[AI 概念域] LangChain 核心组件概念解读(通俗解读)
说明:这里主要解读Langchain中的关键概念。以更形象和更容易理解的方式解读,主要包括:Models(模型)、Prompts(提示)、Indexes(索引)、Memory(内存)、Chains(链)、Agents(代理)及他们彼此之间的关系。
1 Langchain中的关键概念
LangChain 是一个用于开发由大型语言模型(LLM)驱动的应用程序的框架。它旨在简化构建和部署基于语言模型的应用程序的过程,提供了一系列模块和工具,使开发者能够轻松地将 LLM 集成到各种应用程序中。LangChain 的核心目标是帮助开发者构建智能对话机器人、问答系统、文本生成器等应用。
LangChain 包含以下核心组件:
- Models(模型):提供对各种大型语言模型(如 OpenAI ChatGPT、Hugging Face 模型等)的集成和调用接口。
- Prompts(提示):用于创建和管理提示词模板,控制模型的输入和输出。
- Indexes(索引):用于将大量非结构化文本数据结构化,以便模型能够快速准确地检索信息。
- Memory(内存):提供对话记忆功能,使模型能够在对话过程中保留上下文信息,生成更具连贯性的响应。
- Chains(链):将多个组件组合在一起,形成一个完整的应用程序流程。链可以是简单的顺序执行,也可以是复杂的条件分支和循环。
- Agents(代理):允许模型与外部 API 和工具进行交互,扩展模型的功能和应用场景。
看完了这个基本的解释,你对这些概念了解了吗?看概念都懂,然而放在一起。。。总是感觉哪里不太对。这里我们拿Langchain和C语言、Java语言进行类比,你就知道它们之间的关系到底是怎么回事儿了?
先来看LangChain 与 C 语言的类比:
-
LangChain:类似于 C 语言中的标准库,提供了一系列预定义的函数和工具,帮助开发者快速构建应用程序。
-
Models(模型):类似于 C 语言中的函数,每个模型提供特定的功能,如文本生成、问答等。
-
Prompts(提示):类似于 C 语言中的函数参数,用于控制模型的输入和输出。
-
Indexes(索引):类似于 C 语言中的数据结构,用于组织和管理数据。
-
Memory(内存):类似于 C 语言中的变量和数据存储,用于保留对话历史和上下文信息。
-
Chains(链):类似于 C 语言中的程序流程控制,如循环和条件语句,用于组织和控制应用程序的执行流程。
-
Agents(代理):类似于 C 语言中的外部库调用,用于与外部系统和工具进行交互。
再来看LangChain 与 Java 语言的类比:
-
LangChain:类似于 Java 语言中的框架,提供了一套完整的工具和接口,帮助开发者构建智能应用程序。
-
Models(模型):类似于 Java 语言中的类,每个模型提供特定的功能,如文本生成、问答等。
-
Prompts(提示):类似于 Java 语言中的方法参数,用于控制模型的输入和输出。
-
Indexes(索引):类似于 Java 语言中的数据结构,用于组织和管理数据。
-
Memory(内存):类似于 Java 语言中的变量和数据存储,用于保留对话历史和上下文信息。
-
Chains(链):类似于 Java 语言中的流程控制语句,如 if、for、while 等,用于组织和控制应用程序的执行流程。
-
Agents(代理):类似于 Java 语言中的接口,用于与外部系统和工具进行交互。
两轮的类比,怎么样,实际上langchain就是基于LLM大语言模型进行编程而准备的。因此和编程语言中的设计理念均有明确的对应关系。基于此,我们再来理解这几组概念。
1.1 Models(模型)
1.1.1 概念描述
Models 是 LangChain 对接各类大语言模型(LLM)的接口层,承担自然语言生成与理解的核心功能。它支持 OpenAI GPT、Azure OpenAI、Llama 等主流 LLM,并实现输入输出标准化。
1.1.2 形象比喻
如同"翻译官":
- 输入转换:将应用层请求转化为 LLM 能理解的协议格式(如 OpenAI API 规范)
- 输出适配:将模型原始响应转化为结构化数据(JSON/XML)供下游使用
1.1.3 存在意义
- 统一接口:消除不同 LLM 的接入差异(如 OpenAI 与 Claude 的 API 差异)
- 性能优化:内置缓存机制降低重复请求成本
- 扩展能力:支持私有化模型部署(如企业内部微调版 GPT)
1.1.4 关联概念
| 关联概念 | 交互形式 | 技术实现案例 |
|---|---|---|
| Prompts | 接收结构化提示模板 | 通过 model.generate(prompt) 调用 |
| Chains | 作为链式流程的原子单元 | 在 RAG 链中承担最终生成任务 |
1.2 Prompts(提示)
1.2.1 概念描述
Prompts 是经过工程化设计的输入指令模板,通过占位符动态注入上下文信息,精确引导 LLM 生成符合预期的输出。其形态包括:
- 指令模板:
请用{style}风格解释{concept} - 少样本示例:提供输入-输出范例引导模型行为
1.2.2 形象比喻
如同"考试命题":
- 填空题:
西电樱花在_{month}_月开放→ 约束输出格式 - 材料作文:
根据材料{context},分析...→ 控制内容边界
1.2.3 存在意义
- 降低幻觉率:通过模板限定生成范围(如禁止医学诊断建议)
- 提升复用性:同一模板适配多语种/多场景需求
- 增强可控性:支持输出结构校验(通过 Pydantic 模型)
1.2.4 关联概念
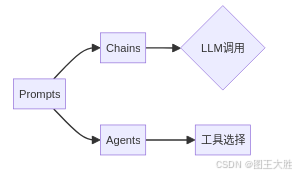
1.3 Indexes(索引)
1.3.1 概念描述
Indexes 是外部知识的结构化存储与检索系统,通过文档分块、向量化、相似度匹配等技术,实现非结构化数据的快速查询。典型应用场景包括:
- 企业知识库:产品手册/合同文档检索
- 实时数据接入:股票行情/新闻快讯查询
1.3.2 形象比喻
如同"图书馆索引系统":
- 编目员(Embedding 模型):将文档转化为向量编码
- 书架(向量数据库):FAISS/Chroma 等存储结构
- 检索台(相似度算法):余弦相似度/KNN 搜索
1.3.3 存在意义
- 突破模型知识时效性:无需重新训练即可接入最新数据
- 降低幻觉风险:生成内容需与检索结果强关联
- 提升专业精度:补充领域知识(如法律条款)
1.3.4 关联概念
| 技术组件 | 交互流程示例 |
|---|---|
| RAG 链 | 检索→增强→生成的三段式处理 |
| Agents | 动态调用索引库补充决策依据 |
1.4 Memory(内存)
1.4.1 概念描述
Memory 是对话状态与历史信息的持久化存储机制,支持短期记忆(会话上下文)与长期记忆(用户偏好)的维护。主要实现形式包括:
- 对话缓冲:保存最近 N 轮交互记录
- 向量记忆:将关键信息编码存储供后续检索
1.4.2 形象比喻
如同"人类记忆系统":
- 工作记忆:临时保存当前对话要点(类似 CPU 缓存)
- 长期记忆:持久化存储用户特征(如偏好语言风格)
1.4.3 存在意义
- 多轮连贯性:实现指代消解(如"它"指向上文实体)
- 个性化服务:记忆用户习惯提升体验
- 效率优化:避免重复输入相同背景信息
1.4.4 关联概念
# 记忆与链的集成示例
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
memory = ConversationBufferMemory()
chain = ConversationChain(llm=llm, memory=memory) # 记忆注入对话链
1.5 Chains(链)
1.5.1 概念描述
Chains 是预定义的任务处理流水线,通过标准化接口串联多个组件(模型/提示/工具),实现复杂业务逻辑的模块化编排。典型链结构包括:
- 检索问答链:Indexes→Prompts→Models
- 数据清洗链:文本拆分→向量化→存储
1.5.2 形象比喻
如同"工厂流水线":
原料(输入)→ 切割机(文本分块)→ 焊接器(信息融合)→ 质检仪(结果校验)→ 成品(输出)
1.5.3 存在意义
- 流程标准化:封装最佳实践(如客服应答流程)
- 组件复用:不同链可共享子模块
- 可观测性:通过 LangSmith 监控各环节性能
1.5.4 关联概念
| 链类型 | 组成要素 | 技术实现 |
|---|---|---|
| LLMChain | Prompt→Model→OutputParser | 基础生成链 |
| RetrievalQA | Retriever→Prompt→Model | 知识增强问答链 |
1.6 Agents(代理)
1.6.1 概念描述
Agents 是具备自主决策能力的智能体,通过 ReAct 模式(思考→行动→观察)动态调用工具链解决问题。其核心特征包括:
- 工具编排:根据上下文选择最佳工具(如计算器/搜索引擎)
- 递归决策:通过多轮 LLM 调用实现复杂任务分解
1.6.2 形象比喻
如同"全能导游":
- 需求解析:理解游客想参观历史古迹
- 路线规划:调用地图工具制定行程
- 应急调整:遇雨雪天气启动备选方案
1.6.3 存在意义
- 动态适应性:突破预定义链的刚性限制
- 跨域协作:集成外部系统(如 CRM/ERP)
- 复杂任务处理:实现多步骤问题求解
1.6.4 关联概念
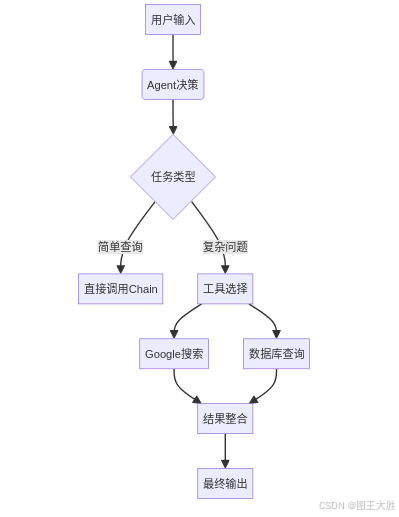
2 概念关系和设计哲学总结
2.1 概念关系全景图
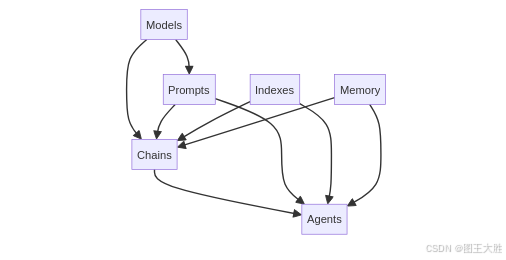
关系解析:
-
纵向分层
- 基础层(Models/Prompts):提供原子能力
- 编排层(Chains/Agents):实现流程控制
- 增强层(Indexes/Memory):扩展知识边界
-
横向协作
- Chains 侧重预定义路径,适合标准化场景
- Agents 强调动态决策,应对复杂需求
- Memory 贯穿全流程维持状态一致性
2.2 概念应用,Langchain代码实测
以下是使用阿里巴巴通义千问模型的 Python 代码示例,涵盖了 Models(模型)、Prompts(提示)、Indexes(索引)、Memory(内存)、Chains(链)和 Agents(代理)等概念:
2.2.1 安装依赖
在运行代码之前,请确保安装了以下依赖:
bash复制
$pip install langchain requests2.2.2 创建 .env 文件
创建一个 .env 文件,用于存储通义千问的 API 密钥:
QWEN_API_KEY=your_qwen_api_key
ALIYUN_API_KEY=your_qwen_api_key
QWEN_API_BASE=https://qwen.aliyuncs.com2.2.3 Python 代码实现
import os
from dotenv import load_dotenv
from langchain.llms import Tongyi
from langchain.prompts import PromptTemplate
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.chains import RetrievalQA, LLMChain
from langchain.agents import initialize_agent, Tool
# ========== 初始化配置 ==========
load_dotenv()
os.environ["DASHSCOPE_API_KEY"] = os.getenv("ALIYUN_API_KEY") # 从.env读取密钥
# ========== Models ==========
llm = Tongyi(
model_name="qwen-plus",
temperature=0.7,
max_length=2000,
model_kwargs={"enable_search": True} # 启用网络增强
)
# ========== Prompts ==========
qa_template = """基于以下知识库内容:
{context}
历史对话记录:
{history}
当前问题:{question}
请用专业中文给出详细回答,要求:
1. 引用知识库中的具体数据
2. 若涉及计算需展示推导过程
3. 保持口语化表达"""
prompt = PromptTemplate(
input_variables=["context", "history", "question"],
template=qa_template
)
# ========== Indexes ==========
documents = [
"西安电子科技大学樱花季传统始于2005年,每年3月20日-4月10日为最佳观赏期",
"2025年校历显示:3月25日举办樱花节开幕式,预计游客峰值日均2万人次",
"樱花分布区域:图书馆前广场(50%)、海棠餐厅步道(30%)、东区实验楼(20%)"
]
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
vector_db = FAISS.from_texts(documents, embeddings)
# ========== Memory ==========
memory = ConversationBufferMemory(
memory_key="history",
return_messages=True,
output_key="output"
)
# ========== Chains ==========
# 知识库问答链
retrieval_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vector_db.as_retriever(search_kwargs={"k": 3}),
memory=memory,
chain_type_kwargs={"prompt": prompt},
return_source_documents=True
)
# 数学计算链
math_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(
"用中文分步解答以下问题,要求展示计算过程:\n{input}"
),
verbose=True
)
# ========== Agents ==========
tools = [
Tool(
name="CampusKnowledge",
func=lambda q: retrieval_chain.run(q)['result'],
description="回答西电樱花相关的知识性问题,需引用校历数据"
),
Tool(
name="MathExpert",
func=math_chain.run,
description="解决数学计算问题,包括统计、代数、几何等"
)
]
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
memory=memory,
verbose=True,
handle_parsing_errors=True
)
# ========== 执行代理 ==========
questions = [
"2025年樱花节预计接待多少游客?按区域分布计算各区域日均接待量",
"如果樱花节期间门票收入为150万元,日均客流量1.2万人,计算人均消费"
]
for idx, q in enumerate(questions, 1):
print(f"\n问题{idx}: {q}")
result = agent.run(q)
print(f"智能回答:\n{result}\n" + "-"*60)
代码说明:
- Models(模型):使用阿里巴巴的通义千问模型来生成文本。
- Prompts(提示):定义了一个提示模板,用于引导模型生成回答。
- Indexes(索引):使用 LangChain 的 向量存储库来存储和检索文档。
- Memory(内存):使用
ConversationBufferMemory来保留对话历史。 - Chains(链):创建了一个链,将提示模板和模型串联起来。
- Agents(代理):初始化了一个代理,用于与模型和工具进行交互。
通过这段代码,你可以使用阿里巴巴通义千问的模型来构建基于大语言模型的应用程序。注意:这里代码主要为理解Langchain中的概念为主。专注于调用方式展示而非逻辑本身,参考即可。
2.3 设计哲学总结
LangChain 通过六大核心概念的模块化设计,构建了 LLM 应用开发的"操作系统":
- 解耦与复用:每个概念专注单一职责(如 Models 对接模型、Prompts 控制输入)。
- 可观测性:通过 LangSmith 实现全链路监控。
- 生态扩展:工具链支持持续集成新能力(如实时 API/私有化模型)。
这种设计使得开发者既能快速搭建基础应用(通过预置 Chains),又能应对高度定制化需求(通过 Agents 扩展)。正如乐高积木的模块化理念,LangChain 正在重塑 LLM 应用的工业化生产方式。