网站被host重定向wordpress图像居中
文章目录
- 数据的准备
- 调用sklearn.datasets中的make_blobs产生300个样本数据,并加工部分数据使其脱离离散群
- 过程
- 示例
- 代码如下
- 原始数据分布图
- x1和x2的柱状分布图
- 拟合高斯分布图
- 异常点检测结果图
- 异常检测实战summary
- **核心要点**
- **扩展建议**
数据的准备
调用sklearn.datasets中的make_blobs产生300个样本数据,并加工部分数据使其脱离离散群
代码如下:
import pandas as pd
from sklearn.datasets import make_blobs# 生成带离群点的数据
#参数说明:
# n_samples=300:生成300个样本点。
# centers=2:生成2个聚类中心(即2个类别)。
# cluster_std=1.0:每个聚类的标准差为1.0(控制聚类的紧密程度,值越大点越分散)。
# random_state=42:固定随机种子,确保每次生成的数据相同。
#返回值:
# X:特征数据,形状为 (300, 2) 的二维数组(默认生成2维数据,方便可视化)。
# y:类别标签(0或1),对应两个聚类。
X, y = make_blobs(n_samples=300, centers=2, cluster_std=1.0, random_state=42)X[-10:] += 5 #将最后10个点变为离群点(人为添加异常),将这10个点在所有特征维度上偏移+5(远离原始聚类中心)
df = pd.DataFrame(X, columns=["x1","x2"])
df.to_excel("abnormal.xlsx", index=False)
