扩散模型-图像编辑【An Edit Friendly DDPM Noise Space: Inversion and Manipulations】
An Edit Friendly DDPM Noise Space: Inversion and Manipulations
便于编辑的扩散概率模型噪声空间:反转与操作
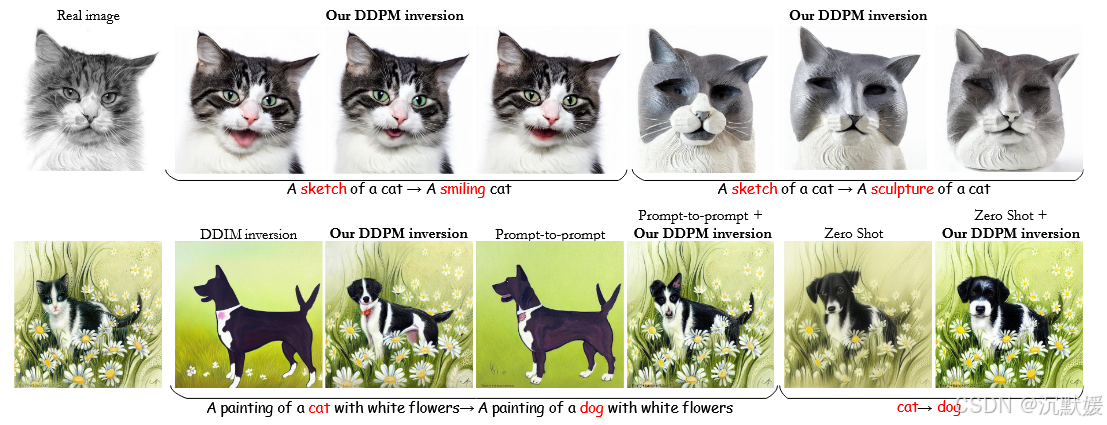
图1. 便于编辑的扩散概率模型反转。我们提出了一种方法,用于提取一系列能够完美重建给定图像的DDPM噪声图。这些噪声图的分布与常规采样中使用的噪声图不同,并且更便于编辑。我们的方法允许对真实图像进行多样化的编辑,而无需对模型进行微调或修改其注意力图,并且还可以轻松集成到其他算法中(此处结合Prompt-to-Prompt [9]和Zero-Shot I2I [21]进行说明)。
摘要
去噪扩散概率模型使用一系列高斯白噪声样本来生成图像。与生成对抗网络(GANs)类似,这些噪声图可被视为与生成图像相关联的潜在编码。然而,这种原始的噪声空间不具备便捷的结构,因此在编辑任务中处理起来颇具挑战。在此,我们为DDPM提出了一种替代的潜在噪声空间,该空间可通过简单的方式实现广泛的编辑操作,并提出了一种反转方法,用于为任何给定图像(真实图像或合成图像)提取这些便于编辑的噪声图。与原始的DDPM噪声空间不同,便于编辑的噪声图不服从标准正态分布,且在各个时间步长上并非统计独立。然而,它们能够完美重建任何所需的图像,并且对这些噪声图的简单变换会转化为对输出图像的有意义操作(例如,移动、颜色编辑)。此外,在文本条件模型中,在更改文本提示的同时固定这些噪声图,可以在保留结构的同时修改语义。我们说明了这一特性如何通过多样的DDPM采样方案实现对真实图像的基于文本的编辑(与流行的非多样的去噪扩散隐含模型(DDIM)反转形成对比)。我们还展示了如何在现有的基于扩散的编辑方法中使用它来提高其质量和多样性。该方法代码已附在此次提交中。
重点信息如下:
-
DDPM与噪声空间:去噪扩散概率模型(DDPM)使用高斯白噪声样本生成图像,但原始噪声空间结构不便,编辑困难。
-
提出的解决方案:提出了一种替代的潜在噪声空间,支持通过简单方式实现多种编辑操作,并提供了一种反转方法,用于提取便于编辑的噪声图。
-
噪声图特性:这些便于编辑的噪声图不服从标准正态分布,且在时间步长上不独立,但能完美重建图像,并支持对图像的有意义操作。
-
文本条件模型中的应用:在文本条件模型中,固定噪声图并更改文本提示可以修改语义同时保留结构,支持基于文本的真实图像编辑。
-
改进现有方法:该技术可用于改进现有的基于扩散的编辑方法,提高其质量和多样性。
结论
我们提出了一种针对扩散概率模型(DDPM)的反转方法。与常规采样中的噪声图相比,我们的噪声图对图像结构的编码更强,因此更适合进行图像编辑。我们展示了(该噪声图)在基于文本的编辑中的优势,无论是单独使用还是与其他编辑方法结合使用。
引言
扩散模型已成为一种强大的生成框架,在图像合成领域达到了最先进的水平。最近的研究利用扩散模型完成各种图像编辑和操作任务,包括文本引导编辑 、图像修复 以及图像到图像的转换 。这些方法面临的一个关键挑战是如何利用它们对真实内容(与模型生成的图像相对)进行编辑。这需要逆转生成过程,即提取一系列噪声向量,如果用这些向量驱动反向扩散过程,将能够重建给定图像。
