SkyVLN: 城市环境中无人机的视觉语言导航和 NMPC 控制;香港科技大学
##论文记录
本文提出SkyVLN这一新型框架,将视觉 - 语言导航(VLN) 与非线性模型预测控制(NMPC) 相融合,以提升无人机在复杂城市环境中的自主性;该框架配备多模态导航智能体,含细粒度空间描述器(HSD) 和历史路径记忆机制(TBMA) ,能解决空间歧义、处理模糊指令并实现回溯,同时通过 NMPC 模块实现动态避障;基于 AirSim 构建高保真 3D 城市仿真环境,在 AVDN 数据集上的实验表明,SkyVLN 在可见和不可见环境中均显著提升导航成功率(如不可见测试集成功率达 42.37%)和效率,优于 Random、CMA、NavGPT 等基线模型。

一、研究背景与意义
- 无人机应用现状:无人机因自主性、机动性和适应性,在监控 、物流(优化路径规划与库存管理,提升配送效率 )、搜救、医疗等领域广泛应用,成为多功能工具。
- 技术发展驱动:大型语言模型(LLMs)能学习应用行为、处理多模态输入(视觉 + 自然语言),通过预训练的视觉 - 语言通用表示实现任务规划与常识推理,为无人机视觉 - 语言导航(VLN)提供可能。
- 现有挑战
- 跨模态接地问题:LLM/VLM 如何增强视觉与语言的跨模态关联未明确。
- 定量效能缺失:视觉定位与语言衍生空间描述的定量效果未探索。
- 空中导航特殊性:相比地面导航,空中导航面临3D 动作空间(需 “上升”“下摇” 等动作)、复杂视觉定位(高楼遮挡 GNSS 信号)、动态避障(长路径 + 天气 / 光照影响)三大难题。
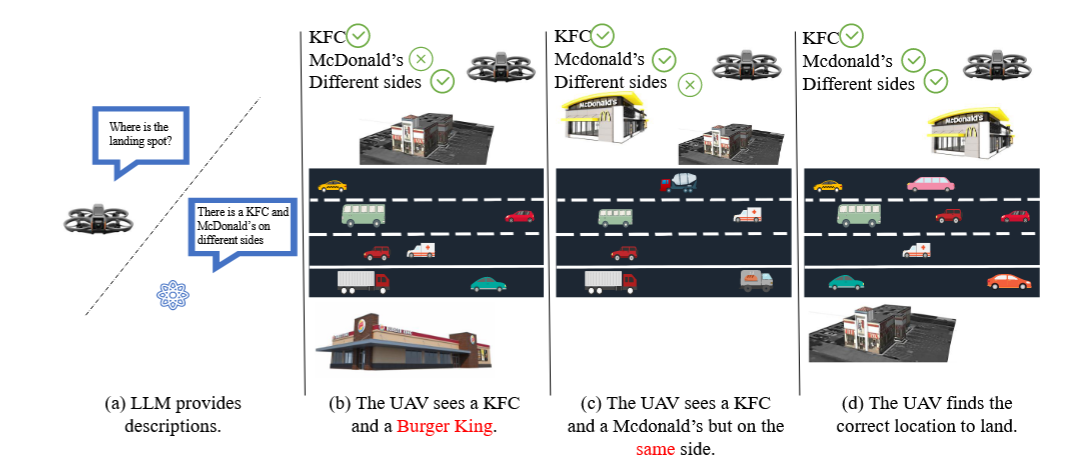
Fig 1:具有位置识别功能的无人机的视觉与语言导航。语言模型(LLM)为无人机提供设计好的着陆点的口头描述(a)。无人机将自身的视觉观察结果与 LLM 的描述(b)至(d)进行对比,并对这些描述的准确性进行推理,从而确认d)作为正确的位置。
相关工作
三种类型的无人机visual language navigation VLN模式。Direct(直接控制)、Instruction-level(指令式)以及end-to-end(端到端式)。
1)直接控制:
核心方式:通过预编程指令控制无人机运动,依据预定义路径或实时传感器数据实现。
优势场景:适用于目标明确、环境清晰的任务,能满足精准机动需求,效率较高。
局限性:
灵活性不足:在存在倒塌建筑的城区、复杂电磁环境或突发干扰场景中,易出现飞行不稳定。
自主性欠缺:无法独立处理任务,不适合长时间作业或远程操作。