过程
- 读取数据
- 画出原始分布图
- 计算x1,x2的平均值和标准差
- 构建高斯分布概率密度函数,并可视化
- 建模型,并进行预测
- 可视化预测结果
- 通过修改概率密度阈值
contamination,调整异常点检测的灵敏度。
示例
代码如下
# load data
import pandas as pd
import numpy as npdata= pd.read_excel('abnormal.xlsx')
print(data.head())
#visualization
from matplotlib import pyplot as plt# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
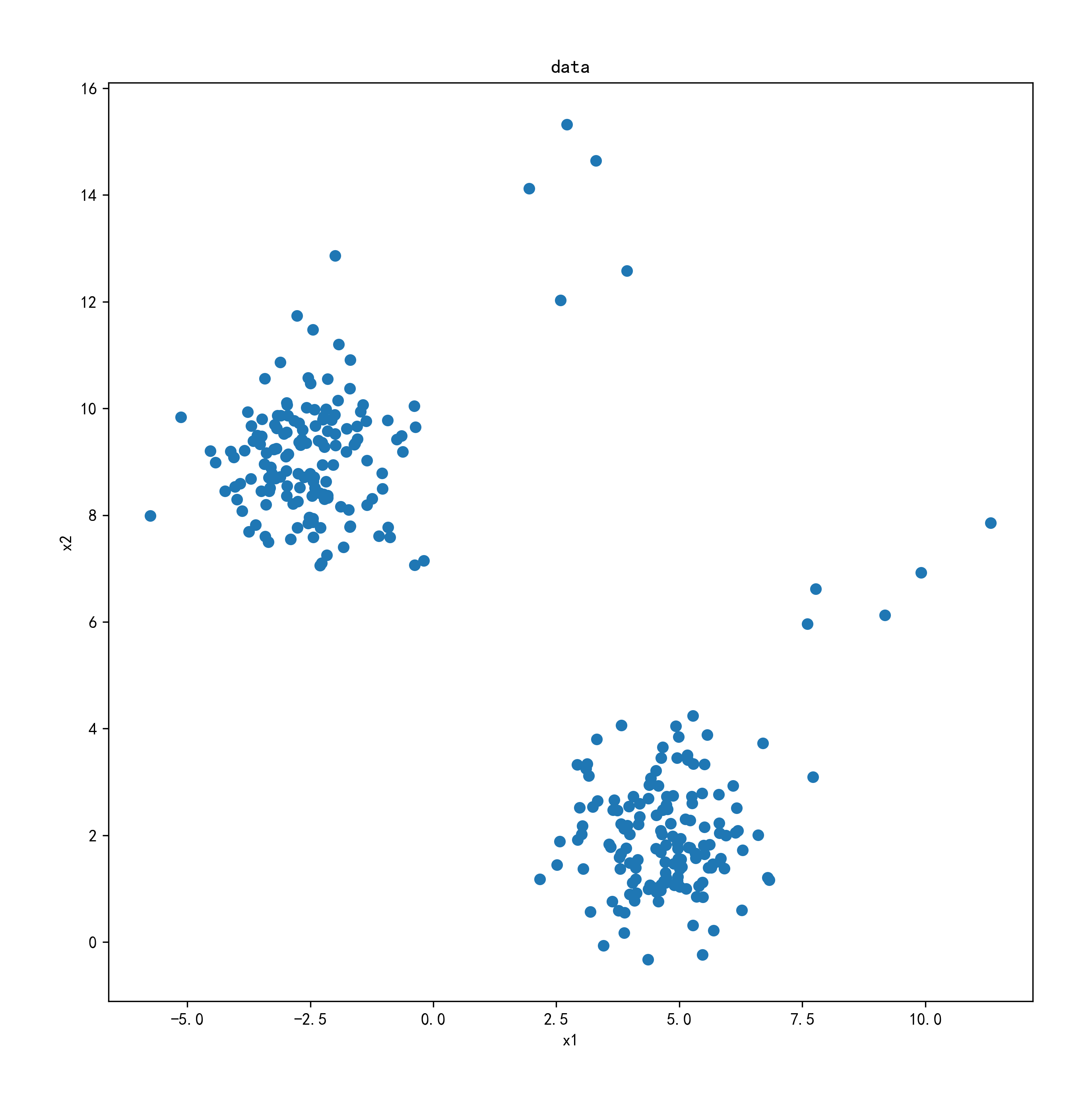
plt.rcParams['axes.unicode_minus'] = Falsefig = plt.figure(figsize=(10, 10))plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'])
plt.title('data')
plt.xlabel('x1')
plt.ylabel('x2')
plt.savefig('original.png', dpi=300, bbox_inches='tight', pad_inches=0.5)
#
# plt.show()#define x1,x2
x1=data.loc[:,'x1']
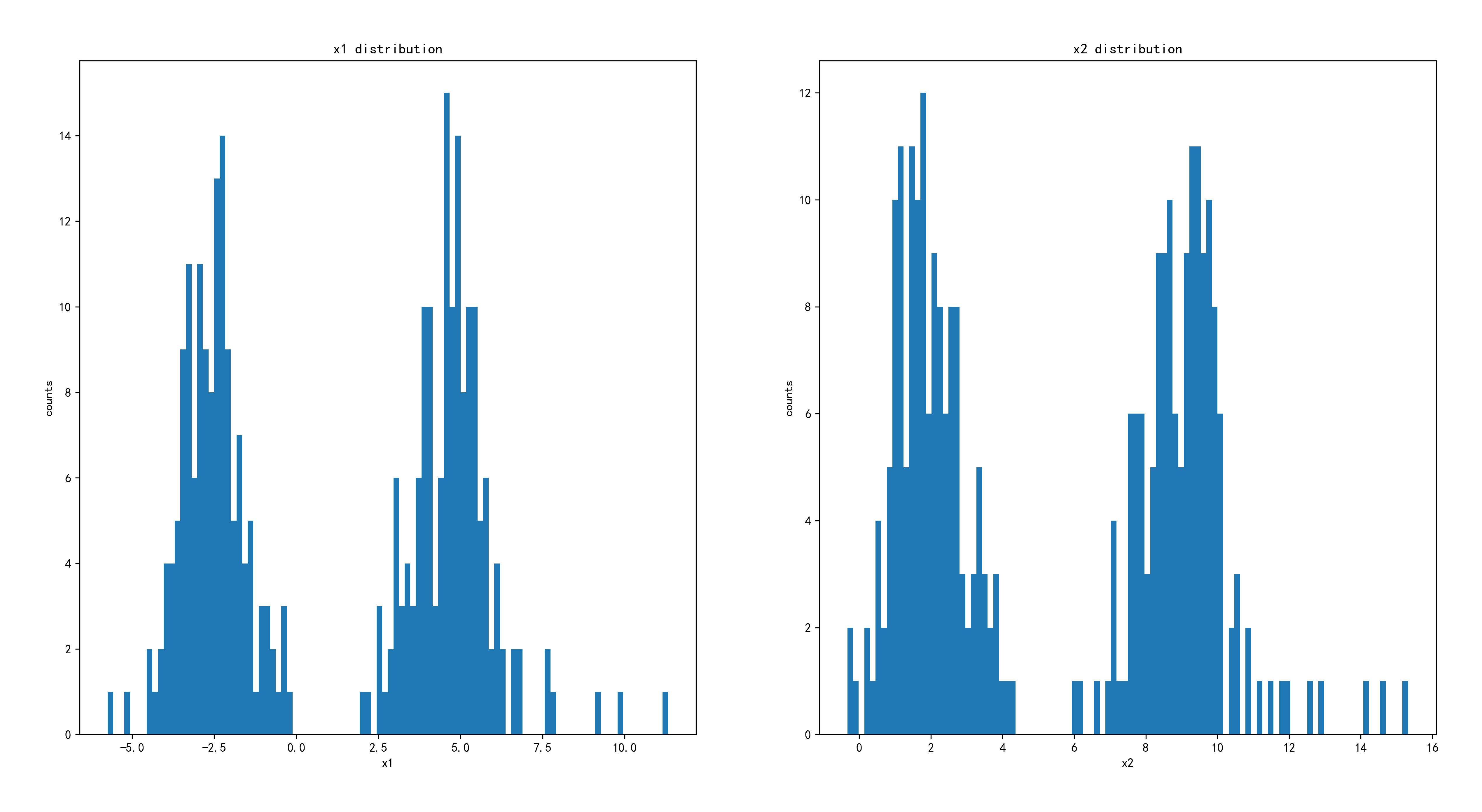
