash_entry初始化新条目(设置初始聚合状态)。 - 保存条目的分组状态到
pergroup[setno]。
- 若
- 分支:若未找到条目(
entry = NULL,溢出模式):- 获取溢出数据结构(
spill)。 - 若
spill->partitions未初始化,调用hashagg_spill_init设置溢出分区。 - 调用
hashagg_spill_tuple,将元组和哈希值写入溢出分区。 - 设置
pergroup[setno] = NULL。
- 获取溢出数据结构(
- 分支:若找到条目或创建新条目(
- 调用
-
继续处理下一分组集:
- 循环处理所有分组集,直至完成。
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划:
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:
pergroup存储哈希分组状态,outerslot包含Seq Scan返回的元组(t1.a值)。 - 步骤 2:
num_hashes = 1(单分组集,Group Key: t1.a),循环仅执行一次。 - 步骤 3:
hash_spill_mode = false(Batches: 1,Memory Usage: 24kB小于work_mem),p_isnew = &isnew。 - 步骤 4:调用
select_current_set(setno=0, true),设置分组集;prepare_hash_slot将t1.a值填充到hashslot。 - 步骤 5:
LookupTupleHashEntry计算t1.a的哈希值(0到99):- 若
t1.a已存在,更新条目。 - 若新值,创建条目(
isnew = true),调用initialize_hash_entry初始化(DISTINCT无聚合函数,仅记录键)。 - 保存条目状态到
pergroup[0]。
- 若
- 本例无溢出(
Batches: 1),不执行溢出分支。
- 步骤 6:单分组集,循环结束。
Mermaid 流程图(原始逻辑)
以下是 Mermaid 流程图,展示 lookup_hash_entries 的原始逻辑,细化分支但不包含 early_stop_limit:
hashagg_finish_initial_spills 函数
hashagg_finish_initial_spills 是 PostgreSQL 哈希聚合(HashAgg)流程中的辅助函数,负责在初始哈希表构建完成后处理磁盘溢出(spill)。它将溢出的分区转换为新的批次(batches),供后续处理,并清理溢出相关资源。
/** hashagg_finish_initial_spills** 在处理完哈希聚合批次(HashAggBatch)后,如果有元组溢出到磁盘,* 将溢出的分区转换为新的批次,供后续执行。* 参数:* aggstate - 聚合节点的运行时状态(AggState)*/
static void
hashagg_finish_initial_spills(AggState *aggstate)
{int setno; // 分组集索引int total_npartitions = 0; // 总分区数/* 检查是否存在溢出数据结构 */if (aggstate->hash_spills != NULL){/* 遍历所有哈希分组集 */for (setno = 0; setno < aggstate->num_hashes; setno++){HashAggSpill *spill = &aggstate->hash_spills[setno]; // 当前分组集的溢出数据total_npartitions += spill->npartitions; // 累积分区数hashagg_spill_finish(aggstate, spill, setno); // 完成当前分组集的溢出处理}/** 不再处理外层计划的元组,仅处理溢出批次的元组。* 初始溢出结构不再需要,释放内存。*/pfree(aggstate->hash_spills); // 释放溢出数据结构aggstate->hash_spills = NULL; // 清空溢出指针}/* 更新哈希聚合的度量信息 */hash_agg_update_metrics(aggstate, false, total_npartitions);aggstate->hash_spill_mode = false; // 关闭溢出模式
}
以下是细化的流程描述,聚焦原始逻辑:
-
初始化变量:
- 定义分组集索引(
setno)和总分区计数(total_npartitions)。
- 定义分组集索引(
-
检查溢出数据结构:
- 检查
aggstate->hash_spills是否存在:- 若为空(无溢出),跳过循环,直接更新度量。
- 若不为空,继续处理。
- 检查
-
遍历哈希分组集:
- 对每个分组集(
setno从 0 到num_hashes-1):- 获取当前分组集的溢出数据结构(
spill)。 - 累积分区数(
spill->npartitions)。 - 调用
hashagg_spill_finish,将溢出分区转换为新批次。
- 获取当前分组集的溢出数据结构(
- 对每个分组集(
-
释放溢出资源:
- 释放
hash_spills内存,设置hash_spills = NULL,表示不再处理外层计划元组,仅处理溢出批次。
- 释放
-
更新度量并关闭溢出模式:
- 调用
hash_agg_update_metrics,记录分区数等信息(spilling = false)。 - 设置
hash_spill_mode = false,退出溢出模式。
- 调用
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划:
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:初始化
setno和total_npartitions = 0。 - 步骤 2:
hash_spills = NULL(Batches: 1,Memory Usage: 24kB小于work_mem),无溢出,跳过循环。 - 步骤 3:无分组集需要处理(
num_hashes = 1,但无溢出)。 - 步骤 4:跳过释放
hash_spills(已是NULL)。 - 步骤 5:调用
hash_agg_update_metrics,记录total_npartitions = 0,设置hash_spill_mode = false。
Mermaid 流程图(原始逻辑)