尽管基于扩散的编辑技术取得了显著进步,但反转仍被视为一项重大挑战,特别是在去噪扩散概率模型(DDPM)采样方案中 [11]。最近的许多方法(例如 [5, 9, 19, 21, 27, 29])依赖于去噪扩散隐式模型(DDIM)方案的近似反转方法 [26],这是一种将单个初始噪声向量映射到生成图像的确定性采样过程。然而,这种DDIM反转方法只有在使用大量扩散时间步(例如1000步)时才能变得准确,即使在这种情况下,它在文本引导的编辑中也常常导致次优结果 。为了应对这种影响,一些方法根据给定的图像和文本提示对扩散模型进行微调。其他方法则以各种方式干预生成过程,例如,将DDIM反转过程中得到的注意力图注入到文本引导的生成过程中 。
在此,我们解决DDPM(去噪扩散概率模型)方案的反转问题。与DDIM(去噪扩散隐式模型)不同,在DDPM中,生成过程涉及T + 1个噪声图,每个噪声图的维度都与生成的输出相同。因此,噪声空间的总维度大于输出的维度,并且存在无限多个能够完美重建图像的噪声序列。虽然这一特性可能在反转过程中提供灵活性,但并非每一个能够完美重建(即实现完美重建)的反转结果都便于编辑。例如,在文本条件模型中,我们对反转的一个要求是,在固定噪声图并更改文本提示时,应生成无伪影的图像,其中语义与新文本对应,但结构保持与输入图像相似。哪些能够完美重建的反转结果满足这一特性?一个看似合理的答案是,噪声图应在统计上独立且服从标准正态分布,就像常规采样中一样。[30]中采用了这种方法。然而,如图2所示,这种原始的DDPM噪声空间实际上并不便于编辑。

图2. 原始(native,即常规)的和便于编辑的噪声空间。当使用DDPM生成图像时(左),可以获得生成该图像的“真实”噪声图。然而,这种原始噪声空间并不便于编辑(第二列)。例如,固定这些噪声图并更改文本提示会改变图像结构(顶部)。同样,翻转(中间)或移动(底部)噪声图会完全改变图像。相比之下,我们便于编辑的噪声图可以在保留结构的同时进行编辑(右)。
在此,我们提出了一种替代性的反转方法,它更适合于编辑应用,包括文本指导的操作以及通过手工绘制的彩色笔触进行的编辑。我们的反转方法将图像更深刻地“印记”到噪声图中,这使得在固定这些噪声图并更改模型条件时,图像结构能够得到更好的保留。这是通过使我们的噪声图具有比原始噪声图更高的方差来实现的。我们的反转方法无需优化,且速度极快。然而,它只需固定噪声图并更改文本条件(即无需对模型进行微调或干预注意力图),就能在相对较少的扩散步骤下在文本引导的编辑任务中取得顶尖效果。重要的是,我们的DDPM反转方法还可以轻松与现有的基于扩散的编辑方法集成,这些方法目前依赖于近似的DDIM反转方法。如图1所示,这提高了它们保持与原始图像相似度的能力。此外,由于我们以随机方式找到噪声向量,因此我们可以提供一组多样化的编辑图像,这些图像都符合文本提示,这是DDIM反转方法本身所不具备的特性,见图1的顶行以及补充材料(SM)。
引言总结
这段内容主要围绕扩散模型(特别是DDPM)在图像编辑中的应用及反转方法的改进展开,具体内容总结如下:
-
扩散模型在图像编辑中的应用及挑战:扩散模型是强大的生成框架,在图像合成领域表现出色,也被用于图像编辑等任务。但利用其编辑真实内容面临挑战,需进行生成过程的反转,即提取能重建给定图像的噪声向量序列。
-