x2=data.loc[:,'x2']fig2 = plt.figure(figsize=(20, 10))
plt.subplot(121)
plt.hist(x1,bins=100)
plt.title('x1 distribution')
plt.xlabel('x1')
plt.ylabel('counts')
plt.subplot(122)
plt.hist(x2,bins=100)
plt.title('x2 distribution')
plt.xlabel('x2')
plt.ylabel('counts')
plt.savefig('distribution.png', dpi=300, bbox_inches='tight', pad_inches=0.5)#Calculate the mean and sigma of x1 and x2x1_mean=x1.mean()
x1_sigma=x1.std()
x2_mean=x2.mean()
x2_sigma=x2.std()#calculate Gaussian distribution p(x)
from scipy.stats import norm
x1_range=np.linspace(0,20,300)
x1_normal=norm.pdf(x1_range,x1_mean,x1_sigma)
x2_range=np.linspace(0,20,300)
x2_normal=norm.pdf(x2_range,x2_mean,x2_sigma)
#visulizae the p(x)
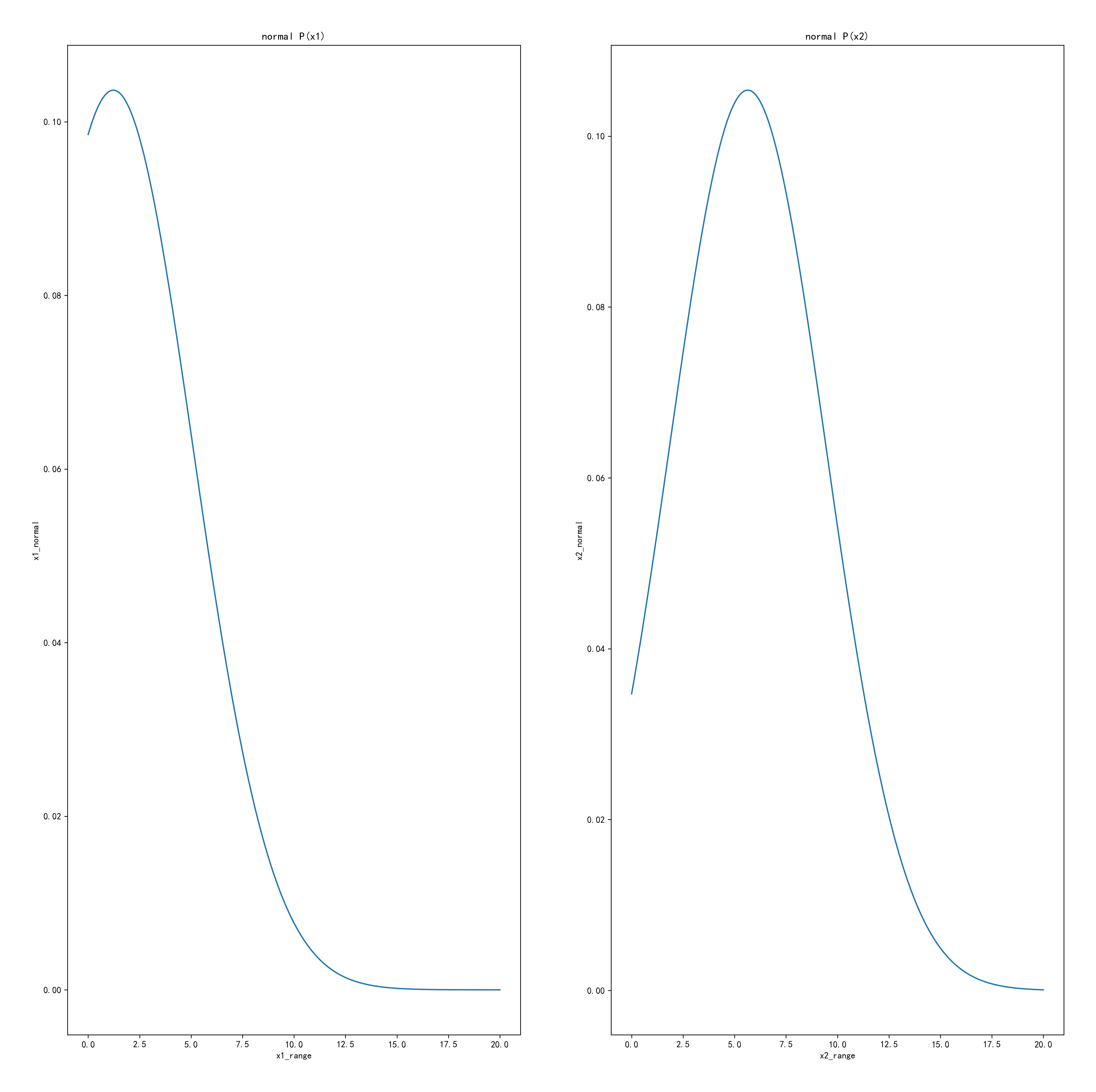
fig3=plt.figure(figsize=(20,20))
plt.subplot(121)