以下是 Mermaid 流程图,展示 hashagg_finish_initial_spills 的原始逻辑,细化分支:
agg_retrieve_hash_table 函数
agg_retrieve_hash_table 是 PostgreSQL 哈希聚合(HashAgg)的核心函数之一,负责从哈希表中检索分组结果。它首先处理内存中的哈希表条目,若内存条目耗尽,则尝试从磁盘溢出分区重新填充哈希表,直至所有分组处理完毕。
/** agg_retrieve_hash_table** 为哈希聚合从哈希表中检索分组结果。* 在内存中元组耗尽后,尝试使用先前溢出的元组重新填充哈希表。* 仅在内存和溢出元组全部耗尽后返回 NULL。* 参数:* aggstate - 聚合节点的运行时状态(AggState)* 返回值:* TupleTableSlot* - 包含分组结果的元组槽,或 NULL(全部耗尽)*/
static TupleTableSlot *
agg_retrieve_hash_table(AggState *aggstate)
{TupleTableSlot *result = NULL; // 初始化结果元组槽为 NULL/* 循环直到获取有效结果或全部耗尽 */while (result == NULL){/* 尝试从内存中的哈希表检索结果 */result = agg_retrieve_hash_table_in_memory(aggstate);if (result == NULL) // 如果内存中无更多结果{/* 尝试重新填充哈希表 */if (!agg_refill_hash_table(aggstate)){aggstate->agg_done = true; // 标记聚合完成break; // 退出循环}}}return result; // 返回结果元组槽或 NULL
}
以下是细化的流程描述,聚焦原始逻辑:
-
初始化结果槽:
- 初始化
result元组槽为NULL。
- 初始化
-
循环检索结果:
- 分支:当
result为NULL时,继续循环:- 调用
agg_retrieve_hash_table_in_memory,从内存中的哈希表获取下一个分组结果:- 若返回有效元组槽(
result != NULL),退出循环。 - 若返回
NULL,内存中条目已耗尽。
- 若返回有效元组槽(
- 子分支:若内存中无结果,调用
agg_refill_hash_table:- 若返回
true,表示成功从溢出分区重新填充哈希表,继续循环。 - 若返回
false,表示无更多溢出元组,设置agg_done = true并退出循环。
- 若返回
- 调用
- 分支:当
-
返回结果:
- 返回
result(有效元组槽或NULL)。
- 返回
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划:
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:
result = NULL。 - 步骤 2:
- 调用
agg_retrieve_hash_table_in_memory,从哈希表(包含 100 个唯一t1.a值)获取分组结果:- 每次返回一个元组槽(
t1.a值),共返回 10 行(受LIMIT 10限制)。 Batches: 1表示无溢出,内存中哈希表(24kB)包含所有分组。
- 每次返回一个元组槽(
- 无需调用
agg_refill_hash_table(无溢出分区)。
- 调用
- 步骤 3:返回每个
result元组槽(包含t1.a),第 11 次调用返回NULL(agg_done = true)。
Mermaid 流程图(原始逻辑)
以下是 Mermaid 流程图,展示 agg_retrieve_hash_table 的原始逻辑,细化分支:
agg_retrieve_hash_table_in_memory 函数
agg_retrieve_hash_table_in_memory 是 PostgreSQL 哈希聚合(HashAgg)的核心函数之一,负责从内存中的哈希表检索分组结果,仅处理内存中的条目(不考虑溢出元组)。它循环扫描哈希表,转换分组数据,执行聚合函数,并生成结果元组。
/** agg_retrieve_hash_table_in_memory** 从内存中的哈希表检索分组结果,不考虑溢出到磁盘的元组。* 参数:* aggstate - 聚合节点的运行时状态(AggState)* 返回值:* TupleTableSlot* - 包含分组结果的元组槽,或 NULL(无更多分组)*/
static TupleTableSlot *
agg_retrieve_hash_table_in_memory(AggState *aggstate)
{ExprContext *econtext; // 输出元组的表达式上下文AggStatePerAgg peragg; // 聚合函数状态数组AggStatePerGroup pergroup; // 分组状态TupleHashEntryData *entry; // 哈希表条目TupleTableSlot *firstSlot; // 扫描元组槽TupleTableSlot *result; // 结果元组槽AggStatePerHash perhash; // 当前分组集的哈希数据/** 获取节点的状态信息。* econtext 是每个输出元组的表达式上下文。*/econtext = aggstate->ss.ps.ps_ExprContext; // 获取表达式上下文peragg = aggstate->peragg; // 获取聚合函数状态firstSlot = aggstate->ss.ss_ScanTupleSlot; // 获取扫描元组槽/** 注意:perhash(及其相关数据)可能在循环中变化,* 因为我们会在不同分组集之间切换。