基于 OpenCV + 深度学习的实时人脸检测与年龄性别识别系统
一、项目背景与核心原理
1.1 项目目标
通过摄像头或本地视频文件,实时捕获每一帧图像,完成以下三大核心任务:
- 人脸检测:精准定位图像中的人脸位置,用矩形框标记
- 年龄估计:预测检测到人脸对应的年龄段(如 25-32 岁)
- 性别识别:判断人脸对应的性别(男性 / 女性)
- 结果可视化:将年龄、性别信息以中文文本形式叠加在人脸框上方,实时展示
1.2 核心技术选型
项目基于成熟的开源工具和预训练模型,无需从零训练,兼顾效率与准确性:

二、案例实现
1、初始化模型
提前下载好模型,模型的网址如下:
https://github.com/GilLevi/AgeGenderDeepLearning
2.1 安装依赖库
项目依赖 3 个核心 Python 库,直接通过 pip 安装:
pip install opencv-python # 图像处理核心
pip install pillow # 中文文本绘制
pip install numpy # 数组运算(OpenCV依赖)2.2 下载预训练模型
系统需要 3 个预训练模型文件(配置文件 + 权重文件),下载后统一放在./model目录下(需手动创建model文件夹),模型来源及下载地址如下:

三、完整代码实现与解析
下面分模块讲解代码逻辑,最终会给出完整可运行代码。
3.1 导入依赖库
首先导入项目需要的所有库:
import cv2 # OpenCV核心
from PIL import Image, ImageDraw, ImageFont # 中文绘制
import numpy as np # 数组处理3.2 模型初始化(加载预训练模型)
通过 OpenCV 的dnn.readNet()方法加载 3 个模型,需要传入「权重文件路径」和「配置文件路径」:
"""====== 1. 模型初始化 ======="""
# 人脸检测模型路径
faceProto = "./model/opencv_face_detector.pbtxt"
faceModel = "./model/opencv_face_detector_uint8.pb"
# 年龄估计模型路径
ageProto = "./model/deploy_age.prototxt"
ageModel = "./model/age_net.caffemodel"
# 性别识别模型路径
genderProto = "./model/deploy_gender.prototxt"
genderModel = "./model/gender_net.caffemodel"# 加载模型
faceNet = cv2.dnn.readNet(faceModel, faceProto) # 人脸检测模型
ageNet = cv2.dnn.readNet(ageModel, ageProto) # 年龄估计模型
genderNet = cv2.dnn.readNet(genderModel, genderProto) # 性别识别模型3.3 变量初始化(定义预测结果映射)
提前定义年龄分段和性别选项,与模型输出的类别索引对应:
"""====== 2. 变量初始化 ======="""
# 年龄分段(与age_net模型输出的8个类别一一对应)
ageList = ['0-2岁', '4-6岁', '8-12岁', '15-20岁', '25-32岁', '38-43岁', '48-53岁', '60-100岁']
# 性别选项(与gender_net模型输出的2个类别一一对应)
genderList = ['男性', '女性']
# 图像预处理均值(age_net和gender_net模型要求的固定均值)
mean = (78.4263377603, 87.7689143744, 114.895847746)3.4 自定义函数 1:人脸检测(获取人脸框)
定义getBoxes()函数,输入视频帧和人脸检测模型,输出「绘制人脸框后的图像」和「人脸框坐标列表」,核心逻辑:
- 将图像转换为 DNN 模型可识别的