plt.plot(x1_range,x1_normal)
plt.title('normal P(x1)')
plt.xlabel('x1_range')
plt.ylabel('x1_normal')
plt.subplot(122)
plt.plot(x2_range,x2_normal)
plt.title('normal P(x2)')
plt.xlabel('x2_range')
plt.ylabel('x2_normal')
plt.savefig('normal.png', dpi=300, bbox_inches='tight', pad_inches=0.5)#establish the model and predict
from sklearn.covariance import EllipticEnvelope
ad_normal=EllipticEnvelope(contamination=0.05) #默认为0.1
ad_normal.fit(data)
y_predict=ad_normal.predict(data)
# print(pd.value_counts(y_predict))
print(pd.Series(y_predict).value_counts())
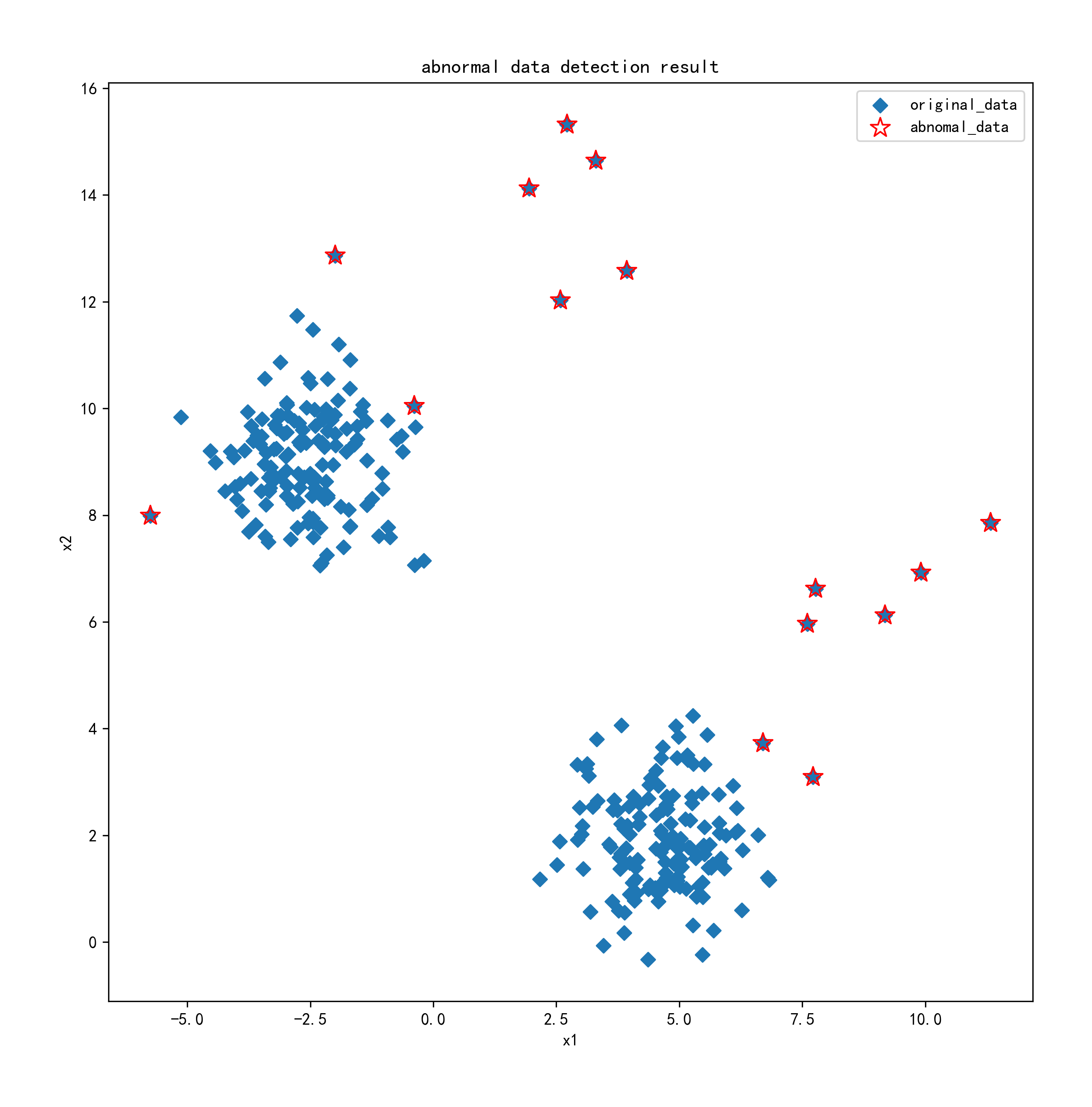
fig4 = plt.figure(figsize=(10, 10))original_data=plt.scatter(data.loc[:,'x1'],data.loc[:,'x2'],marker='D')