*/perhash = &aggstate->perhash[aggstate->current_set]; // 获取当前分组集的哈希数据/** 循环检索分组,直到找到满足 aggstate->ss.ps.qual 的分组*/for (;;){TupleTableSlot *hashslot = perhash->hashslot; // 哈希表槽int i; // 循环计数器CHECK_FOR_INTERRUPTS(); // 检查查询中断信号/** 查找哈希表中的下一个条目*/entry = ScanTupleHashTable(perhash->hashtable, &perhash->hashiter); // 扫描哈希表if (entry == NULL) // 如果没有更多条目{int nextset = aggstate->current_set + 1; // 下一个分组集索引if (nextset < aggstate->num_hashes) // 如果存在更多分组集{/** 切换到下一个分组集,重新初始化并重启循环*/select_current_set(aggstate, nextset, true); // 切换分组集perhash = &aggstate->perhash[aggstate->current_set]; // 更新哈希数据ResetTupleHashIterator(perhash->hashtable, &perhash->hashiter); // 重置迭代器continue; // 继续循环}else // 无更多分组集{return NULL; // 返回 NULL}}/** 为每个分组清空输出元组上下文。* 不使用 ReScanExprContext,因为可能有聚合函数的关闭回调尚未调用。*/ResetExprContext(econtext); // 重置表达式上下文/** 将代表性元组转换回具有正确列的格式*/ExecStoreMinimalTuple(entry->firstTuple, hashslot, false); // 存储最小元组slot_getallattrs(hashslot); // 获取哈希表槽的所有属性ExecClearTuple(firstSlot); // 清空扫描元组槽memset(firstSlot->tts_isnull, true,firstSlot->tts_tupleDescriptor->natts * sizeof(bool)); // 将所有属性标记为 NULL/* 复制分组列到扫描元组槽 */for (i = 0; i < perhash->numhashGrpCols; i++){int varNumber = perhash->hashGrpColIdxInput[i] - 1; // 输入列索引firstSlot->tts_values[varNumber] = hashslot->tts_values[i]; // 复制值firstSlot->tts_isnull[varNumber] = hashslot->tts_isnull[i]; // 复制空值标志}ExecStoreVirtualTuple(firstSlot); // 存储虚拟元组pergroup = (AggStatePerGroup) entry->additional; // 获取分组状态/** 使用代表性输入元组处理限定条件和目标列表中的非聚合列引用*/econtext->ecxt_outertuple = firstSlot; // 设置外部元组prepare_projection_slot(aggstate,econtext->ecxt_outertuple,aggstate->current_set); // 准备投影槽finalize_aggregates(aggstate, peragg, pergroup); // 完成聚合函数计算result = project_aggregates(aggstate); // 投影聚合结果if (result) // 如果投影结果有效return result; // 返回结果元组槽}/* 无更多分组 */return NULL;
}
以下是细化的流程描述,聚焦原始逻辑:
-
初始化变量:
- 获取表达式上下文(
econtext)、聚合函数状态(peragg)、扫描元组槽(firstSlot)。 - 获取当前分组集的哈希数据(
perhash)。
- 获取表达式上下文(
-
循环检索分组:
- 调用
CHECK_FOR_INTERRUPTS检查查询中断。 - 调用
ScanTupleHashTable,获取哈希表中的下一个条目(entry):- 分支:若
entry = NULL(当前分组集耗尽):- 检查是否存在下一个分组集(
nextset < num_hashes):- 若存在,调用
select_current_set切换分组集,更新perhash,调用ResetTupleHashIterator重置迭代器,继续循环。 - 若无更多分组集,返回
NULL。
- 若存在,调用
- 检查是否存在下一个分组集(
- 分支:若
entry != NULL,继续处理。
- 分支:若
- 调用
-
重置表达式上下文:
- 调用
ResetExprContext,清空econtext,避免调用关闭回调(使用普通重置)。
- 调用
-
转换代表性元组:
- 调用
ExecStoreMinimalTuple将哈希表条目的firstTuple存储到hashslot。 - 调用
slot_getallattrs获取hashslot的属性。 - 清空
firstSlot,将所有属性标记为NULL(tts_isnull)。 - 复制分组列(
numhashGrpCols)从hashslot到firstSlot,存储为虚拟元组。
- 调用
-
准备投影和聚合:
- 设置
econtext->ecxt_outertuple = firstSlot,用于非聚合列引用。 - 调用
prepare_projection_slot,准备投影槽。 - 调用
finalize_aggregates,完成聚合函数计算(peragg和pergroup)。 - 调用
project_aggregates,生成投影结果(result)。
- 设置
-
返回结果:
- 分支:若
result不为空,返回结果元组槽。 - 否则,继续循环查找下一个分组。
- 分支:若
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划:
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> HashAggregate (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aGroup Key: t1.aBatches: 1 Memory Usage: 24kBBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:
econtext为输出上下文,peragg = NULL(DISTINCT无聚合函数),firstSlot为扫描槽,perhash指向哈希表(含 100 个唯一t1.a值)。 - 步骤 2:
num_hashes = 1,current_set = 0:ScanTupleHashTable返回哈希表条目(每次一个t1.a值)。- 本例无其他分组集(
nextset >= 1),耗尽后返回NULL.