现有反转方法及问题:许多方法依赖DDIM方案的近似反转方法,但该方法需大量扩散时间步且在文本引导编辑中效果不佳。为改善效果,一些方法对扩散模型微调,或干预生成过程。
-
DDPM反转问题及特性:DDPM生成过程涉及多个噪声图,存在无限多能完美重建图像的噪声序列,但并非所有能完美重建的反转结果都便于编辑。原始DDPM噪声空间不便于编辑,如固定噪声图改文本提示会改变图像结构等。
-
新的反转方法及优势:提出一种替代性反转方法,更适合图像编辑应用。它将图像更深刻地“印记”到噪声图中,无需优化且速度极快。在文本引导编辑任务中,固定噪声图改文本条件就能取得好效果,还能与现有基于扩散的编辑方法集成,提高保持与原始图像相似度的能力,且能以随机方式提供符合文本提示的多样化编辑图像。
相关工作
扩散模型的反转(逆推)
使用扩散模型编辑真实图像需要提取在生成过程中能够生成该图像的噪声向量。绝大多数基于扩散的编辑工作都采用去噪扩散隐式模型(DDIM)方案,该方案是一种从单个噪声图到生成图像的确定性映射 。原始的DDIM论文 针对该方案提出了一种高效的近似逆推方法。这种方法在每个扩散时间步都会产生一个小误差,并且在使用无分类器引导 [10] 时,这些误差往往会累积成有意义的偏差。Mokady等人 [19] 通过修正每个时间步的漂移来提高重建质量。他们的两步法首先使用DDIM逆推来计算一系列噪声向量,然后使用该序列在每个时间步优化输入的空文本嵌入。Miyake等人 [18] 通过无优化的前向传播实现了类似的重建精度,从而实现了更快的编辑过程。Han等人 [8] 提出在空文本嵌入优化中引入正则化项,以提高重建质量。EDICT [29] 通过维护两个耦合的噪声向量,以交替的方式相互逆推,实现了对真实图像的数学精确DDIM逆推。这种方法使扩散过程的计算时间加倍。CycleDiffusion [30] 提出了一种去噪扩散概率模型(DDPM)逆推方法,通过在DDPM采样过程中恢复能够完美重建图像的一系列噪声向量。与我们的方法相反,他们提取的噪声图分布类似于DDPM的原始噪声空间,这导致编辑能力有限(见图2、图4)。
总结
扩散模型在图像编辑中的逆推(反转)问题核心
使用扩散模型编辑真实图像时,需提取能生成该图像的噪声向量,关键在于扩散模型生成过程的逆推,即从生成图像逆向得到生成它的潜在变量(噪声向量等),以此实现图像编辑等任务。
不同扩散模型逆推方案及问题
1. DDIM方案
-
主流应用:绝大多数基于扩散的编辑工作采用DDIM方案,它是从单个噪声图到生成图像的确定性映射。
-
近似逆推方法及问题:原始DDIM论文提出高效近似逆推方法,但每个扩散时间步有小误差,使用无分类器引导时误差会累积成有意义的偏差,影响图像重建质量。
-
改进方法及局限
**- Mokady等人两步法:**先DDIM逆推计算噪声向量序列,再优化输入空文本嵌入,虽提高重建质量但过程较复杂。
**- Miyake等人:**通过无优化前向传播实现类似重建精度,加快编辑过程,但未从本质上解决逆推误差问题。
**- Han等人:**在空文本嵌入优化中引入正则化项提高重建质量,不过对逆推核心问题的改善有限。
**- EDICT:**通过维护两个耦合噪声向量交替逆推实现数学精确DDIM逆推,但使扩散过程计算时间加倍,效率降低。
2. DDPM方案
**- CycleDiffusion方法:**提出DDPM逆推方法,在DDPM采样过程中恢复能完美重建图像的噪声向量序列。但提取的噪声图分布类似DDPM原始噪声空间,编辑能力有限。
Image editing using diffusion models
去噪扩散概率模型(DDPM)采样方法在真实图像编辑中并不流行。若要使用,通常也不会进行精确逆推。两个例子是,Ho等人[11]在真实图像之间进行插值,Meng等人[17]通过用户草图或笔触(SDEdit)编辑真实图像。这两种方法都是先构建真实图像的含噪版本,编辑后再进行反向扩散。它们面临着生成图像的真实感与对原始内容保真度之间的固有权衡。DiffuseIT[15]在参考图像或文本的引导下进行图像转换,同样没有显式逆推。它们通过衡量与原始图像相似度的损失函数来引导生成过程[6]。
一系列论文采用去噪扩散隐式模型(DDIM)逆推来实现文本驱动的图像到图像转换。Narek等人[27]和Cao等人[4]通过在扩散过程中操纵模型内部的空间特征及其自注意力来实现这一目标。Hertz等人[9]根据目标文本提示更改原始图像的注意力图,并将其注入扩散过程。DiffEdit[5]根据源文本提示和目标文本提示自动为图像中需要编辑的区域生成掩码。这用于确保未编辑区域对原始图像的保真度,以应对逆推得到的较差重建质量。但这种方法无法为复杂提示预测准确的掩码。
一些方法利用基于目标文本提示的模型优化。DiffusionCLIP[14]使用基于目标文本的CLIP损失进行模型微调。Imagic[13]首先优化目标文本嵌入,然后优化模型以使用优化后的文本嵌入重建图像。UniTune[28]也采用微调方法,在保持图像结构的同时,在实现全局风格变化和复杂局部编辑方面取得了巨大成功。其他一些工作,如Palette[24]和InstructPix2Pix[3],学习针对特定编辑任务的定制条件扩散模型。
总结
-
DDPM采样方法在真实图像编辑中的情况
-
DDPM采样方法在真实图像编辑中不流行,即便使用也通常不进行精确逆推。
-
Ho等人和Meng等人的方法构建真实图像含噪版本,编辑后反向扩散,存在生成图像真实感与对原始内容保真度的权衡问题。
-
DiffuseIT在参考图像或文本引导下进行图像转换,无显式逆推,通过损失函数引导生成。
-
-
基于DDIM逆推的文本驱动图像到图像转换方法
-
Narek等人和Cao等人通过操纵模型内部空间特征及其自注意力实现转换。
-
Hertz等人根据目标文本提示更改原始图像注意力图并注入扩散过程。
-
DiffEdit自动生成图像需编辑区域掩码,确保未编辑区域保真度,但无法为复杂提示准确预测掩码。
-
-
基于模型优化的方法
-
DiffusionCLIP利用基于目标文本的CLIP损失进行模型微调。
-
Imagic先优化目标文本嵌入,再优化模型重建图像。
-
UniTune采用微调方法,在保持图像结构同时实现全局风格和复杂局部编辑。
-
-
其他相关工作
- Palette和InstructPix2Pix学习针对特定编辑任务的定制条件扩散模型。
DDPM的噪声空间
在这里,我们关注适用于像素空间和潜在空间的去噪扩散概率模型(DDPM)采样方案。DDPM通过试图逆转一个将干净图像x0x_0x0逐渐转化为高斯白噪声的扩散过程来抽取样本,
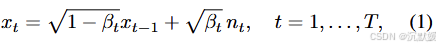
其中nt{n_t}nt是独立同分布的标准正态向量,βt{β_t}βt是某种方差调度。前向过程(1)可以等价地表示为
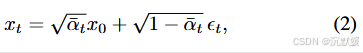
其中αt=1−βtα_t=1−β_tαt=1−βt,αtˉ^=∏s=1tαs\hat{α^ˉ_t}=∏_{s=1}^tα_sαtˉ^=∏s=1tαs,且ϵt∼N(0,I)ϵ_t∼N(0,I)ϵt∼N(0,I)。值得注意的是,在表示(2)中,向量ϵt{ϵ_t}ϵt并非相互独立。这是因为每个ϵtϵ_tϵt对应噪声n1,…,ntn_1,…,n_tn1,…,nt的累积,所以对于所有ttt,ϵtϵtϵt和ϵt−1ϵ_{t−1}ϵt−1高度相关。这一事实对训练过程并无影响,因为训练过程不受不同时间步上ϵtϵ_tϵt联合分布的影响,但这对我们下面的讨论很重要。
生成(逆向)扩散过程从服从N(0,I)N(0,I)N(0,I)的随机噪声向量xTx_TxT开始,并使用以下递归公式对其进行迭代去噪:
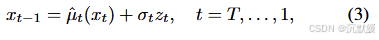
其中zt{z_t}zt是独立同分布的标准正态向量,且
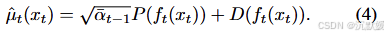

这里,ftf_tft是一个神经网络,经过训练可以从xtx_txt预测ϵtϵ_tϵt,是预测的x0x_0x0,是指向xtx_txt的方向。方差调度由给出,其中η∈[0,1]η∈[0,1]η∈[0,1]。η=1η=1η=1对应于原始的DDPM工作,而η=0η=0η=0对应于确定性的DDIM方案。
这个生成过程可以通过使用在文本[23]或类别[10]上经过训练的神经网络fff进行文本或类别条件生成。或者,条件生成可以通过引导扩散[1, 6]实现,这需要在生成过程中利用预训练的分类器或CLIP模型。
向量xT,zT,…,z1{x_T,z_T,…,z_1}xT,zT,…,z1唯一地确定了过程(3)生成的图像x0x_0x0(但反之不成立)。因此,我们将其视为模型的潜在编码(见图3)。在这里,我们关注的是逆向过程。即,给定一张真实图像x0x_0x0,我们希望提取在(3)中使用的噪声向量,这些噪声向量将生成x0x_0x0。我们希望将这些噪声向量与x0x_0x0保持一致。接下来解释我们的方法,该方法适用于任何η∈(0,1]η∈(0,1]η∈(0,1]。
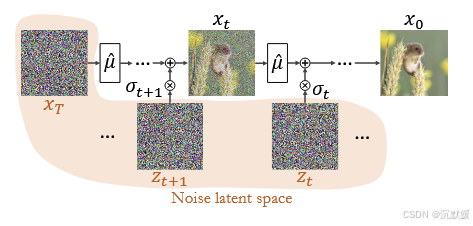
图3. DDPM潜在噪声空间。在DDPM中,生成(逆向)扩散过程利用T+1T+1T+1个噪声图xT,zT,…,z1{x_T,z_T,…,z_1}xT,zT,…,z1,通过TTT个步骤合成图像x0x_0x0。我们将这些噪声图视为与生成图像相关联的潜在编码。
3.1. Edit friendly inversion

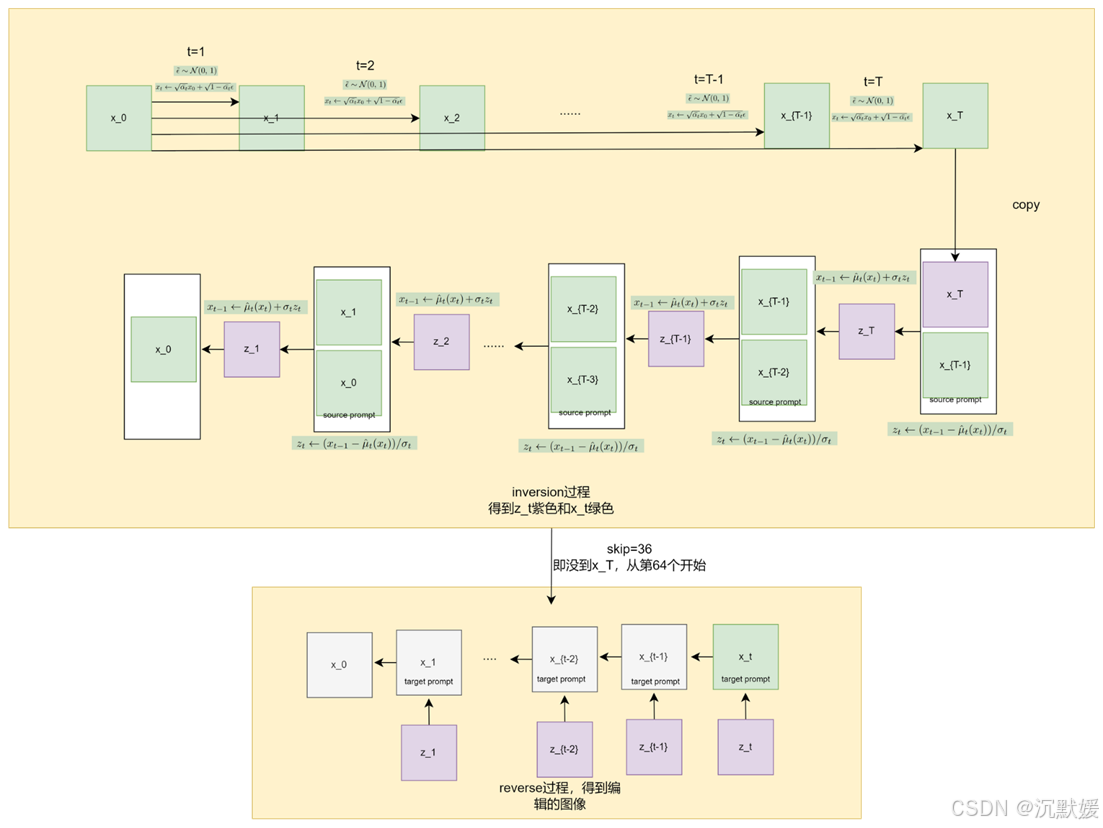
值得注意的是,任何由T+1T+1T+1张图像x0,…,xTx_0,…,x_Tx0,…,xT组成的序列(其中x0x_0x0是真实图像),都可以通过从公式(3)中分离出ztz_tzt来提取一致的噪声图:
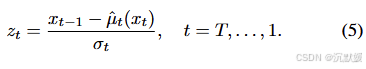
然而,除非精心构建这样的辅助图像序列,否则它们很可能偏离网络ft(⋅)f_t(⋅)ft(⋅)训练时所使用的输入分布。在这种情况下,固定如此提取的噪声图xT,zT,…,z1{x_T,z_T,…,z1}xT,zT,…,z1并改变文本条件可能会导致较差的结果。
那么,如何为公式(5)构建良好的辅助图像x1,…,xTx_1,…,x_Tx1,…,xT呢?一种简单的方法是从与生成过程底层分布相似的分布中抽取这些图像。[30]采用了这种方法。具体来说,他们首先从N(0,I)N(0,I)N(0,I)中采样xTx_TxT。然后,对于t=T,…,1t=T,…,1t=T,…,1,他们使用xtx_txt和真实x0x0x0,根据公式(2)分离出ϵtϵ_tϵt,将其代入公式(4)中的ft(xt)f_t(x_t)ft(xt)来计算μ^t(xt)\hat{μ}_{t}(x_t)μ^t(xt),并使用公式(3)中的μ^t(xt)\hat{μ}_{t}(x_t)μ^t(xt)得到xt−1x_{t−1}xt−1。

图4. 通过CycleDiffusion实现的去噪扩散概率模型(DDPM)逆变换与我们的方法对比。CycleDiffusion的逆变换方法提取出一系列噪声图xT,zT,...,z1{xT,zT,...,z1}xT,zT,...,z1,这些噪声图的联合分布与常规采样中所用的分布接近。然而,固定该潜在编码并替换文本提示时,无法保留图像结构。我们的逆变换方法偏离了常规采样分布,但能更好地编码图像结构。
这种方法提取的噪声图与生成过程的噪声图分布相似。但不幸的是,它们不太适合编辑全局结构。这在文本引导的图4和移位情况的图7中有所说明。原因是DDPM的原始噪声空间首先就不便于编辑。也就是说**,即使我们有一张模型生成的图像,我们有“真实”的噪声图,在改变文本提示的同时固定这些噪声图并不能保留图像的结构**(见图2)。
有趣的是,我们在此观察到,直接从x0x_0x0构建辅助序列x1,…,xTx_1,…,x_Tx1,…,xT,而非通过公式(1),会使图像x0x_0x0更强烈地“印记”到从公式(5)中提取的噪声图上。具体而言,我们建议按如下方式(构建辅助序列)
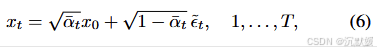
其中ϵt ∼N(0,I)ϵ^~_t∼N(0,I)ϵt ∼N(0,I)在统计上是相互独立的。需要注意的是,尽管公式(6)和公式(2)表面相似,但它们描述的是根本不同的随机过程。在公式(2)中,每对连续的ϵtϵ_tϵt都是高度相关的,而在公式(6)中,ϵt ϵ^~_tϵt 是相互独立的。这意味着在我们的构建方式中,xtx_txt和xt−1x_{t−1}xt−1通常比公式(2)中的情况彼此间隔更远,所以从公式(5)中提取的每个ztz_tzt比常规生成过程中的方差更高。我们的方法提供的伪代码见算法1。

关于这种逆推方法,有几点需要说明。首先,正如我们在补充材料(SM)中所解释的,由于我们补偿了数值误差的累积(算法1的最后一行),该方法能够以机器精度重建输入图像。其次,通过使用μt(⋅)μ^t(⋅)μt(⋅)的适当形式,它可以与任何类型的扩散过程(例如条件模型[11, 12, 23]、引导扩散[6]、无分类器[10])直接结合使用。最后,由于公式(6)中存在随机性,我们可以得到许多不同的逆推结果。虽然其中每一个都能实现完美重建,但当用于编辑时,它们会产生不同变体的编辑图像。这使得在例如基于文本的编辑任务中能够生成多样性,这是DDIM逆推方法自然不具备的特性(见图1和补充材料)。
3.2. Properties of the edit-friendly noise space
3.2. 便于编辑的噪声空间的特性
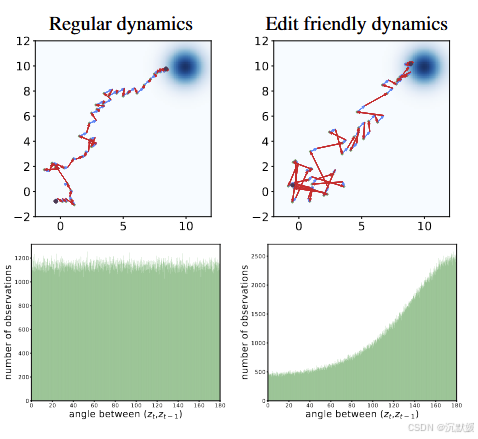
图5. 常规扩散与便于编辑的扩散对比。在常规生成过程(左上角)中,不同时间步的噪声向量(红色)在统计上是相互独立的,因此相邻向量之间的角度在[0, 180°]区间内呈均匀分布(左下角)。而在我们的动态过程(右上角)中,噪声向量的方差更大,且相邻时间步的噪声向量呈负相关(右下角)。
现在,我们探究便于编辑的噪声空间的特性,并将其与原生DDPM噪声空间进行比较。我们先从二维图示入手,如图5所示。此处,我们使用了一个扩散模型,该模型旨在从N((1010),I)N((^{10}_{10}),I)N((1010),I)中进行采样。左上角面板展示了一个常规的DDPM过程,该过程包含40个推理步骤。它从xT∼N((00),I)xT∼N((^0_0),I)xT∼N((00),I)(左下角的黑点)开始,生成一个序列xt{xt}xt(绿点),最终在x0x0x0(右上角的黑点)结束。每一步都分解为确定性漂移μ^t(xt)\hat{μ}_t(x_t)μ^t(xt)(蓝色箭头)和噪声向量ztz_tzt(红色箭头)。在右上角面板中,我们展示了类似的图示,但针对的是我们的潜在空间。具体而言,这里我们使用算法1针对某个给定的x0∼N((1010),I)x_0∼N((^{10}_{10}),I)x0∼N((1010),I)计算序列xt{xt}xt和zt{zt}zt。可以看出,在我们的情况下,噪声扰动zt{zt}zt更大。这一特性源于我们对xtxtxt的构造方式,与式(2)相比,xtxtxt彼此之间通常相距更远。那么,红色箭头怎么会更长,却仍能形成一条从原点指向蓝色云团(目标分布区域)的轨迹呢?仔细观察可以发现,连续噪声向量之间的夹角往往为钝角。换句话说,我们的噪声向量在连续时间上是(负)相关的。这一点也可以从底部的两个图中看出,这两个图分别描绘了常规采样过程和我们采样过程中连续噪声向量之间夹角的直方图。在前一种情况下,角度分布是均匀的;而在后一种情况下,角度分布在180°处有一个峰值。
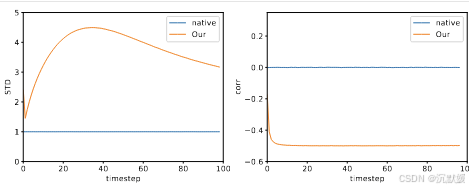
图6. 原生噪声与便于编辑的噪声统计数据对比。此处,我们展示了模型生成图像的{zₜ}逐像素标准差,以及它们之间的逐像素相关性。
在用于图像生成的扩散模型中,也出现了同样的定性特征。图6展示了从在Imagenet数据集上训练的无条件扩散模型中进行100步采样时,ztztzt的逐像素方差以及ztztzt与zt−1zt−1zt−1之间的相关性。这里的统计数据是通过对从该模型中抽取的10幅图像计算得出的。与二维情况一样,我们的噪声向量具有更高的方差,并且在连续时间步之间呈现出负相关性。接下来我们将说明,这些方差更大的噪声向量能更强烈地编码输入图像的结构,因此更适合用于图像编辑。
图7. 图像平移。我们将一张在ImageNet上训练的无条件模型生成的256×256图像向右平移d = 1……16个像素。当平移原生噪声图(顶部)或由CycleDiffusion [30]提取的噪声图(中部)时,图像结构丢失。而使用我们的潜在空间时,图像结构得以保留。
图像平移
直观来看,通过平移潜在编码的所有T + 1个映射图,应该能够实现图像的平移。图7展示了将模型生成图像的潜在编码以不同幅度进行平移后的结果。可以看出,平移原生潜在编码(即用于生成图像的那个编码)会导致图像结构完全丢失。相比之下,平移我们便于编辑的编码,仅会导致轻微的质量下降。补充材料(SM)中提供了定量评估结果。
颜色调整
我们的潜在空间还能方便地实现颜色操控。具体而言,**假设给定一张输入图像x0x0x0、一个二值掩码BBB以及对应的彩色掩码MMM。**我们首先按照之前的方法,利用公式(6)和(5)构建x1,...,xT{x1,...,xT}x1,...,xT并提取z1,...,zT{z1,...,zT}z1,...,zT。接着,我们对噪声图进行如下修改:
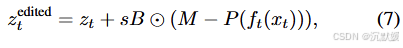
公式功能
-
颜色差异计算:
- (M−P(ft(xt)))(M−P(f_t(x_t)))(M−P(ft(xt))) 计算了期望颜色 MMM 与预测颜色 P(ft(xt))P(f_t(x_t))P(ft(xt)) 之间的差异。
-
应用编辑:
- 通过将颜色差异与掩码 BBB 相乘,并将结果缩放 sss 倍后加到原始潜在表示 ztztzt 上,实现了对指定区域的编辑。
其中P(ft(xt))P(f_t(x_t))P(ft(xt))来自公式(4),sss是控制编辑强度的参数。我们在时间步范围[T1,T2][T1,T2][T1,T2]内进行此修改。请注意,括号中的项对每个时间步中期望颜色与预测的干净图像之间的差异进行编码。图8说明了与SDEdit相比此过程的效果,SDEdit在保真度(相对于输入图像)和与期望编辑的一致性之间存在固有的权衡。我们的方法可以在不修改纹理(掩码内和掩码外的纹理均不修改)的情况下实现强大的编辑效果。

图8. 真实图像的颜色操控。我们的方法(此处以T2=70T2=70T2=70到T1=20T1=20T1=20,s=0.05s=0.05s=0.05应用)产生了显著的编辑效果,同时未改变纹理和结构。另一方面,SDEdit在使用较小噪声时(左图)无法很好地融合掩码,而在噪声较大时(右图)则无法保留结构。在这两种方法中,我们都使用了在ImageNet上训练的无条件模型,推理步数为100步。
文本引导的图像编辑
我们的潜在空间可用于文本驱动的图像编辑。
假设给定一张真实图像x0x_0x0、描述该图像的文本提示psrcp_{src}psrc以及目标文本提示ptarp_{tar}ptar。
为了根据这些提示修改图像,我们在将psrcp_{src}psrc输入到去噪器中的同时,提取便于编辑的噪声图xT,zT,...,z1{xT,zT,...,z1}xT,zT,...,z1。
然后,我们固定这些噪声图,并在将ptarp_tarptar输入到去噪器中的同时生成图像。
我们从时间步T−TskipT−TskipT−Tskip开始运行生成过程,其中TskipTskipTskip是一个控制对输入图像的依从程度的参数。
图1、2、4和9展示了使用这种方法进行的几个文本驱动编辑示例。可以看出,这种方法在保留图像结构的同时很好地修改了语义。此外,它还允许针对任何给定的编辑生成多样化的输出(见图1和补充材料)。我们还进一步说明了将我们的反转方法与依赖DDIM反转的方法结合使用的效果(见图1和11)。可以看出,这些方法通常无法保留精细纹理,如毛发、花朵或树叶,并且通常也无法保留物体的整体结构。通过整合我们的反转方法,结构和纹理得到了更好的保留。