Linux进程(3)
接上篇:我们说到,不可能同一个变量,同一个地址,同时读取,读到不同的内容。
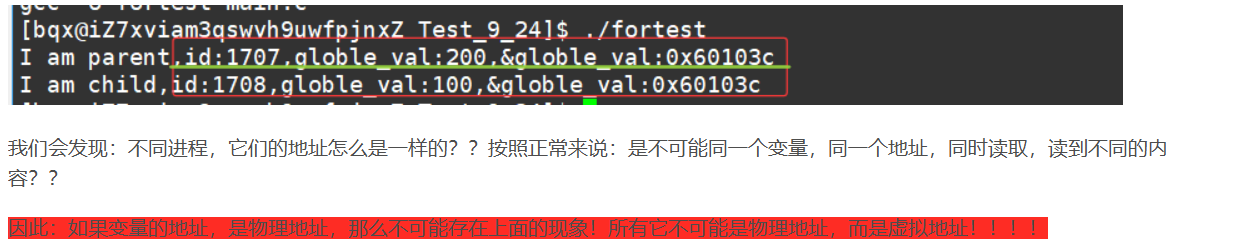
我们现在引出新概念,初步理解这种现象----
第二次谈进程
引入地址空间的概念
我们使用图来形象了解一下:
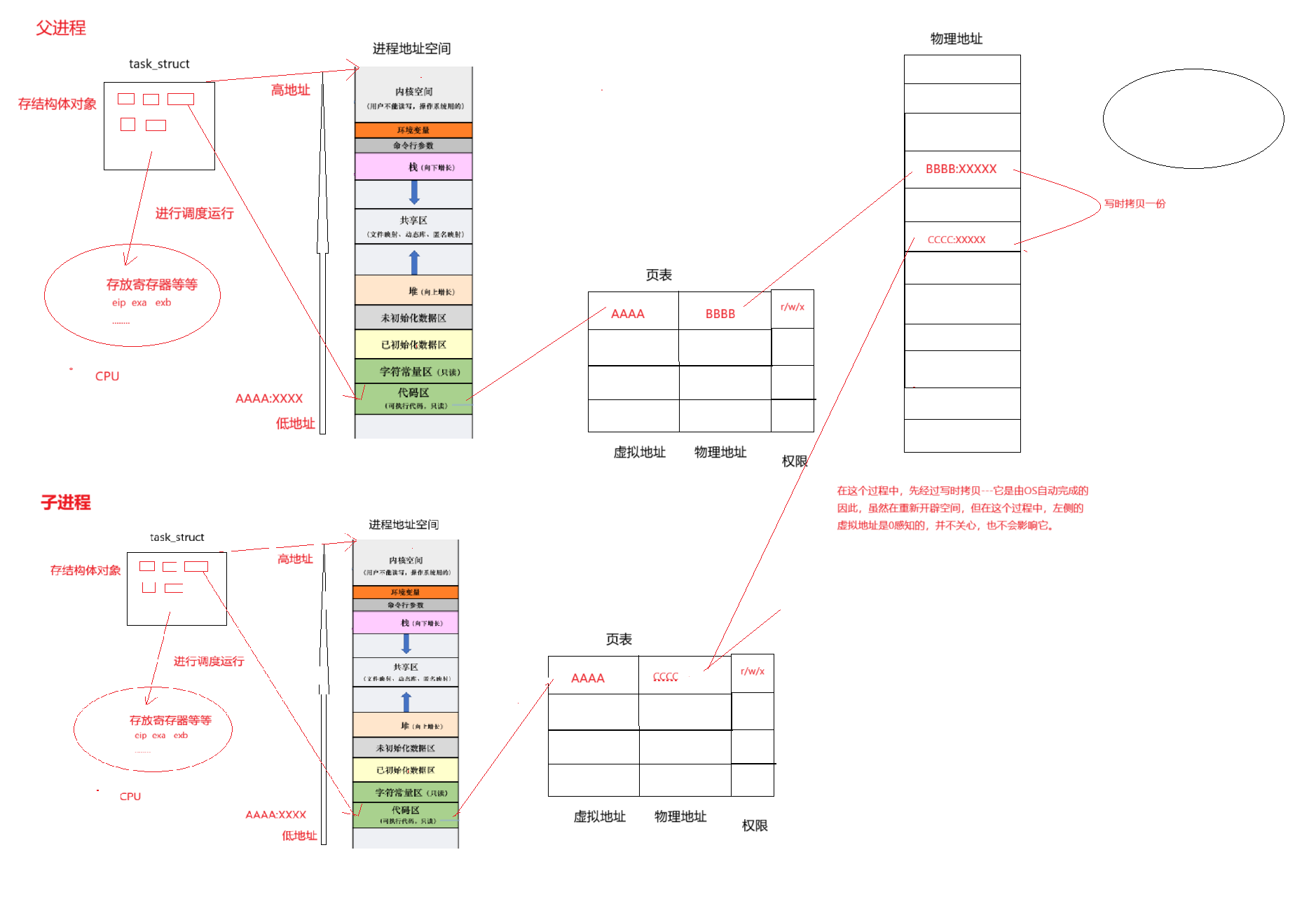
我们现在正式来谈谈进程地址空间的概念:
我们主要围绕下面问题展开分析:
1.什么叫做地址空间?
2.如何理解地址空间上的区域划分?
1.地址空间:
- 地址空间的形成(以32位计算机为例):32位计算机有32根地址总线,每根总线只有0、1两种状态,因此地址范围是 [0, 2^{32}) 。若每个地址对应1字节,地址空间大小为 2^{32} 字节,即4GB。
2.如何理解地址空间上的区域划分?
我们用例子来具体形象地理解它:
struct area{int start;int end; }; struct destop_area { // 约定最大范围100cmstruct area xiaopang;struct area xiaohua; }; struct destop_area line_area = {(1,50), (51,100)}; // 可通过修改start和end调整区域,如:line_area.xiaopang.end -= 10;line_area.xiaohua.start += 10;形成各自都拥有自己的区域空间: struct destop_area {int start_xiaopang;int end_xiaopang;int start_xiaohua;int end_xiaohua; }我们在这里不仅仅要看到给某一个人划分的地址空间的范围:
而且,在范围内,连续的空间中,每一个最小单位都可以有地址,这个地址可以被属于这个人的之间使用。
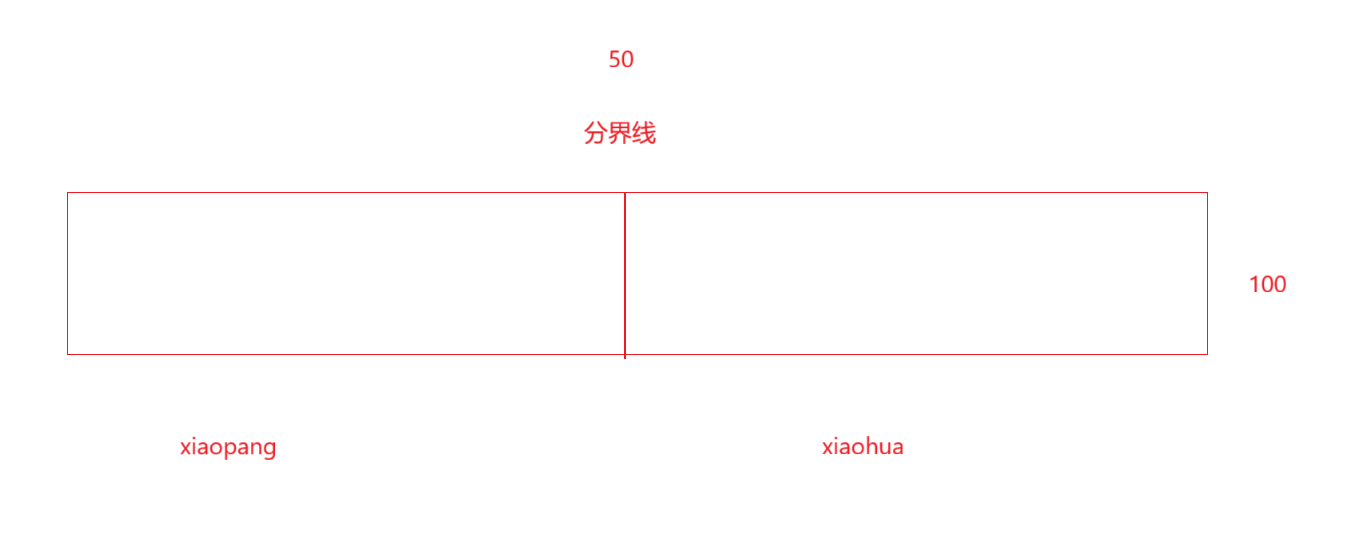
所以,什么是地址空间?
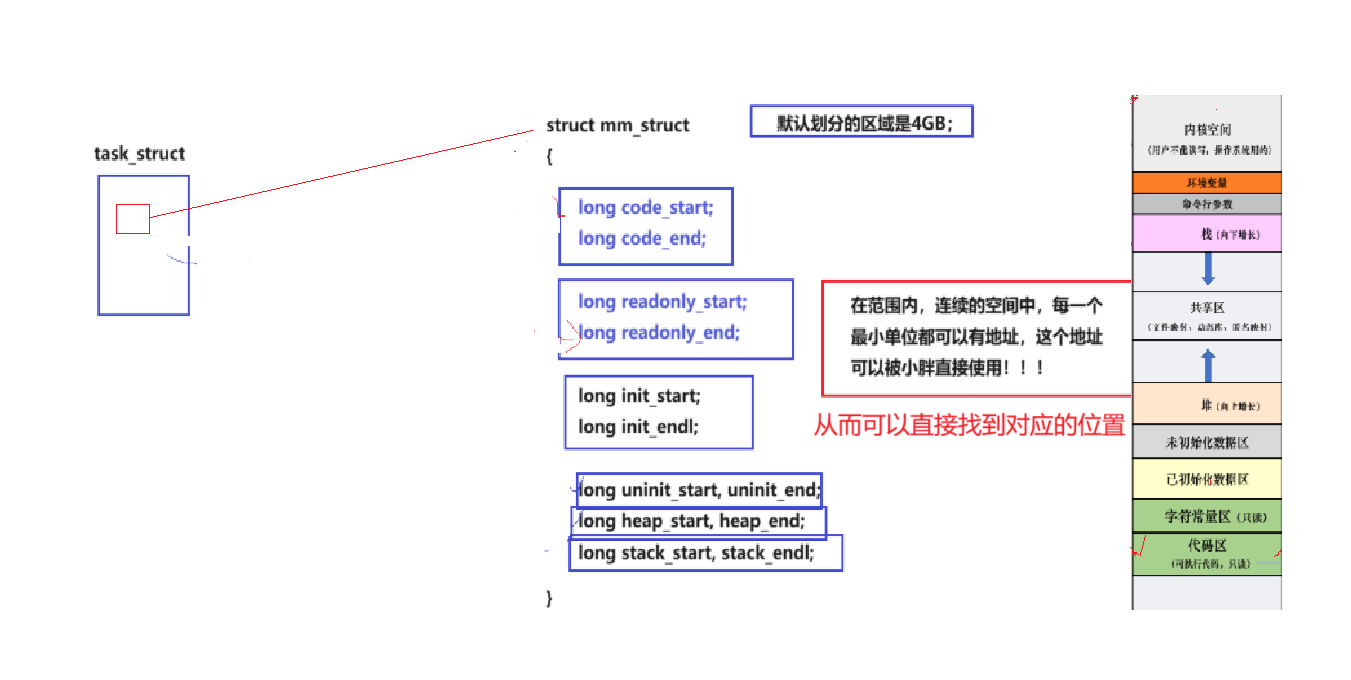
- 地址空间的定义:在连续的空间范围内,每个最小单位都有可被直接使用的地址,这一空间范围就是地址空间。进程地址空间本质是描述进程可使用地址范围的大小。
所以,地址空间内一定要存在各种区域划分,对线性地址进行start和end.
这样看来,地址空间就跟pcb类似,本质上是内核的一个数据结构对象,地址空间也是要被操作系统管理的:先描述,再组织
所以,我们现在就可以再完善一下关于进程的概念了:
进程=内核数据结构(task_struct &&mm_struct &&页表)+程序的代码和数据
虚拟地址空间的作用:
1. 统一内存视角:让进程以一致的方式看待内存,简化进程对内存的访问逻辑。
ps:为什么?大富翁有好多个私生子的例子:
给私生子画饼,将来收100亿财产继承,但每个私生子并不知道他们各自的存在,都认为自己每个人都能有100亿
2. 保护物理内存:通过虚拟地址到物理地址的转换过程,审查寻址请求,拦截异常访问,防止物理内存被非法操作。
3. 模块解耦合:借助地址空间和页表,将进程管理模块与内存管理模块分离,使两者可独立设计与维护。
ok,上面我们只是简单引入页表,但是,我们并没有具体谈谈页表的具体内容:那么现在,我们就来谈谈关于Linux内核中的页表:
一、进程内存管理的核心结构
- task_struct :进程控制块,其中包含指向 mm_struct 的指针 mm_struct *mm ,是进程管理的核心数据结构。
- mm_struct(进程地址空间) :管理进程的内存空间,划分了用户空间(如代码段、数据段、栈等)和内核空间(高地址区域),体现了进程的虚拟地址空间布局。
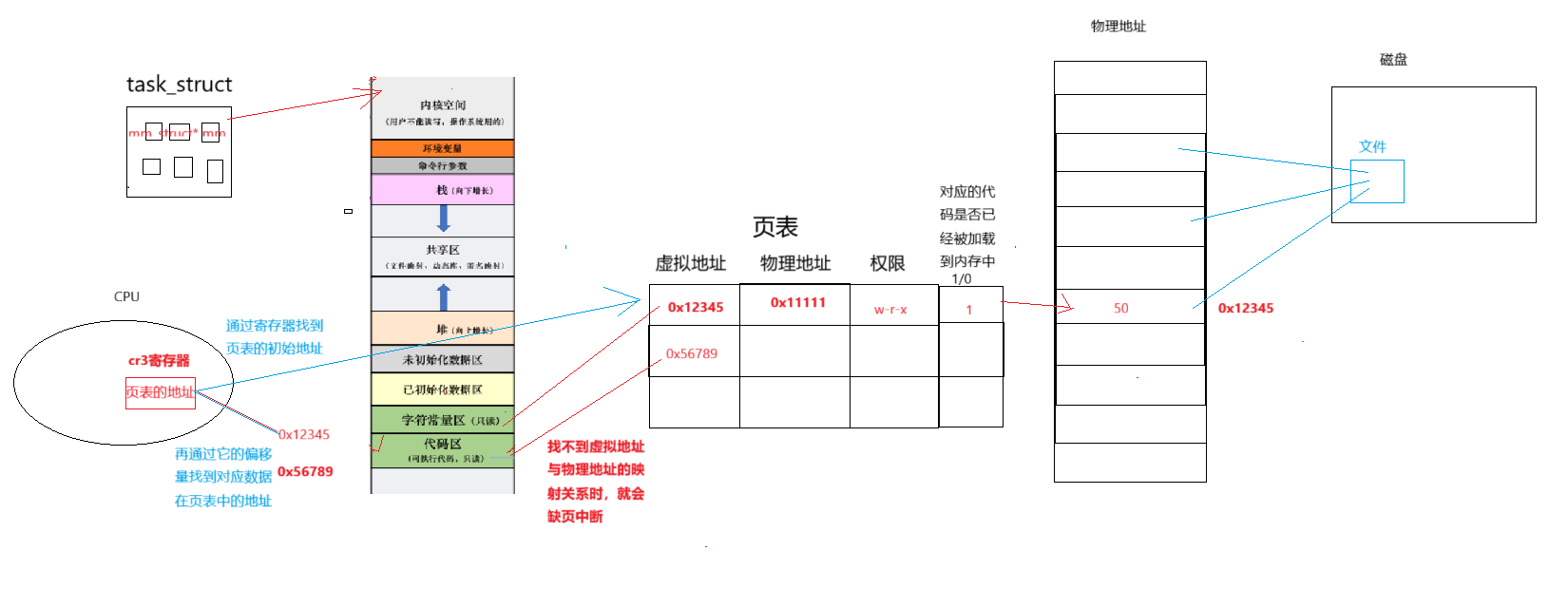
- 页表与 cr3 寄存器:CPU 通过 cr3 寄存器存储页表基址,借助页表实现虚拟地址到物理地址的映射,这是内存管理的硬件支撑。
二、进程独立性的实现
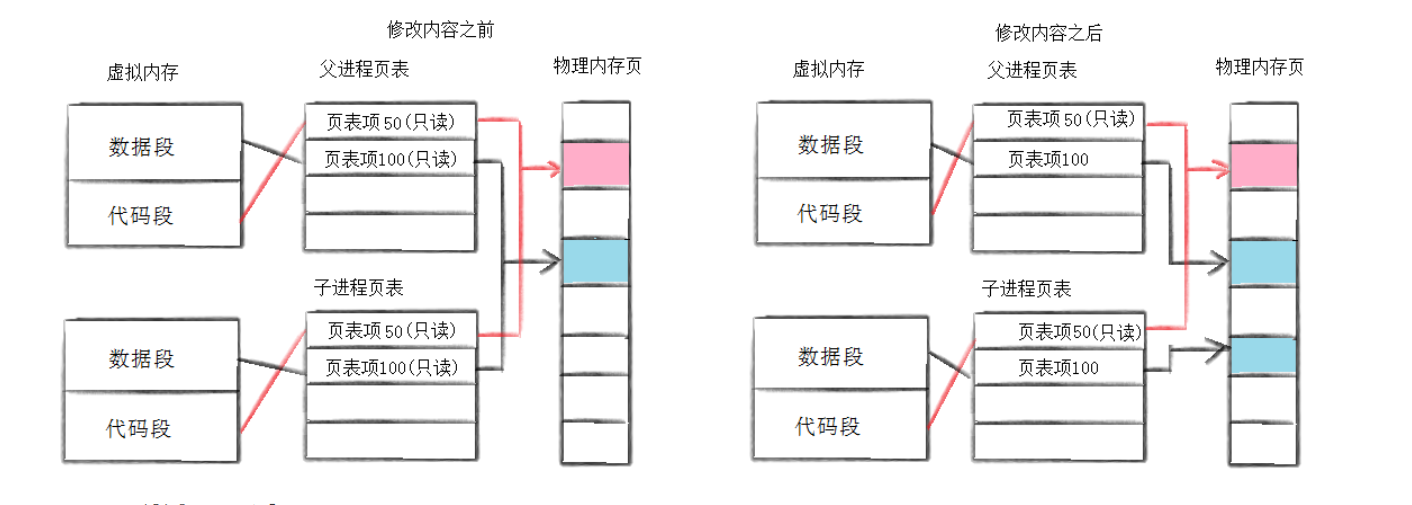
进程具有独立性,是通过独立的虚拟地址空间实现的。每个进程有自己的 mm_struct 和页表,使得不同进程的虚拟地址相互隔离,即使虚拟地址相同,经页表映射后也会指向不同的物理内存区域,从而保证了进程间的内存独立性。
三、进程创建与程序加载机制
- 进程创建时,先创建内核数据结构(如 task_struct 、 mm_struct 、页表等),再按需加载可执行程序(采用惰性加载方式,避免浪费空间和时间)。
- 代码段和字符串常量区被设置为只读,这是为了防止进程运行时意外修改代码,保证程序执行的一致性与安全性。
四、惰性加载与缺页中断
- 操作系统对大文件(或程序)采用惰性加载方式,即并不在进程创建时就将所有代码和数据加载到内存,而是用到时再加载。
- 当进程访问的虚拟地址未加载到物理内存时,会触发缺页中断。此时操作系统会从磁盘(如硬盘)中读取对应的数据或代码,加载到物理内存,并更新页表映射,从而让进程继续执行。这一机制也解释了“如何知道进程的代码/数据不在内存”——通过缺页中断的触发来感知。
五、操作系统的设计共识
现代操作系统遵循“几乎不做任何浪费空间和浪费时间的事情”的原则,例如惰性加载就是这一原则的体现,避免了不必要的内存占用和 IO 开销。
进程终止:
我们常见的进程终止的场景有哪些?
1.代码运行完毕,结果正常
2.代码运行完毕,结果不正常
3.代码异常终止
在进程当中,谁会关心我运行的情况呢?
一般而言是我们进程的父进程要关心!关心什么?
关心它为什么不正确。所以可以用return的不同的返回值数字,表征不同的出错原因,即退出码
父进程为什么要关心?
代码异常终止本质可能就是代码没有跑完,进程的退出码无意义,我们不关心退出码了。
那你要不要关心我为什么异常了呢?以及我发生了什么异常?要,肯定要!
进程出现异常,本质是我们的进程收到了对应的信号
进程退出的方法:
查看进程退出码:
echo $?: 保存的是最近一次进程退出的时候的退出码。
正常退出:
1.从main返回
2.从exit返回
3.从_exit返回
异常退出:
ctrl+c
main函数的返回值,本质表示:进程运行完成时是否是正确的结果,如果不是,可以用不同的数字,表示不同的出错原因!
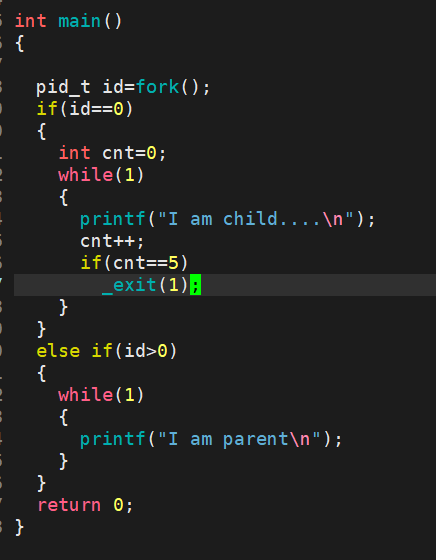
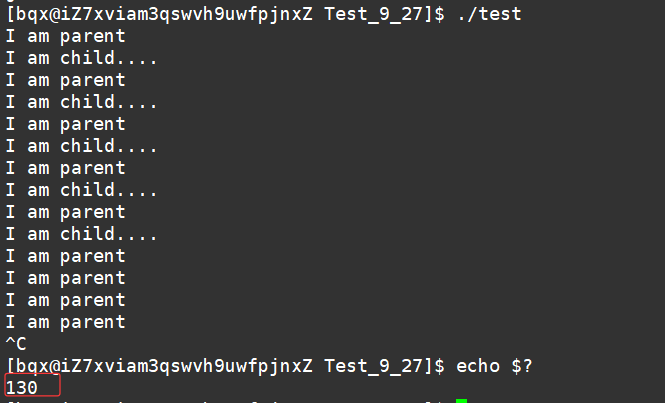
130是什么呢?我们来打印一下它的
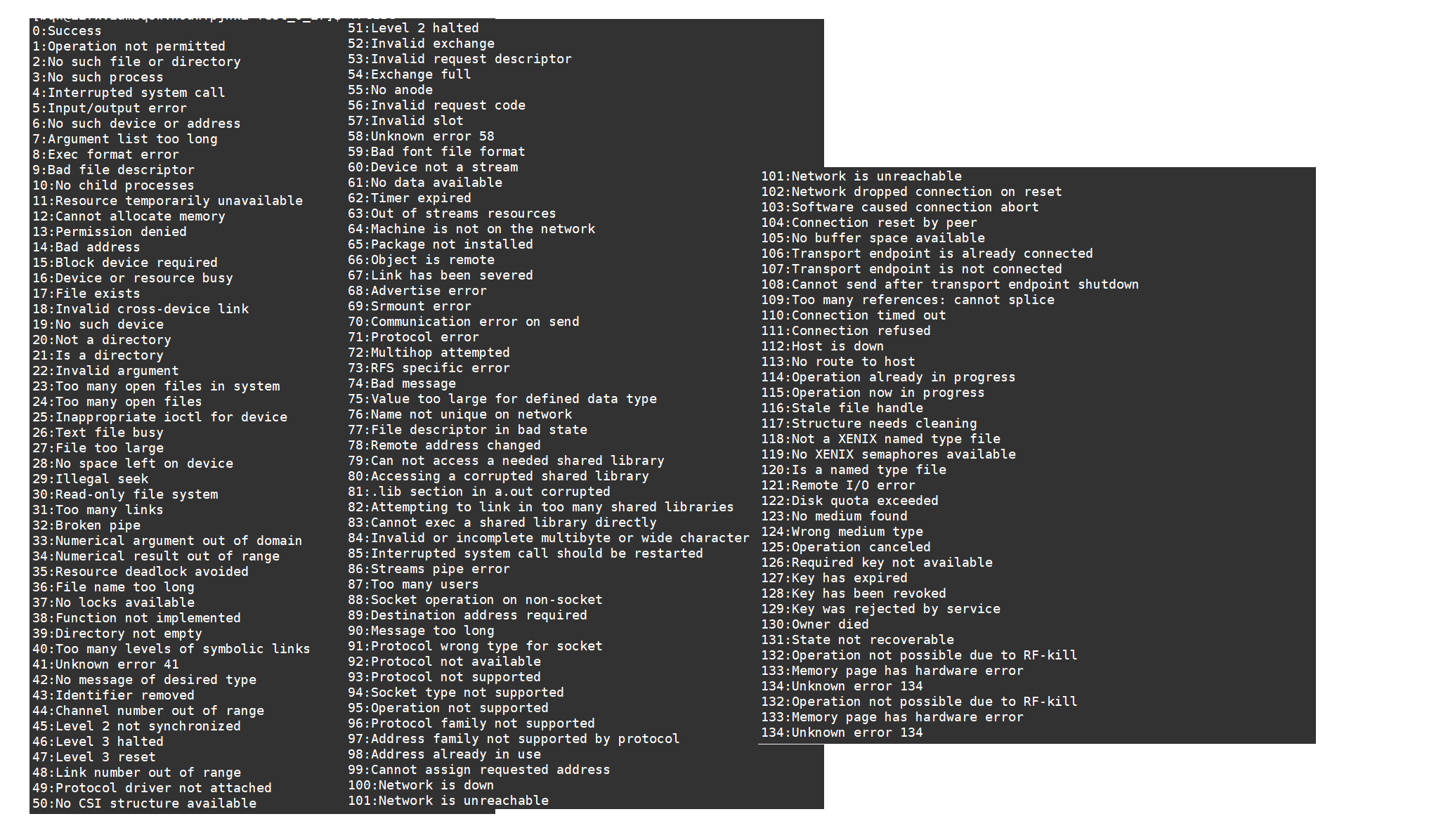
我们可以看到,他们的退出码都是一样的,那么exit与_exit有什么区别呢?
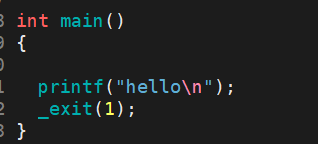
_exit函数:
- 进程会“立即”终止,所有打开的文件描述符会被关闭;进程的子进程会被进程1( init 进程)继承;父进程会收到 SIGCHLD 信号。
- 参数 status 会作为进程的退出状态返回给父进程,父进程可通过 wait(2) 系列调用收集该状态。
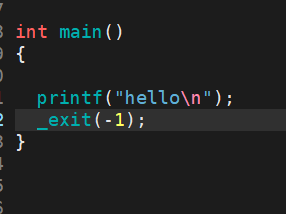
说明:虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?发现返回值是255。
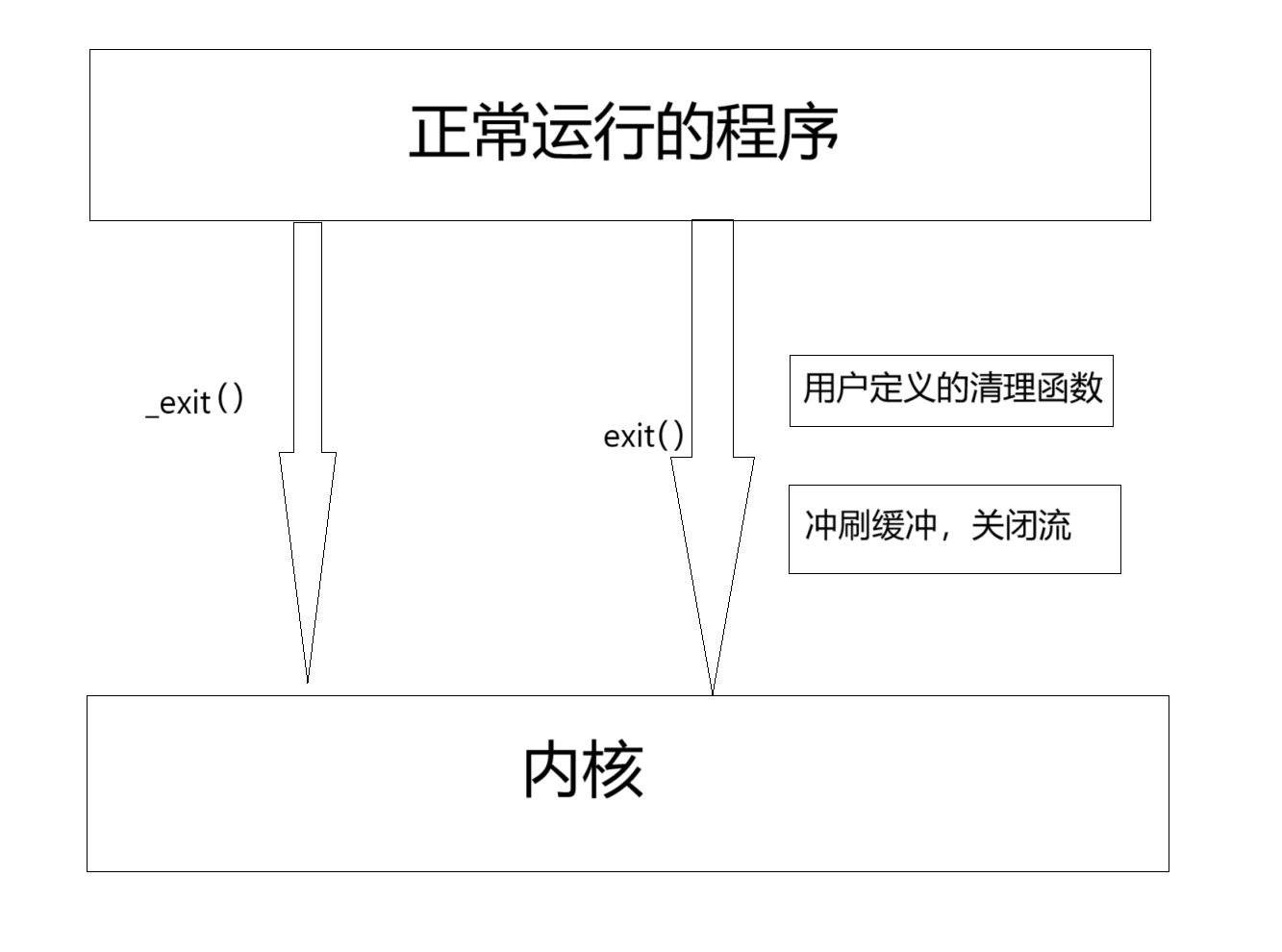
exit函数
exit最后也会调用exit, 但在调用exit之前,还做了其他工作:
1. 执行用户通过 atexit或on_exit定义的清理函数。 2. 关闭所有打开的流,所有的缓存数据均被写入3. 调用_exit
那么,我们的printf一定是先把数据写入缓冲区中,合适的时候,在进行刷新!
这个缓冲区绝对不在内核中!!!
我们来证明一下:
return退出:
return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数。





进程等待
- 是什么:通过系统调用 wait / waitpid ,实现对子进程的状态检测与资源回收功能。
- 为什么
- 必要性:僵尸进程无法被直接杀死,需通过进程等待回收,否则会引发内存泄漏问题。
- 可选性:可通过进程等待获取子进程的退出情况,了解子进程任务的完成状态(可选择关心或不关心)。
- 怎么办
- 代码层面:父进程调用 wait / waitpid 来回收僵尸进程。
认识wait/waitpid
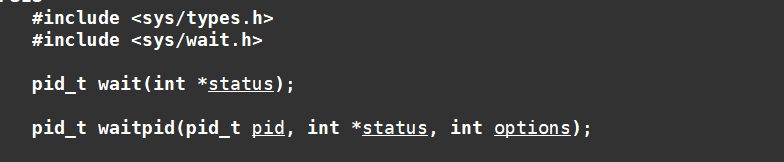
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
返回值:
成功返回被等待进程pid,失败返回-1。
参数:
输出型参数,获取子进程退出状态,不关心则可以设置成为NULL
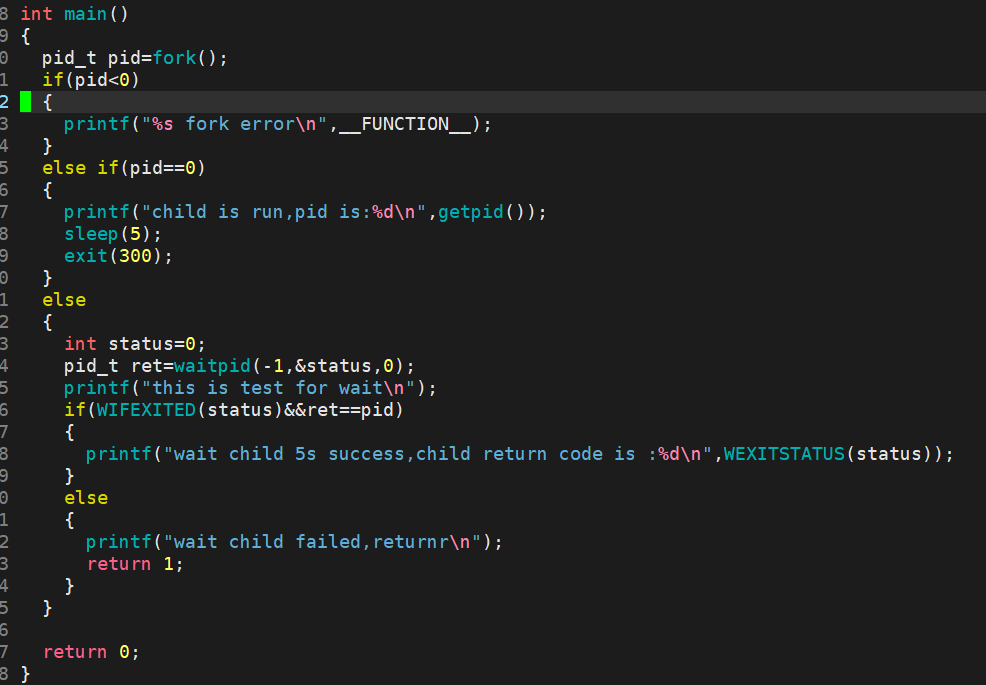
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候waitpid返回收集到的子进程的进程ID;
如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数:
pid:
Pid=-1,等待任一个子进程。与wait等效。
Pid>0.等待其进程ID与pid相等的子进程。
status:
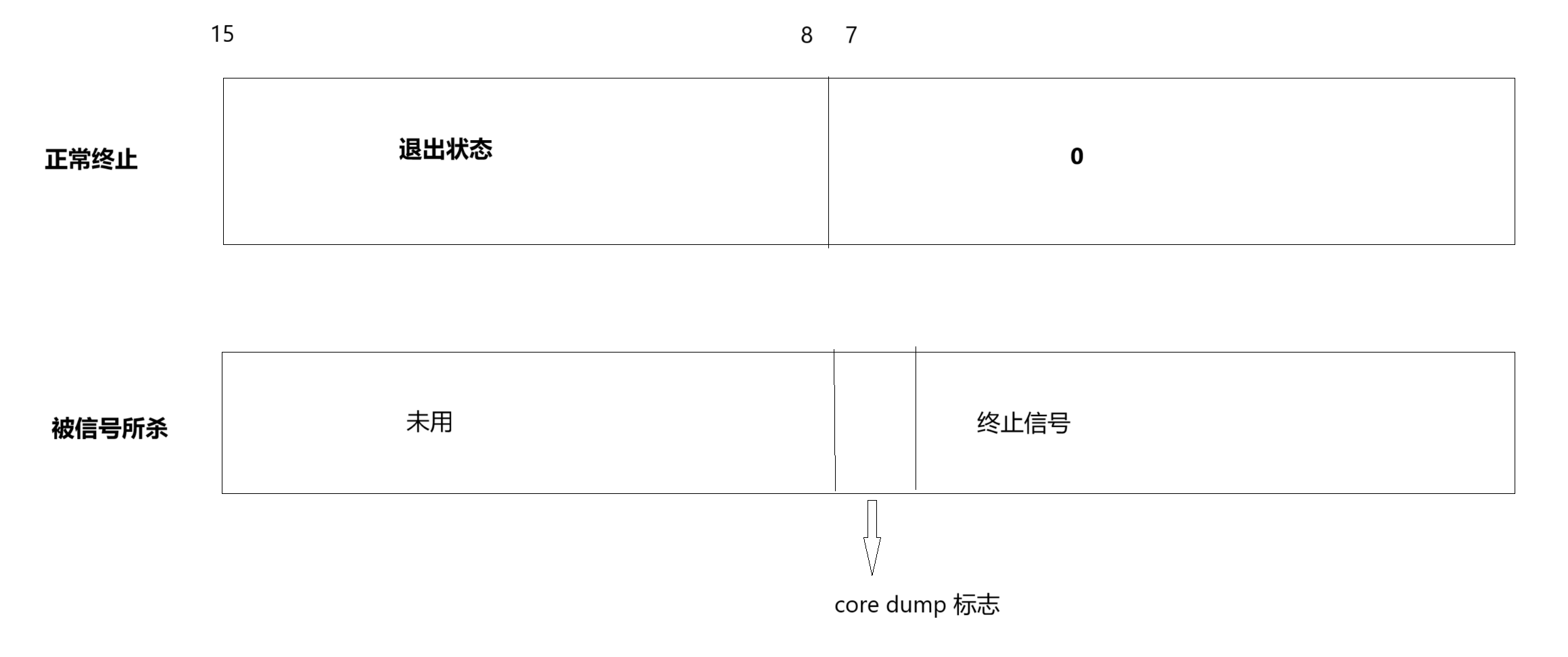
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
options:
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进
程的ID。
如果子进程已经退出,调用wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退
出信息。
如果在任意时刻调用wait/waitpid,子进程存在且正常运行,则进程可能阻塞。
如果不存在该子进程,则立即出错返回。获取子进程status
wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
如果传递NULL,表示不关心子进程的退出状态信息。
否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究status低16比特位)
父进程等待,期望获得子进程退出的哪些信息?
1.子进程代码是否异常
2.没有异常,但结果对吗?exitcode,如果不对的话是因为什么呢?
因此我们的退出码的不同,表示出不同的出错信息。
那么,我们可不可以自己自定义错误码的信息呢?
肯定是可以的,就比如说我们后面要实现日志功能,就会自己设计错误码信息。
在那里,我们会使用enum来自己实现。
ps:父进程要拿子进程的状态数据,任意数据,为什么必须要用wait等系统调用呢?
因为进程具有独立性。
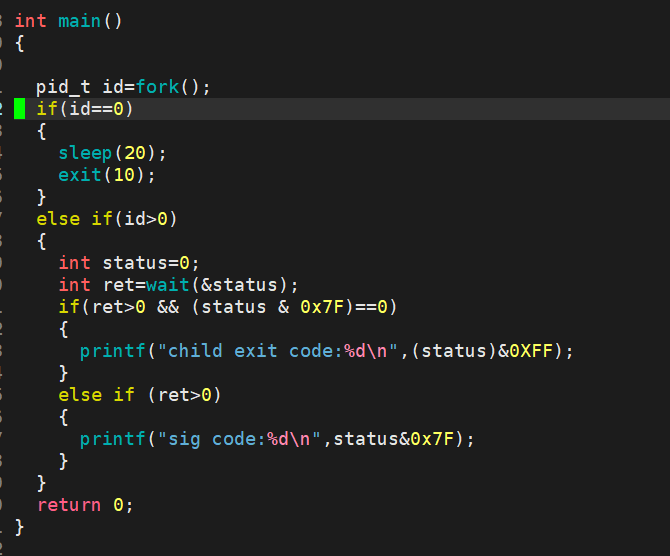


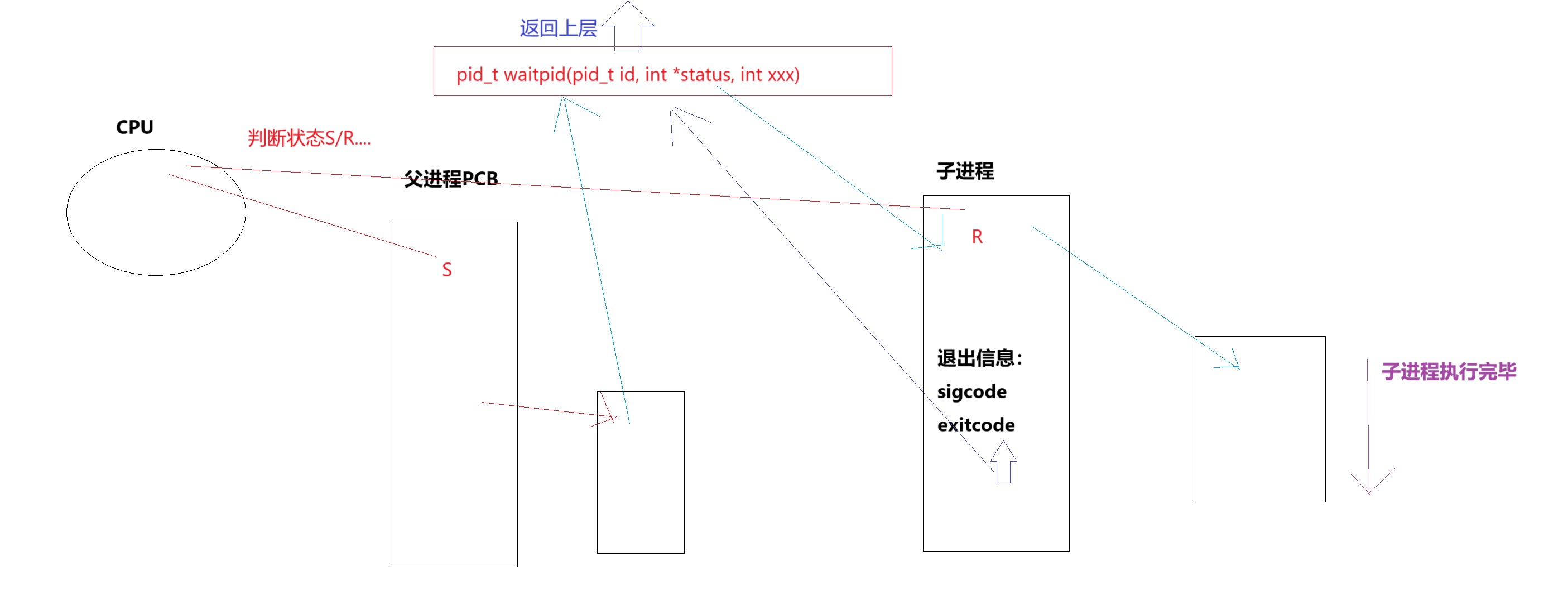

进程阻塞的等待方式:
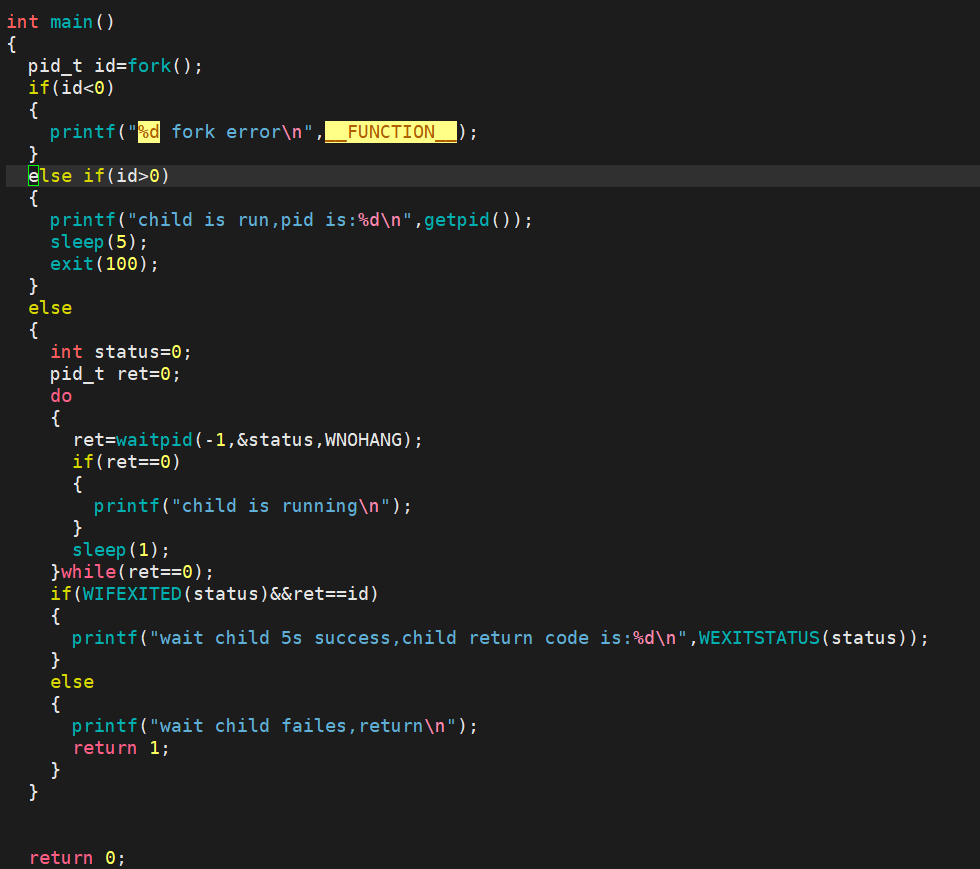
阻塞5s:
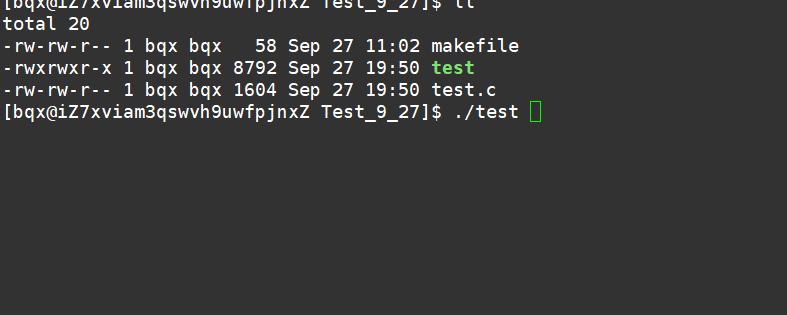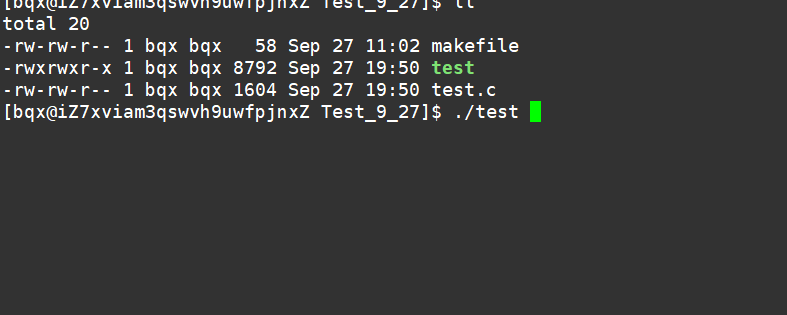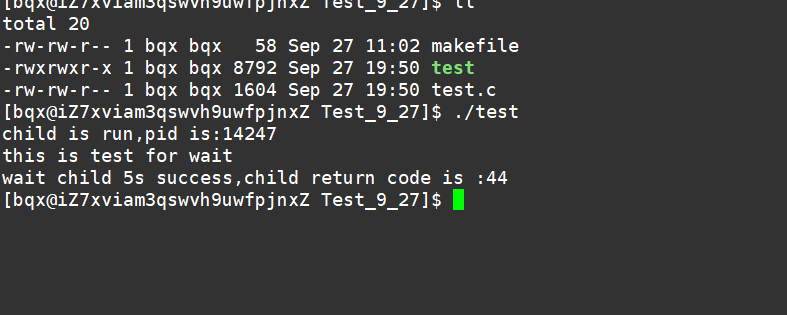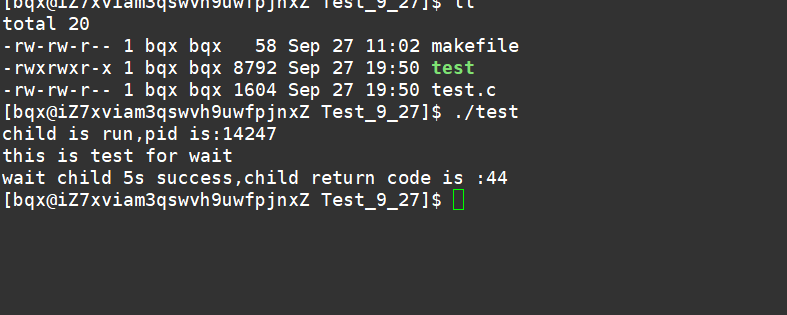
非阻塞等待方式:
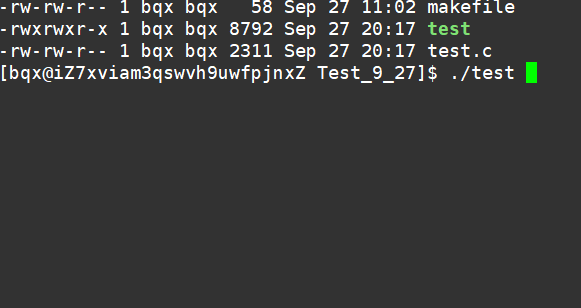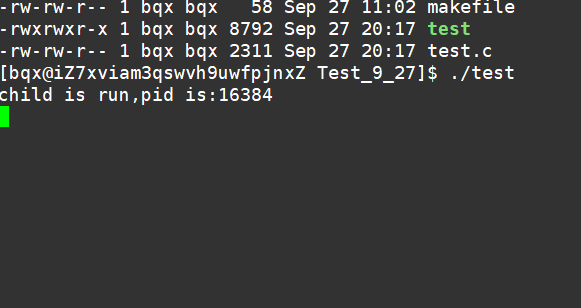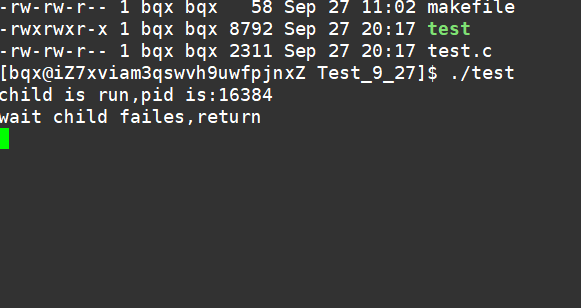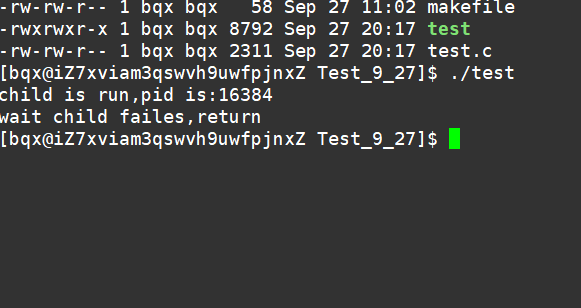
好了,关于本次的分享到处结束啦,希望大家一起进步!
最后,到了本次鸡汤环节:
愿你事事美满!