- 步骤 3:重置
econtext。 - 步骤 4:将
entry->firstTuple(t1.a值)存储到hashslot,复制到firstSlot(仅t1.a列)。 - 步骤 5:设置
ecxt_outertuple = firstSlot,调用prepare_projection_slot和project_aggregates(finalize_aggregates为空操作,DISTINCT无聚合),返回t1.a值。共返回 10 行(受LIMIT 10限制)。 - 步骤 6:返回有效元组槽(10 次),第 11 次返回
NULL.
Mermaid 流程图(原始逻辑)
以下是 Mermaid 流程图,展示 agg_retrieve_hash_table_in_memory 的原始逻辑,细化分支:
agg_retrieve_direct 函数
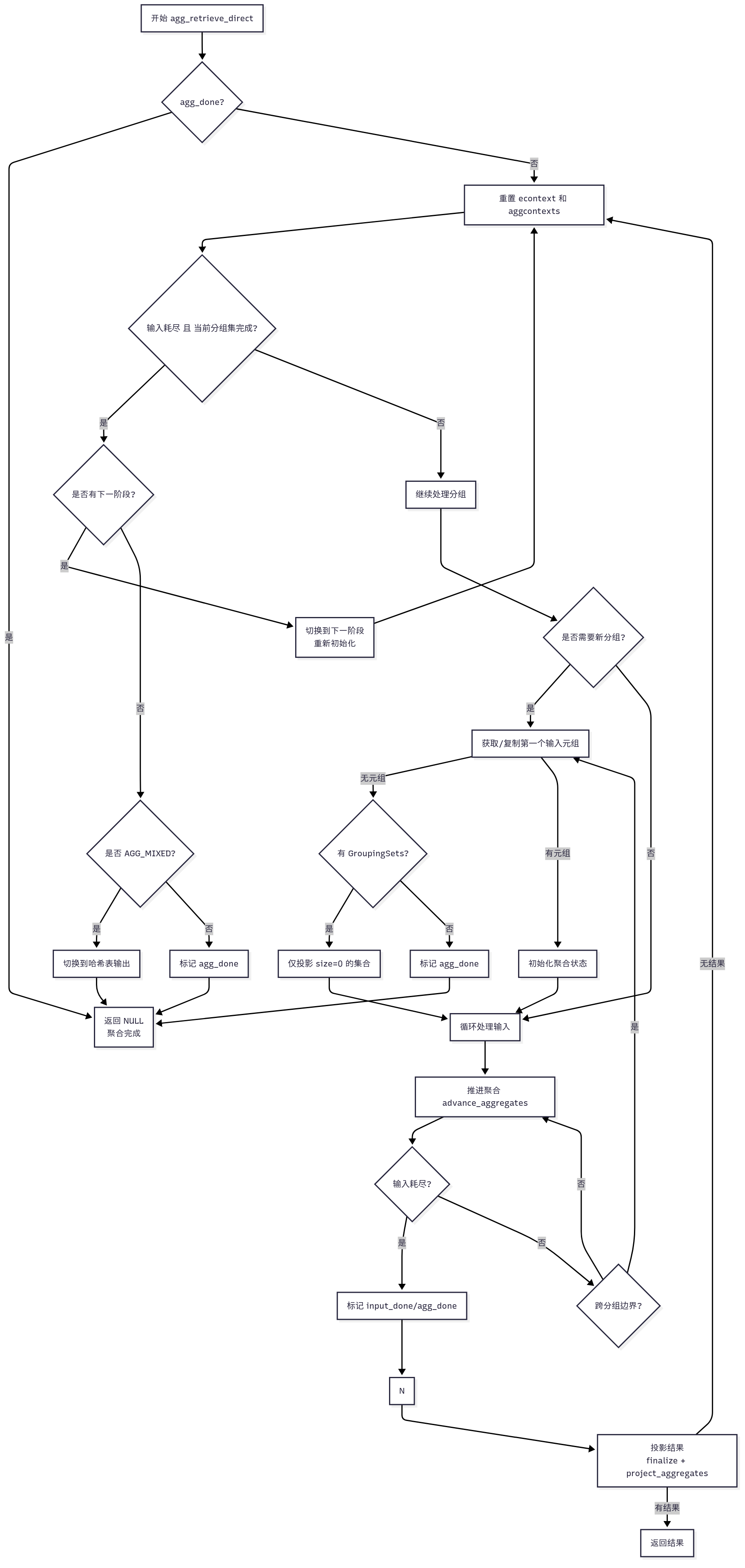
agg_retrieve_direct 是 PostgreSQL 非哈希聚合(AGG_PLAIN 或 AGG_SORTED,可能包含 AGG_MIXED 的排序部分)的核心函数,负责从外层计划读取元组,处理分组,执行聚合函数,并返回结果元组。它支持分组集和多阶段处理,循环直到找到满足条件的有效分组或耗尽所有分组。
/** agg_retrieve_direct** 为非哈希聚合(普通或排序聚合)处理分组并返回结果元组。* 参数:* aggstate - 聚合节点的运行时状态(AggState)* 返回值:* TupleTableSlot* - 包含分组结果的元组槽,或 NULL(无更多分组)*/
static TupleTableSlot *
agg_retrieve_direct(AggState *aggstate)
{Agg *node = aggstate->phase->aggnode; // 聚合计划节点ExprContext *econtext; // 输出元组的表达式上下文ExprContext *tmpcontext; // 输入元组的表达式上下文AggStatePerAgg peragg; // 聚合函数状态数组AggStatePerGroup *pergroups; // 分组状态数组TupleTableSlot *outerslot; // 外层计划元组槽TupleTableSlot *firstSlot; // 扫描元组槽TupleTableSlot *result; // 结果元组槽bool hasGroupingSets = aggstate->phase->numsets > 0; // 是否有分组集int numGroupingSets = Max(aggstate->phase->numsets, 1); // 分组集数量int currentSet; // 当前分组集索引int nextSetSize; // 下一个分组集的列数int numReset; // 需要重置的上下文数量int i; // 循环计数器/** 获取节点的状态信息。* econtext 是每个输出元组的表达式上下文。* tmpcontext 是每个输入元组的表达式上下文。*/econtext = aggstate->ss.ps.ps_ExprContext; // 获取输出上下文tmpcontext = aggstate->tmpcontext; // 获取输入上下文peragg = aggstate->peragg; // 获取聚合函数状态pergroups = aggstate->pergroups; // 获取分组状态firstSlot = aggstate->ss.ss_ScanTupleSlot; // 获取扫描元组槽/** 循环检索分组,直到找到满足 aggstate->ss.ps.qual 的分组。* 对于分组集,projected_set 为 -1(初始调用)或已完成分组的索引。*/while (!aggstate->agg_done){/** 为每个分组清空输出上下文和聚合上下文(含引用传递的转换值)。* 使用 ReScanExprContext 调用关闭回调,确保清理非内存资源。*/ReScanExprContext(econtext);/** 确定在当前边界需要重置的分组集数量。*/if (aggstate->projected_set >= 0 &&aggstate->projected_set < numGroupingSets)numReset = aggstate->projected_set + 1;elsenumReset = numGroupingSets;/* 重置聚合上下文 */for (i = 0; i < numReset; i++){ReScanExprContext(aggstate->aggcontexts[i]);}/** 检查输入是否完成且当前阶段无更多分组集需要投影;* 若完成,切换到下一阶段或标记聚合完成。