blob格式(缩放、归一化) - 模型前向传播,得到检测结果
- 筛选置信度 > 0.7 的结果,计算人脸框坐标并绘制
def getBoxes(net, frame):"""人脸检测函数:获取人脸框坐标并绘制参数:net: 人脸检测模型(faceNet)frame: 输入视频帧返回:frame: 绘制人脸框后的视频帧faceBoxes: 人脸框坐标列表([[x1,y1,x2,y2], ...])"""# 获取视频帧的高度和宽度frameHeight, frameWidth = frame.shape[:2]# 图像转blob:DNN模型输入格式(300x300为faceNet要求的固定尺寸)blob = cv2.dnn.blobFromImage(frame, # 输入图像1.0, # 缩放因子(像素值保持0-255)(300, 300), # 输出图像尺寸[104, 117, 123],# 通道均值(BGR顺序,用于去均值)swapRB=True, # 交换R和B通道(OpenCV默认BGR,模型要求RGB)crop=False # 不裁剪图像)# 模型推理:输入blob并前向传播net.setInput(blob)detections = net.forward() # detections为检测结果(形状:1,1,N,7)faceBoxes = [] # 存储人脸框坐标# 遍历所有检测结果(N个候选框)for i in range(detections.shape[2]):# 提取当前候选框的置信度(detections[0,0,i,2])confidence = detections[0, 0, i, 2]# 筛选置信度>0.7的结果(过滤误检)if confidence > 0.7:# 计算人脸框坐标(模型输出为归一化坐标,需转换为像素坐标)x1 = int(detections[0, 0, i, 3] * frameWidth) # 左边界xy1 = int(detections[0, 0, i, 4] * frameHeight) # 上边界yx2 = int(detections[0, 0, i, 5] * frameWidth) # 右边界xy2 = int(detections[0, 0, i, 6] * frameHeight) # 下边界y# 将坐标添加到列表faceBoxes.append([x1, y1, x2, y2])# 绘制人脸框(绿色,线宽根据帧高度自适应)cv2.rectangle(frame, # 绘制对象(x1, y1), # 左上角坐标(x2, y2), # 右下角坐标(0, 255, 0), # 颜色(BGR:绿色)thickness=int(frameHeight / 150), # 线宽(自适应)lineType=6 # 线条类型(抗锯齿))return frame, faceBoxes3.5 自定义函数 2:中文文本绘制(解决 OpenCV 中文问题)
OpenCV 原生putText()函数不支持中文,因此通过 PIL 库转换图像格式,绘制中文后再转回 OpenCV 格式:
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):"""中文文本绘制函数:在OpenCV图像上添加中文参数:img: 输入OpenCV图像(np.ndarray格式)text: 要绘制的中文文本position: 文本位置((x, y),左上角坐标)textColor: 文本颜色(默认绿色,BGR格式)textSize: 文本大小(默认30)返回:img: 添加中文后的OpenCV图像"""# 1. 将OpenCV图像(BGR)转换为PIL图像(RGB)if isinstance(img, np.ndarray):img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 2. 创建PIL绘图对象draw = ImageDraw.Draw(img)# 3. 