2)指令式:
指令级控制指通过解读高级命令或指令来引导无人机行为,该方式能实现更具人性化的人机交互,让无人机可依据自然语言指令适应环境变化。
局限性:
自然语言指令可能存在歧义,导致无人机产生误解读,进而引发错误操作或任务失败
3)端到端式:
借助机器学习技术,将感知输入直接映射为控制动作,无需人工设计特征提取和决策流程。该类系统在处理复杂数据结构方面展现出潜力,且在不同环境中具备更优的泛化能力。
局限性:
一方面,端到端策略需大量高质量训练数据才能实现良好性能,而这类数据(尤其针对特定或小众应用场景)获取难度较大;另一方面,其模型在全新或未见过的环境中泛化能力较差,易导致性能下降。
二、核心框架:SkyVLN 设计
SkyVLN 是融合视觉 - 语言导航与非线性模型预测控制(NMPC)的框架,架构如图 2 所示,含三大核心模块:
工作流程:
- 智能体(Agent)先通过视觉与语言信息感知环境;
- 寻路提示优化(WPO)模块从感知结果中提取更丰富的空间信息,同时借助存储历史轨迹的记忆层,为模糊导航任务提供更多导航线索;
- 大语言模型(LLM)运动生成器以上述两个模块的导航提示,以及系统提示、动作提示作为输入,输出当前思考与动作
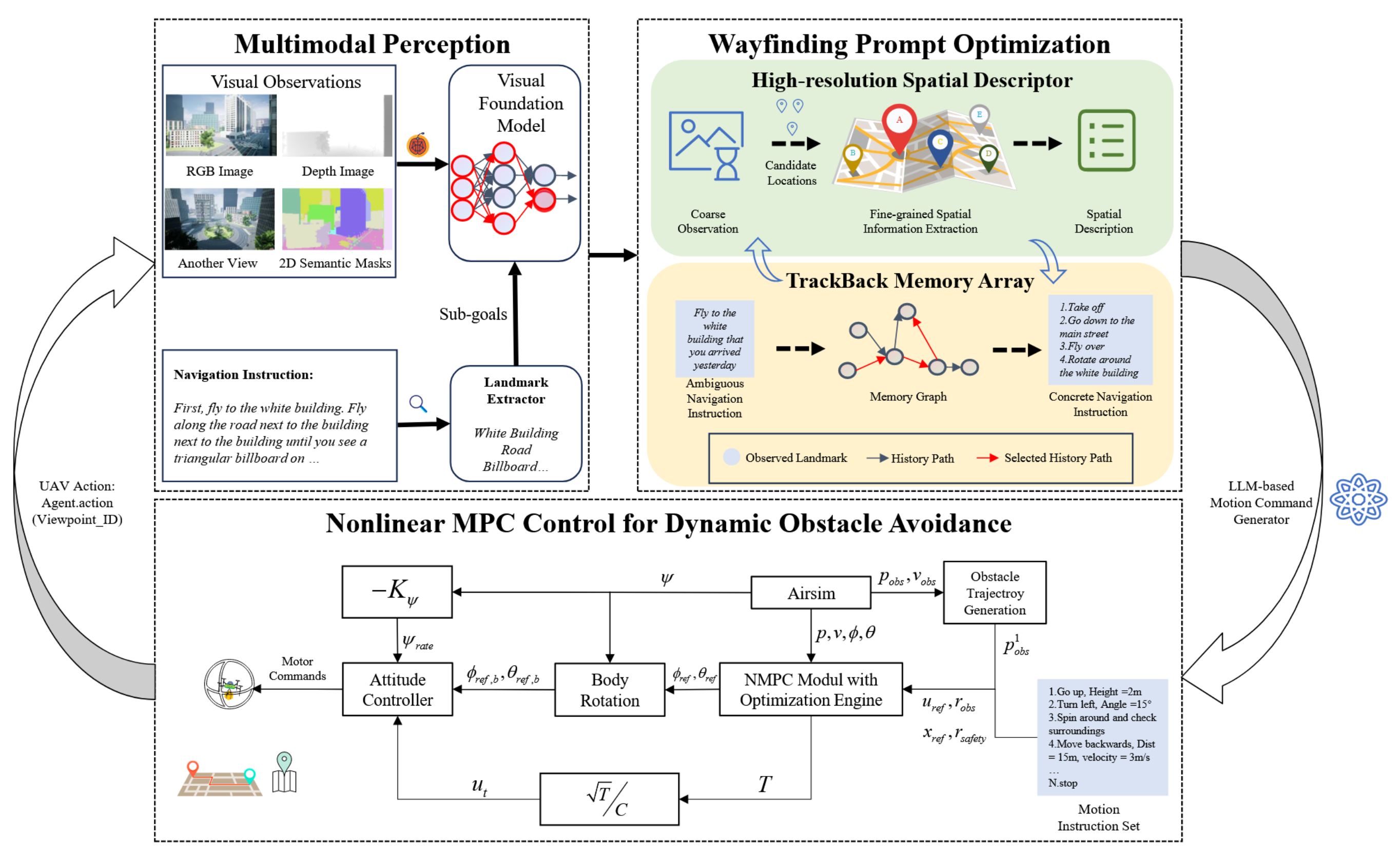
Fig2. VLN代理的整体体系结构可以考虑指令和视觉感知。该解决方案不需要监督培训。提议WPO进一步完善定位精度。
- 初始位姿:每轮任务初,智能体有 12 参数初始位姿 P,含位置 [x,y,z]、线速度 [u,v,w]、姿态角 [φ,θ,ψ] 及角速度 [p,q,r]。
- 任务要求:接收自然语言指令 X(含 L 个词元 wᵢ),需结合指令与视觉感知预测动作。
- 感知限制:虽模拟器支持全景观测,但基线智能体仅获前视 RGB、深度、语义图像,需旋转获取其他视角。
- 终止条件:执行 STOP 动作,或动作数达预设最大值,导航结束。
(一)多模态感知模块
- 视觉感知设备:无人机前置广角相机,可沿俯仰轴上下旋转 90°,需旋转自身获取全景图像,输出RGB 图像、深度图像、语义分割图像三种前视观测数据。(无人机怎么看世界)
- 地标检测与筛选:采用现成视觉 - 语言模型GroundingDINO 粗检测图像中的地标,若同一地标出现在多视角中,选择得分最高的视角作为该地标观测视角。(无人机怎么懂指令)
- 指令子目标提取:利用预训练 LLM(擅长零样本学习与语境理解)从自然语言指令 T 中提取地标短语,形成地标集合 L,公式为:L=LLM ( T, prompt ) (1)(无人机怎么 “聪明地找路”)