*/if (aggstate->input_done == true &&aggstate->projected_set >= (numGroupingSets - 1)){if (aggstate->current_phase < aggstate->numphases - 1){/* 切换到下一阶段 */initialize_phase(aggstate, aggstate->current_phase + 1);aggstate->input_done = false;aggstate->projected_set = -1;numGroupingSets = Max(aggstate->phase->numsets, 1);node = aggstate->phase->aggnode;numReset = numGroupingSets;}else if (aggstate->aggstrategy == AGG_MIXED){/** 混合模式:已输出所有分组数据,切换到哈希表输出。*/initialize_phase(aggstate, 0);aggstate->table_filled = true;ResetTupleHashIterator(aggstate->perhash[0].hashtable,&aggstate->perhash[0].hashiter);select_current_set(aggstate, 0, true);return agg_retrieve_hash_table(aggstate);}else{aggstate->agg_done = true;break;}}/** 获取下一个分组集的列数,用于检查是否到达分组边界。*/if (aggstate->projected_set >= 0 &&aggstate->projected_set < (numGroupingSets - 1))nextSetSize = aggstate->phase->gset_lengths[aggstate->projected_set + 1];elsenextSetSize = 0;/** 如果存在当前分组集的子组,投影它。* 新分组的条件:* - 输入耗尽但未投影所有分组集(已在上面检查)* 或* - 已投影的行不属于最后一个分组集* 且* - 下一个分组集至少有一个分组列* 且* - 前一行和当前行在下一个分组集的列上不同*/tmpcontext->ecxt_innertuple = econtext->ecxt_outertuple;if (aggstate->input_done ||(node->aggstrategy != AGG_PLAIN &&aggstate->projected_set != -1 &&aggstate->projected_set < (numGroupingSets - 1) &&nextSetSize > 0 &&!ExecQualAndReset(aggstate->phase->eqfunctions[nextSetSize - 1],tmpcontext))){aggstate->projected_set += 1;Assert(aggstate->projected_set < numGroupingSets);Assert(nextSetSize > 0 || aggstate->input_done);}else{/** 下一个投影将是第一个(或唯一)分组集。*/aggstate->projected_set = 0;/** 如果没有当前分组的第一个元组,从外层计划获取。*/if (aggstate->grp_firstTuple == NULL){outerslot = fetch_input_tuple(aggstate);if (!TupIsNull(outerslot)){/* 复制第一个输入元组,用于比较和投影 */aggstate->grp_firstTuple = ExecCopySlotHeapTuple(outerslot);}else{/* 外层计划无元组 */if (hasGroupingSets){/** 无输入时,仅投影大小为 0 的分组集。