abnomal_data=plt.scatter(data.loc[:,'x1'][y_predict==-1],data.loc[:,'x2'][y_predict==-1],marker='*',facecolor='none',edgecolor='red',s=150)
plt.title('abnormal data detection result')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend((original_data,abnomal_data),('original_data','abnomal_data'))
plt.savefig('abnormal_detect.png', dpi=300, bbox_inches='tight', pad_inches=0.5)原始数据分布图
x1和x2的柱状分布图
拟合高斯分布图
异常点检测结果图
异常检测实战summary
核心要点
-
方法原理
通过计算数据各维度对应的高斯分布概率密度函数,可用于寻找到数据中的异常点。
- 技术细节:假设数据服从多元高斯分布,低概率密度的点被视为异常。
-
参数调整
通过修改概率密度阈值
contamination,可调整异常点检测的灵敏度。- 关键参数:
contamination:默认为0.1,表示数据中异常点的预期比例(范围0~0.5)。
- 关键参数:
-
算法参考
核心算法参考链接:
EllipticEnvelope文档- 用途:适用于数据分布近似高斯时的异常检测(如金融风控、工业质检)。
扩展建议
-
非高斯数据:
若数据不服从高斯分布,可改用:IsolationForest(基于隔离的异常检测)LocalOutlierFactor(基于局部密度的异常检测)
-
参数调优:
通过交叉验证(如GridSearchCV)优化contamination。