该过程将指令分解为子目标,支持分步推理、自适应路径规划与回溯探索(如图 3)。
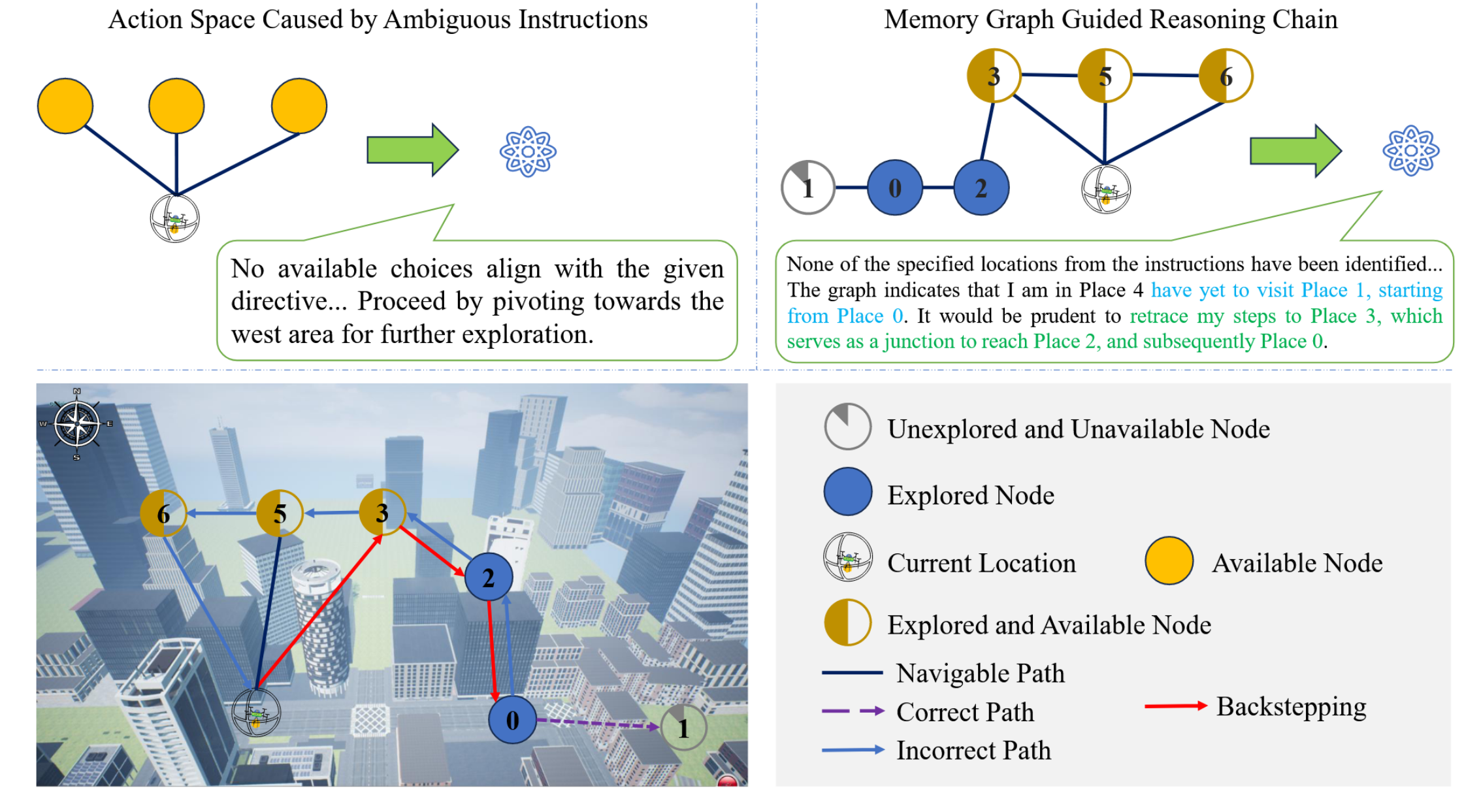
Fig3. GPT代理没有内存图的GPT代理的思维过程的比较。给定有模棱两可的说明的模棱两可的描述,代理可以漫无目的地探索,尤其是在已经发生导航错误时。
左边:没有记忆图的情况
当指令模棱两可时,机器人拿到指令后,发现没有能和指令对上的选择,就只能 “盲目探索”,比如图里说 “朝着西边区域转,继续探索”。就像你没带地图,别人跟你说 “去几个地方”,但没说清楚顺序,你就只能随便选个方向瞎走。
右边:有记忆图的情况
记忆图就像机器人的 “导航记忆本”,会记录哪些地方探索过(蓝色节点)、当前位置(带机器人标的)、哪些路能走(可导航路径)等。当发现指令里指定的地点都还没找到时,记忆图会提示 “该往回走啦”,比如图里说 “得回到地点 3,从那儿能去地点 2,再到地点 0”。这样机器人就不会瞎逛,能根据 “记忆本” 规划更合理的路线。
(二)寻路提示优化(WPO)
用于填补感知结果与推理输入间的差距,含两个互补子模块:
- 高分辨率空间描述器(HSD)
- 解决问题:仅基于无人机视角的粗略空间描述,无法让 LLM 精准判断地标相对位置(如 “前方道路” 可能居中或偏侧)。
- 实现方式:将无人机每个视角划分为9 个特定扇区(如 “#0” 代表左上扇区),结合视觉特征与文字特征,让 LLM 对查询 - 候选对生成描述并排序,精准表述地标在扇区中的坐标(如图 4)。
- 为了解决之前无人机只能模糊描述地标位置的问题,研究里设计了 “高分辨率空间描述器(HSD)” 这个工具:
HSD 先将无人机每个视角分成 9 块带专属标记(如左上角为 “#0”)的区域;再融合无人机图像提取的视觉特征与地标文字提取的文字特征。查询特定地标时,先挑出最像的前几个候选,让 LLM 为 “查询 - 候选” 组合写描述,对比描述与查询的相似度并排序,最终能精确到地标在 9 块区域中的具体位置,避免 “前方” 这类模糊表述,帮无人机精准找地标。
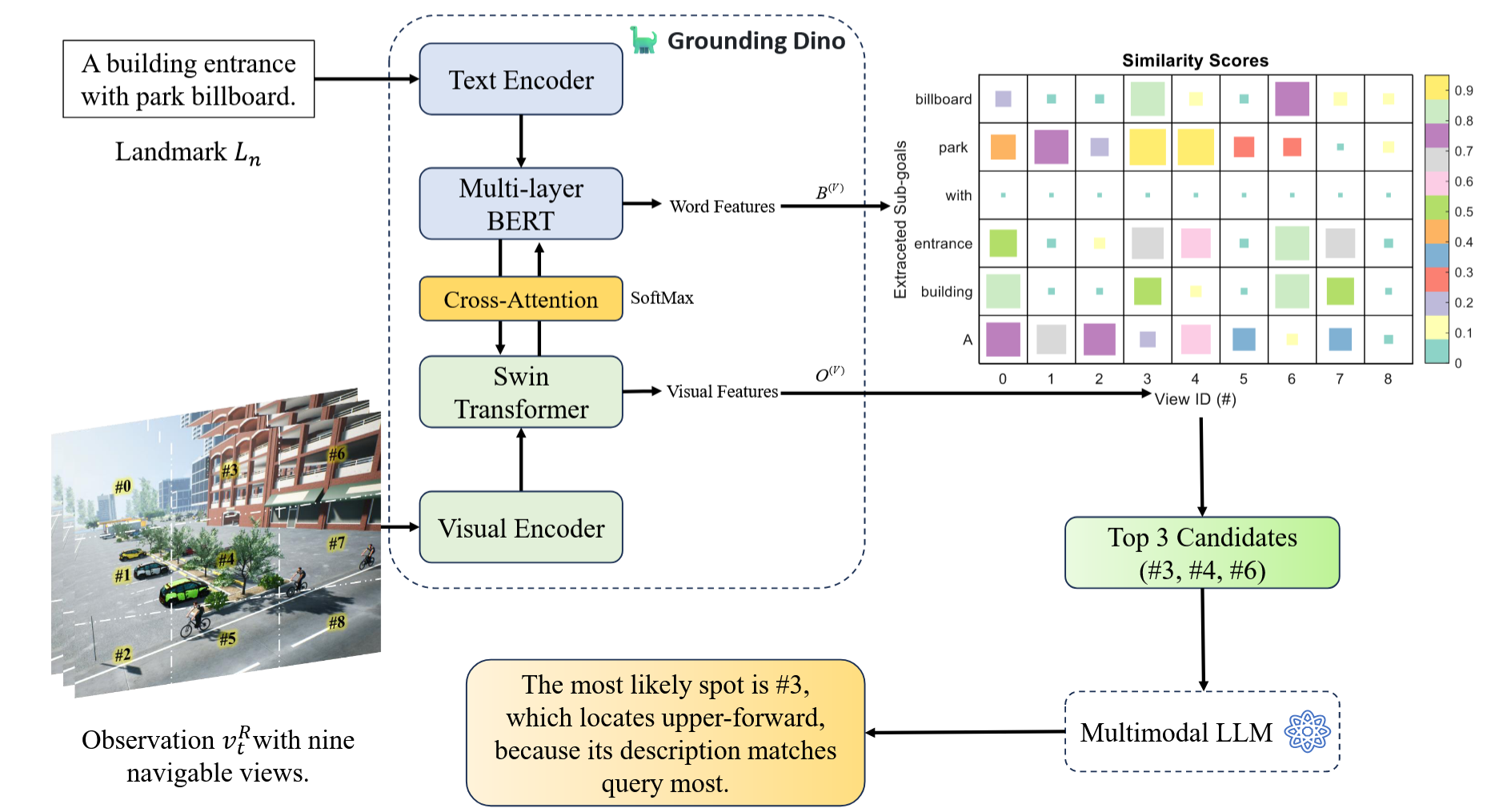
Fig.4:具有里程碑标记的细粒视觉识别器的示意性结构。分数矩阵显示出更高的分数。 LLM根据描述性文本评估并对查询视图对进行排名
- 回溯记忆阵列(TBMA)
- 解决问题:模糊指令(如 “左转→右转→直行”)无地标参考,导致无人机重复动作或盲目探索(如图 3 左)。
- 实现方式:以图结构存储无人机历史轨迹(节点为已遇地标,边为地标间导航指令),通过最短路径算法,基于当前观测地标与目标地标生成可行路径;同时设计格式化提示,让 LLM 向指令发送者请求澄清。
- 协同作用:HSD 检测到模糊地标(如 “白色建筑”)时,触发 TBMA 查询历史参考,TBMA 提供时间上下文后,HSD 重新聚焦相关区域提取特征,优化路径规划。
- 通过在 TBMA 中纳入 “历史节点”(即过去遇到的地标),无人机不再是 “局部盲目导航”,而是能:理解环境的空间结构(比如地标间的相对位置、连接关系);实现全局探索(而非局限于当前视野)和路径规划(基于历史信息规划更合理的路线)。
- 用 TBMA 构建 “空间记忆图” 解决路径存储与检索,用 LLM 解决指令澄清与动作决策,最终让无人机能更智能地完成导航任务。
(三)非线性 MPC 控制(动态避障)
该模块是 SkyVLN 的 “动作执行层”,负责将 LLM 规划的 “路径” 转化为 “安全、精准的飞行控制指令”,核心解决 “动态障碍物避障” 与 “轨迹跟踪精度” 问题,是无人机在复杂城市环境中安全飞行的关键:
文章自定义了6 自由度(6-DoF)无人机动力学模型,公式如下:
{p˙(t)=v(t),v˙(t)=R(ϕ,θ)[00T]+[00−g]−Av(t),A=[Ax000Ay000Az],ϕ˙(t)=1τϕ(Kϕϕref(t)−ϕ(t)),θ˙(t)=1τθ(Kθθref(t)−θ(t)),
\left\{\begin{array}{l} \dot{p}(t)=v(t), \\ \dot{v}(t)=R(\phi, \theta)\left[\begin{array}{l} 0 \\ 0 \\ T \end{array}\right]+\left[\begin{array}{c} 0 \\ 0 \\ -g \end{array}\right]-A v(t), \\ A=\left[\begin{array}{ccc} A_{x} & 0 & 0 \\ 0 & A_{y} & 0 \\ 0 & 0 & A_{z} \end{array}\right], \\ \dot{\phi}(t)=\frac{1}{\tau_{\phi}}\left(K_{\phi} \phi_{ref}(t)-\phi(t)\right), \\ \dot{\theta}(t)=\frac{1}{\tau_{\theta}}\left(K_{\theta} \theta_{ref}(t)-\theta(t)\right), \end{array}\right.
⎩⎨⎧p˙(t)=v(t),v˙(t)=R(ϕ,θ)00T+00−g−Av(t),A=Ax000Ay000Az,ϕ˙(t)=τϕ1(Kϕϕref(t)−ϕ(t)),θ˙(t)=τθ1(Kθθref(t)−θ(t)),
关键参数含义:p(t)p(t)p(t)为无人机位置,(v(t))为速度,(R(\phi,\theta))为欧拉角旋转矩阵(描述姿态),T为电机总推力,g为重力加速度,A为线性阻尼矩阵(影响速度衰减),(\phi/\theta)为横滚 / 俯仰角,(K_{\phi}/K_{\theta})为控制增益,(\tau_{\phi}/\tau_{\theta})为时间常数(描述姿态响应速度)。
核心作用:该模型精准描述无人机的 “位置 - 速度 - 姿态” 动态变化规律,确保 NMPC 模块生成的控制指令符合物理定律,避免 “不可能的动作”(如瞬间大幅转向)。

面向动态障碍物的无人机(UAV)避撞与控制的非线性模型预测控制(Nonlinear MPC)算法,核心逻辑是通过 “实时感知 - 未来预测 - 优化求解 - 执行控制” 的循环,实现无人机在动态障碍物环境下的安全航行,以下是分模块的简要解析:
- 核心概念与输入输出
- 核心技术:非线性 MPC(模型预测控制)
MPC 的本质是 “滚动时域优化”—— 不计算全局轨迹,而是在每个时刻基于当前状态,优化未来一段 “预测时域” 内的控制量,仅执行第一个控制量后,下一时刻重新迭代,适配动态环境。 - 输入(Input):算法启动前需明确的初始条件与参数
- 无人机初始状态(SUAV (0)):如位置、速度、姿态等;
- 动态障碍物初始状态(Cobstacles (0)):如障碍物的初始位置、运动速度;
- 时间参数:预测时域 Tp(预测未来多久的状态)、控制时域 Tc(优化未来多少步的控制量);
- 安全约束 C:如无人机与障碍物的最小安全距离、无人机自身的物理限制(如最大速度、加速度)。
- 输出(Output):最优控制输入 u*
即无人机的执行指令(如电机转速、舵面偏转量等),需满足 “避撞” 与 “跟踪目标(如航点)” 的双重需求。
关键特点(适配 “动态障碍物” 与 “无人机控制”)
- 动态障碍物适配:通过实时测量 + 未来预测,主动规避障碍物的运动(而非仅考虑障碍物当前位置),适合如 “移动车辆”“其他无人机” 等动态场景;
- 非线性适配:明确标注 “Nonlinear MPC”,可处理无人机的非线性动力学模型(如无人机高速飞行时的空气阻力、姿态耦合等非线性特性),比线性 MPC 更贴合实际;
- 约束显式化:将 “避撞”“执行器极限” 作为硬约束写入优化问题,确保控制结果一定满足安全与物理限制,避免 “可行解不安全” 的问题。
总结一下(公式不太好打,直接说结论吧):
前用的 PID 控制,就像 “看到歪了再调”—— 飞偏了才纠正,遇到突然冒出来的障碍反应不过来;而 NMPC 是 “提前预判 + 优化”,能更早发现要撞上障碍,调整动作也更平滑,既不会飞歪太多,也不会因为突然躲障碍而晃得厉害。实验里也验证了,用 NMPC 时,无人机的飞行轨迹更贴参考路线,位置误差小,遇到动态障碍(比如移动的车辆)也能躲开。
三 3D 实验平台的构建
3D 城市环境设计(3D Environment)
该模块构建了仿真平台的 “物理世界基础”,包含多类贴合真实城市的实体元素,确保无人机的视觉观测与空间认知场景具有真实性,具体元素分类如下:
| 元素类别 | 具体内容 | 设计意义 |
|---|---|---|
| 建筑实体 | 商场、住宅小区、公共设施、办公楼、宿舍、信号塔;建筑细节(屋顶太阳能板、外墙空调外机、大门、广告牌) | 提供丰富地标(如广告牌、建筑外观),模拟无人机导航中需识别的视觉参照;建筑细节提升地标辨识度,避免 “同类建筑难以区分” 的问题 |
| 街道系统 | 车道、十字路口、交通信号灯、道路标线、自行车道 | 复现城市中 “需按规则导航” 的场景(如 “穿过十字路口左转”),匹配自然语言指令中的常见路况描述 |
| 动态元素 | 模拟车辆(按真实交通流规律行驶)、模拟行人(按日常行为移动) | 为 NMPC 模块的 “动态避障” 功能提供测试场景,验证框架在移动障碍物环境中的鲁棒性 |
| 城市配套设施 | 街道家具(长椅、路灯、指示牌)、植被(树木、灌木、草坪)、城市便利设施(公交站、建筑入口、公共卫生间) | 丰富环境细节,让视觉观测更贴近真实(如 “公交站旁的树木” 可作为辅助地标),同时模拟无人机可能遇到的非障碍类干扰元素 |
| 此外,该 3D 环境的核心优势在于 “高保真”—— 不仅 3D 模型精度高(如建筑外观纹理、设施比例还原真实),还支持实时数据整合(如动态元素的运动状态实时更新),且专门针对无人机仿真优化,能适配空中视角的观测需求(如建筑顶部细节清晰,便于无人机从高空识别地标)。 | ||
 |
模块 2:VLN 模拟器开发(VLN Simulator)
- 开发基础:基于 AirSim 和 Unreal Engine 4 开发。
- 视觉观测:
- 智能体可在连续户外环境中自由移动与观测;
- 每一步可输出前视的 RGB 图像(vf)、深度图像(vp)及语义分割图像(vp)。
- 动作空间:
- 运动控制:可设置目标位置([x,y,z]ᵀ)、目标速度([u,v,w]ᵀ)、目标姿态([0,ф,ψ,ψ]ᵀ);
- 相机控制:支持视角调整;
- 其他控制:无人机飞行启停。
- 核心特点:与 TouchDown、R2R、RxR 不同,其为连续空间,模拟无人机可在环境内任意点连续飞行。
EXPERIMENT AND RESULTS
Experiment Setup
-
实验数据集:采用 “AVDN 数据集”(参考 [34]),该数据集为复杂城市场景设计,核心特征包括:

- 轨迹长度:平均路径长度 287m,覆盖城市中 “中长距离导航” 场景;
- 指令特点:高频词汇含 “destination(目的地)”“building(建筑)”“go(前往)”“fly(飞行)” 等,贴合真实导航指令的语言习惯(如图 6 的词云所示),可有效测试框架对自然语言指令的理解能力。
-
硬件与软件环境:
- 硬件:实验在搭载 Intel i9 12 代 CPU、NVIDIA GeForce RTX 4070 GPU 的笔记本上运行,满足模拟器与模型计算需求;
- 软件:基于 AirSim 与 Unreal Engine 4 搭建的 3D 实验平台(第四章构建),LLM 采用 GPT-4。
-
关键参数配置:
- 传感器参数:深度传感器感知范围设为 100 米(覆盖城市中高空观测需求),相机视场角设为 90 度(模拟无人机前置广角相机的观测范围);
- 任务约束:与第三章一致,无人机默认仅使用前视视觉(RGB、深度、语义图),需旋转自身获取其他方向观测。
定量结果
通过对比 SkyVLN 完整模型与多类基线模型的核心指标,验证框架性能优势,核心指标为SPL(Success weighted by Path Length,路径长度加权成功率) 与SR(Success Rate,成功率),前者兼顾 “成功抵达” 与 “路径效率”,后者反映任务完成能力:
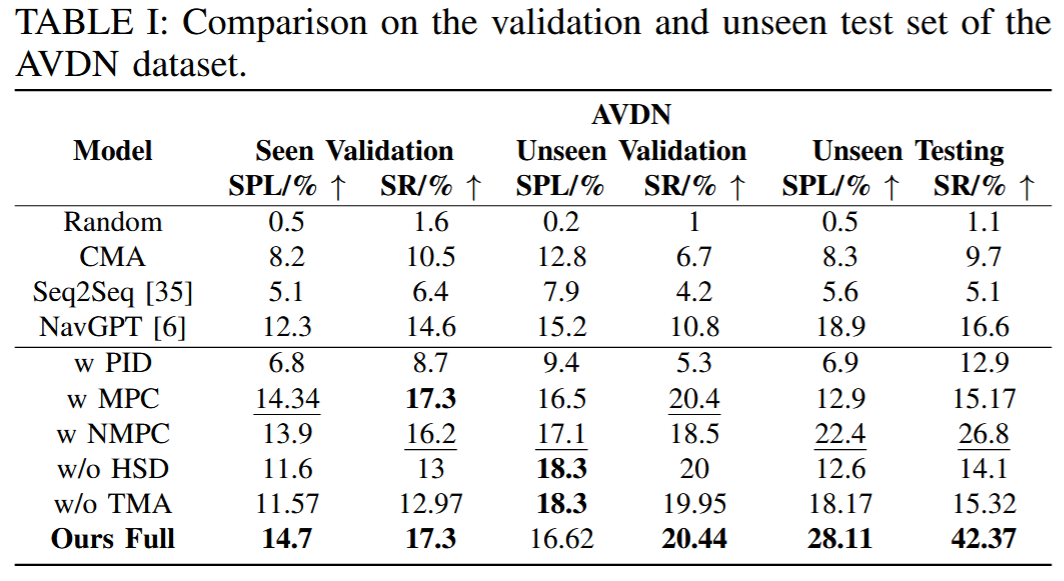
- 对比模型设计:涵盖传统方法、LLM-based 方法、控制优化方法与消融模型,具体包括:
- 传统 / 基础方法:Random(随机动作)、CMA(跨模态对齐)、Seq2Seq(序列生成模型);
- LLM-based 基线:NavGPT [6](仅依赖 LLM 的导航模型);
- 控制优化方法:w PID(PID 控制)、w MPC(传统 MPC 控制)、w NMPC(仅 NMPC 控制);
- 消融模型:w/o HSD(去除高分辨率空间描述器)、w/o TMA(去除回溯记忆阵列);
- 目标模型:Ours Full(SkyVLN 完整框架,含多模态感知、WPO、NMPC)。
- 核心结果(基于 AVDN 数据集,如表 I 所示):
- 可见环境(Seen Validation):Ours Full 与 w MPC 表现最优,SPL 均达 14%+、SR 均为 17.3%,证明完整框架在已知环境中能稳定匹配基线中最优的控制方法;
- 新环境(Unseen Validation/Testing):Ours Full 优势显著,在最具挑战性的 “不可见测试集”(完全未接触的新场景)中,SPL 达 28.11%、SR 达 42.37%,远超其他模型 —— 如 NavGPT 的 SR 仅 16.6%,w NMPC 的 SR 仅 26.8%,w/o HSD/w/o TMA 的 SR 均低于 16%,证明 HSD(精准定位)与 TMA(历史回溯)的协同,让框架在新环境中泛化能力更强;
- 控制方法对比:NMPC 控制(w NMPC、Ours Full)的性能优于 PID 与传统 MPC,尤其在新环境中,w NMPC 的 SPL(22.4%)是 w PID(6.9%)的 3 倍以上,证明 NMPC 的动态避障与轨迹跟踪能力更适配复杂城市场景。
- 轨迹跟踪精度验证:对比 NMPC 与 AirSim 内置的 Simple Flight(PID 控制)的轨迹表现(如图 7、8 所示):
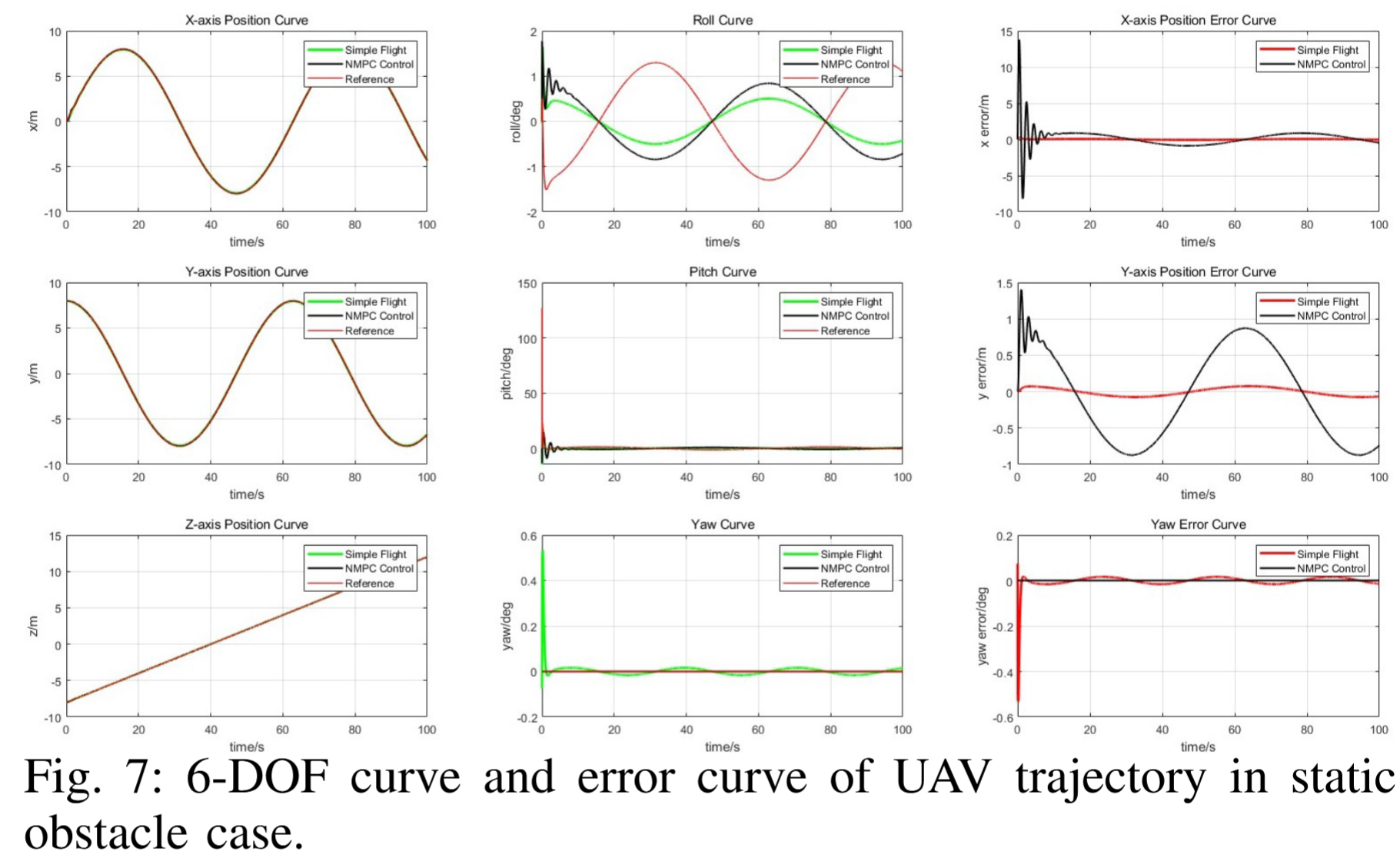
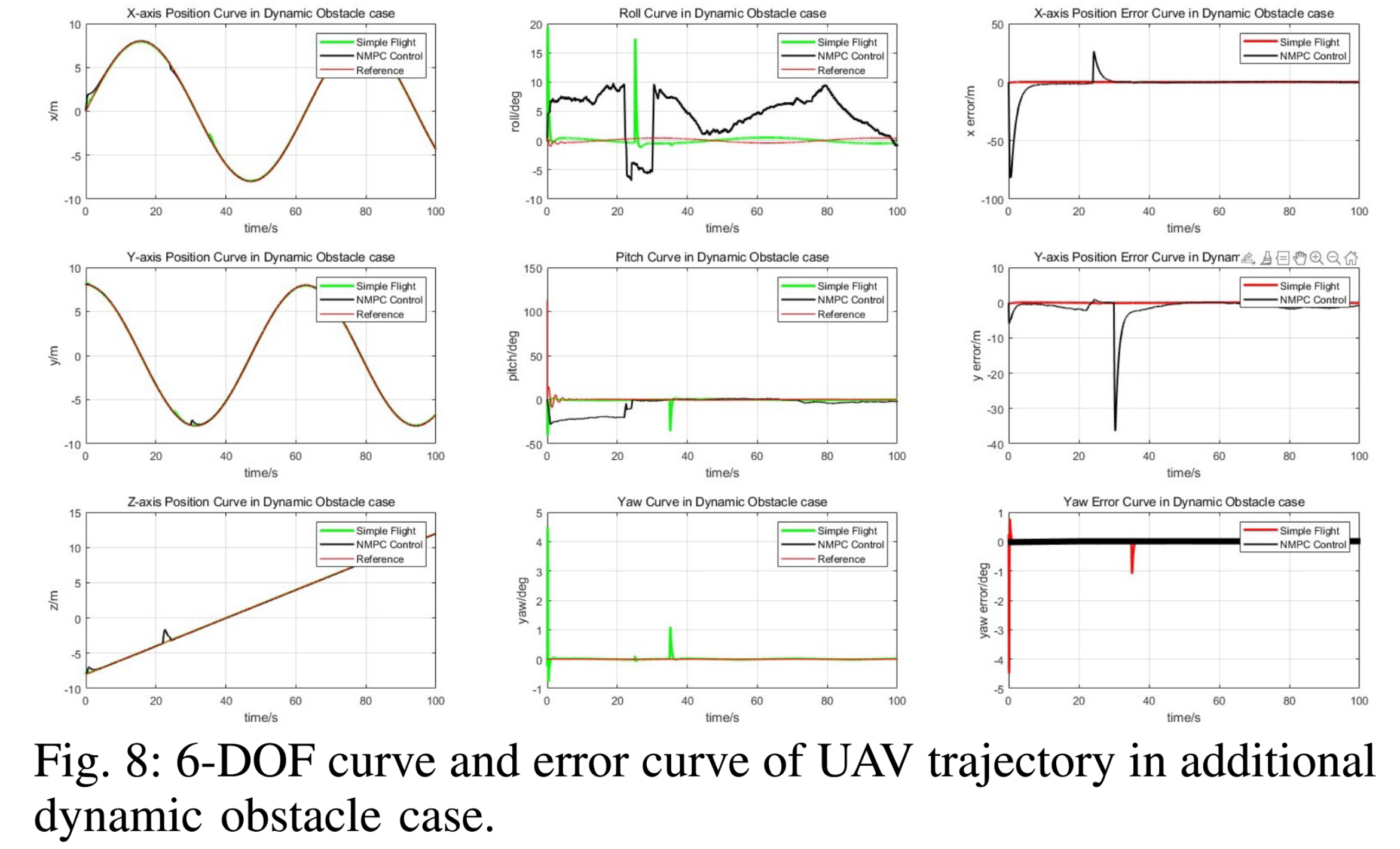
- NMPC 的轨迹(黑线)更贴近参考轨迹(红线),X、Y 轴位置误差显著低于 PID;
- 姿态控制更稳定:NMPC 的横滚、俯仰、偏航角误差快速收敛至接近零,而 PID 误差波动大且持续,证明 NMPC 能更精准控制无人机姿态与位置,为导航成功提供基础。
定性分析(Qualitative Analysis)
通过具体导航场景展示 SkyVLN 的实际工作流程,验证框架 “理解指令 - 视觉匹配 - 动作执行” 的闭环能力,核心以图 9 为例:

- 任务指令:连续多步复杂指令 ——“穿过十字路口左转→沿街道右侧飞行(距建筑≥5 米)→下一个路口六楼送货→飞往粉色建筑大屋顶降落→返回起点”;
- 框架交互逻辑:
- 系统提示:定义无人机角色(“embodied UAV 助手”),限制其仅使用指定功能(如 get_position 查询物体坐标、fly_to 控制飞行);
- 动作提示:明确指令与视觉观测的结合方式 —— 无人机基于深度图(测距离)、语义掩码(分实体类别)、第一视角图像(辨地标),调用 LLM 生成描述与动作代码;
- 执行结果:图中黄色轨迹为无人机实际飞行路径,方格旗为终点,可见无人机能按指令分步完成 “转向 - 避障 - 送货 - 降落”,且轨迹贴合指令要求(如 “沿街道右侧飞”“精准抵达粉色建筑屋顶”),直观证明框架对复杂指令的理解与执行能力。
消融研究(Ablation Study)
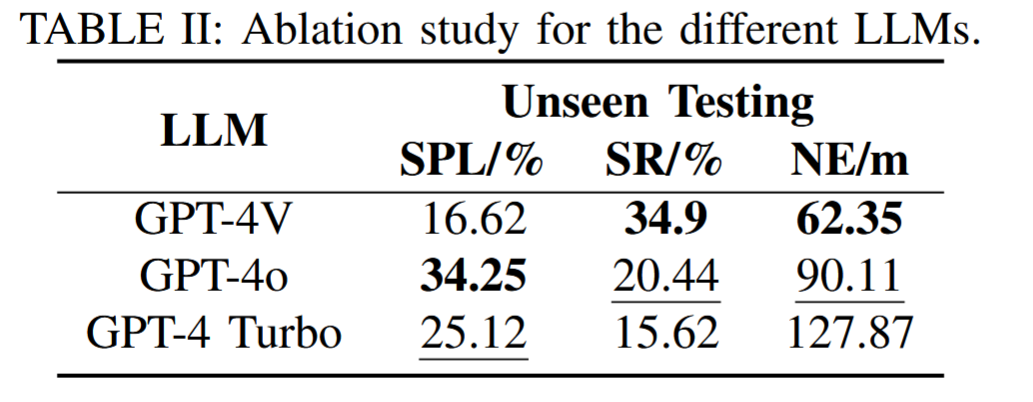
针对 LLM 选型展开测试,分析不同 LLM 对 SkyVLN 导航性能的影响(如表 II 所示),测试场景为 “不可见测试集”,核心指标含 SPL、SR 与 NE(Navigation Efficiency,导航效率,数值越小越优):
- 测试模型:GPT-4V、GPT-4o、GPT-4 Turbo;
- 结果差异:
- 平衡最优:GPT-4V 表现最佳,SR 达 34.9%(最高)、NE 达 62.35m(最低),兼顾成功率与导航效率,是 SkyVLN 的优选 LLM;
- 路径效率高但成功率低:GPT-4o 的 SPL 达 34.25%(最高),但 SR 仅 20.44%、NE 达 90.11m,说明其能规划高效路径,但对 “指令 - 视觉匹配” 的准确性不足;
- 表现最差:GPT-4 Turbo 的 SR 仅 15.62%、NE 达 127.87m,路径探索冗余多,成功率低,证明 LLM 的语境理解与多模态对齐能力对框架性能至关重要。
总结
第 V 部分通过系统实验,从 “量化性能 - 实际场景 - 组件作用” 三方面验证了 SkyVLN 的有效性:
- 定量结果证明,相比传统方法与单一模块优化,SkyVLN 完整框架在新环境中导航成功率提升显著,鲁棒性更强;
- 定性分析展示了框架对复杂指令的处理能力,证明其 “视觉 - 语言对齐” 与 “动作控制” 的协同性;
- 消融研究明确了 LLM 选型、HSD、TMA 对框架的关键作用,为后续优化提供方向,同时也为 “视觉 - 语言导航在无人机领域的应用” 提供了可复现的实验基准。
Conclusion
一、SkyVLN 框架核心定位与设计目标
所提出的 SkyVLN 是一种创新性的视觉 - 语言导航框架,专为无人机(UAV)在复杂城市环境中的作业而精心设计。该方法有望大幅降低操作人员的认知负担,从而在多种场景下推动更高效的任务执行。
二、SkyVLN 框架关键功能与技术优势
- 历史路径记忆功能:集成历史路径记忆功能,使无人机能够长期保持情境感知能力,这对于应对复杂城市景观中的动态复杂性至关重要。
- 多模态感知策略:研究通过采用多模态感知策略,借助大型语言模型(LLMs)提升推理与决策过程的有效性和透明度。
- 动态场景适配控制:融入针对动态场景定制的非线性模型预测控制技术。
- 仿真验证环境:构建了高度详细的三维(3D)仿真环境,用于严格验证导航控制系统的稳定性。
三、未来研究方向
- 安全与任务效率平衡优化:重点优化安全性与任务效率之间的平衡关系。
- 多无人机协同作业拓展:通过集成群体智能,将研究拓展至多无人机协同作业领域。
- 恶劣环境适用性提升:进一步增强无人机控制在恶劣环境条件下的适用性。
四、研究成果意义与价值
本研究的成果为更先进、更智能的无人机导航奠定了基础,凸显了大型语言模型(LLMs)在革新无人机自主作业模式方面的潜力。