*/aggstate->input_done = true;while (aggstate->phase->gset_lengths[aggstate->projected_set] > 0){aggstate->projected_set += 1;if (aggstate->projected_set >= numGroupingSets)break;}if (aggstate->projected_set >= numGroupingSets)continue;}else{aggstate->agg_done = true;if (node->aggstrategy != AGG_PLAIN)return NULL;}}}/* 初始化新输入元组组的工作状态 */initialize_aggregates(aggstate, pergroups, numReset);if (aggstate->grp_firstTuple != NULL){/* 存储第一个输入元组到扫描槽 */ExecForceStoreHeapTuple(aggstate->grp_firstTuple, firstSlot, true);aggstate->grp_firstTuple = NULL;/* 设置第一次 advance_aggregates 调用 */tmpcontext->ecxt_outertuple = firstSlot;/* 处理外层计划元组,直到耗尽或跨越分组边界 */for (;;){/* 混合模式阶段 1 需要更新哈希表 */if (aggstate->aggstrategy == AGG_MIXED &&aggstate->current_phase == 1){lookup_hash_entries(aggstate);}/* 推进聚合函数或组合函数 */advance_aggregates(aggstate);/* 重置每个输入元组的上下文 */ResetExprContext(tmpcontext);outerslot = fetch_input_tuple(aggstate);if (TupIsNull(outerslot)){/* 外层计划元组耗尽 */if (aggstate->aggstrategy == AGG_MIXED &&aggstate->current_phase == 1)hashagg_finish_initial_spills(aggstate);if (hasGroupingSets)aggstate->input_done = true;elseaggstate->agg_done = true;break;}/* 设置下一次 advance_aggregates 调用 */tmpcontext->ecxt_outertuple = outerslot;/* 如果分组,检查是否跨越分组边界 */if (node->aggstrategy != AGG_PLAIN && node->numCols > 0){tmpcontext->ecxt_innertuple = firstSlot;if (!ExecQual(aggstate->phase->eqfunctions[node->numCols - 1],tmpcontext)){aggstate->grp_firstTuple = ExecCopySlotHeapTuple(outerslot);break;}}}}/* 使用代表性输入元组处理非聚合列引用 */econtext->ecxt_outertuple = firstSlot;}Assert(aggstate->projected_set >= 0);currentSet = aggstate->projected_set;prepare_projection_slot(aggstate, econtext->ecxt_outertuple, currentSet);select_current_set(aggstate, currentSet, false);finalize_aggregates(aggstate, peragg, pergroups[currentSet]);/* 如果当前无行可投影,继续循环 */result = project_aggregates(aggstate);if (result)return result;}/* 无更多分组 */return NULL;
}
以下是细化的流程描述,聚焦原始逻辑:
-
初始化变量:
- 获取聚合节点(
node)、表达式上下文(econtext和tmpcontext)、聚合状态(peragg和pergroups)、扫描槽(firstSlot)。 - 计算分组集数量(
numGroupingSets)和是否包含分组集(hasGroupingSets)。
- 获取聚合节点(
-
循环检索分组:
- 分支:当
agg_done = false时:- 调用
ReScanExprContext(econtext)重置输出上下文,调用关闭回调清理资源。 - 计算需要重置的上下文数量(
numReset),重置aggcontexts。 - 子分支:若
input_done = true且projected_set达到最后一个分组集:- 若存在更多阶段(
current_phase < numphases - 1),调用initialize_phase切换阶段,重置input_done和projected_set。 - 若为