加载中文字体(这里使用"STXINGKA.TTF",需确保系统有该字体)# 若字体不存在,可替换为其他中文字体路径(如"C:/Windows/Fonts/simhei.ttf")try:fontStyle = ImageFont.truetype("STXINGKA.TTF", textSize, encoding="utf-8")except IOError:# 字体不存在时,使用默认字体(可能显示乱码,建议提前安装字体)fontStyle = ImageFont.load_default()print("警告:中文字体未找到,可能显示乱码,请安装STXINGKA.TTF或替换字体路径")# 4. 绘制中文文本draw.text(position, text, textColor, font=fontStyle)# 5. 将PIL图像(RGB)转回OpenCV图像(BGR)return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)字体问题说明:若运行时提示「字体未找到」,可:
- 在 Windows 系统中复制
C:/Windows/Fonts/simhei.ttf(黑体)到项目目录 - 将代码中
fontStyle = ImageFont.truetype("STXINGKA.TTF", ...)改为"simhei.ttf"
3.6 主循环(视频捕获与实时处理)
核心逻辑:打开视频 / 摄像头 → 逐帧读取 → 人脸检测 → 年龄性别预测 → 结果可视化 → 按键退出
"""====== 3. 主循环:视频捕获与实时处理 ======="""
def main():# 1. 打开视频源(0表示摄像头,也可替换为本地视频路径如"人.mp4")cap = cv2.VideoCapture("人.mp4") # 本地视频:"人.mp4";摄像头:0# 2. 检查视频源是否打开成功if not cap.isOpened():print("错误:无法打开视频源,请检查路径或摄像头连接")return# 3. 逐帧处理视频while True:# 读取一帧视频(ret为是否成功读取,frame为视频帧)ret, frame = cap.read()# 若视频读取完毕(ret=False),退出循环if not ret:print("视频处理完毕或无法读取帧")break# (可选)镜像处理(摄像头时启用,使画面与实际动作一致)# frame = cv2.flip(frame, 1)# 4. 人脸检测:获取人脸框并绘制frame, faceBoxes = getBoxes(faceNet, frame)# 5. 若未检测到人脸,打印提示并继续下一帧if not faceBoxes:print("当前镜头中没有人")# 在图像上显示提示(英文,避免中文问题)cv2.putText(frame, "No Face Detected", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)cv2.imshow("Face-Age-Gender Detection", frame)# 等待按键(1ms,避免卡顿)if cv2.waitKey(1) == 27: # 按下Esc键(ASCII 27)退出breakcontinue# 6. 遍历每个检测到的人脸,进行年龄和性别预测for faceBox in faceBoxes:# 提取人脸框坐标(x1,y1:左上角;x2,y2:右下角)x1, y1, x2, y2 = faceBox# 裁剪人脸区域(避免超出图像边界,防止报错)face = frame[max(0, y1):min(y2, frame.shape[0]-1), max(0, x1):min(x2, frame.shape[1]-1)]# 7. 图像预处理:将人脸转换为ageNet/genderNet要求的blob格式(227x227)blob = cv2.dnn.blobFromImage(face, # 输入人脸图像1.0, # 缩放因子(227, 227), # 输出尺寸(模型固定要求)mean, # 通道均值(提前定义的mean)swapRB=False, # 不交换R和B通道(模型要求BGR)crop=False # 不裁剪)# 8. 性别预测genderNet.setInput(blob)genderOuts = genderNet.forward() # 输出:[男性概率, 女性概率]genderIdx = genderOuts[0].argmax() # 取概率最大的索引gender = genderList[genderIdx] # 映射为性别标签# 9. 年龄预测ageNet.setInput(blob)ageOuts = ageNet.forward() # 输出:8个年龄段的概率ageIdx = ageOuts[0].argmax() # 取概率最大的索引age = ageList[ageIdx] # 映射为年龄标签# 10. 格式化结果文本(如"男性, 25-32岁")resultText = f"{gender}, {age}"# 11. 在人脸框上方绘制结果(避免文本超出图像顶部)textY = y1 - 10 if y1 > 30 else y1 + 30 # 文本位置自适应frame = cv2AddChineseText(frame, resultText, (x1, textY), textColor=(255, 0, 0))# 12. 显示处理后的视频帧cv2.imshow("Face-Age-Gender Detection", frame)# 13. 按键退出(按下Esc键,ASCII码27)if cv2.waitKey(1) == 27:print("用户按下Esc键,退出程序")break# 14. 释放资源(关闭视频捕获和窗口)cap.release()cv2.destroyAllWindows()# 程序入口:执行主函数
if __name__ == "__main__":main()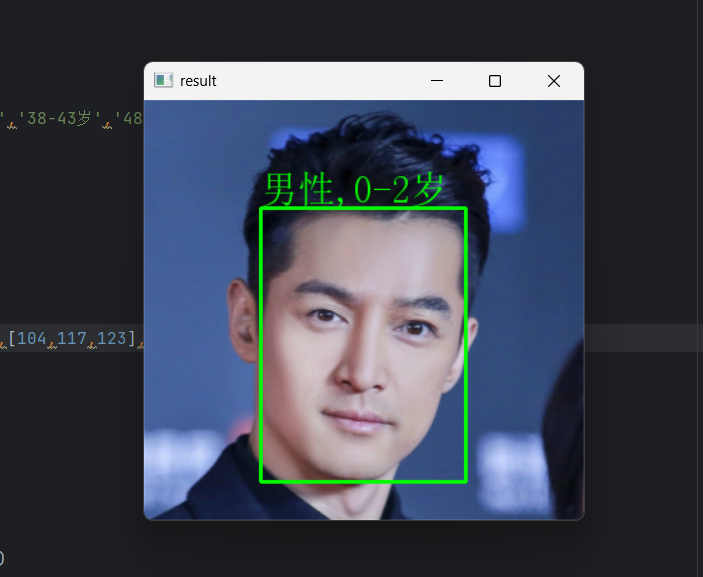
人脸年龄性别识别系统结果不准确的原因分析
一、模型本身的固有局限性
系统使用的预训练模型(age_net、gender_net、opencv_face_detector)是基于特定数据集训练的,其泛化能力受训练数据和模型结构的直接制约,这是结果不准确的核心原因。
1. 训练数据集的偏差
模型的 “认知” 完全依赖于训练时接触的数据,若数据存在以下问题,会直接导致预测偏差:
- 数据分布不均衡:预训练模型(如 GilLevi 的 AgeGenderDeepLearning 模型)的训练数据多来自欧美人群,对亚洲、非洲等其他人种的覆盖不足。例如:模型对亚洲人脸的特征提取不充分,可能将东亚女性的面部特征误判为男性,或对黄种人的年龄增长特征(如皮肤纹理、皱纹分布)学习不足,导致年龄预测偏差。
- 年龄 / 性别标签覆盖不全:年龄模型的输出是 8 个离散年龄段(如
25-32岁、38-43岁),而非连续年龄值。若实际年龄处于两个年龄段之间(如 35 岁),模型只能 “二选一”,易归入相邻区间(如 38-43 岁);此外,训练数据中若某一年龄段(如儿童、老年人)样本量极少,模型对该群体的预测准确率会显著下降。 - 场景单一化:训练数据多为 “正面、光照均匀、无遮挡” 的标准人脸(如证件照风格),缺乏复杂场景样本(如侧脸、逆光、戴口罩 / 眼镜),导致模型在真实场景中鲁棒性不足。
2. 模型结构的简化设计
为兼顾实时性(适合摄像头实时处理),系统使用的模型多为轻量级结构,牺牲了部分精度:
- 人脸检测模型的定位误差:
opencv_face_detector是基于 SSD(Single Shot MultiBox Detector)的轻量级模型,虽检测速度快,但对小脸、模糊人脸的定位精度较低(如人脸框未完整包含额头、下巴)。若裁剪出的人脸区域不完整,后续年龄性别模型会因输入特征缺失导致预测错误。 - 年龄性别模型的特征提取能力有限:
age_net和gender_net基于较早期的 AlexNet 结构(而非 ResNet、ViT 等更先进的网络),对细微特征(如女性的妆容、男性的胡须、不同年龄段的皮肤弹性差异)的捕捉能力较弱,易将 “化妆的年轻女性” 误判为年长,或 “留长发的男性” 误判为女性。
二、输入场景的干扰因素
真实应用场景中的环境、人脸状态会直接破坏模型的 “理想输入条件”,导致特征提取失真,进而影响预测结果。
1. 光照条件的影响
- 逆光 / 过曝:逆光时人脸区域偏暗,过曝时人脸细节(如皱纹、眉毛)被淹没,模型无法提取到有效的年龄性别特征(如年轻人的皮肤亮度、老年人的皱纹纹理),可能将逆光下的年轻人误判为老年人(因暗部特征与老年人肤色更相似)。
- 色温暖差:不同光源(如白炽灯偏黄、荧光灯偏蓝)会改变人脸肤色,而模型训练时基于 “标准白光” 下的肤色特征。例如:暖光下人脸偏黄,可能被模型误判为 “肤色较深的男性”(若训练数据中黄肤色样本多为男性)。
2. 人脸状态的干扰
- 遮挡与姿态:戴口罩(遮挡口鼻)、戴眼镜(反光或遮挡眼部)、侧脸 / 低头(遮挡额头 / 下巴)会导致关键特征缺失 —— 眼部是性别识别的重要特征(如女性眼型更圆润),额头 / 下巴是年龄判断的关键(如老年人额头皱纹、下巴松弛),遮挡后模型只能基于局部特征猜测,准确率大幅下降。
- 动态模糊:摄像头帧率低(如 <15fps)或人脸移动过快时,视频帧会出现动态模糊,人脸边缘、纹理变得模糊,模型无法区分 “模糊的年轻皮肤” 和 “清晰的年长皮肤”,导致年龄预测偏差。
- 妆容与配饰:浓妆(如 heavy contour、深色口红)会改变面部轮廓和肤色,可能让 20 岁女性的面部特征接近 30 岁女性;戴帽子(遮挡额头皱纹)会让老年人的年龄特征被隐藏,误判为年轻人。
三、图像预处理的潜在问题
系统对输入图像的预处理步骤若不符合模型预期,会导致输入特征 “失真”,进而影响预测结果。
1. 人脸裁剪与尺寸缩放的误差
- 裁剪区域超出图像边界:若人脸框靠近图像边缘(如摄像头边缘的人脸),代码中
face = frame[y:y1, x:x1]可能裁剪出 “不完整人脸”(如 y<0 时取 max (0,y),导致额头被截断),模型缺失额头的年龄特征(如年轻人额头饱满、老年人额头有皱纹)。 - 强制缩放的失真:年龄性别模型要求输入为 227×227 像素,若原始人脸是 “高瘦型”(如侧脸),强制缩放到正方形会导致人脸拉伸(如眼睛变宽、脸型变圆),破坏原始特征比例,模型可能将拉伸后的脸型误判为另一性别 / 年龄段。
2. 均值预处理的固定化
代码中对年龄性别模型的输入使用固定均值mean = (78.4263377603, 87.7689143744, 114.895847746),该均值是基于模型训练数据集计算的。若输入图像的像素分布与训练数据差异大(如低分辨率图像的像素值整体偏低),固定均值会导致预处理后的图像特征偏移,与模型 “认知” 的特征不匹配,进而预测错误。
四、标签定义的固有模糊性
系统使用的 “年龄段” 和 “性别” 标签是离散、简化的,与真实世界的复杂性存在矛盾,导致 “结果不准确” 的主观感受。
1. 年龄标签的离散化误差
模型输出的是 8 个离散年龄段(如25-32岁),而非连续年龄值。若实际年龄为 33 岁(处于25-32岁和38-43岁之间),模型只能将其归入其中一个区间,此时无论归入哪一类,都会被用户感知为 “不准确”(实际 33 岁,预测 38-43 岁)。
2. 性别标签的二元化局限
模型将性别分为 “男性” 和 “女性” 两类,但现实中存在非二元性别(如跨性别者、中性风格人群),其面部特征可能同时具有两类性别特征(如跨性别女性的面部轮廓偏男性,但妆容偏女性),模型无法处理这类情况,只能强制归入某一类别,导致 “不准确”。
总结:如何提升准确性?
针对上述原因,可通过以下方式优化(需在 “实时性” 和 “精度” 之间权衡):
- 更换更优模型:使用基于 ResNet 的人脸检测模型(如 MTCNN)提升定位精度,用更先进的年龄性别模型(如 FairFace 预训练模型)提升泛化能力(支持多个人种、复杂场景)。
- 增加数据增强:对输入图像进行光照补偿、去模糊处理,或在代码中加入 “人脸对齐” 步骤(将侧脸、倾斜人脸矫正为正面)。
- 场景约束:在固定场景中使用(如室内白光环境、无遮挡),减少环境干扰。