AGG_MIXED,初始化哈希表阶段,调用agg_retrieve_hash_table。 - 否则,设置
agg_done = true,退出循环。
- 若存在更多阶段(
- 调用
- 分支:当
-
确定下一个分组集列数:
- 若
projected_set有效,获取下一个分组集的列数(nextSetSize);否则,设为 0。
- 若
-
检查新分组:
- 分支:若满足新分组条件(输入耗尽或分组列不同):
- 增加
projected_set。
- 增加
- 否则,设置
projected_set = 0。
- 分支:若满足新分组条件(输入耗尽或分组列不同):
-
获取分组的第一个元组:
- 分支:若
grp_firstTuple = NULL:- 调用
fetch_input_tuple获取外层元组:- 若有效,复制到
grp_firstTuple。 - 若为空:
- 若有分组集,跳过非空分组集,设置
input_done = true。 - 若无分组集,设置
agg_done = true(非AGG_PLAIN返回NULL)。
- 若有分组集,跳过非空分组集,设置
- 若有效,复制到
- 调用
- 分支:若
-
初始化和处理分组:
- 调用
initialize_aggregates初始化聚合状态。 - 若
grp_firstTuple != NULL:- 存储到
firstSlot,清空grp_firstTuple。 - 循环处理外层元组:
- 若
AGG_MIXED且current_phase = 1,调用lookup_hash_entries更新哈希表。 - 调用
advance_aggregates推进聚合。 - 重置
tmpcontext。 - 获取下一个元组,若为空,处理溢出(
AGG_MIXED)并设置input_done或agg_done。 - 若分组(非
AGG_PLAIN),检查分组边界,若不同,复制新元组到grp_firstTuple,退出循环。
- 若
- 存储到
- 调用
-
投影结果:
- 设置
econtext->ecxt_outertuple = firstSlot。 - 调用
prepare_projection_slot和finalize_aggregates。 - 调用
project_aggregates,若返回有效result,返回;否则继续循环。
- 设置
-
返回结果:
- 若无更多分组,返回
NULL。
- 若无更多分组,返回
示例查询关联
示例查询:
SELECT DISTINCT a FROM t1 LIMIT 10;
查询计划(假设使用 AGG_SORTED 而非 HashAggregate):
Limit (cost=21.50..21.60 rows=10 width=4) (actual time=0.723..0.728 rows=10 loops=1)Output: aBuffers: shared hit=9-> Sort (cost=21.50..22.50 rows=100 width=4) (actual time=0.721..0.725 rows=10 loops=1)Output: aSort Key: t1.aBuffers: shared hit=9-> Seq Scan on public.t1 (cost=0.00..19.00 rows=1000 width=4) (actual time=0.018..0.198 rows=1000 loops=1)Output: a, bBuffers: shared hit=9
Planning Time: 0.131 ms
Execution Time: 0.767 ms
关联说明:
- 步骤 1:
aggstrategy = AGG_SORTED,numGroupingSets = 1,peragg = NULL(DISTINCT无聚合函数),firstSlot为扫描槽。 - 步骤 2:
agg_done = false,projected_set = -1,重置econtext,numReset = 1。 - 步骤 3:
nextSetSize = 0(单分组集)。 - 步骤 4:设置
projected_set = 0。 - 步骤 5:
grp_firstTuple = NULL,调用fetch_input_tuple获取1000行(t1.a值),复制第一个元组。 - 步骤 6:
- 初始化聚合(空操作)。
- 存储
grp_firstTuple到firstSlot,循环处理元组:- 调用
advance_aggregates(记录t1.a去重)。 - 获取下一个元组,检查分组边界(
t1.a值不同时退出)。 - 若输入耗尽,设置
agg_done = true.
- 调用
- 步骤 7:设置
ecxt_outertuple,调用project_aggregates,返回t1.a(10行,受LIMIT 10限制)。 - 步骤 8:第
11次返回NULL.
Mermaid 流程图(原始逻辑)
以下是 Mermaid 流程图,展示 agg_retrieve_direct 的原始逻辑,细化分支:
总结
以下是基于 PostgreSQL HashAggregate 相关函数的精简调用关系流程图,使用 Mermaid 语法,仅列出函数名称和中文操作解释,突出调用关系,聚焦原始逻辑。
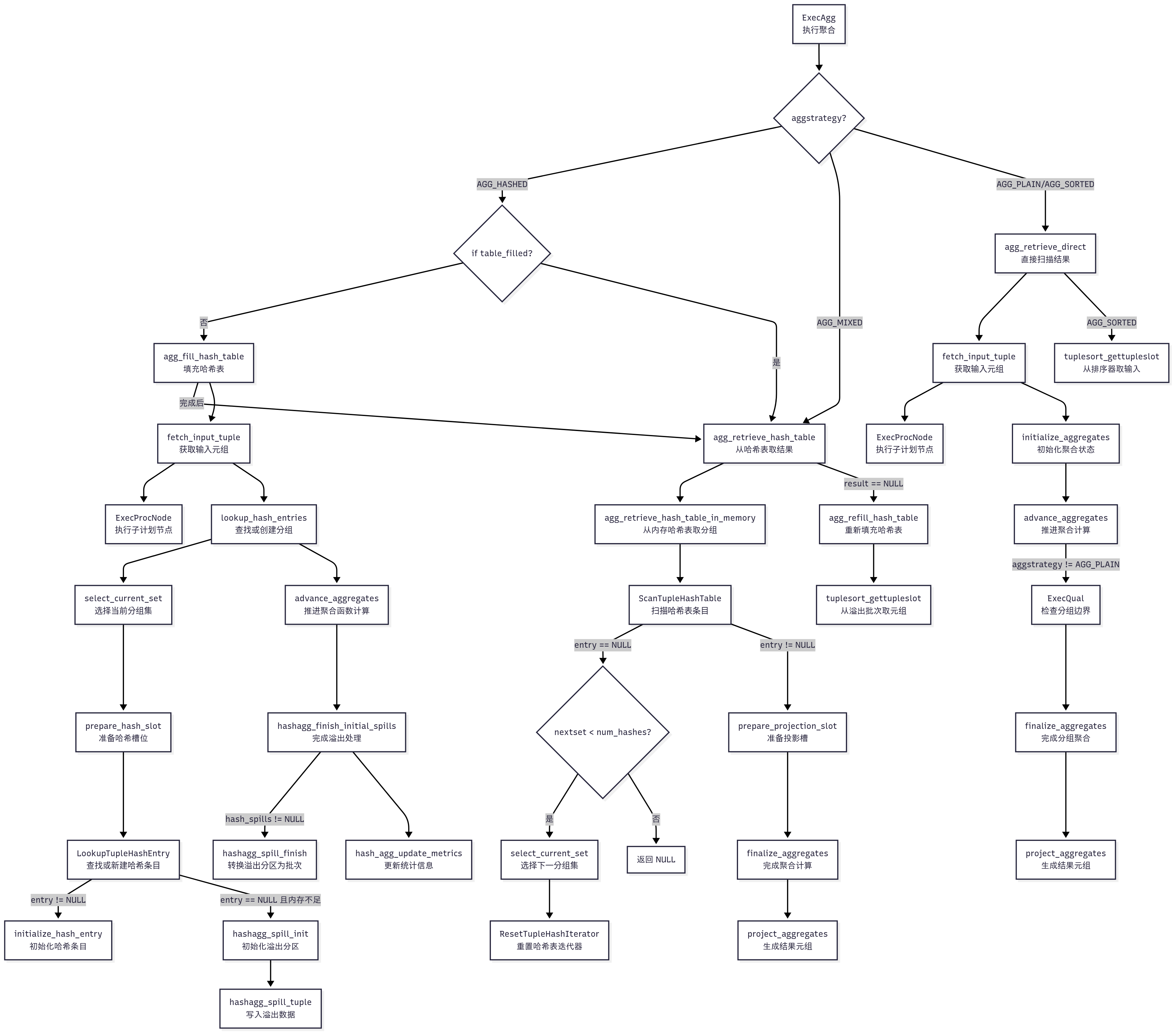
函数名称与中文操作解释
以下是将上述内容整理为表格形式的结果:
| 序号 | 名称 | 功能描述 |
|---|---|---|
| 1 | ExecAgg | 执行聚合,分派策略 |
| 2 | agg_fill_hash_table | 填充哈希表,处理输入元组 |
| 3 | fetch_input_tuple | 获取输入元组 |
| 4 | ExecProcNode | 执行子计划节点(如 Seq Scan) |
| 5 | lookup_hash_entries | 查找或创建分组 |
| 6 | select_current_set | 选择当前分组集 |
| 7 | prepare_hash_slot | 准备哈希槽位 |
| 8 | LookupTupleHashEntry | 查找或新建哈希条目 |
| 9 | initialize_hash_entry | 初始化哈希条目 |
| 10 | hashagg_spill_init | 初始化溢出分区 |
| 11 | hashagg_spill_tuple | 写入溢出数据 |
| 12 | advance_aggregates | 推进聚合函数计算 |
| 13 | hashagg_finish_initial_spills | 完成溢出处理 |
| 14 | hashagg_spill_finish | 转换溢出分区为批次 |
| 15 | hash_agg_update_metrics | 更新统计信息 |
| 16 | agg_retrieve_hash_table | 从哈希表取结果 |
| 17 | agg_retrieve_hash_table_in_memory | 从内存哈希表取分组 |
| 18 | ScanTupleHashTable | 扫描哈希表条目 |
| 19 | ResetTupleHashIterator | 重置哈希表迭代器 |
| 20 | prepare_projection_slot | 准备投影槽 |
| 21 | finalize_aggregates | 完成聚合计算 |
| 22 | project_aggregates | 生成结果元组 |
| 23 | agg_refill_hash_table | 重新填充哈希表 |
| 24 | tuplesort_gettupleslot | 从溢出批次或排序器取元组 |
| 25 | initialize_aggregates | 初始化聚合状态 |
| 26 | ExecQual | 检查分组边界 |
示例查询关联(SELECT DISTINCT a FROM t1 LIMIT 10)
- 计划:
Limit -> HashAggregate -> Seq Scan,Batches: 1,Memory Usage: 24kB. - 调用路径:
- ExecAgg:
aggstrategy = AGG_HASHED,初次table_filled = false,调用agg_fill_hash_table,然后agg_retrieve_hash_table。 - agg_fill_hash_table:循环调用
fetch_input_tuple(通过ExecProcNode获取1000行),lookup_hash_entries(调用select_current_set,prepare_hash_slot,LookupTupleHashEntry,initialize_hash_entry构建哈希表,100个唯一t1.a值),advance_aggregates(去重),hashagg_finish_initial_spills(调用hash_agg_update_metrics,无溢出,hash_spills = NULL)。 - agg_retrieve_hash_table:调用
agg_retrieve_hash_table_in_memory(调用ScanTupleHashTable,prepare_projection_slot,finalize_aggregates(空操作),project_aggregates),返回10行,无需agg_refill_hash_table(无溢出)。 - agg_retrieve_direct:未触发。
- ExecAgg: